目录
实验一 词法分析器设计... 1
【实验目的】... 1
【实验内容】... 1
【流程图】... 1
【源代码】... 2
【程序部分截图】... 18
实验二 LL(1)语法分析程序设计... 20
【实验目的】... 20
【实验内容】... 20
【实验步骤和要求】... 20
【流程图】... 20
【源代码】... 21
【程序截图】... 32
实验一 词法分析器设计
【实验目的】
1.熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。
2.复习高级语言,进一步加强用高级语言来解决实际问题的能力。
3.通过完成词法分析程序,了解词法分析的过程。
【实验内容】
用JAVA语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字,运算符,标识符,常数以及界符)输出。
 【流程图】
【流程图】

【源代码】
package accidence_analyse;
import java.io.*;
import java.util.*;
import buffer.*;
public class AccidenceAnalyser {
private java.io.File SourceFile;
private java.io.File ReserveFile;
private java.io.File ClassFile;
private java.io.File OutputFile;
public Pretreatment pretreatment;
public KeyWordTable keyWordTable;
public ClassIdentity classIdentity;
public Scaner scaner;
public ConcreteScanBufferFactory csbFactory;
/**
* 2) 词法分析器主程序
*/
public AccidenceAnalyser() {
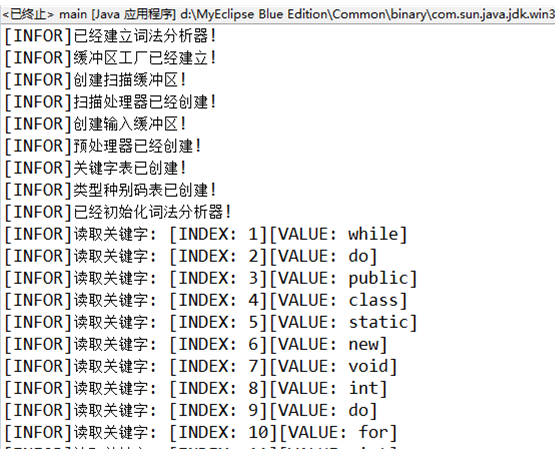
System.out.println("[INFOR]已经建立词法分析器!");
}
public void initAA() {
//创建缓冲工厂
this.csbFactory=newConcreteScanBufferFactory();
//创建字符串扫描对象
scaner = new Scaner(this);
//创建pre处理对象
pretreatment=newPretreatment(SourceFile, this);
//创建关键字表对象
keyWordTable= new KeyWordTable(ReserveFile);
//创建对象种别码表对象
classIdentity = new ClassIdentity(ClassFile);
System.out.println("[INFOR]已经初始化词法分析器!"); }
public void setFilesPath(String reserveFileName, String ClassFileName,String sourceFileName, String outputFileName) {
//创建文件对象
SourceFile = new java.io.File(sourceFileName);
//创建文件对象
ReserveFile = new java.io.File(reserveFileName);
//创建文件对象
ClassFile = new java.io.File(ClassFileName);
//创建文件对象
OutputFile = new java.io.File(outputFileName);
//如果文件已经存在,先删除,然后建立新文件
if (OutputFile.exists()) {OutputFile.delete();}
try {OutputFile.createNewFile();}
catch(Exceptione){e.printStackTrace(System.err);}
try {
//创建文件随机读取对象java.io.RandomAccessFile ROutputFile = new java.io.RandomAccessFile(this.
OutputFile, "rw");
//提示信息
ROutputFile.write("///////////////////////////////////////\n".getBytes());
ROutputFile.write( ("//JAccidenceAnalyser version " + getVersion() +" design by yellowicq//\n").getBytes());
ROutputFile.write("//java词法分析器//////////////\n".getBytes());
ROutputFile.write("//使用java语言开发///\n".getBytes());
ROutputFile.write("\n".getBytes());
ROutputFile.write("词法分析结果如下:\n".getBytes());
//关闭文件流
ROutputFile.close();
}
catch (Exception e) {
e.printStackTrace(System.err);
}
}
public void startAA() {
//从预处理开始词法分析
this.pretreatment.startPretreatment();
}
public void outputAccidence(String outputString) {
//把分析出来的单词写入文件
outputString="\n[第" + this.pretreatment.fileRow + "行]\n" + outputString;
try {
//创建文件随机读取对象
java.io.RandomAccessFile ROutputFile = new java.io.RandomAccessFile(this.OutputFile, "rw");
//移动指针到文件末尾
ROutputFile.seek(ROutputFile.length());
//Start appending!
ROutputFile.write(outputString.getBytes());
//关闭文件流
ROutputFile.close();
}
catch (Exception e) {
e.printStackTrace(System.err);
}
//将分析的单词结果输出到终端
System.out.print(outputString);
}
public void controlThread() {
//控制扫描器启动扫描
scaner.controlThread();
}
//获得版本号
public String getVersion() {
return "1.0";
}
}
package accidence_analyse;
import java.util.*;
import java.io.*;
public class ClassIdentity {
private Hashtable ClassHash;
private File ClassFile;
private FileReader classFileReader; //读文件对象
private int TMP_BUFFER_SIZE = 30;
/**
* 6) 类型种别码程序
*/
public ClassIdentity(java.io.File ClassFile) {
System.out.println("[INFOR]类型种别码表已创建!");
this.ClassFile = ClassFile;
}
//查找类型种别码
public int findKey(String classWord) {
int KEY;
for (Enumeration e = this.ClassHash.keys(); e.hasMoreElements(); ) {
KEY=Integer.parseInt((String)e.nextElement());
if( ( (String)this.ClassHash.get(Integer.toString(KEY))).equalsIgnoreCase(classWord)) {return KEY;}
}
return -1;
}
public void initClassIdentityTable() {
ClassHash = new Hashtable(); //创建hash表
int intLength;
char[] chrBuffer = new char[TMP_BUFFER_SIZE];
String classWord;
int classCounter = 0;
try {
if (ClassFile.exists()) { //文件存在
//创建读文件对象
classFileReader=newjava.io.FileReader(ClassFile);
//读文件内容到hash表
while((intLength=classFileReader.read(chrBuffer)) != -1) {
classCounter++;
//填写hash表
classWord = String.valueOf(chrBuffer).trim();
System.out.println("[INFOR]读取类型种别码: [KEY: " + classCounter + "][VALUE: " + classWord + "]");
this.ClassHash.put(Integer.toString(classCounter), classWord);
}
//关闭读文件对象
classFileReader.close();
}
else { //文件不存在
System.err.println("[ERROR]类型种别码文件不存在!");
}
}
catch (Exception e) {
e.printStackTrace(System.err);
}
}
}
package accidence_analyse;
import java.util.*;
import java.io.*;
public class KeyWordTable {
private Hashtable KWHash;
private File ReserveFile;
private FileReader resFileReader; //读文件对象
private int TMP_BUFFER_SIZE = 30;
/**
* 5) 表留字表程序
*/
public KeyWordTable(java.io.File ReserveFile) {
System.out.println("[INFOR]关键字表已创建!");
this.ReserveFile = ReserveFile;
}
public boolean isKeyWord(String inw) {
String resWord;
//查找hash表
for (Enumeration e = this.KWHash.elements(); e.hasMoreElements(); ) {
resWord = (String) e.nextElement();
if (resWord.equalsIgnoreCase(inw)) {
return true;
}
}
return false;
}
public void initKeyWordTable() {
KWHash = new Hashtable(); //创建hash表
int intLength;
char[] chrBuffer = new char[TMP_BUFFER_SIZE];
String resWord;
int resCounter = 0;
try {
if (ReserveFile.exists()) { //文件存在
//创建读文件对象
resFileReader = new java.io.FileReader(ReserveFile);
//读文件内容到hash表
while((intLength = resFileReader.read(chrBuffer))!= -1) { resCounter++;
//填写hash表
resWord = String.valueOf(chrBuffer).trim();
System.out.println("[INFOR]读取关键字: [INDEX: " + resCounter +"][VALUE: " + resWord + "]");
this.KWHash.put(Integer.toString(resCounter), resWord);}
//关闭读文件对象
resFileReader.close();
}
else { //文件不存在
System.err.println("[ERROR]保留字文件不存在!");
}
}
catch (Exception e) {
e.printStackTrace(System.err);
}
}
}
package accidence_analyse;
import javax.xml.parsers.*;
import org.w3c.dom.*;
public class main {
/**
* 1) 词法分析器引导文件
*/
public static void main(String[] args) {
//读取配置文件,得到系统属性
String cfgString[] = new String[4];
try {
cfgString = main.loadAACfg("d:\\aaCfg.xml");
}
catch (Exception e) {
e.printStackTrace(System.err);
}
//设置待读文件名
//保留字表文件
String reserveFileName = cfgString[0];
//类型种别码表文件
String classFileName = cfgString[1];
//需要分析的源文件
String sourceFileName = cfgString[2];
//输出文件
String outputFileName = cfgString[3];
//创建词法分析器
AccidenceAnalyser aa=new AccidenceAnalyser();
aa.setFilesPath(reserveFileName, classFileName, sourceFileName,outputFileName);
//建立所需要的文件对象
//初始化词法分析器
aa.initAA();
//初始化关键字表
aa.keyWordTable.initKeyWordTable();
//初始化类型种别码表
aa.classIdentity.initClassIdentityTable();
//开始进行词法分析
aa.startAA();
//分析完毕
}
//读取配置文件
private static String[] loadAACfg(String name) throws Exception {
String cfgString[] = new String[4];
/*解析xml配置文件*/
try {
/*创建文档工厂*/
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
/*创建文档解析器*/
DocumentBuilder builder = factory.newDocumentBuilder();
/*解析配置文件*/
Document doc = builder.parse(name);
/*规范化文档*/
doc.normalize();
/*查找接点表*/
NodeList nlists = doc.getElementsByTagName("FilePath");
for (int i = 0; i < nlists.getLength(); i++) {
Element item = (Element) nlists.item(i);
//取得需要的配置属性
cfgString[0] = item.getElementsByTagName("ReserveFileName").item(0).getFirstChild().getNodeValue().trim();
cfgString[1] = item.getElementsByTagName("ClassFileName").item(0).
getFirstChild().getNodeValue().trim();
cfgString[2] = item.getElementsByTagName("SourceFileName").item(0).
getFirstChild().getNodeValue().trim();
cfgString[3] = item.getElementsByTagName("OutputFileName").item(0).
getFirstChild().getNodeValue().trim();
}
}
catch (Exception e) {
e.printStackTrace();
throw new Exception("[ERROR]加载配置文件 " + name + " 错误!");
}
//返回属性数组
return cfgString;
}
}
package accidence_analyse;
import java.io.*;
import buffer.*;
public class Pretreatment {
private String tmpString;
private String outputString;
private int BUFFER_SIZE = 100;
private AccidenceAnalyser aa;
public InputBuffer inputBuffer; //输入缓冲区--共享
private java.io.File SourceFile; //文件对象
private java.io.RandomAccessFile randomAFile; //随机文件对象
public static int fileRow = 0;
/**
* 3) 预处理子程序
*/
public Pretreatment(File SourceFile, AccidenceAnalyser aa) {
try {
this.SourceFile = SourceFile;
this.randomAFile = new java.io.RandomAccessFile(this.SourceFile, "r");
}
catch (FileNotFoundException e) {
e.printStackTrace(System.err);
}
this.aa = aa;
inputBuffer = aa.csbFactory.createInputBuffer(BUFFER_SIZE);
System.out.println("[INFOR]预处理器已经创建!");
}
public void putSourceToINBuffer(String tmpString) {
this.inputBuffer.Data = tmpString.toCharArray();
}
public void putFinToSCBuffer(String filtratedString) {
aa.scaner.scanBuffer.Data = filtratedString.toCharArray();
}
public void controlThread() {
int intLength;
int resCounter = 0;
String tmpString;
String filtratedString;
System.out.println("[INFOR]开始单词分析////////////////////////////////////////");
try {
if (SourceFile.exists()) { //文件存在
//读文件内容到缓冲区
while ( (tmpString = this.randomAFile.readLine()) != null) {
++fileRow;
//分割符
System.out.println("...................begin row " + this.fileRow +
".......................");
//开始这一行分析
System.out.println("[INFOR]正在处理行: " + String.valueOf(fileRow));
//放入输入缓冲区
this.putSourceToINBuffer(tmpString);
//处理字符串
filtratedString = this.filtrateSource(this.inputBuffer.Data);
System.out.println("[INFOR]已过滤句子: " + filtratedString);
//放入扫描缓冲区
this.putFinToSCBuffer(filtratedString);
aa.controlThread();
}
System.out.println(
"[INFOR]分析完毕////////////////////////////////////////////");
}
else { //文件不存在
System.err.println("[ERROR]源文件不存在!");
}
}
catch (Exception e) {
e.printStackTrace(System.err);
}
}
public String filtrateSource(char[] Data) {
String filtratedString = String.valueOf(Data).trim();
return filtratedString;
}
public void startPretreatment() {
this.controlThread();
}
}
package accidence_analyse;
import buffer.*;
publicclass Scaner {
public ScanBuffer scanBuffer; //扫描缓冲区--共享
private String finalAccidence;
private AccidenceAnalyser aa;
privateint BUFFER_SIZE = 100;
private String toDelString;
privateint senLength = 0;
privatechar[] sentenceChar = newchar[1000];
private String TOKEN;
privatechar CHAR;
privateint index = 0;
private String IDENTITY = "identity";
private String DIGIT = "digit";
private String WORD_ERROR_INF = "在此行发现不能识别的单词,此行分析终止!";
privateboolean ASTATE = true;
/**
* 4) 扫描子程序
*/
public Scaner(AccidenceAnalyser aa) {
this.aa = aa;
initBuffer();
this.finalAccidence = "";
System.out.println("[INFOR]扫描处理器已经创建!");
}
public String readFromBuffer(char[] Data) {
String toDelString = String.valueOf(Data);
return toDelString;
}
public String scan(String toDelString) {
sentenceChar = toDelString.toCharArray();
this.senLength = sentenceChar.length;
inti = 0;
//分析单词
while (this.index <= this.senLength) {
//state0:
this.TOKEN = "";
this.CHAR = GETBC(sentenceChar);
if (this.CHAR == ';') {
break; //';'表示这一行结束
}
//进入状态判断
switch (this.CHAR) {
//judge letter
case 'a':case 'b':case 'c':case 'd':case 'e':case 'f':case 'g':case 'h':case 'i':case 'j':case 'k':
case 'l':case 'm':case 'n':case 'o':case 'p':case 'q':case 'r':case 's':case 't':case 'u':case 'v':case 'w':case 'x':case 'y':
case 'z':case 'A':case 'B':case 'C':case 'D':case 'E':case 'F':case 'G':case 'H':case 'I':case 'J':case 'K':case 'L':case 'M':
case 'N':case 'O':case 'P':case 'Q':case 'R':case 'S':case 'T':case 'U':case 'V':case 'W':case 'X':case 'Y':case 'Z':
//do
this.TOKEN = this.CONTACT(TOKEN, CHAR);
//state1
CHAR = this.GETCHAR(sentenceChar);
while (this.ISLETTER(CHAR) || this.ISDIGIT(CHAR)) {
this.TOKEN = this.CONTACT(this.TOKEN, CHAR);
CHAR = this.GETCHAR(sentenceChar);
}
this.RETRACT();
//state2
if (aa.keyWordTable.isKeyWord(TOKEN)) {
this.finalAccidence = this.finalAccidence + "[保留字] " +
this.returnAWord(TOKEN) + "\n";
}
else {
this.finalAccidence = this.finalAccidence + "[标识符] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(IDENTITY)) + "\n";
}
//clear up token
this.TOKEN = "";
break;
//judge ditital
case '0':case '1':case '2':case '3':case '4':case '5':case '6':case '7':case '8': case '9':
//do
this.TOKEN = this.CONTACT(TOKEN, CHAR);
//state3
CHAR = this.GETCHAR(sentenceChar);
while (this.ISDIGIT(CHAR)) {
this.TOKEN = this.CONTACT(TOKEN, CHAR);
CHAR = this.GETCHAR(sentenceChar);
}
this.RETRACT();
//state4
this.finalAccidence = this.finalAccidence + "[数字] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(DIGIT)) + "\n";
//clear up token
this.TOKEN = "";
break;
case '=':
//state5
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[等号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '+':
//state6
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[加号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '*':
//state7
this.TOKEN = this.CONTACT(TOKEN, CHAR);
CHAR = this.GETCHAR(sentenceChar);
//state8
if (CHAR == '*') {
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[乘方] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
}
//state9
else {
this.finalAccidence = this.finalAccidence + "[乘号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
}
//clear up token
this.TOKEN = "";
break;
case ',':
//state10
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[逗号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '(':
//state11
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[左括号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case ')':
//state12
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[右括号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '{':
//state13
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[左大括号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '}':
//state14
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[右大括号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '[':
//state15
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[左中括号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case ']':
//state16
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[右中括号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
case '.':
//state17
this.TOKEN = this.CONTACT(TOKEN, CHAR);
this.finalAccidence = this.finalAccidence + "[点号] " +
this.returnAWord(TOKEN) + "[种别码] " +
String.valueOf(aa.classIdentity.findKey(String.valueOf(CHAR))) +
"\n";
//clear up token
this.TOKEN = "";
break;
default:
//state18
this.TOKEN = this.CONTACT(this.TOKEN, this.CHAR);
//追加出错信息
this.finalAccidence = this.finalAccidence + "[ERROR]" +
this.WORD_ERROR_INF + "'" + this.TOKEN + "'" + "\n";
this.ASTATE = false;
//clear up token
this.TOKEN = "";
break;
}
if (this.ASTATE == false) {
break;
}
}
returnthis.finalAccidence;
}
publicvoid controlThread() {
this.toDelString = this.readFromBuffer(this.scanBuffer.Data);
this.aa.outputAccidence(this.scan(this.toDelString));
//分割符
System.out.println("...................end row " + aa.pretreatment.fileRow +
".........................");
//结束这一行分析
//clear up the var
this.index = 0;
this.finalAccidence = "";
this.ASTATE = true;
this.toDelString = "";
this.senLength = 0;
this.TOKEN = "";
}
public String returnAWord(String TOKEN) {
return TOKEN;
}
publicvoid initBuffer() {
this.scanBuffer = aa.csbFactory.createScanBuffer(BUFFER_SIZE);
}
//以下为字符的处理方法
publicchar GETBC(char[] sentenceChar) {
try {
while ( (sentenceChar[this.index]) == ' ') {
this.index++;
}
this.index++;
}
catch (java.lang.ArrayIndexOutOfBoundsException e) {
return ';'; //表示此行已经结束
}
return sentenceChar[index - 1];
}
publicchar GETCHAR(char[] sentenceChar) {
next();
return sentenceChar[this.index - 1];
}
publicvoid next() {
this.index++;
}
publicboolean ISLETTER(char letter) {
return java.lang.Character.isLetter(letter);
}
publicboolean ISDIGIT(char letter) {
return java.lang.Character.isDigit(letter);
}
public String CONTACT(String TOKEN, char CHAR) {
String tmpS = TOKEN + String.valueOf(CHAR);
TOKEN = tmpS;
return TOKEN;
}
publicboolean ISRESERVE(String TOKEN) {
return aa.keyWordTable.isKeyWord(TOKEN);
}
publicvoid RETRACT() {
this.index--;
}
}
package buffer;
//abstract buffer interface
publicinterface Buffer {
}
package buffer;
publicinterface BufferFactory {
/**
* 7) 抽象扫描缓冲区工厂
*/
public ScanBuffer createScanBuffer(int size);
public InputBuffer createInputBuffer(int size);
}
package buffer;
publicclass ConcreteScanBufferFactory
implements BufferFactory {
/**
* 8) 缓冲区工厂
*/
public ConcreteScanBufferFactory() {
System.out.println("[INFOR]缓冲区工厂已经建立!");
}
public ScanBuffer createScanBuffer(int size) {
System.out.println("[INFOR]创建扫描缓冲区!");
returnnew ScanBuffer(size);
}
publicInputBuffer createInputBuffer(int size) {
System.out.println("[INFOR]创建输入缓冲区!");
returnnew InputBuffer(size);
}
}
package buffer;
importjava.io.*;
publicclass InputBuffer
implements Buffer {
publicchar[] Data;
/**
* 10) 输入缓冲区对象
*/
public InputBuffer(int size) {
this.Data = newchar[size];
}
}
package buffer;
publicclass ScanBuffer
implements Buffer {
publicchar[] Data;
/**
* 11) 扫描缓冲区对象
*/
public ScanBuffer(int size) {
this.Data = newchar[size];
}
}
【程序部分截图】

实验二 LL(1)语法分析程序设计
【实验目的】
1.熟悉判断LL(1)文法的方法及对某一输入串的分析过程。
2.学会构造表达式文法的预测分析表。
【实验内容】
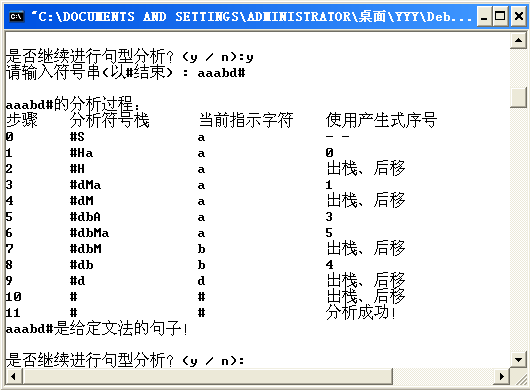
编写一个语法分析程序,对于给定的输入串,能够判断识别该串是否为给定文法的句型。
【实验步骤和要求】
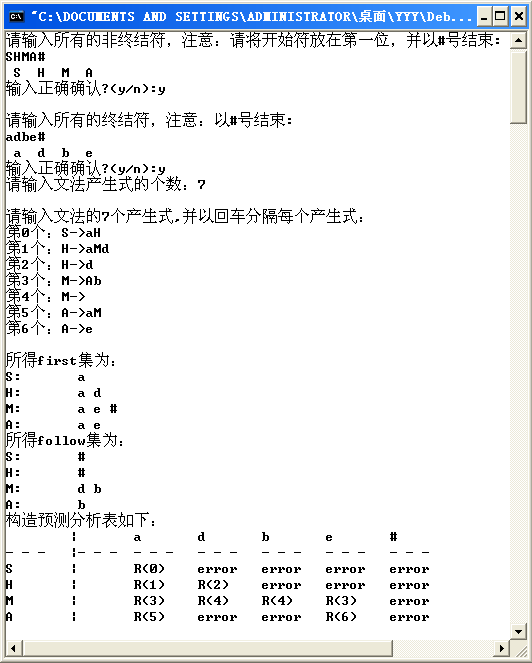
1. 从键盘读入输入串,并判断正误;
2. 若无误,由程序自动构造FIRST、FOLLOW集以及SELECT集合,判断是否为LL(1)文法;
3. 若符合LL(1)文法,由程序自动构造LL(1)分析表;
4. 由算法判断输入符号串是否为该文法的句型。(可参考教材96页的例题1)
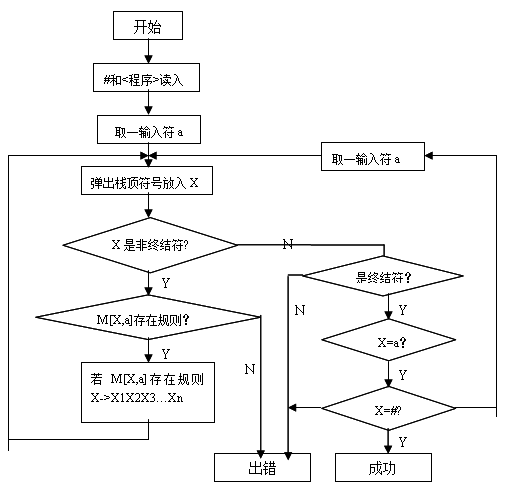
【流程图】
【源代码】
#include "stdio.h"
#include "stdlib.h"
#define MaxRuleNum 8
#define MaxVnNum 5
#define MaxVtNum 5
#define MaxStackDepth 20
#define MaxPLength 20
#define MaxStLength 50
struct pRNode /*产生式右部结构*/
{
int rCursor; /*右部序号*/
struct pRNode *next;
};
struct pNode /*产生式结点结构*/
{
int lCursor; /*左部符号序号*/
int rLength; /*右部长度*/
/*注当rLength = 1 时,rCursor = -1为空产生式*/
struct pRNode *rHead; /*右部结点头指针*/
};
char Vn[MaxVnNum + 1]; /*非终结符集*/
int vnNum;
char Vt[MaxVtNum + 1]; /*终结符集*/
int vtNum;
struct pNode P[MaxRuleNum]; /*产生式*/
int PNum; /*产生式实际个数*/
char buffer[MaxPLength + 1];
char ch; /*符号或string ch;*/
char st[MaxStLength]; /*要分析的符号串*/
struct collectNode /*集合元素结点结构*/
{
int nVt; /*在终结符集中的下标*/
struct collectNode *next;
};
struct collectNode* first[MaxVnNum + 1]; /*first集*/
struct collectNode* follow[MaxVnNum + 1]; /*follow集*/
int analyseTable[MaxVnNum + 1][MaxVtNum + 1 + 1];
/*预测分析表存放为产生式的编号,+1用于存放结束符,多+1用于存放#(-1)*/
int analyseStack[MaxStackDepth + 1]; /*分析栈*/
int topAnalyse; /*分析栈顶*/
/*int reverseStack[MaxStackDepth + 1]; /*颠倒顺序栈*/
/*int topReverse; /*倒叙栈顶*/
void Init();/*初始化*/
int IndexCh(char ch);
/*返回Vn在Vn表中的位置+100、Vt在Vt表中的位置,-1表示未找到*/
void InputVt(); /*输入终结符*/
void InputVn();/*输入非终结符*/
void ShowChArray(char* collect, int num);/*输出Vn或Vt的内容*/
void InputP();/*产生式输入*/
bool CheckP(char * st);/*判断产生式正确性*/
void First(int U);/*计算first集,U->xx...*/
void AddFirst(int U, int nCh); /*加入first集*/
bool HaveEmpty(int nVn); /*判断first集中是否有空(-1)*/
void Follow(int V);/*计算follow集*/
void AddFollow(int V, int nCh, int kind);/*加入follow集,
kind = 0表加入follow集,kind = 1加入first集*/
void ShowCollect(struct collectNode **collect);/*输出first或follow集*/
void FirstFollow();/*计算first和follow*/
void CreateAT();/*构造预测分析表*/
void ShowAT();/*输出分析表*/
void Identify(char *st);/*主控程序,为操作方便*/
/*分析过程显示操作为本行变换所用,与教程的显示方式不同*/
void InitStack();/*初始化栈及符号串*/
void ShowStack();/*显示符号栈中内容*/
void Pop();/*栈顶出栈*/
void Push(int r);/*使用产生式入栈操作*/
#include "LL1.h"
void main(void)
{
char todo,ch;
Init();
InputVn();
InputVt();
InputP();
getchar();
FirstFollow();
printf("所得first集为:");
ShowCollect(first);
printf("所得follow集为:");
ShowCollect(follow);
CreateAT();
ShowAT();
todo = 'y';
while('y' == todo)
{
printf("\n是否继续进行句型分析?(y / n):");
todo = getchar();
while('y' != todo && 'n' != todo)
{
printf("\n(y / n)? ");
todo = getchar();
}
if('y' == todo)
{
int i;
InitStack();
printf("请输入符号串(以#结束) : ");
ch = getchar();
i = 0;
while('#' != ch && i < MaxStLength)
{
if(' ' != ch && '\n' != ch)
{
st[i++] = ch;
}
ch = getchar();
}
if('#' == ch && i < MaxStLength)
{
st[i] = ch;
Identify(st);
}
else
printf("输入出错!\n");
}
}
getchar();
}
void Init()
{
int i,j;
vnNum = 0;
vtNum = 0;
PNum = 0;
for(i = 0; i <= MaxVnNum; i++)
Vn[i] = '\0';
for(i = 0; i <= MaxVtNum; i++)
Vt[i] = '\0';
for(i = 0; i < MaxRuleNum; i++)
{
P[i].lCursor = NULL;
P[i].rHead = NULL;
P[i].rLength = 0;
}
PNum = 0;
for(i = 0; i <= MaxPLength; i++)
buffer[i] = '\0';
for(i = 0; i < MaxVnNum; i++)
{
first[i] = NULL;
follow[i] = NULL;
}
for(i = 0; i <= MaxVnNum; i++)
{
for(j = 0; j <= MaxVnNum + 1; j++)
analyseTable[i][j] = -1;
}
}
/*返回Vn在Vn表中的位置+100、Vt在Vt表中的位置,-1表示未找到*/
int IndexCh(char ch)
{
int n;
n = 0; /*is Vn?*/
while(ch != Vn[n] && '\0' != Vn[n])
n++;
if('\0' != Vn[n])
return 100 + n;
n = 0; /*is Vt?*/
while(ch != Vt[n] && '\0' != Vt[n])
n++;
if('\0' != Vt[n])
return n;
return -1;
}
/*输出Vn或Vt的内容*/
void ShowChArray(char* collect)
{
int k = 0;
while('\0' != collect[k])
{
printf(" %c ", collect[k++]);
}
printf("\n");
}
/*输入非终结符*/
void InputVn()
{
int inErr = 1;
int n,k;
char ch;
while(inErr)
{
printf("\n请输入所有的非终结符,注意:");
printf("请将开始符放在第一位,并以#号结束:\n");
ch = ' ';
n = 0;
/*初始化数组*/
while(n < MaxVnNum)
{
Vn[n++] = '\0';
}
n = 0;
while(('#' != ch) && (n < MaxVnNum))
{
if(' ' != ch && '\n' != ch && -1 == IndexCh(ch))
{
Vn[n++] = ch;
vnNum++;
}
ch = getchar();
}
Vn[n] = '#'; /*以“#”标志结束用于判断长度是否合法*/
k = n; /*k用于记录n以便改Vn[n]='\0'*/
if('#' != ch)
{
if( '#' != (ch = getchar()))
{
while('#' != (ch = getchar()))
;
printf("\n符号数目超过限制!\n");
inErr = 1;
continue;
}
}
/*正确性确认,正确则,执行下下面,否则重新输入*/
Vn[k] = '\0';
ShowChArray(Vn);
ch = ' ';
while('y' != ch && 'n' != ch)
{
if('\n' != ch)
{
printf("输入正确确认?(y/n):");
}
scanf("%c", &ch);
}
if('n' == ch)
{
printf("录入错误重新输入!\n");
inErr = 1;
}
else
{
inErr = 0;
}
}
}
/*输入终结符*/
void InputVt()
{
int inErr = 1;
int n,k;
char ch;
while(inErr)
{
printf("\n请输入所有的终结符,注意:");
printf("以#号结束:\n");
ch = ' ';
n = 0;
/*初始化数组*/
while(n < MaxVtNum)
{
Vt[n++] = '\0';
}
n = 0;
while(('#' != ch) && (n < MaxVtNum))
{
if(' '!= ch && '\n' != ch && -1 == IndexCh(ch))
{
Vt[n++] = ch;
vtNum++;
}
ch = getchar();
}
Vt[n] = '#'; /*以“#”标志结束*/
k = n; /*k用于记录n以便改Vt[n]='\0'*/
if('#' != ch)
{
if( '#' != (ch = getchar()))
{
while('#' != (ch = getchar()))
printf("\n符号数目超过限制!\n");
inErr = 1;
continue;
}
}
/*正确性确认,正确则,执行下下面,否则重新输入*/
Vt[k] = '\0';
ShowChArray(Vt);
ch =' ';
while('y' != ch && 'n' != ch)
{
if('\n' != ch)
{
printf("输入正确确认?(y/n):");
}
scanf("%c", &ch);
}
if('n' == ch)
{
printf("录入错误重新输入!\n");
inErr = 1;
}
else
{
inErr = 0;
}
}
}
/*产生式输入*/
void InputP()
{
char ch;
int i = 0, n,num;
printf("请输入文法产生式的个数:");
scanf("%d", &num);
PNum = num;
getchar(); /*消除回车符*/
printf("\n请输入文法的%d个产生式,并以回车分隔每个产生式:", num);
printf("\n");
while(i < num)
{
printf("第%d个:", i);
/*初始化*/
for(n =0; n < MaxPLength; n++)
buffer[n] = '\0';
/*输入产生式串*/
ch = ' ';
n = 0;
while('\n' != (ch = getchar()) && n < MaxPLength)
{
if(' ' != ch)
buffer[n++] = ch;
}
buffer[n] = '\0';
/* printf("%s", buffer);*/
if(CheckP(buffer))
{
/*填写入产生式结构体*/
pRNode *pt, *qt;
P[i].lCursor = IndexCh(buffer[0]);
pt = (pRNode*)malloc(sizeof(pRNode));
pt->rCursor = IndexCh(buffer[3]);
pt->next = NULL;
P[i].rHead = pt;
n = 4;
while('\0' != buffer[n])
{
qt = (pRNode*)malloc(sizeof(pRNode));
qt->rCursor = IndexCh(buffer[n]);
qt->next = NULL;
pt->next = qt;
pt = qt;
n++;
}
P[i].rLength = n - 3;
i++;
/*调试时使用*/
}
else
printf("输入符号含非法在成分,请重新输入!\n");
}
}
/*判断产生式正确性*/
bool CheckP(char * st)
{
int n;
if(100 > IndexCh(st[0]))
return false;
if('-' != st[1])
return false;
if('>' != st[2])
return false;
for(n = 3; '\0' != st[n]; n ++)
{
if(-1 == IndexCh(st[n]))
return false;
}
return true;
}
/*====================first & follow======================*/
/*计算first集,U->xx...*/
void First(int U)
{
int i,j;
for(i = 0; i < PNum; i++)
{
if(P[i].lCursor == U)
{
struct pRNode* pt;
pt = P[i].rHead;
j = 0;
while(j < P[i].rLength)
{
if(100 > pt->rCursor)
{
/*注:此处因编程出错,使空产生式时
rlength同样是1,故此处同样可处理空产生式*/
AddFirst(U, pt->rCursor);
break;
}
else
{
if(NULL == first[pt->rCursor - 100])
{
First(pt->rCursor);
}
AddFirst(U, pt->rCursor);
if(!HaveEmpty(pt->rCursor))
{
break;
}
else
{
pt = pt->next;
}
}
j++;
}
if(j >= P[i].rLength) /*当产生式右部都能推出空时*/
AddFirst(U, -1);
}
}
}
/*加入first集*/
void AddFirst(int U, int nCh) /*当数值小于100时nCh为Vt*/
/*当处理非终结符时,AddFirst不添加空项(-1)*/
{
struct collectNode *pt, *qt;
int ch; /*用于处理Vn*/
pt = NULL;
qt = NULL;
if(nCh < 100)
{
pt = first[U - 100];
while(NULL != pt)
{
if(pt->nVt == nCh)
break;
else
{
qt = pt;
pt = pt->next;
}
}
if(NULL == pt)
{
pt = (struct collectNode *)malloc(sizeof(struct collectNode));
pt->nVt = nCh;
pt->next = NULL;
if(NULL == first[U - 100])
{
first[U - 100] = pt;
}
else
{
qt->next = pt; /*qt指向first集的最后一个元素*/
}
pt = pt->next;
}
}
else
{
pt = first[nCh - 100];
while(NULL != pt)
{
ch = pt->nVt;
if(-1 != ch)
{
AddFirst(U, ch);
}
pt = pt->next;
}
}
}
/*判断first集中是否有空(-1)*/
bool HaveEmpty(int nVn)
{
if(nVn < 100) /*为终结符时(含-1),在follow集中用到*/
return false;
struct collectNode *pt;
pt = first[nVn - 100];
while(NULL != pt)
{
if(-1 == pt->nVt)
return true;
pt = pt->next;
}
return false;
}
/*计算follow集,例:U->xVy,U->xV.(注:初始符必含#——"-1")*/
void Follow(int V)
{
int i;
struct pRNode *pt ;
if(100 == V) /*当为初始符时*/
AddFollow(V, -1, 0 );
for(i = 0; i < PNum; i++)
{
pt = P[i].rHead;
while(NULL != pt && pt->rCursor != V) /*注此不能处理:U->xVyVz的情况*/
pt = pt->next;
if(NULL != pt)
{
pt = pt->next; /*V右侧的符号*/
if(NULL == pt) /*当V后为空时V->xV,将左符的follow集并入V的follow集中*/
{
if(NULL == follow[P[i].lCursor - 100] && P[i].lCursor != V)
{
Follow(P[i].lCursor);
}
AddFollow(V, P[i].lCursor, 0);
}
else /*不为空时V->xVy,(注意:y->),调用AddFollow加入Vt或y的first集*/
{
while(NULL != pt && HaveEmpty(pt->rCursor))
{
AddFollow(V, pt->rCursor, 1); /*y的前缀中有空时,加如first集*/
pt = pt->next;
}
if(NULL == pt) /*当后面的字符可以推出空时*/
{
if(NULL == follow[P[i].lCursor - 100] && P[i].lCursor != V)
{
Follow(P[i].lCursor);
}
AddFollow(V, P[i].lCursor, 0);
}
else /*发现不为空的字符时*/
{
AddFollow(V, pt->rCursor, 1);
}
}
}
}
}
/*当数值小于100时nCh为Vt*/
/*#用-1表示,kind用于区分是并入符号的first集,还是follow集
kind = 0表加入follow集,kind = 1加入first集*/
void AddFollow(int V, int nCh, int kind)
{
struct collectNode *pt, *qt;
int ch; /*用于处理Vn*/
pt = NULL;
qt = NULL;
if(nCh < 100) /*为终结符时*/
{
pt = follow[V - 100];
while(NULL != pt)
{
if(pt->nVt == nCh)
break;
else
{
qt = pt;
pt = pt->next;
}
}
if(NULL == pt)
{
pt = (struct collectNode *)malloc(sizeof(struct collectNode));
pt->nVt = nCh;
pt->next = NULL;
if(NULL == follow[V - 100])
{
follow[V - 100] = pt;
}
else
{
qt->next = pt; /*qt指向follow集的最后一个元素*/
}
pt = pt->next;
}
}
else /*为非终结符时,要区分是加first还是follow*/
{
if(0 == kind)
{
pt = follow[nCh - 100];
while(NULL != pt)
{
ch = pt->nVt;
AddFollow(V, ch, 0);
pt = pt->next;
}
}
else
{
pt = first[nCh - 100];
while(NULL != pt)
{
ch = pt->nVt;
if(-1 != ch)
{
AddFollow(V, ch, 1);
}
pt = pt->next;
}
}
}
}
/*输出first或follow集*/
void ShowCollect(struct collectNode **collect)
{
int i;
struct collectNode *pt;
i = 0;
while(NULL != collect[i])
{
pt = collect[i];
printf("\n%c:\t", Vn[i]);
while(NULL != pt)
{
if(-1 != pt->nVt)
{
printf(" %c", Vt[pt->nVt]);
}
else
printf(" #");
pt = pt->next;
}
i++;
}
printf("\n");
}
/*计算first和follow*/
void FirstFollow()
{
int i;
i = 0;
while('\0' != Vn[i])
{
if(NULL == first[i])
First(100 + i);
i++;
}
i = 0;
while('\0' != Vn[i])
{
if(NULL == follow[i])
Follow(100 + i);
i++;
}
}
/*=================构造预测分析表,例:U::xyz=============*/
void CreateAT()
{
int i;
struct pRNode *pt;
struct collectNode *ct;
for(i = 0; i < PNum; i++)
{
pt = P[i].rHead;
while(NULL != pt && HaveEmpty(pt->rCursor))
{
/*处理非终结符,当为终结符时,定含空为假跳出*/
ct = first[pt->rCursor - 100];
while(NULL != ct)
{
if(-1 != ct->nVt)
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
ct = ct->next;
}
pt = pt->next;
}
if(NULL == pt)
{
/*NULL == pt,说明xyz->,用到follow中的符号*/
ct = follow[P[i].lCursor - 100];
while(NULL != ct)
{
if(-1 != ct->nVt)
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
else /*当含有#号时*/
analyseTable[P[i].lCursor - 100][vtNum] = i;
ct = ct->next;
}
}
else
{
if(100 <= pt->rCursor) /*不含空的非终结符*/
{
ct = first[pt->rCursor - 100];
while(NULL != ct)
{
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
ct = ct->next;
}
}
else /*终结符或者空*/
{
if(-1 == pt->rCursor) /*-1为空产生式时*/
{
ct = follow[P[i].lCursor - 100];
while(NULL != ct)
{
if(-1 != ct->nVt)
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
else /*当含有#号时*/
analyseTable[P[i].lCursor - 100][vtNum] = i;
ct = ct->next;
}
}
else /*为终结符*/
{
analyseTable[P[i].lCursor - 100][pt->rCursor] = i;
}
}
}
}
}
/*输出分析表*/
void ShowAT()
{
int i,j;
printf("构造预测分析表如下:\n");
printf("\t|\t");
for(i = 0; i < vtNum; i++)
{
printf("%c\t", Vt[i]);
}
printf("#\t\n");
printf("- - -\t|- - -\t");
for(i = 0; i <= vtNum; i++)
printf("- - -\t");
printf("\n");
for(i = 0; i < vnNum; i++)
{
printf("%c\t|\t", Vn[i]);
for(j = 0; j <= vtNum; j++)
{
if(-1 != analyseTable[i][j])
printf("R(%d)\t", analyseTable[i][j]);
else
printf("error\t");
}
printf("\n");
}
}
/*=================主控程序=====================*/
void Identify(char *st)
{
int current,step,r; /*r表使用的产生式的序号*/
printf("\n%s的分析过程:\n", st);
printf("步骤\t分析符号栈\t当前指示字符\t使用产生式序号\n");
step = 0;
current = 0; /*符号串指示器*/
printf("%d\t",step);
ShowStack();
printf("\t\t%c\t\t- -\n", st[current]);
while('#' != st[current])
{
if(100 > analyseStack[topAnalyse]) /*当为终结符时*/
{
if(analyseStack[topAnalyse] == IndexCh(st[current]))
{
/*匹配出栈,指示器后移*/
Pop();
current++;
step++;
printf("%d\t", step);
ShowStack();
printf("\t\t%c\t\t出栈、后移\n", st[current]);
}
else
{
printf("%c-%c不匹配!", analyseStack[topAnalyse], st[current]);
printf("此串不是此文法的句子!\n");
return;
}
}
else /*当为非终结符时*/
{
r = analyseTable[analyseStack[topAnalyse] - 100][IndexCh(st[current])];
if(-1 != r)
{
Push(r); /*产生式右部代替左部,指示器不移动*/
step++;
printf("%d\t", step);
ShowStack();
printf("\t\t%c\t\t%d\n", st[current], r);
}
else
{
printf("无可用产生式,此串不是此文法的句子!\n");
return;
}
}
}
if('#' == st[current])
{
if(0 == topAnalyse && '#' == st[current])
{
step++;
printf("%d\t", step);
ShowStack();
printf("\t\t%c\t\t分析成功!\n", st[current]);
printf("%s是给定文法的句子!\n", st);
}
else
{ while(topAnalyse > 0)
{ if(100 > analyseStack[topAnalyse]) /*当为终结符时*/
{ printf("无可用产生式,此串不是此文法的句子!\n");
return;
}
else
{ r = analyseTable[analyseStack[topAnalyse] - 100][vtNum];
if(-1 != r)
{ Push(r); /*产生式右部代替左部,指示器不移动*/
step++;
printf("%d\t", step);
ShowStack();
if(0 == topAnalyse && '#' == st[current])
{ printf("\t\t%c\t\t分析成功!\n", st[current]);
printf("%s是给定文法的句子!\n", st);
}
else
printf("\t\t%c\t\t%d\n", st[current], r); }
else
{ printf("无可用产生式,此串不是此文法的句子!\n");
return; }
}
}
}
}
}
/*初始化栈及符号串*/
void InitStack()
{ int i;
/*分析栈的初始化*/
for(i = 0; i < MaxStLength; i++)
st[i] = '\0';
analyseStack[0] = -1; /*#(-1)入栈*/
analyseStack[1] = 100; /*初始符入栈*/
topAnalyse = 1;
}
/*显示符号栈中内容*/
void ShowStack()
{ int i;
for(i = 0; i <= topAnalyse; i++)
{ if(100 <= analyseStack[i])
printf("%c", Vn[analyseStack[i] - 100]);
else
{ if(-1 != analyseStack[i])
printf("%c", Vt[analyseStack[i]]);
else
printf("#");
}
}
}
/*栈顶出栈*/
void Pop()
{ topAnalyse--;
}
/*使用产生式入栈操作*/
void Push(int r)
{ int i;
struct pRNode *pt;
Pop();
pt = P[r].rHead;
if(-1 == pt->rCursor) /*为空产生式时*/
return;
topAnalyse += P[r].rLength;
for(i = 0; i < P[r].rLength; i++)
{ /*不为空产生式时*/
analyseStack[topAnalyse - i] = pt->rCursor;/*逆序入栈*/
pt = pt->next;
}/*循环未完时pt为空,则说明rLength记录等出错*/
}
【程序截图】