《数据结构》实验教学大纲
课程编号:020213040 课程学时/学分:60/3 实验总学时:10
课程英文名称: Data Structure 课程类别:技术基础课
开出学期:第四学期/第六学期 开出单位(实验室):信息学院教学机房
制定人:张丽霞 讲师
一、制定依据
根据内蒙古工业大学03版计算机科学与技术专业培养方案、数据结构课程教学大纲制订本课程实验教学大纲。
二、实验安排

三、实验目的、内容与要求
实验一 线性表的应用—Josephus环算法的设计
(一)实验目的
本实验的目的是进一步理解线性表的逻辑结构和存储结构,进一步提高应用理论知识解决实际问题的能力。
(二)实验内容
1.Josephus环问题
设编号为1、2、…n的n个人围坐一圈,约定编号为k(1≤k≤n)的人从1开始报数,数到m的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。
2.百货公司仓库中有一批电视机,按其价格从低到高的次序构成了一个单链表并存于计算机中,链表的每个结点指出同样价格的若干台。现在又新到m台价格为h元的电视机入库。试编写出仓库电视机链表增加电视机的算法。
3.设有一个循环双链表,假设所有结点的data域值不相同,编写一个算法将data域值为x的结点与其右边的一个结点进行交换。
(三)实验要求
实验前充分预习实验指导书内容及相关理论知识内容;实验中严格遵守实验室规范和制度,认真完成实验内容并做好实验纪录;实验后必须按照要求独立完成实验报告。
实验二 二叉树的应用—二叉树遍历算法的设计
(一)实验目的
本实验的目的是通过理解二叉树的逻辑结构和存储结构,进一步提高应用理论知识解决实际问题的能力。
(二)实验内容
1.以二叉链表存储结构的方式创建如下图的二叉树creatree。
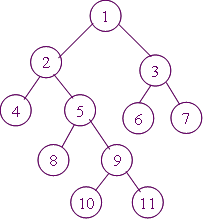
2.试以上题已建立的二叉链表为已知二叉树,编写按层次顺序遍历二叉树的算法。
3.写一个算法find,查找二叉树中的结点。
4.已知一棵二叉树的先序序列和中序序列,写一个建立该二叉树的二叉链表存储结构的算法。
5.判断一棵二叉树是否是完全二叉树。
6.设计一个算法,在以t为根结点的线索二叉树中,插入一个data域值为x的结点作为结点p的右孩子。
(三)实验要求
实验前充分预习实验指导书内容及相关理论知识内容;实验中严格遵守实验室规范和制度,认真完成实验内容并做好实验纪录;实验后必须按照要求独立完成实验报告。
实验三 图的应用—BFS和DFS算法的设计
(一)实验目的
本实验的目的是通过理解图的逻辑结构和存储结构,进一步提高应用理论知识解决实际问题的能力。
(二)实验内容
1.分别编写BFS、DFS算法。


2.判断无向图G是否连通,若连通则返回1,否则返回0。
3.判断无向图G是否是一棵树。若是树,返回1;否则返回0。
4.判断有向图中是否存在回路。
5.假设图G采用邻接表存储,求距离顶点v0的最短路径长度为k的所有顶点,要求尽可能节省时间。
(三)实验要求
实验前充分预习实验指导书内容及相关理论知识内容;实验中严格遵守实验室规范和制度,认真完成实验内容并做好实验纪录;实验后必须按照要求独立完成实验报告。
四、考核方式及成绩评定
实验的考核方式:根据课上实验能力、原型系统效果验收与实验报告的完成情况确定最终的实验成绩,实验成绩占课程总成绩的10%。
五、教材及主要参考资料
1.教材
[1] 数据结构(C语言版). 严蔚敏,吴伟民主编. 北京:清华大学出版社,2002
[2] 数据结构实验指导书. 张丽霞,吕岩编. 自编,2005
2.教学参考书
[1] 数据结构.刘振鹏主编. 北京:中国铁道出版社,2003
[2] 数据结构题集(C语言版).严蔚敏,吴伟民主编.北京:清华大学出版社,1999
六、其它说明
实验报告格式参照信息工程学院实验报告规范要求。
实验一 线性表的应用—Josephus环算法的设计
一、目的
本实验的目的是进一步理解线性表的逻辑结构和存储结构,进一步提高使用理论知识指导解决实际问题的能力。
二、题目
线性表的应用—Josephus环算法的设计
三、实验类型
设计性。本实验设计了一个循环链表,并涉及到了对链表的一些基本操作:建立、删除等
基本操作。
四、要求及提示
说明:以下3个题中,题1是必做题,题2、3可任意选作。
1、Josephus环问题
设编号为1、2、…n的n个人围坐一圈,约定编号为k(1≤k≤n)的人从1开始报数,数到m的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。
实验提示:
(1)、由于当某个人退出圆圈后,报数的工作要从下一个人开始继续,剩下的人仍然是围成一个圆圈的,可以使用循环表,由于退出圆圈的工作对应着表中结点的删除操作,对于这种删除操作频繁的情况,选用效率较高的链表结构,为了程序指针每一次都指向一个具体的代表一个人的结点而不需要判断,链表不带头结点。所以,对于所有人围成的圆圈所对应的数据结构采用一个不带头结点的循环链表来描述。设头指针为p,并根据具体情况移动。
可以采用数据类型定义:
typedef struct node
{
int number; //每个人的编号
struct node *next; //指向表示下一个人的结点的指针
}lnode
(2)、为了记录退出的人的先后顺序,采用一个顺序表进行存储。程序结束后再输出依次退出的人的编号顺序。由于只记录各个结点的number值就可以,所以定义一个整型一维数组。如:int quit[n];n为一个根据实际问题定义的一个足够大的整数。
2、百货公司仓库中有一批电视机,按其价格从低到高的次序构成了一个单链表并存与计算机中,链表的每个结点指出同样价格的若干台。现在又新到m台价格为h元的电视机入库。试编写出仓库电视机链表增加电视机的算法。
3、设有一个循环双链表,假设所有结点的data域值不相同,编写一个算法将data域值为x的结点与其右边的一个结点进行交换。
五、实验报告
1、写出每个算法的思想。
2、画出算法流程图。
3、调试程序出现的问题及解决的方法。
4、打印实验报告及程序清单。
5、报告给出测试的结果并写出设计体会。
六、范例参考
1、问题描述
这是单链表的一个综合练习,包括以下各项内容的函数,可共享被调用,可以通过菜单选择方式运行单链表的各种操作。
1) 建立单链表(1):将用户输入的数据按头插入法建立一个不带头结点的单链表。输入结点数据时以输入一串字符的方式实现,$字符为结束输入字符
2) 建立单链表(2):将用户输入的数据按头插入法建立一个带头结点的单链表。输入数据方式同上。
3) 建立单链表(3):将用户输入的数据按尾插入法建立一个不带头结点的单链表。输入数据方式同上。
4) 建立单链表(4):将用户输入的数据按尾插入法建立一个带头结点的单链表。输入数据方式同上。
5) 逆置单链表:按头插入法建立一个不带头结点的单链表,用最少的辅助空间实现单链表元素的逆置。
6) 有序链表插入元素:建立一个带头结点的单链表,表中元素从小到大有序排列。输入一个元素并将其插入到单链表中正确的位置上。
7) 有序链表删除重复元素:建立一个带头结点的单链表,表中元素递增有序。删除表中值相同的多余元素(即重复元素只保留一个)
8) 无序链表删除重复元素建立一个带头结点的单链表,元素按输入的次序排列。删除表中值相同的多余元素(即重复元素只保留一个)。
9) 两链表合并:建立两个带头结点的单链表a1和a2,元素均递增有序。将两个单链表归并成新的单链表c,c 中元素也递增有序,相同值的元素均保留在c中。
10) 两链表并集:按用户输入的数据建立两个集合a1和a2,同一集合中无重复元素,以带头结点的单链表形式存放。对两集合进行并集运算,结果放在a1 表中。
2、程序清单
#include "datastru.h"
#include <stdio.h>
#include <malloc.h>
#define DATATYPE2 char
typedef struct node
{DATATYPE2 data;
struct node *next;
}LINKLIST;
int locate(LINKLIST *a,char x)
/*检查元素x是否在a表中*/
{LINKLIST *la;
la = a->next;
while(la !=NULL)
if(la->data == x) return 1;
else la = la->next;
return 0;
}
insert(LINKLIST *a,char x)
/*将x元素加入a表中*/
{LINKLIST *p;
p = (LINKLIST *) malloc(sizeof(LINKLIST));
p->data = x;
p->next = a->next;
a->next = p;
}
void unionn(LINKLIST *a1, LINKLIST *b1){
/*两有序表交集*/
LINKLIST *lb;
lb = b1->next;
while(lb != NULL)
{ if (!locate(a1,lb->data)) /*如果b1表中的一个元素不在a1表中*/
insert(a1,lb->data); /*则将b1表中的该元素加入a1表中*/
lb = lb->next;}
}
void unite(LINKLIST *a, LINKLIST *b, LINKLIST *c){
/*a, b为两有序链表,合并到c表,并保持有序*/
LINKLIST *la, *lb, *lc, *p;
la = a->next; lb = b->next; lc = c;
while(la != NULL && lb != NULL)
{ if (la->data <= lb->data)
{ p = (LINKLIST *) malloc(sizeof(LINKLIST));
p->data = la->data; p->next = NULL;
lc->next = p; lc = lc->next; la = la->next;
}
else
{ p = (LINKLIST *) malloc(sizeof(LINKLIST));
p->data = lb->data; p->next = NULL;
lc->next = p; lc = lc->next; lb = lb->next;
}
}
while(la != NULL)
{ p = (LINKLIST *) malloc(sizeof(LINKLIST));
p->data = la->data; p->next = NULL;
lc->next = p; lc = lc->next; la = la->next;
}
while(lb != NULL)
{ p = (LINKLIST *) malloc(sizeof(LINKLIST));
p->data = lb->data; p->next = NULL;
lc->next = p; lc = lc->next; lb = lb->next;
}
}
void delete1(LINKLIST *a){
/*无序链表中删除重复元素,重复元素保留一个*/
LINKLIST *la, *p, *q;
la = a->next;
while(la != NULL)
{ q = la; p = la->next;
while(p != NULL)
{if (p->data == la->data)
{ p = p->next; q->next = p;}
else { q = p; p = p->next;}
}
la = la->next;
}
}
void delete(LINKLIST *a){
/*有序链表中删除重复元素,重复元素保留一个*/
LINKLIST *la;
la = a->next;
while(la != NULL && la->next != NULL)
if (la->data == la->next->data)
la->next = la->next->next;
else la = la->next;
}
inser_order(DATATYPE2 x, LINKLIST *head){
/*有序表中插入元素x,并保持表有序*/
LINKLIST *pr, *pn, *pp;
pr = head; pn = head->next;
while(pn != NULL && pn->data < x)
{pr = pn;
pn = pn->next;}
pp = (LINKLIST *)malloc(sizeof(LINKLIST));
pp->data = x;
pp->next = pr->next;
pr->next = pp;
}
LINKLIST *invertlink(LINKLIST *head){
/*单链表元素逆置*/
LINKLIST *p, *q, *r;
q = NULL; p = head;
while(p != NULL)
{r = q; q = p ;
p = p->next;
q->next = r;}
return q;
}
int count_nohead(LINKLIST *head){
/*不带头结点的单链表:输出单链表元素值并计数*/
int i = 0;
LINKLIST *p;
p = head;
printf("输出单链表元素值 : ");
while(p != NULL)
{printf(" %c",p->data);
i++;
p = p->next;}
printf("\n");
return i;
}
int count_head(LINKLIST *head){
/*带头结点的单链表:输出单链表元素值并计数*/
int i = 0;
LINKLIST *p;
p = head->next;
printf("输出单链表元素值 : ");
while(p != NULL)
{printf(" %c",p->data);
i++;
p = p->next;}
printf("\n");
return i;
}
LINKLIST *creatlink_nohead_head(LINKLIST *head) {
/*用头插入法建立不带头结点的单链表*/
LINKLIST *t;
char ch;
printf("单链表元素值为单个字符, 连续输入,$为结束字符 : ");
while((ch = getchar())!= '$')
{ t = (LINKLIST *) malloc(sizeof(LINKLIST));
t->data = ch;
t->next = head;
head = t;}
return(head);
}
LINKLIST *creatlink_head_head(LINKLIST *head) {
/*用头插入法建立带头结点的单链表*/
LINKLIST *t;
char ch;
t = (LINKLIST *)malloc(sizeof(LINKLIST));
head = t;
t->next = NULL;
printf("单链表元素值为单个字符, 连续输入,$为结束字符 : ");
while((ch = getchar())!= '$')
{t = (LINKLIST *) malloc(sizeof(LINKLIST));
t->data = ch;
t->next = head->next;
head->next = t;}
return(head);
}
LINKLIST *creatlink_nohead_rail(LINKLIST *head){
/*用尾插入法建立不带头结点的单链表*/
LINKLIST *last, *t;
char ch;
last = head;
printf("单链表元素值为单个字符, 连续输入,$为结束字符 : ");
while ((ch = getchar()) != '$')
{t = (LINKLIST *)malloc(sizeof(LINKLIST));
t->data = ch;
t->next = NULL;
if (head == NULL) {head = t; last = t;}
else { last->next = t; last = t;}
}
return (head);
}
LINKLIST *creatlink_head_rail(LINKLIST *head){
/*用尾插入法建立带头结点的单链表*/
LINKLIST *last, *t;
char ch;
t = (LINKLIST *)malloc(sizeof(LINKLIST));
head = t; last = t;
t->next = NULL;
printf("单链表元素值为单个字符, 连续输入,$为结束字符 : ");
while ((ch = getchar()) != '$')
{t = (LINKLIST *)malloc(sizeof(LINKLIST));
t->data = ch;
t->next = NULL;
last->next = t;
last = t;}
return (head);
}
LINKLIST *creatlink_order_head(LINKLIST *head)
/*建立带头结点的有序单链表*/
{ LINKLIST *t, *p, *q;
char ch;
t = (LINKLIST *)malloc(sizeof(LINKLIST));
head = t; t->next = NULL;
printf("单链表元素值为单个字符, 连续输入,$为结束字符 : ");
while ((ch = getchar()) != '$')
{t = (LINKLIST *)malloc(sizeof(LINKLIST));
t->data = ch;
q = head; p = head->next;
while( p != NULL && p->data <= ch) {
q = p; p = p->next;}
q->next = t; t->next = p;
}
return(head);
}
main()
{ LINKLIST *head, *a1, *a2, *c;
int num = 0,loop,j;
char ch;
loop = 1;
while (loop) {
printf("\n\n");
printf(" 1 -- 建立单链表(头插入,不带头结点)\n");
printf(" 2 -- 建立单链表(头插入,带头结点)\n");
printf(" 3 -- 建立单链表(尾插入,不带头结点)\n");
printf(" 4 -- 建立单链表(尾插入,带头结点)\n");
printf(" 5 -- 逆置单链表\n");
printf(" 6 -- 有序链表插入\n");
printf(" 7 -- 有序链表删除重复元素\n");
printf(" 8 -- 无序链表删除重复元素\n");
printf(" 9 -- 两链表合并并排序\n");
printf(" 10 -- 两链表并集\n\n");
printf(" 请选择项号 : ");
scanf("%d",&j);
fflush(stdin);
printf("\n\n");
if(j >= 1 && j <= 10)
switch(j) {
case 1: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_nohead_head(head);
fflush(stdin);
num = count_nohead(head);
printf("单链表元素个数 = %d\n", num);
break;
case 2: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_head_head(head);
fflush(stdin);
num = count_head(head);
printf("单链表元素个数 = %d\n", num);
break;
case 3: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_nohead_rail(head);
fflush(stdin);
num = count_nohead(head);
printf("单链表元素个数 = %d\n", num);
break;
case 4: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_head_rail(head);
fflush(stdin);
num = count_head(head);
printf("单链表元素个数 = %d\n", num);
break;
case 5: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_nohead_head(head);
fflush(stdin);
num = count_nohead(head);
printf("单链表元素个数 = %d\n", num);
printf("\n 逆置单链表\n\n");
head = invertlink(head);
num = count_nohead(head);
break;
case 6: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_order_head(head);
fflush(stdin);
num = count_head(head);
printf("单链表元素个数 = %d\n", num);
printf("\n输入插入元素值 : ");
ch = getchar();
inser_order(ch, head);
printf("\n 元素插入后\n\n");
num = count_head(head);
printf("插入后单链表元素个数 = %d\n", num);
break;
case 7: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_order_head(head);
fflush(stdin);
num = count_head(head);
printf("\n 删除重复元素后\n\n");
delete(head);
num = count_head(head);
break;
case 8: printf("\n 建立单链表\n\n");
head = NULL;
head = creatlink_head_rail(head);
fflush(stdin);
num = count_head(head);
printf("\n 删除重复元素后\n\n");
delete1(head);
num = count_head(head);
break;
case 9: printf("\n 建立单链表a1\n\n");
a1 = NULL;
a1 = creatlink_order_head(a1);
fflush(stdin);
num = count_head(a1);
printf("单链表a1元素个数 = %d\n", num);
printf("\n 建立单链表a2\n\n");
a2 = NULL;
a2 = creatlink_order_head(a2);
fflush(stdin);
num = count_head(a2);
printf("单链表a2元素个数 = %d\n", num);
c = NULL;
c = (LINKLIST *)malloc(sizeof(LINKLIST));
c->next = NULL;
unite(a1, a2, c);
num = count_head(c);
printf("合并到单链表c中,元素个数 = %d\n", num);
break;
case 10:printf("\n 建立单链表a1 \n\n");
a1 = NULL;
a1 = creatlink_head_rail(a1);
fflush(stdin);
num = count_head(a1);
printf("\n 建立单链表a2 \n\n");
a2 = NULL;
a2 = creatlink_head_rail(a2);
fflush(stdin);
num = count_head(a2);
printf("\n\n 两链表交集运算,结果保留在a1中\n\n");
unionn(a1,a2);
num = count_head(a1);
}
printf("结束此练习吗? (0 -- 结束 1 -- 继续) : ");
scanf("%d",&loop);
printf("\n");
}
}
实验二 二叉树的应用—二叉树遍历算法的设计
一、目的
本实验的目的是通过理解二叉树的逻辑结构和存储结构,进一步提高使用理论知识指导解决实际问题的能力。
二、题目
二叉树的应用—二叉树遍历算法的设计
三、实验类型
验证性。本实验验证了二叉树遍历算法的递归算法和非递归算法。
四、要求及提示
说明:以下6个题中,题1和题2是必做题,题3-6可任意选作1或2题
1、以二叉链表的存储结构的方式创建如下图的二叉树creatree
可以采用数据类型定义:
typedef struct node
{ datatype data; //每个结点的数据域
struct node *lchild, *rchild;
// 结点的左孩子指针域lchild,右孩子指针域rchild
}JD;
2.试以上题已建立的二叉链表为已知二叉树,编写按层次顺序遍历二叉树的算法
【相关知识】二叉树的遍历算法
【例题分析】使用一个队列qu[],先将二叉树的根结点入队。当队列不空时循环,从队列中取出一个结点(即出队),访问之,将其不空的左孩子和右孩子入队。
3.写一个算法find,查找二叉树中的结点
提示:采用某种遍历方式查找值为x(x为从键盘输入的一个值),如果找到则返回值1;否则返回值0
4.已知一棵二叉树的先序序列和中序序列,写一个建立该二叉树的二叉链表存储结构的算法 (注:本题可以只给出算法)
提示:若一棵二叉树先序和中序遍历序列分别为:先序序列为 ABDEHCFGI,中序序列为DBEHAFCIG,由先序序列可知,A是根结点,由此可将中序序列分成两部分,左子树结点DBEH和右子树结点FCIG。对于左子树中序DBEH在先序中为BDEH,说明左子树的根结点是B,同样,左子树的中序又可分为D和EH,则B的左子树只有D一个结点,对于EH,在先序中为EH,则B的右子树的根结点为E,H为E的右子树,一次类推,可画出整个二叉树。
5.判断一棵二叉树是否是完全二叉树(注:本题可以只给出算法)
【相关知识】完全二叉树的性质
【例题分析】假设二叉树采用顺序存储结构(若为二叉链表结构,可先转换为顺序存储结构),我们知道。具有n个结点的完全二叉树采用顺序存储结构时,所有结点都放在从0下标开始的相邻位置上,即填满0~n-1的位置
【解题思路】
方法(一)先采用分层遍历的方法把二叉链表转换为顺序结构,再使用上面的例题分析思想可利用队列来实现
方法(二)根据完全二叉树的性质,按层次排列二叉树的结点时,结点是连续存在的。设一个辅助队列qu[] 存放二叉树结点的指针,另设标志变量tag,表示按层次逐层从左到右扫描结点过程是否出现过空结点,其初值为0(表示尚未有空)。算法思想:
(1)若存在根结点,其指针入队
(2)队列不空时循环
1. 若队列指针p为NULL,置tag=1;
2. 若p!=NULL,此时tag=1,判断为非完全二叉树,算法结束;
3. 若tag=0,将其左右孩子的指针入队
(3)队列为空时,判断为完全二叉树,算法结束
6.设计一个算法,在以t为根结点的线索二叉树中,插入一个data域值为x的结点作为结点p的右孩子。(注:本题可以只给出算法)
【相关知识】线索二叉树的结构和性质
【例题分析】设指针变量p指向线索二叉树中的某结点,指针变量r指向要插入的新结点。
若p的右子树为空,则插入过程很简单,即结点p原来的后继结点变为结点r的后继结点,结点p为r的前驱,r成为p的右孩子。结点r的插入对p原来的后继结点没有任何影响。
若p的右子树不为空,则结点r 插入后,结点p原来的右子树变为结点r的右子树,p为r的前驱,r成为p的右孩子,根据中序线索二叉树的定义,这时还需修改结点p原来右子树中最左结点的左指针域,使它由原来的指向结点p改为指向结点r。
五、实验报告
1、写出每个算法的思想。
2、画出算法流程图。
3、调试程序出现的问题及解决的方法。
4、打印实验报告及程序清单。
5、报告给出测试的结果并写出设计体会。
六、范例参考
1、 问题描述(两种方法建立二叉树)
1) 二叉树的建立:设有一棵二叉树如图(a),将二叉树模拟为完全二叉树从根开始对结点进行编号,编号从1 开始,结果如图(b)所示。在运行过程中要求输入结点对应的编号和值时,请按图(c)中的数据输入,最后以编号 I=0;结点值x=’$’结束。
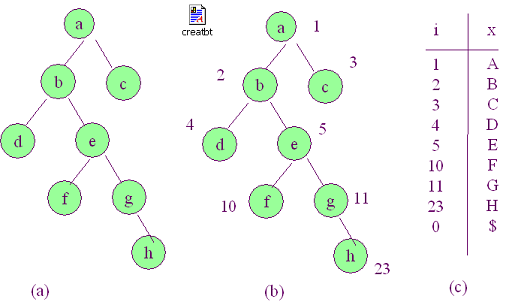
2) 二叉树中序遍历:对建立的二叉树进行中序遍历,并输出遍历结果.中序遍历算法可以用递归算法实现,也可以用非递归算法实现.
2、程序清单
#include <stdio.h>
#include "datastru.h"
#include <malloc.h>
typedef struct node1
{char data;
struct node1 *lchild,*rchild;
}BTCHINALR;
BTCHINALR * createbt( )
{ BTCHINALR *q;
struct node1 *s[30];
int j,i,x;
printf("建立二叉树,输入结点对应的编号和值,编号和值之间用逗号隔开\n\n");
printf("i,x = ");
scanf("%d,%c",&i,&x);
while(i != 0 && x != '$')
{q = (BTCHINALR*)malloc(sizeof(BTCHINALR)); /*建立一个新结点q*/
q->data = x; q->lchild = NULL; q->rchild = NULL;
s[i] = q; /*q新结点地址存入s指针数组中*/
if(i != 1) /*i = 1,对应的结点是根结点*/
{j = i / 2; /*求双亲结点的编号j*/
if(i % 2 == 0) s[j]->lchild = q; /*q结点编号为偶数则挂在双亲结点j的左边*/
else s[j]->rchild = q;} /*q结点编号为奇数则挂在双亲结点j的右边*/
printf("i,x = ");
scanf("%d,%c",&i,&x);}
return s[1]; /*返回根结点地址*/
}
void inorder(BTCHINALR *bt)
/*中序遍历二叉树(递归算法)*/
{if(bt != NULL)
{ inorder(bt->lchild);
printf("%c ",bt->data);
inorder(bt->rchild); }
}
void inorder_notrecursive(BTCHINALR *bt)
/*中序遍历二叉树(非递归算法)*/
{BTCHINALR *q, *s[20];
int top = 0;
int bool = 1;
q = bt;
do {while(q != NULL)
{ top ++; s[top] = q; q = q->lchild; }
if(top == 0) bool = 0;
else { q = s[top];
top --;
printf("%c ",q->data);
q = q->rchild; }
}while(bool);
}
main( )
{ BTCHINALR *bt;
char ch;
int i;
bt = createbt(); i = 1;
while(i) {
printf("\n中序遍历二叉树(递归按y键,非递归按n键): ");
fflush(stdin);
scanf("%c",&ch);
if(ch == 'y') inorder(bt); else inorder_notrecursive(bt);
printf("\n");
printf("\n继续操作吗?(继续按1键,结束按0键): ");
fflush(stdin);
scanf("%d",&i);
}
}
方法二:按先序遍历序列建立二叉树的二叉链表,已知先序序列为:
A B C φ φ D E φ G φ φ F φ φ φ
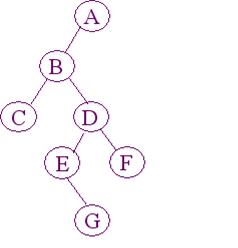
#define datatype char
typedef struct node
{datatype data;
struct node *lchild,*rchild;
}JD;
JD *crt_bt_pre(JD *bt)
{ char ch;
printf("ch=");
scanf("%c",&ch);
if(ch==' ') bt=NULL;
else
{ bt=(JD *)malloc(sizeof(JD));
bt->data=ch;
bt->lchild=crt_bt_pre(bt->lchild);
bt->rchild=crt_bt_pre(bt->rchild);
}
return(bt);
}
实验三 图的应用—BFS和DFS算法的设计
一、目的
本实验的目的是通过理解图的逻辑结构和存储结构,进一步提高使用理论知识指导解决实际问题的能力。
二、题目
图的应用—BFS和DFS算法的设计
三、实验类型
验证性。本实验验证了BFS(深度优先搜索)和DFS(广度优先搜索)算法。
四、要求及提示
说明:以下6个题中,题1是必做题,题2-5可任意选作1或2题
1、分别编写BFS、DFS算法
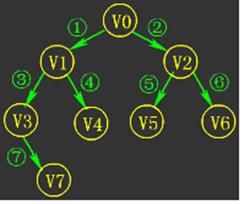
A.实验目的:掌握图的广度和深度优先搜索遍历算法
B.提示:最好使用邻接表法建立无向图和有向图的存储结构,然后实现图的遍历
可以采用数据类型定义:
typedef struct node
{ int adjvex; //邻接点域,存放与Vi邻接的结点在表头数组中的位置
struct node *next; //链域,指示下一条边或弧
}JD;
表头接点:
typedef struct tnode
{ int vexdata; //存放顶点信息
struct node *firstarc; //指示第一个邻接点
}TD;
C.程序实现
2、 判断无向图G是否连通,若连通则返回1,否则返回0
提示:采用遍历方式判断无向图是否连通。先给visited[]数组置初值0,然后从0开始遍历该图,之后若所有顶点i的visited[i]均为1,则该图是连通的,否则不连通。
(注:本题可以只给出算法)
3、判断无向图G是否是一棵数。若是树,返回1;否则返回0
提示:一个无向图G是一棵树的条件是:G必须是无回路的连通图或者是有n-1条边的连通图
(注:本题可以只给出算法)
4、判断有向图中是否存在回路
提示:若一个有向图拓扑排序不成功,则一定存在回路;反之,若拓扑排序成功,则一定不存在回路 (注:本题可以只给出算法)
5、假设图G采用邻接表存储,求距离顶点v0的最短路径长度为k的所有顶点,要求尽可能节省时间
提示:采用宽度优先搜索方法,找出第k层的所有顶点即为所求(宽度优先搜索保证找到的路径是最短路径)。其中,qu[]为队列,qu[][0] 存放顶点编号,qu[][1]存放当前顶点距离顶点v0 的最短路径。
(注:本题可以只给出算法)
五、实验报告
1、写出每个算法的思想。
2、画出算法流程图。
3、调试程序出现的问题及解决的方法。
4、打印实验报告及程序清单。
5、报告给出测试的结果并写出设计体会。
六、范例参考
1、问题描述
1) 建立连通图邻接链表结构:建立过程依赖于图中顶点和边的编号。顶点和边的编号可以预先规定,编法不同,则数据输入的过程和输出的结果也会不同,但广度优先遍历算法的结果都是正确的。
2) 实现广度优先遍历:在以邻接连表为存储结构的无向图上,实现无向图广度优先遍历算法。
3) 实现深度优先遍历:在以邻接连表为存储结构的无向图上,实现无向图深度优先遍历算法。
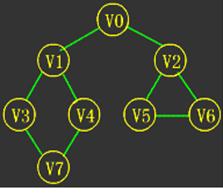
连通图如图所示:

顶点值设定为:
v1=100,v2=200,v3=300,v4=400,v5=500,v6=600,v7=700,v8=800
2、程序清单
广度优先遍历程序清单:
#include "datastru.h"
#include <stdio.h>
#include <malloc.h>
#define VEXTYPE int
#define MAXLEN 40
typedef struct node3 /*表结点结构*/
{ int adjvex; /*存放与表头结点相邻接的顶点在数组中的序号*/
struct node3 *next; /*指向与表头结点相邻接的下一个顶点的表结点*/
}EDGENODE;
typedef struct
{ VEXTYPE vertex; /*存放图中顶点的信息*/
EDGENODE *link; /*指针指向对应的单链表中的表结点*/
}VEXNODE;
typedef struct
{ VEXNODE adjlist[MAXLEN]; /*邻接链表表头向量*/
int vexnum,arcnum; /*顶点数和边数*/
int kind; /*图的类型*/
}ADJGRAPH;
typedef struct qnode
{ int data;
struct qnode *next;
}LINKQLIST;
typedef struct
{ LINKQLIST front;
LINKQLIST rear;
}LINKQUEUE;
ADJGRAPH creat_adjgraph(){
EDGENODE *p;
int i, s, d;
ADJGRAPH adjg;
adjg.kind = 2;
printf("\n\n输入顶点数和边数(用逗号隔开) : ");
scanf("%d,%d", &s, &d);fflush(stdin);
adjg.vexnum = s; /*存放顶点数在adjg.vexnum中 */
adjg.arcnum = d; /*存放边点数在adjg.arcnum中*/
printf("\n\n");
for(i = 0; i < adjg.vexnum; i++)
{printf("输入顶点 %d 的值 : ", i + 1);
scanf("%d", &adjg.adjlist[i].vertex); /*输入顶点的值*/
fflush(stdin);
adjg.adjlist[i].link = NULL;}
printf("\n\n");
for(i = 0; i < adjg.arcnum; i++)
{printf("输入第 %d 条边的起始顶点和终止顶点(用逗号隔开): ", i + 1);
scanf("%d,%d", &s, &d); /*输入边的起始顶点和终止顶点*/
fflush(stdin);
while(s < 1 || s > adjg.vexnum || d < 1 || d > adjg.vexnum)
{ printf("输入错,重新输入: ");
scanf("%d,%d", &s, &d); }
s --;
d --;
p = malloc(sizeof(EDGENODE)); /*建立一个和边相关的结点*/
p->adjvex = d;
p->next = adjg.adjlist[s].link; /*挂到对应的单链表上*/
adjg.adjlist[s].link = p;
p = malloc(sizeof(EDGENODE)); /*建立另一个和边相关的结点*/
p->adjvex = s;
p->next = adjg.adjlist[d].link; /*挂到对应的单链表上*/
adjg.adjlist[d].link = p;}
return adjg;
}
void initlinkqueue(LINKQUEUE *q)
{/*初始化广度遍历中用到的链队列*/
q->front = malloc(sizeof(LINKQLIST));
(q->front)->next = NULL;
q->rear = q->front;
}
int emptylinkqueue(LINKQUEUE *q)
{/*判队列是否为空?*/
int v;
if(q->front == q->rear)
v = 1;
else
v = 0;
return v;
}
void enlinkqueue(LINKQUEUE *q, DATATYPE1 x)
{/*元素x入队列*/
(q->rear)->next = malloc(sizeof(LINKQLIST));
q->rear = (q->rear)->next;
(q->rear)->data = x;
(q->rear)->next = NULL;
}
DATATYPE1 dellinkqueue(LINKQUEUE *q)
{/*删除队头元素*/
LINKQLIST *p;
DATATYPE1 v;
if(emptylinkqueue(q)) {printf("队列空.\n"); v = 0;}
else
{p = (q->front)->next;
(q->front)->next = p->next;
if(p->next == NULL) q->rear = q->front;
v = p->data;
free(p);}
return v;
}
void bfs(ADJGRAPH adjg, int vi)
{/*连通图的广度遍历算法:从vi顶点出发*/
int visited[MAXLEN];
int i, v;
EDGENODE *p;
LINKQUEUE que, *q;
q = &que;
initlinkqueue(q);
for(i = 0; i < adjg.vexnum; i++)
visited[i] = 0; /*visited数组初始化,均置0*/
visited[vi-1] = 1; /*从编号为vi的顶点出发,visited数组对应置1*/
printf(" %d", adjg.adjlist[vi-1].vertex); /*输出vi顶点*/
enlinkqueue(q,vi); /*vi顶点入队列*/
while(!emptylinkqueue(q)) /*队列不空,继续进行遍历*/
{v = dellinkqueue(q); /*取队头元素放入v变量中*/
v --;
p = adjg.adjlist[v].link;
while(p != NULL) /*对应单链表不空,进行广度遍历*/
{if(visited[p->adjvex] == 0)
{visited[p->adjvex] = 1;
printf(" %d", adjg.adjlist[p->adjvex].vertex);
enlinkqueue(q, (p->adjvex)+1);} /*遍历到的结点编号入队列*/
p = p->next;}
}
}
main()
{
ADJGRAPH ag;
int j;
printf("\n连通图的广度遍历\n");
ag = creat_adjgraph(); /*建立连通图的邻接链表结构*/
printf("\n\n输入深度遍历起始顶点(1 -- %d) : ",ag.vexnum);
scanf("%d",&j);
printf("\n\n广度遍历结果序列 : ");
bfs(ag,j); /*连通图的广度遍历算法*/
printf("\n\n");
}
深度优先遍历程序清单:
#include <stdio.h>
#include "datastru.h"
#include <malloc.h>
int visited[MAXLEN];
ADJGRAPH creat_adjgraph()
{
EDGENODE *p;
int i, s, d;
ADJGRAPH adjg;
adjg.kind = 2;
printf("\n\n输入顶点数和边数(用逗号隔开) : ");
scanf("%d,%d", &s, &d);fflush(stdin);
adjg.vexnum = s; /*存放顶点数在adjg.vexnum中 */
adjg.arcnum = d; /*存放边点数在adjg.arcnum中*/
printf("\n\n");
for(i = 0; i < adjg.vexnum; i++) /*输入顶点的值*/
{printf("输入顶点 %d 的值 : ", i + 1);
scanf("%d", &adjg.adjlist[i].vertex);
fflush(stdin);
adjg.adjlist[i].link = NULL;}
printf("\n");
for(i = 0; i < adjg.arcnum; i++)
{printf("输入第 %d 条边的起始顶点和终止顶点(用逗号隔开): ", i+1);
scanf("%d,%d", &s, &d); /*输入边的起始顶点和终止顶点*/
fflush(stdin);
while(s < 1 || s > adjg.vexnum || d < 1 || d > adjg.vexnum)
{ printf("输入错,重新输入: ");
scanf("%d,%d", &s, &d); }
s --;
d --;
p = malloc(sizeof(EDGENODE)); /*建立一个和边相关的结点*/
p->adjvex = d;
p->next = adjg.adjlist[s].link; /*挂到对应的单链表上*/
adjg.adjlist[s].link = p;
p = malloc(sizeof(EDGENODE)); /*建立另一个和边相关的结点*/
p->adjvex = s;
p->next = adjg.adjlist[d].link; /*挂到对应的单链表上*/
adjg.adjlist[d].link = p;}
return adjg;
}
void dfs(ADJGRAPH adjg, int v){
/*连通图的深度遍历算法:从v顶点出发*/
EDGENODE *p;
visited[v - 1] = 1; /*从编号为v的顶点出发,visited数组对应置1*/
v --;
printf(" %d", adjg.adjlist[v].vertex); /*输出v顶点*/
p = adjg.adjlist[v].link; /*取单链表的第一个结点*/
while(p != NULL) /*对应单链表不空,进行遍历*/
{ if(visited[p->adjvex] == 0) /*如果有未被访问过的结点*/
dfs(adjg, (p->adjvex)+1); /*递归调用深度遍历算法*/
p = p->next;} /*取单链表的下一个结点*/
}
main()
{
ADJGRAPH ag;
int i;
printf("\n连通图的深度遍历\n");
ag = creat_adjgraph(); /*建立连通图的邻接链表结构*/
for(i = 0; i < ag.vexnum; i++) /*visited数组初始化,均置0*/
visited[i] = 0;
printf("\n\n输入深度遍历起始顶点(1 -- %d) : ",ag.vexnum);
scanf("%d",&i);
printf("\n\n深度遍结果序列 : ");
dfs(ag,i); /*连通图的深度遍历算法*/
printf("\n\n");
}