五邑大学实验指导书
编译原理实验

开课系部:计算机学院
二0一三 年 九 月
编译原理课程实验指导书
课程名称:编译原理课程实验
课程编号:0800440
课程性质:非独立设课
课程属性:专业基础
课程类别:选修
实验学时 8 实验学分 0.5
开出时间: 三 年级 5~6 学期
适用专业:计算机学院各专业
设计性实验个数: 2
执笔人:白明 编写日期:2013.4.30
第1节 概 述
1、本课程实践的目的和任务
编译原理是一门实践性很强的课程,只有通过实践,才能真正掌握。
实际的编译程序是十分复杂的,有时由多达十几万条指令组成。为此,编译原理的实践教学,采用简化编译过程的办法,选择最关键的3个环节──词法分析、语法分析(包括语义处理、产生无优化的目标指令)、连接调试,进行编程和调试训练。每个环节作为一个实践课题。
2、实践方法
任何一个实用的高级语言,其语法都比较复杂,如选其作为源语言,很难实践全过程。故本实践将定义一个简化的语言──PASCAL语言的一个子集作为源语言,也可以自行定义一个简单的C语言子集,在3个题目中选择两个题目,也可以自行选择与编译技术相关的实验题目,设计调试出它的编译程序。前后贯穿这一条主线进行实践。每次都可利用课余时间编程,利用上机时间进行输入和调试。
建议使用C或C++或JAVA语言。
3、实践报告的规范和要求
每个课题完成后写出实践报告。实践报告包括程序设计时考虑的算法和方法;调试过程中出现的问题和解决的措施;提交电子版的程序清单和调试时所用的源程序。
4、简化的PASCAL语言子集的定义
〈PASCAL子集程序〉→〈变量说明〉〈分程序〉。
〈变量说明〉→〈空〉|VAR〈变量表〉:INTEGER;
〈变量表〉→〈变量〉|〈变量〉,〈变量表〉
〈变量〉→〈标识符〉
〈分程序〉→BEGIN〈语句组〉END
〈语句组〉→〈语句〉|〈语句〉;〈语句组〉
〈语句〉→〈赋值语句〉|〈条件语句〉|〈WHILE语句〉|〈分程序〉
〈赋值语句〉→〈变量〉:=〈算术表达式〉
〈条件语句〉→IF〈布尔表达式〉THEN〈语句〉ELSE〈语句〉
〈WHILE语句〉→WHILE〈布尔表达式〉DO〈语句〉
〈算术表达式〉→〈项〉|〈算术表达式〉+〈项〉|〈算术表达式〉-〈项〉
〈项〉→〈初等量〉|〈项〉*〈初等量〉|〈项〉/〈初等量〉
〈初等量〉→〈无符号数〉|〈变量〉|(〈算术表达式〉)
〈关系表达式〉→〈算术表达式〉〈关系运算符〉〈算术表达式〉
〈标识符〉→〈字母〉|〈标识符〉〈字母〉|〈标识符〉〈数字〉
〈无符号数〉→〈数字〉|〈无符号数〉〈数字〉
〈关系运算符〉→〈|〈= | =| 〉=| 〉|〈〉
〈字母〉→ A│B│C│D│E│F│G│H│I│J│K│L│M│N│O│P│Q│R│S│T│
│U│V│W│X│Y│Z
〈数字〉→ 1│2│3│4│5│6│7│8│9│0
第2节 词法分析
本节进行词法分析程序的编程与调试。
1、目的与要求
1)目的
通过设计调试词法分析程序,实现从源程序中分出各种单词的方法;加深对课堂教学的理解;提高词法分析方法的实践能力。
2)要求
⑴ 掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。
⑵ 掌握词法分析的实现方法。
⑶ 上机调试编出的词法分析程序。
⑶ 实验时间为4-6小时。
2、题目
用C或C++或JAVA语言编写前述PASCAL子集的词法分析程序。
1)主程序设计考虑,(参阅后面给出的程序框架)
主程序的说明部分为各种表格和变量安排空间。
数组k为关键字表,每个数组元素存放一个关键字。采用定长的方式,较短的关键字后面补空格。
P 数组存放分界符。为了简单起见,分界符、算术运算符和关系运算符都放在p表中(学生编程时,应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。
id 和ci 数组分别存放标识符和常数。
instring 数组为输入源程序的单词缓存。
outtoken 记录为输出内部表示缓存。
还有一些为造表填表设置的变量。
主程序开始后,先以人工方式输入关键字,造k表;再输入分界符等造 p 表。
主程序的工作部分设计成便于调试的循环结构。每个循环处理一个单词;接收键盘上送来的一个单词;调用词法分析过程;输出每个单词的内部码。
2)词法分析过程考虑
该过程取名为 lexical,它根据输入单词的第一个字符(有时还需读第二个字符),判断单词类,产生类号:以字符k表示关键字;i表示标识符;c 表示常数;p 表示分界符;s 表示运算符(学生编程时类号分别为1,2,3,4,5)。
对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组 id 中,将常数变为二进制形式存入数组中 ci 中,并记录其在表中的位置。
lexical 过程中嵌有两个小过程:一个名为 getchar,其功能为从 instring 中按顺序取出一个字符,并将其指针 pint 加 1 ;另一个名为 error,当出现错误时,调用这个过程,输出错误编号。
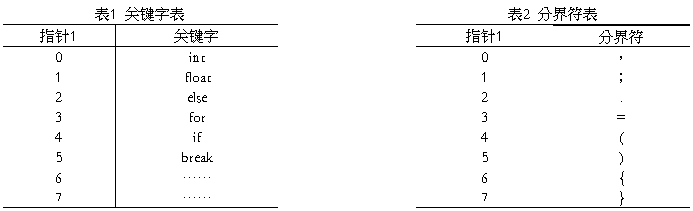
将词法分析程序设计成独(入口)立一遍扫描源程序的结构。流程图见图1所示。

图1 词法分析程序流程图
要求:⑴ 所有识别出的单词都用两个字节的等长表示,称为内部码。第一个字节为 t ,第二个字节为 i 。 t 为单词的种类。关键字的 t=1;分界符的 t=2;算术运算符的 t=3;关系运算符的 t=4;无符号数的 t=5;标识符的 t=6。i 为该单词在各自表中的指针或内部码值。表1 为关键字表;表2 为分界符表;表3 为算术运算符的 i 值;表4 为关系运算符的 i 值。

常数表和标识符表是在编译过程中建立起来的。其 i 值是根据它们在源程序中出现的顺序确定的。
⑵ 常数分析程序、关键字和标识符分析程序、其他单词分析程序请参阅范例自行设计。
⑶ 本实践题可通过扩充下面给出的程序框架完成。
3、程序框架
PROGRAM plexical(input,output);
LABEL l;
CONST
keylen=10;
identlen=10;
TYPE
tstring=ARRAY[1..identlen] OF char;
outreco=RECORD
ty: char;
point: integer;
END; {outreco}
VAR cip,ip,pint,i,j,l,m,errorx:integer;
charl:CHAR;
ci:ARRAY[1..10] OF integer;
k,id:ARRAY[1..keylen] OF tstring;
token:tstring;
outtoken:outreco;
instring:ARRAY[1..10]OF char;
p:ARRAY[1..16] OF ARRAY [1..2] OF char;
PROCEDURE lexical;
VAR l,m,num:integer;
b: boolean;
PROCEDURE getchar;
BEGIN
charl:=instring [pint] ;
pint:=pint+1
END; {getchar}
PROCEDURE error;
BEGIN
writtcln('error',errorx)
END;{error}
BEGIN
FOR 1:=1 TO inentlen DO token[1]:=' ';
getchar;
WHILE char1=' ' DO getchar;
IF char1 IN ['a'..'z']
THEN
BEGIN /*处理标识符*/
m:=1;
WHILE (char1 IN ['a'..'z']) OR (char1 IN ['0'..'9']) DO
BEGIN
IF m<=identlen
THEN
BEGIN
token[m]:=char1;
m:=m+1
END;
getchar
END;{while}
pint:=pint-1;
1:=1;
b:=false;
WHILE (1<=keylen) AND (NOT b) DO
BEGIN
b:=true;
i:=1;
WHILE (i<=identlen) AND b DO
IF k[1] [i]=token[i]
THEN i:=i+1
ELSE b:=false;
IF NOT b THEN l:=l+1
END
IF 1<=keylen
THEN
BEGIN
outtoken.ty:='k';
outtoken.point:=1
END
ELSE
BEGIN
l:=1;
b:=false;
WHILE (l<=ip) AND (NOT b ) DO
BEGIN
b:=true;
i:=1;
WHILE (i<=identlen) AND b DO
IF id[1][i]=token[i]
THEN i:=i+1
ELSE b:=false;
IF NOT b THEN l:=l+1;
END;
IF NOT b THEN l:=l+1;
IF 1>ip
THEN
BEGIN
ip:=ip+1;
FOR m:=1 TO identlen DO id[ip][m]:=token[m];
outtoken.ty:='i';
outtoken.point:=1
END
END
END
ELSE
IF char1 IN ['0'..'9']
THEN
BEGIN
处理常数
END{integer}
ELSE
IF char1 IN [',',';','.',':','(',')']
THEN
BEGIN
处理分界符
END
ELSE
IF char IN ['+','-','*','/','.','<','=','>']
THEN
BEGIN
处理运算符
END
ELSE BEGIN errorx : =2; error END
END; {lexica1}
BEGIN
writeln ('k-table, input!');
FOR 1:=1 TO keyicnDO
FOR m:=1 TO identlenDO
read (k[1] [m] );
readln ;
FOR l:=1 TO identlen DO
id [1] [m]:=' ';
writeln ('p-table, input!');
FOR 1:=1 TO 11 DO
FOR m:=1 TO 2 DO
read(p[1] [m]);
readln;
ip:=0;
cip:=1;
pint:=1;
l: writeln('source, input!');
FOR j:=1 TO identlen DO
Read (instring[j] );
lexical;
writeln (outtoken.ty);
writeln (outtoken. point);
FOR l:=1 TO identlen DO
write (token[ 1 ]);
writeln;
GOTO 1
END.
第3节 语法分析
1、目的与要求
㈠ 目的
通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
㈡ 要求
⑴ 选择最有代表性的语法分析方法,如算符优先法、递归子程序法和LR分析法
⑵ 选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。
⑶ 实验时间为4-6小时。
2、题目
分析对象的BNF定义如下:
〈算术表达式〉∷=〈项〉|〈算术表达式〉+〈项〉|〈算术表达式〉-〈项〉
〈项〉∷=〈因式〉|〈项〉*〈因式〉|〈项〉/〈因式〉
〈因式〉∷=〈变量〉│(〈算术表达式〉)
〈变量〉∷=〈字母〉
〈字母〉∷=A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z
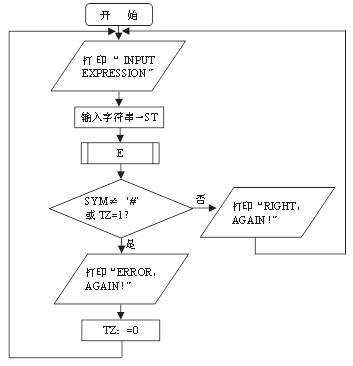
(a)
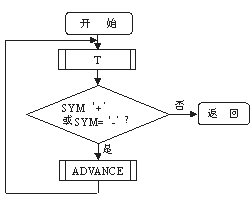
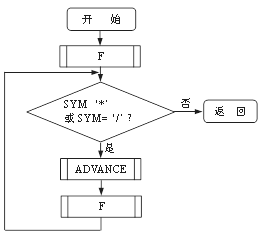
(b) (c)
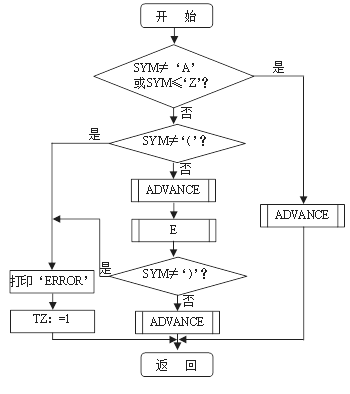
(d)
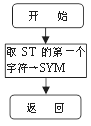

(e) (f)
图3 递归下降法分析表达式之框图
(a) ZC 过程;(b) E 过程;(c) T 过程;
(d) F 过程;(e) 函数过程 SYM ;(f) 过程 ADVANCE
3、算法 用递归下降法分析上述算术表达式的框图,如图2-7-5所示。这里,ZC过程为总控程序,主要完成:
⑴ 通知外界键入算术表达式;
⑵ 控制E过程分析算术表达式;
⑶ 根据分析结果之正误,分别通知外界不同的信息。
ZC过程被设计成可以分析无穷多个算术表达式。E、T和F三个过程分别对应〈算术表达式〉、〈项〉和〈因式〉三个产生式的处理。它们用到两个公共过程。一个是函数过程SYM,它负责从输入字符串ST中取出下一个字符,并存入SYM中等待分析。另一个过程ADVANCE负责剔除ST中的首字符。
4、小结
⑴ 实验前的准备
按实验目的和要求,用C或C++或JAVA语言编写一个语法分析程序,同时考虑相应的数据结构。
⑵ 调试:调试例子应包括符合语法规则的算术表达式,以及分析程序能够判别的若干错例。
⑶ 输出:对于所输入的算术表达式,不论对错,都应有明确的信息告诉外界。
⑷ 扩充:有余力的同学,可适当扩大分析对象。譬如:
① 算术表达式中变量名可以是一般标识符,还可含一般常数、数组元素、函数调用等等。
② 除算术表达式外,还可扩充分析布尔、字符、位等不同类型的各种表达式。③加强语法检查,尽量多和确切地指出各种错误。
⑸ 编写上机实验报告。
第4节 语义分析
1、目的与要求
㈠ 目的
通过上机实习,加深对语法制导翻译原理的理解,掌握将语法分析所识别的语法范畴变换为某种中间代码的语义翻译方法。
㈡ 要求
⑴ 选用目前世界上普遍采用的语义分析方法──语法制导翻译技术。
⑵ 语义分析对象重点考虑经过语法分析后已是正确的语法范畴,实验重点是语义子程序。
⑶ 中间代码选用比较常见的形式,例如四元式。
⑷ 实验时间为3-4小时。
㈢ 题目的选择
语法制导翻译是在语法分析的基础上增加语义操作来实现翻译的。原则上每个产生式对应一个语义子程序。在语法分析的过程中,当一个产生式获得匹配或进行归约时,相应的语义子程序便开始工作,生成中间代码,查填有关表格,检查并报告源程序中的错误,修改编译程序某些变量的值。
高级语言的语法结构类型很多,从实验的角度可分为以下六类:
⑴ 说明语句。如各种数据类型说明(整型、实型、布尔型、字符型、复型、双精度型、枚举、子界、数组、集合、文件、记录、指针等),各种数据空间特性说明(如公用语句,共名语句,等价语句等),初值语句。实验重点是内存空间的分配方法。
⑵ 顺序结构语句。典型代表是各类表达式(如算术表达式、布尔表达式、字符表达式、位表达)及相应的赋值语句。实验重点是算术表达式的翻译方法。
⑶ 控制结构语句。常见的有转移语句、条件语句和各种分叉语句。实验重点是拉链返填的方法。
⑷ 子程序结构。指子程序、函数、过程这类结构的定义和调用。实验重点是哑实结合的方法。
⑸ 循环结构。如计数循环、条件循环等。实验重点是循环化简的方法。
⑹ 格式语句。主要指输入输出语句的格式加工。实验重点是数据编辑的方法。根据教学要求可从以上六类中选择一至三类实验。
2、题目
(1) 题目在对简化的算术表达式进行语法分析的同时生成四元式。
(2) 算法根据题意,所求的四元式生成程序核心部分(指表达式、项和因式的处理)的算法,可用算法描述语言描述如下:
PROCEDURE E;
BEGIN
EIPLACE:=T;
WHILE SYM='+' OR '-' DO
BEGIN
ADVANCE;
E2PLACE:=T;
T1:=NEWTEMP;
GEN(±,E1PLACE,E2PLACE,T1);
E1PLACE:=T1
END;
RETURN(E1PLACE)
END.
PROCEDURE T;
BEGIN
T1PLACE:=F;
WHILE SYM='*' OR ' ' DO
BEGIN
ADVANCE:
T2PLACE:=F;
T1:=NEWTEMP;
GEN(*/,T1PLACE,T2PLACE, T1);
T1PLACE:=T1
END;
RETURN(T1PLACE)
END.
PROCEDURE F:
BEGIN
IF SYM=标识符
THEN
BEGIN
ADVANCE;
RETURN(ENTRY(i))
END
ELSE
IF SYM='('
THEN
BEGIN
ADVANCE;
PLACE:=E;
IF SYM=')'
THEN
BEGIN
ADVANCE;
RETURN(PLACE)
ELSE ERROR
END
ELSE ERROR
END.
这里:E──表达式;T──项;F──因式;ADVANCE──将输入串指针调整至指向下一个输入字符;NEWTEMP──分配一个新的工作单元;GEN──将一个四元式填入四元式表;ENTRY──查找名表,并获得名字所在位置值。
(3)具体要求
①完善并用程序实现2中的翻译算法;
②用算符优先分析法或LR分析法实现所要求的翻译;
③调试、运行翻译程序,观察中间代码的生成过程并写出实验报告。