编译原理实验报告
指导教师:
一. 实验目的
基本掌握计算机语言的词法分析程序的开发方法。以及掌握计算机语言的语 法分析程序设计与属性文法应用的实现方法。锻炼自己的编程能力和逻辑思维能 力,体会计算机编译器的奥妙之处
二. 实验内容
1.编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法 分析程序。
2.给定下列文法:
S→id=E;
S→if C then S
S→while C do S
C→E>E
C→E<=E
用递归子程序法设计并实现语法分析程序,按照生成顺序输出产生式
3.在第四章上机题的基础上,补充以下的语义处理功能,形成一个将源程序翻译成三地址代码序列的翻译程序:
将表达式、赋值语句翻译成三地址代码
将 If 条件语句、While 循环语句翻译成三地址代码
三. 实验要求
1. 编制正规式以及正规文法,画出状态图;
2. 根据状态图,设计词法分析函数int scan( ),完成以下功能:
1) 从键盘读入数据,分析出一个单词。
2) 返回单词种别(用整数表示),
3) 返回单词属性(不同的属性可以放在不同的全局变量中)。
3. 编写测试程序,反复调用函数scan( ),输出单词种别和属性。
4. 改写文法,构造语法分析程序,要求按照最左派生的顺序输出派生的产 生式序列;
5. 改写语法分析程序,构造三地址代码生成程序。
6. 处理的源程序存放在文件中,它可以包含多个语句;
四.系统设计
完成整个系统,实现本个实验的要求,需要两个比较大的模块:词法分析器 和语法分析器。
词法分析器的功能是将输入的程序串分解成一个一个独立的单词,并且记录 下每个单词的类型以及数值。这里词法分析器的实现有两种方法:调用一次词法 分析器,返回一个词的类型以及数值,以此类推;还有一种方法是条用一次词法 分析器将程序串的所有单词都分解出来并保存到一个地方(比如线形表)以便将 来使用。我采用的是前者,因为这样只需要对整个程序访问一遍
语法分析器的功能是将已经分解好的单词按照一定的规范(产生式)组合起 来,由此来确定输入程序的意思。我的设计是“语法分析器调用词法分析器”, 当语法分析其分析进行不下去的时候调用词法分析器获取一个单词,继续进行分 析。而语义功能是镶嵌在语法分析其当中的,当语法分析器分析出用什么产生式 的时候作相应的语义处理。
五.系统实现
词法分析器的实现
<一>词法的正规式描述
标识符:<字母>|(<字母>|<数字字符>)*(ε|_|.) (<字母>|<数字字符>)*
十 进 制 数 : (0|(1|2|3|4|5|6|7|8|9) (0|1|2|3|4|5|6|7|8|9)*)( ε |.)(0|1|2|3|4|5|6|7|8|9)
(0|1|2|3|4|5|6|7|8|9)*
八进制数:0(0|(1|2|3|4|5|6|7) (0|1|2|3|4|5|6|7)*) (ε|.)(0|1|2|3|4|5|6|7) (0|1|2|3|4|5|6|7)*
十六进制数:0x(0(|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f) (0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*) (ε|.)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f) (0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*
运算符和分隔符:+ - * / < > = ( ) ;
关键字:if then else while do
<二>、改变后的正规文法
<标识符>-> <字母><temp> <temp2><temp>
<十进制整数>-><数字字符><temp3><数字字符>
<八进制整数>-> 0 <temp4><temp3> <temp4>
<十六进制整数>-> 0x<temp5><temp3> <temp5>
<运算符和分隔符>->+| - |* |/ |>| < |= |( | ) |;
<关键字>->if| then| else |while |do
< 字 母
>->a|b|c|d|e|f|g|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q| R|S|T|U|V|W|X|Y|Z
<数字字符>->0|1|2|3|4|5|6|7|8|9
<temp>-> (<字母>|<数字字符>)<temp>|ε
<temp2>-> (ε|_|.)
<temp3>-> (ε|.)
<temp4>-> (0|1|2|3|4|5|6|7)<temp4>|ε
<temp5>-> (0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f) <temp5>|ε
将状态合起来,得:
(0)-><1~9>(1)|0(4)|<字母>(12)|<运算符和分隔符>(17) (1)-><0~9>(1)|. (2)
(2)-><0~9>(3) (3)-><0~9>(3)
(4)->.(2)|<1~7>(5)|0(13)|x(8)|X(8) (5)-><0~7>(5)|.(6)
(6)-><0~7>(7) (7)-><0~7>(7)
(8)-><1~9>(9)|<a~f>(9)|0(14) (9)-><0~9>(9)|<a~f>(9)|.(10) (10)-><0~9>(11)|<a~f>(11) (11)-><0~9>(11)|<a~f>(11)
(12)-><0~9>(12)|<a~z>(12)|<A~Z>(12)|.(15)|_(15) (13)->.(6)
(14)->.(10)
(15)-><0~9>(16)|<a~z>(16)|<A~Z>(16) (16)-><0~9>(16)|<a~z>(16)|<A~Z>(16)
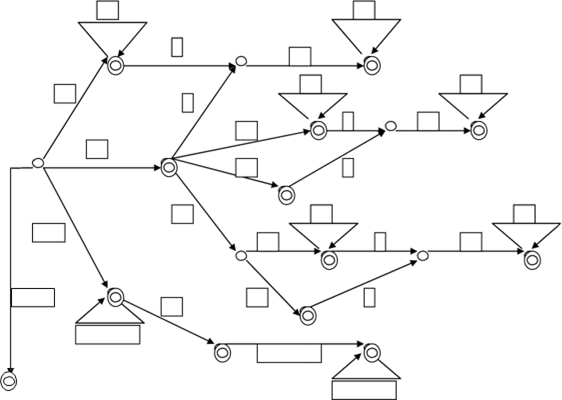
<三>、状态图:
0~9 0~9
1 . 2 3
0~9
1~9
.
0~7 0~7
5 6 7
0 0 4
.
1~7
0 .
13
0~7
x|X
字母
8 1~f
0~f
9
. 10
0~f
0~f
11
分隔符
12
.|_
0 14 .
字母或数字
15 16
字母或数字
17
字母或数字
 <四>、数据结构:
<四>、数据结构:
char* arrBao[5] = {"if","then","else","do","while"};//保留字表
typedef struct{
char type[TYPE_MAX];
char value[VALUE_MAX];
}CNode;//词法分析的节点,保留分析出的 token 的种类和值
<五>、算法(伪码):
bool MyScan(FILE* fp,CNode* &node){
char temp; //当前读取的字符
char s[100]; //保留字符串
int si = 0; //对于控制 s 的下标
int state = 0; //当前状态号
node = new CNode; //返回的节点
while(1){
读取一个字符到 temp;
if(temp == '#') { strcpy(node->type,"#"); strcpy(node->value,"_"); return false; //表示文件结束
}
switch(state){
case 0: //状态 0
if(temp 为 0) state=4; 添加当前字符; continue; if(temp 为 1 到 9) state=1; 添加当前字符; continue; if(temp 为字母) state=12; 添加当前字符; continue; if(temp 为分隔符) 保存相应的分隔符到 node; return true;
if(temp 为空格或回车或 tab) continue; //忽略多个空格和回车
和制表符
else 出错处理; return false;
case 1: //状态 1
if(temp 为数字) state=4; 添加当前字符; continue; if(temp 为小数点) state=2; 添加当前字符; continue; if(temp 为分隔符) 保存为 INT10; return true;
else 出错处理; return false;
case 2: //状态 2
if(temp 为数字) state=3; 添加当前字符; continue;
else 出错处理; return false;
case 3: //状态 3
if(temp 为数字) state=3; 添加当前字符; continue;
if(temp 为分隔符) 保存为 REAL10; return true;
else 出错处理; return false;
case 4: //状态 4
if(temp 为小数点) state=2; 添加当前字符; continue; if(temp 为 1~7) state=5; 添加当前字符; continue; if(temp 为 0) state=13; 添加当前字符; continue; if(temp 为 x 或 X) state=8; 添加当前字符; continue; if(temp 为分隔符) 保存为 INT10; return true;
else 出错处理; return false;
case 5: //状态 5
if(temp 为小数点) state=6; 添加当前字符; continue; if(temp 为 0~7) state=5; 添加当前字符; continue; if(temp 为分隔符) 保存为 INT8; return true;
else 出错处理; return false;
case 6: //状态 6
if(temp 为 0~7) state=7; 添加当前字符; continue;
else 出错处理; return false;
case 7: //状态 7
if(temp 为 0~7) state=7; 添加当前字符; continue;
if(temp 为分隔符) 保存为 INT8; return true;
else 出错处理; return false;
case 8: //状态 8
if(temp 为十六进制数) state=9; 添 加 当 前 字 符 ;
continue;
if(temp 为 0) state=14; 添 加 当 前 字 符 ;
continue;
else 出错处理; return false;
case 9: //状态 9
if(temp 为十六进制数) state=9; 添 加 当 前 字 符 ;
continue;
if(temp 为小数点) state=10; 添 加 当 前 字 符 ;
continue;
if(temp 为分隔符) 保存为 INT16; return true;
else 出错处理; return false;
case 10: //状态 10
if(temp 为十六进制数) state=11; 添 加 当 前 字 符 ;
continue;
else 出错处理; return false;
case 11: //状态 11
if(temp 为十六进制数) state=11; 添 加 当 前 字 符 ;
continue;
if(temp 为分隔符) 保存为 INT16; return true;
else 出错处理; return false;
case 12: //状态 12
if(temp 为数字或者字母) state=12; 添加当前字符 ;
continue;
if(temp 为_或者.) state=15; 添加当前字符 ;
continue;
if(temp 为分隔符)
if(为保留字) 保存为保留字; return true;
else 保存为 IDN; return true;
else 出错处理; return false;
case 13: //状态 13
if(temp 为.) state=6; 添加当前字符; continue; if(temp 为分隔符) 保存为 INT8; return true; else 出错处理; return false;
case 14: //状态 14
if(temp 为.) state=10; 添加当前字符; continue;
if(temp 为分隔符) 保存为 INT16; return true;
else 出错处理; return false;
case 15: //状态 15
if(temp 为数字或者字母) state=16; 添加当前字符 ;
continue;
if(temp 为分隔符)
if(为保留字) 保存为保留字; return true;
else 保存为 IDN; return true;
else 出错处理; return false;
case 16: //状态 16
if(temp 为数字或者字母) state=16; 添加当前字符 ;
continue;
if(temp 为分隔符)
if(为保留字) 保存为保留字; return true;
else 保存为 IDN; return true;
else 出错处理; return false;
}//switch
}//while
}
//主函数源程序
int main(){ FILE* fp; fp=fopen("code1.txt","r"); CNode* node; while(MyScan(fp,node)) {
if(node != NULL){ //分析成功
printf("%s\t%s\n",node->type,node->value);
}
else printf("\n");
}
fclose(fp); getchar(); return 0;
}
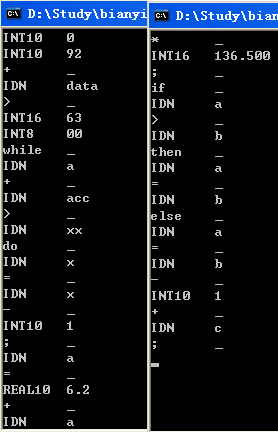
<六>、测试
测试用例:
0 92+data> 0x3f 00 while a+acc>xx do x=x-1;
a=6.2+a*0X88.80;
if a>b then a=b else a=b-1+c;# 测试用例说明:本测试用例测试了十进制数,八进制数,十六进制数,十进制0, 八进制0,十进制小数,八进制小数,十六进制小数,各个关键字以及分隔符, 对于空格,回车,制表符的测试,基本上全了。由于词法分析器中不支持续编译
(理由已在上面阐述),所以出错的例子无法在一个文件中给出,这里忽略。 分析的结果如下:
(三)使用递归子程序法做三地址码生成器
写在前面:递归子程序法的基本思路是:给每一个变量都编写一个函数,产 生式中如果存在变量则调用相应的程序。主函数中调用最开始的程序。这种方法 的思路非常清晰,容易理解,易于控制。
我的理解是如果采用此种方法文法可以不是 LL(1)的,原因如下:首先, 文法必须是没有左递归的,否则系统栈会溢出。但是最左公因子可以不用提取出 来:在一个程序中可以先统一做某些操作,然后根据不同的 token 决定接下来走 哪一个分支。而这些“统一的操作”就是最左公因子。所以为了实现简便,也更 容易理解,我没有提取最左公因子。另外,这种方法中可以存在形如 A->B(+B) * 的产生式,因为在用子程序的时候这种产生式可以用循环控制(循环条件为下一 个 token 为+),将两者结合起来,如下的产生式 E->T1((+|-)T2)*也是合法的, 但用预约分析表决不允许这样的产生式出现,这也是递归子程序这种方法的灵活 以及更贴近最原始的产生式的体现。
之后,在确定了程序应该进入那个分支后,需要在相应的分支之前加入语义 规则。以此来实现三地址码的生成。
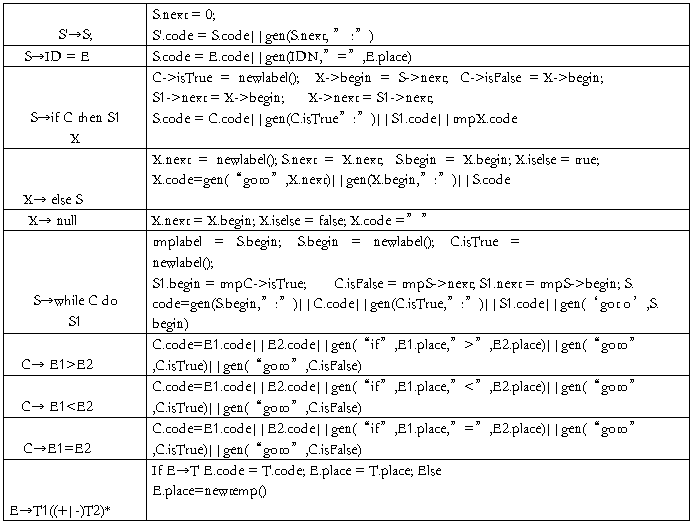
<一>、语义规则。
用递归子程序时,最左公因子可以不用提取,原因见上

<二>、三地址码生成的数据结构
typedef struct{ //S’
char code[CODE_MAX];
}str_S_;
typedef struct{ //S
char code[CODE_MAX];
int begin,next;
}str_S;
typedef struct{ //X
char code[CODE_MAX];
int begin,next;
bool iselse;
}str_X;
typedef struct{ //C
char code[CODE_MAX];
int isFalse,isTrue;
}str_C;
typedef struct{ //E
char code[CODE_MAX];
char place[VALUE_MAX];
}str_E;
typedef struct{ //T
char code[CODE_MAX];
char place[VALUE_MAX];
}str_T;
typedef struct{ //F
char code[CODE_MAX];
char place[VALUE_MAX];
}str_F;
<三>、语义分析的主要程序
bool MyFunction_S_(FILE* fp, str_S_* &tmpS_) { //S’ CNode* node;
str_S* tmpS = new str_S;
tmpS->next = 0; Lnum = 0;
if(MyFunction_S(fp,tmpS)) { //调用 S
if(strcmp(Node->type,";")==0) { //匹配;
if(Lnum != 0) //需要有跳转
sprintf(tmpS_->code,"%s\nL%d:",tmpS->code,tmpS->next);
else //不需要跳转
sprintf(tmpS_->code,"%s\n",tmpS->code);
return true;
}
}
return false;
}
bool MyFunction_S (FILE* fp, str_S* &tmpS){ //S CNode* node;
str_E* tmpE = new str_E; str_C* tmpC = new str_C; str_S* tmpS1= new str_S; str_X* tmpX = new str_X;
if(getNext(fp)) { //读取一个字符
if(strcmp(Node->type,"IDN")==0) { //如果为变量,走变量分支 char* tmpName = Node->value; //记录变量名 if(getNext(fp)) { //匹配变量
//产生式匹配

%s\n",tmpE->code,tmpName,tmpE->place);
return true;
}
}
}
}
then
else if (strcmp(Node->type,"if")==0){ //如果为 if,走 if 分支
if(getNext(fp)) { //匹配 if tmpC->isTrue = newlabel();
tmpX->begin = tmpS->next;//newlabel();
tmpC->isFalse = tmpX->begin; tmpS1->next = tmpX->begin; tmpX->next = tmpS1->next;
//产生式匹配
if(MyFunction_C(fp,tmpC)) //递归执行程序 C
if(strcmp(Node->type,"then")==0) { //检查当前字符是否为
if(MyFunction_S(fp,tmpS1)) //递归执行程序 S
if(MyFunction_X(fp,tmpX)) { //递归执行程序 X
//语义操作
if(tmpX->iselse)
tmpS->next = tmpX->next;
sprintf(tmpS->code,"%sL%d :\n%s%s",tmpC->code,tmpC->isTrue,tmpS1->code,tmp
X->code);
return true;
}
}
}
}
else if (strcmp(Node->type,"while")==0){ //如果为 while,走 while
分支
int tmplabel = tmpS->begin;
tmpS->begin = newlabel(); //分配标签
if(getNext(fp)) { //匹配 while
if(tmpS->begin > 1){ //如果不是第一个 while,不需要新 分配标签
Lnum--;
tmpS->begin = tmplabel;
}
tmpC->isTrue = newlabel();
tmpS1->begin = tmpC->isTrue;
tmpC->isFalse = tmpS->next; //假出口则指向后续代码
tmpS1->next = tmpS->begin; //后续代码需再输出一个标签
if(MyFunction_C(fp,tmpC)) //递归执行程序 C
if(strcmp(Node->type,"do")==0) //匹配 do if(MyFunction_S(fp,tmpS1)) { //递归执行程序 S
//语义操作
if(tmpS->begin == 1) //第一个 while
sprintf(tmpS->code,"L%d :\n%sL%d :\n%s goto
L%d\n ",tmpS->begin,tmpC->code,tmpC->isTrue,tmpS1->code,tmpS->begin);
else { //嵌套的 while
sprintf(tmpS->code,"%sL%d :\n%s goto
L%d\n",tmpC->code,tmpC->isTrue,tmpS1->code,tmpS->begin);
}
return true;
}
}
}
}
return false;
}
bool MyFunction_X (FILE* fp, str_X* &tmpX){ //X CNode* node;
str_S* tmpS = new str_S;
if(strcmp(Node->type,"else")==0) { //如果当前为 else,走 else 分支
tmpX->next = newlabel(); tmpS->next = tmpX->next; tmpS->begin = tmpX->begin;
if(MyFunction_S(fp,tmpS)) { //递归执行 S
L%d :\nL%d:\n%s\nL%d:",tmpX->next,tmpX->begin,tmpS->code,tmpX->next);
sprintf(tmpX->code,"goto L%d
\nL%d:\n%s\n",tmpX->next,tmpX->begin,tmpS->code);
tmpX->iselse = true;
return true;
}
}
else if (strcmp(Node->type,";")==0){ //如果当前为;走空分支
tmpX->next = tmpX->begin; sprintf(tmpX->code,""); tmpX->iselse = true;
return true;
}
return false;
}
bool MyFunction_C (FILE* fp, str_C* &tmpC){ //C CNode* node;
str_E* tmpE1 = new str_E;
str_E* tmpE2 = new str_E;
if(MyFunction_E(fp,tmpE1)) { //递归执行程序 E
if(strcmp(Node->type,">")==0){ //如果当前为>,走>分支
if(getNext(fp)) //匹配>
if(MyFunction_E(fp,tmpE2)) { //递归执行程序 E
sprintf(tmpC->code,"%s%s if %s > %s goto L%d\n goto
L%d\n",tmpE1->code,tmpE2->code,tmpE1->place,tmpE2->place,tmpC->isTrue,tmp
C->isFalse);
return true;
}
}
else if(strcmp(Node->type,"<")==0){ //如果当前为>,走>分支 if(getNext(fp)) //匹配< if(MyFunction_E(fp,tmpE2)) { //递归执行程序 E
sprintf(tmpC->code,"%s%s if %s < %s goto L%d\n goto
L%d\n",tmpE1->code,tmpE2->code,tmpE1->place,tmpE2->place,tmpC->isTrue,tmp
C->isFalse);
return true;
}
}
else if(strcmp(Node->type,"=")==0){ //如果当前为=,走=分支 if(getNext(fp)) //匹配= if(MyFunction_E(fp,tmpE2)) { //递归执行程序 E
sprintf(tmpC->code,"%s%s if %s = %s goto L%d\n goto
L%d\n",tmpE1->code,tmpE2->code,tmpE1->place,tmpE2->place,tmpC->isTrue,tmp
C->isFalse);
return true;
}
}
}
return false;
}
bool MyFunction_E (FILE* fp, str_E* &tmpE){ //E CNode* node;
str_T* tmpT1 = new str_T;
str_T* tmpT2 = new str_T;
bool isFirst = true; //是否为 E->T 运算的标签
if(MyFunction_T(fp,tmpT1)){ //递归执行 T
while(1){
if(strcmp(Node->type,"+")==0) { //如果当前为+,算一个运算式
T+T isFirst = false; //改变标签 if(getNext(fp)) //匹配+ if(MyFunction_T(fp,tmpT2)) { //递归执行 T
strcpy(tmpE->place,newtemp());
sprintf(tmpE->code,"%s%s %s = %s +
%s\n",tmpT1->code,tmpT2->code,tmpE->place,tmpT1->place,tmpT2->place);
strcpy(tmpT1->code,tmpE->code);
strcpy(tmpT1->place,tmpE->place);
}
}
else if(strcmp(Node->type,"-")==0){ //如果当前为-,算一个运算式
T-T
isFirst = false; //改变标签 if(getNext(fp)) //匹配- if(MyFunction_T(fp,tmpT2)) { //递归执行 T
strcpy(tmpE->place,newtemp());
sprintf(tmpE->code,"%s%s %s = %s -
%s\n",tmpT1->code,tmpT2->code,tmpE->place,tmpT1->place,tmpT2->place);
strcpy(tmpT1->code,tmpE->code);
strcpy(tmpT1->place,tmpE->place);
}
}
else break;
}
if(isFirst) { //E->T 的语义操作 strcpy(tmpE->code,tmpT1->code); strcpy(tmpE->place,tmpT1->place);
}
return true;
}
else
return false;
}
bool MyFunction_T (FILE* fp, str_T* &tmpT){ //T CNode* node;
str_F* tmpF1 = new str_F;
str_F* tmpF2 = new str_F;
bool isFirst = true; //是否为 T->F 的标签
if(MyFunction_F(fp,tmpF1)) { //递归执行 F
while(1){
if(strcmp(Node->type,"*")==0) {//如果当前为*,算一个运算式 F*F
isFirst = false; //改变标签 if(getNext(fp)) //匹配* if(MyFunction_F(fp,tmpF2)) { //递归执行 F
strcpy(tmpT->place,newtemp());
sprintf(tmpT->code,"%s%s %s = %s *
%s\n",tmpF1->code,tmpF2->code,tmpT->place,tmpF1->place,tmpF2->place);
strcpy(tmpF1->code,tmpT->code);
strcpy(tmpF1->place,tmpT->place);
}
}
else if(strcmp(Node->type,"/")==0) {//如果当前为*,算一个运算式
F/F isFirst = false; //改变标签 if(getNext(fp)) //匹配/ if(MyFunction_F(fp,tmpF2)){ //递归执行 F
strcpy(tmpT->place,newtemp());
sprintf(tmpT->code,"%s%s %s = %s /
%s\n",tmpF1->code,tmpF2->code,tmpT->place,tmpF1->place,tmpF2->place);
strcpy(tmpF1->code,tmpT->code);
strcpy(tmpF1->place,tmpT->place);
}
}
else break;
}
if(isFirst){ //如果为 T->F 的语义操作 strcpy(tmpT->code,tmpF1->code); strcpy(tmpT->place,tmpF1->place);
}
return true;
}
else
return false;
}
bool MyFunction_F (FILE* fp, str_F* &tmpF){ //F CNode* node;
str_E* tmpE = new str_E;
if(strcmp(Node->type,"(")==0) { //如果当前为(,走(E)分支
if(getNext(fp)) //匹配(
if(MyFunction_E(fp,tmpE)) //递归执行 E
if(strcmp(Node->type,")")==0){ //检查当前是否为右括号
sprintf(tmpF->place,"%s",tmpE->place); sprintf(tmpF->code,"%s",tmpE->code); if(getNext(fp)) { //匹配右括号
return true;
}
}
}
else if(strcmp(Node->type,"INT10")==0){ //如果当前为 INT10 sprintf(tmpF->place,"%s",Node->value);
tmpF->code[0] = '\0';
if(getNext(fp)){ //匹配 INT10 return true;
}
}
else if(strcmp(Node->type,"INT8")==0){ //如果当前为 INT8 sprintf(tmpF->place,"%s",Node->value);
tmpF->code[0] = '\0';
if(getNext(fp)) { //匹配
return true;
}
}
else if(strcmp(Node->type,"INT16")==0){ //如果当前为 INT16 sprintf(tmpF->place,"%s",Node->value);
tmpF->code[0] = '\0';
if(getNext(fp)){ //匹配
return true;
}
}
else if(strcmp(Node->type,"IDN")==0){ //如果当前为变量
sprintf(tmpF->place,"%s",Node->value);
tmpF->code[0] = '\0';
if(getNext(fp)){ //匹配
return true;
}
}
return false;
}
int main(){ FILE* fp; fp=fopen("code3.txt","r"); str_S_* tmpS_ = new str_S_; while(1){
if(MyFunction_S_(fp,tmpS_)){
printf("------------------------------This is a new sentence!\n");
printf("%s\n", tmpS_->code);
}
else if(strcmp(Node->type,"#")==0)
break;
else{
printf("------------------------------This is a new sentence!\n");
printf("HERE IS AN ERROR!!!\n");
if(strcmp(Node->type,"#")==0) //如果文件结束,退出
break;
else //如果文件没有结束,跳过此句,分析下一条语句
for(MyScan(fp,Node); strcmp(Node->type,";")!=0; MyScan(fp,Node))
{}
}
}
fclose(fp); getchar(); return 0;
}
注:这里采用的出错处理的方式:发现问题,提示问题,然后跳过此句,执
行下一条语句(续编译)。我理解的续编译就是这样,因为一条语句中如果有错 误,发现错误的地方之后再进行这条语句的编译是毫无意义的。而且一条语句中 的错误会千奇百怪,如果花大量的精力在如何“改正”这些错误上面(为了这条 语句的“续编译”)得不偿失。而且我看目前的编译器基本上也都是这么做的。 注:由于出错处理是后加的,所以就将它的代码直接写在了 main 函数中,可以 将 main 函数中的相应部分再封装一下。这里没有如此做。
<四>、测试
测试用例:
while a>b do a=1;
while a>b do while a>b do a=1;
if a>2 then a=2;
if a>2 then if a>3 then a=2;
if a>2 then b=3 else c=4;
if a>2 then a>3;
while (a3+15)>0xa do if x2 = 07 then
while y<z do y=y*x/z; #
测试用例说明:测试用例为多条语句,分别测试了 while 语句,while 语句的嵌 套,if 语句,if 语句的嵌套,if then else 语句,出错处理(if a>2 then a>3;) 以及综合语句(实验指导书上的例子)。出错处理的形式已在上面说明,而这个 程序支持续编译,所以可以有错误的语句在例子中。测试结果如下

可以见到,在分析有问题的语句 if a>2 then a>3;时,程序输出 HERE IS AN ERROR!!!(处理方式比较简单)然后跳过此句(以分号作为语句的分界点)继续 向下进行编译。
<五>
实验过程中遇到的问题
这个实验的问题还是比较多的,主要是在语义规则上,具体点就是各个标号 的确定,什么时候需要 next,什么时候需要 begin,while 语句向回调转时候标 签的重复问题。解决 while 标签问题的时候我先判断了一下该 while 是不是被嵌 套的(全局变量 Lnum——表示当前分配的标号——是否大于 1)。如果是,则回 收分配的标签,同时 code 中部输出标签;如果不是,分配标签有效,code 中输 出标签(最外层的 while 需要标签)
还有一个问题到现在没有解决:else 问题。就是我将产生式改写后,X->else S | null,而在之前的 S->if C then S1 X 中,C.false 和 S1 的 next 无法先于 X 确 定:当 X->else S 时,C.false 应该为 X.next;而如果 X-> null,C.false 就为 S.next,为 X.begin。而在我的程序中三地址码是随着程序的进行直接确定的, 所以 C 一定先于 X 执行,所以这个问题无法解决。如果要解决这个问题就需要采 取“拉链回填”的方法:将各个具有相同的标签位置的地方存放在一个链表中, 最后为每个链表分配一个标签,这样 C 的标签就可以在 X 执行完后决定。但是由 于时间关系,我没有将它改为这种形式,问题没有得到解决。所以在我的程序中, 如果用到 else 语句就不能嵌套,否则标签会出现问题。而单纯测试 if then else 语句是没有问题的(见测试)。
心得
在实验前,对于编译我的理解程度是知道词法分析,语法分析,语义分析三者之间的关系,从宏观上大概了解一个编译器的工作过程和工作原理。每堂课都能够认 真听讲,对于所讲的内容基本都能明白。然而,当真正面对实验时,我真正才感到我只是明 白其大概的工作原理,而具体实现上几乎没有什么思路。更让我尴尬的是,对于上课所讲的 东西我确实基本都能明白,然而,却无法与上机的内容联系起来。换句话说,当面对实验时, 我明白我并没有将上课所学的知识融会贯通起来,每节课所学的东西,我都单独的都能够明 白,然而却没有多想一步,考虑每节课之间的联系,以至于在面对实验题目时脑海中无法形 成系统的想法。正因如此,我更加下定决心要把实验做好,要借这个机会把这个学期所学的 东西真正掌握。
实验中我真正体会到了书本上的理论知识与具体程序实现相联系的灵活性,尤其是在实 验二中,体会更为深刻。实验二/三中,书上所学的知识发挥了很大的作用,对于同一个实 验任务,书上面提到了不同的实现方法,此外同学们还可以利用课外的知识来完成,可以说 没有一个定式。而针对不同的方法,在具体实践中会遇到不同的问题,比如我是利用 LL1 自顶向下的分析方法来做的,并且使用的是递归子程序的方法,在实验中主要遇到的问题是 语义规则的设计问题。即使是面对同一个问题,不同的人根据自己的知识水平和编程能力,也会有不同的解决方法。例如,我上面谈到的关于二义性的消除问题的多种解决方法。总而言之,整个实验的灵活性越强,就给了我们越多发挥的空间,每个人根据自己的情况走一条 最适合自己的路,但最终基本上都是殊途同归。我体会很深的是,在我定好自己程序的方向 开始一步一步实现时,每当遇到问题,我就会认真地结合所学的知识来思考解决方案。
谈到收获,我觉得本次上机实验给我的最大收获是,消除了原来对编译器的那种神秘感。 以前只是大概理解编译器的原理,知道几大块程序之间的联系,然而对于具体实现一直感觉 是很神秘,很困难的事,感觉自己根本不可能做出来,是离自己很远的东西。在本次实验后, 虽然只是实现了一个最基本的编译程序,甚至说都不能算是一个完整的编译程序,因为只是 生成了三地址码并没有进一步生成汇编代码,但是把这个基本的过程实现了一遍之后的,对 编译程序的脉络有了更深入的了解,原来感觉不可理解,觉得很难实现的地方现在看来也不再神秘了。此外对于实现编译程序的算法思想也有了一定的了解,虽然自己所使用的是最基 本且实用性不强的算法,但最终能够成功使我相信编译程序 也并不是高不可攀的。