编译原理
词法分析
一、实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求
2.1 待分析的简单的词法
(1)关键字:
begin if then while do end
所有的关键字都是小写。
(2)运算符和界符
: = + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:
ID = letter (letter | digit)*
NUM = digit digit*
(4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:
表2.1 各种单词符号对应的种别码
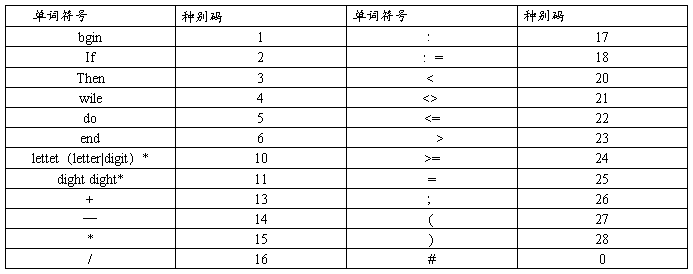
2.3 词法分析程序的功能:
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:
(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……
三、词法分析程序的C语言程序源代码:
#include
#include
char prog[80],token[8],ch;
int syn,p,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"};
scaner();
void scanner_example (FILE *fp);
main()
{
FILE *fp;
fp=fopen("D:\\1.txt","r");//打开文件
scanner_example (fp);
scaner();
}
void scanner_example (FILE *fp)
{
do
{
ch=fgetc (fp);
prog[p++]=ch;
}while (ch!='#');
p=0;
do{
scaner();
switch(syn)
{case 11:printf("( %-10d%5d )\n",sum,syn);
break;
case -1:printf("you have input a wrong string\n");
default: printf("( %-10s%5d )\n",token,syn);
break;
}
}while(syn!=0);
}
scaner()
{ sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
ch=prog[p++];
m=0;
while((ch==' ')||(ch=='\n'))ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{ syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{ while((ch>='0')&&(ch<='9'))
{ sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else switch(ch)
{ case '<':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=22;
token[m++]=ch;
}
else
{ syn=20;
p--;
}
break;
case '>':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=24;
token[m++]=ch;
}
else
{ syn=23;
p--;
}
break;
case '+': token[m++]=ch;
ch=prog[p++];
if(ch=='+')
{ syn=17;
token[m++]=ch;
}
else
{ syn=13;
p--;
}
break;
case '-':token[m++]=ch;
ch=prog[p++];
if(ch=='-')
{ syn=29;
token[m++]=ch;
}
else
{ syn=14;
p--;
}
break;
case '!':ch=prog[p++];
if(ch=='=')
{ syn=21;
token[m++]=ch;
}
else
{ syn=31;
p--;
}
break;
case '=':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=25;
token[m++]=ch;
}
else
{ syn=18;
p--;
}
break;
case '*': syn=15;
token[m++]=ch;
break;
case '/': syn=16;
token[m++]=ch;
break;
case '(': syn=27;
token[m++]=ch;
break;
case ')': syn=28;
token[m++]=ch;
break;
case '{': syn=5;
token[m++]=ch;
break;
case '}': syn=6;
token[m++]=ch;
break;
case ';': syn=26;
token[m++]=ch;
break;
case '\"': syn=30;
token[m++]=ch;
break;
case '#': syn=0;
token[m++]=ch;
break;
case ':':syn=17;
token[m++]=ch;
break;
default: syn=-1;
break;
}
token[m++]='\0';
}
四、结果分析:
输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)…… 如图所示:

五、总结:
词法分析的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。通过本试验的完成,更加加深了对词法分析原理的理解。
语法分析
一、实验目的
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法
用扩充的BNF表示如下:
1<程序>::=begin<语句串>end
2<语句串>::=<语句>{;<语句>}
3<赋值语句>::=ID:=<表达式>
4<表达式>::=<项>{+<项> | -<项>}
5<项>::=<因子>{*<因子> | /<因子>
6<因子>::=ID | NUM | (<表达式>)
2.2 实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“ok”,否则输出“error”。
例如:
输入 begin a:=9; x:=2*3; b:=a+x end #
输出 ok!
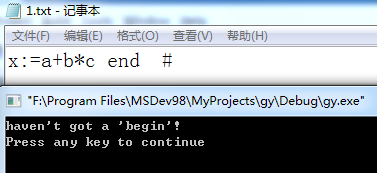
输入 x:=a+b*c end #
输出 error
2.3 语法分析程序的酸法思想
(1)主程序示意图如图2-1所示。

图2-1 语法分析主程序示意图
(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
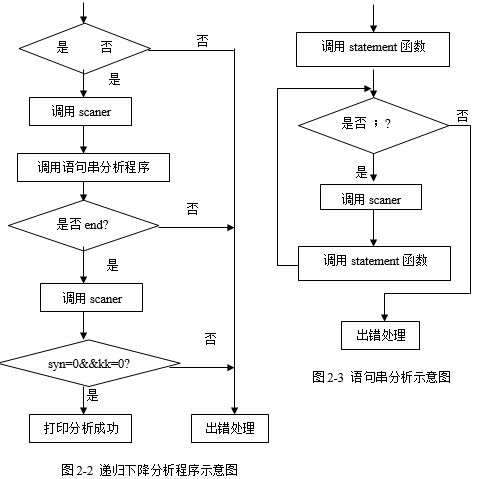
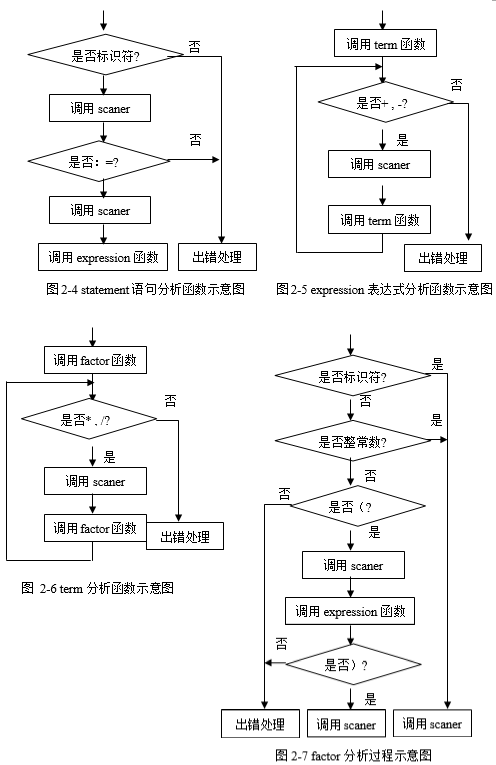
(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
三、语法分析程序的C语言程序源代码:
#include "stdio.h"
#include "string.h"
char prog[100],token[8],ch;
char *rwtab[6]={"begin","if","then","while","do","end"};
int syn,p,m,n,sum;
int kk;
factor(); //递归下降分析
expression();
yucu();
term();
statement(); //语句串分析
parser();
scaner();
void scanner_example (FILE *fp);
main()
{
p=kk=0;
FILE *fp;
fp=fopen("D:\\1.txt","r");//打开文件
scanner_example (fp);
scaner();
parser();
}
void scanner_example (FILE *fp)
{
do
{
ch=fgetc (fp);
prog[p++]=ch;
}while (ch!='#');
p=0;
}
parser() //1
{
if(syn==1)
{
scaner(); /*读下一个单词符号*/
yucu(); //2 /*调用yucu()函数;*/
if (syn==6) //end
{ scaner();
if ((syn==0)&&(kk==0))
printf("ok!\n");
}
else
{
if(kk!=1) printf("the string haven't got a 'end'!\n");
kk=1;
}
}
else
{
printf("haven't got a 'begin'!\n");
kk=1;
}
return;
} //1
yucu() //2 --段分析
{
statement(); //3 /*调用函数statement();*/
while(syn==26) //;
{
scaner(); /*读下一个单词符号*/
if(syn!=6) //end
statement(); /*调用函数statement();*/
}
return;
} //2
statement() //3 --句子分析
{
if(syn==10) //letter
{
scaner(); /*读下一个单词符号*/
if(syn==18) //:=
{
scaner(); /*读下一个单词符号*/
expression(); /*调用函数expression();*/
}
else
{
printf("the sing ':=' is wrong!\n");
kk=1;
}
}
else
{
printf("wrong sentence!\n");
kk=1;
}
return;
} //3
expression() //4 句子内部运算
{
term();
while((syn==13)||(syn==14)) //+ -
{
scaner(); /*读下一个单词符号*/
term(); /*调用函数term();*/
}
return;
} //4
term() //5
{
factor();
while((syn==15)||(syn==16)) //* /
{
scaner(); /*读下一个单词符号*/
factor(); /*调用函数factor(); */
}
return;
} //5
factor()
{
if((syn==10)||(syn==11)) //(letter|digit)
scaner();
else if(syn==27)
{
scaner(); /*读下一个单词符号*/
expression(); /*调用函数expression();*///........//
if(syn==28)
scaner(); /*读下一个单词符号*/
else
{
printf("the error on '('\n");
kk=1;
}
}
else
{
printf("the expression error!\n");
kk=1;
}
return;
} //5
scaner() //6 词法分析
{
sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
m=0;
ch=prog[p++];
while(ch==' ')ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{
while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{
token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
token[m++]='\0';
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{
while((ch>='0')&&(ch<='9'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else switch(ch)
{
case '<':m=0;
ch=prog[p++];
if(ch=='>')
{
syn=21;
}
else if(ch=='=')
{
syn=22;
}
else
{
syn=20;
p--;
}
break;
case '>':m=0;
ch=prog[p++];
if(ch=='=')
{
syn=24;
}
else
{
syn=23;
p--;
}
break;
case ':':m=0;
ch=prog[p++];
if(ch=='=')
{
syn=18;
}
else
{
syn=17;
p--;
}
break;
case '+': syn=13; break;
case '-': syn=14; break;
case '*': syn=15;break;
case '/': syn=16;break;
case '(': syn=27;break;
case ')': syn=28;break;
case '=': syn=25;break;
case ';': syn=26;break;
case '#': syn=0;break;
case 'if': syn=2;break;
case 'then': syn=3;break;
case 'wile': syn=4;break;
case 'do': syn=5;break;
case 'end': syn=6;break;
case ':=': syn=18;break;
case '<>': syn=21;break;
case '<=': syn=22;break;
case '>=': syn=24;break;
default: syn=-1;break;
}
} //6
四、结果分析:在d:1.txt中输入 begin a:=9; x:=2*3; b:=a+x end # 后输出ok! 如图4-1所示:
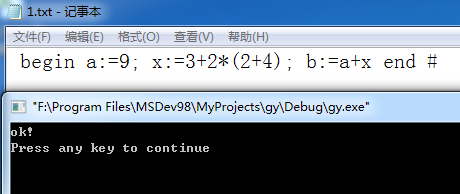
图4-1
输入 x:=a+b*c end # 后输出 haven’t got a ‘begin’ 如图4-2所示:
输入 begin x:=(a+b)*c # 输出 the sting haven’t got a ‘end’!

图4-2
五、总结:
通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”à调用scaner函数读下一个单词符号à调用IrParseà结束。递归下降分析的大致流程为:“先判断是否为begin”à不是则“出错处理”,若是则“调用scaner函数”à调用语句串分析函数à“判断是否为end”à不是则“出错处理”,若是则调用scaner函数à“判断syn=0&&kk=0是否成立”成立则说明分析成功打印出来。不成立则“出错处理”。