昆明理工大学信息工程与自动化学院学生实验报告
( 20## —20##学年第一学期)
课程名称: 开课实验室: 2012 年 12 月 03 日

一、 实验目的及内容
编译技术是理论与实践并重的课程,而其实验课要综合运用所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。
调试并完成一个词法分析程序,加深对词法分析原理的理解。
二、实验原理及基本技术路线图(方框原理图或程序流程图)
1、 待分析的简单语言的词法
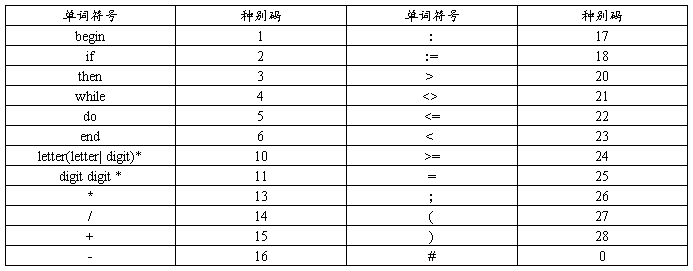
(1) 关键字:
begin if then while do end
所有关键字都是小写。
(2) 运算符和界符:
:= + – * / < <= <> > >= = ; ( ) #
(3) 其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:
ID=letter(letter| digit)*
NUM=digit digit *
(4) 空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。
2、 各种单词符号对应的种别码
3、 词法分析程序的功能
输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
二、 所用仪器、材料(设备名称、型号、规格等或使用软件)
1台PC以及VISUAL C++6.0软件。
三、 实验方法、步骤(或:程序代码或操作过程)
(1)程序代码:
#include<stdio.h>
#include<string.h>
#include<iostream.h>
char prog[80],token[8];
char ch;
int syn,p,m=0,n,row,sum=0;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner()
{
for(n=0;n<8;n++) token[n]=NULL;
ch=prog[p++];
while(ch==' ')
{
ch=prog[p];
p++;
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
m=0;
while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]='\0';
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>='0'&&ch<='9'))
{
{
sum=0;
while((ch>='0'&&ch<='9'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
}
p--;
syn=11;
if(sum>32767)
syn=-1;
}
else switch(ch)
{
case'<':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='>')
{
syn=21;
token[m++]=ch;
}
else if(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case'>':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case':':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}
break;
case'*':syn=13;token[0]=ch;break;
case'/':syn=14;token[0]=ch;break;
case'+':syn=15;token[0]=ch;break;
case'-':syn=16;token[0]=ch;break;
case'=':syn=25;token[0]=ch;break;
case';':syn=26;token[0]=ch;break;
case'(':syn=27;token[0]=ch;break;
case')':syn=28;token[0]=ch;break;
case'#':syn=0;token[0]=ch;break;
case'\n':syn=-2;break;
default: syn=-1;break;
}
}
void main()
{
p=0;
row=1;
cout<<"Please input string:"<<endl;
do
{
cin.get(ch);
prog[p++]=ch;
}
while(ch!='#');
p=0;
do
{
scaner();
switch(syn)
{
case 11: cout<<"("<<syn<<","<<sum<<")"<<endl; break;
case -1: cout<<"Error in row "<<row<<"!"<<endl; break;
case -2: row=row++;break;
default: cout<<"("<<syn<<","<<token<<")"<<endl;break;
}
}
while (syn!=0);
}
(2)创建编辑程序

(3)连接、编译和调试程序
(4)运行程序

五、实验过程原始记录( 测试数据、图表、计算等)
(1)给定源程序
begin x:=8; if x>0 then x:=2*x+1/5; end#
输出结果

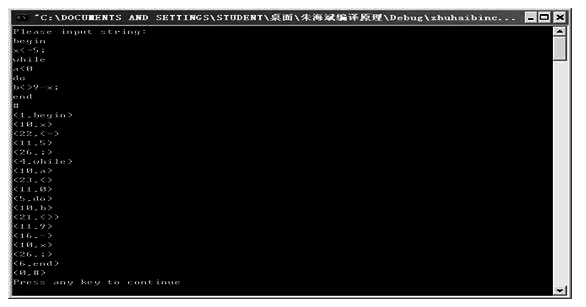
(2)源程序(包括上式未有的while、do以及判断错误语句):
begin
x<=$;
while
a<0
do
b<>9-x;
end
#
六、实验结果、分析和结论(误差分析与数据处理、成果总结等。其中,绘制曲线图时必须用计算纸或程序运行结果、改进、收获)
词法分析的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。通过本试验的完成,更加加深了对词法分析原理的理解。
通过这次实验,我对编译原理这门专业必修课有了进一步的深层次了解,把理论知识应用于实验中,也让我重新熟悉了C++语言的相关内容,加深了对C++语言知识的深化和用途的理解。相信在以后的毕业设计以及读研自己做项目时可以有更大的提升。同时这次试验让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;熟悉了构造词法分析程序的手工方式的相关原理,根据识别语言单词的状态转换图,使用某种高级语言(例如C++语言)直接编写此法分析程序。另外,也让我重新熟悉了C++语言的相关内容,加深了对C++语言的用途的理解。比如:main()函数中,用cin>>ch;语句得到ch值的话,给定源程序的结果第一行得到的是(10,beginx),因为得到的字符串中省略了空格,改用cin.get(ch);问题便解决了。另外,我在程序中加入了row变量,以便能够准确得到错误所在。
第二篇:编译原理实验报告--词法分析器
编译原理实验—词法分析器
姓名:王吉军
学号:09208015
班级:软件92

一、 实验目的
通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。同时增强编写和调试程序的能力。
二、 实验内容及要求
对某特定语言A ,构造其词法规则。
该语言的单词符号包括:
保留字(见左下表)、标识符(字母大小写不敏感)、 整型常数、界符及运算符(见右下表) 。
功能要求如下所示:
·按单词符号出现的顺序,返回二元组序列,并输出。
·出现的标识符存放在标识符表,整型常数存放在常数表,并输出这两个表格。
·如果出现词法错误,报出:错误类型,位置(行,列)。
·处理段注释(/* */),行注释(//)。
·有段注释时仍可以正确指出词法错误位置(行,列)。
三、 实验过程
1、 词法形式化描述
使用正则文法进行描述,则可以得到如下的正规式:
其中ID表示标识符,NUM表示整型常量,RES表示保留字,DEL表示界符,OPR表示运算符。
A→(ID | NUM | RES | DEL | OPR) *
ID→letter(letter | didit)*
NUM→digit digit*
letter→a| … | z | A | … | Z
digit→ 0 | … | 9
RES→ program | begin | end | var | int | and | or | not | if | then | else | while | do
DEL→( | ) | . | ; | ,
OPR→
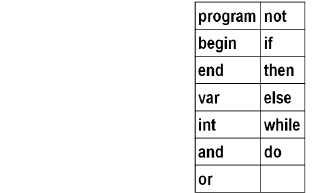
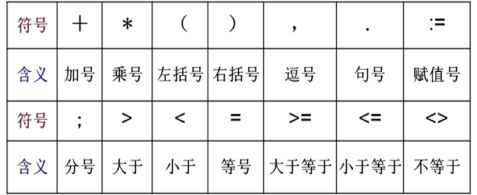
+ | * | := | > | < | = | >= | <= | <>
如果关键字、标识符和常数之间没有确定的算符或界符作间隔,则至少用一个空格作间隔。空格由空白、制表符和换行符组成。
2、 单词种别定义;
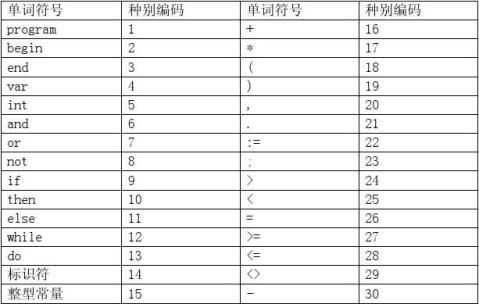
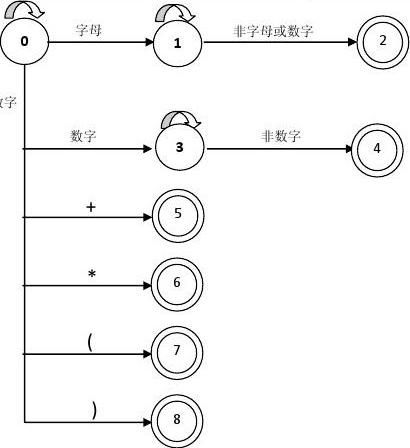
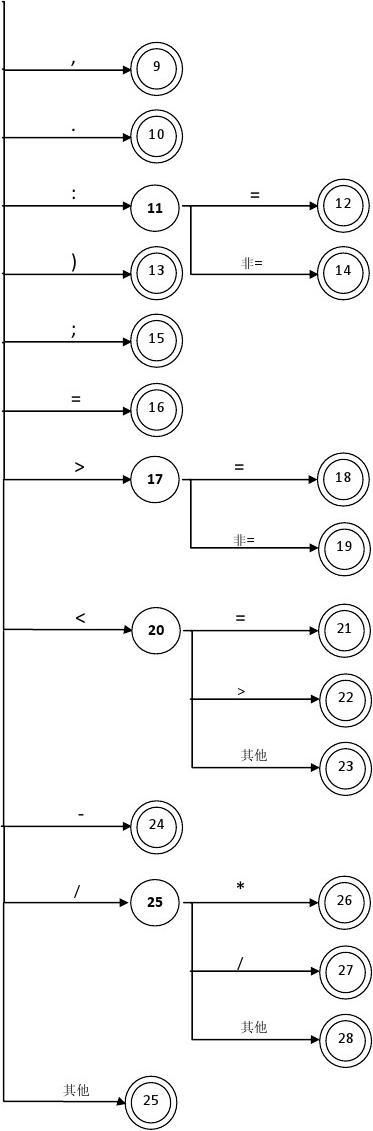
3、 状态转换图;
语言A的词法分析的状态转换图如下所示:
空格符,制表符
或回车符 字母或数字
4、 运行环境介绍;
本次实验采用MyEclipse进行代码的编写和编译及运行,编写语言为java语言;程序的运行环境为windows 7 旗舰版
5、 关键算法的流程图及文字解释;
程序中用到的函数列表:
A类定义各种类函数以及包含主函数public static void main() 变量ch储存当前最新读进的字符的地址
strToken存放当前字符串
main() //主函数
Analysis()//分析函数,每次读入一行文件,进行识别处理;
charGetChar(); //取得当前位置的字符的内容放入ch,并提前指向下一个字符;
char GetNextChar();//取得当前位置的下一位置的字符,
StringConCat(); //将ch指向的字符连接到strToken后面 isLetter(); //判断ch指向的字符是否字母
isDigit(); //判断ch指向的字符是否数字
add(p,str); //向p表中插入当前strToken的字符串
BooleanfindKeyWord(str); //检测当前strToken中的字符串是否保留字,若是,则执行getKeyWordKey(str),返回保留字的id,否则,判别其是否是已存在的标示符,若是,返回标示符的id以及该标示符在表中的位置;
findPunctuation()//判断是否是一个保留的符号;
getindex() //返回已经识别的标示符或者是数字的位置下标; Booleanexist(); //检测当前strToken中的字符串是否在标识符表中已存在,若是,则返回true,否则返回false
void callError(); //出错处理过程,将错误的位置报告出来
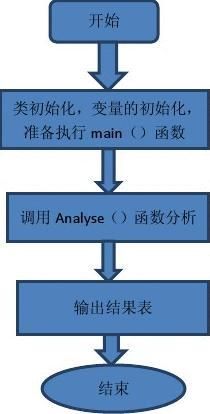
(1)main()函数的流程图如下:
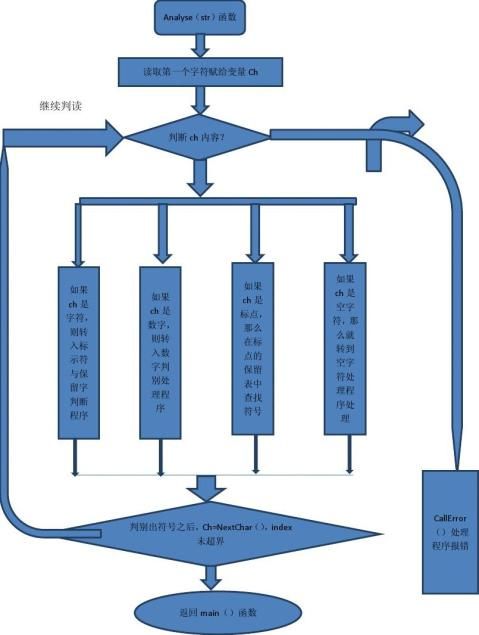
(2)具体分析流程图:
6、测试报告(测试用例,测试结果);
首先输入一个不含错误的程序(两种注释)进行检测:
运行后在控制台上得到的结果如下所示:
得到的二元组序列如下:


经检验,输出的是正确的二元组序列。 再输入一个含有错误的程序(含有注释)进行检验:
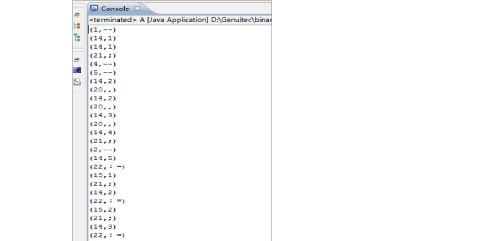

运行后在控制台上得到的结果如下所示:
经检验,错误的位置是正确的
如果是空文件,编译也会通过;
四、 实验总结
通过本次试验,我加深了对编译原理中的词法分析的理解,同时通过动手,更加锻炼了自己。本次试验由于使用的刚刚学习的java语言,通过这次机会加强了自己对java语言的熟悉的使用。
在这次试验中,感谢老师的认真的讲解与同学的无私的帮助。总结来说,自己在这次试验中收获很大。
附:以下为本次实验的源代码:


package Analysis;
importjava.io.BufferedReader;
importjava.io.File;
importjava.io.FileReader;
importjava.io.IOException;
importjava.util.ArrayList;
importjava.util.HashMap;
importjava.util.Map;
public class A {
private static char ch; private static String strToken; private static int index = 0; private static int line = 1; private static booleannoteTag=false; private Map<Integer,String> keywords; privateHashMap<String, Integer> punctuations;
private static ArrayList<String> p=new ArrayList<String>(); private static ArrayList<String> q=new ArrayList<String>();
// get and set 函数 public char getCh() {
} returnch; public void setCh(char ch) { } A.ch = ch; public String getStrToken() { } returnstrToken; public void setStrToken(String strToken) { } A.strToken = strToken; public void setPunctuations(HashMap<String, Integer> punctuations) { } this.punctuations = punctuations; public Map<String, Integer>getPunctuations() { } return punctuations;
// 构造函数 public A() { this.keywords = new HashMap<Integer,String>(); keywords.put(1,"Program"); keywords.put(2,"begin"); keywords.put(3,"end"); keywords.put(4,"var"); keywords.put(5,"int"); keywords.put(6,"and"); keywords.put(7,"or"); keywords.put(8,"not"); keywords.put(9,"if"); keywords.put(10,"then"); public Map<Integer, String>getKeywords() { } return keywords; public void setKeywords(Map<Integer, String> keywords) { } this.keywords = keywords;
keywords.put(11,"else"); keywords.put(12,"while"); keywords.put(13,"do"); this.punctuations = new HashMap<String, Integer>(); punctuations.put("+", 16); punctuations.put("*", 17); punctuations.put("(", 18); punctuations.put(")", 19); punctuations.put(",", 20); punctuations.put(";", 21); punctuations.put(":=", 22); punctuations.put(">", 23); punctuations.put(">=", 24); punctuations.put("<", 25); punctuations.put("<=", 26); punctuations.put(".", 27); punctuations.put("<>", 28); punctuations.put("=", 29); }
// 函数定义(词法分析函数) publicbooleanAnalyse(char[] strArray) { index = 0;// 每次分析一行完成后就将index置0 char temp1; introwLength = strArray.length; outer:while (index <rowLength) { strToken = ""; ch = GetChar(strArray); if (ch == ';'){ System.out.println("(21,;) "); } else if(ch==':') { index++; System.out.println("(22,:=)"); } else if(ch=='.') { System.out.println("(27,.)"); } else if(ch=='>') {
if(( temp1=this.getNextChar(strArray))=='=') System.out.println("(24,>=)"); else { index--; System.out.println("(23,>)"); } } else if(ch=='<') { if(( temp1=this.getNextChar(strArray))=='=') System.out.println("(26,<=)"); else if(temp1=='>') System.out.println("(28,<>)"); else { index--; System.out.println("(25,<)"); } }
else if(ch=='*'&¬eTag==false) { System.out.println("(17,*)"); } else if (java.lang.Character.isLetter(ch)&¬eTag==false) { strToken = contact(strToken, ch); ch = getNextChar(strArray); while ((java.lang.Character.isLetter(ch)) } index--; // System.err.println("!!!"+strToken); if (findKeyword(strToken)) { //System.out.println("(15," + strToken.toString() + ")\n"); int i=getKeyWordKey(strToken); System.out.println("("+i+",--)"); || (java.lang.Character.isDigit(ch))) { strToken = contact(strToken, ch); ch = getNextChar(strArray); } else { if(!exist(p,strToken)) p.add(strToken);
} int i=getindex(p,strToken); //System.out.println("(14," + strToken.toString() + ")\n"); System.out.println("(14,"+i+")"); } else if (java.lang.Character.isDigit(ch)&¬eTag==false) { strToken = this.contact(strToken, ch); ch = this.getNextChar(strArray); while (java.lang.Character.isDigit(ch)) { } index--; strToken = this.contact(strToken, ch); ch = this.getNextChar(strArray); //System.out.println("(15," + strToken.toString() + ")\n"); if(!exist(q,strToken))
q.add(strToken);
int i=getindex(q,strToken);
System.out.println("(15,"+i+")");
");
strToken = ""; } else if (ch == '/'||noteTag==true) { intstartj=index; //注释起始位置标记 intstarti=line; if(noteTag==false){ //System.out.println("该部分是注释注释,从第"+starti+"行第"+startj+"列开始 } char temp = this.getNextChar(strArray); if (temp == '*'&¬eTag==false) { temp = this.getNextChar(strArray); while(index<rowLength){ temp = this.getNextChar(strArray); if(temp=='*'&&( temp1=this.getNextChar(strArray))=='/') { } if(index>=rowLength) index--; break;
} } { } noteTag=true; break outer; else if(noteTag==true&&ch!='*') { while(index<rowLength){ temp = this.getNextChar(strArray); if(temp=='*'&&(temp1=this.getNextChar(strArray))=='/') { noteTag=false; //System.out.println(/*"该部分是注释注释,从第"+starti+"行第"+startj+"列开始*/"到第"+line+"行"+"第"+(index-0)+"列为止");
} break; } } else if(temp=='/')
{ } while(true) { } index++; if(index>=rowLength) break outer;
else
return false; } else { String key = String.valueOf(ch); if (this.findPunctuation(key)) { System.out.println("("+this.getPunctuation(key)+"," + key + ")"); } else if (key.equals(" ") || key.equals(" ")) { // ************????????????????????***********
break; } else return false; //System.out.println( "[未知符号] " + key + "\n"); //strToken = "";
} } } return true; public char GetChar(char[] array) { } try { while ((array[index]) == ' ') { } index++;// 提前指向下一个字符******************** index++; } catch (ArrayIndexOutOfBoundsException e) { } return array[index - 1]; return ' '; public char getNextChar(char[] strChar) { } index++; returnstrChar[index - 1];
publicintgetPunctuation(String str) { publicbooleanfindPunctuation(String str) { } if (this.punctuations.containsKey(str)) { return true; publicbooleanfindKeyword(String str) { } for(int i=0;i<13;i++){ if(str.equalsIgnoreCase(this.keywords.get(i))) } return false; return true; public String contact(String token, char ch) { } return token + String.valueOf(ch); } else return false;
} returnthis.punctuations.get(str); publicboolean Clean() { } return true; public void callError(int line) { System.out.println("出现错误,错误位置在第" + line + "行,第" + index + "列");
publicboolean exist(ArrayList<String>p,StringstrToken) { } publicintgetKeyWordKey(String str) if(p.contains(getStrToken())) return true; else return false; }
{ } for(int i=1;i<=13;i++) { } return 10000; if(str.equalsIgnoreCase(this.keywords.get(i))) return i;
publicintgetindex(ArrayList<String>p,StringStr) {
returnp.lastIndexOf(Str)+1; /*int j=0; for(int i=0;i<p.size();i++) { if(p.get(i).equals(Str)) j++; } return j;*/
}
public static void main(String args[]) { File file = new File("F:\\sample.txt");
A a = new A(); char[] strChar = new char[100];// 限制每行代码字符数不超过100 BufferedReader reader = null; try { //System.out.println("以行为单位读取文件内容,一次读一整行:"); reader = new BufferedReader(new FileReader(file)); String tempString = null; // int line = 1; // 一次读入一行,直到读入null为文件结束 while ((tempString = reader.readLine()) != null) { // 显示行号 //System.out.println("line " + line + ": " + tempString); strChar = tempString.toCharArray(); boolean flag = a.Analyse(strChar); if (flag == true) line++; else { } a.callError(line); break; }
} System.out.println("标示符表"); System.out.println(p.toString()); System.out.println("常数表"); System.out.println(q.toString()); reader.close(); } catch (IOException e) { e.printStackTrace(); } } finally { } if (reader != null) try { reader.close(); } catch (IOException e1) { } // TODO Auto-generated catch block e1.printStackTrace();