
编译原理课内实验报告
计算机11班
2110505018 司默涵
20xx年11月7日
实验一 词法分析器
一、实验题目和要求
1、题目
根据给定的C0语言文法构造词法分析器,采用Lex生成,或者编程实现。
2、实验目的
(1)强化对系统软件综合工程实现能力的训练;
(2)加强对词法分析原理、方法和基本实现技术的理解
3、C0文法简介
program→ { var-declaration | fun-declaration }
var-declaration→ int ID { , ID }
fun-declaration→ ( int | void ) ID ( params ) compound-stmt
params → int ID { , int ID } | void | empty
compound-stmt→ { { var-declaration } { statement } }
statement→ expression-stmt∣compound-stmt ∣if-stmt ∣while-stmt | return-stmt expression-stmt→ [ expression ] ;
if-stmt→ if( expression ) statement [ else statement ]
while-stmt→ while( expression ) statement
return-stmt→ return [ expression ] ;
expression→ ID = expression | simple-expression
simple-expression→ additive-expression [ relop additive-expression ]
relop → < | <= | > | >= | == | !=
additive-expression→ term [( + | - ) term ]
term→ factor [ ( * | / ) factor ]
factor→ ( expression )| ID | call | NUM
call→ ID( args )
args→ expression { , expression } | empty
ID →… ;参见C语言标识符定义
NUM →… ;参见C语言数的定义
二、程序设计思想及设计方案
1、词法分析器流程图(设计思想)
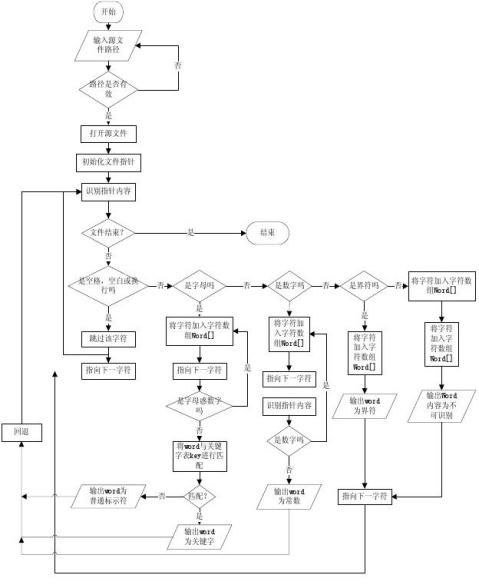
letter|digit
2、简要设计方案
①将待分析程序保存在f盘根目录下的incode.txt文件中,以备词法分析器调用;
②词法分析器对待分析程序进行分析后,在f盘根目录下创建outfile.xml文件,输出词法分析结果;
③待分析代码以‘#’为结束符。
3、程序工作说明
程序的输入文件是任何一个目录下的文件格式的C0语言程序段。
程序的输出文件是以xml格式表示的词法分析的结果。该输出将作为下个实验语法分析的输入文件。(注意:也可以自定义格式,但需要在报告中给出格式说明) 词法分析结果输出成xml文件格式为:
<root>
<Token lineno=xx type=’…’ string=’…’ ></Token>
<Token lineno=xx type=’…’ string=’…’></Token>
…
</root>
4、相关说明
词法分析器任务
输入源程序;扫描、分解字符串,识别出一个个单词(定义符、标识符、运算符、界符、常数)。
单词符号的表示
1) 需要对单词分类,每一个识别出来的单词都属于不同的类型
public enum TokenType
{
//关键字
IF,ELSE,WHILE,RETURN,VOID,INT,
//运算符 + - * / = <<= >>= != ?
PLUS,MINUS,STAR,SLASH, LT,LTEQ,GT,GTEQ,EQ,NEQ,ASSIGN, //界符 ; , ( ) [ ] { } /* */
SEMI,COMMA,LPAREN,RPAREN,LSQUAR,RSQUAR,LBRACE,RBRACE, LCOMMENT,RCOMMENT,
ID, //标识符
NUMBER, //数字常量
ID→letter(letter|didit)*
NUMBER→digit digit *
letter→a|b|?|z|A|B|?|Z
digit→0|?|9 』
NONTOKEN,ERROR,ENDFILE // 其它
};
2) 单词符号的数据结构设计
public class Token
{
string str; //单词字符串
TokenType ttype; //单词的类型
int line; //所在行号信息}
三、源代码
#include<stdio.h> #include<string.h> #include<ctype.h> #include<stdlib.h>
#define MAXBUF 1023
int Judge(char *p) { char
*word[]={"exp","throw","catch","try","virtual","this","delete","new","protected","private","public","class","return","while","if","else","int","void"}; int ptr,i,flag; flag=0;
for(i=0;i<18;i++) { ptr=stricmp(p,word[i]); if(ptr==0) { flag=1; return(i+1); break; } } if(flag==0) { return 0; } return 0; }
char *transform(int a) { char
*word[]={"EXP","THROW","CATCH","TRY","VIRTUAL","THIS","DELETE","NEW","PROTECTED","PRIVATE","PUBLIC","CLASS","RETURN","WHILE","IF","ELSE","INT","VOID"}; if(a<=18&&a>1)
return word[a-1];
else return NULL; }
void lexscanf(FILE *fpin,FILE*fpout) { char arr[MAXBUF]; int i=0; int j=0; char ch; int lineo=1; fprintf(fpout,"<?xml version=\"1.0\" ?>\n"); fprintf(fpout,"<root>\n"); while(1) { fscanf(fpin,"%c",&ch); //从输入文件中读入字符 if(ch==' '||ch=='\t') //清除空白 ; else if(ch=='\n') //识别回车,行数+1 lineo++; else if(isdigit(ch)) //如果输入字符为数字 { while(isdigit(ch)) //一直读字符,直到读入的字符不是数字 { arr[j]=ch; j++; fscanf(fpin,"%c",&ch); } fseek(fpin,-1L,SEEK_CUR); char*
temp1=(char*)malloc(j+1); memcpy(temp1,arr,j); //将缓冲区的内容拷贝到temp1中去 temp1[j]='\0'; j=0; fprintf(fpout,"<token
line=\"%d\" type=\"NUMBER\" string=\"%s\" />\n",lineo,temp1); //在文件中写入数字 free(temp1); } else if(isalpha(ch)) //如果读入的字符为字母 { while(isalpha(ch)||isdigit(ch)) { arr[i]=ch; i++; fscanf(fpin,"%c",&ch); } fseek(fpin,-1L,SEEK_CUR); char* temp=(char*)malloc(i+1); memcpy(temp,arr,i); temp[i]='\0'; i=0; if(Judge(temp)) //如果读入的字母能与关键字相等 { fprintf(fpout,"<token line=\"%d\" type=\"%s\" string=\"%s\"
/>\n",lineo,transform(Judge(temp)),temp); //输出该关键字,并且输出类型号 } else { fprintf(fpout,"<token line=\"%d\" type=\"ID\" string=\"%s\" />\n",lineo,temp); //否则,认定为标示符 } free(temp); } else if(ch=='<') //处理二字符运算符<= { fscanf(fpin,"%c",&ch); if(ch=='=') fprintf(fpout,"<token line=\"%d\" type=\"LTEQ\" string=\"<=\" />\n",lineo,"<="); else
if(isdigit(ch)||isalpha(ch)||ch==' ') { fprintf(fpout,"<token line=\"%d\" type=\"LT\" string=\"<\" />\n",lineo,'<'); fseek(fpin,-1L,SEEK_CUR); } else fprintf(fpout,"error in compiling line %d! Unknown character %c \n",lineo,ch); } else if(ch=='>') //处理二字符运算符>= { fscanf(fpin,"%c",&ch); if(ch=='=') fprintf(fpout,"<token line=\"%d\" type=\"GTEQ\" string=\">=\" />\n",lineo,">="); else
if(isdigit(ch)||isalpha(ch)||ch==' ') { fprintf(fpout,"<token line=\"%d\" type=\"GT\" string=\">\" />\n",lineo,'>'); fseek(fpin,-1L,SEEK_CUR); } else fprintf(fpout,"error in compiling line %d! Unknown character %c \n",lineo,ch); } else if(ch=='=') //处理二字符运算符== { fscanf(fpin,"%c",&ch); if(ch=='=') fprintf(fpout,"<token line=\"%d\" type=\"EQ\" string=\"%s\" />\n",lineo,"==");
else
if(isdigit(ch)||isalpha(ch)||ch==' ') { fprintf(fpout,"<token line=\"%d\" type=\"ASSIGN\" string=\"%c\" />\n",lineo,'='); fseek(fpin,-1L,SEEK_CUR); } else fprintf(fpout,"error in compiling line %d! Unknown character %c \n",lineo,ch); } else if(ch=='/') { fscanf(fpin, "%c",&ch); if(ch=='*') { while(1){ fscanf(fpin,"%c",&ch); while(ch!='*') { fscanf(fpin,"%c",&ch); } fscanf(fpin,"%c",&ch); if(ch=='/') break; } } else fprintf(fpout,"error in compiling line %d! Unknown character %c \n",lineo,ch); } else if(ch=='!') //处理二字符运算符!= { fscanf(fpin,"%c",&ch); if(ch=='=') fprintf(fpout,"<token line=\"%d\" type=\"NEQ\" string=\"%s\" />\n",lineo,"!="); else fprintf(fpout,"error in compiling line %d! Unknown character %c \n",lineo,ch); } else if(ch=='*') //处理二字符运算符*/ { fscanf(fpin,"%c",&ch); if(ch=='/') fprintf(fpout,"<token line=\"%d\" type=\"RCOMMENT\" string=\"%s\" />\n",lineo,"*/"); else if(isdigit(ch)||isalpha(ch)) { fprintf(fpout,"<token line=\"%d\" type=\"STAR\" string=\"%c\" />\n",lineo,'*'); fseek(fpin,-1L,SEEK_CUR); } else fprintf(fpout,"error in compiling line %d! Unknown character %c \n",lineo,ch); } else //处理各种单字符运算符 { if(ch=='+') { fprintf(fpout,"<token line=\"%d\" type=\"PLUS\" string=\"%c\" />\n",lineo,'+'); continue; } if(ch=='-') { fprintf(fpout,"<token line=\"%d\" type=\"MINUS\" string=\"%c\" />\n",lineo,'-'); continue; } if(ch=='%') {
fprintf(fpout,"<token line=\"%d\" type=\"PLUS\" string=\"%c\" />\n",lineo,'%'); continue; } if(ch=='&') { fprintf(fpout,"<token line=\"%d\" type=\"PLUS\" string=\"%c\" />\n",lineo,'&'); continue; } if(ch=='"') { fprintf(fpout,"<token line=\"%d\" type=\"PLUS\" string=\"%c\" />\n",lineo,'"'); continue; } if(ch=='\\') { fprintf(fpout,"<token line=\"%d\" type=\"SLASH\" string=\"%c\" />\n",lineo,'\\'); continue; }
if(ch==';') { fprintf(fpout,"<token line=\"%d\" type=\"SEMI\" string=\"%c\" />\n",lineo,';'); continue; } if(ch==',') { fprintf(fpout,"<token line=\"%d\" type=\"COMMA\" string=\"%c\" />\n",lineo,','); continue; } if(ch==':') { fprintf(fpout,"<token line=\"%d\" type=\"COLON\" string=\"%c\" />\n",lineo,':'); continue; } if(ch=='.') { fprintf(fpout,"<token line=\"%d\" type=\"DOT\" string=\"%c\" />\n",lineo,'.'); continue; } if(ch=='~') { fprintf(fpout,"<token line=\"%d\" type=\"WAVE\" string=\"%c\" />\n",lineo,'~'); continue; } if(ch=='(') { fprintf(fpout,"<token line=\"%d\" type=\"LPAREN\" string=\"%c\" />\n",lineo,'('); continue; } if(ch==')') { fprintf(fpout,"<token line=\"%d\" type=\"RPAREN\" string=\"%c\" />\n",lineo,')'); continue; } if(ch=='[') { fprintf(fpout,"<token line=\"%d\" type=\"LSQUAR\" string=\"%c\" />\n",lineo,'['); continue; } if(ch==']') { fprintf(fpout,"<token
line=\"%d\" type=\"RSQUAR\" string=\"%c\" />\n",lineo,']'); continue;
} if(ch=='{') { fprintf(fpout,"<token line=\"%d\" type=\"LBRACE\" string=\"%c\" />\n",lineo,'{'); continue; } if(ch=='}') { fprintf(fpout,"<token line=\"%d\" type=\"RBRACE\" string=\"%c\" />\n",lineo,'}'); continue; } /*if(ch=='#')//终止符 { fprintf(fpout,"</root>"); break; }*/ else //若都没找到,输入错误! fprintf(fpout,"error in compiling line %d! Unkonwn character %c \n",lineo,ch); }
If(feof(fpin))//文件终止
break; } } }
void main() { FILE *fpin; FILE *fpout; if((fpin=fopen("f:\\incode.txt","rt"))==NULL) { printf("Cannot find the file!"); exit(1); } if((fpout=fopen("f:\\outfile.xml","wt"))==NULL) { printf("Cannot find the file!"); exit(1); }
printf("You can find the outfile in f disk.\n"); lexscanf(fpin,fpout); fclose(fpin); fclose(fpout); }
四、运行结果及分析
1、输入文件内容(示例1) int main()
{
int c[10000],n,i,l,m,j,M,a,b; scanf("%d%d",&l,&m);
for(i=0;i<=l;i++)
c[i]=1;
for(i=0;i<m;i++)
{scanf("%d%d",&a,&b);
for(j=a;j<=b;j++)
c[j]=0;
}
M=0;
for(i=0;i<=l;i++)
M=M+c[i];
printf("%d\n",M);
return 0;
}
#
输入文件内容(示例2,即例程) void f1(int a,int b) {
a = 1;
b = a+b;
}
void main()
{
int a[100];
int b;
float c;
a[b]=a;
if(c<b){
f1(a,b);
}
}
#
2、输出文件内容(示例1) <?xml version="1.0" ?>
<root>
<token line="1" type="INT" string="int" /> <token line="1" type="ID" string="main" /> <token line="1" type="LPAREN" string="("
/> <token line="1" type="RPAREN" string=")" /> <token line="2" type="LBRACE" string="{" /> <token line="3" type="INT" string="int" /> <token line="3" type="ID" string="c" />
<token line="3" type="LSQUAR" string="[" />
<token line="3" type="NUMBER" string="10000" />
<token line="3" type="RSQUAR" string="]" />
<token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="n" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="i" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="l" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="m" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="j" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="M" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="a" /> <token line="3" type="COMMA" string="," />
<token line="3" type="ID" string="b" /> <token line="3" type="SEMI" string=";" /> <token line="4" type="ID" string="scanf" /> <token line="4" type="LPAREN" string="(" />
<token line="4" type="PLUS" string=""" /> <token line="4" type="PLUS" string="%" /> <token line="4" type="ID" string="d" /> <token line="4" type="PLUS" string="%" /> <token line="4" type="ID" string="d" /> <token line="4" type="PLUS" string=""" /> <token line="4" type="COMMA" string="," />
<token line="4" type="PLUS" string="&" /> <token line="4" type="ID" string="l" /> <token line="4" type="COMMA" string="," />
<token line="4" type="PLUS" string="&" /> <token line="4" type="ID" string="m" /> <token line="4" type="RPAREN" string=")" />
<token line="4" type="SEMI" string=";" /> <token line="5" type="ID" string="for" /> <token line="5" type="LPAREN" string="(" />
<token line="5" type="ID" string="i" /> <token line="5" type="ASSIGN" string="=" />
<token line="5" type="NUMBER" string="0" />
<token line="5" type="SEMI" string=";" /> <token line="5" type="ID" string="i" />
<token line="5" type="LTEQ" string="<=" />
<token line="5" type="ID" string="l" /> <token line="5" type="SEMI" string=";" /> <token line="5" type="ID" string="i" /> <token line="5" type="PLUS" string="+" /> <token line="5" type="PLUS" string="+" /> <token line="5" type="RPAREN" string=")" />
<token line="6" type="ID" string="c" /> <token line="6" type="LSQUAR" string="[" />
<token line="6" type="ID" string="i" /> <token line="6" type="RSQUAR" string="]" />
<token line="6" type="ASSIGN" string="=" />
<token line="6" type="NUMBER" string="1" />
<token line="6" type="SEMI" string=";" /> <token line="7" type="ID" string="for" /> <token line="7" type="LPAREN" string="(" />
<token line="7" type="ID" string="i" /> <token line="7" type="ASSIGN" string="=" />
<token line="7" type="NUMBER" string="0"
/>
<token line="7" type="SEMI" string=";" /> <token line="7" type="ID" string="i" /> <token line="7" type="LT" string="<" /> <token line="7" type="ID" string="m" /> <token line="7" type="SEMI" string=";" /> <token line="7" type="ID" string="i" /> <token line="7" type="PLUS" string="+" /> <token line="7" type="PLUS" string="+" /> <token line="7" type="RPAREN" string=")" />
<token line="8" type="LBRACE" string="{" />
<token line="8" type="ID" string="scanf" /> <token line="8" type="LPAREN" string="(" />
<token line="8" type="PLUS" string=""" /> <token line="8" type="PLUS" string="%" /> <token line="8" type="ID" string="d" /> <token line="8" type="PLUS" string="%" /> <token line="8" type="ID" string="d" /> <token line="8" type="PLUS" string=""" /> <token line="8" type="COMMA" string="," />
<token line="8" type="PLUS" string="&" /> <token line="8" type="ID" string="a" /> <token line="8" type="COMMA" string="," />
<token line="8" type="PLUS" string="&" /> <token line="8" type="ID" string="b" /> <token line="8" type="RPAREN" string=")" />
<token line="8" type="SEMI" string=";" /> <token line="9" type="ID" string="for" /> <token line="9" type="LPAREN" string="(" />
<token line="9" type="ID" string="j" /> <token line="9" type="ASSIGN" string="=" />
<token line="9" type="ID" string="a" /> <token line="9" type="SEMI" string=";" /> <token line="9" type="ID" string="j" />
<token line="9" type="LTEQ" string="<=" /> <token line="9" type="ID" string="b" /> <token line="9" type="SEMI" string=";" /> <token line="9" type="ID" string="j" /> <token line="9" type="PLUS" string="+" /> <token line="9" type="PLUS" string="+" /> <token line="9" type="RPAREN" string=")" />
<token line="10" type="ID" string="c" /> <token line="10" type="LSQUAR" string="[" />
<token line="10" type="ID" string="j" /> <token line="10" type="RSQUAR" string="]" />
<token line="10" type="ASSIGN" string="=" />
<token line="10" type="NUMBER" string="0" />
<token line="10" type="SEMI" string=";" /> <token line="11" type="RBRACE" string="}" />
<token line="12" type="ID" string="M" /> <token line="12" type="ASSIGN" string="=" />
<token line="12" type="NUMBER" string="0" />
<token line="12" type="SEMI" string=";" /> <token line="13" type="ID" string="for" /> <token line="13" type="LPAREN" string="(" />
<token line="13" type="ID" string="i" /> <token line="13" type="ASSIGN" string="=" />
<token line="13" type="NUMBER" string="0" />
<token line="13" type="SEMI" string=";" /> <token line="13" type="ID" string="i" /> <token line="13" type="LTEQ" string="<=" />
<token line="13" type="ID" string="l" /> <token line="13" type="SEMI" string=";" /> <token line="13" type="ID" string="i" /> <token line="13" type="PLUS" string="+" /> <token line="13" type="PLUS" string="+" /> <token line="13" type="RPAREN" string=")"
/>
<token line="14" type="ID" string="M" /> <token line="14" type="ASSIGN" string="=" />
<token line="14" type="ID" string="M" /> <token line="14" type="PLUS" string="+" /> <token line="14" type="ID" string="c" /> <token line="14" type="LSQUAR" string="[" />
<token line="14" type="ID" string="i" /> <token line="14" type="RSQUAR" string="]" />
<token line="14" type="SEMI" string=";" /> <token line="15" type="ID" string="printf" /> <token line="15" type="LPAREN" string="(" />
<token line="15" type="PLUS" string=""" /> <token line="15" type="PLUS" string="%" /> 输出文件内容(示例2,即例程)
<?xml version="1.0" ?> <root>
<token line="1" type="VOID" string="void" />
<token line="1" type="ID" string="f1" /> <token line="1" type="LPAREN" string="(" />
<token line="1" type="INT" string="int" /> <token line="1" type="ID" string="a" /> <token line="1" type="COMMA" string="," />
<token line="1" type="INT" string="int" /> <token line="1" type="ID" string="b" /> <token line="1" type="RPAREN" string=")" />
<token line="1" type="LBRACE" string="{" />
<token line="2" type="ID" string="a" /> <token line="2" type="ASSIGN" string="=" />
<token line="2" type="NUMBER" string="1" />
<token line="2" type="SEMI" string=";" /> <token line="3" type="ID" string="b" /> <token line="3" type="ASSIGN" string="="
<token line="15" type="ID" string="d" /> <token line="15" type="SLASH" string="\" /> <token line="15" type="ID" string="n" /> <token line="15" type="PLUS" string=""" /> <token line="15" type="COMMA" string="," />
<token line="15" type="ID" string="M" /> <token line="15" type="RPAREN" string=")" />
<token line="15" type="SEMI" string=";" /> <token line="16" type="RETURN" string="return" />
<token line="16" type="NUMBER" string="0" />
<token line="16" type="SEMI" string=";" /> <token line="17" type="RBRACE" string="}" />
</root>
/>
<token line="3" type="ID" string="a" /> <token line="3" type="PLUS" string="+" /> <token line="3" type="ID" string="b" /> <token line="3" type="SEMI" string=";" /> <token line="4" type="RBRACE" string="}" />
<token line="5" type="VOID" string="void" />
<token line="5" type="ID" string="main" /> <token line="5" type="LPAREN" string="(" />
<token line="5" type="RPAREN" string=")" />
<token line="6" type="LBRACE" string="{" />
<token line="7" type="INT" string="int" /> <token line="7" type="ID" string="a" /> <token line="7" type="LSQUAR" string="[" />
<token line="7" type="NUMBER" string="100" />
<token line="7" type="RSQUAR" string="]" />
<token line="7" type="SEMI" string=";" />
<token line="8" type="INT" string="int" /> <token line="8" type="ID" string="b" /> <token line="8" type="SEMI" string=";" /> <token line="9" type="ID" string="float" /> <token line="9" type="ID" string="c" /> <token line="9" type="SEMI" string=";" /> <token line="10" type="ID" string="a" /> <token line="10" type="LSQUAR" string="[" />
<token line="10" type="ID" string="b" /> <token line="10" type="RSQUAR" string="]" />
<token line="10" type="ASSIGN" string="=" />
<token line="10" type="ID" string="a" /> <token line="10" type="SEMI" string=";" /> <token line="11" type="IF" string="if" /> <token line="11" type="LPAREN" string="(" />
<token line="11" type="ID" string="c" /> <token line="11" type="LT" string="<" />
<token line="11" type="ID" string="b" /> <token line="11" type="RPAREN" string=")" />
<token line="11" type="LBRACE" string="{" />
<token line="12" type="ID" string="f1" /> <token line="12" type="LPAREN" string="(" />
<token line="12" type="ID" string="a" /> <token line="12" type="COMMA" string="," />
<token line="12" type="ID" string="b" /> <token line="12" type="RPAREN" string=")" />
<token line="12" type="SEMI" string=";" /> <token line="13" type="RBRACE" string="}" />
<token line="14" type="RBRACE" string="}" />
</root>
五、实验总结和心得体会
本次编译原理实验进行下来,我实在是感慨颇多。 在实验前,我首先花费了约2天的课余时间进行了构思和初步设计(纸上流程图),其中花费了大约一晚的时间完成了第一版程序的输入。之后直到上机的前一刻,都还在调试和完善程序。实验中,遇到的问题有:
其一,我之前C、C++的学习并不是甚好,很多概念一知半解,特别是文件操作这方面的知识,当时不在教学范围内,课下我也一直没有涉及。这次词法分析器我用C语言实现,涉及到较多的文件操作,这使我文件操作方面的编程能力有些提高。
其二,我在大二下学期没有选修“形式语言与自动机”,现在学习编译原理颇有些迟疑。通过本次实验,我进一步坚定了学好编译原理的信心。 其三,古语云:“书到用时方恨少”,这次我是深刻体会到了这一点。学习计算机科学更需要我在平常及时补充各类知识,加强练习,不可时时事事都临时抱佛脚。 对于以上问题,我通过查阅资料和咨询老师、同学得到了解决。
对于我的程序,由于是用C语言实现的,所以较为繁琐。今后考虑使用老师推荐的lex来实现。
最后,我要感谢赵老师和实验室指导老师的教导和指正。
六、参考文献
1. Kenneth C. Louden著,冯博琴译《编译原理及实践》,机械工业出版社,
20xx年
2. Andrew W.Appel著,赵克佳等译《现代编译原理C语言描述》人民邮电
出版社,20xx年
3. 陈火旺,刘春林等,《程序设计语言编译原理》第三版,国防科大出版
社,20xx年
实验二 语法分析器
一、实验题目和要求
1、题目
编写C0语言的语法分析器的源程序并调试通过。其中语法分析程序既可以自己手动去完成,也可以利用YACC自动生成。
2、实验目的
(1)强化对系统软件综合工程实现能力的训练;
(2)加强对语法分析原理、方法和基本实现技术的理解。
二、程序设计思想及设计方案
1、语法分析器流设计思想
由于语法分析是在词法分析上做的进一步分析,所以要求在上次输出词法分析结果的同时,也需要输出语法分析的结果。该结果用xml格式的文件表示。
具体来说,我在设计程序时首先集成了一个词法分析器(参见实验一),将词法分析的结果保存在一个temp缓存区内,然后送交语法分析器。
语法分析器是一个函数,简述如下:
void Yacc() //语法分析器
{
} fprintf(fpout,"<?xml version=\"1.0\" ?>\n"); fprintf(fpout,"<root>\n"); Cur=0; ChengXu(); boddy(); fprintf(fpout,"</root>");
它调用了Chengxu()、body()两个函数,基本思路是将词法分析分析出的符号与关键字等比较,相等的话则转入相应的分支处理。如,若检测到当前字符串为“if”,则转入处理“条件语句”的部分,以确定是否有if语句的特征存在。 在实际实验中,我所设计的程序对例程可以完全正确地输出结果,对其他测试程序的分析也基本无误,体现了我的设计思路的合理性。在验收时,我首先通过了验收,这是对我极大地鼓舞。
2、简要设计方案
①将待分析程序保存在f盘根目录下的incode.txt文件中,以备词法分析器调用;
②词法分析器对待分析程序进行分析后,在f盘根目录下创建outfile.xml文件,输出词法分析结果;
③待分析代码以‘#’为结束符。
3、程序工作说明
由于语法分析是在词法分析上做的进一步分析,所以要求在上次输出词法分析结果的同时,也需要输出语法分析的结果。该结果用xml格式的文件表示,如: <root>
<Tree lineNo=’…’ nodeType=’…’ string=’…’ dataType=’…’ isArray=’…’ value='...'>
<Child>
<Tree >
…
</Tree>
</Child>
…
</Tree>
…
</root>
4、相关说明
词法分析器任务
将词法分析过程输出的记号输入到语法分析器中,按照C0的文法规则,将记号和相关数据输出到语法树中。
语法树中节点的类型
public enum NodeKind
{
FuncK,SenK,ExpK
};
public enum SenKind {
IfK,WhileK,RetureK ... }
public enum ExpKind {
SimpleK,AssignK }
语法树的节点数据结构
public class treeNode {
Struct treeNode * child[MAXCHILD]; NodeKind nodeKind; Union {
SenKind sen; ExpKind exp; }kind; Union {
TokenType op; Int val;
Char * name; }attr;
ExpType type; int lineNo; }
三、源代码
#include<stdio.h> #include<string.h> #include<ctype.h> #include<stdlib.h>
#define MAXBUF 1023
int Cur=0;
int type[MAXBUF]; int line[MAXBUF]; char *string[MAXBUF];
FILE *fpin; FILE *fpout;
int FuZhiYuJu(); int TiaoJianYuJu(); int XunHuanYuJu(); void BoolLiang(); void BiaoDaShi(); void Xiang(); void YinZi();
void YuJuChuan(); void YuJu(); void Body(); void ChengXu(); void Yacc(); int Judge(char*);
void lexscanf();
int Judge(char *p) { char
*word[]={"exp","throw","catch","try","virtual","this","delete","new","protected","private","public","class","return","while","if","else","int","void","float","string"}; int ptr,i,flag; flag=0;
for(i=0;i<18;i++) { ptr=stricmp(p,word[i]); if(ptr==0) { flag=1; return(i+1); break; } } if(flag==0) { return 0; } return 0; }
void lexscanf() { char arr[MAXBUF]; int i=0; int j=0; char ch; int lineo=1; //fprintf(fpout,"<?xml version=\"1.0\" ?>\n"); //fprintf(fpout,"<root>\n"); while(1) { fscanf(fpin,"%c",&ch); //从输入文件中读入字符 if(ch==' '||ch=='\t') //清除空白 ; else if(ch=='\n') //识别回车,
行数+1 lineo++; else if(isdigit(ch)) //如果输入字符为数字 { while(isdigit(ch)) //一直读字符,直到读入的字符不是数字 { arr[j]=ch; j++; fscanf(fpin,"%c",&ch); } fseek(fpin,-1L,SEEK_CUR); char*
temp1=(char*)malloc(j+1); memcpy(temp1,arr,j); //将缓冲区的内容拷贝到temp1中去 temp1[j]='\0'; j=0; type[Cur]=44; line[Cur]=lineo; string[Cur]=temp1; Cur++; } else if(isalpha(ch)) //如果读入的字符为字母 { while(isalpha(ch)||isdigit(ch)) { arr[i]=ch; i++; fscanf(fpin,"%c",&ch); } fseek(fpin,-1L,SEEK_CUR); char* temp=(char*)malloc(i+1); memcpy(temp,arr,i); temp[i]='\0'; i=0; if(Judge(temp)) //如果读入的字母能与关键字相等 {
type[Cur]=Judge(temp); line[Cur]=lineo; string[Cur]=temp; Cur++; } else { type[Cur]=43; line[Cur]=lineo; string[Cur]=temp; Cur++; } } else if(ch=='<') //处理二字符运算符<= { fscanf(fpin,"%c",&ch); if(ch=='=') { type[Cur]=29; line[Cur]=lineo; string[Cur]="LTEQ"; Cur++; } else
if(isdigit(ch)||isalpha(ch)||ch==' ') { fseek(fpin,-1L,SEEK_CUR); type[Cur]=23; line[Cur]=lineo; string[Cur]="LT"; Cur++; } } else if(ch=='>') //处理二字符运算符>= { fscanf(fpin,"%c",&ch); if(ch=='=') {
type[Cur]=26; line[Cur]=lineo; string[Cur]="GTEQ";
Cur++; } else
if(isdigit(ch)||isalpha(ch)||ch==' ') { fseek(fpin,-1L,SEEK_CUR); type[Cur]=25; line[Cur]=lineo; string[Cur]="GT"; Cur++; } } else if(ch=='=') //处理二字符运算符== { fscanf(fpin,"%c",&ch); if(ch=='=') { type[Cur]=27; line[Cur]=lineo; string[Cur]="EQ"; Cur++; } else
if(isdigit(ch)||isalpha(ch)||ch==' ') { fseek(fpin,-1L,SEEK_CUR); type[Cur]=29; line[Cur]=lineo; string[Cur]="ASSIGN"; Cur++; } } else if(ch=='/') { fscanf(fpin, "%c",&ch); if(ch=='*') { while(1){ fscanf(fpin,"%c",&ch); while(ch!='*')
{
fscanf(fpin,"%c",&ch);
}
fscanf(fpin,"%c",&ch); string[Cur]="SLASH"; Cur++; continue; } if(ch==';') if(ch=='/')
break;
}
}
}
else if(ch=='!') //处理二字符运算
符!=
{
fscanf(fpin,"%c",&ch);
if(ch=='=')
{
type[Cur]=28;
line[Cur]=lineo;
string[Cur]="NEQ";
Cur++;
}
}
else //处理各种单字符运算符
{
if(ch=='+')
{
type[Cur]=19;
line[Cur]=lineo;
string[Cur]="+";
Cur++;
continue;
}
if(ch=='-')
{
type[Cur]=20;
line[Cur]=lineo;
string[Cur]="-";
Cur++;
continue;
}
if(ch=='\\')
{
type[Cur]=22;
line[Cur]=lineo; { type[Cur]=30; line[Cur]=lineo; string[Cur]="SEMI"; Cur++; continue; } if(ch==',') { type[Cur]=31; line[Cur]=lineo; string[Cur]="COMMA"; Cur++; continue; } if(ch==':') { type[Cur]=32; line[Cur]=lineo; string[Cur]="COLON"; Cur++; continue; } if(ch=='.') { type[Cur]=33; line[Cur]=lineo; string[Cur]="DOT"; Cur++; continue; } if(ch=='~') { type[Cur]=34; line[Cur]=lineo; string[Cur]="WAVE"; Cur++; continue; }
if(ch=='(') { type[Cur]=35; line[Cur]=lineo; string[Cur]="LPAREN"; Cur++; continue; }
if(ch==')') { type[Cur]=36; line[Cur]=lineo; string[Cur]="RPAREN"; Cur++; continue; }
if(ch=='[') { type[Cur]=37; line[Cur]=lineo; string[Cur]="LSQUAR"; Cur++; continue; }
if(ch==']') { type[Cur]=38; line[Cur]=lineo; string[Cur]="RSQUAR"; Cur++; continue; }
if(ch=='{') { type[Cur]=39; line[Cur]=lineo; string[Cur]="LBRACE"; Cur++; continue; }
if(ch=='}') { type[Cur]=40; line[Cur]=lineo; string[Cur]="RBRACE";
Cur++; continue; } if(ch=='*') { type[Cur]=21; line[Cur]=lineo; string[Cur]="STAR"; Cur++; continue; } if(ch=='#')//终止符 { type[Cur]=45; line[Cur]=lineo; string[Cur]="STOP"; Cur++; break; } } } }
int FuZhiYuJu() //赋值语句 { if(type[Cur]=!43) { printf("语法错误,缺少标示符。错误行号%d\n",line[Cur]); } else fprintf(fpout,"<tree line=\"%d\" nodetype=\"ASSIGN\" nodestring=\"=\" datatype=\"none\"/>\n",line[Cur]); fprintf(fpout,"<child>\n"); fprintf(fpout,"<tree line=\"%d\" nodetype=\"VarDecl\" nodestring=\"%s\" datatype=\"int\"/>\n",line[Cur],string[Cur]); fprintf(fpout,"</tree>\n"); fprintf(fpout,"</child>\n"); Cur++; if(type[Cur]!=29) {
printf("语法错误,缺少=。错误行号%d\n",line[Cur]); } Cur++; BiaoDaShi(); fprintf(fpout,"</tree>\n"); return 1; }
int TiaoJianYuJu() //条件语句 { if(type[Cur]!=15) { printf("语法错误,缺少if。错误行号%d\n",line[Cur]); } else fprintf(fpout,"<tree line=\"%d\" nodetype=\"IFStm\" nodestring=\"if\" datatype=\"none\"/>\n",line[Cur]); Cur++; if(type[Cur]!=35) { printf("语法错误,缺少(。错误行号%d\n",line[Cur]); } Cur++;
fprintf(fpout,"<child>\n"); BiaoDaShi(); fprintf(fpout,"</child>\n"); if(type[Cur]!=36) { printf("语法错误,缺少)。错误行号%d\n",line[Cur]); } Body(); if(type[Cur]!=16) { fprintf(fpout,"</tree>\n"); return 0; } Body();
fprintf(fpout,"</tree>\n"); return 1; } int XunHuanYuJu() //循环语句 { if(type[Cur]!=14) { printf("语法错误,缺少while。错误行号%d\n",line[Cur]); //return 0; } else
fprintf(fpout,"<tree line=\"%d\" notetype=\"SENTENCES\" notestring=\"none\"
datatype=\"none\"/>\n",line[Cur],string[Cur]); fprintf(fpout,"<child>\n"); fprintf(fpout,"<tree line=\"%d\" nodetype=\"WhileStm\" nodestring=\"while\" datatype=\"none\"/>\n",line[Cur]); Cur++;
if(type[Cur]!=35) { printf("语法错误,缺少(。错误行号%d\n",line[Cur]); } Cur++; fprintf(fpout,"<child>\n"); BiaoDaShi(); fprintf(fpout,"</child>\n"); if(type[Cur]!=36) { printf("语法错误,缺少)。错误行号%d\n",line[Cur]); } Body(); fprintf(fpout,"</tree>\n"); return 1; }
int DiaoYongYuJu()//函数调用语句 { fprintf(fpout,"<tree line=\"%d\" nodetype=\"FunCall\" nodestring=\"%s\"
datatype=\"none\"/>\n",line[Cur],string[Cur]); Cur++; Cur++; fprintf(fpout,"<child>\n");
while(type[Cur]!=36) { if(type[Cur]==43||type[Cur]==44) { fprintf(fpout,"<tree line=\"%d\" nodetype=\"Para\" nodestring=\"%s\"
datatype=\"int\"/>\n",line[Cur],string[Cur]); } Cur++; if(type[Cur]==31) { Cur++; } else if(type[Cur]!=36) { printf("语法错误,没有函数调用。错误行号%d\n",line[Cur]); } } Cur++; fprintf(fpout,"</child>\n"); fprintf(fpout,"</tree>\n"); return 1; }
int ReturnYuJu() { fprintf(fpout,"<tree line=\"%d\"
nodetype=\"ReturnStm\" nodestring=\"return\" datatype=\"none\"/>\n",line[Cur]); Cur++; fprintf(fpout,"<child>\n"); if(type[Cur]==44) { fprintf(fpout,"<tree line=\"%d\" nodetype=\"Number\" nodestring=\"%s\" datatype=\"INT\"/>\n",line[Cur],string[Cur]); } else if(type[Cur]==43) { fprintf(fpout,"<tree line=\"%d\" nodetype=\"Number\" nodestring=\"%s\" datatype=\"INT\"/>\n",line[Cur],string[Cur]); } else {
printf("语法错误,返回值类型错误。错误行号%d\n",line[Cur]); } Cur++; fprintf(fpout,"</child>\n"); fprintf(fpout,"</tree>\n"); return 1; }
void BiaoDaShi() //表达式 {
Xiang(); if(type[Cur]==30||type[Cur]==36) { return; } else { if(type[Cur-1]==19) fprintf(fpout,"<tree line=\"%d\" nodetype=\"PLUS\" nodestring=\"+\" datatype=\"none\"/>\n",line[Cur]); else if(type[Cur-1]==20) fprintf(fpout,"<tree line=\"%d\" nodetype=\"SUB\" nodestring=\"-\" datatype=\"none\"/>\n",line[Cur]); else if(type[Cur-1]==23) fprintf(fpout,"<tree line=\"%d\" nodetype=\"LT\" nodestring=\"<\" datatype=\"none\"/>\n",line[Cur]); else if(type[Cur-1]==24) fprintf(fpout,"<tree line=\"%d\" nodetype=\"LTEQ\" nodestring=\"<=\" datatype=\"none\"/>\n",line[Cur]); else if(type[Cur-1]==25) fprintf(fpout,"<tree line=\"%d\" nodetype=\"GT\" nodestring=\">\" datatype=\"none\"/>\n",line[Cur]); else if(type[Cur-1]==26) fprintf(fpout,"<tree line=\"%d\" nodetype=\"GTEQ\" nodestring=\">=\" datatype=\"none\"/>=\n",line[Cur]); else if(type[Cur-1]==27) fprintf(fpout,"<tree line=\"%d\"
nodetype=\"EQ\" nodestring=\"==\" datatype=\"none\"/>\n",line[Cur]); else if(type[Cur-1]==28) fprintf(fpout,"<tree line=\"%d\" nodetype=\"NEQ\" nodestring=\"!=\" datatype=\"none\"/>\n",line[Cur]); BiaoDaShi(); fprintf(fpout,"</tree>\n"); } }
void Xiang() //项数 { fprintf(fpout,"<child>\n"); YinZi(); while(type[Cur]==21||type[Cur]==22) { Cur++; YinZi(); } fprintf(fpout,"</child>\n"); if(type[Cur]==19||type[Cur]==23||type[Cur]==24||type[Cur]==25||type[Cur]==26||type[Cur]==27||type[Cur]==28||type[Cur]==20) { Cur++; } }
void YinZi() //因子 { switch(type[Cur]) { case 35: Cur++; BiaoDaShi(); Cur++; break; case 43: if(type[Cur+1]==35) { DiaoYongYuJu(); } else { fprintf(fpout,"<tree line=\"%d\" nodetype=\"VarID\" nodestring=\"%s\"
datatype=\"none\"/>\n",line[Cur],string[Cur]); Cur++; } break; case 44: fprintf(fpout,"<tree line=\"%d\" nodetype=\"NUMBER\" nodestring=\"%s\" datatype=\"none\"/>\n",line[Cur],string[Cur]); Cur++; break; default: printf("语法错误,缺少因子。错误行号%d\n",line[Cur]); } }
void YuJuChuan() //语句串 { YuJu(); while(type[Cur]==30||(type[Cur-1]==40&&(((type[Cur]==43||type[Cur]==15)||type[Cur]==14))||type[Cur]==13)) { if(type[Cur-1]==40) { if(type[Cur]==43||type[Cur]==15) { Cur--; } else
if(type[Cur]==14||type[Cur]==13) { Cur--; } } Cur++; YuJu(); } }
void YuJu() //语句 { switch(type[Cur]) {
case 43: if(type[Cur+1]==35) { if(DiaoYongYuJu()==1) { printf("函数调用语句\n"); } } else { if(FuZhiYuJu()==1) { printf("变量声明\n"); } } break; case 15: if(TiaoJianYuJu()==0) { printf("if then 分支语句\n",line[Cur]); } else { printf("if then else 分支语句\n"); } break; case 14: if(XunHuanYuJu()==1) { printf("while do 循环语句\n"); } break; case 17: Cur++; fprintf(fpout,"<tree line=\"%d\" notetype=\"VarDecl\" notestring=\"%s\"
datatype=\"INT\" />\n",line[Cur],string[Cur]); Cur++; break; case 13: if(ReturnYuJu()==1) {
printf("Return语句\n"); } break; /*case 19: if(type[Cur+1]==19) { fprintf(fpout,"<tree line=\"%d\" notetype=\"VarDecl\" notestring=\"%s\"
vartype=\"INT\" />\n",line[Cur],string[Cur]); } break;*/ case 40: break; default: Cur++; break; //printf("语法错误,缺少语句。错误行号%d\n",line[Cur]);
fprintf(fpout,"<tree line=\"%d\" notetype=\"VarDecl\" notestring=\"%s\"
datatype=\"INT\" />\n",line[Cur],string[Cur]); } }
void Body() //程序体 { Cur++; switch(type[Cur]) { case 39: break; case 19:
fprintf(fpout,"<tree line=\"%d\" notetype=\"SENTENCES\" notestring=\"none\"
datatype=\"none\"/>\n",line[Cur],string[Cur]); fprintf(fpout,"<child>\n"); fprintf(fpout,"<tree line=\"%d\" notetype=\"EXPRESSION\" notestring=\"++a\"
datatype=\"none\"/>\n",line[Cur],string[Cur]); break; default: Cur++;
break; //printf("语法错误,缺少{。错误行号%d\n",line[Cur]); } Cur++; if(type[Cur]!=40) { YuJuChuan(); } switch(type[Cur]) { case 40: break; default: Cur++; break; //printf("语法错误,缺少}。错误行号%d\n",line[Cur]); } Cur++; }
void boddy() { fprintf(fpout,"</child>\n"); fprintf(fpout,"</tree>\n"); fprintf(fpout,"</child>\n"); fprintf(fpout,"</tree>\n"); fprintf(fpout,"</child>\n"); fprintf(fpout,"</tree>\n"); }
void ChengXu() //程序 { switch(type[Cur]) { case 17:
//fprintf(fpout,"<tree line=\"%d\" notetype=\"VarDecl\" notestring=\"%s\"
datatype=\"INT\" />\n",line[Cur],string[Cur]); break; case 18: break;
default: break; //printf("语法错误,缺少类型标示符。错误行号%d\n",line[Cur]); } Cur++; switch(type[Cur]) { case 43: break; default: printf("语法错误,缺少标示符。错误行号%d\n",line[Cur]); } Cur++; switch(type[Cur]) { case 30: //如果是;则说明是变量声明 if(type[Cur-2]==17) fprintf(fpout,"<tree line=\"%d\" notetype=\"VarDecl\" notestring=\"%s\"
datatype=\"INT\"/>\n",line[Cur],string[Cur-1]); else fprintf(fpout,"<tree line=\"%d\" notetype=\"VarDecl\" notestring=\"%s\"
datatype=\"VOID\"/>\n",line[Cur],string[Cur-1]); break; case 35://如果是(,则说明是函数声明 if(type[Cur-2]==17) { fprintf(fpout,"<tree line=\"%d\" notetype=\"FunDecl\" notestring=\"%s\"
datatype=\"INT\"/>\n",line[Cur],string[Cur-1]); Cur++; if(type[Cur]!=36) { fprintf(fpout,"<child>\n");
while(type[Cur]!=36) { if(type[Cur]==17) { Cur++; fprintf(fpout,"<tree line=\"%d\" nodetype=\"Para\" nodestring=\"%s\"
datatype=\"int\"/>\n",line[Cur],string[Cur]); } Cur++; if(type[Cur]==31) { Cur++; } else if(type[Cur]!=36) { printf("语法错误,函数参数声明没有,。错误行号%d\n",line[Cur]); } } fprintf(fpout,"</child>\n"); } fprintf(fpout,"<child>\n"); Body(); fprintf(fpout,"</child>\n"); } else { fprintf(fpout,"<tree line=\"%d\" notetype=\"FunDecl\" notestring=\"%s\"
datatype=\"VOID\"/>\n",line[Cur],string[Cur-1]); Cur++; if(type[Cur]!=36) { fprintf(fpout,"<child>\n"); while(type[Cur]!=36) { if(type[Cur]==17) { Cur++; fprintf(fpout,"<tree
line=\"%d\" nodetype=\"Para\" nodestring=\"%s\"
datatype=\"int\"/>\n",line[Cur],string[Cur]); } Cur++; if(type[Cur]==31) { Cur++; } else if(type[Cur]!=36) { printf("语法错误,函数参数声明没有,。错误行号%d\n",line[Cur]); } } fprintf(fpout,"</child>\n"); } fprintf(fpout,"<child>\n"); Body(); fprintf(fpout,"</child>\n"); } break; default: printf("语法错误,缺少; 。错误行号%d\n",line[Cur]); } fprintf(fpout,"</tree>\n"); //while(type[Cur]!=45) //{ //if(type[Cur]==17||type[Cur]==18) //ChengXu(); //else //{ //printf("语法错误,缺少类型标示符。错误行号%d\n",line[Cur]); //break; //} //} }
void Yacc() //语法分析器 { fprintf(fpout,"<?xml
version=\"1.0\" ?>\n"); fprintf(fpout,"<root>\n"); Cur=0; ChengXu(); boddy(); fprintf(fpout,"</root>"); }
void main() {
printf("Try your best to find the location of result!\n"); if((fpin=fopen("f:\\incode1.txt","rt"))==NULL) {
printf("Cannot open file!"); exit(1); } if((fpout=fopen("f:\\outfile.xml","wt"))==NULL) { printf("Cannot open file!"); exit(1); } lexscanf(); Yacc(); fclose(fpin); fclose(fpout); system("pause"); }
四、运行结果及分析
输入文件内容(示例)
void main() {
int a=0; int b=2; while(a==b) ++a; } #
输入文件内容(示例2,即例程)
<?xml version="1.0" ?> <root>
<tree line="1" notetype="FunDecl" notestring="main" datatype="VOID"/> <child>
<tree line="3" nodetype="ASSIGN" nodestring="=" datatype="none"/> <child>
<tree line="3" nodetype="VarDecl" nodestring="a" datatype="int"/> </tree> </child> <child>
<tree line="3" nodetype="NUMBER" nodestring="0" datatype="none"/> </child> </tree>
<tree line="4" nodetype="ASSIGN" nodestring="=" datatype="none"/> <child>
<tree line="4" nodetype="VarDecl" nodestring="b" datatype="int"/> </tree>
</child>
<child>
<tree line="4" nodetype="NUMBER" nodestring="2" datatype="none"/> </child>
</tree>
<tree line="5" notetype="SENTENCES" notestring="none" datatype="none"/> <child>
<tree line="5" nodetype="WhileStm" nodestring="while" datatype="none"/> <child>
<child>
<tree line="5" nodetype="VarID" nodestring="a" datatype="none"/> </child>
<tree line="5" nodetype="EQ" nodestring="==" datatype="none"/> <child>
<tree line="5" nodetype="VarID" nodestring="b" datatype="none"/> </child>
</tree>
</child>
<tree line="6" notetype="SENTENCES" notestring="none" datatype="none"/> <child>
<tree line="6" notetype="EXPRESSION" notestring="++a" datatype="none"/> </tree>
</child>
</tree>
</child>
</tree>
</child>
</tree>
</child>
</tree>
</root>
五、实验总结和心得体会
在实验前,我首先花费了约10天的课余时间进行了构思和初步设计(纸上流程图),其中花费了大约2天的时间完成了第一版程序的输入。之后直到上机的前一刻,都还在调试和完善程序。
值得高兴的是,实验验收时,我所实现的语法分析器首先通过了验收。这对我是一个极大的鼓舞。
实验中,遇到的问题有:
其一,我之前C、C++的学习并不是甚好,很多概念一知半解,特别是文件操作这方面的知识,当时不在教学范围内,课下我也一直没有涉及。这次词法分析器我用C语言实现,涉及到较多的文件操作,这使我文件操作方面的编程能力有些提高。
其二,语法分析却是要比词法分析困难得多。尤其是利用C语言实现C0文法的语法分析,在编程过程中实在有千头万绪、无从下手之感。程序编写下来,却是是对自身各方面的一次磨砺。
其三,我在大二下学期没有选修“形式语言与自动机”,现在学习编译原理颇有些迟疑。通过本次实验,我进一步坚定了学好编译原理的信心。
其四,古语云:“书到用时方恨少”,这次我是深刻体会到了这一点。学习计算机科学更需要我在平常及时补充各类知识,加强练习,不可时时事事都临时抱佛脚。 对于以上问题,我通过查阅资料和咨询老师、同学得到了解决。
其五,我本想用自下而上的LR分析法来完成本次实验,语法分析器的输入也希望有词法分析器完成,即实验一中的输出文件作为本次实验的输入。但经过实践,我发现C0文法似乎有一些移进-规约冲突难以解决,故而很遗憾地,我最终还是采用了自上而下的分析法,在语法分析器内集成了词法分析器。但自下而上的分
析器我也进行了尝试,并做出了一个程序(见附录)。
对于我的程序,由于是用C语言实现的,所以较为繁琐。今后考虑使用老师推荐的lex来实现。
最后,我要感谢赵老师和实验室指导老师的教导和指正。
六、附录
曾尝试设计的语法分析器代码(简要)
void readsource() {
int i=0;
fpin=fopen("d:\\output.xml","r"); if(fpin==NULL) {
printf("can't open file:output.txt\n"); exit(0); }
fscanf(fpin,"<?xml
version=\"1.0\"?>\n<root>\n"); for(i=0;i<=MAXNUM;i++) {
fscanf(fpin,"<token line=\"%d\" type=\"%[^\"]\" string=\"%[^\"]\"
/>\n",&words[i].line,&words[i].type,&words[i].string);
if(words[i].line==0) {
fclose(fpin); return; } } }
void scan(tree *root) { int i=0;
if(root!=NULL) {
if(root->child[1]!=NULL) {
if(!strcmp(root->nodetype,"FunDecl")) {
fprintf(fpout,"<tree line=\"%d\" nodetype=\"%s\" nodestring=\"%s\"
rettype=\"%s\">\n",root->treeline,root->nodet
ype,root->nodestring,root->rettype); } else {
fprintf(fpout,"<tree line=\"%d\" nodetype=\"%s\"
nodestring=\"%s\">\n",root->treeline,root->nodetype,root->nodestring); }
while(root->child[i]!=NULL) {
fprintf(fpout,"<child>\n"); scan(root->child[i++]);
fprintf(fpout,"</child>\n"); }
fprintf(fpout,"</tree>\n"); } else {
if(!strcmp(root->nodetype,"Para")) fprintf(fpout,"<tree line=\"%d\" nodetype=\"%s\" nodestring=\"%s\"
vartype=\"%s\"/>\n",root->treeline,root->nodetype,root->nodestring,root->vartype); else
if(!strcmp(root->nodetype,"VarDecl")) fprintf(fpout,"<tree line=\"%d\" nodetype=\"%s\" nodestring=\"%s\" vartype=\"%s\" modifier=\"%s\"
isArray=\"%d\"/>\n",root->treeline,root->nodetype,root->nodestring,root->vartype,root->modifier,root->isarray); else
fprintf(fpout,"<tree
line=\"%d\" nodetype=\"%s\"
nodestring=\"%s\"/>\n",root->treeline,root->n
odetype,root->nodestring); } } }
由以上程序可以看到,该语法分析器的设计目的是输入词法分析器输出文件,采用LR分析法进行分析。
七、参考文献
1. Kenneth C. Louden著,冯博琴译《编译原理及实践》,机械工业出版社,
20xx年
2. Andrew W.Appel著,赵克佳等译《现代编译原理C语言描述》人民邮电
出版社,20xx年
3. 陈火旺,刘春林等,《程序设计语言编译原理》第三版,国防科大出版
社,20xx年