编译原理实验报告
PL/0 语言编译器分析
词法分析实验
递归下降语法分析实验
LL(1)分析法语法分析实验
教师:
姓名:
班级:
学号:
PL/0 语言编译器分析实验报告
一、实验目的
通过阅读与解析一个实际编译器(PL/0语言编译器)的源代码, 加深对编译阶段(包括词法分析、语法分析、语义分析、中间代 码生成等)和编译系统软件结构的理解,并达到提高学生学习兴趣的目的。
二、实验要求
(1)要求掌握基本的程序设计技巧(C语言)和阅读较大规模程序 源代码的能力;
(2)理解并掌握编译过程的逻辑阶段及各逻辑阶段的功能;
(3)要求能把握整个系统(PL/0语言编译器)的体系结构,各功能 模块的功能,各模块之间的接口;
(4)要求能总结出实现编译过程各逻辑阶段功能采用的具体算法与技术。
三、实验步骤
(1) 根据PL/0语言的语法图,理解PL/0语言各级语法单位的结构,掌握PL/0语言合法程序的结构;
(2)从总体上分析整个系统的体系结构、各功能模块的功能、各模块之间的调用关系、各模块之间的接口;
(3)详细分析各子程序和函数的代码结构、程序流程、采用的主要算法及实现的功能;
(4)撰写分析报告,主要内容包括系统结构框图、模块接口、主要算法、各模块程序流程图等。
四、报告内容
1、 PL/0 语言语法的 BNF 表示-1,对语法描述图的解析
<程序> → <程序体>.
<程序体> → [<常量说明部分>][变量说明部分>][<过程说明部分>]<语句>
<常量说明部分> → const <常量定义>{,<常量定义>};
<常量定义> → <标识符>=<无符号整数>
<无符号整数> → <数字>{<数字>}
<变量说明部分> → var <标识符>{,<标识符>};
<标识符> → <字母>{<字母>|<数字>}
<过程说明部分> → <过程首部><程序体>{;<过程说明部分>};
<过程首部> → procedure <标识符>;
<语句> → <赋值语句>|<条件语句>|<当型循环语句>|<过程调用语句>|
<复合语句>
<赋值语句> → <标识符>:=<表达式>
<复合语句> → begin <语句序列> end
<语句序列> → <语句>{;<语句>}
<条件> → <表达式><关系运算符><表达式>| odd <表达式>
<表达式> → [+|-]<项>{<加法运算符><项>}
<项> → <因子>{<乘法运算符><因子>}
<因子> → <标识符>|<无符号整数>|'('<表达式>')'
<加法运算符> → +|-
<乘法运算符> → *|/
<关系运算符> → =|<>|<|<=|>|>=
<条件语句> → if <条件> then <语句>
<过程调用语句> → call <标识符>
<当型循环语句> → while <条件> do <语句>
<字母> → a|b|...|x|y|z
<数字> → 0|1|2|...|8|9
2、PL/0编译程序的总体设计
? 其编译过程采用一趟扫描方式
? 以语法、语义分析程序为核心
? 词法分析程序和代码生成程序都作为一个过程,
? 当语法分析需要读单词时就调用词法分析程序,
? 而当语法、语义分析正确,
? 需要生成相应的目标代码时,则调用代码生成程序。
? 表格管理程序实现变量,
? 常量和过程标识符的信息的登录与查找。
? 出错处理程序,
? 对词法和语法、语义分析遇到的错误给出在源程序中出错的位置和与错误性质有关的编号,并进行错误恢复。
3、PL/0编译程序结构
 4、编译程序总体流程图
4、编译程序总体流程图
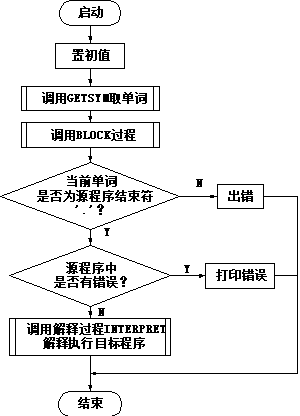
4、详细分析
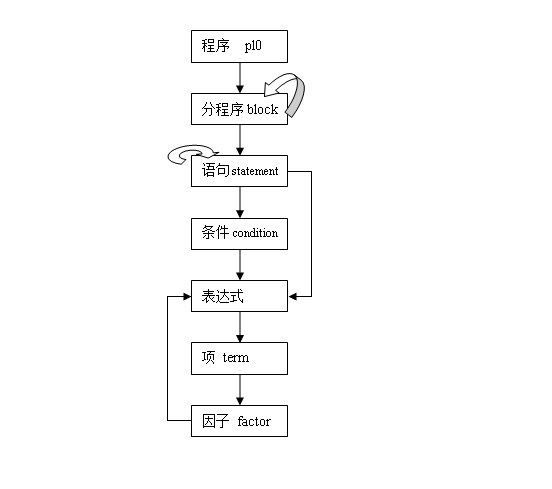
4.1 主要函数功能

4.2 语法调用关系图
Pl/0词法分析程序Getsym
识别的单词: (类别,值)
保留字:如:BEGIN、 END、 IF、 THEN等
运算符: 如:+、-、*、/、:=、#、>=、<=等
标识符: 用户定义的变量名、常数名、过程名
常数: 如:10、25、100等整数
界符: 如:‘,’、‘.’ 、‘;’ 、‘(’ 、‘)’等
Getsym用到三个单元:
SYM:存放单词类别
ID:存放标识符的值
NUM:存放整数的值
词法分析过程GETSYM
所要完成的任务:
滤空格
识别保留字
识别标识符
拼数
识别单字符单词(<,>等)
拼双字符单词(<=,<>等)
输出源程序
读字符子程序(getch)
PL/0编译程序语法分析的设计与实现
自顶向下的语法分析
递归子程序法:对于每个非终结符,编写一个子程序,由该子程序负责识别该语法单位是否正确。
递归子程序法
递归子程序法:对应每个非终结符语法单元,,编一个独立的处理过程(或子程序)。语法分析从读入第一个单词开始,由非终结符<程序>(即开始符)出发,沿语法描述图箭头所指出的方向进行分析。当遇到非终结符时,则调用相应的处理过程,从语法描述图看,也就进入了一个语法单元,再沿当前所进入的语法单元所指箭头方向继续进行分析。当遇到描述图中是终结符时,则判断当前读入的单词是否与图中的终结符相匹配,若匹配,再读取下一个单词继续分析。遇到分支点时,将当前的单词与分支点上多个终结符逐个相比较,若都不匹配时可能是进入下一个非终结符语法单位或是出错。
〈表达式〉的递归子程序实现
procedure expr;
begin
if sym in [ plus, minus ] then
begin getsym; term;
end
else term;
while sym in [plus, minus] do
begin
getsym; term;
end
end;
〈因子〉∷=〈标识符〉|〈无符号整数〉|‘(’〈表达式〉‘)’
〈因子〉的递归子程序实现
procedure factor;
begin
if sym <> ident then
begin
if sym <> number then
begin
if sym = ‘(‘ then
begin
getsym;
expr;
if sym = ‘)’ then
getsym
else error
end
else error
end
else getsym
end
else getsym
end;
说明部分的分析与处理
对每个过程(含主程序)说明的对象(变量,常量和过程)造符号表, 登录标识符的属性。标识符的属性:种类,所在层次,值和分配的相对位置。登录信息由ENTER过程完成。
常量定义语句的处理语法:<常量说明部分>: := const <常量定义>{, <常量定义>};
<常量定义>: := <标识符>=<无符号整数>
<无符号整数>: := <数字>{ <数字>}
if sym = constsym then
begin
getsym; (* 获取下一个token,正常应为用作常量名的标识符 *)
repeat (* 反复进行常量声明 *)
constdeclaration; (* 声明以当前token为标识符的常量 *)
while sym = comma do (* 如果遇到了逗号则反复声明下一常量*)
begin
getsym; (* 获取下一个token,这里正好应该是标识符 *)
constdeclaration (* 声明以当前token为标识符的常量 *)
end;
if sym = semicolon then (* 如果常量声明结束,应遇到分号 *)
getsym (* 获取下一个token,为下一轮循环做好准备 *)
else
error(5) (*提示5号错误 *)
until sym <> ident (* 如果遇到非标识符,则常量声明结束 *)
end;
常量说明处理
procedure constdeclaration;
begin
if sym = ident then
begin
getsym;
if sym in [eql, becomes] then (* 如果是等号或赋值号 *)
if sym = becomes then (* 如果是赋值号(常量生明中应该是等号) *)
error(1); (* 提示1号错误 *)
getsym; (* 获取下一个token,等号或赋值号后应接上数字 *)
if sym = number then (* 如果的确是数字 *)
begin
enter(constant); (* 把这个常量登陆到符号表 *)
getsym (* 获取下一个token,为后面作准备 *)
end
else error(2) (* 如果等号后接的不是数字,提示2号错误 *)
else error(3)(* 如常量标识符后不是等号或赋值号,提示3号错误 *)
end
else error(4)
end(* constdeclaration *);
变量定义语句的处理语法:<变量说明部分>: := var <标识符>{, <标识符>};
if sym=varsym then
begin
getsym;
repeat
vardeclaration;(*变量说明处理*)
while sym=comma do
begin
getsym;
vardeclaration
end;
if sym=semicolon then
getsym
else error(5)
until sym<>ident;
end;
变量说明处理procedure ardeclaration;
begin
if sym=ident then
begin
enter(variable);
getsym
end
else error(4)
end(*vardeclaration*);
过程定义语句的处理程序:
while sym = procsym do (* 循环声明各子过程 *)
begin
getsym; (* 获取下一个token,此处正常应为作为过程名的标识符 *)
if sym = ident then (* 如果token确为标识符 *)
begin
enter(procedur); (* 把这个过程登录到名字表中 *)
getsym (* 获取下一个token,正常情况应为分号 *)
end
else
error(4); (* 否则提示4号错误 *)
if sym = semicolon then (* 如果当前token为分号 *)
getsym (* 获取下一个token,准备进行语法分析的递归调用 *)
else
error(5); (* 否则提示5号错误 *)
目标代码结构和代码生成
代码生成代码生成是由过程GEN完成。GEN有3个参数,分别代表目标代码的功能码,层差和位移量。
PL/0编译程序的语法错误处理
在进入某个语法单位时,调用TEST,检查当前符号是否属于该语法单位的开始符号集合。若不属于,则滤去开始符号和后继符号集合外的所有符号。
在语法单位分析结束时,调用TEST,检查当前符号是否属于调用该语法单位时应有的后继符号集合。若不属于,则滤去后继符号和开始符号集合外的所有符号。
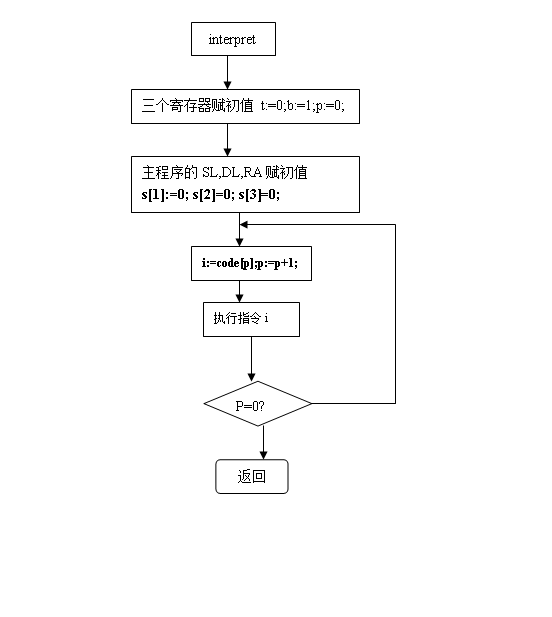
解释执行的流程图
词法分析实验报告
一 、实验目的
1、加深对词法分析理论的理解,培养动手实践的能力。词法分析的功能:扫描源程序字符流,按照源语言的词法规则识别出各类单词版本号,并产生用于语法分析的符号序列,即将字符串源程序转换成符号串源程序.
2、巩固和加深对线性表、栈、队列、字符串、树、图、查找、排序等理论知识的理解。
3、掌握现实复杂问题的分析建模和解决方法(包括问题描述、系统分析、设计建模、代码实现、结果分析等)。
4、提高利用计算机分析解决综合性实际问题的基本能力。
二 、实验内容与设计思想
内容: 编写一个词法分析程序,并进行简单的词法进行分析.
设计思想: 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值,并促留在文件中。
三、详细设计
#include <stdio.h>
#include <conio.h>
#include <string.h>
#include <stdlib.h>
#define BAOLZ 1
#define BIAOSF 2
#define CHANGS 3
#define YUNSF 4
#define FENGF 5
char * baoliuzi[10]={"if","int","for","while","do","return","break","continue","main","void"};
char * yunsuanfu[5]={"+","-","*","/","="};
char * fengefu[6]={",",";","{","}","(",")"};
//函数声明
int isnumber(char ch);
int iszimu(char ch);
void scanner();
void main() //主函数
{
scanner();
}
///*************************************************************///
void scanner()//词法分析程序算法
{ int i=0;
char ch;
FILE * fpin;
FILE * fpout;
//文件操作
if ((fpin=fopen("shiyan1in.txt","r"))==NULL)
{ printf ("cannot open the file");
}
if((fpout=fopen("shiyan1out.txt","w+"))==NULL)
{ printf ("cannot open the file");
} //获取文件的第一个字符
ch=fgetc(fpin); //读取近来的字符进行判断
while(ch!=EOF)
{ int a,b;
char buffer[20]={'\0'}; //暂时存储从文件读来的字符及其对每次buffer都进行清空
if(ch=='10'||ch=='13'||ch=='09'||ch==' ') //对空格进行过滤
ch=fgetc(fpin);
a=iszimu(ch); //a表示字母函数的返回值
b=isnumber(ch); //b表示数字函数的返回值
//****************************************************************
//判断标识符和保留字
if(a==1)
{ int r1;
int j=0;
while(a)
{ int m,n;
m=iszimu(ch); // m表示字母函数的返回值
n=isnumber(ch); //n表示数字函数的返回值
if(m==1||n==1)
{ buffer[j]=ch;
ch=fgetc(fpin);
j++;
}
else break;
}
for(i=0;i<10;i++)
{
r1=strcmp(baoliuzi[i],buffer);
if(r1==0)
{
printf("%s是保留字\n",buffer); //输出到界面上
fprintf(fpout,"(%i,\"%s\")\n",BAOLZ,buffer); ///输出到文件
break;
}
}
if(r1!=0)
{
printf("%s是字符\n",buffer);
fprintf(fpout,"(%i,\"%s\")\n",BIAOSF,buffer);
}
continue; //接受下一个字符串
}
//*****************************************************************
//判断是数字 b表示数字函数的返回值
else if(b==1)
{
int j=0;
while(b)
{
int m,n;
m=iszimu(ch);
n=isnumber(ch);
if(n==1)
{ buffer[j]=ch;
ch=fgetc(fpin);
j++;
}
else break;
}
printf("%s是数字\n",buffer);
fprintf(fpout,"(%i,\"%s\")\n",CHANGS,buffer); ///输出到文件
continue;
}
//******************************************************************
//判断是运算符或者是界符
else
int r1,r2;
buffer[0]=ch;
for(i=0;i<5;i++)
r1=strcmp(yunsuanfu[i],buffer);
if(r1==0)
{ printf("%s是运算符\n",buffer);
fprintf(fpout,"(%i,\"%s\")\n",YUNSF,buffer); ///输出到文件
break;
}
}
for(i=0;i<6;i++)
{ r2=strcmp(fengefu[i],buffer);
if(r2==0) {
printf("%s是界符\n",buffer);
fprintf(fpout,"(%i,\"%s\")\n",FENGF,buffer); ///输出到文件
break;
}
}
ch=fgetc(fpin);
continue;
}
}
fclose(fpin);
fclose(fpout);
}
//******************************************************************
//判断一个字符是否是字母
int iszimu(char ch)
{
int flag=0;
if((ch >= 'a' && ch<='z')||(ch>='A' && ch<='Z'))
flag=1;
return flag;
}
//******************************************************************
//判断一个字符是否是字母
int isnumber(char ch)
{
int flag=0;
if(ch>='0' && ch<='9')
flag=1;
return flag;
}
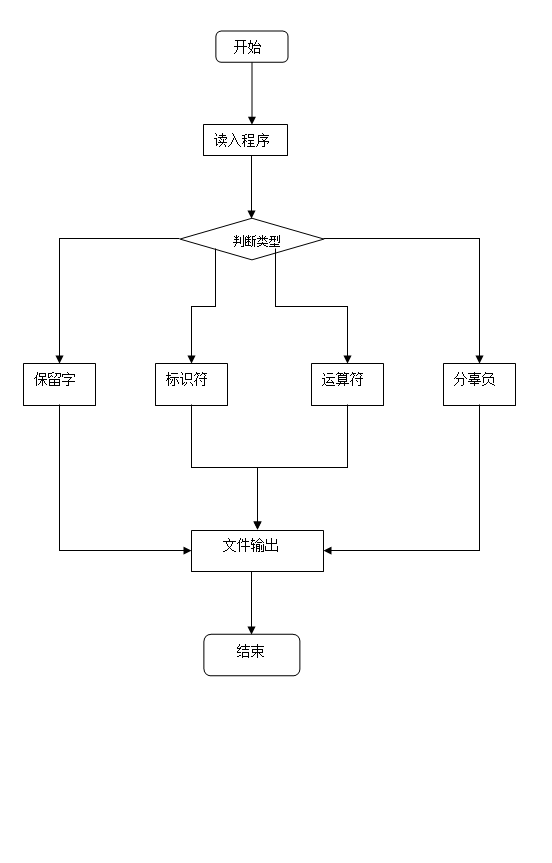
四、流程图
五、运行结果
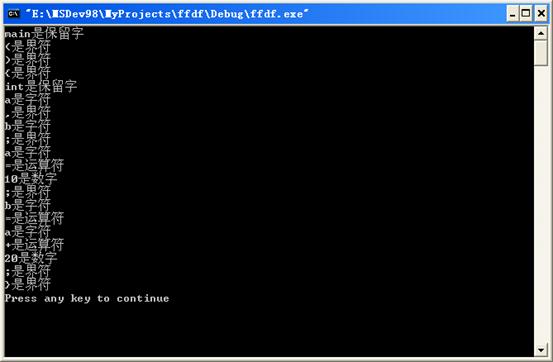
文件输出:
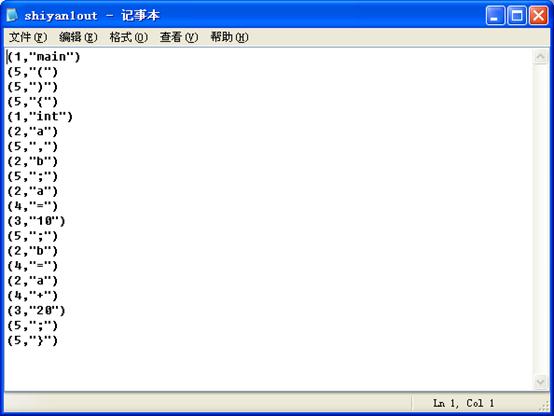
六、心得体会:
通过该实验,主要有以下几方面收获:
一、 对实验原理有更深的理解。
二、然后可以先写出程序的函数定义,每个函数实现相应的功能,再用这些函数写出主程序模块。
三、 通过本次编译原理课程设计,激发了我学习的积极性,培养了我独立发现问题、分析问题,解决问题的能力。更增强我与同学交流沟通和共同解决问题合作的能力。
四、模块化思想是程序设计中一个十分重要部分,它可以把一个程序分成若干部分,然后分块进行编写,它可以大大减少我们因疏忽造成返工时的时间等等。
递归下降语法分析实验报告
一、实验目的
根据某一文法编制调试递归下降分析程序,以便对任意输入的符号串进行分析。本次实验的目的主要是加深对递归下降分析法的理解。
注:也可以采用预测分析方法、算符优先分析方法来进行分析。具体参照课本上的说明,以下是递归下降分析法的介绍。
二 、实验内容与设计思想
编写一个小的语法分析程序,并进行简单的词法进行分析.
三详细设计
#include<iostream.h>
#include<string.h>
#include<stdio.h>
typedef struct
{char R;char r;int flag;}array;typedef struct
{char E;char e;}charLode;typedef struct
charLode *base; int top;
char str[80][80],arr[80][80],brr[80][80];array F[20];
int m,kk,p,ppp,FF=1;char r[10];
int crr[20][20],FLAG=0;char ccrr1[1][20],ccrr2[20][1];
void Initstack(charstack &s)//定义栈
{s.base=new charLode[20];s.top=-1;}
void push(charstack &s,charLode w)
{ s.top++;s.base[s.top].E=w.E;
s.base[s.top].e=w.e;}
void pop(charstack &s,charLode &w)
{ w.E=s.base[s.top].E;w.e=s.base[s.top].e; s.top--;
}int IsEmpty(charstack s)
{if(s.top==-1 return 1;else return 0;}
int IsLetter(char ch)
{if(ch>='A'&&ch<='Z') return 1;
else return 0;
}
//judge1是判断是否是算符文法:若产生式中含有两个相继的非终结符则不是算符文法
int judge1(int n)
{int j=3,flag=0;
for(int i=0;i<=n;i++) while(str[i][j]!='\0')
{char a=str[i][j];char b=str[i][j+1];
if(IsLetter(a)&&IsLetter(b))
{flag=1;break;}else j++;
}if(flag==1)return 0;else return 1;
}
//judge2是判断文法G是否为算符优先文法:若不是算符文法或若文法中含空字或终结符的优先级不唯一则不是算符优先文法
void judge2(int n)
{for(int i=0;i<=n;i++)
if(str[i][3]=='~'||judge1(n)==0||FLAG==1)//'~'代表空字
{cout<<"文法G不是算符优先文法!"<<endl;FF=0;break;}
if(i>n)cout<<"文法G是算符优先文法!"<<endl;
}
//search1是查看存放终结符的数组r中是否含有重复的终结符
int search1(char r[],int kk,char a)
{
for(int i=0;i<kk;i++)
if(r[i]==a)break;
if(i==kk) return 0;else return 1;
}
//createF函数是用F数组存放每个终结符与非终结符和组合,并且值每队的标志位为0;F数组是一个结构体
void createF(int n)
{int k=0,i=1;char g;
char t[10];//t数组用来存放非终结符
t[0]=str[0][0];while(i<=n)
{if(t[k]!=str[i][0])
{k++;t[k]=str[i][0];g=t[k];i++;}
else i++;}
kk=0;char c;for(i=0;i<=n;i++)
{ int j=3; while(str[i][j]!='\0')
{c=str[i][j];if(IsLetter(c)==0)
{if(!search1(r,kk,c))
r[kk]=c;kk++;//r数组用来存放终结符 }
j++;} }m=0;for(i=0;i<k;i++)
for(int j=0;j<kk-1;j++)
{F[m].R=t[i];F[m].r=r[j];F[m].flag=0;
m++; }}
//search函数是将在F数组中寻找到的终结符与非终结符对的标志位值为1
void search(charLode w)
{for(int i=0;i<m;i++)
if(F[i].R==w.E&&F[i].r==w.e){F[i].flag=1;break;}}
void FirstVT(int n)//求FirstVT
{charstack sta;charLode w;int i=0;Initstack(sta);while(i<=n)
{ int k=3; w.E=str[i][0];char a=str[i][k]; char b=str[i][k+1];
if(!IsLetter(a))//产生式的后选式的第一个字符就是终结符的情况
{w.e=a;push(sta,w);search(w); i++;
}else if(IsLetter(a)&&b!='\0'&&!IsLetter(b))//产生式的后选式的第一个字符是非终结符的情况
{ w.e=b; push(sta,w);search(w);i++;
} else i++;}charLode ww;
while(!IsEmpty(sta))
{pop(sta,ww); for(i=0;i<=n;i++)
{w.E=str[i][0];if(str[i][3]==ww.E&&str[i][4]=='\0')
{w.e=ww.e;push(sta,w);search(w); break; }}p=0;int k=1;i=1;while(i<m)
if(F[i-1].flag==1)
{ arr[p][0]=F[i-1].R;arr[p][k]=F[i-1].r;
} while(F[i].flag==0&&i<m)
i++ if(F[i].flag==1)
{ if(F[i].R==arr[p][0]) k++;
else {arr[p][k+1]='\0';p++;k=1;}i++; }} }
void LastVT(int n)//求LastVT
{charstack sta;charLode w;
for(int i=0;i<m;i++) F[i].flag=0;i=0;Initstack(sta);while(i<=n)
{ int k=strlen(str[i]);w.E=str[i][0];char a=str[i][k-1];char b=str[i][k-2];if(!IsLetter(a))
{w.e=a;push(sta,w);search(w);
i++;}else if(IsLetter(a)&&!IsLetter(b))
{w.e=b; push(sta,w);search(w)i++;}else i++;
}charLode ee;while(!IsEmpty(sta))
{pop(sta,ee);for(i=0;i<=n;i++)
{w.E=str[i][0];
if(str[i][3]==ee.E&&str[i][4]=='\0')
{w.e=ee.e;push(sta,w);search(w);
} }}int k=1;i=1;ppp=0;while(i<m)
{if(F[i-1].flag==1)
{brr[ppp][0]=F[i-1].R;
brr[ppp][k]=F[i-1].r;
}while(F[i].flag==0&&i<m)
i++; if(F[i].flag==1)
{ if(F[i].R==arr[ppp][0] k++;
else {brr[ppp][k+1]='\0';ppp++;k=1;} i++;
}} }void createYXB(int n)//构造优先表
{int i,j;
for(j=1;j<=kk;j++)ccrr1[0][j]=r[j-1];
for( i=1;i<=kk;i++)
ccrr2[i][0]=r[i-1];
for(i=1;i<=kk;i++)for(j=1;j<=kk;j++)
crr[i][j]=0;int I=0,J=3;while(I<=n)
{if(str[I][J+1]=='\0')
{I++;J=3;}
Else
while(str[I][J+1]!='\0')
{char aa=str[I][J];
char bb=str[I][J+1];if(!IsLetter(aa)&&!IsLetter(bb))//优先及等于的情况,用1值表示等于
{ for(i=1;i<=kk;i++)
{ if(ccrr2[i][0]==aa)
break; }
for(j=1;j<=kk;j++)
{if(ccrr1[0][j]==bb)break;
}if(crr[i][j]==0)
crr[i][j]=1;else {FLAG=1;I=n+1;}
J++; }
if(!IsLetter(aa)&&IsLetter(bb)&&str[I][J+2]!='\0'&&!IsLetter(str[I][J+2]))//优先及等于的情况
{ for(i=1;i<=kk;i++)
{ if(ccrr2[i][0]==aa)break;
}for(int j=1;j<=kk;j++)
{ if(ccrr1[0][j]==str[I][J+2])break;
} if(crr[i][j]==0)
crr[i][j]=1;else {FLAG=1;I=n+1;}
}if(!IsLetter(aa)&&IsLetter(bb))//优先及小于的情况,用2值表示小于
{ for(i=1;i<=kk;i++)
{ if(aa==ccrr2[i][0])
break; } for(j=0;j<=p;j++)
{ if(bb==arr[j][0])
break;}for(int mm=1;arr[j][mm]!='\0';mm++)
{ for(int pp=1;pp<=kk;pp++)
{if(ccrr1[0][pp]==arr[j][mm]) break;
}if(crr[i][pp]==0)
crr[i][pp]=2;else {FLAG=1;I=n+1;}
}J++; }
if(IsLetter(aa)&&!IsLetter(bb))//优先及大于的情况,用3值表示大于
{ for(i=1;i<=kk;i++)
{ if(ccrr1[0][i]==bb)
break;for(j=0;j<=ppp;j++)
{ if(aa==brr[j][0] break;
}for(int mm=1;brr[j][mm]!='\0';mm++)
{ for(int pp=1;pp<=kk;pp++)
{ if(ccrr2[pp][0]==brr[j][mm]) break;
} if(crr[pp][i]==0)
crr[pp][i]=3;else {FLAG=1;I=n+1;}
} J++;
} } }}//judge3是用来返回在归约过程中两个非终结符相比较的值
int judge3(char s,char a)
{int i=1,j=1;while(ccrr2[i][0]!=s)
i++;while(ccrr1[0][j]!=a) j++;
if(crr[i][j]==3) return 3else if(crr[i][j]==2) return 2;else if(crr[i][j]==1)
return 1;else return 0;
}void print(char s[],char STR[][20],int q,int u,int ii,int k)//打印归约的过程
{cout<<u<<" ";
for(int i=0;i<=k;i++)
cout<<s[i];cout<<" ";
for(i=q;i<=ii;i++) cout<<STR[0][i];cout<<" ";
}void process(char STR[][20],int ii)//对输入的字符串进行归约的过程
{ cout<<"步骤"<<" "<<"符号栈"<<" "<<"输入串"<<" "<<"动作"<<endl;
int k=0,q=0,u=0,b,i,j;char s[40],a;
s[k]='#';print(s,STR,q,u,ii,k);
cout<<"预备"<<endl;
k++;u++ s[k]=STR[0][q];
q++;print(s,STR,q,u,ii,k);
cout<<"移进"<<endl;
while(q<=ii)
{ a=STR[0][q]; if(!IsLetter(s[k])) j=k;
else j=k-1; b=judge3(s[j],a);
if(b==3)//大于的情况进行归约
{ while(IsLetter(s[j-1])) j--;
for(i=j;i<=k;i++) s[i]='\0';
k=j;s[k]='N';u++; print(s,STR,q,u,ii,k);
cout<<"归约"<<endl;
} else if(b==2||b==1)//小于或等于的情况移进
{ k++;
s[k]=a;u++; q++;
print(s,STR,q,u,ii,k);
if(s[0]=='#'&&s[1]=='N'&&s[2]=='#')
cout<<"接受"<<endl;
else cout<<"移进"<<endl;
} else {cout<<"出错"<<endl;break;}
}if(s[0]=='#'&&s[1]=='N'&&s[2]=='#')
cout<<"归约成功"<<endl;
else cout<<"归约失败"<<endl;
}void main()
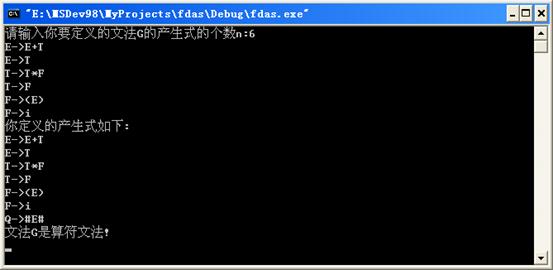
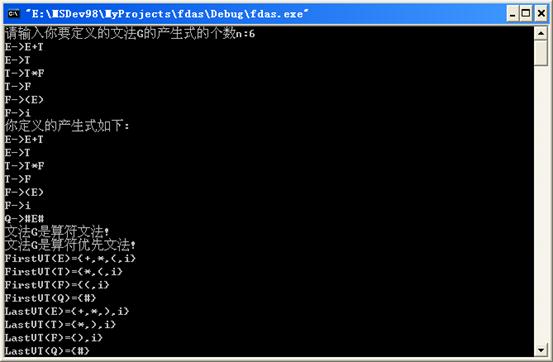
{int n,i,j;cout<<"请输入你要定义的文法G的产生式的个数n:";
cin>>n;for(i=0;i<n;i++)
{ gets(str[i]);
j=strlen(str[i]); str[i][j]='\0';
}str[i][0]='Q';
str[i][1]='-';str[i][2]='>';str[i][3]='#';
str[i][4]=str[0][0];
str[i][5]='#'; str[i][6]='\0';
cout<<"你定义的产生式如下:"<<endl;
for(i=0;i<=n;i++)
cout<<str[i]<<endl;
if(judge1(n)==0)//判断文法G是否为算符文法
cout<<"文法G不是算符文法!"<<endl;
if(judge1(n)==1)
{cout<<"文法G是算符文法!"<<endl; createF(n);
FirstVT(n);LastVT(n);
createYXB(n);
judge2(n);//判断文法G是否为算符优先文法
if(FLAG==0)
{for(i=0;i<=p;i++)//打印FirstVT
{ cout<<"FirstVT("<<arr[i][0]<<")={";
for(int l=1;arr[i][l+1]!='\0';l++)
cout<<arr[i][l]<<",";
cout<<arr[i][l]<<"}"<<endl;
cout<<"FirstVT(Q)={#}"<<endl;
for(i=0;i<=ppp;i++)//打印LastVT
{ cout<<"LastVT("<<arr[i][0]<<")={";
for(int l=1;brr[i][l+1]!='\0';l++)
cout<<brr[i][l]<<",";
cout<<brr[i][l]<<"}"<<endl;} cout<<"LastVT(Q)={#}"<<endl;
cout<<"优先表如下:"<<endl;
for(i=1;i<kk;i++)//打印优先关系表
{ cout<<" "; cout<<ccrr1[0][i];
} cout<<endl;
for(i=1;i<kk;i++)
{ cout<<ccrr2[i][0]<<" ";
for(j=1;j<kk;j++)
{ if(crr[i][j]==0)cout<<" ";
else if(crr[i][j]==1) cout<<"=";
else if(crr[i][j]==2) cout<<"<";
else if(crr[i][j]==3)
cout<<">";
cout<<" ";
} cout<<endl } }
if(FF==1){char STR[1][20];
cout<<"请输入要规约的字符串:"<<endl;
gets(STR[0]);
int ii=strlen(STR[0]);
STR[0][ii]='#'; cout<<"下面是规约的过程:"<<endl;
process(STR,ii)}
四、流程图
五、结果分析:
输入错误情况:
正确输入:

六 心得
通过本次编译原理课程设计,激发了我学习的积极性,培养了我独立发现问题、分析问题,解决问题的能力。更增强我与同学交流沟通和共同解决问题合作的能力。
理解了编译原理知识点及学科之间的融合渗透。将以前学的VC++的基本知识应用于软件设计,加深了对VC++界面程序设计的理解,达到了学以致用的目
LL(1)分析法语法分析实验报告
一、实验目的
通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
二、实验内容
u 根据某一文法编制调试 LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
u 构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
u 分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
三、 LL(1)分析法实验设计思想及算法
u 模块结构:
(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);
(3)控制部分:从键盘输入一个表达式符号串;
(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。

四、实验要求
1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
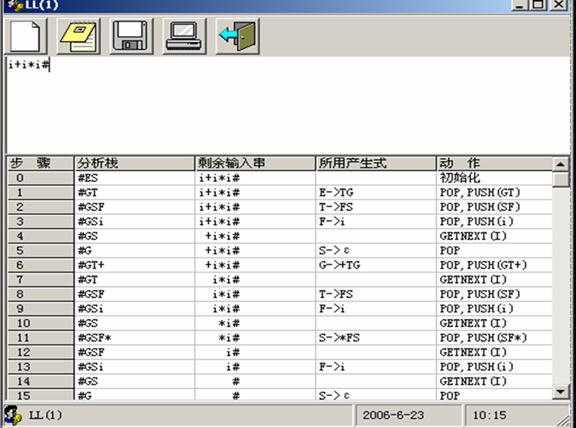
3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:
(1)E->TG
(2)G->+TG|—TG
(3)G->ε
(4)T->FS
(5)S->*FS|/FS
(6)S->ε
(7)F->(E)
(8)F->i
输出的格式如下:
六、实验源程序
LL1.java
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
import javax.swing.table.DefaultTableModel;
import java.sql.*;
import java.util.Vector;
publicclass LL1 extends JFrame implements ActionListener
{
/**
*
*/
privatestaticfinallongserialVersionUID = 1L;
JTextField tf1;
JTextField tf2;
JLabel l;
JButton b0;
JPanel p1,p2,p3;
JTextArea t1,t2,t3;
JButton b1,b2,b3;
JLabel l0,l1,l2,l3,l4;
JTable table;
Statement sta;
Connection conn;
ResultSet rs;
DefaultTableModel dtm;
String Vn[]=null;
Vector<String> P=null;
int firstComplete[]=null;//存储已判断过first的数据
char first[][]=null;//存储最后first结果
int followComplete[]=null;//存储已判断过follow的数据
char follow[][]=null;//存储最后follow结果
char select[][]=null;//存储最后select结果
int LL=0;//标记是否为LL(1)
String vt_tou[]=null;//储存Vt
Object shuju[][]=null;//存储表达式数据
char yn_null[]=null;//存储能否推出空
LL1()
{
setLocation(100,0);
setSize(700,780);
tf1=new JTextField(13);
tf2=new JTextField(13);
l=new JLabel(">>");
l0=new JLabel("输入字符串:");
l1=new JLabel("输入的文法为: ");
l2=new JLabel(" ");
l3=new JLabel("分析的结果: ");
l4=new JLabel("预测分析表: ");
//p1=new JPanel();
p2=new JPanel();
p3=new JPanel();
t1=new JTextArea(24,20);
t2=new JTextArea(1,30);
t3=new JTextArea(24,40);
b0=new JButton("确定(S为开始)");
b1=new JButton(" 判断文法 ");
b2=new JButton("输入");
b3=new JButton("清空");
table=new JTable();
JScrollPane jp1=new JScrollPane(t1);
JScrollPane jp2=new JScrollPane(t2);
JScrollPane jp3=new JScrollPane(t3);
p2.add(tf1);
p2.add(l);
p2.add(tf2);
p2.add(b0);
p2.add(b1);
p2.add(l0);
p2.add(l2);
p2.add(jp2);
p2.add(b2);
p2.add(b3);
p2.add(l1);
p2.add(l3);
p2.add(jp1);
p2.add(jp3);
p3.add(l4);
p3.add(new JScrollPane(table));
add(p2,"Center");
add(p3,"South");
b0.addActionListener(this);
b1.addActionListener(this);
b2.addActionListener(this);
b3.addActionListener(this);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
table.setPreferredScrollableViewportSize(new Dimension(660,200));
setVisible(true);
}
publicvoid actionPerformed(ActionEvent e)
{
if(e.getSource()==b0)
{
String a=tf1.getText();
String b=tf2.getText();
t1.append(a+'→'+b+'\n');
}
if(e.getSource()==b1)
{
t3.setText("");
int Vnnum=0,k;
Vn=new String[100];
P=new Vector<String>();
String s[]=t1.getText().split("\n");
for(int i=0;i<s.length;i++)
{
if(s.length<2){
t3.setText("文法输入有误,请重新输入");//判断长度是否符合
return;
}
if(s[i].charAt(0)<='Z'&&s[i].charAt(0)>='A'&&s[i].charAt(1)=='→')
{
for(k=0;k<Vnnum;k++)
{
if(Vn[k].equals(s[i].substring(0, 1))){
break;
}
}
if(Vnnum==0||k>=Vnnum)
{
Vn[Vnnum]=s[i].substring(0, 1);//存入Vn数据
Vnnum++;
}
P.add(s[i]);
}
else
{
t3.setText("文法输入有误,请重新输入");
return;
}
}
yn_null=newchar[100];
first=newchar[Vnnum][100];
int flag=0;
String firstVn[]=null;
firstComplete=newint[Vnnum];
for(int i=0;Vn[i]!=null;i++) //依次求 FIRST**
{
flag=0;
firstVn=new String[20];
if((flag=add_First(first[i],Vn[i],firstVn,flag))==-1)return;
firstComplete[i]=1;
}
t3.append("first集:"+"\n"); //显示FIRST**
for(int i=0;Vn[i]!=null;i++)
{
t3.append("first("+Vn[i]+")={ ");
for(int j=0;first[i][j]!='\0';j++)
{
t3.append(first[i][j]+" , ");
}
t3.append("}"+"\n");
}
follow=newchar[Vnnum][100];
String followVn[]=null;
followComplete=newint[Vnnum];
for(int i=0;Vn[i]!=null;i++) //求FOLLOW**
{
flag=0;
followVn=new String[20];
if((flag=tianjiaFollow(follow[i],Vn[i],followVn,flag))==-1)return;
followComplete[i]=1;
}
t3.append("follow集:"+"\n"); //显示FOLLOW**
for(int i=0;Vn[i]!=null;i++)
{
t3.append("follow("+Vn[i]+")={ ");
for(int j=0;follow[i][j]!='\0';j++)
{
t3.append(follow[i][j]+" , ");
}
t3.append("}"+"\n");
}
select=newchar[P.size()][100];
for(int i=0;i<P.size();i++) //求SELECT**
{
flag=0;
tianjiaSelect(select[i],(String)P.elementAt(i),flag);
}
t3.append("select集:"+"\n"); //显示SELECT**
for(int i=0;i<P.size();i++)
{
t3.append("select("+(String)P.elementAt(i)+")={ ");
for(int j=0;select[i][j]!='\0';j++)
{
t3.append(select[i][j]+" , ");
}
t3.append("}"+"\n");
}
for(int i=0;Vn[i]!=null;i++)//判断select交集是否为空
{
int biaozhi=0;
char save[]=newchar[100];
for(int j=0;j<P.size();j++)
{
String t=(String)P.elementAt(j);
if(t.substring(0,1).equals(Vn[i]))
{
for(k=0;select[j][k]!='\0';k++)
{
if(puanduanChar(save,select[j][k]))
{
save[biaozhi]=select[j][k];
biaozhi++;
}
else//当有交集时,不为LL(1)文法
{
t3.append("不是LL(1)文法!!"+"\n");
return;
}
}
}
}
}
char Vt[]=newchar[100];
int biaozhi=0;
for(int i=0;i<P.size();i++)
{
String t=(String)P.elementAt(i);
for(int j=2;j<t.length();j++)//提取表达式右侧的终结符存入Vt
{
if(t.charAt(j)>'Z'||t.charAt(j)<'A')
{
if(puanduanChar(Vt,t.charAt(j)))
{
Vt[biaozhi]=t.charAt(j);
biaozhi++;
}
}
}
}
if(puanduanChar(Vt,'#'))//若可推出空集,则将#加入Vt。
{
Vt[biaozhi]='#';
biaozhi++;
}
vt_tou=new String[biaozhi+1];//根据select和表达式生成预测分析表
shuju=new String[Vnnum][biaozhi+1];
String f="";
vt_tou[0]=f;
for(int i=0;i<biaozhi;i++)
{
vt_tou[i+1]=String.valueOf(Vt[i]);
}
for(int i=0;i<Vnnum;i++)
{
shuju[i][0]=Vn[i];
}
for(int i=0;i<P.size();i++)
{
String t=(String)P.elementAt(i);
int j;
for(j=0;j<Vn.length;j++)
{
if(Vn[j].equals(t.substring(0,1)))
{
break;
}
}
for(k=0;select[i][k]!='\0';k++)
{
int y=puanduanXulie(Vt,select[i][k]);
shuju[j][y+1]=t.substring(1);
}
}
dtm=new DefaultTableModel(shuju,vt_tou);//显示预测分析表
table.setModel(dtm);
LL=1;
}
if(e.getSource()==b3)//清空列表
{
tf1.setText("");
tf2.setText("");
t1.setText("");
t2.setText("");
t3.setText("");
Vn=null;
P=null;
firstComplete=null;
first=null;
followComplete=null;
follow=null;
select=null;
dtm=new DefaultTableModel();
table.setModel(dtm);
}
if(e.getSource()==b2)//输入字符串并预测分析
{
t3.setText("");
if(LL==1)
{
String s=t2.getText();
for(int i=0;i<s.length();i++)
{
if(s.charAt(i)=='\0')
{
t3.setText("字符串中请不要加入空格"+"\n");
return;
}
}
char zifu[]=newchar[100];//剩余输入串
char fenxi[]=newchar[100];//分析栈
zifu[0]='#';
fenxi[1]='S';
fenxi[0]='#';
int fzifu=1;
int ffenxi=2;
for(int i=s.length()-1;i>=0;i--)
{
zifu[fzifu]=s.charAt(i);
fzifu++;
}
int buzhou=2;
char n[]=newchar[65];//存储要显示的内容
t3.append("步骤 分析栈 剩余输入串 所用产生式或匹配"+"\n");
n[0]='1';
n[15]='#';
n[14]='S';
int u=29;
for(int i=fzifu-1;i>=0;i--)
{
n[u]=zifu[i];
u++;
}
while(!(fenxi[ffenxi-1]=='#'&&zifu[fzifu-1]=='#'))//剩余输入串不为#则分析
{
int i,j;
char t=zifu[fzifu-1];
char k=fenxi[ffenxi-1];
if(t==k)//产生式匹配
{
n[49]=k;
n[50]='匹';
n[51]='配';
t3.append(String.copyValueOf(n)+"\n");
n=newchar[65];
fzifu--;
ffenxi--;
if(buzhou<10)
n[0]=(char)('0'+buzhou);//显示步骤数
else
{
n[0]=(char)('0'+buzhou/10);
n[1]=(char)('0'+buzhou%10);
}
u=14;
for(int y=ffenxi-1;y>=0;y--)//处理分析栈,出栈
{
n[u]=fenxi[y];
u++;
}
u=29;
for(int y=fzifu-1;y>=0;y--)//处理剩余字符串,消除一个字符
{
n[u]=zifu[y];
u++;
}
buzhou++;
continue;
}
for(i=0;Vn[i]!=null;i++)//搜寻所用产生式的左部
{
if(Vn[i].equals(String.valueOf(k)))break;
}
for(j=0;j<vt_tou.length;j++)//判断是否匹配
{
if(vt_tou[j].equals(String.valueOf(t)))break;
}
if(j>=vt_tou.length)//全部产生式都不能符合则报错
{
t3.append(String.copyValueOf(n));
t3.append("\n"+"该串不是该文法的句型"+"\n");
return;
}
Object result1=shuju[i][j];
if(result1==null)
{
t3.append(String.copyValueOf(n));
t3.append("\n"+"该串不是该文法的句型"+"\n");
return;
}
else//找到所用产生式
{
n[49]=Vn[i].charAt(0);
u=50;
String result=(String)result1;
for(int y=0;y<result.length();y++)
{
n[u]=result.charAt(y);
u++;
}
t3.append(String.copyValueOf(n)+"\n");
n=newchar[65];
ffenxi--;
for(i=result.length()-1;i>0;i--)//将分析栈内非终结符换为右边表达式
{
if(result.charAt(i)!='#')
{
fenxi[ffenxi]=result.charAt(i);
ffenxi++;
}
}
}
if(buzhou<10)//显示“步骤”
n[0]=(char)('0'+buzhou);
else
{
n[0]=(char)('0'+buzhou/10);
n[1]=(char)('0'+buzhou%10);
}
u=14;
for(int y=ffenxi-1;y>=0;y--)
{
n[u]=fenxi[y];
u++;
}
u=29;
for(int y=fzifu-1;y>=0;y--)
{
n[u]=zifu[y];
u++;
}
buzhou++;
}
n=newchar[65];
n[0]='1';
n[14]='#';
n[29]='#';
n[49]='分';
n[50]='析';
n[51]='成';
n[52]='功';
t3.append(String.copyValueOf(n));
t3.append("\n"+"该串是此文法的句型"+"\n");
return;
}
else
{
t3.setText("请先依次输入LL(1)文法,并点击 文法判断 按钮"+"\n");
return;
}
}
}
privateint add_First(char a[],String b,String firstVn[],int flag) //计算FIRST**(递归)
{
if(puanduanString(firstVn,b.charAt(0))){addString(firstVn,b);}
else
{
return flag;
}
for(int i=0;i<P.size();i++)
{
String t=(String)P.elementAt(i);
for(int k=2;k<t.length();k++)
{
if(t.substring(0, 1).equals(b))
{
if(t.charAt(k)>'Z'||t.charAt(k)<'A')//表达式右端第i个不是非终结符
{
if(flag==0||puanduanChar(a,t.charAt(k)))
{
if(t.charAt(k)=='#')//#时直接加入first
{
if(k+1==t.length())
{
a[flag]=t.charAt(k);
flag++;
}
int flag1=0;
for(int j=0;yn_null[j]!='\0';j++)//所求非终结符进入yn_null**
{
if(yn_null[j]==b.charAt(0))//判断能否推出空
{
flag1=1;break;
}
}
if(flag1==0)
{
int j;
for(j=0;yn_null[j]!='\0';j++)
{
}
yn_null[j]=b.charAt(0);
}
continue;
}
else//终结符直接加入first**
{
a[flag]=t.charAt(k);
flag++;
break;
}
}break;
}
else//非终结符
{
if(!puanduanString(Vn,t.charAt(k)))
{
int p=firstComplete(t.charAt(k));//当该非终结符的first已经求出
if(p!=-1)
{
flag=addElementFirst(a,p,flag);//直接加入所求first
}
elseif((flag=add_First(a,String.valueOf(t.charAt(k)),firstVn,flag))==-1)
return -1;
int flag1=0;
for(int j=0;yn_null[j]!='\0';j++)//当非终结符的first有空
{
if(yn_null[j]==t.charAt(k))
{
flag1=1;break;
}
}
if(flag1==1)//当非终结符的first能推出空
{
if(k+1==t.length()&&puanduanChar(a,'#'))//之后无符号,且所求first无#
{
a[flag]='#';//first中加入#
flag++;
}
continue;//判断下一个字符
}
else
{
break;
}
}
else//错误
{
t3.setText("文法输入有误"+"\n");
return -1;
}
}
}
}
}
return flag;
}
privateint tianjiaFollow(char a[],String b,String followVn[],int flag) //计算FOLLOW**(递归)
{
if(puanduanString(followVn,b.charAt(0))){addString(followVn,b);}
else
{
return flag;
}
if(b.equals("S"))//当为S时#存入follow
{
a[flag]='#';
flag++;
}
for(int i=0;i<P.size();i++)
{
String t=(String)P.elementAt(i);
for(int j=2;j<t.length();j++)
{
if(t.charAt(j)==b.charAt(0)&&j+1<t.length())
{
if(t.charAt(j+1)!='\0')
{
if((t.charAt(j+1)>'Z'||t.charAt(j+1)<'A'))//所求为终结符
{
if(flag==0||puanduanChar(a,t.charAt(2)))//自身
{
a[flag]=t.charAt(j+1);
flag++;
}
}
else//所求为非终结符
{
int k;
for(k=0;Vn[k]!=null;k++)
{
if(Vn[k].equals(String.valueOf(t.charAt(j+1))))
{
break;//找寻下一个非终结符的Vn位置
}
}
flag=addElementFirst(a,k,flag);//把下一个非终结符first加入所求follow集
for(k=j+1;k<t.length();k++)
{
if((t.charAt(j+1)>'Z'||t.charAt(j+1)<'A'))break;
else
{
if(panduan_kong(t.charAt(k)))
{}
else
{
break;
}
}
}
if(k>=t.length())//下一个非终结符可推出空,把表达式左边非终结符的follow集加入所求follow集
{
int p=followComplete(t.charAt(0));
if(p!=-1)
{
flag=addElementFollow(a,p,flag);
}
elseif((flag=tianjiaFollow(a,String.valueOf(t.charAt(0)),followVn,flag))==-1)
return -1;
}
}
}
else//错误
{
t3.setText("文法输入有误,请重新输入"+"\n");
return -1;
}
}
if(t.charAt(j)==b.charAt(0)&&j+1==t.length())//下一个字符为空,把表达式左边非终结符的follow集加入所求follow集
{
int p=followComplete(t.charAt(0));
if(p!=-1)
{
flag=addElementFollow(a,p,flag);
}
elseif((flag=tianjiaFollow(a,String.valueOf(t.charAt(0)),followVn,flag))==-1)
return -1;
}
}
}
return flag;
}
privatevoid tianjiaSelect(char a[],String b,int flag) //计算SELECT**
{
int i=2;
int biaozhi=0;
while(i<b.length())
{
if((b.charAt(i)>'Z'||b.charAt(i)<'A')&&b.charAt(i)!='#')//是终结符
{
a[flag]=b.charAt(i);//将这个字符加入到Select**,结束Select**的计算
break;
}
elseif(b.charAt(i)=='#')//是空
{
int j;
for(j=0;Vn[i]!=null;j++)//将表达式左侧的非终结符的follow加入select
{
if(Vn[j].equals(b.substring(0,1)))
{
break;
}
}
for(int k=0;follow[j][k]!='\0';k++)
{
if(puanduanChar(a,follow[j][k]))
{
a[flag]=follow[j][k];
flag++;
}
}
break;
}
elseif(b.charAt(i)>='A'&&b.charAt(i)<='Z'&&i+1<b.length())//是非终结符且有下一个字符
{
int j;
for(j=0;Vn[i]!=null;j++)
{
if(Vn[j].equals(String.valueOf(b.charAt(i))))
{
break;
}
}
for(int k=0;first[j][k]!='\0';k++)
{
if(puanduanChar(a,first[j][k]))//把表达式右侧所有非终结符的first集加入。
{
if(first[j][k]=='#')//first中存在空
{
biaozhi=1;
}
else
{
a[flag]=first[j][k];
flag++;
}
}
}
if(biaozhi==1)//把右侧所有非终结符的first中的#去除
{
i++;biaozhi=0;continue;
}
else
{
biaozhi=0;break;
}
}
elseif(b.charAt(i)>='A'&&b.charAt(i)<='Z'&&i+1>=b.length())//是非终结符且没有下一个字符
{
int j;
for(j=0;Vn[i]!=null;j++)
{
if(Vn[j].equals(String.valueOf(b.charAt(i))))
{
break;
}
}
for(int k=0;first[j][k]!='\0';k++)
{
if(puanduanChar(a,first[j][k]))
{
if(first[j][k]=='#')
{
biaozhi=1;//表达式右侧能推出空,标记
}
else
{
a[flag]=first[j][k];//不能推出空,直接将first集加入select集
flag++;
}
}
}
if(biaozhi==1)//表达式右侧能推出空
{
for(j=0;Vn[i]!=null;j++)
{
if(Vn[j].equals(b.substring(0,1)))
{
break;
}
}
for(int k=0;follow[j][k]!='\0';k++)
{
if(puanduanChar(a,follow[j][k]))
{
a[flag]=follow[j][k];//将将表达式左侧的非终结符的follow加入select
flag++;
}
}
break;
}
else
{
biaozhi=0;break;
}
}
}
}
//返回b在Vt[]的位置
privateint puanduanXulie(char Vt[],char b)
{
int i;
for(i=0;Vt[i]!='\0';i++)
{
if(Vt[i]==b)break;
}
return i;
}
//判断b是否在a中,在返回false,不在返回true
privateboolean puanduanChar(char a[],char b)
{
for(int i=0;a[i]!='\0';i++)
{
if(a[i]==b)returnfalse;
}
returntrue;
}
//判断b是否在a中,在返回false,不在返回true
privateboolean puanduanString(String a[],char b)
{
for(int i=0;a[i]!=null;i++)
{
if(a[i].equals(String.valueOf(b)))returnfalse;
}
returntrue;
}
//把b加入字符串组firstVn[]
privatevoid addString(String firstVn[],String b)
{
int i;
for(i=0;firstVn[i]!=null;i++)
{
}
firstVn[i]=b;
}
//判断b是否已完成first判断
privateint firstComplete(char b)
{
int i;
for(i=0;Vn[i]!=null;i++)
{
if(Vn[i].equals(String.valueOf(b)))
{
if(firstComplete[i]==1)return i;
elsereturn -1;
}
}
return -1;
}
//判断b是否已完成follow判断
privateint followComplete(char b)
{
for(int i=0;Vn[i]!=null;i++)
{
if(Vn[i].equals(String.valueOf(b)))
{
if(followComplete[i]==1)return i;
elsereturn -1;
}
}
return -1;
}
//把相应终结符添加到first**中
privateint addElementFirst(char a[],int p,int flag)
{
for(int i=0;first[p][i]!='\0';i++)
{
if(puanduanChar(a,first[p][i])&&first[p][i]!='#')
{
a[flag]=first[p][i];
flag++;
}
}
return flag;
}
//把相应终结符添加到follow**中
privateint addElementFollow(char a[],int p,int flag)
{
for(int i=0;follow[p][i]!='\0';i++)
{
if(puanduanChar(a,follow[p][i]))
{
a[flag]=follow[p][i];
flag++;
}
}
return flag;
}
//判断a能是否包含空
privateboolean panduan_kong(char a)
{
int i;
for(i=0;Vn[i]!=null;i++)
{
if(Vn[i].equals(String.valueOf(a)))
{
break;
}
}
for(int j=0;first[i][j]!='\0';j++)
{
if(first[i][j]=='#')returntrue;
}
returnfalse;
}
publicstaticvoid main(String[] args) {
new LL();
}
}
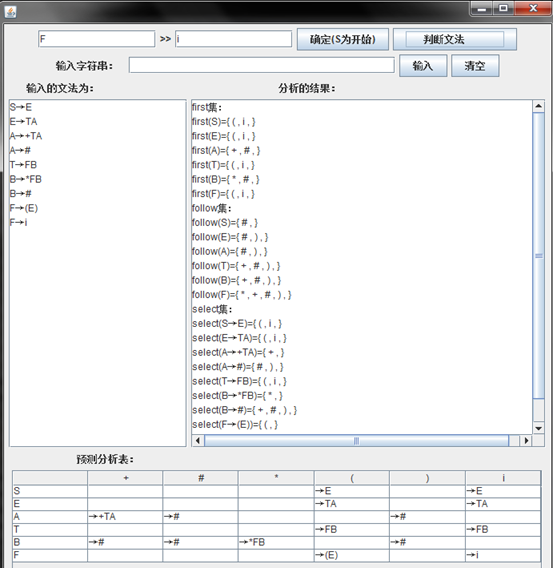
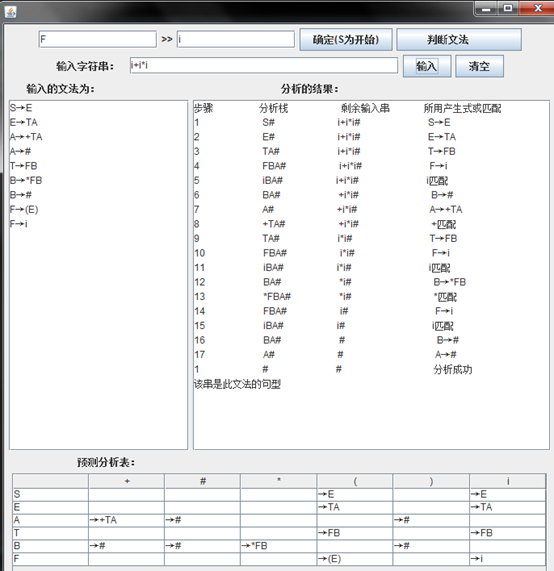
七、实验结果
八、实验心得体会
通过这次的实验,我深入了解了词法分析器和LL(1)文法预测分析法设计和实现,增强了我的自学能力和独立思考能力,也让我对程序设计有了更大的兴趣,自己通过查找资料、复习课本、编程调试,写实验报告等环节,进一步掌握了以前学到的知识,并且还对编译原理应用有了更深入的认识与掌握。在完成这个程序后,真的很开心,也了使我解到编译原理的魅力所在,激发了我要解决更多更难问题的决心。
通过实践的学习,我认到学好计算机要重视实践操作,不仅仅是学习java语言,还是其它的语言,以及其它的计算机方面的知识都要重在实践,所以后在学习过程中,我会更加注视实践操作,使自己便好地学好计算机。