
课程实验报告
课程名称: 《编译原理》
专业班级:
学 号:
姓 名:
指导教师:
报告日期:
计算机科学与技术学院
实验一 词法分析程序实现
一、实验目的与要求
通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符形式的源程序流转化为一个由各类单词符号组成的流的词法分析方法。
二、实验内容
根据教学要求并结合学生自己的兴趣和具体情况,从具有代表性的高级程序设计语言的各类典型单词中,选取一个适当大小的子集。例如,可以完成无符号常数这一类典型单词的识别后,再完成一个尽可能兼顾到各种常数、关键字、标识符和各种运算符的扫描器的设计和实现。
输入:由符合或不符合所规定的单词类别结构的各类单词组成的源程序。
输出:把单词的字符形式的表示翻译成编译器的内部表示,即确定单词串的输出形式。例如,所输出的每一单词均按形如(CLASS,VALUE)的二元式编码。对于变量和常数,CLASS字段为相应的类别码;VALUE字段则是该标识符、常数的具体值或在其符号表中登记项的序号(要求在变量名表登记项中存放该标识符的字符串;常数表登记项中则存放该常数的二进制形式)。对于关键字和运算符,采用一词一类的编码形式;由于采用一词一类的编码方式,所以仅需在二元式的CLASS字段上放置相应的单词的类别码,VALUE字段则为“空”。另外,为便于查看由词法分析程序所输出的单词串,要求在CLASS字段上放置单词类别的助记符。
三、实现方法与环境
词法分析是编译程序的第一个处理阶段,可以通过两种途径来构造词法分析程序。其一是根据对语言中各类单词的某种描述或定义(如BNF),用手工的方式(例如可用C语言)构造词法分析程序。一般地,可以根据文法或状态转换图构造相应的状态矩阵,该状态矩阵同控制程序便组成了编译器的词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。构造词法分析程序的另外一种途径是所谓的词法分析程序的自动生成,即首先用正规式对语言中的各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程序所应进行的语义处理工作,然后由一个所谓词法分析程序的构造程序对上述信息进行加工。如美国BELL实验室研制的LEX就是一个被广泛使用的词法分析程序的自动生成工具。
总的来说,开发一种新语言时,由于它的单词符号在不停地修改,采用LEX等工具生成的词法分析程序比较易于修改和维护。一旦一种语言确定了,则采用手工编写词法分析程序效率更高。
四、实验设计
1)题目1:试用手工编码方式构造识别以下给定单词的某一语言的词法分析程序。
语言中具有的单词包括五个有代表性的关键字begin、end、if、then、else;标识符;整型常数;六种关系运算符;一个赋值符和四个算术运算符。参考实现方法简述如下。
单词的分类:构造上述语言中的各类单词符号及其分类码表。
表I 语言中的各类单词符号及其分类码表

处理过程:在一个程序设计语言中,一般都含有若干类单词符号,为此可首先为每类单词建立一张状态转换图,然后将这些状态转换图合并成一张统一的状态图,即得到了一个有限自动机,再进行必要的确定化和状态数最小化处理,最后据此构造词法分析程序。在此为了使词法分析程序结构比较清晰,且尽量避免某些枝节问题的纠缠,假定要编译的语言中,全部关键字都是保留字,程序员不得将它们作为源程序中的标识符;在源程序的输入文本中,关键字、标识符、整常数之间,若未出现关系和算术运算符以及赋值符,则至少须用一个空白字符加以分隔。作了这些限制以后,就可以把关键字和标识符的识别统一进行处理。即每当开始识别一个单词时,若扫视到的第一个字符为字母,则把后续输入的字母或数字字符依次进行拼接,直至扫视到非字母、数字字符为止,以期获得一个尽可能长的字母数字字符串,然后以此字符串查所谓保留字表(此保留字表已事先造好),若查到此字符串,则取出相应的类别码;反之,则表明该字符串应为一标识符。采用上述策略后,针对表I中部分单词可以构造一个如图1所示的有限自动机(以状态转换图表示)。在图1中添加了当进行状态转移时,词法分析程序应执行的语义动作。
题目2:将表I单词集中的整常数改为无符号常数,修改题目1中已开发的扫描器。
无符号常数的单词分类码助记符:UCON;其值为无符号常数的机内二进制表示。
描述无符号数的BNF定义和状态转换图:
无符号数的文法G如下:
〈无符号数〉→ d〈余留无符号数〉
〈无符号数〉→ ·〈小数部分〉
〈无符号数〉→ d
〈余留无符号数〉→ d〈余留无符号数〉
〈余留无符号数〉→ ·〈十进小数〉
〈余留无符号数〉→ E〈指数部分〉
〈余留无符号数〉→ d
〈余留无符号数〉→ ·
〈十进小数〉→ E〈指数部分〉
〈十进小数〉→ d〈十进小数〉
〈十进小数〉→ d
〈小数部分〉→ d〈十进小数〉
〈小数部分〉→ d
〈指数部分〉→ d〈余留整指数〉
〈指数部分〉→ +〈整指数〉
〈指数部分〉→ -〈整指数〉
〈指数部分〉→ d
〈整指数〉→ d〈余留整指数〉
〈整指数〉→ d
〈余留整指数〉→ d〈余留整指数〉
〈余留整指数〉→ d
图2所示为上述文法的状态转换图,其中编号0、1、2、…、6分别代表非终结符号<无符号数>、<余留无符号数>、<十进小数>、<小数部分>、<指数部分>、<整指数>及<余留整指数>。
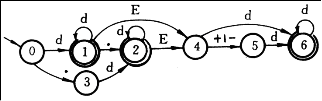
图2 文法G[<无符号数>]的状态转换图
实现无符号数识别的参考方法:在计算机内实现状态转换图的方法之一,是以状态图中的各个状态为行,以可能输入的各个输入符号为列,组成一个状态矩阵。其中,矩阵的元素用来指明下一个状态和扫描器应完成的语义动作(如拼接字符、数制转换、查填符号表以及输出单词的内部表示等)。由于在一个状态矩阵中,通常有许多状态都是出错状态,为了节省存放状态矩阵的存储空间,在具体实现时,常常采用更为紧凑和有效的数据结构。例如,对于文法G[<无符号数>]的状态转换图,可按表II的形式来存放其状态矩阵。表II中的第一列为各状态Si的编号,第二列分别列出了在每一状态下可能扫视到的输入符号aj(其中“other”是一个符号集合,用来表示在相应状态所属的那一栏中,除其前所列字符之外的全部其它字符),第三列指出当(Si,aj)出现时应执行的语义动作(通常用若干个语句来实现,若其后空,则表示不进行任何处理),最后一栏用来指明下一状态的编号(若其后NULL或“结束”则表示无后继状态)。状态矩阵中所嵌入的语义动作,其功能是在扫描源程序字符串的过程中,把识别出的字符串形式的无符号数,逐步转换为相应的二进制整数(ICON)或二进制浮点数(FCON)的内部形式,方法见教材第56页。(注:考虑能否采用C语言的库函数实现此语义处理工作。)
表II 包含语义处理过程的识别无符号数的状态矩阵
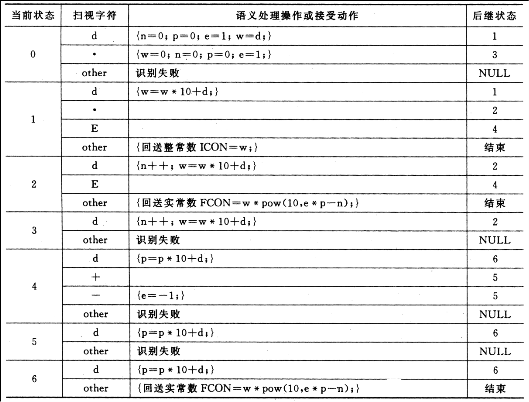
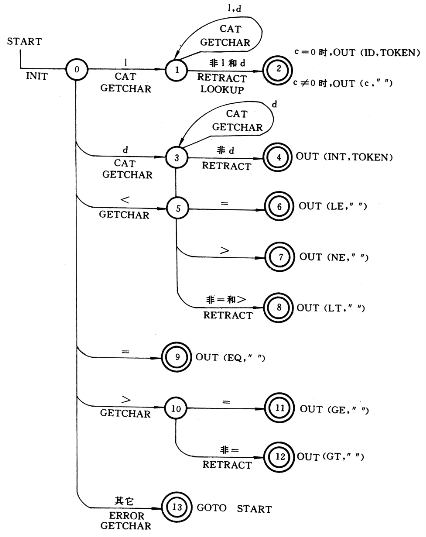
图1 识别表I所列语言中的部分单词的DFA及相关的语义过程
图1及程序一中所出现的语义变量及语义函数的含义和功能说明如下。
函数GETCHAR:每调用一次,就把扫描指示器当前所指示的源程序字符送入字符变量ch,然后把扫描指示器前推一个字符位置。
字符数组TOKEN:用来依次存放一个单词词文中的各个字符。
函数CAT:每调用一次,就把当前ch中的字符拼接于TOKEN中所存字符串的右边。
函数LOOKUP:每调用一次,就以TOKEN中的字符串查保留字表,若查到,就将相应关键字的类别码赋给整型变量c;否则将c置为零。
函数RETRACT:每调用一次,就把扫描指示器回退一个字符位置(即退回多读的那个字符)。
函数OUT:一般仅在进入终态时调用此函数,调用的形式为OUT(c,VAL)。其中,实参c为相应单词的类别码或其助记符;当所识别的单词为标识符和整数时,实参VAL为TOKEN(即词文分别为字母数字串和数字串),对于其余种类的单词,VAL均为空串。函数OUT的功能是,在送出一个单词的内部表示之后,返回到调用该词法分析程序的那个程序。
五、源程序
#include<stdio.h>
#include<string.h>
char prog[80],token[6];
char ch;
int syn,p,m,n,sum;
char * rwtab[6]={"begin","if","then","while","do","end"};
main()
{
p=0;
printf("\nplease intput string:");
do
{
ch=getchar();
prog[p++]=ch;
}while(ch!='#');
p=0;
do
{
scaner();
switch(syn)
{
case 11:printf("(%d,%d)\n",syn,sum);break;
case -1:printf("input error\n"); break;
default:printf("(%d,%s)\n",syn,token);
}
}while(syn!=0);
getch();
}
/*词法扫描程序:*/
scaner()
{
for(n=0;n<8;n++)
token[n]=NULL;
m=0;
ch=prog[p++];
while(ch==' ')ch=prog[p++];
if((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A'))
{
while((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')||(ch<='9'&&ch>='0'))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]='\0';
ch=prog[--p];
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else
if((ch<='9'&&ch>='0'))
{
sum=0;
while((ch<='9'&&ch>='0'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
ch=prog[--p];
syn=11;
}
else
switch(ch)
{
case '<':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='>')
{
syn=21;
token[m++]=ch;
}
else
if(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=20;
ch=prog[--p];
}
break;
case '>':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
ch=prog[--p];
}
break;
case ':':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
ch=prog[--p];
}
break;
case '+':syn=13;token[0]=ch;break;
case '-':syn=14;token[0]=ch;break;
case '*':syn=15;token[0]=ch;break;
case '/':syn=16;token[0]=ch;break;
case ':=':syn=18;token[0]=ch;break;
case '<>':syn=21;token[0]=ch;break;
case '<=':syn=22;token[0]=ch;break;
case '>=':syn=24;token[0]=ch;break;
case '=':syn=25;token[0]=ch;break;
case ';':syn=26;token[0]=ch;break;
case '(':syn=27;token[0]=ch;break;
case ')':syn=28;token[0]=ch;break;
case '#':syn=0;token[0]=ch;break;
default:syn=-1;
}
}
六、源程序说明:
字符数组TOKEN:用来依次存放一个单词词文中的各个字符。
函数getchar:每调用一次,就把扫描指示器当前所指示的源程序字符送入字符变量ch,然后把扫描指示器前推一个字符位置。
函数lookup:每调用一次,就以TOKEN中的字符串查保留字表,若查到,就将相应关键字的类别码赋给整形变量c;否则将c置为零。
函数ungetc:每调用一次,就把扫描指示器回退一个字符位置(即退回多读的那个字符)。
函数out:一般仅在进入终态时调用此函数,调用的形式为out(c)。其中,实参c为相应单词的类别码。函数根据类别码选择输出形式。
七 实验结果及分析(包括结果描述、实验现象分析、影响因素讨论、综合分析和结论等)
(1)输入字符串begin x:=9; if x>0 then x:= 2*x+1/3; end #
其结果如下图所示
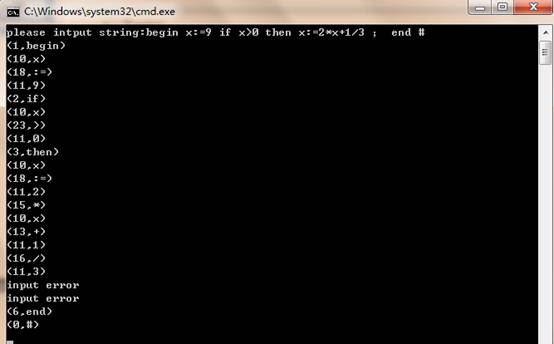
(2)输入字符串hello#其输出结果如下图所示:

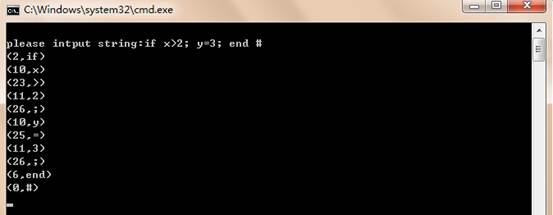
(3)输入字符串if x>2; y=3; end #其结果如下图所示:
实验二 语法分析程序实现
一、实验目的与要求
通过设计、编制、调试一个典型的语法分析程序(任选有代表性的语法分析方法,如算符优先法、递归下降法、LL(1)、SLR(1)、LR(1)等,作为编制语法分析程序的依据),对扫描器所提供的单词序列进行语法检查和结构分析,实现并进一步掌握常用的语法分析方法。
二、实验内容
选择对各种常见高级程序设计语言都较为通用的语法结构作为分析对象,给出其文法描述(注意应与所采用的语法分析方法比较贴近),设计并实现一个完整的语法分析程序。
输入:源程序以文件的形式输入。
输出:对于所输入的源程序,如果输入符号串是给定文法定义的合法句子,则输出“RIGHT”,并且给出每一步归约的过程;如果不是句子,即输入串有错误,则输出“ERROR”,并且显示已经归约出的各个文法符号。
三、基本实验题目
以如下文法G1所定义的算术表达式的赋值语句作为分析对象,编写并调试一个语法分析程序。
G1[<赋值语句>]:
<赋值语句> → <变量>:=<算术表达式>
<算术表达式> → <项> | <算术表达式>+<项> | <算术表达式>-<项>
<项> → <因式> | <项>*<因式> | <项>/<因式>
<因式> → <变量> | <常数> | (<算术表达式>)
<变量> → <标识符>
<标识符> → <标识符> <字母> | <标识符> <数字> | <字母>
<常数> → <整数> | <浮点数>
<整数> → <数字> | <数字> <整数>
<浮点数> → ? <整数> | <整数> ? <整数>
<字母> → A|B|C|…|X|Y|Z|a|b|c|…|x|y|z
<数字> → 0|1|2|…9
四、源程序
#include<iostream>
using namespace std;
#include<stdio.h>
#include<string.h>
#define MAX 150 //词法分析表的最大容量
#define MAXBUF 255 //缓冲区的最大缓冲量
void term();
void lrparser();
void statement();
void yucu();
void expression();
void factor();
char prog[MAXBUF],token[MAX];
char ch;
int syn,p,m,n,sum,kk;
char * rwtab[6]={"begin","if","then","while","do","end"};
//////////////////////////////////////////////////////////
/*词法扫描程序:*/
void scaner()
{
for(m=0;m<MAX;m++)
token[m]=NULL;
m=0;sum=0;
ch=prog[p++];
while(ch==' ')ch=prog[p++];
if((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A'))
{
while((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')||(ch<='9'&&ch>='0'))
{
token[m++]=ch;
ch=prog[p++]; //读取下一个字符
}
token[m++]='\0';
ch=prog[--p];
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1; //给出syn值
break;
}
}
else
if((ch<='9'&&ch>='0'))
{
sum=0;
while((ch<='9'&&ch>='0'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
ch=prog[--p];
syn=11;
}
else
switch(ch)
{
case '<':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='>')
{
syn=21;
token[m++]=ch;
}
else
if(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=20;
ch=prog[--p];
}
break;
case '>':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
ch=prog[--p];
}
break;
case ':':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
ch=prog[--p];
}
break;
case '+':syn=13;token[0]=ch;break;
case '-':syn=14;token[0]=ch;break;
case '*':syn=15;token[0]=ch;break;
case '/':syn=16;token[0]=ch;break;
case ':=':syn=18;token[0]=ch;break;
case '<>':syn=21;token[0]=ch;break;
case '<=':syn=22;token[0]=ch;break;
case '>=':syn=24;token[0]=ch;break;
case '=':syn=25;token[0]=ch;break;
case ';':syn=26;token[0]=ch;break;
case '(':syn=27;token[0]=ch;break;
case ')':syn=28;token[0]=ch;break;
case '#':syn=0;token[0]=ch;break;
default:syn=-1;
break;
}
}
///////////////////////////////////////////////////////
void statement()
{
if (syn==10)
{
scaner(); //读下一个单词符号
if (syn==18)
{
scaner(); //读下一个单词符号
expression(); //调用expression函数
}
else
{
printf("error!");
kk=1;
}
}
else
{
printf("error!");
kk=1;
}
return;
}
////////////////////////////////////////////////////////
void expression()
{
term();
while(syn==13 || syn==14)
{
scaner();
term();
}
return;
}
///////////////////////////////////////////////////////
void term()
{
factor();
while(syn==15 || syn==16)
{
scaner();
factor();
}
return;
}
//////////////////////////////////////////////////////
void lrparser()
{
if (syn==1) //begin
{
scaner();
yucu();
if (syn==6) //end
{
scaner();
if (syn==0 && kk==0) printf("success \n");
}
else
{
if(kk!=1) printf("error,lose 'end' ! \n");
kk=1;
}
}
else
{
printf("error,lose 'begin' ! \n");
kk=1;
}
return;
}
/////////////////////////////////////////////////////
void yucu()
{
statement();
while(syn==26) //;
{
scaner();
statement();
}
return;
}
/////////////////////////////////////////////////////
void factor()
{
if(syn==10 || syn==11) scaner(); //为标识符或整常数时,读下一个单词符号
else if(syn==27)
{
scaner();
expression();
if(syn==28) scaner();
else {printf(" ')' 错误\n"); kk=1;}
}
else { printf("表达式错误\n"); kk=1;}
return;
}
////////////////////////////////////////////////////
void main()
{p=0;
printf("********************语法分析程序***************\n");
printf("请输入源程序:\n");
do
{ scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
scaner();
lrparser();
printf("语法分析结束!\n");
}
五、实验结果及分析(包括结果描述、实验现象分析、影响因素讨论、综合分析和结论等)
(1)输入字符串begin x:=2*y end #其结果如下图所示:

(2)输入的字符串少了begin,则会有提示信息:

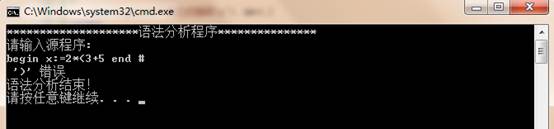
(3)输入的字符串的括号不全,也会有提示信息:
对课程实验的评分:

指导老师签字:
时间: 年 月 日