
武汉理工大学
学生实验报告书
实验课程名称 编译原理
开 课 学 院 计算机科学与技术学院
指导老师姓名 饶文碧
学 生 姓 名
学生专业班级
— 学年 第学期
实验课程名称: 编译原理

实验课程名称: 编译原理

第二篇:编译原理_实验报告
编译原理实验报告
《编译原理》实验教学大纲
一、课程名称:编译原理(Principle of Compiler)
二、课程编码:4111204
三、课程总学时: 72 学时[理论: 54 学时;实验: 18 学时
四、课程总学分: 4 学分
五、适用专业和开课学期:计算机科学与技术专业,第7学期。
六、实验的目的与任务:
编译原理是计算机类专业特别是计算机软件专业的一门重要专业课。设置该课程的目的在于系统地向学生讲述编译系统的结构、工作流程及编译程序各组成部分的设计原理和实现技术,使学生通过学习既掌握编译理论和方法方面的基本知识,也具有设计、实现、分析和维护编译程序等方面的初步能力。编译原理是一门理论性和实践性都比较强的课程。进行上机实验的目的是使学生通过完成上机实验题目加深对课堂教学内容的理解。同时培养学生实际动手能力。
七、主要仪器设备及台(套)数:一人一机。
八、主要实验教材(指导书)及参考用书:
[1]《编译原理》,吕映芝、张素琴、蒋维杜,清华大学出版社,1998年出版
[2] 《编译程序设计原理》,杜书敏、王永宁,北京大学出版社,1988年出版
[3] 《计算机编译原理》,张幸儿,科学出版社,1999年出版
[4]《编译程序原理与技术》,李赣生等,清华大学出版社,1997年10月出版。
九、成绩考核方式及评分标准:
由指导教师结合实验报告质量及学习态度等采用5级记分制评分。实验成绩占期终综合测评成绩的30%。
十、实验开出率:100%
十一、实验项目与要求:
实验一:词法分析
一、实验目的
给出PL/0文法规范,要求编写PL/0语言的词法分析程序。
二、实验准备
微机CPU主频1.3G以上,128M内存,安装好C语言,PASCAL语言,或C++。
三、实验时间
6学时
四、实验内容
已给PL/0语言文法,输出单词(关键字、专用符号以及其它标记)。
二.实验内容
1、格式
输入:源程序文件。 输出:关键字、专用符号以及其它标记。
2、编译对象:
包含如下基本内容 1) 变量说其它标记: 明语句 2) 赋值语句 3) 条件转移语句 4) 表达式(算术表达式和逻辑表达式) 5) 循环语句 6) 过程调用语句
3、 实现过程
本次实验所用的语言为标准C,以下同。本功能实现的主函数为getToken函数。通过从文件中读取字符到缓冲区中并由C语言字符的状态转换图流程判断返回一个字符(Token)。分析出来的Token主要分为关键字,专用符号,标记符号。
本实验实现的C语言的基本词法如下:
关键字: els if int return void while
专用符号: + - * / < >= == != = ; , ( ) [ ] { } /* */
其它标记: id num
ID = letter letter*
NUM = digit digit*
letter = a|b|...|z|A|B|...|Z|
ditit= 0|1|...|9
通过在C语言中定义一个枚举类型来识别这些符号:
PL/0语言的EBNF表示
<常量定义>::=<标识符>=<无符号整数>;
<标识符>::=<字母>={<字母>|<数字>};
<加法运算符>::=+|-
<乘法运算符>::=*|/
<关系运算符>::==|#|<|<=|>|>=
<字母>::=a|b|…|X|Y|Z
<数字>::=0|1|2|…|8|9
4、主体结构的说明
在这里说明部分告诉我们使用的LETTER,DIGIT, IDENT(标识符,通常定义为字母开头的字母数字串)和STR(字符串常量,通常定义为双引号括起来的一串字符)是什么意思.这部分也可以包含一些初始化代码.例如用#include来使用标准的头文件和前向说明(forward ,references).这些代码应该再标记"%{"和"%}"之间;规则部分>可以包括任何你想用来分析的代码;我们这里包括了忽略所有注释中字符的功能,传送ID名称和字符串常量内容到主调函数和main函数的功能.
5、实现原理
程序中先判断这个句语句中每个单元为关键字、常数、运算符、界符,对与不同的单词符号给出不同编码形式的编码,用以区分之。
三:设计过程
1. 关键字:void,main,if,then,break,int,Char,float,include,for,while,printfscanf 并为小写。
2."+”;”-”;”*”;”/”;”:=“;”:”;”<“;”<=“;”>“;”>=“;”<>“;”=“;”(“;”)”;”;”;”#”为运算符。
3. 其他标记 如字符串,表示以字母开头的标识符。
4. 空格符跳过。
5. 各符号对应种别码
关键字分别对应1-13
运算符分别对应401-418,501-513。
字符串对应100
常量对应200
结束符#
四:举例说明
目标:实现对常量的判别
代码:
digit [0-9]
letter [A-Za-z]
other_char [!-@\[-~]
id ({letter}|[_])({letter}|{digit}|[_])*
string {({letter}|{digit}|{other_char})+}
int_num {digit}+
%%
[ |\t|\n]+
"auto"|"double"|"int"|"struct"|"break"|"else"|"long"|"switch"|"case"|"enum"|"register"|"typedef"|"char"|"extern"|"return"|"union"|"const"|"float"|"short"|"unsigned"|"continue"|"for"|"signed"|"void"|"default"|"goto"|"sizeof"|"do"|"if"|"static"|"while"|"main" {Upper(yytext,yyleng);printf("%s,NULL\n",yytext);}
\"([!-~])*\" {printf("CONST_string,%s\n",yytext);}
-?{int_num}[.]{int_num}?([E][+|-]?{int_num})? {printf("CONST_real,%s\n",yytext);}
"0x"?{int_num} {printf("CONST_int,%s\n",yytext);}
","|";"|"("|")"|"{"|"}"|"["|"]"|"->"|"."|"!"|"~"|"++"|"--"|"*"|"&"|"sizeof"|"/"|"%"|"+"|"-"|">"|"<"|">="|"<="|"=="|"!="|"&"|"^"|"|"|"&"|"||"|"+="|"-="|"*="|"/="|"%="|">>="|"<<="|"&="|"^="|"|="|"=" {printf("%s,NULL\n",yytext);}
{id} {printf("ID,%s\n",yytext);}
{digit}({letter})+ {printf("error1:%s\n",yytext);}
%%
#include <ctype.h>
Upper(char *s,int l)
{
int i;
for(i=0;i<l;i++)
{
s[i]=toupper(s[i]);
}
}
yywrap()
{
return 1;
}
五:源程序:
#include<iostream.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int i,j,k,flag,number,status;
/*status which is use to judge the string is keywords or not!*/
char ch;
char words[10] = {" "};
char program[500];
int Scan(char program[])
{
char *keywords[13] = {"void","main","if","then","break","int", "char", "float", "include","for","while","printf", "scanf"};
number = 0; status = 0;
j = 0;ch = program[i++]; /* To handle the lettle space ands tab*/
/*handle letters*/
if ((ch >= 'a') && (ch <= 'z' ))
{
while ((ch >= 'a') && (ch <= 'z' ))
{
words[j++]=ch;
ch=program[i++];
}
i--;
words[j++] = '\0';
for (k = 0; k < 13; k++)
if (strcmp (words,keywords[k]) == 0)
switch(k)
{
case 0:{
flag = 1;
status = 1;
break;
}
case 1:{
flag = 2;
status = 1;
break;
}
case 2:{
flag = 3;
status = 1;
break;
}
case 3:{
flag = 4;
status = 1;
break;
}
case 4:{
flag = 5;
status = 1;
break;
}
case 5:{
flag = 6;
status = 1;
break;
}
case 6:{
flag = 7;
status = 1;
break;
}
case 7:{
flag = 8;
status = 1;
break;
}
case 8:{
flag = 9;
status = 1;
break;
}
case 9:{
flag = 10;
status = 1;
break;
}
case 10:{
flag = 11;
status = 1;
break;
}
case 11:{
flag = 12;
status = 1;
break;
}
case 12:{
flag = 13;
status = 1;
break;
}
}
if (status == 0)
{
flag = 100;
}
}
/*handle digits*/
else if ((ch >= '0') && (ch <= '9'))
{
number = 0;
while ((ch >= '0' ) && (ch <= '9' ))
{
number = number*10+(ch-'0');
ch= program[i++];
}
flag = 200;
i--;
}
/*opereation and edge handle*/
else switch (ch)
{
case '=':{
if (ch == '=')
words[j++] = ch;
words[j]= '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j]= '\0';
flag = 401;
}
else
{
i--;
flag = 402;
}
break;
}
case'>':{
if (ch == '>')
words[j++] = ch;
words[j] = '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j] = '\0';
flag = 403;
}
else
{
i--;
flag = 404;
}
break;
}
case'<':{
if (ch == '<')
words[j++] = ch;
words[j] = '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j]= '\0';
flag = 405;
}
else
{
i--;
flag = 406;
}
break;
}
case'!':{
if (ch == '!')
words[j++] = ch;
words[j]= '\0';
ch = program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j]= '\0';
flag= 407;
}
else
{
i--;
flag = 408;
}
break;
}
case'+':{
if (ch == '+')
words[j++] = ch;
words[j] = '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j] = '\0';
flag= 409;
}
else if (ch == '+')
{
words[j++] = ch;
words[j] = '\0';
flag= 410;
}
else
{
i--;
flag= 411;
}
break;
}
case'-':{
if (ch == '-')
words[j++] = ch;
words[j] = '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j] = '\0';
flag = 412;
}
else if( ch == '-')
{
words[j++] = ch;
words[j] = '\0';
flag = 413;
}
else
{
i--;
flag = 414;
}
break;
}
case'*':{
if (ch == '*')
words[j++] = ch;
words[j] = '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j] = '\0';
flag = 415;
}
else
{
i--;
flag = 416;
}
break;
}
case'/':{
if (ch == '/')
words[j++] = ch;
words[j] = '\0';
ch= program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j] = '\0';
flag= 417;
}
else
{
i--;
flag = 418;
}
break;
}
case';':{
words[j] = ch;
words[j+1] = '\0';
flag = 501;
break;
}
case'(':{
words[j] = ch;
words[j+1] = '\0';
flag = 502;
break;
}
case')':{
words[j] = ch;
words[j+1] = '\0';
flag = 503;
break;
}
case'[':{
words[j] = ch;
words[j+1] = '\0';
flag = 504;
break;
}
case']':{
words[j] = ch;
words[j+1] = '\0';
flag = 505;
break;
}
case'{':{
words[j] = ch;
words[j+1] = '\0';
flag= 506;
break;
}
case'}':{
words[j] = ch;
words[j+1] = '\0';
flag = 507;
break;
}
case':':{
words[j] = ch;
words[j+1] = '\0';
flag = 508;
break;
}
case'"':{
words[j] = ch;
words[j+1] = '\0';
flag = 509;
break;
}
case'%':{
if (ch == '%')
words[j++] = ch;
words[j] = '\0';
ch = program[i++];
if (ch == '=')
{
words[j++] = ch;
words[j] = '\0';
flag= 510;
}
else
{
i--;
flag = 511;
}
break;
}
case',':{
words[j] = ch;
words[j+1] = '\0';
flag = 512;
break;
}
case'#':{
words[j] = ch;
words[j+1] = '\0';
flag = 513;
break;
}
case'@':{
words[j] = '#';
flag = 0;
break;
}
default:{
flag = -1;
break;
}
}
return flag;
}
main()
{
i=0;
printf("please input a program end with @");
do
{
ch = getchar();
program[i++] = ch;
}while(ch != '@');
i = 0;
do{
flag = Scan(program);
if (flag == 200)
{
printf("(%2d,%4d)",flag,number);
}
else if (flag == -1)
{
printf("(%d,error)",flag);
}
else
{
printf("(%2d,%4s)",flag,words);
}
}while (flag != 0);
system("pause");
}
实验二:语法分析
一、实验目的
给出PL/0文法规范,要求编写PL/0语言的语法分析程序。
二、实验准备
微机CPU主频1.3G以上,128M内存,安装好C语言,PASCAL语言,或C++。
三、实验时间
6学时
四、实验内容
已给PL/0语言文法,利用递归子程序法,编制语法分析程序,要求将错误信息输出到语法错误文件中,输出语法树。
PL/0语法如下:
<程序>"<分程序>.
<分程序> "[<常量说明>][<变量说明>][<过程说明>]<语句>
<常量说明> "CONST<常量定义>{,<常量定义>};
<常量定义> "<标识符>=<无符号整数>
<无符号整数> " <数字>{<数字>}
<变量说明> "VAR <标识符>{, <标识符>}
<标识符> "<字母>{<字母>|<数字>}
<过程说明> "<过程首部><分程序>{; <过程说明> }
<过程首部> "PROCEDURE <标识符>;
<语句> "<赋值语句>|<条件语句>|<当循环语句>|<过程语句>
|<复合语句>|<读语句><写语句>
<赋值语句> "<标识符>:=<表达式>
<复合语句> "BEGIN <语句> {;<语句> }END
<条件语句> " <表达式> <关系表达式> <表达式> |ODD<表达式>
<表达式> " [+|-]<项>{<加碱运算符> <项>}
还有10条规则构成了PL/0语言,为此文法写一个语法分析器。
CONST A=10;
VAR B,C;
 PROCEDURE Q;
PROCEDURE Q;
VAR X;
BEGIN
READ(X);
B:=X;
WHILE X#0
X:=X-1;
END;
BEGIN
WRITE(A);
CALL Q;
END.
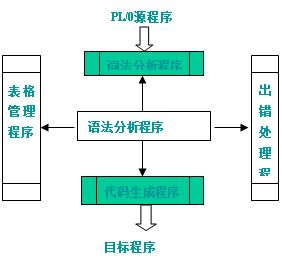
(1)PL/0编译程序结构
递归子程序法:
对于每个非终结符,编写一个子程序,由该子程序负责识别该语法单位是否正确。
表达式的文法
〈表达式〉∷=[+|-]〈项〉{(+|-)〈项〉}
〈项〉∷=〈因子〉{(*|/)〈因子〉}
〈因子〉∷=〈标识符〉|〈无符号整数〉|‘(’〈表达式〉‘)’
〈表达式〉的递归子程序实现
procedure expr;
begin
if sym in [ plus, minus ] then
begin
getsym; term;
end
else term;
while sym in [plus, minus] do
begin
getsym; term;
end
end;
〈项〉∷=〈因子〉{(*|/)〈因子〉}
〈项〉的递归子程序实现
procedure term;
begin
factor;
while sym in [ times, slash ] do
begin
getsym; factor;
end
end;
〈因子〉∷=〈标识符〉|〈无符号整数〉|‘(’〈表达式〉‘)’
〈因子〉的递归子程序实现
procedure factor;
begin
if sym <> ident then
if sym <> number then
if sym = ‘(‘ then
begin
getsym;
expr;
if sym = ‘)’ then getsym
else error
end
else error
else getsym
else getsym
end;
程序核心代码和注释:
public void analyzer()
{
//***************************
//循环读取grammar.txt
//***************************
/*此处代码略*/
//***************************
//循环读取 lengh.txt
//***************************
/*此处代码略*/
//****************************
// 读入文件,进行语法分析
//
//****************************
string strReadFile;
strReadFile="input.txt";
myTextRead.myStreamReader=new StreamReader(strReadFile);
string strBufferText;
int wid =0;
Console.WriteLine("分析读入程序(记号ID):\n");
do
{
strBufferText =myTextRead.myStreamReader.ReadLine();
if(strBufferText==null)
break;
foreach (String subString in strBufferText.Split())
{
if(subString!="")
{
int ll;
if(subString!=null)
{
ll= subString.Length; //每一个长度
}
else
{
break;
}
int a=ll+1;
char[] b = new char[a];
StringReader sr = new StringReader(subString);
sr.Read(b, 0, ll); //把substring 读到char[]数组里
int sort=(int)b[0];
// word[i] 和 wordNum[i]对应
//先识别出一整个串,再根据开头识别是数字还是字母
Word[wid]=subString;
if(subString.Equals("void"))
{wordNum[wid]=0;}
else
{
if(subString.Equals("main"))
{wordNum[wid]=1;}
else
{
if(subString.Equals("()"))
{wordNum[wid]=2;}
else
{
if(subString.Equals("{"))
{wordNum[wid]=3;}
else
{
if(subString.Equals("int"))
{wordNum[wid]=4;}
else
{
if(subString.Equals("="))
{wordNum[wid]=6;}
else
{
if(subString.Equals("}"))
{wordNum[wid]=22;}
else
{
if(subString.Equals(";"))
{wordNum[wid]=23;}
else //识别变量和数字
{
if(sort>47&sort<58)
{wordNum[wid]=7;}
else
{wordNum[wid]=5;}
}
}
}
}
}
}
}
}
Console.Write(subString+"("+wordNum[wid]+")"+" ");
wid++;
}
}
Console.WriteLine("\n");
}while (strBufferText!=null);
wordNum[wid]=24;
myTextRead.myStreamReader.Close();
//*********************************
//读入LR分析表
//
//***********************************
/*此处代码略*/
int[] state = new int[100];
string[] symbol =new string[100];
state[0]=0;
symbol[0]="#";
int p1=0;
int p2=0;
Console.WriteLine("\n按文法规则归约顺序如下:\n");
//***************
// 归约算法如下所显示
//***************
while(true)
{
int j,k;
j=state[p2];
k=wordNum[p1];
t=LR[j,k]; //当出现t为0的时候
if(t==0)
{
//错误类型
string error;
if(k==0)
error="void";
else
if(k==1)
error="main";
else
if(k==2)
error="()";
else
if(k==3)
error="{";
else
if(k==4)
error="int";
else
if(k==6)
error="=";
else
if(k==22)
error="}";
else
if(k==23)
error=";";
else
error="其他错误符号";
Console.WriteLine("\n检测结果:");
Console.WriteLine("代码中存在语法错误");
Console.WriteLine("错误状况:错误状态编号为 "+j+" 读头下符号为 "+error);
break;
}
else
{
if(t==-100) //-100为达到接受状态
{
Console.WriteLine("\n");
Console.WriteLine("\n检测结果:");
Console.WriteLine("代码通过语法检测");
break;
}
if(t<0&&t!=-100) //归约
{
string m=grammar[-t];
Console.Write(m+" "); //输出开始符
int length=lengh[-t];
p2=p2-(length-1);
Search mySearch=new Search();
int right=mySearch.search(m);
if(right==0)
{
Console.WriteLine("\n");
Console.WriteLine("代码中有语法错误");
break;
}
int a=state[p2-1];
int LRresult= LR[a,right];
state[p2]=LRresult;
symbol[p2]=m;
}
if(t>0)
{
p2=p2+1;
state[p2]=t;
symbol[p2]=Convert.ToString(wordNum[p1]);
p1=p1+1;
}
}
}
myTextRead.myStreamReader.Close();
Console.Read();
}
实验三:语义分析
一、实验目的
给出PL/0文法规范,要求编写PL/0语言的语义分析程序。
二、实验准备
微机CPU主频1.3G以上,128M内存,安装好C语言,PASCAL语言,或C++。
三、实验时间
6学时
四、实验内容
已给PL/0语言文法,条件语句的翻译分析程序设计(输出四元式)
题 目: 条件语句的翻译分析程序设计(输出四元式)
初始条件:
理论:学完编译课程,掌握一种计算机高级语言的使用。
实践:计算机实验室提供计算机及软件环境。如果自己有计算机可以在其上进行设计。
要求完成的主要任务: (包括课程设计工作量及其技术要求,以及说明书撰写等具体要求)
(1) 写出符合LL(1)法的文法及属性文法。
(2) 完成题目要求的中间代码四元式的描述。
(3) 写出LL(1)法的思想,完成语义分析程序设计。
(4) 编制好分析程序后,设计若干用例,上机测试并通过所设计的分析程序。
(5) 设计报告格式按附件要求书写。课程设计报告书正文的内容应包括: 问题描述; 文法及属性文法的描述; 语法分析方法及中间代码形式的描述; 简要的分析与概要设计; 详细的算法描述; 给出软件的测试方法和测试结果。
五、源代码程序:
#include "stdio.h"
#include "stdlib.h"
#define MaxRuleNum 8
#define MaxVnNum 5
#define MaxVtNum 5
#define MaxStackDepth 20
#define MaxPLength 20
#define MaxStLength 50
/*-----------------main struct define-----------------*/
/*
声明:非终结符序号 = 100 + Vn的下标
终结符序号 = Vn的下标
*/
/*++++++++++文法结构++++++++++*/
struct pRNode /*产生式右部结构*/
{
int rCursor; /*右部序号*/
struct pRNode *next;
};
struct pNode /*产生式结点结构*/
{
int lCursor; /*左部符号序号*/
int rLength; /*右部长度*/
/*注当rLength = 1 时,rCursor = -1为空产生式*/
struct pRNode *rHead; /*右部结点头指针*/
};
char Vn[MaxVnNum + 1]; /*非终结符集*/
int vnNum;
char Vt[MaxVtNum + 1]; /*终结符集*/
int vtNum;
struct pNode P[MaxRuleNum]; /*产生式*/
int PNum; /*产生式实际个数*/
char buffer[MaxPLength + 1];
char ch; /*符号或string ch;*/
char st[MaxStLength]; /*要分析的符号串*/
/*++first and follow collect struct++*/
struct collectNode /*集合元素结点结构*/
{
int nVt; /*在终结符集中的下标*/
struct collectNode *next;
};
struct collectNode* first[MaxVnNum + 1]; /*first集*/
struct collectNode* follow[MaxVnNum + 1]; /*follow集*/
/*+++++++++++++analysis table struct++++++++++++++++*/
int analyseTable[MaxVnNum + 1][MaxVtNum + 1 + 1];
/*预测分析表存放为产生式的编号,+1用于存放结束符,多+1用于存放#(-1)*/
/*+++++++++++++++analysis stack struct++++++++++++++*/
int analyseStack[MaxStackDepth + 1]; /*分析栈*/
int topAnalyse; /*分析栈顶*/
/*int reverseStack[MaxStackDepth + 1]; /*颠倒顺序栈*/
/*int topReverse; /*倒叙栈顶*/
/*------------------function declare---------------*/
void Init();/*初始化*/
int IndexCh(char ch);
/*返回Vn在Vn表中的位置+100、Vt在Vt表中的位置,-1表示未找到*/
void InputVt(); /*输入终结符*/
void InputVn();/*输入非终结符*/
void ShowChArray(char* collect, int num);/*输出Vn或Vt的内容*/
void InputP();/*产生式输入*/
bool CheckP(char * st);/*判断产生式正确性*/
void First(int U);/*计算first集,U->xx...*/
void AddFirst(int U, int nCh); /*加入first集*/
bool HaveEmpty(int nVn); /*判断first集中是否有空(-1)*/
void Follow(int V);/*计算follow集*/
void AddFollow(int V, int nCh, int kind);/*加入follow集,
kind = 0表加入follow集,kind = 1加入first集*/
void ShowCollect(struct collectNode **collect);/*输出first或follow集*/
void FirstFollow();/*计算first和follow*/
void CreateAT();/*构造预测分析表*/
void ShowAT();/*输出分析表*/
void Identify(char *st);/*主控程序,为操作方便*/
/*分析过程显示操作为本行变换所用,与教程的显示方式不同*/
void InitStack();/*初始化栈及符号串*/
void ShowStack();/*显示符号栈中内容*/
void Pop();/*栈顶出栈*/
void Push(int r);/*使用产生式入栈操作*/
LL1.CPP :
/*-------------------------*/
#include "LL1.h"
/*----main function--------*/
void main(void)
{
char todo,ch;
Init();
InputVn();
InputVt();
InputP();
getchar();
FirstFollow();
printf("所得first集为:");
ShowCollect(first);
printf("所得follow集为:");
ShowCollect(follow);
CreateAT();
ShowAT();
todo = 'y';
while('y' == todo)
{
printf("\n是否继续进行句型分析?(y / n):");
todo = getchar();
while('y' != todo && 'n' != todo)
{
printf("\n(y / n)? ");
todo = getchar();
}
if('y' == todo)
{
int i;
InitStack();
printf("请输入符号串(以#结束) : ");
ch = getchar();
i = 0;
while('#' != ch && i < MaxStLength)
{
if(' ' != ch && '\n' != ch)
{
st[i++] = ch;
}
ch = getchar();
}
if('#' == ch && i < MaxStLength)
{
st[i] = ch;
Identify(st);
}
else
printf("输入出错!\n");
}
}
getchar();
}
/*--------function definition-------*/
void Init()
{
int i,j;
vnNum = 0;
vtNum = 0;
PNum = 0;
for(i = 0; i <= MaxVnNum; i++)
Vn[i] = '\0';
for(i = 0; i <= MaxVtNum; i++)
Vt[i] = '\0';
for(i = 0; i < MaxRuleNum; i++)
{
P[i].lCursor = NULL;
P[i].rHead = NULL;
P[i].rLength = 0;
}
PNum = 0;
for(i = 0; i <= MaxPLength; i++)
buffer[i] = '\0';
for(i = 0; i < MaxVnNum; i++)
{
first[i] = NULL;
follow[i] = NULL;
}
for(i = 0; i <= MaxVnNum; i++)
{
for(j = 0; j <= MaxVnNum + 1; j++)
analyseTable[i][j] = -1;
}
}
/*返回Vn在Vn表中的位置+100、Vt在Vt表中的位置,-1表示未找到*/
int IndexCh(char ch)
{
int n;
n = 0; /*is Vn?*/
while(ch != Vn[n] && '\0' != Vn[n])
n++;
if('\0' != Vn[n])
return 100 + n;
n = 0; /*is Vt?*/
while(ch != Vt[n] && '\0' != Vt[n])
n++;
if('\0' != Vt[n])
return n;
return -1;
}
/*输出Vn或Vt的内容*/
void ShowChArray(char* collect)
{
int k = 0;
while('\0' != collect[k])
{
printf(" %c ", collect[k++]);
}
printf("\n");
}
/*输入非终结符*/
void InputVn()
{
int inErr = 1;
int n,k;
char ch;
while(inErr)
{
printf("\n请输入所有的非终结符,注意:");
printf("请将开始符放在第一位,并以#号结束:\n");
ch = ' ';
n = 0;
/*初始化数组*/
while(n < MaxVnNum)
{
Vn[n++] = '\0';
}
n = 0;
while(('#' != ch) && (n < MaxVnNum))
{
if(' ' != ch && '\n' != ch && -1 == IndexCh(ch))
{
Vn[n++] = ch;
vnNum++;
}
ch = getchar();
}
Vn[n] = '#'; /*以“#”标志结束用于判断长度是否合法*/
k = n; /*k用于记录n以便改Vn[n]='\0'*/
if('#' != ch)
{
if( '#' != (ch = getchar()))
{
while('#' != (ch = getchar()))
;
printf("\n符号数目超过限制!\n");
inErr = 1;
continue;
}
}
/*正确性确认,正确则,执行下下面,否则重新输入*/
Vn[k] = '\0';
ShowChArray(Vn);
ch = ' ';
while('y' != ch && 'n' != ch)
{
if('\n' != ch)
{
printf("输入正确确认?(y/n):");
}
scanf("%c", &ch);
}
if('n' == ch)
{
printf("录入错误重新输入!\n");
inErr = 1;
}
else
{
inErr = 0;
}
}
}
/*输入终结符*/
void InputVt()
{
int inErr = 1;
int n,k;
char ch;
while(inErr)
{
printf("\n请输入所有的终结符,注意:");
printf("以#号结束:\n");
ch = ' ';
n = 0;
/*初始化数组*/
while(n < MaxVtNum)
{
Vt[n++] = '\0';
}
n = 0;
while(('#' != ch) && (n < MaxVtNum))
{
if(' ' != ch && '\n' != ch && -1 == IndexCh(ch))
{
Vt[n++] = ch;
vtNum++;
}
ch = getchar();
}
Vt[n] = '#'; /*以“#”标志结束*/
k = n; /*k用于记录n以便改Vt[n]='\0'*/
if('#' != ch)
{
if( '#' != (ch = getchar()))
{
while('#' != (ch = getchar()))
;
printf("\n符号数目超过限制!\n");
inErr = 1;
continue;
}
}
/*正确性确认,正确则,执行下下面,否则重新输入*/
Vt[k] = '\0';
ShowChArray(Vt);
ch = ' ';
while('y' != ch && 'n' != ch)
{
if('\n' != ch)
{
printf("输入正确确认?(y/n):");
}
scanf("%c", &ch);
}
if('n' == ch)
{
printf("录入错误重新输入!\n");
inErr = 1;
}
else
{
inErr = 0;
}
}
}
/*产生式输入*/
void InputP()
{
char ch;
int i = 0, n,num;
printf("请输入文法产生式的个数:");
scanf("%d", &num);
PNum = num;
getchar(); /*消除回车符*/
printf("\n请输入文法的%d个产生式,并以回车分隔每个产生式:", num);
printf("\n");
while(i < num)
{
printf("第%d个:", i);
/*初始化*/
for(n =0; n < MaxPLength; n++)
buffer[n] = '\0';
/*输入产生式串*/
ch = ' ';
n = 0;
while('\n' != (ch = getchar()) && n < MaxPLength)
{
if(' ' != ch)
buffer[n++] = ch;
}
buffer[n] = '\0';
/* printf("%s", buffer);*/
if(CheckP(buffer))
{
/*填写入产生式结构体*/
pRNode *pt, *qt;
P[i].lCursor = IndexCh(buffer[0]);
pt = (pRNode*)malloc(sizeof(pRNode));
pt->rCursor = IndexCh(buffer[3]);
pt->next = NULL;
P[i].rHead = pt;
n = 4;
while('\0' != buffer[n])
{
qt = (pRNode*)malloc(sizeof(pRNode));
qt->rCursor = IndexCh(buffer[n]);
qt->next = NULL;
pt->next = qt;
pt = qt;
n++;
}
P[i].rLength = n - 3;
i++;
/*调试时使用*/
}
else
printf("输入符号含非法在成分,请重新输入!\n");
}
}
/*判断产生式正确性*/
bool CheckP(char * st)
{
int n;
if(100 > IndexCh(st[0]))
return false;
if('-' != st[1])
return false;
if('>' != st[2])
return false;
for(n = 3; '\0' != st[n]; n ++)
{
if(-1 == IndexCh(st[n]))
return false;
}
return true;
}
/*=====first & follow========*/
/*计算first集,U->xx...*/
void First(int U)
{
int i,j;
for(i = 0; i < PNum; i++)
{
if(P[i].lCursor == U)
{
struct pRNode* pt;
pt = P[i].rHead;
j = 0;
while(j < P[i].rLength)
{
if(100 > pt->rCursor)
{
/*注:此处因编程出错,使空产生式时
rlength同样是1,故此处同样可处理空产生式*/
AddFirst(U, pt->rCursor);
break;
}
else
{
if(NULL == first[pt->rCursor - 100])
{
First(pt->rCursor);
}
AddFirst(U, pt->rCursor);
if(!HaveEmpty(pt->rCursor))
{
break;
}
else
{
pt = pt->next;
}
}
j++;
}
if(j >= P[i].rLength) /*当产生式右部都能推出空时*/
AddFirst(U, -1);
}
}
}
/*#用-1表示,kind用于区分是并入符号的first集,还是follow集
kind = 0表加入follow集,kind = 1加入first集*/
void AddFollow(int V, int nCh, int kind)
{
struct collectNode *pt, *qt;
int ch; /*用于处理Vn*/
pt = NULL;
qt = NULL;
if(nCh < 100) /*为终结符时*/
{
pt = follow[V - 100];
while(NULL != pt)
{
if(pt->nVt == nCh)
break;
else
{
qt = pt;
pt = pt->next;
}
}
if(NULL == pt)
{
pt = (struct collectNode *)malloc(sizeof(struct collectNode));
pt->nVt = nCh;
pt->next = NULL;
if(NULL == follow[V - 100])
{
follow[V - 100] = pt;
}
else
{
qt->next = pt; /*qt指向follow集的最后一个元素*/
}
pt = pt->next;
}
}
else /*为非终结符时,要区分是加first还是follow*/
{
if(0 == kind)
{
pt = follow[nCh - 100];
while(NULL != pt)
{
ch = pt->nVt;
AddFollow(V, ch, 0);
pt = pt->next;
}
}
else
{
pt = first[nCh - 100];
while(NULL != pt)
{
ch = pt->nVt;
if(-1 != ch)
{
AddFollow(V, ch, 1);
}
pt = pt->next;
}
}
}
}
/*输出first或follow集*/
void ShowCollect(struct collectNode **collect)
{
int i;
struct collectNode *pt;
i = 0;
while(NULL != collect[i])
{
pt = collect[i];
printf("\n%c:\t", Vn[i]);
while(NULL != pt)
{
if(-1 != pt->nVt)
{
printf(" %c", Vt[pt->nVt]);
}
else
printf(" #");
pt = pt->next;
}
i++;
}
printf("\n");
}
/*计算first和follow*/
void FirstFollow()
{
int i;
i = 0;
while('\0' != Vn[i])
{
if(NULL == first[i])
First(100 + i);
i++;
}
i = 0;
while('\0' != Vn[i])
{
if(NULL == follow[i])
Follow(100 + i);
i++;
}
}
/*=====构造预测分析表,例:U::xyz====*/
void CreateAT()
{
int i;
struct pRNode *pt;
struct collectNode *ct;
for(i = 0; i < PNum; i++)
{
pt = P[i].rHead;
while(NULL != pt && HaveEmpty(pt->rCursor))
{
/*处理非终结符,当为终结符时,定含空为假跳出*/
ct = first[pt->rCursor - 100];
while(NULL != ct)
{
if(-1 != ct->nVt)
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
ct = ct->next;
}
pt = pt->next;
}
if(NULL == pt)
{
/*NULL == pt,说明xyz->,用到follow中的符号*/
ct = follow[P[i].lCursor - 100];
while(NULL != ct)
{
if(-1 != ct->nVt)
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
else /*当含有#号时*/
analyseTable[P[i].lCursor - 100][vtNum] = i;
ct = ct->next;
}
}
else
{
if(100 <= pt->rCursor) /*不含空的非终结符*/
{
ct = first[pt->rCursor - 100];
while(NULL != ct)
{
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
ct = ct->next;
}
}
else /*终结符或者空*/
{
if(-1 == pt->rCursor) /*-1为空产生式时*/
{
ct = follow[P[i].lCursor - 100];
while(NULL != ct)
{
if(-1 != ct->nVt)
analyseTable[P[i].lCursor - 100][ct->nVt] = i;
else /*当含有#号时*/
analyseTable[P[i].lCursor - 100][vtNum] = i;
ct = ct->next;
}
}
else /*为终结符*/
{
analyseTable[P[i].lCursor - 100][pt->rCursor] = i;
}
}
}
}
}
/*输出分析表*/
void ShowAT()
{
int i,j;
printf("构造预测分析表如下:\n");
printf("\t|\t");
for(i = 0; i < vtNum; i++)
{
printf("%c\t", Vt[i]);
}
printf("#\t\n");
printf("- - -\t|- - -\t");
for(i = 0; i <= vtNum; i++)
printf("- - -\t");
printf("\n");
for(i = 0; i < vnNum; i++)
{
printf("%c\t|\t", Vn[i]);
for(j = 0; j <= vtNum; j++)
{
if(-1 != analyseTable[i][j])
printf("R(%d)\t", analyseTable[i][j]);
else
printf("error\t");
}
printf("\n");
}
}
/*=============主控程序(四元式)=*/
void Identify(char *st)
{
int current,step,r; /*r表使用的产生式的序号*/
printf("\n%s的分析过程:\n", st);
printf("步骤\t分析符号栈\t当前指示字符\t使用产生式序号\n");
step = 0;
current = 0; /*符号串指示器*/
printf("%d\t",step);
ShowStack();
printf("\t\t%c\t\t- -\n", st[current]);
while('#' != st[current])
{
if(100 > analyseStack[topAnalyse]) /*当为终结符时*/
{
if(analyseStack[topAnalyse] == IndexCh(st[current]))
{
/*匹配出栈,指示器后移*/
Pop();
current++;
step++;
printf("%d\t", step);
ShowStack();
printf("\t\t%c\t\t出栈、后移\n", st[current]);
}
else
{
printf("%c-%c不匹配!", analyseStack[topAnalyse], st[current]);
printf("此串不是此文法的句子!\n");
return;
}
}
else /*当为非终结符时*/
{
r = analyseTable[analyseStack[topAnalyse] - 100][IndexCh(st[current])];
if(-1 != r)
{
Push(r); /*产生式右部代替左部,指示器不移动*/
step++;
printf("%d\t", step);
ShowStack();
printf("\t\t%c\t\t%d\n", st[current], r);
}
else
{
printf("无可用产生式,此串不是此文法的句子!\n");
return;
}
}
}
if('#' == st[current])
{
if(0 == topAnalyse && '#' == st[current])
{
step++;
printf("%d\t", step);
ShowStack();
printf("\t\t%c\t\t分析成功!\n", st[current]);
printf("%s是给定文法的句子!\n", st);
}
else
{
while(topAnalyse > 0)
{
if(100 > analyseStack[topAnalyse]) /*当为终结符时*/
{
printf("无可用产生式,此串不是此文法的句子!\n");
return;
}
else
{
r = analyseTable[analyseStack[topAnalyse] - 100][vtNum];
if(-1 != r)
{
Push(r); /*产生式右部代替左部,指示器不移动*/
step++;
printf("%d\t", step);
ShowStack();
if(0 == topAnalyse && '#' == st[current])
{
printf("\t\t%c\t\t分析成功!\n", st[current]);
printf("%s是给定文法的句子!\n", st);
}
else
printf("\t\t%c\t\t%d\n", st[current], r);
}
else
{
printf("无可用产生式,此串不是此文法的句子!\n");
return;
}
}
}
}
}
}
/*初始化栈及符号串*/
void InitStack()
{
int i;
/*分析栈的初始化*/
for(i = 0; i < MaxStLength; i++)
st[i] = '\0';
analyseStack[0] = -1; /*#(-1)入栈*/
analyseStack[1] = 100; /*初始符入栈*/
topAnalyse = 1;
}
/*显示符号栈中内容*/
void ShowStack()
{
int i;
for(i = 0; i <= topAnalyse; i++)
{
if(100 <= analyseStack[i])
printf("%c", Vn[analyseStack[i] - 100]);
else
{
if(-1 != analyseStack[i])
printf("%c", Vt[analyseStack[i]]);
else
printf("#");
}
}
}
/*栈顶出栈*/
void Pop()
{
topAnalyse--;
}
/*使用产生式入栈操作*/
void Push(int r)
{
int i;
struct pRNode *pt;
Pop();
pt = P[r].rHead;
if(-1 == pt->rCursor) /*为空产生式时*/
return;
topAnalyse += P[r].rLength;
for(i = 0; i < P[r].rLength; i++)
{
/*不为空产生式时*/
analyseStack[topAnalyse - i] = pt->rCursor;/*逆序入栈*/
pt = pt->next;
}/*循环未完时pt为空,则说明rLength记录等出错*/
}