科研课题总结报告
课题名称:
任务来源: 课题编号:
课题负责人: 起止时间:
承担单位:
(盖章)
已拨经费: (万元),已使用 (万元)
1、 研究、试验方法或技术路线(包括工艺流程)
2、 主要研究成果、创新点、学术意义及应用价值
3、 与原科研设计之比较(包括完成、未完成或超出完成研究内容情况)。
4、 对本课题深入研究的设想。
5、 发表(要有刊物封面、封底)或未发表的全部论文、专利证书、检测或验收报告的复印件。
6、 推广应用证明材料或论文发表后被引用情况证明。
7、 经费决算报告
8、 原科研设计书
9、所在单位意见及公章

10、卫生局意见及公章

11、计划下达部门意见及公章

第二篇:研究课题报告
附件1
研究课题报告
大型复杂数据和流数据的分析与建模
(课题开始时间2006.10 至今)
张响亮
法国自动化和计算机国家研究院(INRIA)&
法国巴黎十一大学 ;
简介 : 本课题报告介绍我在法国自动化和计算机国家研究院(INRIA)和巴黎十一大学读博士至今(2006.10 - 2009.11)的主要工作。我的博士论文方向是“基于统计机器学习方法的大型复杂数据和流数据的分析与建模”。我将通过1)研究动机和目的, 2)研究方法, 3)研究结果, 4)总结等4个部分来介绍该课题。
1. 研究动机和目的
本课题的起源是为了解决“网格计算”中的运行管理和监控问题。这里提到的“网格”指的是欧洲最大的网格计算系统,EGEE(Enabling Grids for E-sciencE)。它在50多个国家拥有250个站点,共包含68000个CPU,24小时不间断提供服务,每天大约有上百万的任务(jobs)运行在其中。
对于这样一个庞大而复杂的分布式计算系统,它的管理和监控需要很多熟练的人工操作去发现某些站点是否有问题,导致某些任务执行失败或丢失等。然而面对结构复杂、数据量极大的工作日志(logs)来说,仅仅凭借人工简单的查看是不可能做不到的。
我们课题要解决的问题就是,通过“机器学习”(Machine Learning)和 “数据挖掘”(Data Mining)的方法,对大型复杂的日志数据进行建模和分析,提取出能反映数据的有意义的模式,以一种简单、可视的方式表达给管理员,帮助他们能非常直观的发现并解决问题。
在实现这个解决方案的过程中,我们遇到了一些挑战:
i) 数据量超大,数据结果异常复杂。正如前文所述,整个网格系统中运行的任务非常
多,而每一个任务在日志中都有几十个特征来描述。同时,这些描述性的特征又有着不同的属性和类别。
1
ii) 数据的动态性。网格中的任务来自各个应用领域,如物理,化学,生物,天文等。这
些任务在用户和时间方面都表现出非常大的动态变化。比如,有的用户提交的任务需要大的CPU,有的用户需要大的内存空间;工作日中网格繁忙的时候,任务的处理会需要多的等待时间,而周末比较空闲时,则会相对轻松。这种高速的并随时间出现发生变化的数据,也称为“流数据”(streaming data)。如何处理流数据是一个难题。 在3年的研究中,我在导师的指导下可以说很好的解决了这2个数据挖掘领域的热点问题。
2. 研究方法
目前的数据挖掘领域,已经有一些针对大型数据和流数据的文献[1-6]. 我们的工作与这些文献一样,都关注用聚类(clustering)算法 将相似的点聚到一起成为类。这样整个数据就被若干个类(cluster)来表述。我们建立一个模型,这个模型记录这些类的中心,半径以及成员数等等。由此以来,数据就被模型所描述。
对于大型复杂数据和流数据,我们不可能按照常规做法,一次性将所有数据都拿来聚类,因为数据量太大而且数据在动态变化之中,一次性聚类需要很大的计算量,而且没有实时性。常用的解决方案就是,对大型数据进行分割,先局部分别聚类,然后再集中到一起整体聚类;对于流数据,由于其动态变化的特点,一般采用在线聚类(online clustering)的方法,即时更新模型。然而,目前存在的相关研究方法还有一些缺陷。具体表现在:
i) 聚类时必须提前定义整个数据中类的个数。这是目前经典的聚类算法k-means, k-
centers的必须要求。这个先验知识是很难获取的。另外更重要的一点是,对于流数据,可聚成的类的个数也是在不断变化的,因此我们很难给定一个固定的值作为参数。
流数据的结构和分布是一直在不断变化的。算法的模型应该具备跟踪变化的能力,并且检测新的类模式是否出现,并将它添加到当前模型。同时,如果模型中某些类模式已经老化,我们也应该将其弱化或者剔除,以节省空间且精确描述模型。
模型中关于类的描述,要能实时呈现出来,通过可视化方式让管理员清楚的知道目前关于数据的概括描述。 ii) iii)
为了解决聚类算法的问题,我们采用了一个非常新的方法,叫做Affinity Propagation, 简称AP [7],20xx年发表在Science上。该算法通过每一对点与点之间的消息传递迭代来最终收敛到稳定的类的划分。它的优点就是不需要提前给定类的个数,并且聚类结果优于传统的k-centers方法。但是它的致命缺点就是计算量非常大,复杂度达到?(N2logN),这里N是数据中点的个数。可想而知,大型数据中点的个数非常大,那么用AP来聚类将是一个不可能完成的任务。
针对AP的这个缺点,我们首先提出了加权AP(weighted AP(WAP))的方法。在不改变所传递的信息量的前提下,对临近点的进行整合,使得整合过的点的聚类结果与原始点的聚类结果相同。
2
在此基础上,我们还提出了针对大型数据的分级AP (Hierarchical AP(Hi-AP))的方法。具体做法是,先将大型数据?分块成N2个子集?i,然后对每一个子集?i分别使用AP聚类,得到类的中心点集合Ei?{ej,nj},其中ej是某个类的中心点,nj是某类中元素的个数。然后,我们对N2个Ei做集合,在这些中心点使用WAP进行聚类,此时,每个中心点代表的点的个数nj被考虑,影响该点传递信息的量。因此在这些中心点上用WAP聚类,就等价于用AP对所有点的聚类。
我们提出的Hi-AP方法在2组数据中分别被验证,实验结果表明,Hi-AP大大的降低了计算时间(从几分钟到几秒钟),但是聚类的效果并没有太大改变。有关结果发表在欧洲机器学习与数据挖掘领域顶级会议ECML /PKDD '2008中 [9] (同时也是国际机器学习与数据挖掘领域最好的会议之一)。同时,为了从理论上更好地验证Hi-AP算法的效果,我们对它从数学理论上进行了证明,发表在国际数据挖掘领域中最顶级的会议SIGKDD '2009中[10]。
解决了大型数据的聚类之后,我们来考虑流数据的聚类问题。我们提出了一个在线的流数据聚类算法,称为StrAP。该算法的实现简单但非常实用有效,借助算法描述表1,可以清楚的描述它的构造。
首先,如果有一个流数据,各个点数据按时间顺序到达。我们对先期到达的一小部分点用AP进行聚类,得到StrAP初始模型。
然后,当有一个点xt到达,将它与StrAP模型中的中心点比较,找出与它距离最近的点xi。 接着,判断点xt与xi之间的距离d(xi,xt)与阈值?的关系。如果距离比阈值小,说明点xt与模型是可匹配的,因此,我们简单更新StrAP模型中对应的以xi为中心的那个类。如果距离比阈值大,说明点xt与模型距离很远,是一个新的类或噪音,当前模型不能接受它,因此将它放入一个暂存盒(Reservoir),等待后续处理。
暂存盒中的点有可能是一些新的类模式,有必要在适当的时候将他们加入到模型中去。关键是什么样的时候才适当。我们有2个判断的标准去重新建立StrAP模型。一是给定暂存盒的大小,另一个是用一种检测变化的统计方法,称为Page-Hinkley [8]。当满足这2个标准之一时,我们用WAP对现有模型中的中心点和暂存盒中的点,一起进行聚类,从而得到新的模型。接着对新来的点,我们重复以上过程。通过这个过程, 我们既考虑了数据的变化(数据变化检测), 又降低了算法的复杂度(分级聚类和加权聚类)。可以满足大型复杂流数据的实时处理。
3
StrAP算法描述表1
输入: 数据流 x1,?,xt,?,
匹配阈值?
初始化:AP对数据流先期到达的部分(x1,?,xT)T个点聚类,得到StrAP 模型;
暂存盒={}
在线聚类:
--1 某新的点xt到达
--2 在模型中找到与
如果
否则
--4 将xt 放入 暂存盒 中
如果 检测到分布情况变化
--5 重新建立 StrAP模型
--6 清空 暂存盒
去第1步 重复执行直到结束 xt 距离最近的中心点 xi d(xi,xt)?? --3 更新StrAP模型
我们对StrAP分别在一组人工数据和基准数据(benchmark),进行了多方位的验证。同时还与文献[3]中的方法进行了比较。实验结果表明,我们比文献[3]中的DenStream方法,在聚类准确度方面表现好很多。具体结果发表在ECML /PKDD文章中[9]。
在验证了StrAP在基准数据上的有效性之后,我们将它用在解决开篇提到的“网格监控问题”。图1是该系统的结构图。
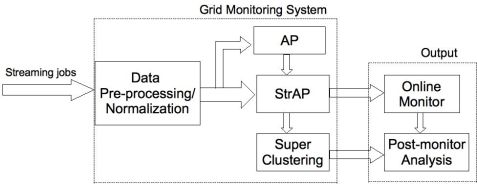
图1 实时在线网格监控系统结构图
我们将“任务流”(job streams)作为输入,经过初始化之后,每个任务被在线聚类。StrAP模型以一种总结性描述的方式记录了所有的“任务模式类”(job pattern)。这种简洁的描述可 4
以很容易被可视化(online monitor),作为输出供管理员查看。同时还有一个super clustering, 就是像Hi-AP第二层那样对StrAP中产生的类再次聚类,用来做历史数据分析(Post-monitor)。关于这个“在线实时网格监控系统”我们发表在网格计算类顶级会议CCGrid中[11]。
3 研究结果
在本报告中,我们将呈现一部分的实验结果,更多的详细研究结果发表在[9-11]中。
图2是关于大规模数据聚类算法Hi-AP的验证,我们使用了237,087个EGEE任务。图2中以聚类的Distortion作为衡量标准,我们比较了Hi-AP算法和作为基准的k-centers算法。聚类结果的Distortion定义为每个点和它所属类的中心点之间距离的平方和,D??d2(xi,ci),其中ci
i?1N
是xi点所属类的中心。很明显,Distortion越小,就说明相似的点都聚在一个类中,因此聚类的
效果就越好。当然,Distortion的比较是要基于相同的类个数(K),K越大,Distortion会越小。所以,从图2中我们可以看出在相同的K条件下,Hi-AP比基准Hi-k-centers有更小的Distortion。这里的Hi-AP simple与Hi-AP的唯一不同,就是再次聚类时,Hi-AP使用WAP,而Hi-AP simple使用AP。从而,Hi-AP的聚类效果也比Hi-AP simple 要好。
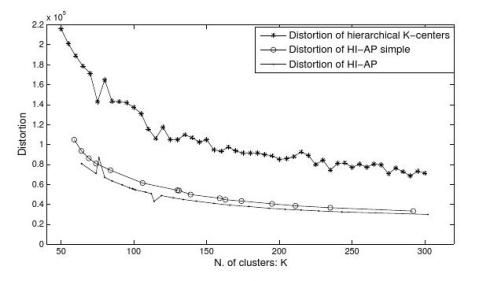
图2 Hi-AP在EGEE任务上的验证结果
图3 是我们提出的流数据聚类的StrAP方法与[3]中的DenStream方法比较的结果。两个方法都是基于完全相同的数据,一种在入侵检测领域里广泛使用的Benchmark数据(KDDcup 1999)。494,021条网络连接被在线聚类,关于聚类结果的衡量,我们使用了聚类纯度这个标准
1K|Cid|, 其中K是类个数,|Ci| 是i类中包含的点数,|Cid| 是i类中占主导性purity??Ki?1|Ci|
的点数。这里主导性可以解释为,在一个类Ci包含的点中,它们都有自己的label(表明自己的
5
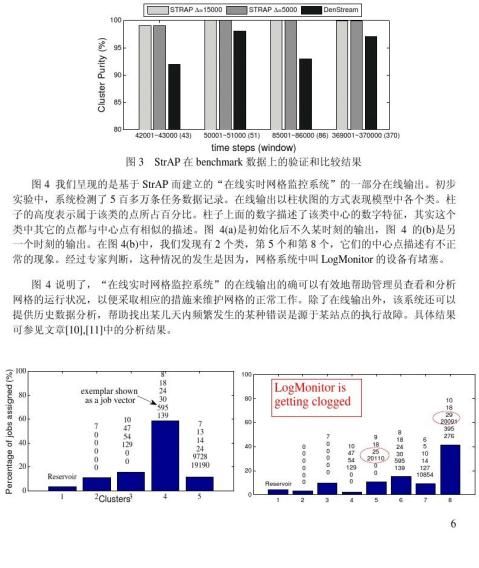
属性),有一种label是主导性的,因为拥有这个label的点最多。所以,如果一个类中的点都有相同的label,那么它的纯度就是100%。从全局出发,我们对K个类的纯度做平均,得到一种分类结果的纯度。
从图3可以看出,我们提出的StrAP明显比DenStream方法有较高的聚类纯度,具有更好的聚类效果。
(a) (b)
图4 在线实时网格监控系统的在线输出,(a)和(b)分别是不同时刻的输出
4 总结
关于“大型数据”和“流数据”的统计分析课题,源起于“复杂系统网格”的管理和分析。在对本课题的研究中,首先我们通过Hi-AP解决了“大型数据”的聚类问题,通过StrAP解决了“流数据”的聚类问题。在此基础上,我们建立了“在线实时网格监控系统”。
关于这3个部分的贡献,我们都分别在多种数据上验证过,并与基准方法进行了比较。实验结果表明,本课题中提出的方法Hi-AP和StrAP,可以更有效,更方便的解决大型复杂数据和流数据的聚类问题。同时,所开发的监控系统,也确实能够将网格的运行状况以可视化的方式呈现给管理员,帮助他们分析和维护网格情况。
事实上,Hi-AP和StrAP还可以被应用在更多方面,只要是需要对大型数据和流数据进行聚类的。一个例子就是对网络连接的检测,网络中的异常情况有千万种,但正常情况的模式都比较接近。通过StrAP,可以自主地建立并更新正常模型,则与正常模型相悖的就要引起注意了。这方面的研究工作已经开始,例如其他研究人员应用我们提出的StrAP方法在自治的入侵检测中, 相关的结果发表在[12-14]中。
我们下一步的研究分为两个方面,一方面是理论部分,我们将完善StrAP在线聚类的参数问题,之前的参数都是根据经验值选择,在[10]中我们尝试了用优化的方式来设置参数,接下来更多的简便方法将进一步使参数自适应的调整。另一个方面是应用部分,除了网络连接的应用外,我们还正在尝试用StrAP对法国移动供应商ORANGE的手机用户进行分析。将来还会有更多的应用领域等待我们尝试。
参考文献
[1] Charu C. Aggarwal, Jiawei Han, Jianyong Wang, and Philip S. Yu. A framework for
clustering evolving data streams. In Proceedings of the International Conference on Very
Large Data Bases(VLDB), pages 81–92, 2003.
[2] Paul S. Bradley, Usama M. Fayyad, and Cory Reina. Scaling clustering algorithms to large databases. In Knowledge Discovery and Data Mining, pages 9–15, 1998.
[3] F. Cao, M. Ester, W. Qian, and A. Zhou. Density-based clustering over an evolving data stream with noise. In SIAM Conference on Data Mining (SDM), pages 326–337, 2006.
[4] Yixin Chen and Li Tu. Density-based clustering for real-time stream data. In KDD ’07: Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 133–142, 2007.
[5] Sudipto Guha, Ra jeev Rastogi, and Kyuseok Shim. CURE: an e?cient clustering algo- rithm for large databases. In SIGMOD ’98: Proceedings of ACM SIGMOD international
conference on Management of data, pages 73–84, 1998.
[6] Sudipto Guha, Adam Meyerson, Nina Mishra, Ra jeev Motwani, and Liadan O’Callaghan. 7
Clustering data streams: Theory and practice. IEEE Transactions on Knowledge and
Data Engineering(TKDE), 15:515–528, 2003.
[7] B. Frey and D. Dueck. Clustering by passing messages between data points. Science, 315: 972–976, 2007.
[8] D. Hinkley. Inference about the change-point from cumulative sum tests. Biometrika, 58: 509–523, 1971.
[9] Xiangliang Zhang, Cyril Furtlehner, and Michele Sebag. Data streaming with a?nity prop- agation. In European Conference on Machine Learning and Practice of Knowledge Dis-
covery in Databases, ECML/PKDD, pages 628–643, 2008.
[10] Xiangliang Zhang, Cyril Furtlehner, Julien Perez, Cecile Germain-Renaud, and Michele Sebag. Toward autonomic grids: Analyzing the job ?ow with a?nity streaming. In
KDD ’09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, 2009.
[11] Xiangliang Zhang, Michele Sebag, and Cecile Germain-Renaud. Multi-scale real-time grid monitoring with job stream mining. In 9th IEEE International Symposium on Cluster
Computing and the Grid (CCGrid), 2009.
[12] Wei Wang, Thomas Guyet, Svein J. Knapskog, "Autonomic Intrusion Detection System",
Proceedings of 12th International Symposium On Recent Advances in Intrusion Detection (RAID), pp. 359-361, 2009.
[13] Wei Wang, Florent Masseglia, Thomas Guyet, Rene Quiniou and Marie-Odile Cordier, "A General Framework for Adaptive and Online Detection of Web attacks". Proceedings of 18th international World Wide Web conference (WWW), pp. 1141-1142, 2009 .
[14] Wei Wang, Thomas Guyet, Rene Quiniou, Marie-Odile Cordier, Florent Masseglia, "Online and adaptive anomaly Detection: detecting intrusions in unlabelled audit data streams". Proceedings of conference Extraction et Gestion des Connaissances (EGC), pp. 457-458, 2009.
8