《信息论与编码》实验报告
姓名:
班级:
学号:
年 月
实验一:绘制信源熵函数曲线
一、实验目的
1. 掌握离散信源熵的原理和计算方法。
2. 熟悉matlab软件的基本操作,练习应用matlab软件进行信源熵函数曲线的绘制。
3. 理解信源熵的物理意义,并能从信源熵函数曲线图上进行解释其物理意义。
二、实验原理
1. 离散信源相关的基本概念、原理和计算公式
产生离散信息的信源称为离散信源。离散信源只能产生有限种符号。
假定X是一个离散随机变量,即它的取值范围R={x1,x2,x3,…}是有限或可数的。设第i个变量xi发生的概率为pi=P{X=xi}。则:
定义一个随机事件的自信息量I(xi)为其对应的随机变量xi出现概率对数的负值。即:
I(xi)= -log2p(xi)
定义随机事件X的平均不确定度H(X)为离散随机变量xi出现概率的数学期望,即:
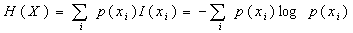
单位为 比特/符号 或 比特/符号序列。
平均不确定度H(X)的定义公式与热力学中熵的表示形式相同,所以又把平均不确定度H(X)称为信源X的信源熵。
必须注意一下几点:
a) 某一信源,不管它是否输出符号,只有这些符号具有某些概率特性,必有信源的熵值;这熵值是在总体平均上才有意义,因而是个确定值,一般写成H(X),X是指随机变量的整体(包括概率分布)。
b) 信息量则只有当信源输出符号而被接收者收到后,才有意义,这就是给与信息者的信息度量,这值本身也可以是随机量,也可以与接收者的情况有关。
c) 熵是在平均意义上来表征信源的总体特征的,信源熵是表征信源的平均不确定度,平均自信息量是消除信源不确定度时所需要的信息的量度,即收到一个信源符号,全部解除了这个符号的不确定度。或者说获得这么大的信息量后,信源不确定度就被消除了。信源熵和平均自信息量两者在数值上相等,但含义不同。
d) 当某一符号xi的概率p(xi)为零时,p(xi)log p(xi) 在熵公式中无意义,为此规定这时的 p(xi)log p(xi) 也为零。当信源X中只含有一个符号x时,必有p(x)=1,此时信源熵H(X)为零。
2. MATLAB二维绘图
三、实验内容
用matlab软件绘制二源信源熵函数曲线。根据曲线说明信源熵的物理意义。
实验过程:
输入代码
>> p = 0:0.02:1;
h = -p.*log2(p)-(1-p).*log2(1-p);
>> plot(p,h)
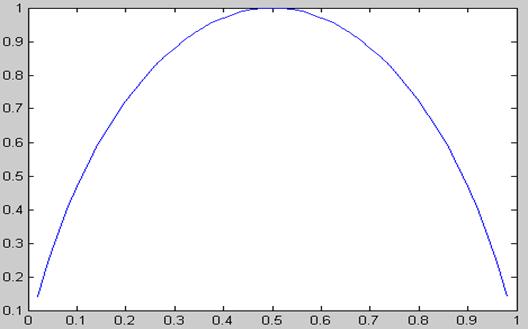
物理意义:信源熵为信源的平均不确定性,而概率的大小决定了信息量的大小。
由图上可知概率为1时,信息量最小,不确定性最低;概率等于0.5时熵最大。
实验二:哈夫曼编解码
一、实验目的
1. 掌握哈夫曼编码的原理及编码步骤
2. 练习matlab中哈夫曼编码函数的调用及通信工具箱的使用
二、实验原理
通信的根本问题是如何将信源输出的信息在接收端的信宿精确或近似的复制出来。为了有效地复制信号,就通过对信源进行编码,使通信系统与信源的统计特性相匹配。
若接收端要求无失真地精确地复制信源输出的信息,这样的信源编码即为无失真编码。即使对于一个小的时间段内,连续信源输出的信息量也可以是无限大的,所以对其是无法实现无失真编码的;而离散信源输出的信息量却可以看成是有限的,所以只有离散信源才可能实现无失真编码。
凡是能载荷一定的信息量,且码字的平均长度最短,可分离的变长码的码字集合都可以称为最佳码。为此必须将概率大的信息符号编以短的码字,概率小的符号编以长的码字,使得平均码字长度最短。
变字长编码的最佳编码定理:在变字长码中,对于概率大的信息符号编以短字长的码;对于概率小的信息符号编以长字长的码。如果码字长度严格按照符号概率的大小顺序排列,则平均码字长度一定小于俺任何顺序排列方式得到的码字长度。
哈夫曼编码就是利用了这个定理,讲等长分组的信源符号,根据其概率分布采用不等长编码。概率大的分组,使用短的码字编码;概率小的分组,使用长的码字编码。哈夫曼编码把信源按概率大小顺序排列,并设法按逆次序分配码字的长度。在分配码字的长度时,首先将出现概率最小的两个符号相加,合成一个概率;第二步把这个合成的概率看成是一个新组合符号的概率,重复上述做法,直到最后只剩下两个符号的概率为止。完成以上概率相加顺序排列后,再反过来逐步向前进行编码。每一步有两个分支,各赋予一个二进制码,可以对概率大的编为0码,概率小的编为1码。反之亦然。
哈夫曼编码的具体步骤归纳如下:
1. 统计n个信源消息符号,得到n个不同概率的信息符号。
2. 将这n个信源信息符号按其概率大小依次排序:
p(x1) ≥ p(x2)≥ …≥ p(xn)
3. 取两个概率最小的信息符号分别配以0和1两个码元,并将这两个概率相加作为一个新的信息符号的概率,和未分配的信息符号构成新的信息符号序列。
4. 将剩余的信息符号,按概率大小重新进行排序。
5. 重复步骤3,将排序后的最后两个小概论相加,相加和与其他概率再排序。
6. 如此反复重复n-2次,最后只剩下两个概率。
7. 从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字,构成霍夫曼编码字。编码结束。
哈夫曼编码产生最佳整数前缀码,即没有一个码字是另一个码字的前缀,因此哈夫曼编码是唯一码。
编码之后,哈夫曼编码的平均码长为:
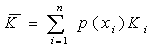
哈夫曼编码的效率为:

三、实验内容
为某一信源进行哈夫曼编码。该信源的字符集为X={x1,x2,…x6 },相应的概率矢量为:P=(0.30,0.25,0.21,0.10,0.09,0.05),即X,P的概率空间为:

根据哈夫曼编码算法对该信源进行哈夫曼编码。并计算其平均码长和编码效率。
调用matlab哈夫曼编码函数进行哈夫曼编码,与人工编码结果做比较。
huffmandict函数: 为已知概率分布的信源模型生成哈夫曼编解码索引表。
调用方法如下:
[dict,avglen] = huffmandict (symbols, p)
[dict,avglen] = huffmandict (symbols, p, N)
[dict,avglen] = huffmandict (symbols, p, N, variance)
实验过程:
>> a = [1:6];
p = [0.30 0.25 0.21 0.10 0.09 0.05];
[dict,avglen] = huffmandict(a,p)
dict =
[1] [1x2 double]
[2] [1x2 double]
[3] [1x2 double]
[4] [1x3 double]
[5] [1x4 double]
[6] [1x4 double]
avglen = 2.3800
>> [dict,avglen] = huffmandict(a,p,4)
dict =
[1] [ 1]
[2] [ 2]
[3] [1x2 double]
[4] [1x2 double]
[5] [1x2 double]
[6] [1x2 double]
avglen =1.4500
>> [dict,avglen] = huffmandict(a,p,3)
dict =
[1] [ 1]
[2] [1x2 double]
[3] [1x2 double]
[4] [1x3 double]
[5] [1x3 double]
[6] [1x3 double]
avglen =1.9400
>> [dict,avglen] = huffmandict(a,p,5)
dict =
[1] [ 1]
[2] [1x2 double]
[3] [1x2 double]
[4] [1x2 double]
[5] [1x2 double]
[6] [1x2 double]
avglen =1.7000
实验三:离散信道容量
一、实验目的
1. 掌握离散信道容量的计算。
2. 理解离散信道容量的物理意义。
3. 练习应用matlab软件进行二元对称离散信道容量的函数曲线的绘制,并从曲线上理解其物理意义。
二、实验原理
信道是传送信息的载体—信号所通过的通道。
信息是抽象的,而信道则是具体的。比如二人对话,二人间的空气就是信道;打电话,电话线就是信道;看电视,听收音机,收、发间的空间就是信道。
研究信道的目的:在通信系统中研究信道,主要是为了描述、度量、分析不同类型信道,计算其容量,即极限传输能力,并分析其特性。
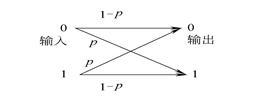
二元对称信道BSC(Binary Symmetric Channel)
二进制离散信道模型有一个允许输入值的集合X={0,1}和可能输出值的集合Y={0,1},以及一组表示输入和输出关系的条件概率(转移概率)组成。如果信道噪声和其他干扰导致传输的二进序列发生统计独立的差错,且条件概率对称,即
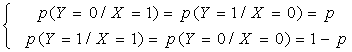
这种对称的二进制输入、二进制输出信道称做二元对称信道(或二进制对称信道,简称BSC信道),如下图所示:
信道容量公式:
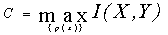
三、实验内容
BSC信道是DMC信道对称信道的特例,对于转移概率为P(0/1)=P(1/0)=p,P(0/0)=P(1/01)=1-p,求出其信道容量公式,并在matlab上绘制信道容量C与p的曲线。根据曲线说明其物理意义。
输入代码:>> p = linspace(0,1,50);
c = 1+p.*log2(p)+(1-p).*log2(1-p);
plot(p,c)
xlabel('p')
ylabel('c')
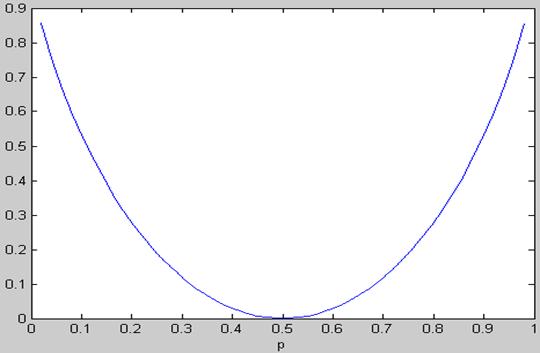
物理意义:二元对称信道容量在等可能概率时达到最小为零。在转移概率为P(0/1)=P(1/0)=0(或1),P(0/0)=P(1/01)=1(或0)时达到最大。
第二篇:实验4
中北大学经济与管理学院
实验报告
课程名称电子商务支付与结算 学号 学生姓名 辅导教师
