
燕山大学
编译原理课程设计报告
题目:PL/0编译程序的研究与改进
学 院 信息学院
年级专业 12计算机应用2班
学生姓名
学 号
指导教师
设计日期 2014年12月29日—
2015年1月2日
一丶设计目的
1.研究改进或自行设计、开发一个简单的编译程序或其部分功能
2.加深对编译理论和编译过程的理解。编程语言不限。
二丶课程设计任务
扩展PL/0编译程序功能
(1)阅读、研究PL/0编译程序源文件。
(2)在上述工作基础上,可有选择地补充、完善其中词法分析、语法分析、语义分析、目标代码生成、目标代码解释执行等部分的功能。如以语法分析部分为例,则可以增加处理更多语法成分的功能,如可处理一维数组、++、--、+=、-=、*=、/=、%(取余)、!(取反)、repeat、for、else、开方、处理注释、错误提示、标示符或变量中可以有下划线等。
三丶设计思想
1 扩充语句for(<语句>;<条件>;<语句>)<语句>;
2 扩充语句if <条件> then <语句> else <语句>;
3 增加自增自减运算++和—和+=,-=运算;
4 修改不等号#,为!=;
四丶主要变量说明
enum symbol {nul, ident, number, plus, minus, times, slash, oddsym,eql,neq, lss, leq,gtr,geq, lparen,rparen,comma, semicolon, period,becomes,
beginsym, endsym, ifsym, thensym, elsesym,
repeatsym, untilsym, forsym, whilesym, writesym,
readsym, dosym, callsym,constsym, varsym,
procsym, inc,dec, plusbk,minusbk, lbrack, rbrack,colon,
其中else, for, repeat, until, plusbk, minusbk, 为扩充
五丶算法描述
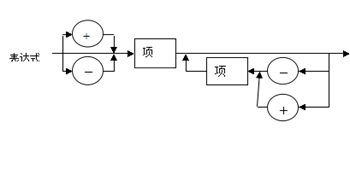
表达式语法描述图
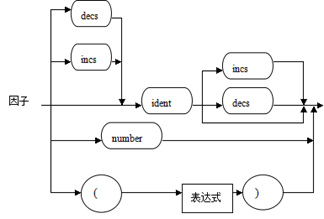
因子语法描述图
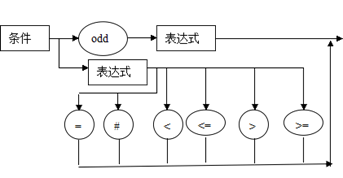
条件语法描述图
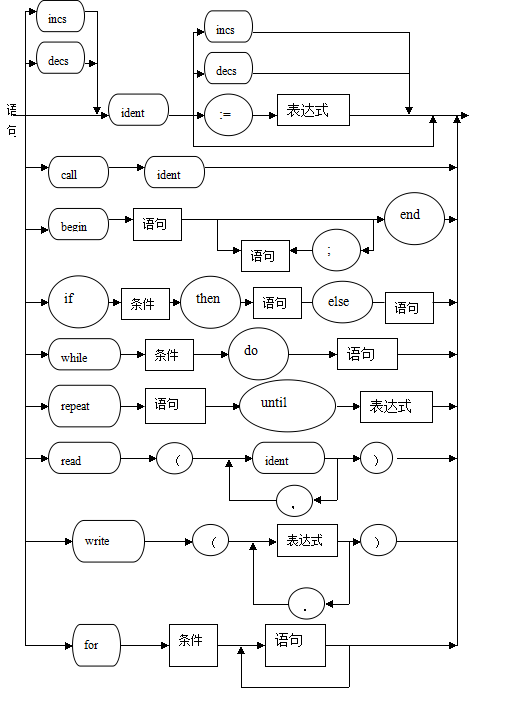
语句语法描述图
六丶程序结构
1.在语句处理中加入if-then-else语句
在原有程序if(sym==then){...}后加入下列代码:
cx1 = cx;
gendo(jpc, 0, 0);
statementdo(fsys, ptx, lev);
if(sym == elsesym){
getsymdo;
cx2 = cx;
gendo(jmp, 0, 0);
code[cx1].a = cx;
statementdo(fsys, ptx, lev);
code[cx2].a = cx;}
else
code[cx1].a = cx;
2.语句处理中加入for循环语句
if(sym == forsym){
getsymdo;
if(sym != lparen) error(34);//没有左括号出错
else {
getsymdo;
statementdo(nxtlev, ptx, lev); //S1代码
if(sym != semicolon) error(10); //语句缺少分号出错
else{
cx1=cx;
getsymdo;
conditiondo(nxtlev, ptx, lev); //E代码
if(sym!=semicolon)error(10);//语句缺少分号出错
else {
cx2=cx;
gendo(jpc,0,0);
cx3=cx;
gendo(jmp,0,0);
getsymdo;
cx4=cx;
statementdo(nxtlev, ptx, lev); //S2代码
if(sym != rparen) error(22);//缺少右括号出错
else {
gendo(jmp,0,cx1);
getsymdo;
cx5=cx;
statementdo(nxtlev, ptx, lev); //S3代码
code[cx3].a=cx5;
gendo(jmp,0,cx4);
code[cx2].a=cx;
} } } } }
3.扩充++和—运算符
对于++和--运算符,扩充时要注意存在两个情况:
1)作为语句的时候;2)作为表达式中的因子的时候。
注意:扩充时增加因子开始符facbegsys[incs]=true和facbegsys[decs]=true。
扩充的语法描述见结构设计中的PL/0分程序和主要语句的语法描述中的描述图,详细代码见程序。
1)作为语句的时候,有四种情况:
a++; a--; ++a; --a;
文法的EBNF表示形式为:
<自增自减语句>::=<标识符>[++ |--]|[++|-- ]<标识符>
文法分析过程大体如下图: 
++a和—a a++和a—
生成中间代码对于a++;++a;和a--;--a;语句的处理如下:
先将变量的值取出放在栈顶,后将1入栈,后执行加法或减法运算oprv指令的2(加法)、3(减法),后将运算后的栈顶值存回变量。
a++;和++a;语句的中间代码:lod 0 3;lit 0 1;opr 0 2;sto 0 3;
a--;和--a;语句的中间代码:lod 0 3;lit 0 1;opr 0 3;sto 0 3;
2)作为因子的时候,有两种情况:
a++和a--作为因子,比如:b:=a++*a--;语句
++a和--a作为因子,比如:b:=--a+2*++a;语句
文法的EBNF表示形式为:
<表达式>::=...[ ++|--]<标识符>|<标识符>[++| --]...
其中的...表示前后都可以有其他的项或因子
生成中间代码
①对于因子++a和--a的中间代码生成处理和a++;等语句处理一样;
②对于因子a++和a—的中间代码生成处理如下:
a++:lod 0 3;lit 0 1;opr 0 2;sto 0 3;lod 0 3;lit 0 1;opr 0 3;
a--:lod 0 3;lit 0 1;opr 0 3;sto 0 3;lod 0 3;lit 0 1;opr 0 2;
先将变量的值取出放在栈顶,后将1入栈,后执行加法或减法运算opr指令的2(加法)、3(减法),后将运算后的栈顶值存回变量,后将变量的值又取出来放入栈顶,后将1入栈,如果是a++就执行减法,如果是a—就执行加法,以实现先用a的值后再加1。
4.修改不等号#为!=
注释源程序中的ssym['#'] = neq语句,在getsym中加入下列代码:
//修改不等号为!=
else if(ch=='!'){
getchdo;
if(ch=='='){
sym=neq;
getchdo; }
else sym=nul; }
七丶运行结果
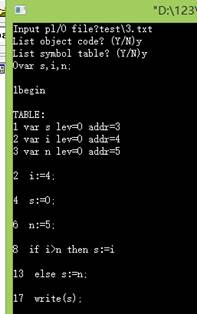
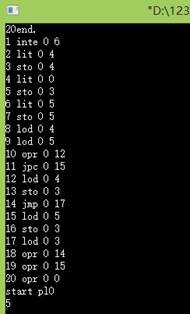
1.测试for功能
测试程序:
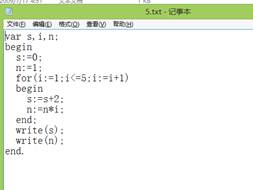
运行结果:
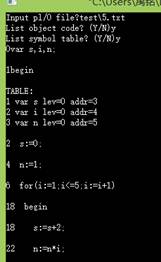
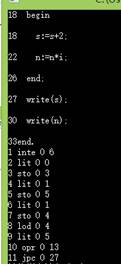

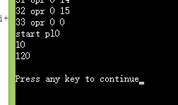
2.测试if-then-else功能
测试程序:

运行结果:
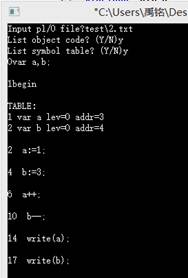
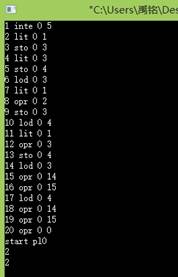
2.测试增加的++,--功能
测试程序:

运行结果:
八丶心得体会
本次课程设计是在读懂PL/0编译器程序后进行扩展功能完善程序。
由于三级项目已经做过部分内容,开始并没有遇到什么困难。但是随着深入,遇到了越来越多的困难,自己的水平不是很高,通过查资料和询问同学,克服了部分难题,也让我得到了很多的收获。也让我对PL0编译程序有了更深的了解,也让我深刻了对编译原理的理解。增强了自己的实践动手能力。虽然做的并不是很好但是,我尽了自己最大的努力去学习和研究。
总体来说,本次课程设计对PL/0编译程序的扩充让我获得很多知识,不仅让我深刻理解编译程序的思想和实现,同时也让我对编程的理解更加透彻。
第二篇:编译原理课程设计课设报告
1. 课程设计题目名称:语法高亮转换软件
2. 课程设计任务目的与任务 目 的: ·通过此次课程设计更深一步了解此法分析
·培养解决工程问题的能力,例如方案的制定
·了解设计和实现一个实际高级语言编译器所面临的各种问题及其复杂程度。 主要任务: 输入:cpp源代码文件,后缀为.cpp的文件;输出:网页文件,后缀为.html
文件;实现功能:将cpp源代码转换成网页文件,在浏览器中打开网页文件时,
网页中显示C++源代码并以高亮语法表示显示。
3. 设计思想和实现方法
设计思想:词法分析程序完成从输入文件中读取字符形式的高级语言源程序,并把输入
转化为一个由单词符号组成的流。构造词法分析器的一种简单办法是用状态
转化图来描述源语言词法记号流,然后手工把这种状态转换图翻译成为识别
记号的程序。用这种方法可以产生高效的词法分析器。
实现方法:用C++语言编写一个词法分析器,使之能识别输入串,并把分析结果(单词符号,
标识符,关键字等等)输出.输入源程序,输入单词符号,本词法分析器可以辨别
关键字,标识符,常数,运算符号和某些界符,运用了文件读入来获取源程序代
码,再对该源程序代码进行词法分析,这就是词法分析器的基本功能.当词法分
析器调用预处理子程序处理出一串输入字符放进扫描缓冲区之后,分析器就
从此缓冲区中逐一识别单词符号.当缓冲区里的字符串被处理完之后,它又调
用预处理子程序来处理新串.
4. 程序说明:
程序一开始要求读入一个代码文件,接着把读入的源程序打印出来.然后进行词法分析,程序定义两个数组keyword[60]和cha[31],前者用来存放关键字,后者用来存放中断字符。从文件中读入字符,与cha[31]中的中断字符相比较。判断读入的是否为中断字符,如果不是继续读入字符;如果是中断字符,将前面读入的字符放入到一个字符串当中,
将此字符串与keyword[60]中存放的关键字比较,如是关键字则做相应处理即着色;如果不是关键字不作处理。
程序流程图:
5. 程序运行结果
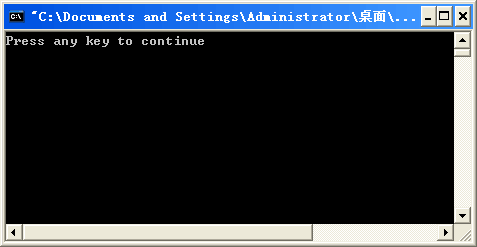
example.cpp文件中的内容:// example.cpp
#include <iostream>
#define pi 3.1415
using namespace std;
int main()
{
int n = 0;
float a = 12.34;
char ch = 'a';
cout << "hello C++ ";
for (int i = 0; i < 10; i++) a = n + ch;
}
return 0;
运行程序 :
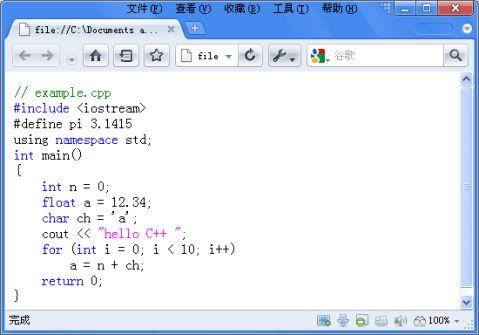
查看wyl.html中的显示内容:
6. 测试报告:
为了更好的检查程序最终输出是否正确,可以用记事本打开wyl.html查看代码。
wyl.html代码如下:
7. 存在问题及分析:
刚开始编写程序时,编写程序不知道如何从一个文件中读入字符,如何将一个字符串直接输出到文件当中。这主要是对C++语言中的一些函数不了解造成的。
在设计如何过滤中断字符和判断是否为关键字时,出现了迷茫,不知道该如何操作。这主要是算法不成熟导致的,没有正确的算法就不可能设计出正确的。要想设计出一个好的程序首先要有一个好的思想然后将这个思想转化为正确的算法,根据算法编写程序。
虽然最终程序写出来了也完成了课程设计的要求,但是编写的程序还是存在一些不足。首先,程序并没有把C++中所有的关键子都添加进去,只是添加了一些最常用的。其次,由于自己编程能力有限所编的程序执行效率有点低。
8. 总结及体会:
经过一个星期的编译原理课程设计,本人在单老师的指导下,顺利完成该课程设计.通过该课程设计,收获颇多。
一、 对实验原理有更深的理解
通过该课程设计,掌握了什么是编译程序,编译程序工作的基本过程及其各阶段的基本任务,熟悉了编译程序总流程框图,了解了编译程序的生成过程,对课本上的知识有了更深的理解,课本上的知识是机械的,表面的.通过把该算法的内容,算法的执行顺序在计算机上实现,把原来以为很深奥的书本知识变的更为简单,对实验原理有更深的理解.
二、对该理论在实践中的应用有深刻的理解
通过把该算法的内容,算法的执行顺序在计算机上实现,知道和理解了该理论在计算机中是怎样执行的, 对该理论在实践中的应用有深刻的理解 .
三、激发了学习的积极性
通过该课程设计,全面系统的理解了编译原理程序构造的一般原理和基本实现方法.把死板的课本知识变得生动有趣,激发了学习的积极性.把学过的计算机编译原理的知识强化,能够把课堂上学的知识通过自己设计的程序表示出来,加深了对理论知识的理解.以前认识是模糊的,概念上的,现在通过自己动手做实验,从实践上认识了知识的运用,对计算机编译原理的认识更加深刻.课程设计中程序比较复杂,在调试时应该仔细,在程序调试时,注意命令的正确性.,培养实践动手能力和程序开发能力.
四、理解了该知识点以及学科之间的融合渗透
本次课程设计程序部分是用C++语言编写的,把《编译原理》,《算法分析与设计》《C语言》三门学科联系起来,把各个学科之间的知识融合起来 ,把各门课程的知识联系起来,对计算机整体的认识更加深刻.使我加深了对《编译原理》,《算法分析与设计》《C++语言》三门课程的认识.
参考文献
[1] 陈意云 张昱,《编译原理》,高等教育出版社
[2] 王雷 刘志成 周晶,《编译原理课程设计》,机械工业出版社
[3] Internet网络相关资源
附录:源代码
/*cpp完成将wyl文件里的.cpp文本转换成wyl.html文件 并可以识别出关键字并用高亮表示*/
//头文件
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
//关键词表
string keyword[60]={ "auto","bool","break","case","catch","char","class",
"const","const_cast","continue","default","delete","do",
"double","dynamic_cast","else","enum","explicit","extern","false","float","for", "friend","goto","#include","if","inline","int",
"long","mutable","namespace","new","operator", "private", "protected","public","register", "return","short", "signed","sizeof","static","static_cast","struct","switch","template", "this","true","try","typedef","typeid","typename","union","unsigned", "using","virtual","void","volatile","while","_asm",};
cha[31]={' //中断字符表 char
','\t','\n','{','}',',','.','[',']','*','\\','/','?','<','>',';',':','^','%','@','!','~','`','(',')','+','-','|','=','\'','\"'};
ifstream fin("wyl.cpp");
ofstream fout("wyl.html");
void main()
{ /*主函数*/
fout<<"<html>"<<endl; fout<<"<body>"<<endl; int num=60; //查找是否为关键字的函数 如果是 则高亮表示 void searchword(string word); //判断读入字符是否为中断字符 bool ismark(char); //处理中断字符 void mark(char);
char m;
while(!fin.eof())
{ /*读入文件的字符并处理*/ m=fin.get(); string n; while(!ismark(m)&&!fin.eof())
{/*如果不是中断字并且不是全文结束符,则继续读入下一个次,并将之前读入的字符全部存入字符串a中*/
} if(ismark(m)) {/*如果是中断字,则判断字符串a是否为关键字,并处理关键字*/ searchword(n); mark(m); n=n+m; m=fin.get();
} if(fin.eof())break; } fout<<"</body>"<<endl; fout<<"</html>"; fin.close(); fout.close();
}
void searchword(string word)
{/*查找关键字并输出*/
} int flag=0; for(int i=0;i<50;i++) { } if(keyword[i]==word.data()) { flag=1; } fout<<"<font color=\"blue\">"<<word.data()<<"</font>"; break; if(flag==0) fout<<word.data();
bool ismark(char ch)
{/*判断中断符*/
for(int i=0;i<31;i++)
} { if(ch==cha[i])return 1; } return 0;
void mark(char ch) {/*处理中断符*/
char m; string a; a=ch; string b; int n=0; void search_end(int); switch(ch) { case '\n':fout<<"<br>";n=0;break; case '\t':fout<<" ";n=0;break; //一个制表符等于4个空格 case '<':fout<<"<";n=0;break; case '>':fout<<">";n=0;break; case ' ':fout<<" ";n=0;break; case '\'': {/*当读入字符为 ' 时,查找匹配的下一个'并输出之间的字符*/ } m=fin.get(); while(m!='\n'&&m!='\'') { switch(m) { case '<':b="<";break; case '>':b=">";break; case ' ':b=" ";break; case '\t':b=" ";break; default:b=m;break; } a=a+b; m=fin.get(); } if(m=='\n') fout<<a.data()<<"<br>"; else fout<<a.data()<<'\''; break; case '\"': {/*查找匹配的"并输出字符串*/ m=fin.get(); while(m!='\n'&&m!='\"') { switch(m) { case '<':b="<";break;
} } case '>':b=">";break; case ' ':b=" ";break; case '\t':b=" ";break; case '\\':b='\\';m=fin.get();b=b+m;break; default:b=m;break; } a=a+b; m=fin.get(); if(m=='\n') fout<<"<font color=\"ff00ff\">"<<a.data()<<"<br>"<<"</font>"; else fout<<"<font color=\"ff00ff\">"<<a.data()<<'\"'<<"</font>"; break;
case '/':
{/*判断是否为注释,如果是,则调用处理注释函数,如果不是,则当做一般字符处理*/
}
m=fin.get(); if(m=='/')search_end(0); else if(m=='*')search_end(1); else fout<<'/'<<m; break; } case '\\': { } m=fin.get(); fout<<'\\'<<m; break; default:fout<<ch;break; } void search_end(int flag) {/*读入注释并输出的函数*/ string a; string b; char m; int n=0; int t=0; if(flag==0) { m=fin.get(); while(m!='\n')
} } else { } { } switch(m) { case '<':b="<";break; case '>':b=">";break; case ' ':b=" ";break; case '\t':b=" ";break; default:b=m;break; } a=a+b; m=fin.get(); fout<<"<font color=\"green\">"<<"//"<<a.data()<<"</font>"<<"<br>"; while(n==0||t==0) { m=fin.get(); } fout<<"<font color=\"green\">"<<"/*"<<a.data()<<"</font>"; switch(m) { case '<':b="<";n=0;break; case '>':b=">";n=0;break; case ' ':b=" ";n=0;break; case '\t':b=" ";n=0;break; case '\n':b="<br>";break; case '*': n=1;b=m; break; case '/': { if(n==1) t=1; else n=0; b=m;break; } default:b=m;n=0;break; } a=a+b;
