《编译原理》课程设计报告
学院(系): 电子信息与电气工程学院计算机系
班 级: F0603034
学生姓名: 徐晓峰 学号 5060309852
指导教师: 张冬茉

一、 课程设计目的
通过课程设计进一步理解高级语言在计算机中的执行过程,了解现代编译器的运作机制,加深对编译原理中重点算法和编译技术的理解,提高自己自学和理解的能力。学会如何利用已有软件JFLex、Java_cup对词法分析器及语法分析器的构造。
二、 设计概述
本tiger语言编译器的编译过程涉及到编译五个阶段中的二个,即词法分析器、语法分析器。其中语法分析后还完成了语法树的打印的构造以及类型检查。词法分析器由JFLex编译正则式生成,词法分析器编译产生式生成,语法分析器由CUP生成。结果通过GUI界面呈现在使用者面前。
编译程序需要在单词级别上来分析和翻译源程序,所以首先要识别出单词,而词法分析部分的任务是:从左至右扫描源程序的字符串,按照词法规则(正则文法规则)识别出一个个正确的单词,并转换成该单词相应的二元式(种别码、属性值)交给语法分析使用。因此,词法分析是编译的基础。执行词法分析的程序称为词法分析器。
语法分析是编译程序的核心部分,其主要任务是确定语法结构,检查语法错误,报告错误的性质和位置,并进行适当的纠错工作。
三、 设计过程
(一) 设计构思
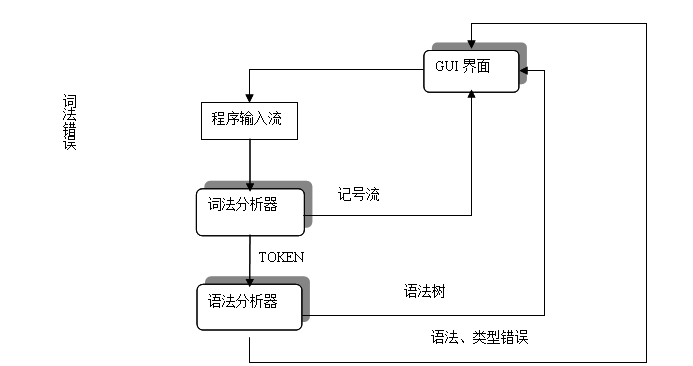
程序主要完成三大功能模块:词法分析器、语法分析器、GUI人机交互界面。词法分析器由JFLex编译正则式生成,其中必须为外界提供一个获取记号流的接口,实验中定为java_cup.runtime.Symbol next_token。语法分析器是建立在词法分析器上的,故必须包含词法分析器以便获得记号流,next_token为语法分析器提供TOKEN,语法分析器的对外接口是:java_cup.runtime.Symbol debug_parse(),同时返回语法树的根节点。
GUI界面是提供人机交互的,它能够依次显示词法分析阶段分析得到的所有TOKEN的信息,语法阶段生成的语法树,另外对于词法和语法阶段出现的错误在“错误提示”文本框中一一列举出来,提供用户改进代码的信息。
 流程图:
流程图:
类及文件说明:
包Absyn
Print.java //print out the syntax tree
…… //The abstract syntax classes for Tiger
包errormsg
ErrorMsg.java //used to produce error messages with detail information
包java_cup.runtime //Support for CUP parser
包parse
Grm.java //Parser analyser
MainInterface.java //GUI interface
Sym.java //tokens' decimal representation
Yylex.java //Lexer analyser
包Semant
Entry.java //for bindings in value environment
Env.java //holds a value ,type environment and an error printer
ExpTy.java //holds the result of translating and type-checking
FunEntry.java //for function bindings
Semant.java //the main type-checking module
VarEntry.java //for variable bindings
包Symbol
Symbol.java //makes strings into unique Symbol objects
Table.java //does environments with Scopes
包Translate
包Types //describes Tiger_language types
(二) 词法分析器
这部分的工作主要是熟悉JFLex的使用以及正确书写正则式,通过正则式的书写,生成相应的词法分析器。
1. JFLex的使用
修改jflex-1.4.2\bin中的jflex.bat文件中的参数, JAVA_HOME=%JAVA_HOME%\lib\classes.zip;
JFLEX_HOME=%JFLEX_HOME%\lib\JFlex.jar;
运行jflex.bat 并给选择输入文件(tiger.jlex),在没有错误的情况下,它在输出目录下生成一个Yylex.java的词法分析器。
tiger.jlex文件开始部分的书写格式如下:
package parse; //将词法分析器打包在Parse下
import errormsg.ErrorMsg; //导入类
%%
%cup //支持与cup的关联
%line //支持yyline()调用
%column //支持yycolumn()调用
%char
%state COMMENT,STRING //声明两个新的状态
%{ //设置所有可能的词法错误类型
StringBuffer str = new StringBuffer();
private static final String errorM[] = {
"Error: Unmatched end-of-comment punctuation.",
"Error: Unmatched start-of-comment punctuation.",
"Error: Unclosed string.",
"Error: Illegal character."
};
private void newline() { //保持errormsg里的行数记录变量的正确性
errorMsg.newline(yychar);
}
private void err(String s) { …… } //通过errormsg报错
private java_cup.runtime.Symbol tok(int kind, Object value) {
return new java_cup.runtime.Symbol(kind, yychar, yychar+yylength(), value); //返回所识别的TOKEN
}
public Yylex(java.io.FileReader s, ErrorMsg e) {
this(s); //重载Yylex构造函数,方便错误输出
errorMsg = e;
}
private ErrorMsg errorMsg; // ErrorMsg对象声明
private int comment_count = 0; //变量,用于处理注释嵌套
%}
%eofval{
{ //到文件末尾时判断最后的状态是否是YYINITIAL,若不是则报相应的错误
if(zzLexicalState!=0){
switch(zzLexicalState){
case 2: {err(errorM[E_STARTCOMMENT]);
break;}
case 4: {err(errorM[E_UNCLOSEDSTR]);
break;}
default: { /*do nothing*/ }
}
}
return tok(sym.EOF, null);
}
%eofval}
//一些基本类型简化表达式的定义
ALPHA=[A-Za-z] //字母
DIGIT=[0-9] //数字
LINE_TERMINATOR = \r|\n|\r\n //换行符
NONNEWLINE_WHITE_SPACE_CHAR=[\ \t\f\b\012] //非换行空白符
WHITE_SPACE_CHAR ={LINE_TERMINATOR} | NONNEWLINE_WHITE_SPACE_CHAR}
//空白符
%%
2. 正规表达式的书写
Tiger需要识别的变量和字符有:整型常量、字符常量、操作符、括符、分隔符、关键字、标识符、COMMENT 。
整型常量: 一个整形数字,即字母的任意组合。
字符常量: 用双引号引起来的字符,可跨行但行尾必须以\结尾,行首\开始。字符 常量中间可包含转义字符如:\r \n \t \f \” \\ \xyz x,y,z表示 0~127的整数。
操作符: + - * / > >= < <= = := & |
括符: ( ) { } [ ]
分隔符: ; :
关键字: while do for to if else then let in end type var array of break nil function
标识符:以字符开头,加上字符、数字、下划线的任意组合
评论: 以/*开头,以*/结尾中间可嵌套任意个但必须是封闭的。
一般的字符或者保留字只需返回它的名字就可以了,例如:在YYINITAIL的状态下识 别到最长匹配串为“array” ,则直接返回token,编号为sym.java中已经定义的数字 编号,书写的格式如下:
<YYINITIAL> "array" { return tok(sym.ARRAY,null); }
下面着重谈一下对于字符串和注释的处理:
字符串的处理:
ã 在YYINITIAL状态下遇到一个 ” 时表示识别字符常量的开始,此时就要进入先前声明的STRING 状态,先前声明的字符串str用来保存已识别的字符常量(初始化为空),代码如下:
<YYINITIAL> \" { str.setLength(0); yybegin(STRING);}
ã 当识别的过程中如果碰到转义字符\n \t \" \\,在str后添加相应的字符,碰到非转移字符就直接添加到str后面,忽略两个反斜杠之间的所有空白字符,代码如下:
<STRING> [^\n\r\"\\]+ { str.append(yytext()); }
<STRING> \\n { str.append('\n'); }
<STRING> \\\\ { str.append('\\'); }
<STRING> \\{WHITE_SPACE_CHAR}+\\ { /*do nothing*/}
ã 特别是当碰到\跟上三位数字时,应该判断数值范围是否在ASCII范围中
<STRING> \\0{DIGIT}{DIGIT}|\\1[0-1]{DIGIT}|\\12[0-7] {
str.append((char)Integer.valueOf(new String(yytext().getBytes(),1,3)).intValue());}
ã 当再次识别到"时标志着字符串的识别结束,此时将str中的字符串内容作为String的内容返回,同时应该返回YYINITIAL状态,继续识别其他的TOKEN
<STRING> \" {
yybegin(YYINITIAL);
return tok(sym.STRING,str.toString()); }
ã 识别到这些token以外的其他字符,则直接报错
<STRING> . {err(errorM[E_ILLEGAL]); }
注释的处理:
ã 在YYINITIAL状态下遇到一个 /* 时表示识别注释的开始,此时就要进入先前声明的COMMENT状态,同时comment_count加1,以实现注释嵌套的实现。如果在COMMENT状态下又一次识别到/*表示另一个注释嵌套的开始,此时也需要对comment_count进行加1的操作,代码如下:
<YYINITIAL> "/*" {
yybegin(COMMENT);
comment_count = comment_count + 1; }
<COMMENT> "/*" { comment_count = comment_count + 1; }
Ò 但是如果在YYINITIAL状态下遇到一个 */则是一个错误,需要报出,代码如下:
<YYINITIAL> "*/" { err(errorM[E_ENDCOMMENT]); }
ã 在COMMENT状态下遇到*/则表示着一个嵌套中的注释结束,此时需要对comment_count进行减1的操作,如果操作之后其值为0,表示整个注释已经结束,回到YYINITIAL状态,如若不然则继续在COMMENT的状态下识别,代码如下:
<COMMENT> "*/" {
comment_count = comment_count - 1;
if (comment_count == 0)
yybegin(YYINITIAL);}
ã 识别到这些token以外的其他字符,则直接忽略
<COMMENT> . { /*do nothing*/ }
3. 词法分析器的结构
词法分析器实现了Lexer接口,也就是实现了Token next_token()这个方法,不断调用此方法就可以获得所有的记号流。使用词法分析器时需要指定输入流InputStream以及ErrorMsg,InputStream完成源程序的读取,ErrorMsg完成对错误信息的输出。
至此词法分析器的构造已经基本基本结束了。
(三) 语法分析器
完成语法分析器的主要步骤是cup文件的编写,由于语法树的数据结构已给出,所以产生式的编写可以直接参考tiger语言的语法模式,当然这其中产生了许多冲突,但是可以通过设置符号的优先级来解决移进和规约的冲突。
1. CUP的使用
CUP的使用需要在命令行的环境下进行,打开命令提示符,输入如下所示的语句,
既可以在当前目录下生成语法分析器Grm.java,Grm.cup的书写格式如下所示:
Cup开始部分的书写格式如下:
package parse; //产生在parse包里面
import Absyn.*;
import javax.swing.*;
action code {:
static Symbol.Symbol sym(String s) { //将字符串转化为Symbol
return Symbol.Symbol.symbol(s);
}
:};
parser code {:
Yylex lexer;
public static Exp parseResult; //记录语法树根节点的变量
errormsg.ErrorMsg errorMsg; //输出语法错误的ErrorMsg对象声明
public void syntax_error(java_cup.runtime.Symbol current) {
report_error("Syntax error (" + current.sym + ")", (java_cup.runtime.Symbol)current);
}
public void report_error(String message, java_cup.runtime.Symbol tok) {
errorMsg.error(tok.left, message);
}
public Grm(errormsg.ErrorMsg err, JTextArea text) {
this(); //语法分析器的构造
errorMsg=err;
textin=text;
}
:};
init with {: //语法分析器初始化,从界面文本框中获取输入流
lexer = new Yylex( new java.io.StringBufferInputStream(textin.getText()),errorMsg);
:};
scan with {: java_cup.runtime.Symbol symb= lexer.debug_next_token();
for(;(symb.sym==sym.error)&&symb.sym!=sym.EOF;)
symb= lexer.debug_next_token();
return symb;
:}; //同过debug_next_token获取token并打印出token
//终结符
terminal String STRING;
terminal Integer INT;
terminal COMMA, COLON, SEMICOLON, LPAREN, RPAREN, LBRACK, RBRACK, LBRACE, RBRACE, DOT;
terminal PLUS, MINUS, TIMES, DIVIDE, EQ, NEQ, LT, LE, GT, GE, AND, OR, ASSIGN, UMINUS;
terminal ARRAY, IF, THEN, ELSE, WHILE, FOR, TO, DO, LET, IN, END, OF, BREAK, NIL, FUNCTION, VAR, TYPE, ID;
//终结符优先级次序
precedence right DO, ELSE, THEN;
precedence nonassoc ASSIGN;
precedence left OR;
precedence left AND;
precedence nonassoc EQ, NEQ, LT, LE, GT, GE;
precedence left PLUS, MINUS;
precedence left TIMES, DIVIDE;
precedence left UMINUS;
precedence left LBRACK;
? 关于优先级次序的说明:由于在语法分析的过程中会产生许多移进和规约的冲突,通过设置终结符的优先级可以避免一些情况的发生。将PLUS、MINUS的优先级定义在
TIMES、DIVIDE之前即可使乘除的优先级高于加减运算的优先级。另外通过设置比较运算符的有限次序,可以避免分析时的移进--归约冲突。
此外在实际的cup生成过程中,还会出现一些其他的冲突,例如以下两个冲突的解决:
№.1
出现冲突
between lvalue ::= ID (*)
and lvalue ::= ID (*) LBRACK expr RBRACK
and expr ::= ID (*) LBRACK expr RBRACK OF expr
under symbol LBRACK
解决办法:把left LBRACK 设为最高优先级,这样的话当碰到是归约ID还是移进 LBRACK的冲突时,系统会自动根据优先级而去执行移进的动作。
№.2
出现冲突
between expr ::= IF expr THEN expr (*)
and expr ::= IF expr THEN expr (*) ELSE expr
under symbol ELSE
解决办法:把right DO,ELSE,THEN设为最低优先级,通过precedence right
ELSE,THEN语句;定义为右结合的then将与else结合,故先移进。
№.3
负号和减号识别时有冲突,解决方案是重新定义一个终结符UMINUS算数运算符中最 高优先级,负号时重新赋予UMINUS的优先级。
2. 语法的书写
按照Tiger Manual上的语法规则,将上面的语法一一写入cup文件的后面,必要的时候定义适当的非终结符来完成语法的结构。每一条语法规则都应该返回其相应的语句类型,这些类型都已经在Absyn包中定义好了,只 要根据语句的类型按照定义返回即可。其中,要注意的是一些链表的连接,如ExpList、FieldList等,需要保证这些对象的连接正确性。
ã 首先,在语法分析前完成非终结符的定义,定义如下:
non terminal FieldList type_fields, type_fields_n, type_fields_ex;
non terminal FieldExpList field_list, field_list_n, field_list_ex;
non terminal ExpList expr_list, expr_list_n, expr_list_ex, expr_seq, expr_seq_n, expr_seq_ex;
non terminal DecList declaration_list, declaration_list_ex;
non terminal Ty type;
non terminal Dec declaration, type_declaration, variable_declaration, function_declaration;
non terminal Exp expr, program; //文法开始符
non terminal Var lvalue;
ã 其次在文法开始符的语法句的执行语句中,将第一个Exp传给先前定义的parseResul,代码如下:
start with program;
program ::= expr:e {: parser.parseResult = e; :};
ã 对于一些常规的语法,只需返回相应的语句类型即可,如赋值语句
expr ::= lvalue:l ASSIGN expr:e
{: RESULT = new AssignExp(lleft, l, e); :};
ã 对于需要连接起来的类型,如ExpList,FieldExpList,FieldList,DecList,可以通过消除左递归的方法来将多个具有向后指针的类型的语句相连,另外链表还可以为空,下面举ExpList的例子来说明处理的方法:
expr_list ::= expr_list_n:l…………………………………………………(1)
{: RESULT = l; :}
| {: RESULT = null; :};
expr_list_n ::= expr:e expr_list_ex:x…………………………………(2)
{: RESULT = new ExpList(e, x); :};
expr_list_ex::=COMMA expr_list_n:l ……………………………………(3)
{: RESULT = l; :}
| {: RESULT = null; :};
在(1)开始识别的时候先判断这个表达式是否为空,若空则直接返回null,否则进入(2),因为至少有一个Explist的存在,所以可以声明一个新的ExpList,并将它的tail指向下一个可能的ExpList,当然下一个ExpList可能为空,所以在处理expr_list_ex时需要判断其是否为空,如空则直接返回null,否则可以将嵌套进行下去。
3. 语法树的生成
语法分析结束后,同时会返回整棵语法树的根结点,我们可以利用这个根节点进行语法树的打印,调用Absyn\Print.Java中的prExp(par.parseResult,2),将整个语法树在屏幕上打印出来,同时还可以在Print.Java中定义一个string变量将需要的打印内容储存起来,在屏幕上打印完之后在GUI界面的文本框内显示出来。
4. 类型检查
ã 类型检查运作思想
语法分析结束后,我们还可以对整棵语法树进行类型检查,我们可以从语法树的根结点开始对每一个分支进行扫描,根据Tiger语言所所规定的语法类型规则进行判断这一条语句运算或者返回的类型是否符合要求,如果类型不匹配立即报出类型错误。
类型检查的关键是管理好符号表。整个检查过程维护一张变量表,一张类型表,都是Table类型的。Table是按键值方式存储,关键字是Symbol类型,值是Binder类型,Binder中变量value存储具体的信息。变量表的value存储Entry类型,Entry说明变量的类型以及其它信息。类型表的value存储的是Type类型,保存类型的具体信息。Binder类是一个链表结构,也就是说一个符号可以几个类型,如本地变量覆盖全局变量,本地类型覆盖全局类型等。
类型检查所用到的类的关系可以从下图中看清:
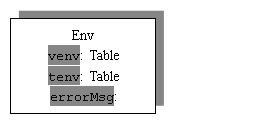







每个变量或类型都有一个有效范围,在function的声明过程中,其声明的变量只在它的函数体中有效,出了函数体就失去了它的作用范围,成为了一个无效的变量。又如在in end中又嵌套了let in end 语句,则外面语句中声明的变量在里面的语句中仍然有效(重复声明会覆盖)。可以利用table中的beginscope()和endscope()来确定变量的作用范围。调用函数 beginScope() 添加一个标记,标记起始位置。当这个变量的作用域到底时用调用函数 endScope() 把先前的声明都删掉。
ã 遇到的实际问题与思考
№.1
类型检查的过程中,还有一个递归调用的问题,如testcase6
let
function do_nothing1(a: int, b: string)=
do_nothing2(a+1)
function do_nothing2(d: int) =
do_nothing1(d, "str")
in
do_nothing1(0, "str2")
End
其中do_nothing1函数的body需要调用do_nothing2,但是按照函数按顺序声明的话,此时do_nothing2还没有被声明,因而不能够被识别,会报错。
解决方法:在let语句检查declist之前将所有的dec(包括type_declaration,function_declaration)置入相应的表中,这样的话当检查上述的函数do_nothing1时就不会出现do_nothing2还未被声明的情况了。
№.2
类型检查的过程中,还有一个循环定义的问题,如testcase16
let
type a=c
type b=a
type c=d
type d=a
in
end
解决方法:在这四个类型定义中,都用到了其他一起声明的类型,存在类似a-c-d-a的类型循环定义,到最后四个四个变量的类型还是没有被实在定义,这是不允许的。解决的方法是在检查类型定义之前用bind(ExpTy)函数将新声明的类型的binding设为声明中将要被赋予的类型。这样在进入类型声明的检查中,只需通过isloop()函数判断是否是循环定义就可知道是否出错。在这样的设计之下,代码
let
type a=c
type b=a
type c=d
type d=int
in
end
就不会出现如上的错误了,a-c-d-int就会跳出检查,返回false
№.3
在Declist中的声明中要求函数和类型的声明分别必须放在一起,如
let
function g(a:int):int = a
type t = int
function g(a:int):int = a
in
end
示例中说这是合法的,应为声明的时候是以类处理的,funcDec和后面的funcDec一起处理,typeDec和后面的typeDec一起处理,导致检查不出这个重复定义函数。我认为这里有点不太合理,我的想法是可以在let语句的检查中将所有的声明都放入环境变量中,这样的话既可以检查出是否重复定义,有可以使类型的前后调用不受阻碍。
即在ExpTy transExp(LetExp e)中添加如下代码:
ArrayList<String> list =new ArrayList<String>();
for(DecList tmp=e.decs;tmp!=null;tmp=tmp.tail){
Dec head=tmp.head;
if(head instanceof TypeDec){ //置入新的类型
TypeDec td=(TypeDec)head;
if(list.contains(td.name.toString()))
env.errorMsg.error(td.pos,"type '"+td.name+"' has been already defined");
list.add(td.name.toString());
env.tenv.put(td.name,new NAME(td.name));
}
if(head instanceof FunctionDec){ //置入新的函数变量
FunctionDec fd=(FunctionDec)head;
Type re=transTy(fd.result);
RECORD rc=transTypeFields(fd.params);
if(list.contains(fd.name.toString()))
env.errorMsg.error(fd.pos,"function '"+fd.name+"' already defined");
else{
list.add(fd.name.toString());
env.venv.put(fd.name, new FunEntry(rc,re));
}
}
}
list.clear();
这样的处理过后,就会达到上述的效果,不过这只是我的个人意见,虽然与tiger语言的要求有矛盾,但我认为这不失为一种好的改进。处于这种改动,testcases中的有点不应该报错的例子,在本编译器中会出错,像上述例子就会报“重复定义”的类型错误,所以请使用者注意这一点。
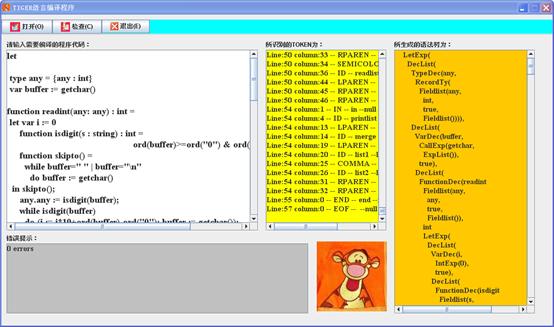
(四) GUI界面
最后介绍一下本编译器GUI界面的实现及结构。在界面中有一个工具栏和三个显示窗口和一个输入窗口,分别为:
源程序输入窗口-------用于获取需要检查的代码
语法树输出窗口-------显示语法树
 TOKEN输出窗口--------显示所识别的TOKEN
TOKEN输出窗口--------显示所识别的TOKEN
错误信息输出窗口-----显示源程序中的词法、语法和类型错误
打开-----------------从文件输入程序
检查-----------------执行编译程序,检查错误
退出-----------------退出程序
1. 文件输入
点击“打开”按钮会触发鼠标事件,会新建一个JFileChooser,选择文件并确定后,会从所选文件路径中将内容读出来并置入输入文本框。另外,还记录下本次的路径,当下一次再次打开时就以上次的路径为当前路径。
2. 树的输出
修改Absyn中的Print.Java文件,在其中定义一个String变量str,在语法树向屏幕输出的同时也将信息保存在str中,当屏幕输出完成之后,可将str传递给界面中的文本框,达到语法树的输出功能。
3. 错误输出
词法分析,语法分析、类型检查阶段错误信息都是由ErrorMsg类实现。这个类中添加了一个JtextArea的变量,在定义的时候将外部的调入,这样的话当调用error函数时就可以直接在界面的文本框内输出错误信息。
四、 总结与感想
这次编译原理课程设计主要是实现Tiger语言编译器前面一些分析阶段的功能,包括词法分析、语法分析和类型检查等。词法分析部分既词法分析器的设计,词法分析是编译的基础,词法分析器从输入流获取源程序,进行分析之后给语法分析器提供token,语法分析器从中进行语法分析,同时生成语法树,之后根据这棵语法素进行类型检查。总的来说,一个编译器的实现过程是很复杂的,但又是井井有条的。本编译器所能实现的功能只是其中的一小部分,要想完整地实现一个编译器的功能确实还有很多的工作要做。
在本次课程设计中,充分体现了上半学期编译原理课程中的一些基础的知识,对于后来的debug和设计思路都提供了很大的帮助,也达到了课程设计的目的。另外在课程设计的过程中也用到了很多java语言方面的知识和大量编程技巧,在程序的实际编写方面提供了许多的经验。可以说通过本次课程设计不仅对编译原理这一门课程也有了更加深刻的了解,同时自己的编程能力也有所提高,对于java程序的理解和运用也有所感悟和提高。同时,我也发现自己在所学知识不够全面,自己的自学和理解能力有所欠缺,以后需要在这些方面多加注意,多加完善,为今后其他的课程设计甚至今后的就业打下扎实的基础。
五、 鸣谢
对于在本次编译原理课程设计中给予我帮助的助教老师和同学表示由衷的感谢!特别感谢Herr Gu同学对我耐心的指导,以及在一些问题上给予我解决问题的思想。
参考文献
Alfred V.Aho Ravi Sethi Jeffrey D.Ullman 著 Cpmpilers Principles, Techniq1ues, and Tools 机械工业出版社出版