

课程设计
课程名称 编译原理
题目名称 PL/0编译器的扩充
学生学院 计算机学院
专业班级计算机科学与技术12(4)
学 号 3112005901
学生姓名 柏石先
指导教师 李杨

2014 年 12 月 28日
一、 实验目的与要求
基本内容(成绩范围:“中”、“及格”或“不及格”)
(1)扩充赋值运算:*= 和 /=
(2)扩充语句(Pascal的FOR语句):
FOR <变量>:=<表达式>STEP<表达式> UNTIL<表达式>Do<语句>
选做内容(成绩评定范围扩大到:“优”和“良”)
(1)增加类型:① 字符类型; ② 实数类型。
(2)增加 注释; 注释由/*和*/包含;
(3)扩充函数:① 有返回值和返回语句;② 有参数函数。
(4)增加一维数组类型(可增加指令)。
(5)其他典型语言设施。
二、 实验环境与工具
1、源语言:PL/0语言,PL/0语言是PASCAL语言的子集,它的编译程序是一个编译解析执行系统,后缀名为.PL0;
2、目标语言:生成文件后缀为*.COD的目标代码
3、实现平台:Borland C++Builder 6
4、运行平台:Windows 8.1
三、 设计概述
1、 结构设计说明
(1)PL/0编译系统的结构框架

源语言:源语言是基于C语言写的PL/0编译程序——PL0语言(可 以看成 Pascal语言的子集)
目标语言:假想的栈式计算机计算语言,即类PCODE指令代码。
指令格式如下:
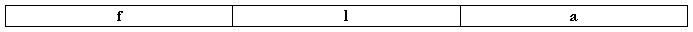
其中f代表功能码,l表示层次差,a的含意对不同的指令有所区别。
具体的指令功能表:

四、 设计分析
(一)扩充赋值运算:*= 和 /=
需要增加2个运算符*= 和 /=,用下面表格定义的SYM代替
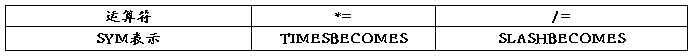
*= 和 /=的语法描述图:
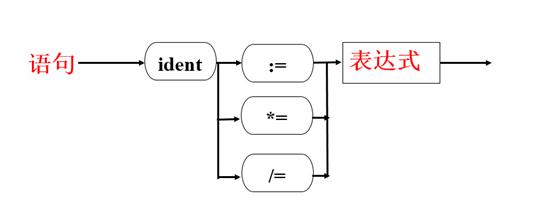
(二)扩充语句(Pascal的FOR语句)
因为在Pascal中的FOR语句描述为:
FOR <变量>:=<表达式> STEP <表达式> UNTIL <表达式> DO <语句>
所以增加FOR,STEP,UNTIL,DO
FOR语句语法描述图为:
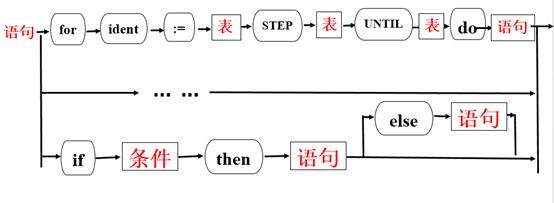
五、 程序设计
1) 增加所需要的保留字和运算符,实现*=和/=,以及FOR语句,应该增加TIMESBECOMES,SLASHBECOMES,FOR,STEP,UNTIL,DO。
注:因为要求课设和之前实验的内容合并在一起,所以保留了课程实验已经添加的保留字和运算符,之前的已经添加了的不再赘述。
具体实现的语句如下所示:
typedef enum {NUL, IDENT, NUMBER, PLUS, MINUS, TIMES,
SLASH, ODDSYM, EQL, NEQ, LSS, LEQ, GTR, GEQ,
LPAREN, RPAREN, COMMA, SEMICOLON, PERIOD,
BECOMES, BEGINSYM, ENDSYM, IFSYM, THENSYM,
WHILESYM, WRITESYM, READSYM, DOSYM, CALLSYM,
CONSTSYM, VARSYM, PROCSYM, PROGSYM,ELSESYM,
FORSYM,STEPSYM,UNTILSYM,RETURNSYM,
TIMESBECOMES,SLASHBECOMES,ANDSYM,ORSYM,NOTSYM
} SYMBOL;
这里需要考虑需要增加保留字的个数,以及如何命名,再将新增的保留字添加对应的保留字的集合中。具体实现的语句如下所示:
char *SYMOUT[] = {"NUL", "IDENT", "NUMBER", "PLUS", "MINUS", "TIMES",
"SLASH", "ODDSYM", "EQL", "NEQ", "LSS", "LEQ", "GTR", "GEQ",
"LPAREN", "RPAREN", "COMMA", "SEMICOLON", "PERIOD",
"BECOMES", "BEGINSYM", "ENDSYM", "IFSYM", "THENSYM",
"WHILESYM", "WRITESYM", "READSYM", "DOSYM", "CALLSYM",
"CONSTSYM", "VARSYM", "PROCSYM", "PROGSYM" ,"ELSESYM",
"FORSYM","STEPSYM","UNTILSYM","RETURNSYM","TIMESBECOMES",
"SLASHBECOMES", "ANDSYM", "ORSYM", "NOTSYM"};
2) 将新增的保留字按照字母表升序的方式添加,运算符参照已有的运算符来进行添加,注意好符号与SYM的对应。具体实现的语句如下所示:
特别注意点:此处一定要考虑到PLO编译器采用了折半查找算法来进行操作,如果新增的保留字没有按照既定的升序规则来插入,会造成在编译过程中,编译器无法识别某些保留字。
strcpy(KWORD[ 1],"BEGIN"); strcpy(KWORD[ 2],"CALL");
strcpy(KWORD[ 3],"CONST"); strcpy(KWORD[ 4],"DO");
strcpy(KWORD[ 5],"ELSE");
strcpy(KWORD[ 6],"END");
strcpy(KWORD[ 7],"FOR");
strcpy(KWORD[ 8],"IF");
strcpy(KWORD[ 9],"ODD"); strcpy(KWORD[ 10],"PROCEDURE");
strcpy(KWORD[ 11],"PROGRAM"); strcpy(KWORD[12],"READ");
strcpy(KWORD[13],"RETURN");
strcpy(KWORD[14],"STEP");
strcpy(KWORD[15],"THEN");
strcpy(KWORD[16],"UNTIL");
strcpy(KWORD[17],"VAR");
strcpy(KWORD[18],"WHILE"); strcpy(KWORD[19],"WRITE");
WSYM[ 1]=BEGINSYM; WSYM[ 2]=CALLSYM;
WSYM[ 3]=CONSTSYM; WSYM[ 4]=DOSYM;
WSYM[ 5]=ELSESYM;
WSYM[ 6]=ENDSYM;
WSYM[ 7]=FORSYM;
WSYM[ 8]=IFSYM;
WSYM[ 9]=ODDSYM; WSYM[ 10]=PROCSYM;
WSYM[ 11]=PROGSYM; WSYM[12]=READSYM;
WSYM[13]=RETURNSYM;
WSYM[14]=STEPSYM;
WSYM[15]=THENSYM;
WSYM[16]=UNTILSYM;
WSYM[17]=VARSYM;
WSYM[18]=WHILESYM; WSYM[19]=WRITESYM;
SSYM['+']=PLUS; SSYM['-']=MINUS;
SSYM['*']=TIMES; SSYM['/']=SLASH;
SSYM['(']=LPAREN; SSYM[')']=RPAREN;
SSYM['=']=EQL; SSYM[',']=COMMA;
SSYM['.']=PERIOD;
SSYM[';']=SEMICOLON;
SSYM['&']=ANDSYM;
SSYM['|']=ORSYM;
SSYM['!']=NOTSYM;
3) 特别需要注意的两点,这个是很容易被忽略的地方,就是在完成保留字和运算符的增加以后,一定要对PLO编译器对保留字个数已经单词总数定义进行相应的修改。
保留字总数
比如说在不添加任何保留字的情况下,PL0编译器的原保留字应该是14个,所以在Unit1.CPP中有定义const NORW = 14; /* # OF RESERVED WORDS */
而在实验中因为新增加保留字5个,故此处应改为:
const NORW = 19; /* # OF RESERVED WORDS */
单词总数
与保留字总数一样,我们增加完保留字和运算符以后,要修改单词总是,比如原单词总数是33,因为原编译器中并未定义一个常量来进行统一管理,所以需要对所有“i<33”的地方进行修改。因为实验中新增加单词10个,故应改为“i<43”。
如下面代码所示举例:
SYMSET SymSetUnion(SYMSET S1, SYMSET S2) {
SYMSET S=(SYMSET)malloc(sizeof(int)*43);
for (int i=0; i<43; i++)
if (S1[i] || S2[i]) S[i]=1;
else S[i]=0;
return S;
}
特别是这个地方也要更改数目为43,不然会发生异常信息。
DECLBEGSYS=(int*)malloc(sizeof(int)*43);
STATBEGSYS=(int*)malloc(sizeof(int)*43);
FACBEGSYS =(int*)malloc(sizeof(int)*43);
for(int j=0; j<43; j++) {
DECLBEGSYS[j]=0; STATBEGSYS[j]=0; FACBEGSYS[j] =0;
}
体会:在这里的细节导致出现了很多意料不到的问题,很多时候调试了很久才发现,有些地方漏改了,其实可以考虑设置一个全局变量,进行统一修改,不过考虑到对编译器增加全局变量不是很好的一种方式,难免会发生出现可能的篡改,而且不够直观,故只是在原来基础上做出修改。
4) 新增的运算符需要被编译器识别,必须满足编译器做词法分析时,能够正确得到对应的SYM,因此在GetSym()函数中在相应位置增加相应的运算符分析判断,具体实现如下面所示的语句:
else
if(CH=='*'){
GetCh();
if(CH=='=') {SYM=TIMESBECOMES; GetCh();}
else SYM=TIMES;}
else
if(CH=='/'){
GetCh();
if(CH=='='){SYM=SLASHBECOMES;
GetCh();}
else SYM=SLASH;}
体会:这里是双字符判断,需要注意判别的连贯性,处理不同情况下对于的SYM或者报错方式。
5) 完成*=和/=的语法分析以后,需要考虑其语义的实现,也就是考虑如何实现语句的处理,这里根据前面设计的语法描述图来进行相应的语句分析。
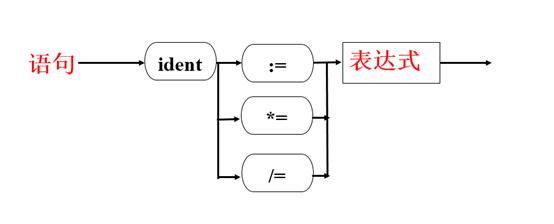 依据语法描述图,首选找到STATEMENT函数中IDENT语句体,即case IDENT:语句中加入对*=和/=的语句描述。注意这里有三种情况,要考虑到相互不能影响。表达式的分析采用EXPRESSION(FSYS,LEV,TX);语句就行。
依据语法描述图,首选找到STATEMENT函数中IDENT语句体,即case IDENT:语句中加入对*=和/=的语句描述。注意这里有三种情况,要考虑到相互不能影响。表达式的分析采用EXPRESSION(FSYS,LEV,TX);语句就行。
从指令功能表可知:
OPR,0,4代表次栈顶乘以栈顶,退两个栈元素,结果值进栈
OPR,0,5代表次栈顶除以栈顶,退两个栈元素,结果值进栈
一定要注意是次栈顶对栈顶的操作,所以要注意被除数(被乘数)和除数(乘数)的入栈的先后次序,不可颠倒。
case IDENT:
i=POSITION(ID,TX);
if (i==0) Error(11);
else
if (TABLE[i].KIND!=VARIABLE) { /*ASSIGNMENT TO NON-VARIABLE*/
Error(12); i=0;
}
GetSym();
if (SYM==BECOMES||TIMESBECOMES||SLASHBECOMES)
{
OPSYM=SYM;
if (SYM==TIMESBECOMES)
{
GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR); //取值到栈顶
}
else if (SYM==SLASHBECOMES)
{
GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR); //取值到栈顶
}
GetSym(); }
else Error(13);
EXPRESSION(FSYS,LEV,TX);
if (OPSYM == TIMESBECOMES)
{
GEN(OPR,0,4); // OPR,0,4代表次栈顶乘以栈顶,退两个栈元素,结果值进栈
}
else if (OPSYM == SLASHBECOMES)
{
GEN(OPR,0,5); // OPR,0,5代表次栈顶除以栈顶,退两个栈元素,结果值进栈
}
if (i!=0)
{
GEN(STO,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);
}
break;
体会:这里在调试过程中发现了编译程序中的一个BUG:
当我测试除等运算时,发现目标代码的生成没有问题,可是结果变成了取余运算,调试许久以后,才发现原来在编译器源码中Interpret()函数的语句中的除运算变成了取余运算。也就造成了OPR 0,5语句本来应该是表示除运算指令,变成了取余运算指令。
所以把该语句修改为:
case 5: T--; S[T]=S[T] / S[T+1]; break;
结果就可以正常输出。所以面对这种BUG,还好老师提醒一下,才发现是这个原因。
6) 在增加了所有FOR循环需要的保留字以后,根据FOR循环的语法描述进行语义分析。因为在Pascal中的FOR语句描述为:FOR <变量>:=<表达式> STEP <表达式> UNTIL <表达式> DO <语句>。所以按照这个语义,进行相应的语句处理。
case FORSYM:
GetSym();
if (SYM!=IDENT) Error(13);//是否为 变量符号
else {
i=POSITION(ID,TX);
if (i==0) Error(11);
else if (TABLE[i].KIND!=VARIABLE) //赋值语句中,赋值左部标识符是变量
{ Error(12); i=0; }
GetSym();
if(SYM!=BECOMES) Error(13);
else {
GetSym();
/*处理赋值语句右部的表达式*/
EXPRESSION(SymSetUnion(SymSetNew(UNTILSYM,STEPSYM,DOSYM),FSYS),LEV,TX);
if(i!=0)
GEN(STO,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR); //保持初始值
CX1=CX;//如果是赋值语句,跳转到untilsym执行
GEN(JMP,0,0);
CX2=CX; //保持循环开始点
if(SYM!=STEPSYM) Error(19);
else{
GetSym();
EXPRESSION(SymSetUnion(SymSetNew(UNTILSYM,STEPSYM,DOSYM),FSYS),LEV,TX);
GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR); //循环变量放到栈顶
GEN(OPR,0,2);
GEN(STO,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);//将栈顶的值放入循环变量
//GetSym();
if(SYM!=UNTILSYM) Error(19);
else{
CODE[CX1].A=CX; //如果是赋值语句,跳转到untilsym执行
GetSym();
EXPRESSION(SymSetUnion(SymSetNew(UNTILSYM,STEPSYM,DOSYM),FSYS),LEV,TX);
GEN(LOD,LEV-TABLE[i].vp.LEVEL,TABLE[i].vp.ADR);
GEN(OPR,0,12); //次栈顶是否比栈顶小,是,1进栈,否,0进栈
CX3=CX;
GEN(JPC,0,0);// 栈顶布尔值非0则转移
if(SYM=DOSYM) {
GetSym();
STATEMENT(FSYS,LEV,TX);
GEN(JMP,0,CX2);//跳回step
CODE[CX3].A=CX;
}
else Error(19);
}}}}
//跳出for循环
break;
体会:这里的语句分析的次序应该是按照语句出现的先后,而不是语义的先后,不然逻辑很难处理,而且根据循环的方式,进行相应的跳转回填操作比较多,因为要求是对表达式进行操作,所以EXPRESSION()语句的处理也比较多。
六、 测试用例
因为这个整合了前面课程实验和课程设计的全部内容,因此对代码的检测也写了很多的测试用例。
下面是相关说明:

七、 运行结果
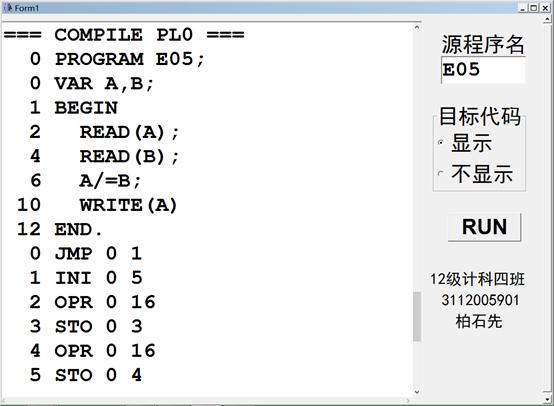
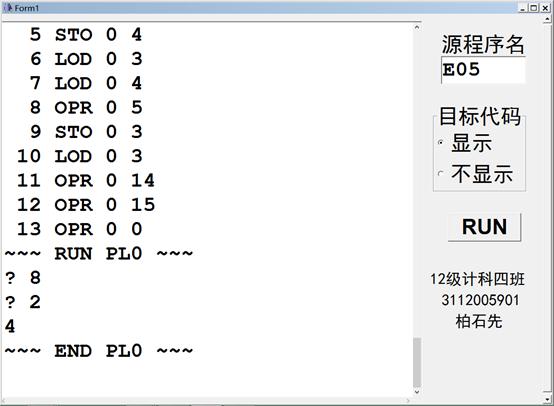
1. 测试/=运算(结果截图,测试用例E05.PL0)
运行代码截图:
结果输出截图:
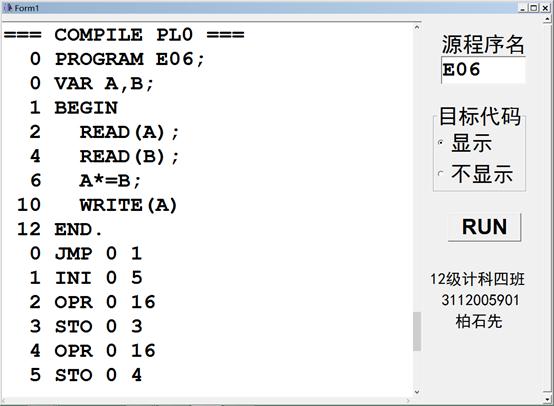
测试*=运算(结果截图,测试用例E06.PL0)
结果输出截图:

目标代码生成:
0 JMP 0 1
1 INI 0 7
2 LIT 0 4
3 STO 0 5
4 OPR 0 16
5 STO 0 3
6 OPR 0 16
7 STO 0 4
8 LOD 0 3
9 LIT 0 1
10 OPR 0 2
11 STO 0 6
12 JMP 0 19
13 LOD 0 4
14 LIT 0 2
15 OPR 0 2
16 LOD 0 6
17 OPR 0 2
18 STO 0 6
19 LOD 0 3
20 LIT 0 10
21 OPR 0 2
22 LOD 0 6
23 OPR 0 12
24 JPC 0 31
25 LOD 0 5
26 LOD 0 6
27 OPR 0 4
28 OPR 0 14
29 OPR 0 15
30 JMP 0 13
31 OPR 0 0
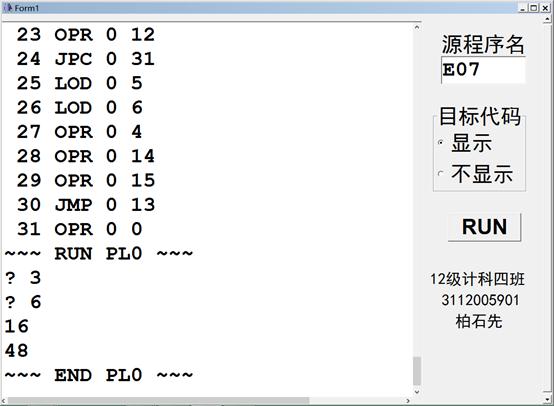
测试FOR循环语句(结果截图,测试用例E07.PL0)
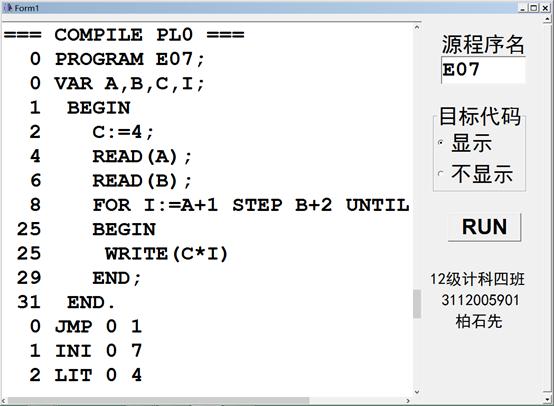
结果输出截图:
八、 心得体会
总的来说,编译原理课程设计,难度挺大,加上本身时间比较重叠,所以很多问题都没有时间去尝试。而且也遇到像编译器存在某些小BUG的问题(比如OPR 0,5),导致调试了很久,才发现问题不在自己的代码。最印象深刻的是对FOR语句的处理,因为FOR语句的语义分析比较繁琐,老师虽然在课堂讲了两次,也听明白了,但是实际动手还是发现有比较大的困难。这也在一些方面体现了知识的活学活用还是不够。
对于编译原理这门课,我觉得考虑问题的分析方式还是很有意思,也对如何编译这个过程的处理有了一个大致的摸索。切实的进行编译器编程之后,对这个编译器如何实现我们的代码转换有了新的认识,站在这个基础上去理解高级语言的语法分析的过程,去想象高级语言的语义分析的思路,对自己的编程感悟也有了一些提高。
编译原理实验是一个要很注意细节的事情,因为在处理细节上必须注意,比如我在处理保留字数量和单词数量上就一直摸索了好久,期间也造成了一些像内存溢出,无法识别保留字的错误。而对于像FOR语句,主要是对于语义处理,和语句之间的衔接跳转回调的理解。
总之,编译原理是一门需要细心和耐心的学科,对于我们理解高级语言的实现由很大的促进。衷心感谢在学习过程中李扬老师的耐心指导。