计算机硬件实验室实验报告

一、实验目的:
根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
二、实验要求:
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:
(1)E->TG
(2)G->+TG|—TG
(3)G->ε
(4)T->FS
(5)S->*FS|/FS
(6)S->ε
(7)F->(E)
(8)F->i
输出的格式如下:
(1)LL(1)分析程序,编制人:姓名,学号,班级
(2)输入一以#结束的符号串(包括+—*/()i#):在此位置输入符号串
(3)输出过程如下:

(4)输入符号串为非法符号串(或者为合法符号串)
备注:
(1)在“所用产生式”一列中如果对应有推导则写出所用产生式;如果为匹配终结符则写明匹配的终结符;如分析异常出错则写为“分析出错”;若成功结束则写为“分析成功”。
(2) 在此位置输入符号串为用户自行输入的符号串。
(3)上述描述的输出过程只是其中一部分的。
注意:
1.表达式中允许使用运算符(+-*/)、分割符(括号)、字符i,结束符#;
2.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);
三、实验过程:
1.模块设计:将程序分成合理的多个模块(函数),每个模块做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.程序编写
(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);
(3)控制部分:从键盘输入一个表达式符号串;
(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
四、实验结果:
(1)写出程序流程图
(2)给出运行结果
示例程序:注意:本示例只要修改分析的句子即可,不要改写文法
/*LL(1)分析法源程序,只能在VC++中运行 */
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<dos.h>
char A[20];/*分析栈*/
char B[20];/*剩余串*/
char v1[20]={'i','+','-','*','/','(',')','#'};/*终结符 */
char v2[20]={'E','G','T','S','F'};/*非终结符 */
int j=0,b=0,top=0,l;/*L为输入串长度 */
typedef struct type/*产生式类型定义 */
{
char origin;/*大写字符 */
char array[5];/*产生式右边字符 */
int length;/*字符个数 */
}type;
type e,t,g,g1,g2,s,s2,s1,f,f1;/*结构体变量 */
type C[10][10];/*预测分析表 */
void print()/*输出分析栈 */
{
int a;/*指针*/
for(a=0;a<=top+1;a++)
printf("%c",A[a]);
printf("\t\t");
}/*print*/
void print1()/*输出剩余串*/
{
int j;
for(j=0;j<b;j++)/*输出对齐符*/
printf(" ");
for(j=b;j<=l;j++)
printf("%c",B[j]);
printf("\t\t\t");
}/*print1*/
void main()
{
int m,n,k=0,flag=0,finish=0;
char ch,x;
type cha;/*用来接受C[m][n]*/
/*把文法产生式赋值结构体*/
e.origin='E';
strcpy(e.array,"TG");
e.length=2;
t.origin='T';
strcpy(t.array,"FS");
t.length=2;
g.origin='G';
strcpy(g.array,"+TG");
g.length=3;
g1.origin='G';
strcpy(g1.array,"-TG");
g1.length=3;
g2.origin='G';
g2.array[0]='^';
g2.length=1;
/////////////////////////////////////////////
s.origin='S';
strcpy(s.array,"*FS");
s.length=3;
s1.origin='S';
strcpy(s1.array,"/FS");
s1.length=3;
s2.origin='S';
s2.array[0]='^';
s2.length=1;
////////////////////////////////
f.origin='F';
strcpy(f.array,"(E)");
f.length=3;
f1.origin='F';
f1.array[0]='i';
f1.length=1;
for(m=0;m<=4;m++)/*初始化分析表*/
for(n=0;n<=5;n++)
C[m][n].origin='N';/*全部赋为空*/
/*填充分析表*/
//char v1[20]={'i','+','-','*','/','(',')','#'};/*终结符 */
//char v2[20]={'E','G','T','S','F'};/*非终结符 */
C[0][0]=e;C[0][5]=e;
C[1][1]=g;C[1][2]=g1;C[1][3]=C[1][4]=C[1][7]=g2;
C[2][0]=t;C[2][3]=t;C[2][5]=t;
C[3][1]=C[3][2]=s2;C[3][3]=s;C[3][4]=s1;C[3][6]=C[3][7]=s2;
C[4][0]=f1; C[4][5]=f;
printf("LL(1)分析程序,编制人:武普泉,20号,1020562班\n");
printf("输入一以#结束的符号串(包括+ - * / () i #):");
do/*读入分析串*/
{
scanf("%c",&ch);
if ((ch!='i') &&(ch!='+') &&(ch!='-')&&(ch!='*')&&(ch!='/')&&(ch!='(')&&(ch!=')')&&(ch!='#'))
{
printf("输入串中有非法字符\n");
exit(1);
}
B[j]=ch;
j++;
}while(ch!='#');
l=j;/*分析串长度*/
ch=B[0];/*当前分析字符*/
A[top]='#'; A[++top]='E';/*'#','E'进栈*/
printf("步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 \n");
do
{
x=A[top--];/*x为当前栈顶字符*/
printf("%d",k++);
printf("\t\t");
for(j=0;j<=7;j++)/*判断是否为终结符*/
if(x==v1[j])
{
flag=1;
break;
}
if(flag==1)/*如果是终结符*/
{
if(x=='#')
{
finish=1;/*结束标记*/
printf("acc!\n");/*接受 */
getchar();
getchar();
exit(1);
}/*if*/
if(x==ch)
{
print();
print1();
printf("%c匹配\n",ch);
ch=B[++b];/*下一个输入字符*/
flag=0;/*恢复标记*/
}/*if*/
else/*出错处理*/
{
print();
print1();
printf("%c出错\n",ch);/*输出出错终结符*/
exit(1);
}/*else*/
}/*if*/
else/*非终结符处理*/
{
for(j=0;j<=4;j++)
if(x==v2[j])
{
m=j;/*行号*/
break;
}
for(j=0;j<=7;j++)
if(ch==v1[j])
{
n=j;/*列号*/
break;
}
cha=C[m][n];
if(cha.origin!='N')/*判断是否为空*/
{
print();
print1();
printf("%c->",cha.origin);/*输出产生式*/
for(j=0;j<cha.length;j++)
printf("%c",cha.array[j]);
printf("\n");
for(j=(cha.length-1);j>=0;j--)/*产生式逆序入栈*/
A[++top]=cha.array[j];
if(A[top]=='^')/*为空则不进栈*/
top--;
}/*if*/
else/*出错处理*/
{
print();
print1();
printf("%c出错\n",x);/*输出出错非终结符*/
exit(1);
}/*else*/
}/*else*/
}while(finish==0);
}/*main*

第二篇:编译原理实验报告三
实验三 语义分析程序实现
一、实验目的与要求
在实现词法、语法分析程序的基础上,编写相应的语义子程序,进行语义处理,加深对语法制导翻译原理的理解,进一步掌握将语法分析所识别的语法范畴变换为某种中间代码(四元式)的语义分析方法,并完成相关语义分析器的代码开发。
二、一般实现方法
语法制导翻译模式是在语法分析的基础上,增加语义操作来实现的,实际上是对前后文无关文法的一种扩展。一般而言,首先需要根据进行的语义分析工作,完成对给定文法的必要拆分和语义动作的编写,从而为每一个产生式都配备相应的语义子程序,以便在进行语法分析的同时进行语义解释。即在语法分析过程中,每当用一个产生式进行推导或归约时,语法分析程序除执行相应的语法分析动作之外,还要调用相应的语义子程序,以便完成生成中间代码、查填有关表格、检查并报告源程序中的语义错误等工作。每个语义子程序需指明相应产生式中各个符号的具体含义,并规定使用该产生式进行分析时所应采取的语义动作。这样,语法制导翻译程序在对源程序从左到右进行的一遍扫描中,既完成语法分析任务,又完成语义分析和中间代码生成方面的工作。本实验要求从编译器的整体设计出发,重点通过对实验二中语法分析程序的扩展,完成一个编译器前端程序的编写、调试和测试工作,形成一个将源程序翻译为中间代码序列的编译系统。
三、实验内容
基本实验题目:对文法G2[<算术表达式>]中的产生式添加语义处理子程序,完成运算对象是简单变量(标识符)和无符号数的四则运算的计值处理,将输入的四则运算转换为四元式形式的中间代码。
输入:包含测试用例(由标识符、无符号数和+、?、*、/、(、)构成的算术表达式)的源程序文件。
输出:将源程序转换为中间代码形式表示,并将中间代码序列输出到文件中。若源程序中有错误,应指出错误信息。
五、源程序
# include <stdio.h>
# include <ctype.h>
# include <string.h>
# include <math.h>
# include <stdlib.h>
# define UNKNOWN -1
# define LB 0
# define RB 1
# define PL 2
# define MI 3
# define MU 4
# define DI 5
# define UCON 6 //Suppose the class number of unsigned constant is 7
# define OVER
# define LT 8
# define LE 9
# define EQ 10
# define NE 11
# define GT 12
# define GE 13
# define IS 19//14至18被五个关键字占用
# define ID 20
#define MAX_KEY_NUMBER 20 /*关键字的数量*/
#define KEY_WORD_END "waiting for your expanding" /*关键字结束标记*/
char *KeyWordTable[MAX_KEY_NUMBER]={"begin","end", "if", "then", "else", KEY_WORD_END};
char TOKEN[20]="";//存储已扫描的单词
char ch=' ';//用于存储带判断的字符
int row=1;
////////////////////////无符号数部分
#define DIGIT 1
#define POINT 2
#define OTHER 3
#define POWER 4
#define PLUS 5
#define MINUS 6
#define ClassOther 200
#define EndState -1
int index=0;
int w,n,p,e,d;
int Class; //Used to indicate class of the word
int ICON;
float FCON;
static int CurrentState; //Used to present current state, the initial value:0
////////////////////////语法分析部分
////////////////////////产生式
// 1、E->E+T 2、E->E-T 3、E->T 4、T->T*F 5、T->T/F 6、T->F 7、F->(E) 8、F->i
# define SMAX 256
///////////////////////goto表的列项
# define E 0
# define T 1
# define F 2
int StateStack[SMAX];//状态栈
int StackPoint;//状态栈指针
int TopState;//作为状态栈盏栈顶指针
int InputWordType;//输入的单词类型
//////////////// ( ) + - * / i #
char Action[16][8][4]={"s4", " ", " ", " ", " ", " ", "s5", " ",
" ", " ", "s6", "s7", " ", " ", " ", "A",
" ", "r3", "r3", "r3", "s8", "s9", " ", "r3",
" ", "r6", "r6", "r6", "r6", "r6", " ", "r6",
"s4", " ", " ", " ", " ", " ", "s5", " ",
" ", "r8", "r8", "r8", "r8", "r8", " ", "r8",
"s4", " ", " ", " ", " ", " ", "s5", " ",
"s4", " ", " ", " ", " ", " ", "s5", " ",
"s4", " ", " ", " ", " ", " ", "s5", " ",
"s4", " ", " ", " ", " ", " ", "s5", " ",
" ", "s15", "s6", "s7", " ", " ", " ", " ",
" ", "r1", "r1", "r1", "s8", "s9", " ", "r1",
" ", "r2", "r2", "r2", "s8", "s9", " ", "r2",
" ", "r4", "r4", "r4", "r4", "r4", " ", "r4",
" ", "r5", "r5", "r5", "r5", "r5", " ", "r5",
" ", "r7", "r7", "r7", "r7", "r7", " ", "r7",};//action表
// E T F
int Goto[16][3]={ { 1, 2, 3},
{-1, -1, -1},
{-1, -1, -1},
{-1, -1, -1},
{10, 2, 3},
{-1, -1, -1},
{-1, 11, 3},
{-1, 12, 3},
{-1, -1, 13},
{-1, -1, 14},
{-1, -1, -1},
{-1, -1, -1},
{-1, -1, -1},
{-1, -1, -1},
{-1, -1, -1},
{-1, -1, -1},};//goto表
////////////////////////语义分析部分
#define PMAX 5//define 后面不加括号,定义产生式符号属性字符串的长度
int NXQ=0; /*全局变量NXQ用于指示所要产生的下一个四元式的编号*/
int NXTemp=1;//整型变量NXTemp指示临时变量的编号
int SentenceCount=1;//存放文件中句子的个数
struct QUATERNION /*四元式表的结构*/
{
char op[PMAX]; /*操作符*/
char arg1[PMAX]; /*第一个操作数*/
char arg2[PMAX]; /*第二个操作数*/
char result[PMAX]; /*运算结果*/
}pQuad[256]; /*存放四元式的数组*/
char EBracket_Place[PMAX];//(E)的语义属性
char i_Place[PMAX];
char E_Place[PMAX];
char T_Place[PMAX];
char F_Place[PMAX];
int EXCUTE (int state, int symbol,FILE *fp,char JudgeStr[],int row,int index);
int GetChar (char ch);
int HandleError (char StrJudge[],int row);
int Push( int State );
int Pop(int count);
int SLRControl(FILE* fp);
void GEN(char *Op, char *Arg1, char *Arg2, char *Result);
char *NewTemp(void);
void NextSentence(FILE* fp);//当语法或者词法产生错误的时候,跳过当前错误的句子,将文件指针指向下一个句子的开始
////////////////////////查保留字表,判断是否为关键字
int lookup (char *token)
{
int n=0;
while (strcmp(KeyWordTable[n], KEY_WORD_END)) //strcmp比较两串是否相同,若相同返回0
{
if (!strcmp(KeyWordTable[n], token)) //比较token所指向的关键字和保留字表中哪个关键字相符
{
return n+1; //根据单词分类码表I,设置正确的关键字类别码,并返回此类别码的值
break;
}
n++;
}
return 6; //单词不是关键字,而是标识符
}
////////////////////////输出分析结果
void out (int i, char* pStr)
{
char Mnemonic[5];
if(0==i)
{
strcpy(Mnemonic,"LB");
}
else if(1==i)
{
strcpy(Mnemonic,"RB");
}
else if(2==i)
{
strcpy(Mnemonic,"PL");
}
else if(3==i)
{
strcpy(Mnemonic,"MI");
}
else if(4==i)
{
strcpy(Mnemonic,"MU");
}
else if(5==i)
{
strcpy(Mnemonic,"DI");
}
else if(6==i)
{
strcpy(Mnemonic,"UCON");
}
else if(7==i)
{
strcpy(Mnemonic,"OVER");
}
else if(8==i)
{
strcpy(Mnemonic,"LT");
}
else if(9==i)
{
strcpy(Mnemonic,"LE");
}
else if(10==i)
{
strcpy(Mnemonic,"EQ");
}
else if(11==i)
{
strcpy(Mnemonic,"NE");
}
else if(12==i)
{
strcpy(Mnemonic,"GT");
}
else if(13==i)
{
strcpy(Mnemonic,"GE");
}
else if(14==i)
{
strcpy(Mnemonic,"BEGIN");
}
else if(15==i)
{
strcpy(Mnemonic,"END");
}
else if(16==i)
{
strcpy(Mnemonic,"IF");
}
else if(17==i)
{
strcpy(Mnemonic,"THEN");
}
else if(18==i)
{
strcpy(Mnemonic,"ELSE");
}
else if(19==i)
{
strcpy(Mnemonic,"IS");
}
else if(20==i)
{
strcpy(Mnemonic,"ID");
}
else
{
strcpy(Mnemonic,"Unkown Type");
}
printf("(%s )对应 %s\n",Mnemonic,pStr);
}
////////////////////////报错部分
void report_error (int row)
{
printf("%s 无法识别的单词! In the %d row\n",TOKEN,row);
}
////////////////////////扫描程序部分
void scanner(FILE *fp)
{
int i, c;
fseek(fp,-1,1);//首先回溯一个字符,就是将文件所有的字符都在scanner内部判断,外部while循环不会浪费任何字符
ch=fgetc (fp);//scanner中要想判断字符,必须开头先读一个字符
while(' '==ch||'\n'==ch||'\t'==ch)//消耗文件中空字符串
{
if('\n'==ch)
{
row++;
}
ch=fgetc (fp);
}
if(EOF==ch)
{
return;
}
if (isalpha (ch)) /*it must be a identifer!*/
{
TOKEN[0]=ch; ch=fgetc (fp); i=1;
while (isalnum (ch))
{
TOKEN[i]=ch; i++;
ch=fgetc (fp);
}
TOKEN[i]= '\0';
fseek(fp,-1,1); /* retract*/
c=lookup (TOKEN);
if (c!=6) out (c+13,TOKEN); else out (c+14,TOKEN);//此处加13或者14因为一些常量的定义产生冲突,被迫修改以适应
}
else if(isdigit(ch)|| '.'==ch)
{
fseek (fp,-1,1);//回溯一个字符,为下面循环内部使用先读字符后判断的格式。
int Type;
CurrentState=0;
i=0;
do
{
ch=fgetc(fp);
TOKEN[i]=ch;
i++;
TOKEN[i]='\0';
Type=GetChar(ch);
EXCUTE (CurrentState,Type,fp,TOKEN,row,i);
}while(CurrentState!=EndState);
}else
switch(ch)
{
case '<': ch=fgetc(fp);
if(ch=='=')out(LE,"<=");
else if(ch=='>') out (NE,"<>");
else
{
out (LT,"<");
}
break;
case '=':
{
ch=fgetc(fp);
if('='==ch)
{
out(EQ, "==");
}
else
{
out(IS, "=");
}
}
break;
case '>': ch=fgetc(fp);
if(ch=='=')out(GE,">=");
else
{
out(GT,">");
}
break;
case '+':
{
InputWordType=PL;
out(PL,"+");
}
break;
case '-':
{
InputWordType=MI;
out(MI,"-");
}
break;
case '*':
{
InputWordType=MU;
out(MU,"*");
}
break;
case '/':
{
InputWordType=DI;
out(DI,"/");
}
break;
case '(':
{
InputWordType=LB;
out(LB,"(");
}
break;
case ')':
{
InputWordType=RB;
out(RB,")");
}
break;
case '#':
{
InputWordType=OVER;
out(OVER,"#");
}
break;
default:
{
InputWordType=UNKNOWN;
report_error(row);
}break;
}
return;
}
/////////////////////////无符号数判断矩阵执行程序
int EXCUTE (int state, int symbol,FILE *fp,char JudgeStr[],int row,int index)//row用于指示出错的行数,index用于为待输出的字符串赋结束符‘\0’时用
{
switch (state)
{
case 0:switch (symbol)
{
case DIGIT: n=0;p=0;e=1;w=d;CurrentState=1;Class=UCON;break;
case POINT: w=0;n=0;p=0;e=1;CurrentState=3;Class=UCON;break;
default:
{
Class=ClassOther;
CurrentState=EndState;
InputWordType=UNKNOWN;
printf("无符号数的第一个字符是非法的!\n");
}
}
break;
case 1:switch (symbol)
{
case DIGIT: w=w*10+d;break; //CurrentState=1
case POINT: CurrentState=2;break;
case POWER: CurrentState=4;break;
default:
{
if (ch!=EOF)//如果是因为读到文件结束字符而终止识别(是正确识别一个无符号数结束),就不应该回退,否则可能造成死循环
{
fseek(fp,-1,1);//遇到其他的字符,可能是一条语句中的其他字符,需后退,因为主函数外层循环每次都要读一个字符进行判断,而这个判读不回溯,所以在内部把这个多读的字符回溯
}
ICON=w;CurrentState=EndState;
JudgeStr[index-1]='\0';
InputWordType=UCON;
printf("(UCON,%i)对应 %s\n",ICON,JudgeStr);
}break;
}
break;
case 2:switch (symbol)
{
case DIGIT: n++;w=w*10+d;break;
case POWER: CurrentState=4;break;
default:
{
if (ch!=EOF)
{
fseek(fp,-1,1);
}
FCON=w*pow(10,e*p-n);CurrentState=EndState;
JudgeStr[index-1]='\0';
InputWordType=UCON;
printf("(UCON,%f)对应于 %s\n",FCON,JudgeStr);
}
}
break;
case 3:switch (symbol)
{
case DIGIT: n++;w=w*10+d;CurrentState=2;break;
default:
{
InputWordType=UNKNOWN;
HandleError(JudgeStr,row);CurrentState=EndState;
}
}
break;
case 4:switch (symbol)
{
case DIGIT: p=p*10+d;CurrentState=6;break;
case MINUS: e=-1;CurrentState=5;break;
case PLUS: CurrentState=5;break;
default:
{
InputWordType=UNKNOWN;
HandleError(JudgeStr,row);CurrentState=EndState;
}
}
break;
case 5:switch (symbol)
{
case DIGIT: p=p*10+d;CurrentState=6;break;
default:
{
InputWordType=UNKNOWN;//判断一个无符号数的最后一个字符应该都是多余读取的,所以为了防止引起后面再次判断下一无符号数时产生呑字符的现象,都应该回溯一个字符
HandleError(JudgeStr,row);CurrentState=EndState;
}
}
break;
case 6:switch (symbol)
{
case DIGIT:p=p*10+d;break;
default:
{
if (ch!=EOF)
{
fseek(fp,-1,1);
}
FCON=w*pow(10,e*p-n);CurrentState=EndState;
JudgeStr[index-1]='\0';
InputWordType=UCON;
printf("(UCON,%f)对应 %s\n",FCON,JudgeStr);
}break;
}
break;
}
return CurrentState;
}
////////////////////////无符号数判断过程中的字符类型判断程序
int GetChar (char ch)
{
if(isdigit(ch)) {d=ch-'0';return DIGIT;}
if (ch=='.') return POINT;
if (ch=='E'||ch=='e') return POWER;
if (ch=='+') return PLUS;
if (ch=='-') return MINUS;
return OTHER;
}
/////////////////////////判断出错报错程序
int HandleError (char StrJudge[],int row)
{
printf ("Row: %d*****%s 不合法的无符号数!\n",row,StrJudge);
return 0;
}
////////////////////////语法分析程序
int SLRControl(FILE* fp)
{
while(Action[TopState][InputWordType][0] != 'A')
{
if (UNKNOWN==InputWordType)
{
printf("**********************分析语句 %i 时词法分析出错******************\n",SentenceCount);
return 0;
}
printf("栈顶状态:%i\n",TopState);
printf("扫描的单词类型:%i\n",InputWordType);
if (-1==TopState)
{
printf("分析语句 %i 时状态栈栈顶指针错误!分析结束\n",SentenceCount);
return 0;
}
if (' ' == Action[TopState][InputWordType][0])
{
printf("分析语句 %i 时语法分析出错!分析结束\n",SentenceCount);
return 0;
}
else if('s'==Action[TopState][InputWordType][0])
{
Push(atoi(&Action[TopState][InputWordType][1]));
printf("执行压栈操作\n");
if (EOF!=fgetc(fp))
{
scanner(fp);
}
else
{
printf("语句 %i 不完整!分析结束\n",SentenceCount);
return 0;
}
}
else if('r'==Action[TopState][InputWordType][0])
{
int ProductionNum=atoi(&Action[TopState][InputWordType][1]);
int ProdutionLeft=0;
if (1==ProductionNum)
{
ProdutionLeft=E;//为下面差goto表提供列坐标
Pop(3);
printf("用产生式 1 归约\n");
char* Temp=NewTemp();
GEN("+",E_Place,T_Place,Temp);
strcpy(E_Place,Temp);
printf("生成四元式:(+,E_Place,T_Place,E_Place)\n");
}
else if(2==ProductionNum)
{
ProdutionLeft=E;
Pop(3);
printf("用产生式 2 归约\n");
char* Temp=NewTemp();
GEN("-",E_Place,T_Place,Temp);
strcpy(E_Place,Temp);
printf("生成四元式:(-,E_Place,T_Place,E_Place)\n");
}
else if(3==ProductionNum)
{
ProdutionLeft=E;
Pop(1);
printf("用产生式 3 归约\n");
char* Temp=NewTemp();
GEN("",T_Place,"",Temp);
strcpy(E_Place,Temp);
}
else if(4==ProductionNum)
{
ProdutionLeft=T;
Pop(3);
printf("用产生式 4 归约\n");
char* Temp=NewTemp();
GEN("*",T_Place,F_Place,Temp);
strcpy(T_Place,Temp);
printf("生成四元式:(*,T_Place,F_Place,T_Place)\n");
}
else if(5==ProductionNum)
{
ProdutionLeft=T;
Pop(3);
printf("用产生式 5 归约\n");
char* Temp=NewTemp();
GEN("/",T_Place,F_Place,Temp);
strcpy(T_Place,Temp);
printf("生成四元式:(/,T_Place,F_Place,T_Place)\n");
}
else if(6==ProductionNum)
{
ProdutionLeft=T;
Pop(1);
printf("用产生式 6 归约\n");
char* Temp=NewTemp();
GEN("+",F_Place,"",Temp);
strcpy(T_Place,Temp);
}
else if(7==ProductionNum)
{
ProdutionLeft=F;
Pop(3);
printf("用产生式 7 归约\n");
char* Temp=NewTemp();
GEN("+",EBracket_Place,"",Temp);
strcpy(F_Place,Temp);
}
else if(8==ProductionNum)
{
ProdutionLeft=F;
Pop(1);
printf("用产生式 8 归约\n");
char* Temp=NewTemp();
GEN("+",i_Place,"",Temp);
strcpy(F_Place,Temp);
}
else
{
printf("分析语句 %i 时产生式编号超出范围!分析结束\n",SentenceCount);
return 0;
}
Push(Goto[TopState][ProdutionLeft]);
}
}
printf("栈顶状态:%i\n",TopState);
printf("扫描的单词类型:%i\n",InputWordType);
printf("语句正确\n");
return 1;
}
////////////////////////状态栈的压栈和出栈程序
int Push( int State )
{
if (SMAX==StackPoint)
{
printf("状态栈已满!");
return 0;
}
StateStack[StackPoint]=State;
StackPoint++;
TopState=State;//用topstate存储当前栈顶状态
return 1;
}
int Pop(int count) //内部要把处理完的数组的顶部的值赋给topstate
{
StackPoint=StackPoint-count;
if (StackPoint<0)
{
printf("状态栈指针不能为负值!");
return 0;
}
TopState=StateStack[StackPoint-1];
return 1;
}
////////////////////////语法分析部分
void GEN(char *Op, char *Arg1, char *Arg2, char *Result)
{
strcpy (pQuad[NXQ].op, Op); //全局变量,是用于存放四元式的数组
strcpy (pQuad[NXQ].arg1, Arg1);
strcpy (pQuad[NXQ].arg2, Arg2);
strcpy (pQuad[NXQ].result, Result);
NXQ++; /*全局变量NXQ用于指示所要产生的下一个四元式的编号*/
}
char *NewTemp(void) /*产生一个临时变量*/
{
char *TempID=(char*)malloc(PMAX);
sprintf (TempID, "T%d", NXTemp++);
return TempID;
}
void NextSentence(FILE* fp)
{
while ('#' != ch)
{
ch=fgetc(fp);
}
SentenceCount++;
return;
}
/////////////////////////主程序
int main(int argc, char* argv[])
{
FILE *p=fopen("D:\\YDW.txt","r");
if(ch=fgetc(p)==EOF)//不管小括号内的判断是否成功,p指针都会向后移一个位置,判断不成功,ch中存的字符不变
{
printf("The file is null.\n");
return 0;
}
do
{
TopState=0;
StackPoint=0;
memset(StateStack,-1,sizeof(StateStack));
printf("语句分析开始\n");
scanner(p);
SLRControl(p);
NextSentence(p);
} while (EOF!=fgetc(p));
fclose(p);
return 0;
}
六.测试用例及运行结果分析
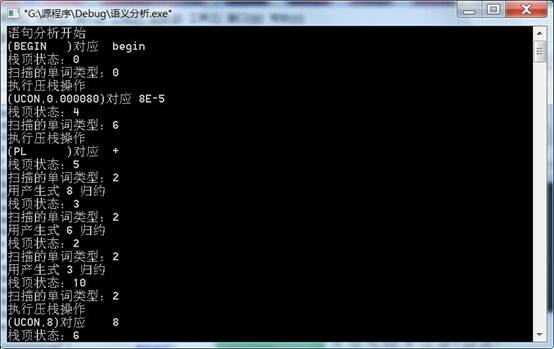
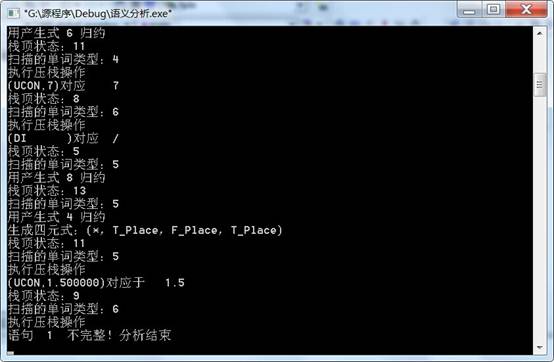
测试用例:begin 8E-5+8*7/1.5
运行结果: