升级JDK选型报告
选型范围: JDK 6,JDK 7,JDK 8
JDK各版本的新特性
JDK后一版本包含之前所有版本的新特性
JDK 6
简化Web Services
Mustang 将简化Web services 的开发和发布. XML和Web服务一直都是Mustang的关注重点.. Mustang为此引入了JAX-WS(Java Architecture for XML-Web Services) 2.0 以及JAXB(Java Architecture for XML Binding) 2.0.. 同时还有Streaming API for XML (STaX), 它提供了一个双向API,这个API可以通过一个事件流来读取或者写入XML,其中包括跳过某个部分,然后直接关注与文档中的另外一个小部分的能力。
Scripting,整合脚本语言
目前来讲,Java 开发者们必须在Java之外独立地额外编码来使用non-Java 脚本语言。这个头痛的问题将被Mustang 消灭,开发者将更加轻松的使用Perl、PHP、Python、JavaScript 和Ruby等脚本语言。新的框架将允许人们操作任意的脚本语言,和使用Java 对象。 Java SE6中实现了JSR223。这是一个脚本框架,提供了让脚本语言来访问Java内部的方法。你可以在运行的时候找到脚本引擎,然后调用这个引擎去执行脚本。这个脚本API允许你为脚本语言提供Java支持。另外,Web Scripting Framework允许脚本代码在任何的Servlet容器(例如Tomcat)中生成Web内容。
Database,绑定Derby
开源嵌入式数据库 Derby(JavaDB) 绑定在JDK 1.6中.具体可以参考:JDK 1.6 将绑定开源数据库 Derby
更丰富的Desktop APIs
Mustang中拥有更多强的桌面API提供给开发者, 开发者可以更简单地开发更强大的桌面应用, 比如启动界面的支持,系统托盘的支持,JTable排序等等
监视和管理
Java SE 6中对内存泄漏增强了分析以及诊断能力。当遇到java.lang.OutOfMemory异常的时候,可以得到一个完整的堆栈信息,并且当堆已经满了的时候,会产生一个Log文件来记录这个致命错误。另外,JVM还添加了一个选项,允许你在堆满的时候运行脚本。(这也就是提供了另外一种方法来诊断错误)
增强的JMX 监视API在MBean的属性值传入了一个特定的参数的时候,允许这个应用程序发送一个事件通告。(这里的属性值可以在很复杂的类型中)
对于Solaris 10的用户,为Solaris提供的Hotspot JVM中,提供了一种通过Solaris DTrace(这是个系统的调试工具)来追踪显示JVM内部的活动情况,包括垃圾收集,类装载,线程,锁等等。
Pluggable Annotations
从Java SE 5 带来得新特性Annotations,将在Mustang继续扮演重要角色..
Compiler API:访问编译器
对于Java开发工具, 或者Web框架 等的开发者来说, 利用编译器编译动态生成的代码, 是一个普遍的需求.
Mustang实现了JSR 199, 提供了Java编译器API(应用程序接口),允许你从一个Java应用程序中去编译其他的Java源程序--比如在应用程序中动态生成的一些源代码..
Security:安全性
Java SE 6的安全部分,增加了 XML-Digital Signature (XML-DSIG) APIs, 整合了GSS/Kerberos的操作API,LDAP上的JAAS认证。
Instrumentation
利用 Java 代码,即 java.lang.instrument 做动态 Instrumentation 是 Java SE 5 的新特性,它把 Java 的 instrument 功能从本地代码中解放出来,使之可以用 Java 代码的方式解决问题。在 Java SE 6 里面,instrumentation 包被赋予了更强大的功能:启动后的 instrument、本地代码(native code)instrument,以及动态改变 classpath 等等。在 Java SE 5 当中,开发者只能在 premain 当中施展想象力,所作的 Instrumentation 也仅限与 main 函数执行前,这样的方式存在一定的局限性。在 Java SE 6 的 Instrumentation 当中,有一个跟 premain“并驾齐驱”的“agentmain”方法,可以在 main 函数开始运行之后再运行。
Http
在 Java SE 6 当中,围绕着 HTTP 协议出现了很多实用的新特性:NTLM 认证提供了一种 Window 平台下较为安全的认证机制;JDK 当中提供了一个轻量级的 HTTP 服务器;提供了较为完善的 HTTP Cookie 管理功能;更为实用的 NetworkInterface;DNS 域名的国际化支持等等。
HTTP Cookie管理可以应用客户操作临时变量的保存,如查询条件,当前状态等
JMX与系统管理
管理系统的构架 其中 Agent / SubAgent 起到的就是翻译的作用:把 IT 资源报告的消息以管理系统能理解的方式传送出去。也许读者有会问,为什么需要 Agent 和 SubAgent 两层体系呢?这里有两个现实的原因:
管理系统一般是一个中央控制的控制软件,而 SubAgent 直接监控一些资源,往往和这
些资源分布在同一物理位置。当这些 SubAgent 把状态信息传输到管理系统或者传达管理系统的控制指令的时候,需要提供一些网络传输的功能。
1. 管理系统的消息是有一定规范的,消息的翻译本身是件复杂而枯燥的事情。
一般来说,管理系统会将同一物理分布或者功能类似的 SubAgent 分组成一组,由一个共用的 Agent 加以管理。在这个 Agent 里封装了 1 和 2 的功能。
JMX 和管理系统
JMX 既是 Java 管理系统的一个标准,一个规范,也是一个接口,一个框架。图 2 展示了 JMX 的基本架构。
JMX 构架和其它的资源系统一样,JMX 是管理系统和资源之间的一个接口,它定义了管理系统和资源之间交互的标准。javax.management.MBeanServer 实现了 Agent 的功能,以标准的方式给出了管理系统访问 JMX 框架的接口。而 javax.management.MBeans 实现了 SubAgent 的功能,以标准的方式给出了 JMX 框架访问资源的接口。而从类库的层次上看,JMX 包括了核心类库 java.lang.management 和 javax.management 包。java.lang.management 包提供了基本的 VM 监控功能,而 javax.management 包则向用户提供了扩展功能。 JMX帮助开发者监控JVM的信息。
编辑器API
JDK 6 提供了在运行时调用编译器的 API。在传统的 JSP 技术中,服务器处理 JSP 通常需要进行下面 6 个步骤:
1. 分析 JSP 代码;
2. 生成 Java 代码;
3. 将 Java 代码写入存储器;
4. 启动另外一个进程并运行编译器编译 Java 代码;
5. 将类文件写入存储器;
6. 服务器读入类文件并运行;
但如果采用运行时编译,可以同时简化步骤 4 和 5,节约新进程的开销和写入存储器的输出开销,提高系统效率。实际上,在 JDK 5 中,Sun 也提供了调用编译器的编程接口。然而不同的是,老版本的编程接口并不是标准 API 的一部分,而是作为 Sun 的专有实现提供的,而新版则带来了标准化的优点。
新 API 的第二个新特性是可以编译抽象文件,理论上是任何形式的对象 —— 只要该对象实现了特定的接口。有了这个特性,上述例子中的步骤 3 也可以省略。整个 JSP 的编译运行在一个进程中完成,同时消除额外的输入输出操作。
第三个新特性是可以收集编译时的诊断信息。作为对前两个新特性的补充,它可以使开发人员轻松的输出必要的编译错误或者是警告信息,从而省去了很多重定向的麻烦
一些有趣的新特性:
1 本地行为 java.awt.Desktop
比如用默认程序打开文件,用默认浏览器打开url,再也不用那个browserlauncher那么费劲了
Desktop desk=Desktop.getDesktop();
desk.browse(new URI("/"));
desk.open(file)
desk.print(file)
2 console下密码输入 java.io.Console
再也不用自己写线程去删echo字符了
Console console = System.console();
char password[] = console.readPassword("Enter password: ");
3 获取磁盘空间大小 java.io.File的新方法
File roots[] = File.listRoots();
for (File root : roots) {
System.out.println(root.getPath()+":"+root.getUsableSpace()
+"/"+root.getTotalSpace());
}
4 专利过期,可以提供合法的lzw的gif encoder了
ImageIO.write(input, "GIF", outputFile);
5 JAXB2.0 增加了java-to-xml schema,完成java bean,xml间转换非常容易
6 xml数字签名 javax.xml.crypto,记得以前似乎只有ibm有个类库实现了
7 编译器,以前是com.sun.tools.javac,现在是javax.tools.JavaCompiler
有人写了完全在内存里的生成源文件,编译,反射运行的过程,比较好玩。
8 脚本引擎,javax.script,内嵌的是Mozilla Rhino1.6r2 支持ECMAScript1.6
语法新特性
1,switch中可以使用字串
Java代码
1.String s = "test";
2.switch (s) {
3.case "test" :
4. System.out.println("test");
5.case "test1" :
6. System.out.println("test1");
7.break ;
8.default :
9. System.out.println("break");
10.break ;
11. }
String s = "test"; switch (s) { case "test" : System.out.println("test"); case "test1" : System.out.println("test1"); break ; default : System.out.println("break"); break ; }
2,"<>"这个玩意儿的运用List<String> tempList = new ArrayList<>(); 即泛型实例化类型自动推断。
3. 语法上支持集合,而不一定是数组
Java代码
1.final List<Integer> piDigits = [ 1,2,3,4,5,8 ];
final List<Integer> piDigits = [ 1,2,3,4,5,8 ];
4. 新增一些取环境信息的工具方法
Java代码
1.File System.getJavaIoTempDir() // IO临时文件夹
2.File System.getJavaHomeDir() // JRE的安装目录
3.File System.getUserHomeDir() // 当前用户目录
4.File System.getUserDir() // 启动java进程时所在的目录
5........
File System.getJavaIoTempDir() // IO临时文件夹File System.getJavaHomeDir() // JRE的安装目录File System.getUserHomeDir() // 当前用户目录File System.getUserDir() // 启动java进程时所在的目录.......
5. Boolean类型反转,空指针安全,参与位运算
Java代码
1.Boolean Booleans.negate(Boolean booleanObj)
2. True => False , False => True, Null => Null
3.boolean Booleans.and(boolean[] array)
4.boolean Booleans.or(boolean[] array)
5.boolean Booleans.xor(boolean[] array)
6.boolean Booleans.and(Boolean[] array)
7.boolean Booleans.or(Boolean[] array)
8.boolean Booleans.xor(Boolean[] array)
Boolean Booleans.negate(Boolean booleanObj)True => False , False => True, Null => Nullboolean Booleans.and(boolean[] array)boolean Booleans.or(boolean[] array)boolean Booleans.xor(boolean[] array)boolean Booleans.and(Boolean[] array)boolean Booleans.or(Boolean[] array)boolean Booleans.xor(Boolean[] array)
6. 两个char间的equals
Java代码
1.boolean Character.equalsIgnoreCase(char ch1, char ch2)
boolean Character.equalsIgnoreCase(char ch1, char ch2)
7,安全的加减乘除
Java代码
1.int Math.safeToInt(long value)
2.int Math.safeNegate(int value)
3.long Math.safeSubtract(long value1, int value2)
4.long Math.safeSubtract(long value1, long value2)
5.int Math.safeMultiply(int value1, int value2)
6.long Math.safeMultiply(long value1, int value2)
7.long Math.safeMultiply(long value1, long value2)
8.long Math.safeNegate(long value)
9.int Math.safeAdd(int value1, int value2)
10.long Math.safeAdd(long value1, int value2)
11.long Math.safeAdd(long value1, long value2)
12.int Math.safeSubtract(int value1, int value2)
JDK 7
Java 1.4到1.5的修改很大,在编译compile-time 方面提升很大,Java 6在运行时runtime智能上做了优化,Java 7的主要改进:模块化。我们分析一下Java 7的主要修改:
* Modularization 模块化– JSR 294 或者 Project Jigsaw
* JVM 对动态语言的支持
* 更多新的 I/O APIs 即将完成,包括真正的异步I/O 和最终的真实的文件系统 file system API – JSR 203
* 对XML本地语言支持. (可能的probable)
* Safe rethrow – 允许catch捕获语句让编译器更加聪明的知道基于什么情况下重新throw什么内容。
* Null dereference expressions – Null 和 ‘?’ syntax 比较,语法类似 Groovy? 让开发者避免过多的空值验证。
* 更好的类型推断 Better type inference
* 多重捕获Multi-catch
* JSR 296 – Swing 应用框架 application framework – 这方面需要更简单和简洁。
“小的”sun方面的修改有:
* 升级的类加载class loader 架构;
* XRender pipeline for Java 2D:是Open JDK ntegrators Challenge project项目;
* Swing 更新 – JXLayer, DatePicker, CSS styling 等;
* JavaFX
sun方面“快速”的修改,主要是性能更新:
* 并发方面的细微调整 concurrency tweaks (JSR 166),更好的支持Multicore
* G1 垃圾收集器Garbage collector - 带来更小的中断时间,有希望替代 CMS (Concurrent mark sweep) GC
* 64 bit VM的压缩指针Compressed pointer
* MVM-lite – 多个虚拟机能够独立运行应用和允许用kill -9杀死java应用。
类型推导
JDK 1.7引入一个新的操作符<>,也被称作钻石操作符,它使得构造方法也可以进行类型推导 。在Java 7之前,类型推导只对方法可用,正如Joshua Bloch在Effiective Java第二版中所预言 的那样,现在终于在构造方法中实现了。在这之前,你得在对象创建表达式的左右两边同时指定类型,现在你只需要在左边指定就可以了,就像下面这样。
JDK 7之前
Map<String, List<String>> employeeRecords = new HashMap<String, List<String>>(); List<Integer> primes = new ArrayList<Integer>();
JDK 7
Map<String, List<String>> employeeRecords = new HashMap<>();
List<Integer> primes = new ArrayList<>();
在Java 7中可以少敲些代码了,尤其是在使用集合的时候,因为那里大量用到了泛型。点击这里了解更多关于Java钻石操作符的信息。(译注:原文没提供链接啊)
在switch中支持String
在JDK 7之前 ,只有整型才能用作switch-case语句的选择因子。在JDK7中,你可以将String用作选择因子了。比如:
String state = "NEW";
switch (day) {
case "NEW": System.out.println("Order is in NEW state"); break;
case "CANCELED": System.out.println("Order is Cancelled"); break;
case "REPLACE": System.out.println("Order is replaced successfully"); break;
case "FILLED": System.out.println("Order is filled"); break;
default: System.out.println("Invalid");
}
比较的时候会用到String的equals和hashCode()方法,因此这个比较是大小写敏感的。在switch中使用String的好处是,和直接用if-else相比 ,编译器可以生成更高效的代码。更详细的说明请点击这里。
自动资源管理(Automatic Resource Management)
在JDK 7之前,我们需要使用一个finally块,来确保资源确实被释放掉,不管try块是完成了还是中断了。比如说读取文件或者输入流的时候,我们需要在finally块中关闭它们,这样会导致很多的样板代码,就像下面这样:
public static void main(String args[]) {
FileInputStream fin = null;
BufferedReader br = null;
try {
fin = new FileInputStream("info.xml");
br = new BufferedReader(new InputStreamReader(fin));
if (br.ready()) {
String line1 = br.readLine();
09
System.out.println(line1);
}
} catch (FileNotFoundException ex) {
System.out.println("Info.xml is not found");
} catch (IOException ex) {
System.out.println("Can't read the file");
} finally {
try {
if (fin != null) fin.close();
if (br != null) br.close();
} catch (IOException ie) {
System.out.println("Failed to close files");
}
}
}
看下这段代码 ,是不是很多样板代码?
而在Java 7里面,你可以使用try-with-resource的特性来自动关闭资源,只要是实现了AutoClosable和Cloaeable接口的都可以,Stream, File, Socket,数据库连接等都已经实现了。JDK 7引入了try-with-resource语句,来确保每个资源在语句结束后都会调用AutoCLosable接口的close()方法进行关闭。下面是Java 7中的一段示例代码,它看起来可是简洁多了:
public static void main(String args[]) {
try (FileInputStream fin = new FileInputStream("info.xml");
BufferedReader br = new BufferedReader(new InputStreamReader(fin));) {
if (br.ready()) {
String line1 = br.readLine();
System.out.println(line1);
}
} catch (FileNotFoundException ex) {
System.out.println("Info.xml is not found");
} catch (IOException ex) {
System.out.println("Can't read the file");
}
}
由于Java负责关闭那些打开的资源比如文件和流这种,因此文件描述符泄露的事情应该不会再发生了,应该也不会再看到文件描述符错误的提示了。甚至JDBC 4.1都已经开始支持了AutoClosable了。
Fork Join框架
Fork/join框架是ExecutorService接口的实现,它使得你可以充分利用现代服务器多处理器带来的好处。这个框架是为了那些能递归地拆分成更小任务的工作而设计的。它的目标是去压榨处理器的能力以提升程序的性能。就像别的ExecutorService的实现一样,fork/join框架也是把任务分发给线程池中的多个线程。它的不同之处在于它使用的是一种工作窃取算法(work-stealing algorithm),这和生产者消费者的算法有很大的不同。已经处理完任务的工作线程可以从别的繁忙的线程那里窃取一些任务来执行。fork/join框架的核心是ForkJoinPool类,它继承自AbstractExecutorService。ForkJoinPool类实现了核心的工作窃取算法,可以执行ForkJoinTask进程。你可以把代码封装在一个ForkJoinTask的子类里,比如RecursiveTask或者RecursiveAction。更多信息就参考这里。
数值字面量中使用下划线
JDK 7中,你可以在数值字面量中使用'_'来提升可读性。这对在源代码中使用了大数字的人来说尤其有用,例如在金融或者计算领域中。比方说这么写,
int billion = 1_000_000_000; // 10^9
long creditCardNumber = 1234_4567_8901_2345L; //16 digit number
long ssn = 777_99_8888L;
double pi = 3.1415_9265;
float pif = 3.14_15_92_65f;
你可以在合适的位置插入下划线使得它可读性更强,比如说一个很大的数字可以每隔三位放一个下划线,对于信用卡卡号而言,通常是16位长度,你可以每隔4个数字就放一个下划线,就如它们在卡片上所显示的那样。顺便说一句,要记住,你不能在小数后面,或者数字的开始和结束的地方放下划线。比如说,下面的数值字面量就是不正确的,因为它们错误地使用了下划线:
double pi = 3._1415_9265; // underscore just after decimal point
long creditcardNum = 1234_4567_8901_2345_L; //underscore at the end of number
long ssn = _777_99_8888L; //undersocre at the beginning
你可以读下我的这篇文章了解更多的一些关于下划线使用的例子。
在一个catch块中捕获多个异常
JDK 7中,单个catch块可以处理多个异常类型。
比如说在JDK 7之前,如果你想捕获两种类型的异常你得需要两个catch块,尽管两个
的处理逻辑都是一样的:
try {
......
} catch(ClassNotFoundException ex) {
ex.printStackTrace();
} catch(SQLException ex) {
ex.printStackTrace();
}
而在JDK 7中,你只须使用一个catch块就搞定了,异常类型用‘|’进行分隔:
try {
......
} catch(ClassNotFoundException|SQLException ex) {
ex.printStackTrace();
}
顺便说一句,这种用法是不包括异常的子类型的。比如说,下面这个多个异常的捕获语句就会抛出编译错误:
try {
......
} catch (FileNotFoundException | IOException ex) {
ex.printStackTrace();
}
这是因为FileNotFoundException是IOException 的子类,在编译的时候会抛出下面的错误: java.io.FileNotFoundException is a subclass of alternative java.io.IOException at Test.main(Test.java:18)。
使用"ob"前缀的二进制字面量
JDK7中,对于整型类型(byte, short, int 和long)来说,你可以用'0b'前缀来表明这是一个二进制的字面量,就像C/C++中那样。在这之前,你只能使用8进制(前缀'0')或者16进制(前缀是'0x'或者‘0X')的字面量。
int mask = 0b01010000101;
这样写好处更明显:
int binary = 0B0101_0000_1010_0010_1101_0000_1010_0010;
8.Java NIO 2
Java SE 7中引入了java.nio.file包,以及相关的java.nio.file.attibute包,全面支持了文件
IO以及对默认文件系统的访问。它同时还引入了Path 类,你可以用它来代表操作系统中的任意一个路径。新的文件系统API兼容老的版本,并且提供了几个 非常实用的方法,可以用来检查,删除,拷贝和移动文件。比如,你可以在Java中判断一个文件是否是隐藏文件。你还可以在Java中创建软链接和硬链接。JDK 7的新的文件API还能够使用通配符来进行文件的搜索。你还可以用它来监测某个目录 是否有变动。我推荐你看下它的官方文档来了解更多的一些有意思的特性。
G1垃圾回收器
JDK7中引入了一个新的垃圾回收器,G1,它是Garbage First的缩写。G1回收器优先回收垃圾最多的区域。为了实现这个策略它把堆分成了多个区域,就好比Java 7之前分成三个区域那样(新生代,老生代和持久代)。G1回收器是一个可预测的回收器,同时对那些内存密集型的程序它还能保证较高的吞吐量。
重抛异常的改进
Java SE 7的编译器和之前的版本相比,在重新抛出异常这块进行了更精确的分析。这使得你在方法声明的throws子句中可以指定更精确的异常类型。在JDK 7之前,重抛的异常的类型被认为是catch参数中的指定的异常类型。比如说,如果你的try块中抛出了一个ParseException以及一个IOException,为了捕获所有的异常,然后重新抛出来,你会去捕获Exception类型的异常,并且声明你的方法抛出的异常类型是Exception。这种方式有点不太精确,因为你实际抛出的是一个通用的Exception类型,而调用你的方法的语句需要去捕获这个通用的异常。看一下Java 1.7前的这段异常处理的代码可能你会更明白些:
public void obscure() throws Exception{
try {
new FileInputStream("abc.txt").read();
new SimpleDateFormat("ddMMyyyy").parse("12-03-2014");
} catch (Exception ex) {
System.out.println("Caught exception: " + ex.getMessage());
throw ex;
}
}
JDK 7以后你就可以在方法的throws子句中明确的指定异常类型了。精确的异常重抛指的是,如果你在catch块中重新抛出异常,实际真正抛出的异常类型会是:
你的try块抛出的异常
还没有被前面的catch块处理过,并且
catch的参数类型是Exception的某个子类。
这使得异常重抛变得更精确。你可以更准确的知道方法抛出的是何种异常,因此你可以更好的处理它们,就像下面这段代码这样:
public void precise() throws ParseException, IOException {
try {
new FileInputStream("abc.txt").read();
new SimpleDateFormat("ddMMyyyy").parse("12-03-2014");
} catch (Exception ex) {
System.out.println("Caught exception: " + ex.getMessage());
throw ex;
}
}
Java SE 7的编译器允许你在preciese() 方法声明的throws子句中指定ParseException和IOException类型,这是因为你抛出的异常是声明的这些异常类型的父类,比如这里我们抛出的是java.lang.Exception,它是所有受检查异常的父类。有的地方你会看到catch参数中带final关键字,不过这个不再是强制的了。
JDK 8
函数式接口
Java 8 引入的一个核心概念是函数式接口(Functional Interfaces)。通过在接口里面添加一个抽象方法,这些方法可以直接从接口中运行。如果一个接口定义个唯一一个抽象方法,那么这个接口就成为函数式接口。同时,引入了一个新的注解:@FunctionalInterface。可以把他它放在一个接口前,表示这个接口是一个函数式接口。这个注解是非必须的,只要接口只包含一个方法的接口,虚拟机会自动判断,不过最好在接口上使用注解 @FunctionalInterface 进行声明。在接口中添加了 @FunctionalInterface 的接口,只允许有一个抽象方法,否则编译器也会报错。
java.lang.Runnable 就是一个函数式接口。
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
Lambda 表达式
函数式接口的重要属性是:我们能够使用 Lambda 实例化它们,Lambda 表达式让你能够将函数作为方法参数,或者将代码作为数据对待。Lambda 表达式的引入给开发者带来了不少优点:在 Java 8 之前,匿名内部类,监听器和事件处理器的使用都显得很冗长,代码可读性很差,Lambda 表达式的应用则使代码变得更加紧凑,可读性增强;Lambda 表达式使并行操作大集合变得很方便,可以充分发挥多核 CPU 的优势,更易于为多核处理器编写代码;
Lambda 表达式由三个部分组成:第一部分为一个括号内用逗号分隔的形式参数,参数是函数式接口里面方法的参数;第二部分为一个箭头符号:->;第三部分为方法体,可以是表达式和代码块。语法如下:
1. 方法体为表达式,该表达式的值作为返回值返回。
(parameters) -> expression
2. 方法体为代码块,必须用 {} 来包裹起来,且需要一个 return 返回值,但若函数式接口里面方法返回值是 void,则无需返回值。
(parameters) -> { statements; }
例如,下面是使用匿名内部类和 Lambda 表达式的代码比较。
下面是用匿名内部类的代码:
button.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
System.out.print("Helllo Lambda in actionPerformed");
}
});
下面是使用 Lambda 表达式后:
button.addActionListener(
\\actionPerformed 有一个参数 e 传入,所以用 (ActionEvent e)
(ActionEvent e)->
System.out.print("Helllo Lambda in actionPerformed")
);
上面是方法体包含了参数传入 (ActionEvent e),如果没有参数则只需 ( ),例如 Thread 中的 run 方法就没有参数传入,当它使用 Lambda 表达式后:
Thread t = new Thread(
\\run 没有参数传入,所以用 (), 后面用 {} 包起方法体
() -> {
System.out.println("Hello from a thread in run");
}
);
通过上面两个代码的比较可以发现使用 Lambda 表达式可以简化代码,并提高代码的可读性。
为了进一步简化 Lambda 表达式,可以使用方法引用。例如,下面三种分别是使用内部类,使用 Lambda 表示式和使用方法引用方式的比较:
//1. 使用内部类
Function<Integer, String> f = new Function<Integer,String>(){
@Override
public String apply(Integer t) {
return null;
}
};
//2. 使用 Lambda 表达式
Function<Integer, String> f2 = (t)->String.valueOf(t);
//3. 使用方法引用的方式
Function<Integer, String> f1 = String::valueOf;
要使用 Lambda 表达式,需要定义一个函数式接口,这样往往会让程序充斥着过量的仅为 Lambda 表达式服务的函数式接口。为了减少这样过量的函数式接口,Java 8 在 java.util.function 中增加了不少新的函数式通用接口。例如:
Function<T, R>:将 T 作为输入,返回 R 作为输出,他还包含了和其他函数组合的默认方法。
Predicate<T> :将 T 作为输入,返回一个布尔值作为输出,该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(与、或、非)。
Consumer<T> :将 T 作为输入,不返回任何内容,表示在单个参数上的操作。
例如,People 类中有一个方法 getMaleList 需要获取男性的列表,这里需要定义一个函数式接口 PersonInterface:
interface PersonInterface {
public boolean test(Person person);
}
public class People {
private List<Person> persons= new ArrayList<Person>();
public List<Person> getMaleList(PersonInterface filter) {
List<Person> res = new ArrayList<Person>();
persons.forEach(
(Person person) ->
{
if (filter.test(person)) {//调用 PersonInterface 的方法
res.add(person);
}
}
);
return res;
}
}
为了去除 PersonInterface 这个函数式接口,可以用通用函数式接口 Predicate 替代如下:
class People{
private List<Person> persons= new ArrayList<Person>();
public List<Person> getMaleList(Predicate<Person> predicate) {
List<Person> res = new ArrayList<Person>();
persons.forEach(
person -> {
if (predicate.test(person)) {//调用 Predicate 的抽象方法 test
res.add(person);
}
});
return res;
}
}
接口的增强
Java 8 对接口做了进一步的增强。在接口中可以添加使用 default 关键字修饰的非抽象方法。还可以在接口中定义静态方法。如今,接口看上去与抽象类的功能越来越类似了。
默认方法
Java 8 还允许我们给接口添加一个非抽象的方法实现,只需要使用 default 关键字即可,这个特征又叫做扩展方法。在实现该接口时,该默认扩展方法在子类上可以直接使用,它的使用方式类似于抽象类中非抽象成员方法。但扩展方法不能够重载 Object 中的方法。例如:toString、equals、 hashCode 不能在接口中被重载。
例如,下面接口中定义了一个默认方法 count(),该方法可以在子类中直接使用。 public interface DefaultFunInterface {
//定义默认方法 count
default int count(){
return 1;
}
}
public class SubDefaultFunClass implements DefaultFunInterface {
public static void main(String[] args){
//实例化一个子类对象,改子类对象可以直接调用父接口中的默认方法 count
SubDefaultFunClass sub = new SubDefaultFunClass();
sub.count();
}
}
静态方法
在接口中,还允许定义静态的方法。接口中的静态方法可以直接用接口来调用。
例如,下面接口中定义了一个静态方法 find,该方法可以直接用 StaticFunInterface .find() 来调用。
public interface StaticFunInterface {
public static int find(){
return 1;
}
}
public class TestStaticFun {
public static void main(String[] args){
//接口中定义了静态方法 find 直接被调用
StaticFunInterface.fine();
}
}
集合之流式操作
Java 8 引入了流式操作(Stream),通过该操作可以实现对集合(Collection)的并行处理和函数式操作。根据操作返回的结果不同,流式操作分为中间操作和最终操作两种。最终操作返回一特定类型的结果,而中间操作返回流本身,这样就可以将多个操作依次串联起来。根据流的并发性,流又可以分为串行和并行两种。流式操作实现了集合的过滤、排序、映射等功能。
Stream 和 Collection 集合的区别:Collection 是一种静态的内存数据结构,而 Stream 是有关计算的。前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
串行和并行的流
流有串行和并行两种,串行流上的操作是在一个线程中依次完成,而并行流则是在多个线程上同时执行。并行与串行的流可以相互切换:通过 stream.sequential() 返回串行的流,通过 stream.parallel() 返回并行的流。相比较串行的流,并行的流可以很大程度上提高程序的执行效率。
下面是分别用串行和并行的方式对集合进行排序。
串行排序:
List<String> list = new ArrayList<String>();
for(int i=0;i<1000000;i++){
double d = Math.random()*1000;
list.add(d+"");
}
long start = System.nanoTime();//获取系统开始排序的时间点
int count= (int) ((Stream) list.stream().sequential()).sorted().count();
long end = System.nanoTime();//获取系统结束排序的时间点
long ms = TimeUnit.NANOSECONDS.toMillis(end-start);//得到串行排序所用的时间 System.out.println(ms+”ms”);
并行排序:
List<String> list = new ArrayList<String>();
for(int i=0;i<1000000;i++){
double d = Math.random()*1000;
list.add(d+"");
}
long start = System.nanoTime();//获取系统开始排序的时间点
int count = (int)((Stream) list.stream().parallel()).sorted().count();
long end = System.nanoTime();//获取系统结束排序的时间点
long ms = TimeUnit.NANOSECONDS.toMillis(end-start);//得到并行排序所用的时间 System.out.println(ms+”ms”);
串行输出为 1200ms,并行输出为 800ms。可见,并行排序的时间相比较串行排序时间要少不少。
中间操作
该操作会保持 stream 处于中间状态,允许做进一步的操作。它返回的还是的 Stream,允许更多的链式操作。常见的中间操作有:
filter():对元素进行过滤;
sorted():对元素排序;
map():元素的映射;
distinct():去除重复元素;
subStream():获取子 Stream 等。
例如,下面是对一个字符串集合进行过滤,返回以“s”开头的字符串集合,并将该集合依次打印出来:
list.stream()
.filter((s) -> s.startsWith("s"))
.forEach(System.out::println);
这里的 filter(...) 就是一个中间操作,该中间操作可以链式地应用其他 Stream 操作。 终止操作
该操作必须是流的最后一个操作,一旦被调用,Stream 就到了一个终止状态,而且不能再使用了。常见的终止操作有:
forEach():对每个元素做处理;
toArray():把元素导出到数组;
findFirst():返回第一个匹配的元素;
anyMatch():是否有匹配的元素等。
例如,下面是对一个字符串集合进行过滤,返回以“s”开头的字符串集合,并将该集合依次打印出来:
list.stream() //获取列表的 stream 操作对象
.filter((s) -> s.startsWith("s"))//对这个流做过滤操作
.forEach(System.out::println);
这里的 forEach(...) 就是一个终止操作,该操作之后不能再链式的添加其他操作了。
注解的更新
对于注解,Java 8 主要有两点改进:类型注解和重复注解。
Java 8 的类型注解扩展了注解使用的范围。在该版本之前,注解只能是在声明的地方使用。现在几乎可以为任何东西添加注解:局部变量、类与接口,就连方法的异常也能添加注解。新增的两个注释的程序元素类型 ElementType.TYPE_USE 和 ElementType.TYPE_PARAMETER 用来描述注解的新场合。ElementType.TYPE_PARAMETER 表示该注解能写在类型变量的声明语句中。而 ElementType.TYPE_USE 表示该注解能写在使用类型的任何语句中(例如声明语句、泛型和强制转换语句中的类型)。
对类型注解的支持,增强了通过静态分析工具发现错误的能力。原先只能在运行时发现的问题可以提前在编译的时候被排查出来。Java 8 本身虽然没有自带类型检测的框架,但可以通过使用 Checker Framework 这样的第三方工具,自动检查和确认软件的缺陷,提高生产效率。
例如,下面的代码可以通过编译,但是运行时会报 NullPointerException 的异常。 public class TestAnno {
public static void main(String[] args) {
Object obj = null;
obj.toString();
}
}
为了能在编译期间就自动检查出这类异常,可以通过类型注解结合 Checker Framework 提前排查出来:
import org.checkerframework.checker.nullness.qual.NonNull;
public class TestAnno {
public static void main(String[] args) {
@NonNull Object obj = null;
obj.toString();
}
}
编译时自动检测结果如下:
点击查看代码清单
另外,在该版本之前使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8 引入了重复注解机制,这样相同的注解可以在同一地方声明多次。重复注解机制本身必须用 @Repeatable 注解。
例如,下面就是用 @Repeatable 重复注解的例子:
@Retention(RetentionPolicy.RUNTIME) \\该注解存在于类文件中并在运行时可以通过反射获取
@interface Annots {
Annot[] value();
}
@Retention(RetentionPolicy.RUNTIME) \\该注解存在于类文件中并在运行时可以通过反射获取
@Repeatable(Annots.class)
@interface Annot {
String value();
}
@Annot("a1")@Annot("a2")
public class Test {
public static void main(String[] args) {
Annots annots1 = Test.class.getAnnotation(Annots.class);
System.out.println(annots1.value()[0]+","+annots1.value()[1]);
// 输出: @Annot(value=a1),@Annot(value=a2)
Annot[] annots2 = Test.class.getAnnotationsByType(Annot.class);
System.out.println(annots2[0]+","+annots2[1]);
// 输出: @Annot(value=a1),@Annot(value=a2)
}
}
注释 Annot 被 @Repeatable( Annots.class ) 注解。Annots 只是一个容器,它包含 Annot 数组, 编译器尽力向程序员隐藏它的存在。通过这样的方式,Test 类可以被 Annot 注解两次。重复注释的类型可以通过 getAnnotationsByType() 方法来返回。
安全性
现今,互联网环境中存在各种各种潜在的威胁,对于 Java 平台来说,安全显得特别重要。为了保证新版本具有更高的安全性,Java 8 在安全性上对许多方面进行了增强,也为此推迟了它的发布日期。下面例举其中几个关于安全性的更新:
支持更强的基于密码的加密算法。基于 AES 的加密算法,例如 PBEWithSHA256AndAES_128 和 PBEWithSHA512AndAES_256,已经被加入进来。
在客户端,TLS1.1 和 TLS1.2 被设为默认启动。并且可以通过新的系统属性包 jdk.tls.client.protocols 来对它进行配置。
Keystore 的增强,包含新的 Keystore 类型 java.security.DomainLoadStoreParameter 和为 Keytool 这个安全钥匙和证书的管理工具添加新的命令行选项-importpassword。同时,添加和更新了一些关于安全性的 API 来支持 KeyStore 的更新。
支持安全的随机数发生器。如果随机数来源于随机性不高的种子,那么那些用随机数来产生密钥或者散列敏感信息的系统就更易受攻击。SecureRandom 这个类的 getInstanceStrong 方法如今可以获取各个平台最强的随机数对象实例,通过这个实例生成像 RSA 私钥和公钥这样具有较高熵的随机数。
JSSE(Java(TM) Secure Socket Extension)服务器端开始支持 SSL/TLS 服务器名字识别 SNI(Server Name Indication)扩展。SNI 扩展目的是 SSL/TLS 协议可以通过 SNI 扩展来识别客户端试图通过握手协议连接的服务器名字。在 Java 7 中只在客户端默认启动 SNI 扩展。如今,在 JSSE 服务器端也开始支持 SNI 扩展了。
安全性比较差的加密方法被默认禁用。默认不支持 DES 相关的 Kerberos 5 加密方法。
如果一定要使用这类弱加密方法需要在 krb5.conf 文件中添加 allow_weak_crypto=true。考虑到这类加密方法安全性极差,开发者应该尽量避免使用它。
IO/NIO 的改进
Java 8 对 IO/NIO 也做了一些改进。主要包括:改进了 java.nio.charset.Charset 的实现,使编码和解码的效率得以提升,也精简了 jre/lib/charsets.jar 包;优化了 String(byte[],*) 构造方法和 String.getBytes() 方法的性能;还增加了一些新的 IO/NIO 方法,使用这些方法可以从文件或者输入流中获取流(java.util.stream.Stream),通过对流的操作,可以简化文本行处理、目录遍历和文件查找。
新增的 API 如下:
BufferedReader.line(): 返回文本行的流 Stream<String>
File.lines(Path, Charset):返回文本行的流 Stream<String>
File.list(Path): 遍历当前目录下的文件和目录
File.walk(Path, int, FileVisitOption): 遍历某一个目录下的所有文件和指定深度的子目录 File.find(Path, int, BiPredicate, FileVisitOption... ): 查找相应的文件
下面就是用流式操作列出当前目录下的所有文件和目录:
Files.list(new File(".").toPath())
.forEach(System.out::println);
全球化功能
Java 8 版本还完善了全球化功能:支持新的 Unicode 6.2.0 标准,新增了日历和本地化的 API,改进了日期时间的管理等。
Java 的日期与时间 API 问题由来已久,Java 8 之前的版本中关于时间、日期及其他时间日期格式化类由于线程安全、重量级、序列化成本高等问题而饱受批评。Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。新的 java.time 中包含了所有关于时钟(Clock),本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)和持续时间(Duration)的类。历史悠久的 Date 类新增了 toInstant() 方法,用于把 Date 转换成新的表示形式。这些新增的本地化时间日期 API 大大简化了了日期时间和本地化的管理。
例如,下面是对 LocalDate,LocalTime 的简单应用:
//LocalDate
LocalDate localDate = LocalDate.now(); //获取本地日期
localDate = LocalDate.ofYearDay(2014, 200); // 获得 2014 年的第 200 天
System.out.println(localDate.toString());//输出:2014-07-19
localDate = LocalDate.of(2014, Month.SEPTEMBER, 10); //2014 年 9 月 10 日
System.out.println(localDate.toString());//输出:2014-09-10
//LocalTime
LocalTime localTime = LocalTime.now(); //获取当前时间
System.out.println(localTime.toString());//输出当前时间
localTime = LocalTime.of(10, 20, 50);//获得 10:20:50 的时间点
System.out.println(localTime.toString());//输出: 10:20:50
//Clock 时钟
Clock clock = Clock.systemDefaultZone();//获取系统默认时区 (当前瞬时时间 )
long millis = clock.millis();//
性能测试
测试版本: JDK 1.5(目前ITOM正在使用)、JDK 6、JDK 7(未找到JDK 8相关测试 数据)
测试环境: Dell D630 笔记本运行 Windows 7 RTM (32 bit) , Intel Core 2 CPU (2.4GHz), 3GB RAM.
测试数据:
Test 1. 添加5百万string 数值。
Test 2. 5百万 ArrayList <String> 数据插入,使用Test 1数据。
Test 3. 5百万键值的HashMap <String, Integer>,每个键-值对通过并发线程计算,测试并发能力。
Test 4. 打印5百万 ArrayList <String> 数值到文件,并且回读。
四次测试结果如下:
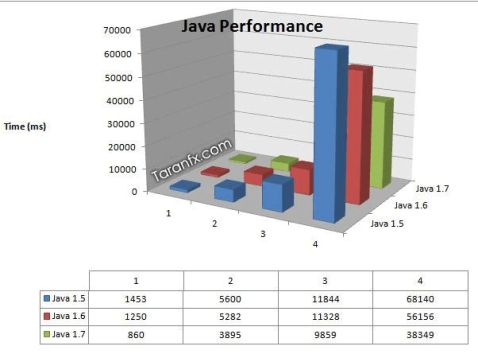
结论是:
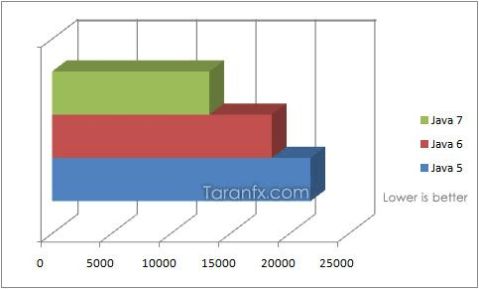
Java 5 <=== 18% faster=== < Java 6 < ===46% faster===< Java 7
选型分析结果 随着新版本不断加入的新增功能简化了开发,提升了代码可读性,增强了代码的安全性,提高了代码的执行效率,为开发者带来了全新的 Java 开发体验。但是由于新版本发布之后存在一个不断解决Bug、缺陷从而逐渐稳定成熟的过程,JDK 8目前刚刚发布不到一年时间,相关的文档和问题解决方案还不是很丰富;与之配套的Tomcat、Eclipse等软件还在不断完善的过程中;且Java将不在支持JDK 8在Windows XP系统上的运行;故建议本次版本升级选择相对更稳定、成熟的JDK 7版本。