电气工程学院神经网络实验报告 院系:电气工程学院 专业:电气工程及其自动化
实验二 基于BP网络的多层感知器
一 实验目的:
1.理解基于BP网络的多层感知器的工作原理
2.通过调节算法参数的了解参数的变化对BP多层感知器训练的影响
3.了解BP多层感知器的局限性
二 实验内容:
1.根据实验内容推导出输出的计算公式以及误差的计算公式
2.使用Matlab编程实现BP多层感知器
3.调节学习率η及隐结点的个数,观察对于不同的学习率、不同的隐结点个数时算法的收敛速度
4.改用批处理的方法实验权值的收敛,并加入动量项来观察批处理以及改进的的算法对结果和收敛速度的影响。
三.实验原理以及过程的推导
1. 基本BP 算法的多层感知器模型
下面所示是一个单输入单输出的BP多层感知器的模型,它含有一个隐层。
输出O
输出层
W=(w1,w2,……….wj)
…………. Y=(y1,y2,…….yj )
隐层 y0
V=(v1,v2,…….vj)
 输入层
输入层
X0 X












 下面对误差和权值的调整过程进行推导
下面对误差和权值的调整过程进行推导
对于单样本的输入Xi则隐层的输出:
yi=f1(netj);
netj=(xi*vi)
输出层的输出:
O=f2(net);
net=(wi*yi)
变换函数:
f1=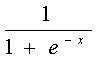
f2=x;
当网络输出与期望输出不等时,存在输出误差E
E= (d-o)2;
(d-o)2;
计算各层的误差:把误差分配到各层以调整各层的权值,所以,各层权值的调整量等于误差E对各权值的负偏导与学习率的乘积,计算得到对权值W和权值V的调整量如下:
将上面的式子展开到隐层得:
E=(d-o)2=[d- f2(net)]= [d-f2( 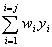 )]
)]
将上式展开到输入层得:
E=(d-o)2=[d- f2(net)]= [d-f2( 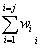 f1(
f1( ))]
))]
调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即
Δwj=-
Δvj=-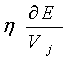
计算得到对各权值的调整为:
Δwj=η*(d(1,p)-o(1,p))*y(1,i)
Δvj=*(d(1,p)-o(1,p))*w(1,i)*y(1,i)*(1-y(1,i))*x(1,p)
其中P为第P个样本:
四 实验步骤
Step 1 初始化
对权值矩阵W、V 赋随机数,将样本模式计数器p 和训练次数计数器q 置于1,误差E置0,学习率η设为0~1 内的小数,网络训练后的精度Emin 设为一个正的小数;
Step 2 输入训练样本对,计算各层输出用当前样本Xp、dp 对向量数组X、d 赋值,用下式计算Y 和O 中各分量
yi=f1(netj);
netj=(xi*vi)
O=f2(netj);
net=(wi*yi)
Step 3 计算网络输出误差
设共有P 对训练样本,网络对于不同的样本具有不同的误差2 ?
Step 4 计算各层误差信号:各层的误差信号为误差E对各层权值的偏导
Step 5 调整各层权值
Δw=η*(d(1,p)-o(1,p))*y(1,i)
Δv=*(d(1,p)-o(1,p))*w(1,i)*y(1,i)*(1-y(1,i))*x(1,p)
Step 6 检查是否对所有样本完成一次轮训
若p<P,计算器p=p+1,q=q+1,返回Step 2, 否则转到Step 7
Step 7 检查网络总误差是否达到精度要求
当用ERME作为网络的总误差时,若满足ERME<Emin,训练结束,否则E 置0,p 置1,返回Step 2。
单样本训练:每输入一个样本,都要回传误差并调整权值,会导致收敛速度过慢
批处理(Batch)训练:根据总误差,计算各层的误差信号并调整权值,在样本数较多时,批训练比单样本训练时的收敛速度快
五 实验结果
对于单本输入的网络程序如下:function limoyan;%建立以limoyan为文件名的m文件
clc;
clear;
x=[-4:0.08:4];%产生样本
j=input('j=');%输入隐结点的个数
n=input('n=');%输入学习率
w=rand(1,j);%对权值w赋较小的初值
w0=0.5;%对权值w0赋较小的初值
v=rand(1,j);%对权值V赋较小的初值
v1=rand(1,j);%对权值V1赋较小的初值
x0=-1;%对阈值x0赋初值
y0=-1;%对阈值y0赋初值
err=zeros(1,101);
wucha=0;
erro=[];
Erme=0;
zong=[];
Emin=0.1;
d=zeros(1,101);%以初值0赋给期望输出
for m=1:101
d(1,m)=1.1*(1.0-x(1,m)+2*x(1,m)*x(1,m))*exp(-x(1,m)*x(1,m)/2);%以Hermit多项式产生期望输出
end;
o=zeros(1,101);
netj=zeros(1,j);
net=zeros(1,j);
y=zeros(1,j);
p=1;
q=1;
while q<30000 %设定最大的迭代交数
for p=1:101 %计算隐层的输出
for i=1:j
netj(1,i)=v(1,i)*x(1,p)+v1(1,i)*x0;
y(1,i)=1/(1+exp(-netj(1,i)));
end;
o(1,p)=w*y'+y0*w0+0.01*randn(1,1);%计算输出并给输出加上上定的扰动
wucha=1/2*(d(1,p)-o(1,p))*(d(1,p)-o(1,p));%计算误差
err(1,p)=wucha;
erro=[erro,wucha];
for m=1:j;%调整各层的权值
w0=w0-n*w0;
w(1,m)=w(1,m)+n*(d(1,p)-o(1,p))*y(1,m);
v(1,m)=v(1,m)+n*(d(1,p)-o(1,p))*w(1,m)*y(1,m)*(1-y(1,m))*x(1,p);
v1(1,m)=v1(1,m)+n*(d(1,p)-o(1,p))*w(1,m)*y(1,m)*(1-y(1,m))*x0;
end;
q=q+1;
end;
Erme=0;
for t=1:101;
Erme=Erme+err(1,t);
end;
err=zeros(1,101);
Erme=sqrt(Erme/101);
zong=[zong,Erme];
if Erme<Emin break;%误差达到允许值时停止迭代
end;
end;%输入结果
Erme
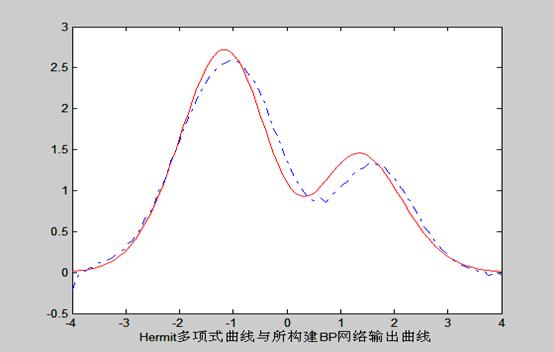
plot(x,d,'-r');
hold on;
plot(x,o,'-.b');
xlabel('Hermit多项式曲线与所构建BP网络输出曲线')
q
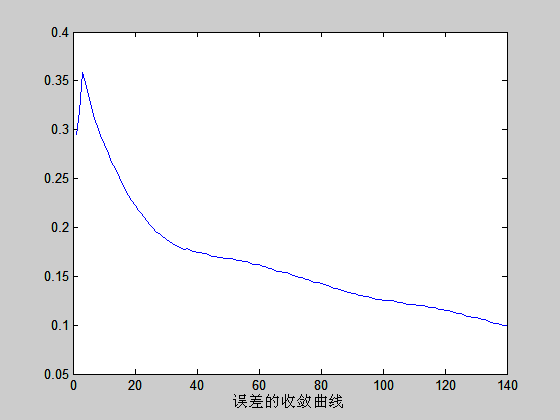
figure(2);
plot(zong);
xlabel('误差的收敛曲线')
命令窗口的输出如下:
j=5
n=0.05
Erme = 0.0996
q = 19999
Hermit多项式曲线与所构建BP网络输出曲线:
误差的收敛曲线如下:
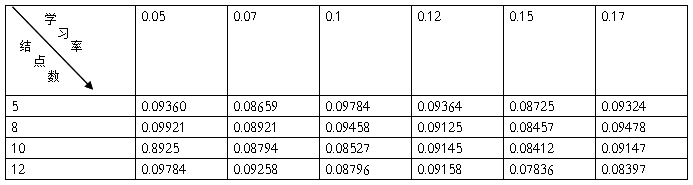
单样本训练的统计如下:
对于批处理的情况:
在原程序的基础上改变中间的一段;
命令窗口的输出如下:
j=10
n=0.1
Erme = 0.0997
q = 15757
Hermit多项式曲线与所构建BP网络输出曲线:
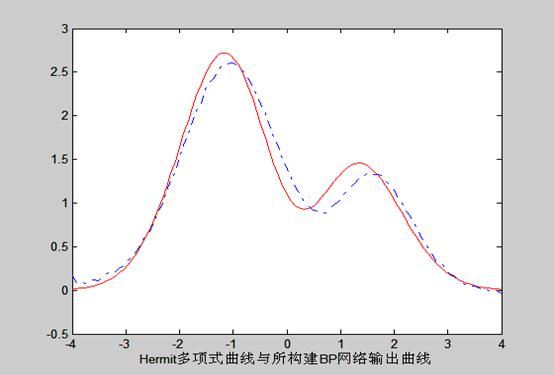
误差的收敛曲线如下:
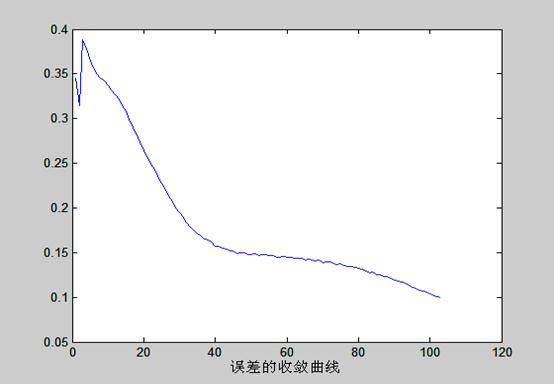
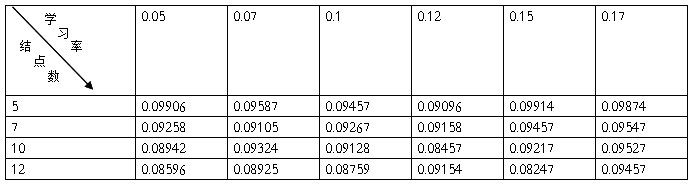
单样本训练的统计如下:
对于加入动量项的网络如下: 命令窗口的输出如下:
j=15
n=0.1
Erme = 0.1000
q = 6768
Hermit多项式曲线与所构建BP网络输出曲线:

误差的收敛曲线如下
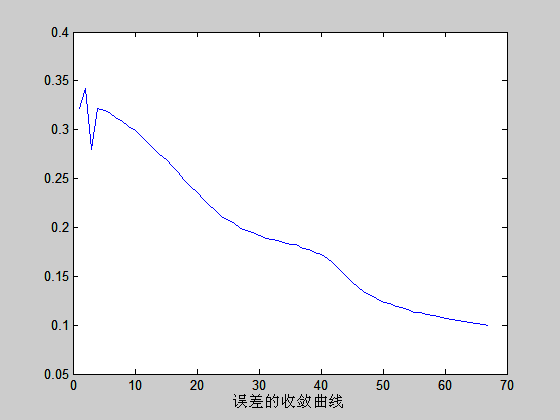 :
:
单样本训练的统计如下:
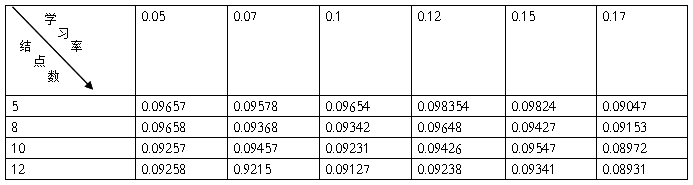
六.问题回答
1. 比较单样本训练和批处理训练的区别;
答:单样本输入是每输入一个样本就调整一次权值,并计算误差的大小,而对于批处理来说,是等所有的样本都输入以后再调整权值.当样本较多的时候批处理能获得较快的收敛速度.
2. 根据结果分析增加动量项后算法的变化
答:加入动量项后,就等于让权值的收敛方向向着一定的方向进行,由输出的数据可以看出这一点,对于相同的结点数,相同的学习率,加入动量项后,收速度即迭代次数明显的降低.
2 改变不同参数的BP网络运行情况及结果,并给予相应的结果分析
答:改变不同参数,对网络运行情况的影响,可以概括为:随着结点数的增多,收敛的概率和速度都会相应的有把增加.相应的误差会要小一点.但误差的大小除了取决于结点外,还主要决定于到达允许误差时的值,所以总误差的值有一定的随机性.对于改变网络的学习率,对来说小的学习率会使收敛更稳定一点,但是速度也会相对地慢一点,大的学习率在一定程度上能加快收敛的速度,但是稳定性要比小的学习率小的多,换句话说,大的学习率收敛的概率要小得多,很容易发散,所以说,随着学习的增大,迭代的次数会先减小后增大。大到一定程度进,由于波动太大。结果就不在收敛;
3 思考:输出层可以采用Sigmoid函数吗?为什么?
答:输出层可以采用的函数很多,从理论上说,一个函数都是可以应用的,但是如果采用Sigmoid函数的话,占用的内存要比用线性函数大的多,相对的运行的速度也要比用线性函数慢的多,而对于连续的函数的拟合,输出函数用线性函数就能很好的解决。
4 试验中遇到的问题和解决方法
答:在开始的时候把问题想得太简单,在没有加阈值的情下编出了程序,运行后才发现,结点数很多,想明白后再阈值加上使程序显得混乱。
第二篇:LSTM神经网络实验
实验 算法LSTM神经网络实验
【实验名称】
LSTM神经网络实验
【实验要求】
掌握KLSTM神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用;
【背景描述】
LSTM是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
【知识准备】
了解KLSTM神经网络模型的使用场景,数据标准。掌握Python/TensorFlow数据处理一般方法。了解keras神经网络模型搭建,训练以及应用方法
【实验设备】
Windows或Linux操作系统的计算机。部署TensorFlow,Python。本实验提供centos6.8环境。
【实验说明】
采用sp500数据集作为算法数据,把数据集分为训练集与测试集,分别对模型进行训练和测试。
【实验环境】
Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。
【实验步骤】
第一步:启动python:
命令行中键入python:

第二步:导入用到的包,读取并处理数据:
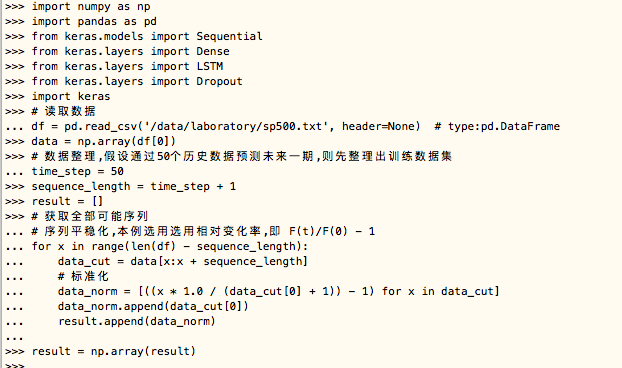
(1).导入所需包
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
import keras
(2).读取数据,数据源地址为:/opt/algorithm/LSTMNET/sp500.txt
df = pd.read_csv('/opt/algorithm/LSTMNET/sp500.txt', header=None)
data = np.array(df[0])
(3).整理数据,假设通过50个历史数据预测未来一期,则先整理出训练数据集
time_step = 50
sequence_length = time_step + 1
result = []
(4).获取全部可能序列,序列平稳化,本例选用选用相对变化率,即 F(t)/F(0) - 1
for x in range(len(df) - sequence_length):
data_cut = data[x:x + sequence_length]
# 标准化
data_norm = [((x * 1.0 / (data_cut[0] + 1)) - 1) for x in data_cut]
data_norm.append(data_cut[0])
result.append(data_norm)
result = np.array(result)
第三步:数据集划分
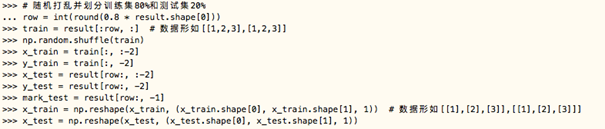
(1).随机打乱并划分训练集80%和测试集20%
row = int(round(0.8 * result.shape[0]))
train = result[:row, :] # 数据形如[[1,2,3],[1,2,3]]
np.random.shuffle(train)
x_train = train[:, :-2]
y_train = train[:, -2]
x_test = result[row:, :-2]
y_test = result[row:, -2]
mark_test = result[row:, -1]
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
第四步:搭建神经网络
(1).构建神经网络,模型为 1->50->100->1 网络
model = Sequential()
建立全连接层-首层需要指定输入层维度
model.add(LSTM(units=50,
input_shape=(50, 1),
activation="tanh",
use_bias=True,
return_sequences=True
)
)
model.add(Dropout(0.2))
model.add(LSTM(units=100,
activation="tanh",
use_bias=True,
)
)
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation="linear",
use_bias=True,
)
)

第五步:定义模型训练方法,损失函数,停止规则以及训练参数并训练网络
(1).建立评估函数,设计目标误差函数,以及训练方法
model.compile(loss='mean_squared_error', optimizer="rmsprop")
(2).提前结束训练的阈值,下面参数,观察误差,连续5次无改善.则结束训练
early_stopping = keras.callbacks.EarlyStopping(monitor='loss', patience=5, verbose=0, mode='auto')
(3).模型训练
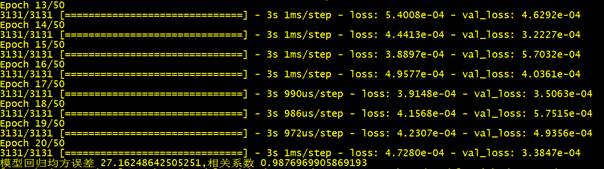
model.fit(x_train, y_train, epochs=50, batch_size=512, verbose=1, validation_split=0.05, callbacks=[early_stopping])

第六步:模型应用于测试集,并输出准确率
(1).模型预测与评价
pred = model.predict(x_test).reshape(len(x_test))
(2).构建评价数据
F = pd.DataFrame({"y": y_test, "pred": pred, "mark_test": mark_test})
F["pred"] = F["pred"].map(lambda x: x + 1) * F["mark_test"].map(lambda x: x - 1)
F["y"] = F["y"].map(lambda x: x + 1) * F["mark_test"].map(lambda x: x - 1)
F["mse"] = (F["y"] - F["pred"]) ** 2
(3).均方误差
mse = np.sqrt(F["mse"].sum() / len(F))
(4).相关系数
corr = F[["pred", "y"]].corr()["y"]["pred"]
(5).打印数据
print("模型回归均方误差 %s,相关系数 %s" % (mse, corr))

第七步:通过以下命令执行python文件,直接查看结果
python /opt/algorithm/LSTMNET/LSTMNet.py
【问题与回答】
关于记忆网络的注意点,请看算法介绍ppt