西北农林科技大学研究生教学参考书
《人工神经网络与应用实验指导》
信息工程学院
二〇##年十二月十三日
实验一 MATLAB ANN工具箱及感知器实现
一、实习目的和意义
使学生熟悉并掌握Matlab基本运算编程和运行,掌握人工神经网络工具箱帮助、示例等资源,掌握自主学习Matlab编程的能力,并能设计实现感知器,为后续处理打下基础。
二、实习内容
1、熟悉Matlab基本运算编程,掌握人工神经网络工具箱帮助、示例等资源。
(1)学会给矩阵赋值及常用矩阵运算;
(2)学会在命令窗口单步执行命令;编写m文件及运行的方法;
(3)掌握命令后“;”的显示控制作用,掌握清除命令窗口clc、图像窗口clf、内存和函数clear等命令的用法。
(4)学会用plot(x,y)绘制图形的方法;绘制双曲正切S函数的一阶导数曲线。
(5)掌握人工神经网络工具箱帮助、示例等资源。
2、设计一个感知器,并运行,分析结果、理解感知器算法。
三、实习参考
(1)Matlab基本运算
Matlab区分大小写,Abc,ABC,abc表示不同的矩阵名。在矩阵A中,同一行中的内容用逗号分隔,而采用分号来表示换行。一般情况下,用于同行中分隔的逗号是可以由空格来代替的。
基本的赋值语句:A=[1,2,3;4,5,6;7,8,0]
矩阵加减法运算:C=A+B 和C=A-B。
矩阵的转置:AT =A’。
矩阵的点乘:C=A.×B
矩阵的除法:x=A./B。
矩阵乘法:C=A×B
对一个矩阵单个元素赋值和操作:
A(:,j)表示A矩阵的第j列元素;A(i,:)表示A矩阵的第i列全部元素。
在命令窗口中,输入 help 命令,如help plot,则会给出相关的帮助信息。
(2)S曲线函数式为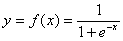 ,设x在[-10,10]之间每隔0.1取一个值。用plot()绘制S曲线。可编写m文件(polt_s.m)如下:
,设x在[-10,10]之间每隔0.1取一个值。用plot()绘制S曲线。可编写m文件(polt_s.m)如下:
%画S曲线
x=[-10:0.1:10]; %给x赋值
y=1./(1.0+exp(-x)) %计算y
plot(x,y) %绘制x-y关系曲线(S曲线)
hold on %保持图形,在原图上继续绘制
y1=y*(1.-y); %计算S曲线的一阶导数
plot(x,y1,'--r') %绘制S曲线的一阶导数曲线
(3)设计一个二维输入矢量分为两类。
%gzq1.m
%P 输入向量,T为目标向量
P=[-1.0 -0.5 +0.3 -0.1;
-0.5 +0.5 -0.5 +1.0]
T=[1 1 0 0];
plotpv(P,T); %绘制感知器的输入输出矢量
disp('按任意键继续.')
pause %按任意键继续
net=newp([-1 1;-1 1],1); %NEWP 建立一个感知器.
plotpv(P,T); %绘制输入向量
plotpc(net.IW{1},net.b{1}); %绘制初始分类线
net.adaptParam.passes = 3;
net = adapt(net,P,T); %ADAPT返回一个最佳分类的网络ner
plotpc(net.IW{1},net.b{1}); %绘制训练后的分类线
%利用训练好的感知器进行分类
p=[0.7;1.2]; %给定一个输入
a=sim(net,p) %SIM对感知器神经网络进行仿真.行尾无“;”号,
%在命令窗口显示a的值。
disp('结束!')
四、思考与讨论
1、如何控制程序运行暂停时间?
2、比较一个命令行后有无“;”的差别。
3、画出gzq1.m中网络模型。
4、查帮助并分析plot、plotpv、plotpc的不同。
实验二 自适应线性元件的设计与训练
一、实习目的和意义
掌握用Matlab人工神经网络工具箱设计自适应线性元件的方法,掌握人工神经网络学习和训练过程;理解误差曲面;分析比较自适应线性元件的不足。
二、实习内容
1、掌握自适应线性元件的方法。设计一个线性神经元响应特定输入下的目标输出:P = [1.0 -1.2];T = [0.5 1.0];用ERRSURF函数计算在一定范围可能权重和阈值下的神经元的误差,用PLOTES以等高线的形式绘制误差表面,并在误差曲面上绘制出最佳权重、阈值的点。
2、设计一个线性神经元件,线性神经元以实现对输入矢量P = [+1.0 +1.5 +3.0 4.5]和输出矢量T = [+0.5 +1.1 +1.7 2.6]的线性拟合。
3、在上面的网络设计中,不断增大学习率,分析学习大小对训练次数及网络能否收敛的影响。
三、实习参考
(1)自适应线性元件的方法及误差曲面分析
% 模式联想误差曲面
% 设计一个线性神经元响应特定输入下的目标输出
% P定义两个1单元的输入模式,T定义相关的1单元的目标矢量
P = [1.0 -1.2];
T = [0.5 1.0];
% ERRSURF计算在一定范围可能权重和阈值下的神经元的误差
% PLOTES绘制误差表面.并在误差曲面上绘制出最佳权重、阈值的点。
w_range = -1:0.1:1; %权重取值范围
b_range = -1:0.1:1; %阈值取值范围
ES = errsurf(P,T,w_range,b_range,'purelin'); %计算误差
plotes(w_range,b_range,ES); %绘制误差曲面
pause
net = newlind(P,T); %函数NEWLIND设计一个误差最小的网络层
%SIM仿真网络的输入P。可以计算出神经元的误差,
A = sim(net,P)
E = T - A
SSE = sumsqr(E) %SUMSQR累加平方误差
plotes(w_range,b_range,ES); %重新绘制误差曲面
pause
plotep(net.IW{1,1},net.b{1},SSE);
%用SOLVELIN返回的权值和阈值在误差曲面上绘制出位置
% 用一个输入进行测试。
p = -1.2;
a = sim(net,p)
(2)线性拟合线性元件设计
%拟合线性问题
% P-输入矢量;T-目标矢量
P = [+1.0 +1.5 +3.0 4.5];
T = [+0.5 +1.1 +1.7 2.6];
%计算最大学习率,包括阈值
maxlr = maxlinlr(P,'bias');
%newlin用于建立一个线性网络
net = newlin([-2 2],1,[0],maxlr);
%设置最大训练步数
net.trainParam.epochs = 15;
[net,tr] = train(net,P,T);%tr为训练记录(训练步数,性能)
%仿真
p = -1.1;
a = sim(net, p)
四、思考与讨论
1、自适应线性元件和感知器有哪些不同?
2、自适应线性元件的传递函数是哪种类型?
3、自适应线性元件设计为多层是否可以提高网络性能?
4、学习率大小对训练次数及网络性影响如何?
实验三 BP网络设计与训练(一)
一、实习目的和意义
掌握用Matlab人工神经网络工具箱设计BP网络的方法,掌握BP网络的设计以及训练过程;掌握用BP网络进行函数逼近和分类的基本设计方法;分析比较几种BP训练算法的训练性能;掌握动量法、自适应学习速率算法的设计和应用;通过实验,对局部极小问题有深入的理解。
二、实习内容
1、设计并训练一个BP网络,使其进行模式p = [-1 -1 2 2; 0 5 0 5]进行分类。
2、用动量法训练BP网络,比较动量法和纯梯度法对同一个BP网络进行训练的效率。
3、设计一个BP网络,用于逼近一个函数。该函数输入范围为[-2,2],输出为T=sin(2*pi*P)+0.2*randn(size(P))。改变隐层神经元数量,分析比较不同隐层神经元数量下网络训练效率及最终训练结果。
4、设计一个BP网络,用自适应学习率算法对其训练,用于逼近一个函数。21个输入在[-1,1]之间,输出为 [-0.9602 -0.5770 0.0729 0.3771 0.6405 0.6600 0.4609 0.1336 -0.2013 -0.4344 -0.5000 -0.3930 -0.1647 0.0988 0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201]。
5、在实习内容3中,事先给定一个不合适的初始权值和阈值,考察局部极小值问题。
三、实习参考
1、BP算法主要函数:
(1)变换函数:对数S型激活函数logsig.m;双曲正切S型激活函数tansig.m;线性激活函数purelin.m;
(2)误差相关函数:误差函数sumsqr.m;误差的变化函数deltalin.m,deltatan.m和deltasig.m,分别用于线性层、双曲正切层和对数层。
(3)newff,生成一个前向网络,如,net = newff([0 10],[5 1],{'tansig' 'purelin'},’trainlm’ );
(4)网络训练函数:A、train() 纯梯度法训练一个神经网络;B、traingda() 自适应学习速率梯度下降法;C、trainrp()回弹BP算法;D、共轭梯度算法训练函数3个:traincgp()、traincgb()、trainscg();E、trainlm(),Levenberg-Marquardt训练算法。
(5)学习函数:A、learngd (),梯度下降法学习函数;B、learnbpm(),利用动量规则改进的BP算法。
(6)sim (),网络仿真函数。
(7)函数具体用法可参考帮助,或在命令窗口输入:help 函数名,如help learnbpm,回车即可。
2、缺省训练参数及训练参数设置方法
(1)缺省训练参数
net.trainParam.epochs=10
net.trainParam.goal =0
net.trainParam.lr=0.01
net.trainParam.lr_inc=1.05 Ratio to increase learning rate
net.trainParam.lr_dec=0.7 Ratio to decrease learning rate
net.trainParam.max_fail=5 Maximum validation failures
net.trainParam.max_perf_inc=1.04 Maximum performance increase
net.trainParam.min_grad=1e-10 Minimum performance gradient
net.trainParam.show=25
net.trainParam.time=inf Maximum time to train in seconds
(2)训练参数设置方法
在m文件中编写上述相关设置命令,等号的右侧直接给出设置的训练参数即可。如:
net.trainParam.epochs=200 %设计最大训练次数为200。
四、思考与讨论
1、如何确定BP网络的层数、各层单元个数?
2、学习率大小对网络训练性能有何影响?
3、分析对比几种训练函数的训练性能。
4、如何设置初始权值和阈值?
5、局部极小问题有哪些改进方法?
实验四 BP网络设计与训练(二)
一、实习目的和意义
掌握用BP网络解决实际预测问题的方法,包括数据规格化处理、训练样本和测试样本的组织,网络隐层层数和神经元个数的确定,以及传递函数和训练参数的确定等。
二、实习内容
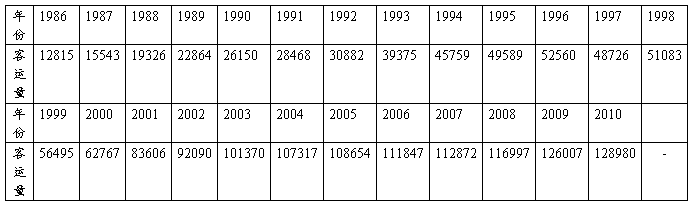
现有某省1986~20##年的客运量数据。编程实现用BP网络预测20##年和20##年公路客运量。
表1 某省1986~20##年的客运量数据
三、实习参考
1、 实现思路
1986~20##年客运量数据N=25个历史观察值,可采用长度n=5为一期,n0=2为滚动间隔。即用前5年的数据预测下一年的数据,每隔2年开始一期长度为5年的观察数据。
2、 样本组织
20期数据样本分成两组,每组10个,分别做为训练集(1986年开始)和测试集(1987年开始)。
3、 网络结构
BP网络有5个输入(5年运量数据),1个输出(预测运量)。
隐层可采用单隐含层或双隐层。隐含层神经元数目采用试差法确定。若采用双隐层,则第1、2隐含层神经元数目分别可选8、5进行实验。
若为单隐层,隐层神经元数可选14左右进行实验。
4、 数据规格化处理
将表1中的输入、输出数据规格化到区间[0.2~0.9]内。规一化公式:
规格化后数据=z1+(z2-z1)*(x-xmin)/(xmax-xmin)
式中:[z1 z2]-规格化后的数据范围,如本例z1=0.2,z2=0.9;x为待规格化数据;xmin、xmax-分别为数据序列的最小、最大值。
在程序中可用:p1=0.2+(0.9-0.2).*(p0-min(p0))./(max(p0)-min(p0))实现。
6、程序设计技巧
(1)按每5年为一期组织样本,作为训练集,p为输入,t为目标。从第1986年客运量开始。编程参考如下:
j=0;
for i=1:10;
p(:,i)=p1(i+j:i+j+4)'; %取第i个训练样本,给p
t(:,i)=p1(i+j+5);
j=j+1;
end
(2)按每5年为一期组织样本,作为测试集,testp为输入,testt为目标。从1987年客运量开始。编程参考如下:
j=0;
for i=1:10;
testp(:,i)=p1(i+j+1:i+j+5)';
testt(:,i)=p1(i+j+6);
j=j+1;
end
(3)建立两层隐含层BP网络,隐层神经元数为8、 5,输出为1个单元,训练函数为trainlm。
net = newff(p,t,[8 5 1],{'tansig' 'tansig' 'purelin'},'trainlm');
(4)设置训练参数
net.trainParam.lr=0.6; %学习率
net.trainParam.epochs = 10000; %最大训练次数
net.trainParam.goal = 0.0001; %目标误差
(5)训练、仿真网络
net = train(net,p,t);
%仿真
y = sim(net,testp); %将1987起的10组测试数据输入网络进行测试
E=testt-y; %计算测试集网络输出和目标的误差
mse=MSE(E) %计算均方误差
(6)预测20##年客运情况
P11=p1(21:25)' %取预测数据,2006-2010共5年,转置成列矢量
Y11=sim(net,p11) %用sim仿真,计算20##年客运量(规一化值)
y2011=min(p0)+(y11-0.2)*(max(p0)-min(p0))/0.7; %求出客运量实际值
四、思考与讨论
1、为什么要对数据进行规格化?
2、若取第一个隐层的神经元个数比第二个隐层大,网络训练效果如何?分析为什么。
3、可否用训练好的BP网络预测20##年的运量?为什么?
4、分别用1个隐层和2个隐层BP网络进行预测,比较训练时间和泛化效果。
实验五 SOFM、LVQ网络设计与训练
一、实习目的和意义
掌握SOFM网络、LVQ网络设计方法,能对实际问题进行聚类或分类。
二、实习内容
1、掌握SOFM网络的方法。一组随机建立的数据点集合P,设计一个竞争网络将它们分成自然的类。
2、设计一个LVQ网络,将10个二维输入矢量聚类。
三、实习参考
(1)一组随机建立的数据点集合P,设计一个竞争网络将它们分成自然的类。
% comp_learn1.m 自组织网络的训练
X = [0 1; 0 1]; %簇的中心在该范围内
clusters = 8; %设定建立的簇为8个
points = 10; % 每个簇10个点.
std_dev = 0.05; % 每个簇的标准差
P = nngenc(X,clusters,points,std_dev); % nngenc可以建立一个数据点簇
% 绘制P矢量
plot(P(1,:),P(2,:),'+r');
title('Input Vectors');
xlabel('p(1)');
ylabel('p(2)');
net = newc([0 1;0 1],8,.1);%建立一个竞争网络
w = net.IW{1};
plot(P(1,:),P(2,:),'+r');
hold on;
circles = plot(w(:,1),w(:,2),‘ob’);
%用蓝色o绘制权矢量
net.trainParam.epochs = 7;
net = train(net,P); %训练网络
w = net.IW{1};
delete(circles); %删除circles句柄
plot(w(:,1),w(:,2),'ob');
p = [0; 0.2]; %用竞争层分类
a = sim(net,p)
(2)设计一个LVQ网络,将10个二维输入矢量聚类。
% P为10个2维矢量, C为分类矢量
P = [-3 -2 -2 0 0 0 0 +2 +2 +3;
0 +1 -1 +2 +1 -1 -2 +1 -1 0];
C = [1 1 1 2 2 2 2 1 1 1];
T = ind2vec(C); %转换类别号为目标矢量
% 绘制数据点, Red = class 1, Cyan = class 2.
colormap(hsv);
plotvec(P,C)
title('Input Vectors');
xlabel('P(1)');
ylabel('P(2)');
pause
% NEWLVQ 建立 LVQ,输入范围、隐层神经元数4, 典型类百分比矢量、学习率
net = newlvq(minmax(P),4,[.6 .4],0.1);
% 绘制竞争层神经元权重矢量.
hold on
W1 = net.IW{1};
plot(W1(1,1),W1(1,2),'ow')
title('Input/Weight Vectors');
xlabel('P(1), W(1)');
ylabel('P(2), W(3)');
pause
% 训练结束后,重新绘制输入矢量 '+',竞争神经元权重矢量 'o'.
%Red = class 1, Cyan = class 2.
%设置训练参数
net.trainParam.epochs=150;
net.trainParam.show=Inf;
net=train(net,P,T);
cla;
plotvec(P,C);
hold on;
plotvec(net.IW{1}',vec2ind(net.LW{2}),'o');
pause
% 用 LVQ 分类. 输入矢量 [0.2; 1],Red = class 1, Cyan = class 2.
p = [0.2; 1];
a = vec2ind(sim(net,p))
四、思考与讨论
1、SOFM网络聚类的准则是什么?
2、SOFM网络竞争层算法和BP网络有何不同?
3、LVQ网络结构与工作原理?
实验六 RBF网络设计与训练
一、实习目的和意义
掌握RBF网络、GRNN和PNN网络的设计方法,学会用GRNN网络进行函数逼近、用PNN网络对实际问题进行分类。
二、实习内容
1、在Matlab下绘制出高斯径向基函数图形。并将中心为0的基函数a1,分别平移2、-1.5得到a2和a3,将a1、a2、a3线性组合得到a4,绘制出a4图形。
2、设输入p在-1~1之间,数据间隔为0.1。设计一个正规化RBF网络逼近
T= [-.9602 -.5770 -.0729 .3771 .6405 .6600 .4609 ...
.1336 -.2013 -.4344 -.5000 -.3930 -.1647 .0988 ...
.3072 .3960 .3449 .1816 -.0312 -.2189 -.3201]
用RBF有效设计方法,改变扩展常数为0.01和18,分别观察逼近效果,深入理解不能拟合和过拟合现象。
3、设P = [1 2 3 4 5 6 7 8];T = [0 1 2 3 2 1 2 1]。试设计一个GRNN网络实现函数逼近。
4、设输入为P = [1 2; 2 2; 1 1]';期望输出为Tc = [1 2 3]。试设计一个PNN网络对输入进行分类。
三、实习参考
1、 径向基函数和其线性组合
a1=radbas(p)产生一个径向基函数。其算法为a1=radbas(p) = exp(-p^2)
向右平移基函数:a2 = radbas(p-2);
向左平移基函数:a3 = radbas(p+1.5);
基函数的线性组合:a4 = a1+ a2 + a3;
试在a1、a2、a3前增加一个适当的加权系数,考察a4图形的变化。
2、RBF网络有效设计:
net=newrb(P,T,GOAL,SPREAD,MN,DF)
GOAL-目标误差;NM-最大神经元个数;DF-迭代过程显示频率。
3、GRNN设计
net = newgrnn(P,T,spread);
试用一个不在输入样本中的数据进行仿真。
4、 用PNN 进行分类参考程序如下。
P = [1 2; 2 2; 1 1]';%输入样本为3个点
Tc = [1 2 3]; %3个样本对应1-3类
plot(P(1,:),P(2,:),'.','markersize',30) %绘制样本点
for i=1:3, text(P(1,i)+0.1,P(2,i),sprintf('class %g',Tc(i))), end %每个样本注释第X类。
axis([0 3 0 3])
title('Three vectors and their classes.')
xlabel('P(1,:)')
ylabel('P(2,:)')
T = ind2vec(Tc); %转换目标类标记为矢量
spread = 1; %设置扩展常数
net = newpnn(P,T,spread); 建立PNN网络
A = sim(net,P); %仿真
Ac = vec2ind(A); %将类别矢量转换成类别号
plot(P(1,:),P(2,:),'.','markersize',30)
axis([0 3 0 3])
for i=1:3,text(P(1,i)+0.1,P(2,i),sprintf('class %g',Ac(i))),end
title('Testing the network.')
xlabel('P(1,:)')
ylabel('P(2,:)')
四、思考与讨论
1、RBF网络的基本思想是什么?
2、GRNN、RBF和PNN在输出层各有何不同?
3、GRNN输入样本个数、输入样本维数和隐含层神经元个数之间有何关系?
4、PNN的输出层神经元个数与何参数相同?
实验七 标准支持向量机C-SVM分类
一、实习目的和意义
掌握支持向量机原理及编程实现,深入理解支持向量及不同核函数对SVM性能的影响,学习解二次优化方程、寻找支持向量等程序设计方法。
二、实习内容
1、构造2类训练样本集,选择合适的核函数,编程实现求解的Laglange系数、寻找出支持向量并绘制出,然后进行分类。
2、用不同的核函数进行实验比较。
3、用BP网络进行分类,并比较二者训练时间的差异。
三、实习参考
1、 标准支持向量机C-SVM分类参考程序
% 支持向量机C-SVM分类算法
close all
clear all
clc
% ------------------------------------------------------------%
% 构造两类训练数据集
fprintf('支持向量机分类 C_SVM \n')
fprintf('_____________________________________\n')
fprintf('构造 ...\n');
C = 100; % 拉格朗日乘子上界
ker = struct('type','linear');%选择核函数
%ker ='linear'; %核函数有4种
% linear : k(x,y) = x'*y
% poly : k(x,y) = (x'*y+c)^d
% gauss : k(x,y) = exp(-0.5*(norm(x-y)/s)^2)
% tanh : k(x,y) = tanh(g*x'*y+c)
n = 50;
randn('state',2);%选择正态分布数据
x1 = randn(n,2); %产生50×2的随机数据
y1 = ones(n,1); %产生50×1的1阵
x2 = 4+randn(n,2); %在X1的基础上产生50×2的随机数据X2
y2 = -ones(n,1); %产生50×1的-1阵
figure; %绘制由X1、X2构成的数据点集分布
plot(x1(:,1),x1(:,2),'bx',x2(:,1),x2(:,2),'k.');
hold on;
pause
X = [x1;x2]; % 训练样本,50×2的矩阵,50为样本个数,2为样本维数
Y = [y1;y2]; % 训练目标,50×1的矩阵,50为样本个数,Y值为+1或-1
% ------------------------------------------------------------%
% 训练 %
fprintf('training ...\n');
tic %启动计时器starts a stopwatch timer
% ------------------------------------------------------------%
%训练%
% ------------------------------------------------------------%
% 解二次优化方程
n = length(Y);
H = (Y*Y').*Calckernel(ker,X,X);
f = -ones(n,1);
A = [];
b = [];
Aeq = Y';
beq = 0;
lb = zeros(n,1);
ub = C*ones(n,1);
a0 = zeros(n,1);
options = optimset;
options.LargeScale = 'off';
options.Display = 'off';
%quadprog()二次方程式求解子程序,需要安装优化工具箱
[a,fval,eXitflag,output,lambda] = quadprog(H,f,A,b,Aeq,beq,lb,ub,a0,options);
eXitflag %推出标记,为1时问题收敛解决
% 输出 svm
svm.ker = ker;
svm.x = X;
svm.y = Y;
svm.a = a; % a为求解的Laglange系数
% ------------------------------------------------------------%
% ------------------------------------------------------------%
fprintf('训练时间为 t_train:\n');
t_train = toc %toc为tic启动后经过的时间
% ------------------------------------------------------------%
% 寻找支持向量
a = svm.a;
epsilon = 1e-8; % 如果小于此值则认为是0
i_sv = find(a>epsilon); % 寻找支持向量的下标
fprintf('支持向量下标为 :') %输出支持向量的下标(行号)
i_sv
plot(X(i_sv,1),X(i_sv,2),'ro'); %用蓝色O绘制支持向量
pause
% ------------------------------------------------------------%%
% 求 b
%epsilon = 1e-8; % 如果小于此值则认为是0
%i_sv = find(a>epsilon); % 支持向量下标
tmp = (Y.*a)'*Calckernel(ker,X,X(i_sv,:)); % 行向量
b = 1./Y(i_sv)-tmp';
b = mean(b);
fprintf('构造函数 Y = sign(tmp+b):')
tmp
b
% ------------------------------------------------------------%
% 测试输出
fprintf('测试开始 ...\n');
[x1,x2] = meshgrid(-2:0.05:7,-2:0.05:7);
[rows,cols] = size(x1);
nt = rows*cols; % 测试样本数
Xt = [reshape(x1,nt,1),reshape(x2,nt,1)];
tic
% ------------------------------------------------------------%
% ------------------------------------------------------------%
ker = svm.ker;
X = svm.x;
Y = svm.y;
a = svm.a;
% ------------------------------------------------------------%
% ------------------------------------------------------------%
% 测试输出
nt = size(Xt,1); % 测试样本数
tmp = (Y.*a)'*Calckernel(ker,X,Xt);
Yd = sign(tmp+b)';
% ------------------------------------------------------------%
% ------------------------------------------------------------%
fprintf('预测时间为 t_sim:\n');
t_sim = toc
Yd = reshape(Yd,rows,cols);
contour(x1,x2,Yd,[0 0],'m'); % 得出分类面
hold off;
四、思考与讨论
1、什么是支持向量?
2、常用核函数有哪些?各有何特点?
3、求解Laglange系数的思想是什么?
4、SVM分类得到的超平面和BP网络得到的超平面有何不同?