广东技术师范学院实验报告


实验 (一) 项目名称: 建立并行计算平台
一、实验目的
在一个局域网中建立能够互相通信的两台计算机,为以后实验建立一个实验平台。
二、实验内容:
1.1 系统要求
安装MPICH for Microsoft Windows 对系统有如下要求:
Windows NT4/2000/XP 的Professional 或Server 版(不支持Windows 95/98)
所有主机必须能够建立TCP/IP 连接
MPICH 支持的编译器有:MS VC++ 6.x,MS VC++.NET,Compaq Visual Fortran 6.x,Intel Fortran,gcc ,以及g77 。安装MPICH ,必须以管理员的身份登录。
1.2 安装
以管理员的身份登录每台主机,在所有主机上建立一个同样的账户(当然也可以每个机器使用不同的用户名和账户,然后建立一个配置文件,使用命令行的方式运行程序),然后,运行下载的安装文件,将MPICH 安装到每台主机上。
打开“任务管理器”中的“进程”选项卡,查看是否有一个mpd.exe 的进程。如果有的话说明安装成功。以后每次启动系统,该进程将自动运行。打开任务管理器如下:
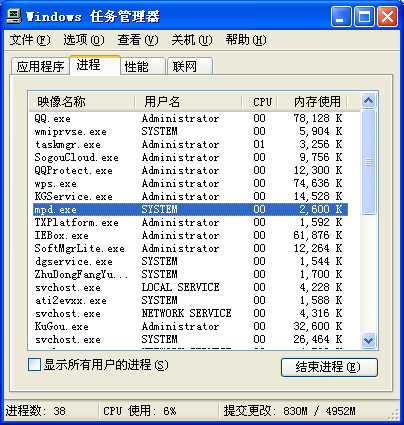
1.3 注册与配置
安装好MPICH 之后还必须对每台计算机进行注册和配置才能使用。其中注册必须每台计算机都要进行,配置只要在主控的计算机执行就行了。
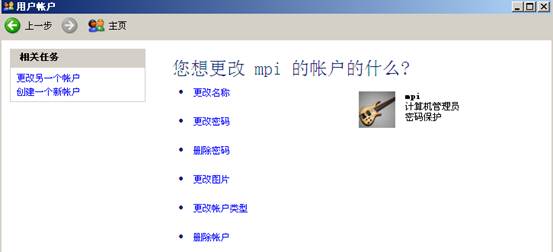
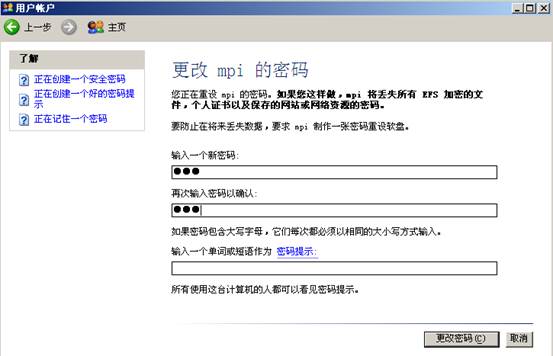
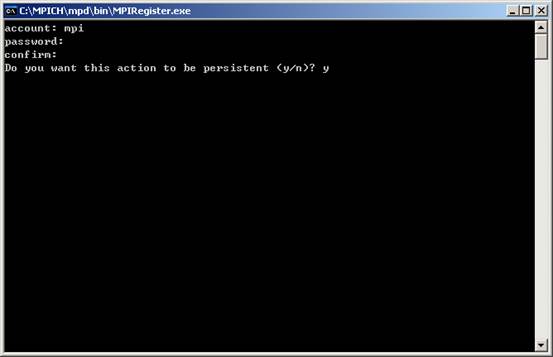
注册的目的是,将先前在每台计算机上申请的账号与密码注册到MPICH 中去,这样MPICH 才能在网络环境中访问每台主机。配置方法:运行“mpich\mpd\bin\MPIRegister.exe”首先会提示输入用户账号,然后会提示输入两边密码,之后会问你是否保持上面的设定。如果选择是,则上面的信息将写入硬盘,否则保存在内存中,再重新启动之后就不存在了。
注册新账户:
创建密码:
注册到MPICH中去:
打开“开始->程序->MPICH->mpd-> MPICH Configuration tool”进行配置如下:

1.4 mpich与编译环境的整合
新建工程:
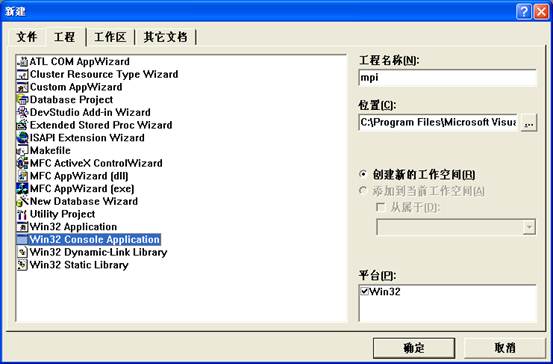
C/C++选项卡设置:
Win32 Debug设置如下:
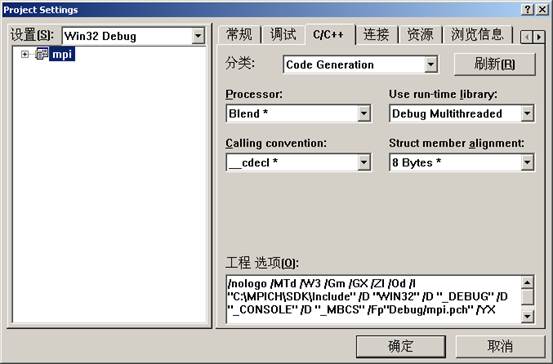
Win32 Release设置如下:
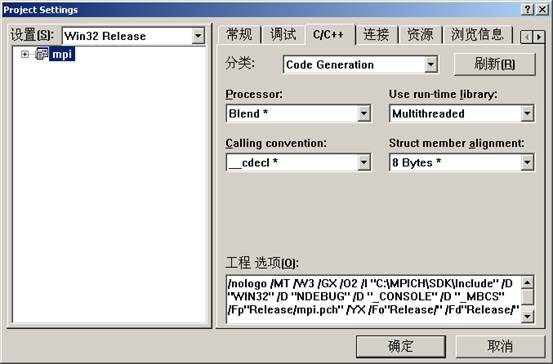
All Configurations设置如下:
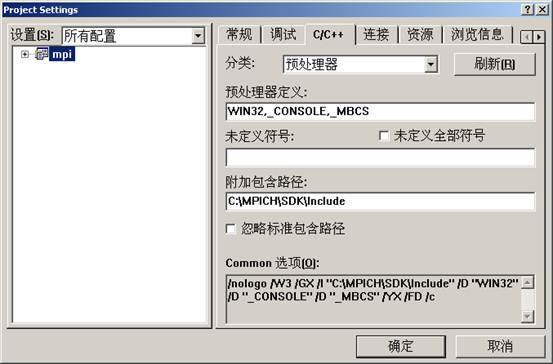
Link选项卡设置:
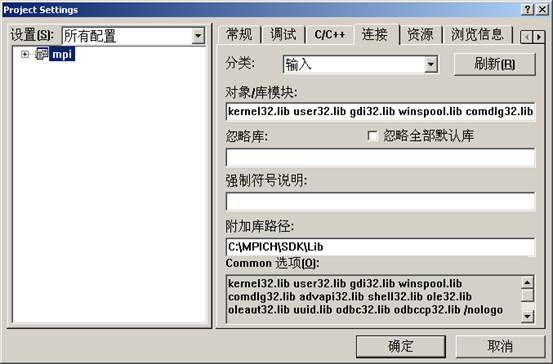
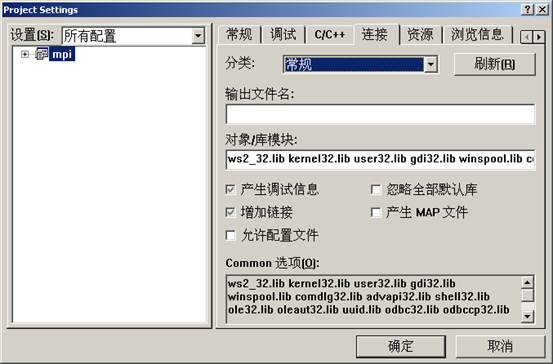
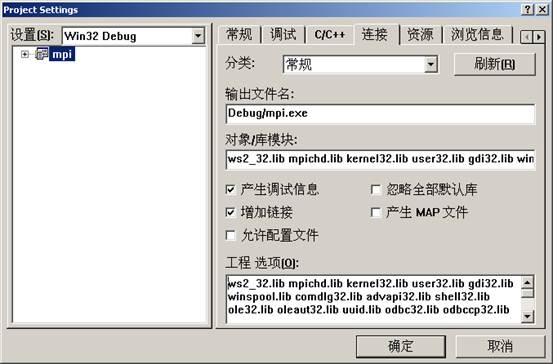
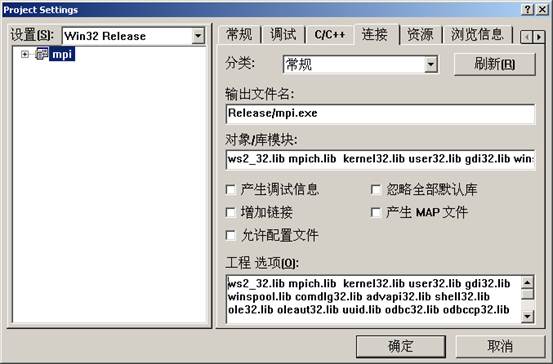
往mpi工程中添加cpi.c文件:
Vc编译成可执行程序mpi.exe,将mpi.exe插入到guiMPIRUN.exe中,单机运行:
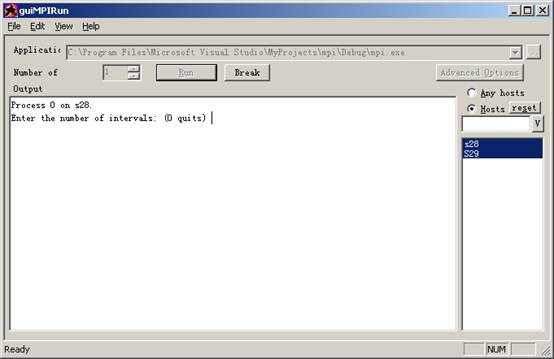
两台计算机并行计算:

三、实验分析与结论
在进行本次实验过程中,由于互连的两台计算机各种安装路径或账户命名不同,均导致两台计算机无法连接成功,最后通过不断的努力,终于排除障碍,成功建立并行计算平台,完成本实验。
第二篇:并行计算实验指导(1)免费版
大家支持免费共享
2 串匹配
串匹配(String Matching)问题是计算机科学中的一个基本问题,也是复杂性理论中研究的最广泛的问题之一。它在文字编辑处理、图像处理、文献检索、自然语言识别、生物学等领域有着广泛的应用。而且,串匹配是这些应用中最耗时的核心问题,好的串匹配算法能显著地提高应用的效率。因此,研究并设计快速的串匹配算法具有重要的理论价值和实际意义。
串匹配问题实际上就是一种模式匹配问题,即在给定的文本串中找出与模式串匹配的子串的起始位置。最基本的串匹配问题是关键词匹配(Keyword Matching)。所谓关键词匹配,是指给定一个长为n的文本串T[1,n]和长为m的模式串P[1,m],找出文本串T中与模式串所有精确匹配的子串的起始位置。串匹配问题包括精确串匹配(Perfect String Matching)、随机串匹配(Randomized String Matching)和近似串匹配(Approximate String Matching)。另外还有多维串匹配(Multidimensional String Matching)和硬件串匹配(Hardware String Matching)等。
本章中分别介绍改进的KMP串匹配算法,采用散列技术的随机串匹配算法,基于过滤算法的近似串匹配算法,以及它们的MPI编程实现。
2.1 KMP串匹配算法
2.1.1 KMP串匹配及其串行算法
KMP算法首先是由D.E. Knuth、J.H. Morris以及V.R. Pratt分别设计出来的,所以该算法被命名为KMP算法。KMP串匹配算的基本思想是:对给出的的文本串T[1,n]与模式串P[1,m],假设在模式匹配的进程中,执行T[i]和P[j]的匹配检查。 若T[i]=P[j],则继续检查T[i+1]和P[j+1]是否匹配。若T[i]≠P[j],则分成两种情况:若j=1,则模式串右移一位,检查T[i+1]和P[1]是否匹配;若1<j≤m,则模式串右移j-next(j)位,检查T[i]和P[next(j)]是否匹配(其中next是根据模式串P[1,m]的本身局部匹配的信息构造而成的)。重复此过程直到j=m或i=n结束。
1. 修改的KMP算法
在原算法基础上很多学者作了一些改进工作,其中之一就是重新定义了KMP算法中的next函数,即求next函数时不但要求P[1,next(j) -1]=P[j-(next(j) -1),j-1],而且要求P[next(j)] ≠P[j],记修改后的next函数为newnext。在模式串字符重复高的情况下修改的KMP算法比传统KMP算法更加有效。
算法 14.1 修改的KMP串匹配算法
输入:文本串T[1,n]和模式串P[1,m]
输出:是否存在匹配位置
procedure modeifed_KMP
1
Begin
(1) i=1,j=1
(2) while i≤n do
(2.1) while j≠0 and P[j]≠T[i] do
j=newnext[j]
end while
(2.2)if j=m then
return true
else
j=j+1,i=i+1
end if
end while
(3) return false
End
算法 14.2 next函数和newnext函数的计算算法 输入:模式串P[1,m]
输出:next[1,m+1]和newnext[1,m] procedure next
Begin
(1) next[1]=0
(2) j=2
(3) while j≤m do
(3.1)i=next[j-1]
(3.2)while i≠0 and P[i]≠P[j-1] do
i=next[i]
end while
(3.3)next[j]=i+1
(3.4)j=j+1
end while
End
procedure newnext
Begin
(1) newnext(1)=0
(2) j=2
(3) while j≤m do
(3.1)i=next(j)
(3.2)if i=0 or P[j]≠P[i+1] then
newnext[j]=i
else
newnext[j]=newnext[i]
end if
(3.3)j=j+1
2
end while
End
2. 改进的KMP算法
易知算法14.1的时间复杂度为O(n),算法14.2的时间复杂度为O(m)。算法14.1中所给出的KMP算法只能找到第一个匹配位置,实际应用中往往需要找出所有的匹配位置。下面给出改进后的算法14.3便解决了这一问题。
算法 14.3 改进KMP串匹配算法
输入:文本串T[1,n]和模式串P[1,m]
输出:匹配结果match[1,n]
procedure improved_KMP
Begin
(1) i=1,j=1
(2) while i≤n do
(2.1)while j≠0 and P[j]≠T[i] do
j=newnext[j]
end while
(2.2)if j=m then
match[i-(m-1)]=1
j=next[m+1]
i=i+1
else
i=i+1
j=j+1
end if
end while
(3) max_prefix_len=j-1
End
算法 14.4 next函数和newnext函数的计算算法
输入:模式串P[1,m]
输出:next[1,m+1]和newnext[1,m]
procedure NEXT
Begin
(1) next[1]=newnext[1]=0
(2) j=2
(3) while j≤m+1 do
(3.1)i=next[j-1]
(3.2)while i≠0 and W[i]≠W[j-1]) do
i=next[i]
end while
(3.3)next[j]=i+1
(3.4)if j≠m+1 then
if W[j] ≠W[i+1] then
3
newnext[j]=i+1
else
newnext[j]=newnext[i+1]
end if
end if
(3.5)j=j+1
end while
End
在算法14.3中,内层while循环遇到成功比较时和找到文本串中模式串的一个匹配位置时文本串指针i均加1,所以至多做n次比较;内while循环每次不成功比较时文本串指针i保持不变,但是模式串指针j减小,所以i-j的值增加且上一次出内循环时的i-j值等于下一次进入时的值,因此不成功的比较次数不大于i-j的值的增加值,即小于n,所以总的比较次数小于2n,所以算法14.3的时间复杂度为O(n)。算法14.4只比的算法14.2多计算了next(m+1),至多多做m-1次比较,所以算法14.4的时间复杂度同样为O(m)。
2.1.2 KMP串匹配的并行算法
1. 算法原理
在介绍了改进的KMP串行算法基础上,这一节主要介绍如何在分布存储环境中对它进行实现。设计的思路为:将长为n的文本串T均匀划分成互不重叠的p段,分布于处理器0到p-1中,且使得相邻的文本段分布在相邻的处理器中,显然每个处理器中局部文本段的长度为?n/p?(最后一个处理器可在其段尾补上其它特殊字符使其长度与其它相同)。再将长为m的模式串P和模式串的newnext函数播送到各处理器中。各处理器使用改进的KMP算法并行地对局部文本段进行匹配,找到所有段内匹配位置。
但是每个局部段(第p-1段除外)段尾m-1字符中的匹配位置必须跨段才能找到。一个简单易行的办法就是每个处理器(处理器p-1除外)将本局部段的段尾m-1个字符传送给下一处理器,下一处理器接收到前一处理器传来的字符串后,再接合本段的段首m-1个字符构成一长为2(m-1)的段间字符串,对此字符串做匹配,就能找到所有段间匹配位置。但是算法的通信量很大,采用下述两种改进通信的方法可以大大地降低通信复杂度:①降低播送模式串和newnext函数的通信复杂度。利用串的周期性质,先对模式串P作预处理,获得其最小周期长度|U|、最小周期个数s及后缀长度|V|(P=UsV),只需播送U,s,|V|和部分newnext函数就可以了,从而大大减少了播送模式串和newnext函数的通信量。而且串的最小周期和next函数之间的关系存在着下面定理1所示的简单规律,使得能够设计出常数时间复杂度的串周期分析算法。②降低每个处理器(处理器p-1除外)将本局部文本段的段尾m-1个字符传送给下一处理器的通信复杂度。每个处理器在其段尾m-1个字符中找到模式串P的最长前缀串,因为每个处理器上都有模式串信息,所以只需传送该最长前缀串的长度就行了。这样就把通信量从传送模式串P的最长前缀串降低到传送一个整数,从而大大地降低了通信复杂度。而且KMP算法结束时模式串指针j-1的值就是文本串尾模式串最大前缀串的长度,这就可以在不增加时间复杂度的情况下找到此最大前缀串的长度。
2. 串的周期性分析
定义14.1:给定串P,如果存在字符串U以及正整数K≥2,使得串P是串Uk的前缀(Prefix),则称字符串U为串P的周期(Period)。字符串P的所有周期中长度最短的周期 4
称为串P的最小周期(Miximal Period)。
串的周期分析对最终并行算法设计非常关键,串的最小周期和next函数之间的关系存在着如下定理14.1所示的简单规律,基于该规律可以设计出常数时间复杂度的串周期分析算法。
定理14.1:已知串P长为m,则u=m+1-next(m+1)为串P的最小周期长度。
算法 14.5 串周期分析算法
输入:next[m+1]
输出:最小周期长度period_len
最小周期个数period_num
模式串的后缀长度pattern-suffixlen
procedure PERIOD_ANALYSIS
Begin
period_len=m+1-next(m+1)
period_num=(int)m/period_len
pattern_suffixlen=m mod period_len
End
3. 并行算法描述
在前述的串行算法以及对其并行实现计的分析的基础上,我们可以设计如下的并行KMP串匹配算法。
算法 14.6 并行KMP串匹配算法
输入:分布存储的文本串Ti[1,?n/p?](i=0,1,2,…,p-1)
存储于P0的模式串P[1,m]
输出:所有的匹配位置
Begin
(1) P0 call procedure NEXT /*调用算法14.4,求模式串P的
next函数和newnext函数*/
P0 call procedure PERIOD_ANALYSIS /*调用算法14.5分析P的周期*/
(2) P0 broadcast period_len,period_num,period_suffixlen to other processors /*播送
P之最小周期长度、最小周期个数和后缀长度*/
P0 broadcast P[1,period_len] /*不播送P之最小周期*/
if period_num=1 then /*播送P之部分newnext函数,如周期为1,则播送整个
newnext函数;否则播送2倍周期长的newnext函数*/
broadcast newnext [1,m]
else
broadcast newnext[1,2*period_len]
end if
(3) for i=1 to p-1 par-do /*由传送来的P之周期和部分newnext函数重构整个模式串
和newnext函数*/
Pi rebuild newnext
end for
for i=1 to p-1 par-do /*调用算法14.7做局部段匹配,并获得局部段尾最大前缀串
之长度*/
5
Pi call procedure KMP(T,P ,n ,0,match)
end for
(4) for i =0 to p-2 par-do
Pi send maxprefixlen to Pi+1
end for
for i=1 to p-1 par-do
Pi receive maxprefixlen from Pi-1
Pi call procedure KMP(Ti,P,m-1, maxprefixlen,match+m-1) /*调用
算法14.7做段间匹配*/
end for
End
该算法中调用的KMP算法必须重新修改如下,因为做段间匹配时已经匹配了maxprefixlen长度的字符串,所以模式串指针只需从maxprefixlen+1处开始。
算法 14.7 重新修改的KMP算法
输入:分布存储的文本串和存储于P0的模式串P[1,m]
输出:所有的匹配位置
procedure KMP(T,P,textlen, matched_num,match)
Begin
(1) i=1
(2) j=matched_num+1
(3) while i≤textlen do
(3.1)while j≠0 and P[j]≠T[i] do
j=newnext[j]
end while
(3.2)if j=m then
match[i-(m-1)]=1
j=next[m+1]
i=i+1
else
j=j+1
i=i+1
end if
end while
(4) maxprefixlen=j-1
End
下面从计算时间复杂度和通信时间复杂度两个方面来分析该算法的时间复杂度。在分析计算时间复杂度时,假定文本串初始已经分布在各个处理器上,这是合理的,因为文本串一般很大,不会有大的变化,只需要分布一次就可以,同时也假定结果分布在各处理器上。 本算法的计算时间由算法步(1)中所调用的算法14.4的时间复杂度O(m)和算法14.5的时间复杂度O(1);算法步(3)和算法步(4)所调用的改进的KMP算法14.7的时间复杂度O(n/p)和O(m)构成。所以本算法总的计算时间复杂度为O(n/p+m)。通信复杂度由算法步(2)播送模式串信息(最小周期串U及最小周期长度、周期个数和后缀长度三个整数)和newnext函数(长度为2u的整数数组,u为串U的长度)以及算法步(4)传送最大前缀串长度组成,所以通信复杂度与具体采用的播送算法有关。若采用二分树通信技术,则总的 6
通信复杂度为O(ulogp)。
MPI源程序请参见章末附录。
2.2 随机串匹配算法
2.2.1 随机串匹配及其串行算法
采用上一节所述的KMP算法虽然能够找到所有的匹配位置,但是算法的复杂度十分高,在某些领域并不实用。本节给出了随机串匹配算法,该算法的主要采用了散列(Hash)技术的思想,它能提供对数的时间复杂度。其基本思想是:为了处理模式长度为m的串匹配问题,可以将任意长为m的串映射到O(logm)整数位上,映射方法须得保证两个不同的串映射到同一整数的概率非常小。所得到的整数之被视为该串的指纹(Fingerprint),如果两个串的指纹相同则可以判断两个串相匹配。
1. 指纹函数
本节中假定文本串和模式串取字符集∑={0,1}中的字母。
如上所述,随机串匹配算法的基本策略是将串映射到某些小的整数上。令T是长度为n的文本串,P是长度为m≤n的模式串,匹配的目的就是识别P在T中出现的所有位置。考虑长度为m的T的所有子串集合B。这样的起始在位置i(1≤i≤n-m+1)的子串共有n-m+1个。于是问题可重新阐述为去识别与P相同的B中元素的问题。该算法中最重要的是如何选择一个合适的映射函数(Mapping Function),下面将对此进行简单的讨论。
令F?{fp}p?s是函数集,使得fp将长度为m的串映射到域D,且要求集合F满足下述三个性质:①对于任意串X∈B以及每一个p∈S(S为模式串的取值域),fp(X)由O(logm)位组成;②随机选择fp?F,它将两个不等的串X和Y映射到D中同一元素的概率是很小的;③对于每个p∈S和B中所有串,应该能够很容易的并行计算fp(X)。
上述三个性质中,性质①隐含着fp(X)和fp(P)可以在O(1)时间内比较,其中fp(X)被称为串X的指纹;性质②是说,如果两个串X和Y的指纹相等,则X=Y的概率很高;性质③主要是针对该算法的并行实现的需求对集合F加以限制。对于串行算法函数fp只需要满足前两个性质即可。
本节中我们采用了这样一类指纹函数:将取值{0,1}上的串X集合映射到取值整数环Z上的2?2矩阵。令f(0)和f(1)定义如下:
?10?f(0)???,11???11?f(1)????01?
该函数目前只满足性质2,为了使其同时满足性质1需要对该函数作如下更改:
p令p是区间[1,2,…,M]中的一个素数,其中M是一个待指定的整数;令Zp是取模
7
的整数环。对于每个这样的p,我们定义fp(X)为f(X)modp,即fp(X)是一个2?2的矩阵,使得fp(X)的(i,j)项等于f(X)的相应项取模p。
由此构造的函数fp同时满足前述性质1和2。
2. 串行随机串匹配算法
用上面定义的指纹函数可以构造一个随机串匹配算法。先计算模式串P(1,m)和子串T(i,i+m-1)的指纹函数(其中1≤i≤n-m+1,m≤n),然后每当P的指纹和T(i,i+m-1)的指纹相等时,则标记在文本T的位置i与P出现匹配。算法描述如下:
算法 14.8 串行随机串匹配算法
输入:数组T(1,n)和P(1,m),整数M。
输出:数组MATCH,其分量指明P在T中出现的匹配位置。
Begin
(1) for i=1 to n-m+1 do
MATCH(i)=0
end for
(2) 在区间[1,2,…,M]中随机的选择一素数,并计算fp(P)
(3) for i=1 to n-m+1 do
Li= fp(T(i,i?m?1))
end for
(4) for i=1 to n-m+1 do
if Li=fp(P) then
MATCH(i)=1
end if
end for
End
很显然在该算法中步骤(1)和(4)的时间复杂度均为O(n-m);步骤(2)和(3)中求模式串和文本串各个子串的指纹的时间复杂度分别O(m)和O(n-m)。
2.2.2 随机串匹配的并行算法
对上述串行算法的并行化主要是针对算法14.7中步骤(3)的并行处理,也就是说需要选择一个合适的函数fp使其同时满足上述三个性质。前面一节给出了同时满足前两个性质的函数,这里我们主要针对性质3来讨论已得指纹函数类F。
函数类F?{fp}的一个关键性质就是每个fp都是同态(Homomorphic)的,即对于任意两个串X和Y,fP(XY)?fp(X)fp(Y)。下面给出了一个有效的并行算法来计算文本串T中所有子串的指纹。
8
对于每个1≤i≤n-m+1,令Ni?fp(T(1,i)),易得Ni?fp(T(1))fp(T(2))?fp(T(i))。因为矩阵乘法是可结合的,所以此计算就是一种前缀和的计算;同时每个矩阵的大小为2?2,因此这样的矩阵乘法可以在O(1)时间内完成。所以,所有的Ni都可以在O(logn)时间内,总共使用O(n)次操作计算。
0??1?1?1定义14.2:gp(0)?fp(0)???,gp(1)?fp(1)??0p?11????1p?1?。则乘积1??
Ri?gp(T(i))gp(T(i?1))?gp(T(1))也是一个前缀和计算,并且对于1?i?n,它可以在O(logn)时间内运用O(n)次操作计算。
容易看到,fp(T(i,i?m?1))?Ri?1Ni?m?1,因此,一旦所有的Ri和Ni都计算出来了,则每个这样的矩阵均可在O(1)时间内计算之。所以,长度为n的正文串T中所有长度为m≤n的子串的指纹均可在O(logn)时间内使用O(n)次操作而计算之。
这样,函数fp同时满足了前述三个性质。在此基础上我们给出了在分布式存储体系结构上随机串匹配的并行算法。
算法 14.9 并行随机串匹配算法
输入:数组T(1,n)和P(1,m),整数M。
输出:数组MATCH,其分量指明P在T中出现的位置。
Begin
(1) for i=1 to n-m+1 par-do
MATCH(i)=0;
end for
(2) Select a random prime number in [1,2,…,M],then count fp(P)。
(3) for i=1 to n-m+1 par-do
Li= fp(T(i,i?m?1));
end for
(4) for i=1 to n-m+1 par-do
if Li=fp(P) then
MATCH(i)=1
end if
end for
End
该并行算法的计算复杂度为O(logn)。处理期间的通信包括在对文本串到各个处理器的分派,其通信复杂度为O(n/p+m);以及匹配信息的收集,其通信复杂度为O(n/p)。 MPI源程序请参见所附光盘。
9
2.3 近似串匹配算法
2.3.1 近似串匹配及其串行算法
前两节所讨论的串匹配算法均属于精确串匹配技术,它要求模式串与文本串的子串完全匹配,不允许有错误。然而在许多实际情况中,并不要求模式串与文本串的子串完全精确地匹配,因为模式串和文本串都有可能并不是完全准确的。例如,在检索文本时,文本中可能存在一些拼写错误,而待检索的关键字也可能存在输入或拼写错误。在这种情况下的串匹配问题就是近似串匹配问题。
近似串匹配问题主要是指按照一定的近似标准,在文本串中找出所有与模式串近似匹配的子串。近似串匹配问题的算法有很多,按照研究方法的不同大致分为动态规划算法,有限自动机算法,过滤算法等。但上述所有算法都是针对一般的近似串匹配问题,也就是只允许有插入、删除、替换这三种操作的情况。本节中还考虑了另外一种很常见的错误—换位,即,文本串或模式串中相邻两字符的位置发生了交换,这是在手写和用键盘进行输入时经常会发生的一类错误。为修正这类错误引入了换位操作,讨论了允许有插入、删除、替换和换位四种操作的近似串匹配问题。
1. 问题描述:
给定两个长度分别为m和n的字符串A[1,m]和B[1,n],ai,bj∈∑(1≤i≤m,1≤j≤n,∑是字母表),串A与串B的编辑距离(Editor Distance)是指将串A变成串B所需要的最少编辑操作的个数。最常见的编辑操作有三种:①插入(Insert),向串A中插入一个字符;②删除(Delete),从串A中删除一个字符;③替换(Replace),将串A中的一个字符替换成串B中的一个字符。其中,每个编辑操作修正的串A与串B之间的一个不同之处称为一个误差或者错误。
最多带k个误差的串匹配问题(简称为k-differences问题)可描述如下:给定一个长度为n的文本串T=t1…tn,一个长度为m的模式串P=p1…pm,以及整数k(k≥1),在文本串T中进行匹配查找,如果T的某个子串ti…tj与模式串P的编辑距离小于等于k,则称在tj处匹配成功,要求找出所有这样的匹配结束位置tj。
另外一种很常见的编辑操作是换位(Exchange):将串A中的两个相邻字符进行交换。该操作用于修正相邻两字符位置互换的错误。一个换位操作相当于一个插入操作加上一个删除操作。但是,当近似匹配允许的最大误差数k一定时,允许有换位操作的情况较之不允许有换位操作的情况,往往能够找出更多的匹配位置。
例如,假定文本串T=abcdefghij,模式串P=bxcegfhy,k=4,问在文本串的第9个字符处是否存在最多带4个误差的匹配?
首先考虑允许有换位操作的情况,文本串与模式串的对应关系如下:
t1 t2 t3 t4 t5 t6 t7 t8 t9 t10
T: a b c d e f g h i j P: b x c e g f h y
① ② ③ ④
其中,①,②,③,④ 4个位置分别对应于删除、插入、换位和替换操作,可见在t9处确实有最多带4个误差的匹配。
不允许有换位操作的情况,对应关系如下:
t1 t2 t3 t4 t5 t6 t7 t8 t9 t10
T: a b c d e f g h i j
10
P: b x c e g f h y
① ② ③ ④ ⑤
可以看出,在t9处不存在最多带4个误差的匹配,因为匹配成功所需要的最少编辑操作个数为5。
由此可见,允许有换位操作的近似串匹配算法比以往未考虑换位操作的算法更加实用有效。尤其是在文本检索和手写体识别等实际应用中,新算法的检索成功率和识别率更高,准确性更好,功能更强。
2. k-differences问题的动态规划算法
一般的k-differences问题的一个著名算法采用了动态规划(Dynamic Programming)的技术,可以在O(mn)时间内解决该问题。其基本思想是:根据文本串T[1,n]和模式串P[1,m]计算矩阵D(m+1)x(n+1),其中D[i,j](0≤i≤m,0≤j≤n)是模式串P的前缀子串p1…pi与文本串T的任意以tj结尾的子串之间的最小误差个数(即最小编辑距离)。显然,如果D[m,j] ≤k,则表明在文本串T的tj处存在最多带k个误差的匹配。D[i,j]由以下公式计算:
D[0,j]=0,0≤j≤n
D[i,0]=i,1≤i≤m
D[i,j]=min(D[i-1,j]+1,D[i,j-1]+1,D[i-1,j-1]+δ(pi,tj))
其中,δ(pi,tj)=0,如果pi=tj;否则,δ(pi,tj)=1。
可以看出,D[i,j]的计算是通过递推方式进行的。D[0,j]对应于模式串为空串,而文本串长度为j的情况,显然,空串不需要任何编辑操作就能在文本串的任何位置处匹配,所以D[0,j]=0。D[i,0]对应于模式串长度为i,而文本串为空串的情况,此时,至少需要对模式串进行i次删除操作才能与文本串(空串)匹配,所以D[i,0]=i。在计算D[i,j]时,D[i-1,j],D[i,j-1],D[i-1,j-1]都已计算出,D[i-1,j]+1,D[i,j-1]+1,D[i-1,j-1]+δ(pi,tj)分别对应于对模式串进行插入、删除、替换操作的情况,由于D[i,j]是最小编辑距离,所以取三者中的最小值。
上述动态规划算法只考虑了插入、删除、替换三种编辑操作,但很容易将其推广到允许有换位操作的情况。考虑D[i,j]的计算,若pi-1pi=titi-1,则D[i,j]的一个可能取值是D[i-2,j-2]+1,即,将pi-1pi变成titi-1只需要进行一次换位操作,从而最小编辑距离只增加1。由此可对上述算法进行简单的修改,使之适用于允许有插入、删除、替换和换位四种编辑操作的情况。
算法14.10 允许有换位操作的k-differences问题的动态规划算法。
输入:文本串T[1,n],模式串P[1,m],近似匹配允许的最大误差数k。
输出:所有匹配位置。
K-Diff_DynamicProgramming(T,n,P,m,k)
Begin
(1) for j=0 to n do D[0,j]=0 end for
(2) for i=1 to m do D[i,0]=i end for
(3) for i=1 to m do
(3.1) for j=1 to n do
(ⅰ) if (P[i]=T[j]) then
D[i,j]=D[i-1,j-1]
else if (P[i]=T[j-1] and P[i-1]=T[j]) then
D[i,j]=min(D[i-2,j-2]+1,D[i-1,j]+1,D[i,j-1]+1)
else
11
D[i,j]=min(D[i-1,j]+1,D[i,j-1]+1,D[i-1,j-1]+1)
end if
end if
(ⅱ) if (i=m and D[i,j]<=k) then
找到P在T中的一个最多带k个误差的近似匹配,
输出匹配结束位置j;
end if
end for
end for
End
显然,该算法的时间复杂度为O(mn)。
3. 基于过滤思想的扩展的近似串匹配算法:
经典的动态规划算法在实际应用中速度很慢,往往不能满足实际问题的需要。为此,S.Wu和U.Manber以及Gonzalo Navarro和Ricardo Baeza-Yates等人先后提出了多个基于过滤(Filtration)思想的更加快速的近似串匹配算法。这些算法一般分为两步:①按照一定的过滤原则搜索文本串,过滤掉那些不可能发生匹配的文本段;②再进一步验证剩下的匹配候选位置处是否真的存在成功匹配。由于在第一步中已经滤去了大部分不可能发生匹配的文本段,因此大大加速了匹配查找过程。在实际应用中,这些过滤算法一般速度都很快。下面我们针对前面定义的扩展的近似串匹配问题,讨论了加入换位操作后的k-differences问题的过滤算法。
过滤算法基于这样一种直观的认识:若模式串P在文本串T的tj处有一个最多带k个误差的近似匹配,则P中必然有一些子串是不带误差地出现在T中的,也就是说,P中必然有一些子串与T中的某些子串是精确匹配的。
引理14.1:在允许有换位操作的最多带k个误差的串匹配问题中,如果将模式串P划分成2k+1段,那么对于P在T中的每一次近似出现(最多带k个误差),这2k+1段中至少有一段是不带误差地出现在T中的。
证明:这个引理很容易证明。试想,将k个误差,也就是对模式串P所做的k个编辑操作,分布于2k+1个子模式串中。由于一个插入,删除或替换操作只能改变一个子模式串,而一个换位操作有可能改变两个子模式串(例如,在子模式串i的最后一个字符与子模式串i+1的第一个字符之间进行一次换位操作),所以k个编辑操作最多只能改变2k个子模式串。这就是说,在这2k+1个子模式串中,至少有一个是未被改变的,它不带误差地出现在文本串T中,与T的某个(些)子串精确匹配。■
根据上面的引理,我们可设计过滤算法,其原理描述如下:
第1步:
(1) 将模式串P尽可能均匀地划分成2k+1个子模式串P1,P2,…,P2k+1,每个子模式串的长度为??m??m??或?2k?1?。 具体地说,如果m=q(2k+1)+r,0≤r<2k+1,2k?1????
?m?的子模式串和(2k+1)-r个长度为??2k?1?那么可以将模式串P划分成r个长度为?
12
?m?的子模式串。 ???2k?1?
(2) 采用一种快速的精确串匹配算法,在文本串T中查找P1,P2,…,P2k+1这2k+1个子模式串,找到的与某个子模式串P?(1≤?≤2k+1)精确匹配的位置也是可能与整个模式串P发生最多带k个误差的近似匹配的候选位置。
第2步:
采用动态规划算法(算法14.10)验证在各候选位置附近是否真的存在最多带k个误差的近似匹配。假定在第一步中找到了以pj(1≤j≤m)开头的子模式串P?(1≤?≤2k+1)在文本串中的一个精确匹配,且该匹配的起始位置在文本串的ti处,则需要验证从ti-j+1-k到ti-j+m+k之间的文本段T[i-j+1-k, i-j+m+k]。因为在本文所讨论的问题中,允许的编辑操作包括插入,删除,替换和换位,近似匹配允许的最大误差数为k,所以如果在候选位置ti附近存在最多带k个误差的近似匹配,只可能发生在这个长度为m+2k的文本段范围内,超出这个范围,误差数就大于k了。因此在上述情况下,只需要验证T[i-j+1-k,i-j+m+k]就足够了。
算法14.11 允许有换位操作的k-differences问题的过滤算法。
输入:文本串T(长度n),模式串P(长度m),近似匹配允许最大误差数k。 输出:所有匹配位置。
K-Diff_Filtration(T,n,P,m,k)
Begin
(1) r=m mod (2k+1)
(2) j=1
(3) for ?=1 to 2k+1 do
(3.1) if (?<=r= then len=??m?? 2k?1??
else len=??m? ??2k?1?
end if
(3.2) for each exact matching position i in T reported by search(T,n,P[j,j+len-1],len) do
check the area T[i-j+1-k, i-j+m+k]
end for
(3.3) j=j+len
end for
End
过滤算法的时间性能与模式串的长度m,近似匹配允许的最大误差数k,以及字母表中各字符出现的概率等因素都密切相关。误差率α定义为近似匹配允许的最大误差数k与模式串长度m的比值,即α=k/m。在误差率α很小的情况下,算法14.11的平均时间复杂度为O(kn)。
2.3.2 近似串匹配的并行算法
这一节首先介绍扩展近似串匹配过滤算法在PRAM模型上的并行化方法,然后给出了分布式存储模型的并行化过滤算法。
13
1. 扩展近似串匹配问题的过滤算法在PRAM模型上的并行化
首先假设有p个处理器。由于,最多带k个误差的串匹配问题要求在文本串中找出所有成功匹配的结束位置tj,因此可以将整个问题划分成p个子问题,每个子问题的文本串长度为?=?n/p?(最后一段长度不够可以用特殊字符补齐),用p个处理器并行求解,每个处理器求解一个子问题。子问题i(1≤i≤p)对应于:求结束于t(i-1)?+1,t(i-1)?+2,…,ti?的最多带k个误差的近似匹配。
考虑第i个子问题。由于在定义的扩展近似串匹配问题中,允许的编辑操作包括插入、删除、替换和换位,而允许的最大误差数为k,因此结束于t(i-1)?+1的最多带k个误差的近似匹配的最左起始位置应该是t(i-1)?+1-(k+m-1)。这说明,在求解子问题i(2≤i≤p)时,必须结合前一文本段的最后k+m-1个字符,才能找出所有的匹配位置。
算法14.12 扩展近似串匹配问题的基于PRAM模型的并行化过滤算法
输入:文本串T[1,n],模式串P[1,m],近似匹配允许的最大误差数k
输出:所有匹配位置
Begin
(1) ?=?n/p?
(2) K-Diff_Filtration(T[1,?],?,P,m,k)
(3) for i=2 to p par-do
K-Diff_Filtration(T[(i-1)?+1-(k+m-1),i?],?+k+m-1,P,m,k)
end for
End
算法14.12的平均时间复杂度的分析与上一节中串行过滤算法的分析完全类似。此时,用于查找2k+1个子模式串的时间开销为O((2k+1)?+m)+O((2k+1)(?+k+m-1)+m)
31/2α=O(kn/p+km),用于验证所有候选位置的时间开销约为2mα/σ。通过类似的分析讨论可
以得出如下结论:在误差率α很小的情况下,算法14.12的平均时间复杂度为O(kn/p+km),其中,n、m、k和p分别是文本串长度、模式串长度、近似匹配允许的最大误差数和算法所使用的处理器个数。
2. 扩展近似串匹配问题的基于分布式存储模型的并行化过滤算法
扩展近似串匹配问题的基于分布式存储模型的并行化过滤算法与前述的基于PRAM模型的并行化过滤算法在设计原理和设计思路上是完全一样的。只不过由于是在分布式存储环境下,文本串和模式串分布存储于不同的处理器上,因此算法中涉及到处理器之间的通信。 算法的设计思路是这样的:将长度为n的文本串T均匀地划分成长度相等且互不重叠的p段(最后一段长度不够可以用特殊字符补齐)。将这p个局部文本串按照先后顺序分布于处理器0到(p-1)上,也就是说,第1个局部文本串放在处理器0上,第2个局部文本串放在处理器1上,……,第p个局部文本串放在处理器p-1上。这样一来,相邻的局部文本串就被分布在相邻的处理器上,而且每个处理器上局部文本串的长度均为?n/p?。算法中假定长度为m的模式串P初始存储于处理器0上,所以必须将它播送到各个处理器上,以便所有处理器并行求解近似串匹配问题。但是根据上小节中的分析,结束位置在各局部文本串(第1个局部文本串除外)的前m+k-1个字符中的那些匹配位置必须跨越该局部文本串才能找到,具体地说,就是必须结合前一局部文本串的最后m+k-1个字符,才能找到结束于这些位置的 14
近似匹配。因此,每个处理器(处理器p-1除外)应将它所存储的局部文本串的最后m+k-1个字符发送给下一处理器,下一处理器接收到上一处理器发送来的m+k-1个字符,再结合自身所存储的长度为?n/p?的局部文本串进行近似匹配查找,就可以找出所有的匹配位置。在播送模式串P到各处理器上,以及发送局部文本串最后m+k-1个字符到下一处理器的通信操作结束之后,各处理器调用K-Diff_Filtration算法并行地进行匹配查找,处理器0求解文本串长度为?n/p?,模式串长度为m的子问题,其它各处理器求解文本串长度为?n/p?+m+k-1,模式串长度为m的子问题。
算法14.13 扩展近似串匹配问题的基于分布式存储模型的并行化过滤算法
输入:分布存储于处理器Pi上的文本串Ti[1,?n/p?],
存储于处理器P0上的模式串P[1,m],
近似匹配允许的最大误差数k
输出:分布于各个处理器上的匹配结果
Begin
(1) P0 broadcast m
(2) P0 broadcast P[1,m];
(3) for i=0 to p-2 par-do
Pi send Ti[?n/p?-m-k+2,?n/p?] to Pi+1;
end for
(4) for i=1 to p-1 par-do
Pi receive Ti-1[?n/p?-m-k+2,?n/p?] from Pi-1;
end for
(5) P0 call K-Diff_Filtration(T0[1,?n/p?],?n/p?,P,m,k);
(6) for i=1 to p-1 par-do
Pi call K-Diff_Filtration
(Ti-1[?n/p?-m-k+2,?n/p?]+Ti[1,?n/p?],?n/p?+m+k-1,P,m,k);
end for
End
算法14.13的时间复杂度包括两部分,一部分是计算时间复杂度,另一部分是通信时间复杂度。算法中假定文本串初始已经分布于各个处理器上,最终的匹配结果也分布于各个处理器上。算法的计算时间由算法第(5)步中各处理器同时调用算法14.12(K-Diff_Filtration算法)的时间复杂度构成。根据对算法14.11的平均时间复杂度的分析,在误差率α很小的情况下,算法14.13的平均计算时间复杂度为O(kn/p+km),当模式串长度m远远小于局部文本串长度n/p时,平均计算时间复杂度为O(kn/p)。算法的通信时间由算法第(1)步播送模式串长度m的时间,第(3)步播送模式串P的时间,以及第(4)步发送各局部文本串末尾m+k-1个字符到下一处理器的时间构成。通信时间复杂度与具体采用的播送算法有关。若以每次发送一个字符的时间为单位时间,则通信时间复杂度为O(m+k)。 15
MPI源程序请参见所附光盘。
2.4 小结
本章主要讨论了几个典型的并行串匹配算法,关于KMP算法的具体讨论可参考[1],[2],[3],Karp和Rabin在[4]中首先提出了随机串匹配的算法,关于该算法的正确性证明可参阅[5];文献[6]和[7]分别讨论了近似串匹配,允许由换位操作的近似串匹配算法见文献[8]。
参考文献
[1]. Knuth D E, Morris J H, Pratt V R. Fast Pattern Matching in Strings. SIAM Journal of
Computing, 1977, 6(2):322-350
[2]. 朱洪等. 算法设计与分析. 上海科学技术出版社, 1989
[3]. 陈国良, 林洁, 顾乃杰. 分布式存储的并行串匹配算法的设计与分析. 软件学报, 2002.6,
11(6):771-778
[4]. Karp R M, Rabin M O. Efficient randomized pattern-matching algorithms. IBM J. Res.
Develop., 1987,31(2):249-260
[5]. 陈国良 编著. 并行算法的设计与分析(修订版). 高等教育出版社, 2002.11
[6]. Wu S, Manber U. Fast test searching allowing errors. Communications of the ACM, 1993,
35(10):83-91
[7]. Ricardo B Y, Gonzalo N. Faster Approximate String Matching. In Algorithmica, 1999. 23(2) [8]. 姚珍. 带有换位操作的近似串匹配算法及其并行实现. 中国科学技术大学硕士论
文,2000.5
附录 KMP串匹配并行算法的MPI源程序
1. 源程序gen_ped.c
#include <stdio.h> #include <stdlib.h> #include <malloc.h> #include <string.h>
/*根据输入参数生成模式串*/ int main(int argc,char *argv[]) {
int strlen,pedlen,suffixlen,num,i,j; char *string; FILE *fp;
strlen=atoi(argv[1]);
pedlen=atoi(argv[2]); srand(atoi(argv[3]));
string=(char*)malloc(strlen*sizeof(char)); if(string==NULL)
{ }
for(i=0;i<pedlen;i++) {
num=rand()%26; printf("malloc error\n"); exit(1);
16
string[i]='a'+num; }
for(j=1;j<(int)(strlen/pedlen);j++)
strncpy(string+j*pedlen,string,pedlen);
if((suffixlen=strlen%pedlen)!=0) strncpy(string+j*pedlen,string,suffixlen);
if((fp=fopen(argv[4],"w"))!=NULL) {
2. 源程序 kmp.c
#include <malloc.h> #include <sys/stat.h> #include <sys/types.h> #include <stdio.h> #include <string.h> #include <mpi.h>
#define MAX(m,n) (m>n?m:n)
typedef struct{ int pedlen; int psuffixlen; int pednum;
}pntype;
/*对模式串进行周期分析,并计算相应的new和
newval值*/
void Next(char *W,int patlen,int *nextval,
pntype *pped) { int i,j,plen; int *next;
if((next=(int *)malloc((patlen+1)*sizeof(int)))
==NULL) { printf("no enough memory\n");
exit(1);
}
/*计算next和nextval*/
next[0]=nextval[0]=-1;
fprintf(fp,"%s",string); fclose(fp);
} else
{ printf("file open error\n"); exit(1);
} return;
}
j=1; while(j<=patlen)
{ i=next[j-1];
while(i!=(-1) && W[i]!=W[j-1])
i=next[i]; next[j]=i+1;
if(j!=patlen) {
if( W[j]!=W[i+1])
nextval[j]=i+1;
else
nextval[j]=nextval[i+1];
}
j++;
}
pped->pedlen=patlen-next[patlen]; pped->pednum=(int)(patlen/pped->pedlen); pped->psuffixlen=patlen%pped->pedlen;
free(next);
}
/*改进的KMP算法*/
void kmp(char *T,char*W,int textlen,int patlen,
int *nextval,pntype *pped,int prefix_flag, int matched_num,int *match,int *prefixlen) {
int i,j;
17
i=matched_num; j=matched_num;
while(i<textlen) {
if((prefix_flag==1)&&((patlen-j)>
(textlen-i)))
break; while(j!=(-1) && W[j]!=T[i])
j=nextval[j];
if(j==(patlen-1))
{
match[i-(patlen-1)]=1;
if(pped->pednum+pped->psuffixlen
==1) j = -1 ;
else
j=patlen-1-pped->pedlen;
} j++;
i++;
}
(*prefixlen)=j; }
/*重构模式串以及next函数*/
void Rebuild_info(int patlen,pntype *pped,
int *nextval,char *W) {
int i;
if (pped->pednum == 1)
memcpy(W+pped->pedlen,W,
pped->psuffixlen);
else {
memcpy(W+pped->pedlen,W,
pped->pedlen);
for (i=3; i<=pped->pednum; i++)
{
memcpy(W+(i-1)*pped->pedlen,W,
pped->pedlen);
memcpy(nextval+(i-1)*
pped->pedlen,
nextval+pped->pedlen, pped->pedlen*sizeof(int));
}
if(pped->psuffixlen!=0)
{
memcpy(W+(i-1)*pped->pedlen,W,
pped->psuffixlen); memcpy(nextval+(i-1)*
pped->pedlen,nextval+ pped->pedlen,
pped->psuffixlen*sizeof(int)); } }
}
/*生成文本串*/
void gen_string(int strlen,int pedlen,char *string,
int seed) { int suffixlen,num,i,j;
srand(seed);
for(i=0;i<pedlen;i++)
{ num=rand()%26;
string[i]='a'+num;
}
for(j=1;j<(int)(strlen/pedlen);j++)
strncpy(string+j*pedlen,string,pedlen); if((suffixlen=strlen%pedlen)!=0) strncpy(string+j*pedlen,string,suffixlen); }
/*从文件读入模式串信息*/
void GetFile(char *filename,char *place, int *number) { FILE *fp;
struct stat statbuf;
if ((fp=fopen(filename,"rb"))==NULL)
{
printf ("Error open file %s\n",filename);
exit(0);
18
}
if(((*place)=(char *)malloc(sizeof(char)*
statbuf.st_size)) == NULL){
{ }
fprintf (fp,"This is the match result on node %d
printf ("Error open file %s\n",filename);
exit(0);
fstat(fileno(fp),&statbuf);
printf ("Error alloc memory\n");
exit(1);
}
if (fread((*place),1,statbuf.st_size,fp) !=statbuf.st_size){
printf ("Error in reading num\n");
exit(0);
}
fclose (fp);
(*number)=statbuf.st_size; }
/*打印运行参数信息*/
void PrintFile_info(char *filename,char *T,int id) { FILE *fp; int i;
if ((fp=fopen(filename,"a"))==NULL) { printf ("Error open file %s\n",filename); exit(0);
}
fprintf (fp,"The Text on node %d is %s .\n",
id,T);
fclose (fp); }
/*打印匹配结果*/
void PrintFile_res(char *filename,int *t,int len,
int init,int id) { FILE *fp; int i;
if ((fp=fopen(filename,"a"))==NULL) \n",id);
for (i=0; i<=len-1; i++)
if(t[i]==1) fprintf (fp,"(%d) +\n",i+init);
else
fprintf (fp,"(%d) -\n",i+init); fclose (fp);
}
void main(int argc,char *argv[]) { char *T,*W; int *nextval,*match;
int textlen,patlen,pedlen,nextlen_send; pntype pped;
int
i,myid,numprocs,prefixlen,ready; MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,
&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,
&myid);
nextlen_send=0; ready=1;
/*读如文本串长度*/ textlen=atoi(argv[1]); textlen=textlen/numprocs;
pedlen=atoi(argv[2]);
if((T=(char *)malloc(textlen*sizeof(char)))
==NULL) { printf("no enough memory\n");
exit(1);
}
gen_string(textlen,pedlen,T,myid);
19
if(myid==0) { PrintFile_info("match_result",T,myid); if(numprocs>1)
MPI_Send(&ready,1,MPI_INT,1,0,
MPI_COMM_WORLD);
} else {
MPI_Recv(&ready,1,MPI_INT,myid-1,
myid-1,MPI_COMM_WORLD, &status);
PrintFile_info("match_result",T,myid); if(myid!=numprocs-1)
MPI_Send(&ready,1,MPI_INT,
myid+1,myid,
MPI_COMM_WORLD);
}
printf("\n");
if((match=(int *)malloc(textlen*sizeof(int)))
==NULL) { printf("no enough memory\n"); exit(1);
}
/*处理器0读入模式串,并记录运行参数*/ if(myid==0)
{
printf("processor num = %d \n",
numprocs);
printf("textlen = %d\n",
textlen*numprocs);
GetFile("pattern.dat",&W,&patlen);
printf("patlen= %d\n",patlen); if((nextval=(int *)malloc(patlen*
sizeof(int)))==NULL) {
printf("no enough memory\n"); exit(1);
}
/*对模式串进行分析,对应于算法14.6
步骤(1)*/
Next(W,patlen,nextval,&pped); if(numprocs>1) {
if (pped.pednum==1) nextlen_send = patlen; else
nextlen_send = pped.pedlen*2;
} } /*向各个处理器播送模式串的信息,对应于算 法14.6步骤(2)*/
if(numprocs>1)
{ MPI_Bcast(&patlen, 1, MPI_INT, 0,
MPI_COMM_WORLD);
if(myid!=0)
if(((nextval=(int *)malloc(patlen*
sizeof(int)))==NULL)
||((W=(char *)malloc(patlen* sizeof(char)))==NULL))
{
printf("no enough memory\n");
exit(1); }
MPI_Barrier(MPI_COMM_WORLD);
MPI_Bcast(&pped,3,MPI_INT,0,
MPI_COMM_WORLD);
MPI_Bcast(&nextlen_send,1,MPI_INT,0,
MPI_COMM_WORLD);
MPI_Bcast(nextval,nextlen_send,
MPI_INT,0,
MPI_COMM_WORLD);
MPI_Bcast(W,pped.pedlen,
MPI_CHAR,0,
MPI_COMM_WORLD);
}
MPI_Barrier(MPI_COMM_WORLD);
/*调用修改过的KMP算法进行局部串匹配,
对应于算法14.6步骤(3)*/
20
if(numprocs==1) {
kmp(T,W,textlen,patlen,nextval,
&pped,1,0,
match+patlen-1,&prefixlen);
} else
{ if(myid!=0)
/*各个处理器分别根据部分串数据以及周期信息重构模式串*/
Rebuild_info(patlen,&pped,nextval,W);
if(myid!=numprocs-1)
kmp(T,W,textlen,patlen,nextval,
&pped,0,0,match+patlen-1, &prefixlen);
else
kmp(T,W,textlen,patlen,nextval,
&pped,1,0,match+patlen-1, &prefixlen);
MPI_Barrier(MPI_COMM_WORLD);
/*各个处理器进行段间匹配,对应于算法14.6步骤(4)*/ if(myid<numprocs-1)
MPI_Send(&prefixlen,1,MPI_INT,
myid+1,99,
MPI_COMM_WORLD);
if(myid>0)
MPI_Recv(&prefixlen,1,MPI_INT,
myid-1,99,
MPI_COMM_WORLD, &status);
MPI_Barrier(MPI_COMM_WORLD);
if((myid>0)&&(prefixlen!=0))
kmp(T-prefixlen,W,
prefixlen+patlen-1, patlen,nextval,&pped,1, prefixlen,
match+patlen-1-prefixlen, &prefixlen);
MPI_Barrier(MPI_COMM_WORLD);
}
/*输出匹配结果*/ if(myid==0) {
PrintFile_res("match_result",
match+patlen-1,textlen-patlen+1,0, myid);
if(numprocs>1)
MPI_Send(&ready,1,MPI_INT,1,0,
MPI_COMM_WORLD);
} else {
MPI_Recv(&ready,1,MPI_INT,
myid-1,myid-1,
MPI_COMM_WORLD,&status);
PrintFile_res("match_result",match,
textlen,myid*textlen-patlen+1, myid);
if(myid!=numprocs-1)
MPI_Send(&ready,1,MPI_INT,
myid+1,myid,
MPI_COMM_WORLD);
} free(T); free(W); free(nextval);
MPI_Finalize();
}
21
3. 运行实例
编译:gcc gen_ped.c –o gen_ped
mpicc kmp.c –o kmp
运行:首先运行gen_ped生成模式串,gen_ped Strlen Pedlen Seed Pattern_File。其中Strlen代表模式串的长度,Pedlen代表模式串的最小周期长度,Seed是随机函数使用的种子数,Pattern_File是生成数据存储的文件,这里在kmp.c中固定指定的文件名为pattern.dat。本例中使用了如下的参数。
gen_ped 3 2 1 pattern.dat
之后可以使用命令 mpirun –np SIZE kmp m n来运行该串匹配程序,其中SIZE是所使用的处理器个数,m表示文本串长度,n为文本串的周期长度。本实例中使用了SIZE=3个处理器,m=18,n=3。
mpirun –np 3 kmp 18 2
运行结果:
存储于pattern.dat中的模式串为:qmq
存储于match_result中的匹配结果为:
The Text on node 0 is asasas .
The Text on node 1 is qmqmqm .
The Text on node 2 is ypypyp .
This is the match result on node 0
(0) -
(1) -
(2) -
(3) -
This is the match result on node 1
(4) -
(5) -
(6) +
(7) -
(8) +
(9) -
This is the match result on node 2
(10) -
(11) -
(12) -
(13) -
(14) -
(15) -
说明:该运行实例中,令文本串长度为18,随机产生的文本串为asasasqmqmqmypypyp,分布在3个节点上;模式串长度为3,随机产生的模式串为qmq。最后,节点1上得到两个匹配位置,由+表示出来。
22