两个矩阵相乘的行列划分并行算法
摘要:给定两个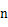 阶矩阵
阶矩阵 与
与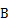 ,矩阵乘法是指计算
,矩阵乘法是指计算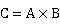 ,现在对两个矩阵乘法进行串行和并行的实验和分析
,现在对两个矩阵乘法进行串行和并行的实验和分析
关键词:并行算法;矩阵相乘;
算法原理:
1、串行算法
通常的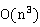 矩阵乘矩阵的串行计算过程如算法1所示,此外为计算矩阵相乘,还可以有对3层循环采用其他嵌套形式的串行算法。
矩阵乘矩阵的串行计算过程如算法1所示,此外为计算矩阵相乘,还可以有对3层循环采用其他嵌套形式的串行算法。
算法1: 稠密矩阵相乘的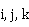 形式串行算法
形式串行算法
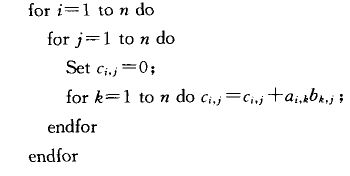
2、并行算法
两个矩阵相乘的行列划分并行算法假设一共有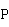 个进程,将矩阵
个进程,将矩阵 按行分成个块,将矩阵
按行分成个块,将矩阵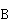 按列分成个块:
按列分成个块:
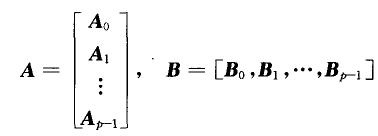
每块包含连续若干个行.为使得负载平衡,应使得每块中的行数尽量相等.将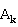 与
与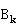 分别存储在进程
分别存储在进程 的
的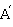 与
与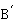 中.将
中.将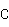 分为
分为 块,且将
块,且将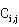 存储在
存储在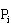 的
的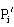 中,如算法2
中,如算法2
算法2 稠密矩阵乘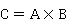 的行列划分并行算法
的行列划分并行算法
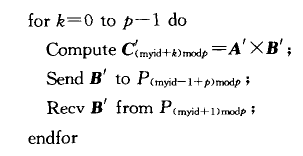
实验由MPICH2在VS2010上进行并行环境的配置来完成,单机情况下用进程数的个数模拟多处理器。
在实验中算法由以下几个函数实现:
void readData();此函数被rankID为0的进程调用,负责从dataIn.txt文件中A[M,K],B[P,N]两个相乘矩阵的数据,并为结果矩阵C[M,N]分配空间。其中C[N,N]=A[M,K]*B[P,N]。
int gcd(int M,int N,int group_size) 此函数用来返回两个整数的不大于group_size的最大公因子,即算法所用到的处理器个数,为了保证行划分和列划分可以平均的划分,通过求M,N不大于group_size的最大公因子来确定实际用到的处理器p。
void printResult();此函数被rankID为0的进程调用,用来将A,B,C矩阵打印输出给用户,并输出用于分发数据和并行计算的时间。
int main(int argc, char **argv) ;程序的主函数。
算法分析(可扩展性分析):
在LogP模型上,算法2并行执行时间为:
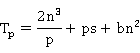
由此可知,并行效率为:
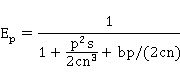
因此,等效率函数为: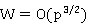
算法的MPI程序:
// matrix.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "stdio.h"
#include "stdlib.h"
#include "mpi.h"
#include<mpicxx.h>
#define intsize sizeof(int)
#define floatsize sizeof(float)
#define charsize sizeof(char)
#define A(x,y) A[x*K+y]
#define B(x,y) B[x*N+y]
#define C(x,y) C[x*N+y]
#define a(x,y) a[x*K+y]
#define b(x,y) b[x*n+y]
#define buffer(x,y) buffer[x*n+y] /* 此宏用来简化对标号为奇数的处理器内的缓冲空间的访问 */
#define c(l,x,y) c[x*N+y+l*n]
float *a,*b,*c,*buffer;
int s;
float *A,*B,*C; /* A[M,K],B[P,N].正确的情况下K应该等于P,否则无法进行矩阵相乘 */
int M,N,K,P ;
int m,n;
int myid;
int p; /* 保存工作站集群中处理器数目,也即通信子大小 */
FILE *dataFile; /* 用于读取输入文件内容和将计算结果输出到结果文件的临时文件指针 */
MPI_Status status;
double time1;
double starttime,endtime;
/*
* 函数名: readData
* 功能: 此函数被rankID为0的进程调用,负责从dataIn.txt文件中读入
* A[M,K],B[P,N]两个相乘矩阵的数据,并为结果矩阵C[M,N]分配空间。
* 其中C[N,N]=A[M,K]*B[P,N]
* 输入: 无
* 返回值:无
*/
void readData()
{
int i,j;
starttime = MPI_Wtime();
dataFile=fopen("dataIn.txt","r");
fscanf(dataFile,"%d%d", &M, &K); /* 读取矩阵A的行,列数M,K */
A=(float *)malloc(floatsize*M*K); /* 为矩阵A分配空间 */
for(i = 0; i < M; i++) /* 读入矩阵A的各元素 */
{
for(j = 0; j < K; j++)
{
fscanf(dataFile,"%f", A+i*K+j);
}
}
fscanf(dataFile,"%d%d", &P, &N); /* 读取矩阵B的行,列数P,N */
if (K!=P) /* K应该等于P,否则矩阵无法相乘 */
{
printf("the input is wrong\n");
exit(1);
}
B=(float *)malloc(floatsize*K*N); /* 为矩阵B分配空间 */
for(i = 0; i < K; i++) /* 从文件中读入矩阵B的各元素 */
{
for(j = 0; j < N; j++)
{
fscanf(dataFile,"%f", B+i*N+j);
}
}
fclose(dataFile);
printf("Input of file \"dataIn.txt\"\n");
printf("%d\t %d\n",M, K); /* 输出A矩阵的维数 */
for(i=0;i<M;i++) /* 输出A矩阵的数据 */
{
for(j=0;j<K;j++) printf("%f\t",A(i,j));
printf("\n");
}
printf("%d\t %d\n",K, N); /* 输出B矩阵的维数 */
for(i=0;i<K;i++) /* 输出B矩阵的数据 */
{
for(j=0;j<N;j++) printf("%f\t",B(i,j));
printf("\n");
}
C=(float *)malloc(floatsize*M*N); /* 为结果矩阵C[M,N]分配空间 */
}
/*
* 函数名: gcd
* 功能: 此函数用来返回两个整数的不大于group_size的最大公因子
* 输入: M,N:要求最大公因数的两个整数
* group_size所求公因子必须小于此参数,此参数代表用户指定的通信子大小
* 返回值:M和N的不大于group_size的最大公因子
*/
int gcd(int M,int N,int group_size)
{
int i;
for(i=M; i>0; i--)
{
if((M%i==0)&&(N%i==0)&&(i<=group_size))
return i;
}
return 1;
}
/*
* 函数名: printResult
* 功能:此函数被rankID为0的进程调用,用来将A,B,C矩阵打印输出给用户,
* 并输出用于分发数据和并行计算的时间
* 输入:无
* 返回值:无
*/
void printResult()
{
int i,j;
printf("\nOutput of Matrix C = AB\n");
for(i=0;i<M;i++) /* 输出C矩阵的结果数据 */
{
for(j=0;j<N;j++) printf("%f\t",C(i,j));
printf("\n");
}
endtime=MPI_Wtime();
printf("\n");
printf("Whole running time = %f seconds\n",endtime-starttime);
printf("Distribute data time = %f seconds\n",time1-starttime);
printf("Parallel compute time = %f seconds\n",endtime-time1);
}
/*
* 函数名: main
* 功能:程序的主函数
* 输入:argc为命令行参数个数;
* argv为每个命令行参数组成的字符串数组。
* 输出:返回0代表程序正常结束;其它值表明程序出错。
*/
int main(int argc, char **argv)
{
int i,j,k,l,group_size,mp1,mm1;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&group_size);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
p=group_size;
//下面一段程序负责从dataIn.txt文件中读入A[M,K],B[P,N]两个相乘矩阵的数据,
//并为结果矩阵C[M,N]分配空间。C[N,N]=A[M,K]*B[P,N]
//注意这段程序只有编号为0的处理器才执行此步操作
if(myid==0)
{
readData();
}
if (myid==0) /* 由编号为0的进程将A,B两矩阵的行列维数M,K,N发送给所有其他进程 */
for(i=1;i<p;i++)
{
MPI_Send(&M,1,MPI_INT,i,i,MPI_COMM_WORLD);
MPI_Send(&K,1,MPI_INT,i,i,MPI_COMM_WORLD);
MPI_Send(&N,1,MPI_INT,i,i,MPI_COMM_WORLD);
}
else /* 编号非0的进程负责接收A,B两矩阵的行列维数M,K,N */
{
MPI_Recv(&M,1,MPI_INT,0,myid,MPI_COMM_WORLD,&status);
MPI_Recv(&K,1,MPI_INT,0,myid,MPI_COMM_WORLD,&status);
MPI_Recv(&N,1,MPI_INT,0,myid,MPI_COMM_WORLD,&status);
}
p=gcd(M,N,group_size);
m=M/p; /* m代表将矩阵按行分块后每块的行数 */
n=N/p; /* m代表将矩阵按列分块后每块的列数 */
if(myid<p)
{
a=(float *)malloc(floatsize*m*K); /* a[m,K]用来存储本处理器拥有的矩阵A的行块 */
b=(float *)malloc(floatsize*K*n); /* b[K,n]用来存储此时处理器拥有的矩阵B的列块 */
c=(float *)malloc(floatsize*m*N); /* c[m,N]用来存储本处理器计算p-1次得到所有结果 */
if (myid%2!=0) /* 为标号为奇数的处理器分配发送缓冲空间 */
buffer=(float *)malloc(K*n*floatsize);
if (a==NULL||b==NULL||c==NULL) /* 如果分配空间出错,则打印出错信息 */
printf("Allocate space for a,b or c fail!");
if (myid==0) /* 标号为0的处理器将应该它拥有的矩阵A,B的元素读入自己的a,b中 */
{
for (i=0;i<m;i++)
for (j=0;j<K;j++)
a(i,j)=A(i,j);
for (i=0;i<K;i++)
for (j=0;j<n;j++)
b(i,j)=B(i,j);
}
if (myid==0) /* 标号为0的处理器将其他处理器的初始数据分别发给各处理器 */
{
for (i=1;i<p;i++)
{
MPI_Send(&A(m*i,0),K*m,MPI_FLOAT,i,i,MPI_COMM_WORLD);
for (j=0;j<K;j++)
MPI_Send(&B(j,n*i),n,MPI_FLOAT,i,i,MPI_COMM_WORLD);
}
free(A);
free(B); /* 至此,A,B两矩阵的数据已经完全被分散到各处理器。释放A,B所占空间 */
}
else /* 标号非0的处理器从0处理器接受各自的初始矩阵数据 */
{
MPI_Recv(a,K*m,MPI_FLOAT,0,myid,MPI_COMM_WORLD,&status);
for (j=0;j<K;j++)
MPI_Recv(&b(j,0),n,MPI_FLOAT,0,myid,MPI_COMM_WORLD,&status);
}
if (myid==0)
time1=MPI_Wtime(); /* 标号为0的处理器记录开始矩阵相乘计算的时间 */
for (i=0;i<p;i++) /* 一共进行p轮计算 */
{
l=(i+myid)%p;
for (k=0;k<m;k++)
for (j=0;j<n;j++)
for (c(l,k,j)=0,s=0;s<K;s++)
c(l,k,j)+=a(k,s)*b(s,j);
mm1=(p+myid-1)%p; /* 计算本进程的前一个进程的标号 */
mp1=(myid+1)%p; /* 计算本进程的后一个进程的标号 */
if (i!=p-1)
{
if(myid%2==0) /* 偶数号处理器先发送后接收 */
{
MPI_Send(b,K*n,MPI_FLOAT,mm1,mm1,MPI_COMM_WORLD);
MPI_Recv(b,K*n,MPI_FLOAT,mp1,myid,MPI_COMM_WORLD,&status);
}
else /*奇数号处理器先将B的列块存于缓冲区buffer中,然后接收编号在其后面的
处理器所发送的B的列块,最后再将缓冲区中原矩阵B的列块发送给编号
在其前面的处理器 */
{
for(k=0;k<K;k++)
for(j=0;j<n;j++)
buffer(k,j)=b(k,j);
MPI_Recv(b,K*n,MPI_FLOAT,mp1,myid,MPI_COMM_WORLD,&status);
MPI_Send(buffer,K*n,MPI_FLOAT,mm1,mm1,MPI_COMM_WORLD);
}
}
}
if (myid==0) /* 标号为0的进程直接将计算结果保存到结果矩阵C中 */
for(i=0;i<m;i++)
for(j=0;j<N;j++)
C(i,j)=*(c+i*N+j);
if (myid!=0) /* 标号非0的进程则要把计算结果发送到标号为0的处理器中去 */
MPI_Send(c,m*N,MPI_FLOAT,0,myid,MPI_COMM_WORLD);
else /* 标号为0的进程负责接收其他进程的计算结果并保存到结果矩阵C中 */
{
for(k=1;k<p;k++)
{
MPI_Recv(c,m*N,MPI_FLOAT,k,k,MPI_COMM_WORLD,&status);
for(i=0;i<m;i++)
for(j=0;j<N;j++)
C((k*m+i),j)=*(c+i*N+j);
}
}
if(myid==0) /* 0号处理器负责将A,B,C矩阵打印输出给用户,并输出用于分发数据和并行计算的时间 */
printResult();
}
MPI_Finalize();
if(myid<p) /* 释放所有临时分配空间 */
{
free(a);
free(b);
free(c);
if(myid==0) /* 只有0号进程要释放C */
free(C);
if(myid%2!=0) /* 只有奇数号进程要释放buffer */
free(buffer);
}
printf("%d",p);
getchar();
return (0);
}
算例,结果及分析:
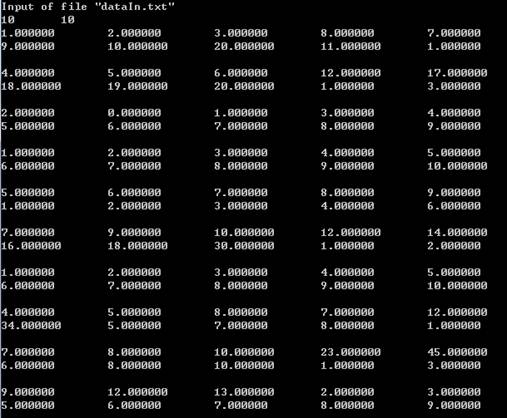
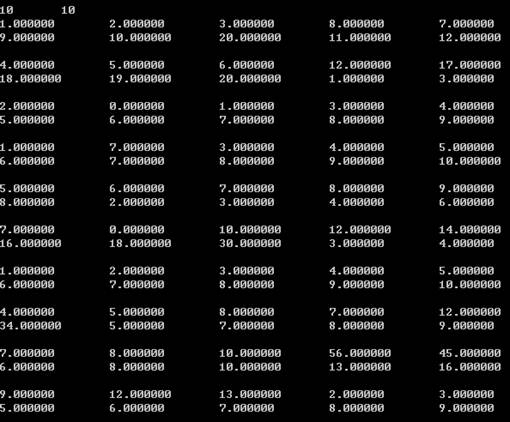
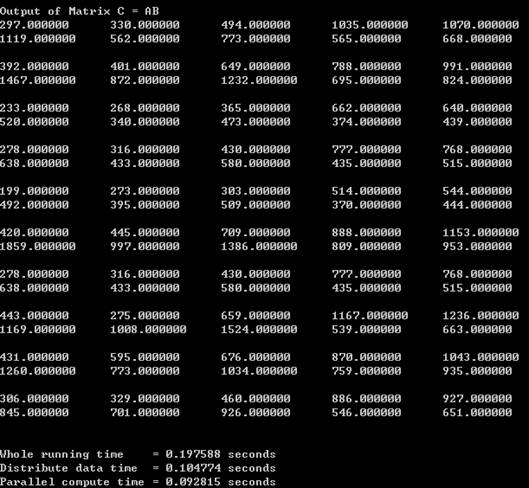
上面的dataIn.txt是两个10乘以10的矩阵,总的时间是0.197588秒,可以看到主要的时间用来通讯和分发数据,并行计算的时间其实较短。
换一个算例,即10乘以20矩阵乘以20乘以10 的矩阵,下面是运行时间:

数据量增大,但是并行时间并没有大量增加,而是在通讯时间上面消耗更多时间,跟算法可扩展的等效率分析一致。
参考文献
· [1] 都志辉,《高性能计算之并行编程技术—— MPI并行程序设计》
· [2] 《数值并行算法与软件》,科学出版社, 20##-08-01