广东技术师范学院实验报告


实验 (四) 项目名称:并行程序设计(3)
一、实验目的
在一个局域网中建立能够互相通信的两台计算机,实现两台计算机并行运算。
二、实验内容:
要求:修改代码cpi.c,将任务分配改为按块分配:假设共有P个进程,将n个计算间顺序分成P块,每个进程负责一块的计算,注意当n不是P的倍数时应该尽量保持负载平衡。程序代码cpi.c参考如下:
#include "mpi.h"
#include <stdio.h>
double f( double a ) { return (4.0 / (1.0 + a*a)); }
int main( int argc, char *argv[])
{
int n, myid, numprocs, i, namelen;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
double startwtime, endwtime;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
MPI_Get_processor_name(processor_name,&namelen);
fprintf(stderr,"Process %d on %s
", myid, processor_name);
if (myid == 0) {
n=10000;
startwtime = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid; i < n; i += numprocs) {
x = h * ((double)i + 0.5);
sum += f(x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0) {
endwtime = MPI_Wtime();
printf("pi is approximately %.16f, error is %.16f
", pi, pi - PI25DT);
printf("wall clock time = %f
", endwtime-startwtime);
}
MPI_Finalize();
return 0;
}
实验源程序代码:
#include "mpi.h"
#include <stdio.h>
#include <iostream.h>
#include <fstream.h>
void main(int argc, char *argv[])
{
int rank, size;
const int MAXX = 40;
const int MAXY = 40;
const int MAXPROCESSOR = 64;
float Data[MAXY][MAXY];
int ArraySize[2];
int i, j, k;
double startwtime, endwtime;
int namelen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Status Status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Get_processor_name(processor_name, &namelen);
cout<<"线程"<<"在运行主机"<<processor_name<<endl;
if(rank == 0)
{
ifstream in("input.txt");
in>>ArraySize[0]>>ArraySize[1];
for(i = 0; i < ArraySize[0]; i++)
for(j = 0; j < ArraySize[1]; j++)
in>>Data[i][j];
cout<<"二维数组如下:"<<endl;
for(i = 0; i < ArraySize[0]; i++)
{
for(j =0; j < ArraySize[1]; j++)
cout<<Data[i][j]<<" ";
cout<<endl;
}
}
MPI_Bcast(ArraySize, 2, MPI_INT, 0, MPI_COMM_WORLD);
int AverageLineNumber, HeavyProcessorNumber, MyLineNumber;
int CurrentLine, StartLine, SendSize;
float SendArray[MAXX*MAXY];
AverageLineNumber = ArraySize[0]/size;
HeavyProcessorNumber = ArraySize[0]%size;
if(rank < HeavyProcessorNumber)
MyLineNumber = AverageLineNumber + 1;
else
MyLineNumber = AverageLineNumber;
if(rank == 0)
{
CurrentLine = ArraySize[0];
for(i = size - 1; i >= 0; i--)
{
SendSize = 0;
if(i == 0)
startwtime = MPI_Wtime();
if(i < HeavyProcessorNumber)
StartLine = CurrentLine - AverageLineNumber;
else
StartLine = CurrentLine - AverageLineNumber + 1;
for(j = StartLine - 1; j < CurrentLine; j++)
for(k = 0; k < ArraySize[1]; k++)
SendArray[SendSize++] = Data[j][k];
if(i != 0)
MPI_Send(SendArray, SendSize, MPI_FLOAT, i, 10, MPI_COMM_WORLD);
CurrentLine = StartLine - 1;
}
}
else
MPI_Recv(SendArray, MyLineNumber * ArraySize[1], MPI_FLOAT, 0, 10, MPI_COMM_WORLD, &Status);
float *Sum = new(float);
*Sum = 0;
for(i = 0; i < MyLineNumber * ArraySize[1]; i++)
*Sum += SendArray[i];
cout<<"在线程"<<rank<<"计算的结果为:"<<*Sum<<endl;
float ALLSum[64];
MPI_Gather(Sum, 1, MPI_FLOAT, ALLSum, 1, MPI_FLOAT, 0, MPI_COMM_WORLD);
if(rank == 0)
{
*Sum = 0;
for(i = 0; i < size; i++)
*Sum += ALLSum[i];
cout<<"二维数据所有元素和为:"<<*Sum<<endl;
endwtime = MPI_Wtime();
printf("运行时间为:%f\n", endwtime-startwtime);
}
MPI_Finalize();
}
单机运行:
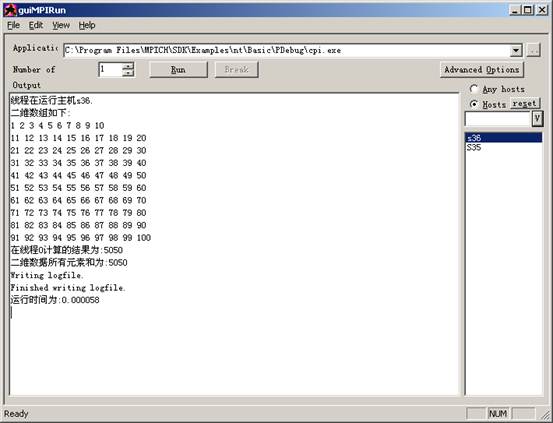
多机运行:
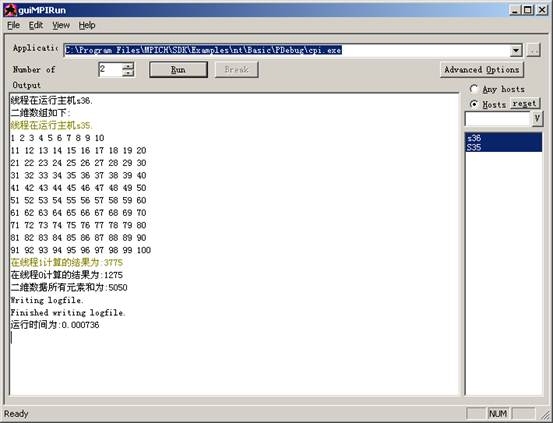
三、实验分析与结论
经过多次在机房与同学互相讨论,最终解决问题,成功实现多机按块执行任务。。
第二篇:并行计算实验指导(9)免费版
支持免费共享
10 快速傅氏变换和离散小波变换
长期以来,快速傅氏变换(Fast Fourier Transform)和离散小波变换(Discrete Wavelet Transform)在数字信号处理、石油勘探、地震预报、医学断层诊断、编码理论、量子物理及概率论等领域中都得到了广泛的应用。各种快速傅氏变换(FFT)和离散小波变换(DWT)算法不断出现,成为数值代数方面最活跃的一个研究领域,而其意义远远超过了算法研究的范围,进而为诸多科技领域的研究打开了一个崭新的局面。本章分别对FFT和DWT的基本算法作了简单介绍,若需在此方面做进一步研究,可参考文献[2]。
2.1 快速傅里叶变换FFT
离散傅里叶变换是20世纪60年代是计算复杂性研究的主要里程碑之一,19xx年Cooley和Tukey所研究的计算离散傅里叶变换(Discrete Fourier Test)的快速傅氏变换(FFT)将计算量从О(n2)下降至О(nlogn),推进了FFT更深层、更广法的研究与应用。FFT算法有很多版本,但大体上可分为两类:迭代法和递归法,本节仅讨论迭代法,递归法可参见文献[1]、[2]。
2.1.1 串行FFT迭代算法
假定a[0],a[1], ?,a[n-1] 为一个有限长的输入序列,b[0], b[1], ?,b[n-1]为离散傅里叶变换的结果序列,则有:b[k]??a[k]Wnkm(k?0,1,2,...,n?1),其中 Wn?e
m?0n?12?in,实际上,上式可
写成矩阵W和向量a的乘积形式:
?b0??w0
?b??w0?1???b2???w0????????
?bn?1??w0?????a0???a???1???a2? w2w4?w2(n?1)?????????????w(n?1)w2(n?1)?w(n?1)(n?1)??an?1??w0w1w0?w0w2?wn?1
一般的n阶矩阵和n维向量相乘,计算时间复杂度为n2,但由于W是一种特殊矩阵,故可以降低计算量。FFT的计算流图如图 2.1所示,其串行算法如下:
算法22.1 单处理器上的FFT迭代算法
输入:a=(a0,a1, ?,an-1)
输出:b=(b0,b1, ?,bn-1)
Begin
(1)for k=0 to n-1 do
ck=ak
end for
(2)for h=logn-1 downto 0 do
(2.1) p=2h (2.2) q=n/p
(2.3) z=wq/2
(2.4) for k=0 to n-1 do
if (k mod p=k mod2p) then (i)ck = ck + ck +p
(ii)ck +p=( ck - ck +p)z k modp /* ck不用(i)计算的新值 */ end if end for
end for
(3)for k=1 to n-1 do
br(k) = ck /* r(k)为k的位反 */ end for End
a0a1a2a3a4a5a6a7
b0b4b2b6b1b5b3b
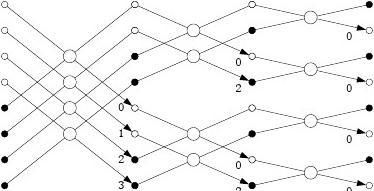
7
图 2.1 n=4时的FFT蝶式变换图
显然, FFT算法的计算复杂度为O(nlogn)。
2.1.2 并行FFT算法
设P为处理器的个数,一种并行FFT实现时是将n维向量a划分成p个连续的m维子向量,这里m??n/p?,第i个子向量中下标为i×m, ?, (i+1)×m-1,其元素被分配至第i号处理器(i=0,1, ?, p-1)。由图 2.1可以看到,FFT算法由logn步构成,依次以2logn-1、2logn-2、…、2、1为下标跨度做蝶式计算,我们称下标跨度为2h的计算为第h步(h=logn-1, logn-2, …, 1, 0)。并行计算可分两阶段执行:第一阶段,第logn-1步至第logm步,由于下标跨度h≥ m,各处理器之间需要通信;第二阶段,第logm-1步至第0步各处理器之间不需要通信。具体并行算法框架描述如下:
算法22.2 FFT并行算法 输入:a=(a0,a1, ?,an-1)
输出:b=(b0,b1, ?,bn-1)
Begin
对所有处理器my_rank(my_rank=0,?, p-1)同时执行如下的算法:
(1)for h=logp-1 downto 0 do
/* 第一阶段,第logn-1步至第logm步各处理器之间需要通信*/
(1.1) t=2i, ,l=2(i+logm) ,q=n/l , z=wq/2 , j= j+1 ,v=2j /*开始j=0*/
(1.2)if ((my_rank mod t)=(my_rank mod 2t)) then
/*本处理器的数据作为变换的前项数据*/
(i) tt= my_rank+p/v
(ii)接收由tt 号处理器发来的数据块,并将接收的数据块存于
c[my_rank*m+n/v]到c[my_rank*m+n/v+m]之中
(iii)for k=0 to m-1 do
c[k]=c[k]+c[k+n/v]
c[k+n/v]=( c[k]- c[k+n/v])*z(my_rank*m+k) mod l
end for
(iv)将存于c[my_rank*m+n/v]到c[my_rank*m+n/v+m]之中的数据块发送 到tt 号处理器
else /*本处理器的数据作为变换的后项数据*/
(v)将存于之中的数据块发送到my_rank-p/v 号处理器
(vi)接收由my_rank-p/v 号处理器发来的数据块存于c中
end if
end for
(2)for i=logm-1 downto 0 do /*第二阶段,第logm-1步至第0步各处理器之间
不需要通信*/
(2.1) l=2i ,q=n/l , z=wq/2
(2.2)for k=0 to m-1 do
if ((k mod l)=(k mod 2l)) then
c[k]=c[k]+c[k+l]
c[k+l]=( c[k]- c[k+l])*z(my_rank*m+k) mod l
end if
end for
end for
End
由于各处理器对其局部存储器中的m维子向量做变换计算,计算时间为mlogn;点对点通信2logp次,每次通信量为m,通信时间为2(ts?mtw)logp,因此快速傅里叶变换的并行计算时间为Tp?mlogn?2(ts?mtw)logp。
MPI源程序请参见章末附录。
2.2 离散小波变换DWT
2.2.1 离散小波变换DWT及其串行算法
先对一维小波变换作一简单介绍。设f(x)为一维输入信号,记?jk(x)?2?j/2?(2?jx?k),?jk(x)?2?j/2?(2?jx?k),这里?(x)与?(x)分别称为定标函数与子波函数,{?jk(x)}与
记P0f=f,在第j级上的一维离散小波变换DWT(Discrete {?jk(x)}为二个正交基函数的集合。
Wavelet Transform)通过正交投影Pjf与Qjf将Pj-1f分解为:
Pj?1f?Pjf?Qjf??ckj?jk??dkj?
kkjk
?1jj?1j其中:ckj??h(n)c2jk?n,dk??g(n)c2k?n (j?1,2,...,L,k?0,1,...,N2?1),这里,{h(n)}
n?0n?0p?1p?1
与{g(n)}分别为低通与高通权系数,它们由基函数{?jk(x)}与{?jk(x)}来确定,p为权系数
0的长度。{Cn}为信号的输入数据,N为输入信号的长度,L为所需的级数。由上式可见,每级一维DWT与一维卷积计算很相似。所不同的是:在DWT中,输出数据下标增加1时,权系数在输入数据的对应点下标增加2,这称为“间隔取样”。
算法22.3 一维离散小波变换串行算法
输入:c0=d0(c00, c10,…, cN-10)
h=(h0, h1,…, hL-1)
g=(g0, g1,…, gL-1)
输出:cij , dij (i=0, 1,…, N/2j-1, j≥0)
Begin
(1)j=0, n=N
(2)While (n≥1) do
(2.1)for i=0 to n-1 do
(2.1.1)cij+1=0, dij+1=0
(2.1.2)for k=0 to L-1 do
jcij?1? cij?1?hk c(k?2i) mod n,dij?1?dij?1?gkd(jk?2i)modn end for
end for
(2.2)j=j+1, n=n/2
end while
End
显然,算法22.3的时间复杂度为O(N*L)。
在实际应用中,很多情况下采用紧支集小波(Compactly Supported Wavelets),这时相
应的尺度系数和小波系数都是有限长度的,不失一般性设尺度系数只有有限个非零值:h1,?,hN,N为偶数,同样取小波使其只有有限个非零值:g1,?,gN。为简单起见,设尺度系
0数与小波函数都是实数。对有限长度的输入数据序列:cn?xn,n?1,2,?,M(其余点的值都
看成0),它的离散小波变换为:
ckj?1??cnjhn?2k
n?Z
dkj?1??cnjgn?2k
n?Z
j?0,1,?,J?1
其中J为实际中要求分解的步数,最多不超过log2M,其逆变换为
j?1cn?j?ckhn?2kk?Z?j?ckhn?2kk?Z
j?J,?,1
注意到尺度系数和输入系列都是有限长度的序列,上述和实际上都只有有限项。若完全按照上述公式计算,在经过J步分解后,所得到的J+1个序列dkj,j?0,1,?,J?1和ck的非零项的个数之和一般要大于M,究竟这个项目增加到了多少?下面来分析一下上述计算过程。
j=0时计算过程为 j
c1k??xnhn?2k
n?1
M
1kMd??xngn?2k
n?1
1NM?不难看出,ck的非零值范围为:k???1,?,?1,0,?,??1,即有?22???
k??N?M??M?N?1?1个非零值。dk的非零值范围相同。继续往下分解时,非零项出?1??????22?2???
现的规律相似。分解多步后非零项的个数可能比输入序列的长度增加较多。例如,若输入序
1234列长度为100,N=4,则dk有51项非零,dk有27项非零,dk有15项非零,dk有9项非
56零,dk有6项非零,dk有4项非零,ck有4项非零。这样分解到6步后得到的序列的非6
零项个数的总和为116,超过了输入序列的长度。在数据压缩等应用中,希望总的长度基本不增加,这样可以提高压缩比、减少存储量并减少实现的难度。
可以采用稍微改变计算公式的方法,使输出序列的非零项总和基本上和输入序列的非零项数相等,并且可以完全重构。这种方法也相当于把输入序列进行延长(增加非零项),因而称为延拓法。
只需考虑一步分解的情形,下面考虑第一步分解(j=1)。将输入序列作延拓,若M为偶数,直接将其按M为周期延拓;若M为奇数,首先令xM?1?0。然后按M+1为周期延拓。作了这种延拓后再按前述公式计算,相应的变换矩阵已不再是H和G,事实上这时的变换
矩阵类似于循环矩阵。例如,当M=8,N=4时矩阵H变为:
h3h100h3
h4h200h4
0h3h100
0h4h200
00h3h10
00h4h20
h100h3h1
h200 h4h2
当M=7,N=4时矩阵H变为:
h3h100h3
h4h200h4
0h3h100
0h4h200
00h3h10
00h4h20
h100h3h1
从上述的矩阵表示可以看出,两种情况下的矩阵内都有完全相同的行,这说明作了重复计算,因而从矩阵中去掉重复的那一行不会减少任何信息量,也就是说,这时我们可以对矩阵进行截短(即去掉一行),使得所得计算结果仍然可以完全恢复原输入信号。当M=8,N=4时截短后的矩阵为:
?h3?hH??1
?0??0?
h4
h200
0h3h10
0h4h20
00h3h1
00h4h2
h100h3
h2??0? 0??h4??
当M=7,N=4时截短后的矩阵为:
?h3
?hH??1
?0??0?
h4
h200
0h3h10
0h4h20
00h3h1
00h4h2
h100h3
??? ????
?M?
这时的矩阵都只有??行。分解过程成为:
?2?
C1?HC0 D1?GC0
?M?
向量C1 和D1都只有??个元素。重构过程为:
?2?
C0?H*C1?G*D1
可以完全重构。矩阵H,G有等式
H*H+G*G=I
?M?
一般情况下,按上述方式保留矩阵的??行,可以完全恢复原信号。
?2?
这种方法的优点是最后的序列的非0元素的个数基本上和输入序列的非0元素个数相同,特别是若输入序列长度为2的幂,则完全相同,而且可以完全重构输入信号。其代价是得到的变换系数Dj中的一些元素已不再是输入序列的离散小波变换系数,对某些应用可能是不适合的,但在数据压缩等应用领域,这种方法是可行的。
2.2.2 离散小波变换并行算法
下设输入序列长度N=2t,不失一般性设尺度系数只有有限个非零值:h0,?,hL-1,L为偶数,同样取小波使其只有有限个非零值:g0,?,gL-1。为简单起见,我们采用的延拓
0?x,(n?0,1,?,N?1)按周期N延长,使他成为无限长度的方法计算。即将有限尺度的序列cnn序列。这时变换公式也称为周期小波变换。变换公式为:
c
j?1
k
??chn?2k??hncj
jnn?Z
n?0
L?1
n?2k
dkj?1??gndj
n?0
L?1
n?2k
j?0,1,?,J?1
其中<n+2k>表示n+2k对于模N/2j的最小非负剩余。注意这时ckj和dkj是周期为N/2j的周期序列。其逆变换为
cnj?1?
k?Z
?ckjhn?2k??ckjgn?2k
k?Z
j?J,?,1
j在n=2k附近的值从变换公式中可以看出,计算输出点ckj?1和dkj?1,需要输入序列cn(一
j
般而言,L远远小于输入序列的长度)。设处理器台数为p,将输入数据cn(n?0,1,?,N/2j?1)
按块分配给p台处理器,处理器i得到数据cnj(n?i和dnj?1(n?i
NN
,?,(i?1)?1),让处理器i负责cnj?1jjP2P2
NN
,?,(i?1)?1)的计算,则不难看出,处理器i 基本上只要用到局部数据,P2j?1P2j?1
只有L/2个点的计算要用到处理器i+1中的数据,这时做一步并行数据发送:将处理器i+1中前L-1个数据发送给处理器i,则各处理器的计算不再需要数据交换,关于本算法其它描述可参见文献[1]。
算法22.4 离散小波变换并行算法
输入:hi(i=0,?, L-1), gi(i=0,?, L-1), ci0(i=0,?, N-1) 输出:cik (i=0,?, N/2k-1,k>0)
Begin
对所有处理器my_rank(my_rank=0,?, p-1)同时执行如下的算法: (1)j=0;
(2)while (j<r) do
(2.1)将数据cnj(n?0,1,?,N/2j?1)按块分配给p台处理器 (2.2)将处理器i+1中前L-1个数据发送给处理器i (2.3)处理器i负责cn
j?1
和dn(n?i
j?1
NN
,?,(i?1)?1)的计算 j?1j?1
p2p2
(2.4)j=j+1 end while
End
这里每一步分解后数据cnj?1和dnj?1已经是按块存储在P台处理器上,因此算法第一步中的数据分配除了j=0时需要数据传送外,其余各步不需要数据传送(数据已经到位)。因此,按LogP模型,算法的总的通信时间为:2(Lmax(o,g)+l),远小于计算时间O(N)。
MPI源程序请参见所附光盘。
2.3 小结
本章主要讨论一维FFT和DWT的简单串、并行算法,二维FFT和DWT在光学、地震以及图象信号处理等方面起着重要的作用。限于篇幅,此处不再予以讨论。同样,FFT和DWT的并行算法的更为详尽描述可参见文献[2]和文献[3],专门介绍快速傅氏变换和卷积算法的著作可参见[4]。另外,二维小波变换的并行计算及相关算法可参见文献[5],LogP模型可参考文献[3]。
参考文献
[1]. [2]. [3]. [4].
王能超 著.数值算法设计.华中理工大学出版社,1988.9
陈国良 编著.并行计算——结构·算法·编程.高等教育出版社,1999.10 陈国良 编著.并行算法设计与分析(修订版).高等教育出版社,2002.11
Nussbaumer H J. Fast Fourier Transform and Convolution Algorithms.2nded. Springer- Verlag,1982
[5]. 陈崚.二维正交子波变换的VLSI并行计算.电子学报,1995,23(02):95-97
附录 FFT并行算法的MPI源程序
1. 源程序fft.c
#include <stdio.h> #include <stdlib.h> #include <complex.h> #include <math.h> #include "mpi.h"
#define MAX_PROCESSOR_NUM 12 #define MAX_N #define PI
50
3.141592653
void shuffle(complex<double>* f, int beginPos,
int endPos);
#define Q_TAG 101 #define R_TAG 102 #define S_TAG 103 #define S_TAG2 104
void evaluate(complex<double>* f, int beginPos, int endPos, const complex<double>* x,
complex<double> *y, int leftPos, int rightPos, int totalLength);
#define EPS 10E-8 #define V_TAG 99 #define P_TAG 100
void print(const complex<double>* f,
int fLength);
void readDoubleComplex(FILE *f,
complex<double> &z);
int main(int argc, char *argv[]) {
}
readDoubleComplex(fin, variableNum); if ((variableNum < 1)||(variableNum >
MAX_N))
puts("variableNum out of range!");
{ exit(-1);
complex<double> p[MAX_N], q[MAX_N], s[2*MAX_N], r[2*MAX_N]; complex<double> w[2*MAX_N]; complex<double> temp; int variableNum; MPI_Status status; int rank, size; int i, j, k, n; int wLength; int everageLength; int moreLength; int startPos; int stopPos; FILE *fin;
MPI_Init(&argc, &argv);
MPI_Get_rank(MPI_COMM_WORLD,
&rank);
MPI_Get_size(MPI_COMM_WORLD,
&size);
if(rank == 0) {
fin = fopen("dataIn.txt", "r"); if (fin == NULL) {
puts("Not find input data file");
puts("Please create a file
\"dataIn.txt\"");
puts("<example for dataIn.txt> "); puts("2"); puts("1.0 2");
puts("2.0 -1");
exit(-1);
} else {
readDoubleComplex(fin, p[i]); for(i = 0; i < variableNum; i ++) readDoubleComplex(fin, q[i]); for(i = 1; i < size; i ++)
MPI_Send(&variableNum,1,
MPI_INT,i, V_TAG, MPI_COMM_WORLD);
MPI_Send(p,variableNum,
MPI_DOUBLE_COMPLEX,i, P_TAG,
PI_COMM_WORLD);
MPI_Send(q,variableNum, MPI_DOUBLE_COMPLEX,i, Q_TAG,
MPI_COMM_WORLD);
} MPI_Recv(&variableNum,1,MPI_INT,0, V_TAG,MPI_COMM_WORLD, &status);
MPI_Recv(p,variableNum,
} for(i = 0; i < variableNum; i ++) puts("Read from data file \"dataIn.txt\""); printf("p(t) = "); print(p, variableNum); printf("q(t) = "); print(q, variableNum); {
fclose(fin);
MPI_DOUBLE_COMPLEX,0, P_TAG, PI_COMM_WORLD, &status);
MPI_Recv(q,variableNum,
MPI_DOUBLE_COMPLEX,0, Q_TAG,MPI_COMM_WORLD, &status);
}
wLength = 2*variableNum; for(i = 0; i < wLength; i ++) {
w[i]= complex<double>
(cos(i*2*PI/wLength), sin(i*2*PI/wLength));
}
everageLength = wLength / size; moreLength = wLength % size;
startPos = moreLength + rank * everageLength; stopPos = startPos + everageLength - 1;
if(rank == 0) {
startPos = 0;
stopPos = moreLength+everageLength -
1;
}
evaluate(p, 0, variableNum - 1, w, s,
startPos, stopPos, wLength); evaluate(q, 0, variableNum - 1, w, r,
startPos, stopPos, wLength); for(i = startPos; i <= stopPos ; i ++) s[i] = s[i]*r[i]/(wLength*1.0);
if (rank > 0) {
MPI_Send((s+startPos),
everageLength,
MPI_DOUBLE_COMPLEX, 0, S_TAG, MPI_COMM_WORLD);
MPI_Recv(s,wLength,
MPI_DOUBLE_COMPLEX,0, S_ TAG2,MPI_ COMM_WORLD,
&status);
} else {
for(i = 1; i < size; i ++) {
MPI_Recv((s+moreLength+i*
everageLength),everageLength, MPI_DOUBLE_COMPLEX, i,S_TAG,
MPI_COMM_WORLD, &status);
}
for(i = 1; i < size; i ++)
{
MPI_Send(s,wLength,
MPI_DOUBLE_COMPLEX,i, S_TAG2,
MPI_COM M_WORLD);
} }
for(int i = 1; i < wLength/2; i ++) {
temp = w[i]; w[i] = w[wLength - i]; w[wLength - i] = temp;
} evaluate(s, 0, wLength - 1, w, r, startPos,
stopPos, wLength);
if (rank > 0) {
MPI_Send((r+startPos), everageLength,
MPI_DOUBLE_COMPLEX,0, R_TAG,
MPI_COMM_WORLD);
} else {
for(i = 1; i < size; i ++) {
MPI_Recv((r+moreLength+i*
everageLength), everageLength,
MPI_DOUBLE_COMPLEX, i, R_TAG,
MPI_COMM_WORLD, &status);
}
puts("\nAfter FFT r(t)=p(t)q(t)"); printf("r(t) = "); print(r, wLength - 1); puts("");
printf("Use prossor size = %d\n",size); }
MPI_Finalize(); }
void evaluate(complex<double>* f, int beginPos, int endPos, const complex<double>* x, complex<double>* y, int leftPos, int rightPos, int totalLength) {
int i;
complex<double>
tempX[2*MAX_N],tempY1[2*MAX_N], tempY2[2*MAX_N];
int midPos = (beginPos + endPos)/2;
if ((beginPos > endPos)||(leftPos > rightPos)) {
puts("Error in use Polynomial!"); exit(-1); }
else if(beginPos == endPos) {
for(i = leftPos; i <= rightPos; i ++)
y[i] = f[beginPos];
}
else if(beginPos + 1 == endPos) {
for(i = leftPos; i <= rightPos; i ++) y[i] = f[beginPos] + f[endPos]*x[i];
}
else {
shuffle(f, beginPos, endPos); for(i = leftPos; i <= rightPos; i ++) tempX[i] = x[i]*x[i];
evaluate(f, beginPos, midPos, tempX,
tempY1, leftPos, rightPos,totalLength); evaluate(f, midPos+1, endPos, tempX,
tempY2, leftPos, rightPos, totalLength);
for(i = leftPos; i <= rightPos; i ++)
y[i] = tempY1[i] + x[i]*tempY2[i];
}
}
void shuffle(complex<double>* f, int beginPos, int
endPos)
{ complex<double> temp[2*MAX_N]; int i, j;
for(i = beginPos; i <= endPos; i ++)
temp[i] = f[i]; j = beginPos;
for(i = beginPos; i <= endPos; i +=2) {
f[j] = temp[i]; j ++; }
for(i = beginPos +1; i <= endPos; i += 2) {
f[j] = temp[i]; j ++; }
} void print(const complex<double>* f, int fLength) {
bool isPrint = false; int i;
if (abs(f[0].real()) > EPS)
{
printf(“%lf”, f[0].real()); isPrint = true; }
for(i = 1; i < fLength; i ++) {
if (f[i].real() > EPS) {
if (isPrint) printf(" + "); else isPrint = true;
printf("%lft^%d", f[i].real(),i);
2. 运行实例
编译:mpicc –o fft fft.cc
运行:使用如下命令运行程序
mpirun –np 1 fft mpirun –np 2 fft mpirun –np 3 fft mpirun –np 4 fft mpirun –np 5 fft
运行结果:
Input of file "dataIn.txt" 4
1 3 3 1 0 1 2 1
Output of solution
Read from data file "dataIn.txt" p(t) = 1 + 3t^1 + 3t^2 + 1t^3 q(t) = 1t^1 + 2t^2 + 1t^3
After FFT r(t)=p(t)q(t)
r(t) = 1t^1 + 5t^2 + 10t^3 + 10t^4 + 5t^5 + 1t^6
Use prossor size = 1 End of this running
Read from data file "dataIn.txt" p(t) = 1 + 3t^1 + 3t^2 + 1t^3 q(t) = 1t^1 + 2t^2 + 1t^3
After FFT r(t)=p(t)q(t)
r(t) = 1t^1 + 5t^2 + 10t^3 + 10t^4 + 5t^5 + 1t^6
}
else if (f[i].real() < - EPS) {
if(isPrint) printf(" - "); else isPrint = true;
printf("%lft^%d", -f[i].real(),i); } }
if (isPrint == false) printf("0"); printf("\n");
}
Use prossor size = 2
End of this running
Read from data file "dataIn.txt"
p(t) = 1 + 3t^1 + 3t^2 + 1t^3
q(t) = 1t^1 + 2t^2 + 1t^3
After FFT r(t)=p(t)q(t)
r(t) = 1t^1 + 5t^2 + 10t^3 + 10t^4 + 5t^5 + 1t^6
Use prossor size = 3
End of this running
Read from data file "dataIn.txt"
p(t) = 1 + 3t^1 + 3t^2 + 1t^3
q(t) = 1t^1 + 2t^2 + 1t^3
After FFT r(t)=p(t)q(t)
r(t) = 1t^1 + 5t^2 + 10t^3 + 10t^4 + 5t^5 + 1t^6
Use prossor size = 4
End of this running
Read from data file "dataIn.txt"
p(t) = 1 + 3t^1 + 3t^2 + 1t^3
q(t) = 1t^1 + 2t^2 + 1t^3
After FFT r(t)=p(t)q(t)
r(t) = 1t^1 + 5t^2 + 10t^3 + 10t^4 + 5t^5 + 1t^6
Use prossor size = 5
End of this running
说明:运行中可以使用参数ProcessSize,如mpirun –np ProcessSize fft来运行该程序,其中ProcessSize是所使用的处理器个数, 本实例中依次取1、2、3、4、5个处理器分别进行计算。