第六章 非参数统计分析方法的SAS编程实现
作者:薛富波 最终修改日期: 20##-12-19
一、npar1way过程语句格式简介
二、不同类型资料的非参数检验方法
1. 两独立样本差别的秩和检验
2.配对设计资料的秩检验
3.完全随机设计多组数据分布位置差别的秩和检验
三、几条重要提示
非参数统计分析方法(non-parametric statistics)是相对参数统计分析方法而言的,又称为不拘分布(distribution-free statistics)的统计分析方法或无分布形式假定(assumption free statistics)的统计分析方法。其中包括Wilcoxon秩和检验、Kruskal-Wallis秩和检验、friedman秩和检验等,它们分别对应不同设计类型的资料。
SAS中对于非参数分析方法功能的实现主要由npar1way过程来完成,从过程名字就可以看出,在此过程的处理进程中,只能一次指定一个因素进行分析。下面我们先来了解一下npar1way过程的语句格式以及各语句和选项的基本功能。
一、npar1way过程语句格式简介
npar1way过程属于SAS的STAT模块,对于统计学教科书上所涉及的非参数统计方法几乎都可以通过此过程来完成。Npar1way过程的基本语句格式如下。

Proc npar1way语句标志npar1way过程的开始,默认情况下(不列举任何选项):npar1way过程对最新创建的数据集进行分析,将缺失数据排除在分析过程之外;执行方差分析过程(等同于ANOVA选项),对样本分布位置的差异进行检验(与选项WILCOXON, MEDIAN, SAVAGE以及VW等效),并进行经验分布函数检验(等同于EDF选项)。此语句后可用的选项见表6.1。
表6.1 Proc npar1way语句选项及其含义

在构成npar1way过程的语句中,by语句、class语句以及freq语句和其它我们已经讨论过的过程完全相同,不再多嘴。
1. exact语句
exact语句要求SAS对指定的统计量(选项)进行精确概率的计算。其后的统计量选项可为以下项目,分别对应相应的统计计算方式(可参见表6.1)。
AB,KLOTZ,KS,MEDIAN,MOOD,SAVAGE,SCORES=DATA,ST,WILCOXON,VW等。
运算选项为精确概率的计算过程指定一些控制项目,如选项“mc”要求以Monte Carlo方法计算精确概率。
2. output语句
output语句与其它过程中相应的语句大同小异,不同之处在于语句最后的选项。此处的选项绝大多数包括在表6.1中,指定在输出数据集中包含所指定项目所对应的统计量。
3. var语句
此处的var语句与其它过程的也基本相同,用以指定要进行分析的变量,变量必须为数值型。若省略此语句,SAS将对除by语句、class语句以及freq语句中指定的变量之外的所有数值型变量进行分析。
关于npar1way过程的内容基本上就这些,了解这么多足够处理一般的统计学问题,下面我们结合实例来演示非参数检验的SAS编程实现过程。
二、不同类型资料的非参数检验方法
1. 两独立样本差别的秩和检验
例6-1 下表(表6.2)为来自两个样本A、B的测量数据,经检验知两样本方差不齐,试做非参数检验比较两组数据的差别。
表6.2 两独立样本A、B测量数据

对于此资料,我们应选用Wilcoxon秩和检验(rank sum test)方法,编制SAS程序如下。

程序中因素“g”分组因素,“1”代表A组,“2”代表B组,“x”为待分析的变量。Proc npar1way语句后的选项“Wilcoxon”指定SAS进行Wilcoxon秩和检验。提交以上程序,运行结果如下。
The SAS System 22:08 Tuesday, December 10, 2002 1
The NPAR1WAY Procedure
Wilcoxon Scores (Rank Sums) for Variable x
Classified by Variable g
Sum of Expected Std Dev Mean
g N Scores Under H0 Under H0 Score
----------------------------------------------------------------------------------------------------
1 8 89.0 68.0 9.521905 11.1250
2 8 47.0 68.0 9.521905 5.8750
Wilcoxon Two-Sample Test
Statistic 89.0000
Normal Approximation
Z 2.1529
One-Sided Pr > Z 0.0157
Two-Sided Pr > |Z| 0.0313
t Approximation
One-Sided Pr > Z 0.0240
Two-Sided Pr > |Z| 0.0480
Z includes a continuity correction of 0.5.
The SAS System 22:08 Tuesday, December 10, 2002 2
The NPAR1WAY Procedure
Kruskal-Wallis Test
Chi-Square 4.8640
DF 1
Pr > Chi-Square 0.0274
SAS给出的结果较为详细,比医学统计教科书上的内容要多很多,首先给出两组数据的的基本信息(样本量、秩和等),还给出在零假设下各组统计量(Sum of scores项)的期望值(Ecpected Under H0项)及标准差(Std Dev Under H0项),最后还给出以近似z检验以及近似t检验所得的统计量和所对应的单、双侧概率值。另外,默认状态下,SAS还同时给出Kruskal-Wallis检验的结果。
所不同的是,在两样本量相同时,SAS以秩和较大者作为对象统计量进行概率值的计算,而非医学统计学教材上所说的以较小秩和为对象统计量。在两样本量不同时,SAS以样本量较小组的秩和为对象统计量,这一点则与教材上的相同。
下面我们再对两组等级资料的非参数检验方法进行练习。
例6-2 用某药治疗不同病情的老年慢性支气管炎病人, 疗效见表6.3,试比较该药对两种病情的疗效。
表6.3 某药对两种不同病情的支气管炎疗效

对于此例,我们将疗效看成待分析的变量x,从“控制”到“近控”分别对其赋值1、2、3、4,病情则作为分组因素,同时需引入一个频度因素f,以代表不同取值状态下x的频数。编制程序如下。

程序和例6-1的基本相同,只根据资料特点增加了freq语句。提交程序,运行结果如下。
The SAS System 22:08 Tuesday, December 10, 2002 7
The NPAR1WAY Procedure
Wilcoxon Scores (Rank Sums) for Variable x
Classified by Variable g
Sum of Expected Std Dev Mean
g N Scores Under H0 Under H0 Score
--------------------------------------------------------------------------------------------------
1 126 12955.50 13167.0 389.776482 102.821429
2 82 8780.50 8569.0 389.776482 107.079268
Average scores were used for ties.
Wilcoxon Two-Sample Test
Statistic 8780.5000
Normal Approximation
Z 0.5413
One-Sided Pr > Z 0.2941
Two-Sided Pr > |Z| 0.5883
t Approximation
One-Sided Pr > Z 0.2944
Two-Sided Pr > |Z| 0.5889
Z includes a continuity correction of 0.5.
The SAS System 22:08 Tuesday, December 10, 2002 8
The NPAR1WAY Procedure
Kruskal-Wallis Test
Chi-Square 0.2944
DF 1
Pr > Chi-Square 0.5874
结果给出的内容和例6-1也是完全相同的,这里所用的统计量为样本量较小组的秩和。
2. 配对设计资料的秩检验
配对设计资料一般采用配对t检验方法进行分析,但若配对数据差数的分布非正态分布,但其总体分布基本对称,则可采用Wilcoxon符号秩检验(signed rank test)作为配对t检验的替代方法。Wilcoxon符号秩检验功效很高,在数据满足配对t检验的要求时,符号秩检验的功效可达配对t检验功效的95%。
令我搞不懂的是,SAS中符号检验(sign test)和符号秩检验的功能不是在npar1way过程中实现,而是通过univariate过程来实现的。我想可能因为这两项功能涉及的是关于单变量分析的缘故。所以,这里我们只好再来复习一下univariate过程的内容。
例6-3 采用配对设计,用某种放射线的A,B两种方式分别局部照射家兔的两个部位,观察放射性急性皮肤损伤程度,结果见表6.4。试用符号秩检验比较A,B的损伤程度是否不同。
表6.4 家兔皮肤损伤程度

根据题目意图,编制SAS程序如下。

此例中,我们须对两次测得数据的差值进行单变量分析,所以数据步中用到赋值语句“d=x1-x2;”。Univariate过程在默认状态下即给出关于待分析变量的符号检验以及符号秩检验结果,“proc univariate”语句后的“loccount”选项指定SAS给出样本数据在系统指定位置参数(默认值为0)两侧的分布情况,即相当于对符号检验结果的进一步描述。
提交执行以上程序,结果如下。
The SAS System 21:13 Thursday, December 12, 2002 1
The UNIVARIATE Procedure
Variable: d
Basic Statistical Measures
Location Variability
Mean -8.00000 Std Deviation 10.44466
Median -8.00000 Variance 109.09091
Mode -8.00000 Range 38.00000
Interquartile Range 13.00000
NOTE: The mode displayed is the smallest of 2 modes with a count of 2.
Tests for Location: Mu0=0
Test -Statistic- -----p Value------
Student's t t -2.6533 Pr > |t| 0.0225
Sign M -3 Pr >= |M| 0.1460
Signed Rank S -29 Pr >= |S| 0.0220
Location Counts: Mu0=0.00
Count Value
Num Obs > Mu0 3
Num Obs ^= Mu0 12
Num Obs < Mu0 9
此结果大家应当比较熟悉(删去了其余关于参数检验的部分),注意标有“Tests for Location: Mu0=0”的部分,即为我们所要的结果,其中第一行为参数检验的t检验结果,后两行则分别为符号检验以及符号秩检验的分析结果。标有“Location Counts: Mu0=0.00”的部分是关于样本分布情况的描述,本例为3个受试对象的差值大于零,9个小于零。
大家需要注意,这里的符号秩检验计算所得的秩和与我们在教科书上看到的结果不同(教科书上计算的统计量即秩和T=10),应是所依据的算法不同所致,但所得的P值是相同的,不会影响分析的结果。
3. 完全随机设计多组数据分布位置差别的秩和检验
这一部分的内容相当于参数检验中的方差分析,依据的方法是Kruskal-Wallis秩和检验,此方法的基本思想与Wilcoxon秩和检验基本相同,都是基于各组混合编秩后,各组秩和应相等的假设。两者的不同点就在于Kruskal-Wallis秩和检验是针对多组(大于2)数据的分析,而Wilcoxon秩和检验则只用于对两组数据的比较。
例6-4 为研究精氨酸对小鼠截肢后淋巴细胞转化功能的影响,将21只小鼠分等分成3组:A组为对照,B组为截肢组,C组为截肢加精氨酸治疗组。观测脾淋巴细胞对HPA刺激的增值反应,测量指标是3H吸收量(cpm),数据如表6.5所示,试分析各组测量值是否不同。
表6-4 脾淋巴细胞对HPA刺激的增值反应(测量指标 3H吸收量cpm)
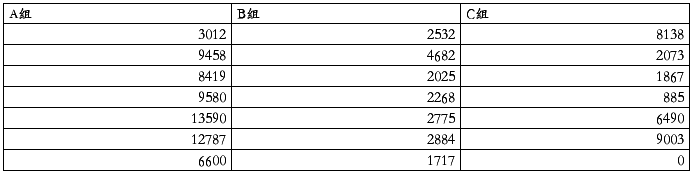
医学统计学教科书上对于此类资料分析方法的介绍虽与两组数据比较的方法有所区别,统计量的计算方法和结果也各不相同,但在SAS中,对这两类资料进行分析的操作过程却是基本相同的,大家可以从相应的SAS程序中看到这一点。
此例分析过程的SAS程序编制如下。

从SAS程序看,此例分析步骤和例6-1完全相同,不再多做解释,提交运行后结果如下。
The SAS System 21:13 Thursday, December 12, 2002 6
The NPAR1WAY Procedure
Wilcoxon Scores (Rank Sums) for Variable x
Classified by Variable g
Sum of Expected Std Dev Mean
g N Scores Under H0 Under H0 Score
-----------------------------------------------------------------
1 7 119.0 77.0 13.403980 17.000000
2 7 54.0 77.0 13.403980 7.714286
3 7 58.0 77.0 13.403980 8.285714
Kruskal-Wallis Test
Chi-Square 9.8479
DF 2
Pr > Chi-Square 0.0073
大家可以看到,此处结果和例6-1的却有所不同,第一部分(标有“Wilcoxon Scores (Rank Sums) for Variable x”的部分)的内容完全一样,两组数据比较时的各种近似检验结果这里是没有的,这里的最终结果只有Kruskal-Wallis秩和检验分析结果,而P值的计算这里所依据的是卡方分布。
三、几条重要提示
1. Npar1way过程对于缺失值(missing value)的处理
如果缺失值出现在反应变量(var语句指定的变量),npar1way过程会将该条记录排除在分析之外。
默认情况下,npar1way过程也会将分类变量中出现缺失值的记录排除出分析过程。如果指定选项“missing”,npar1way过程则将分类变量中出现的缺失值当作一个单独的水平进行处理。
对于by语句中指定的变量,缺失值将被默认地当作一个独立水平进行处理。
对于freq语句中指定的变量,出现缺失值的记录一定会被排除出分析过程。
2. npar1way过程对于同秩(ties)问题的处理方式
Npar1way过程处理同秩问题的方式在任何一种非参数检验方法中均相同,即无论相同秩次的记录出现在同一组或不同的组中,均给它们分配相应的平均秩次,再根据这些平均秩次进行各种计算,跟教科书上介绍的方法完全一样。
npar1way过程对于此问题的处理到此为止,不像教科书上介绍的那样对计算所得的统计量再进行某种校正。对于相同秩次出现较少的数据,这一点对分析的结果影响不大,但对于同秩现象较多的数据,分析结果的偏差就不容忽视,尤其是对于那些近似检验来说更是如此。处理这一问题的理想办法就是计算精确概率,npar1way过程提供了实现这一功能的途径,即exact语句。
SAS的非参数检验方法就介绍这么多的内容,关于其它类型设计(如区组设计)资料的非参数检验方法,以及多组数据比较时的两两比较方法,因各种算法尚未成熟,还没有得到业界的广泛认可,SAS中还没有设计关于此类方法的现成实现途径,所以这里暂不作介绍。当然通过自行编制的程序,以上过程完全可以实现,但操作过程较为复杂,我们留待以后再讨论吧。
(薛富波,2002.12.12)