生命是永恒不断的创造,因为在它内部蕴含着过剩的精力,它不断流溢,越出时间和空间的界限,它不停地追求,以形形色色的自我表现的形式表现出来。
--泰戈尔
《医学统计学习题》
一、名词解释题:(20分)
1、总体:根据研究目的确定的同质的观察单位其变量值的集合。
2、计量资料:又称为定量资料,指构成其的变量值是定量的,其表现为数值大小,有单位。
3、抽样误差:由于抽样造成的统计量与参数之间的差别,特点是不能避免的,可用标准误描述其大小。
4、总体均数的可信区间:按一定的概率大小估计总体均数所在的范围(CI)。常用的可信度为95%和99%,故常用95%和99%的可信区间。
二、选择题:(20分)
1、某地5人接种某疫苗后抗体滴度为:1:20、1:40、1:80、1:160、1:320。为求平均滴度,最好选用:
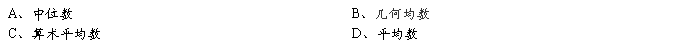
2、为了直观地比较化疗后相同时间点上一组乳癌患者血清肌酐和血液尿素氮两项指标观察值的变异程度的大小,可选用的变异指标是:
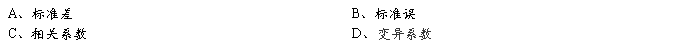
3、某疗养院测得1096名飞行员红细胞数(万/mm2),经检验该资料服从正态分布,其均数值为414.1,标准差为42.8,求得的区间(414.1-1.96×42.8,414.1+1.96×42.8),称为红细胞数的:
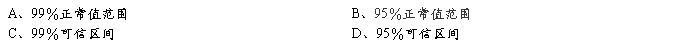
4、某医院一年内收治202例腰椎间盘后突病人,其年龄的频数分布如下:
年龄(岁) 10~ 20~ 30~ 40~ 50~ 60~
人数 6 40 50 85 20 1
为了形象表达该资料,适合选用:
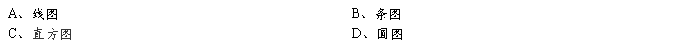
5、有资料如下表:
甲、乙两个医院某传染病各型治愈率

由于各型疾病的人数在两个医院的内部构成不同,从内部看,乙医院各型治愈率都高于甲医院,但根据栏的结果恰好相反,纠正这种矛盾现象的统计方法是:
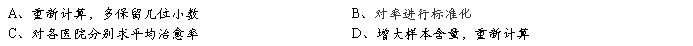
6、5个样本率作比较,χ2>χ20.01,4,则在α=0.05检验水准下,可认为:
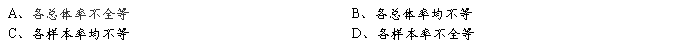
7、两个独立小样本计量资料比较的假设检验,首先应考虑:
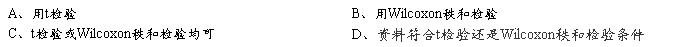
8、标准正态分布曲线下,0到1.96的面积为:
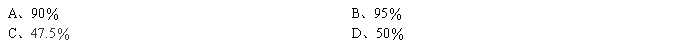
9、均数与标准差的关系是:

10、某临床医生测得900例正常成年男子高密度脂蛋白(g/L)的数据,用统计公式求出了该指标的95%的正常值范围,问这900人中约有多少人的高密度脂蛋白(g/L )的测定值在所求范围之内?
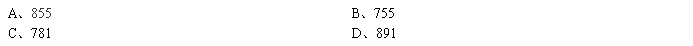
三、简答题:(40分)
1、 标准正态分布(u分布)与t分布有何异同?
相同点:集中位置都为0,都是单峰分布,是对称分布,标准正态分布是t分布的特例(自由度是无限大时)
不同点:t分布是一簇分布曲线,t 分布的曲线的形状是随自由度的变化而变化,标准正态分布的曲线的形状不变,是固定不变的,因为它的形状参数为1。
2、 标准差与标准误有何区别和联系?
?区别:
1.含义不同:⑴s描述个体变量值(x)之间的变异度大小,s越大,变量值(x)越分散;反之变量值越集中,均数的代表性越强。⑵标准误是描述样本均数之间的变异度大小,标准误 越大,样本均数与总体均数间差异越大,抽样误差越大;反之,样本均数越接近总体均数,抽样误差越小。
 2.与n的关系不同: n增大时,⑴s σ(恒定)。 ⑵标准误减少并趋于0(不存在抽样误差)。
2.与n的关系不同: n增大时,⑴s σ(恒定)。 ⑵标准误减少并趋于0(不存在抽样误差)。
3.用途不同: ⑴s:表示x的变异度大小,计算cv,估计正常值范围,计算标准误等 ⑵ :参数估计和假设检验。
?联系: 二者均为变异度指标,样本均数的标准差即为标准误,标准差与标准误成正比。
3、 应用相对数时的注意事项有哪些?P39
4、 简述直线回归与直线相关的区别。
1资料要求上不同:直线回归分析适用于应变量是服从正态分布的随机变量,自变量是选定变量;直线相关分析适用于服从双变量正态分布的资料。
2 两种系数的意义不同:回归系数是表明两个变量之间数量上的依存关系,回归系数越大回归直线越陡峭,表示应变量随自变量变化越快;相关系数是表明两个变量之间相关的方向和紧密程度的,相关系数越大,两个变量的关联程度越大。
四、计算分析题:(20分)
用甲、乙两种培养基培养结核杆菌45份,得资料如下表,问甲、乙两种培养基的培养效果有无差异?
要求:详细写出检验步骤。
甲乙两种培养基培养结核杆菌的结果

注:χ20.05,1=3.84
1、 建立假设:H0:B=C;H1:B≠C
2、 确定α:α=0.05
3、 选择检验方法、计算统计量:
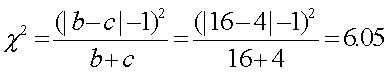
4、 确定P值:6.05>3.84,故P<0.05
5、 统计推断:按α=0.05,拒绝H0假设,接受H1假设,可以认为甲乙两种培养基的培养结果的差别有统计学意义。
第二篇:医学统计学总结
一、两组或多组计量资料的比较
1.两组资料:
1)大样本资料或服从正态分布的小样本资料
(1)若方差齐性,则作成组t检验
(2)若方差不齐,则作t’检验或用成组的Wilcoxon秩和检验
2)小样本偏态分布资料,则用成组的Wilcoxon秩和检验
2.多组资料:
1)若大样本资料或服从正态分布,并且方差齐性,则作完全随机的方差分析。如果方差分析的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:LSD检验,Bonferroni检验等)进行两两比较。
2)如果小样本的偏态分布资料或方差不齐,则作Kruskal Wallis的统计检验。如果Kruskal Wallis的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:用成组的Wilcoxon秩和检验,但用Bonferroni方法校正P值等)进行两两比较。
二、分类资料的统计分析
1.单样本资料与总体比较
1)二分类资料:
(1)小样本时:用二项分布进行确切概率法检验;
(2)大样本时:用U检验。
2)多分类资料:用Pearson c2检验(又称拟合优度检验)。
2. 四格表资料
1)n>40并且所以理论数大于5,则用Pearson c2
2)n>40并且所以理论数大于1并且至少存在一个理论数<5,则用校正c2或用Fisher’s 确切概率法检验
3)n£40或存在理论数<1,则用Fisher’s 检验
3. 2×C表资料的统计分析
1)列变量为效应指标,并且为有序多分类变量,行变量为分组变量,则行评分的CMH c2或成组的Wilcoxon秩和检验
2)列变量为效应指标并且为二分类,列变量为有序多分类变量,则用趋势c2检验
3)行变量和列变量均为无序分类变量
(1)n>40并且理论数小于5的格子数<行列表中格子总数的25%,则用Pearson c2
(2)n£40或理论数小于5的格子数>行列表中格子总数的25%,则用Fisher’s 确切概率法检验
4. R×C表资料的统计分析
1)列变量为效应指标,并且为有序多分类变量,行变量为分组变量,则CMH c2或Kruskal Wallis的秩和检验
2)列变量为效应指标,并且为无序多分类变量,行变量为有序多分类变量,作none zero correlation analysis的CMH c2
3)列变量和行变量均为有序多分类变量,可以作Spearman相关分析
4)列变量和行变量均为无序多分类变量,
(1)n>40并且理论数小于5的格子数<行列表中格子总数的25%,则用Pearson c2
(2)n£40或理论数小于5的格子数>行列表中格子总数的25%,则用Fisher’s 确切概率法检验
三、Poisson分布资料
1.单样本资料与总体比较:
1)观察值较小时:用确切概率法进行检验。
2)观察值较大时:用正态近似的U检验。
2.两个样本比较:用正态近似的U检验。
配对设计或随机区组设计四、两组或多组计量资料的比较
1.两组资料:
1)大样本资料或配对差值服从正态分布的小样本资料,作配对t检验
2)小样本并且差值呈偏态分布资料,则用Wilcoxon的符号配对秩检验
2.多组资料:
1)若大样本资料或残差服从正态分布,并且方差齐性,则作随机区组的方差分析。如果方差分析的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:LSD检验,Bonferroni检验等)进行两两比较。
2)如果小样本时,差值呈偏态分布资料或方差不齐,则作Fredman的统计检验。如果Fredman的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:用Wilcoxon的符号配对秩检验,但用Bonferroni方法校正P值等)进行两两比较。
五、分类资料的统计分析
1.四格表资料
1)b+c>40,则用McNemar配对c2检验或配对边际c2检验
2)b+c£40,则用二项分布确切概率法检验
2.C×C表资料:
1)配对比较:用McNemar配对c2检验或配对边际c2检验
2)一致性问题(Agreement):用Kap检验
变量之间的关联性分析六、两个变量之间的关联性分析
1.两个变量均为连续型变量
1)小样本并且两个变量服从双正态分布,则用Pearson相关系数做统计分析
2)大样本或两个变量不服从双正态分布,则用Spearman相关系数进行统计分析
2.两个变量均为有序分类变量,可以用Spearman相关系数进行统计分析
3.一个变量为有序分类变量,另一个变量为连续型变量,可以用Spearman相关系数进行统计分析
七、回归分析
1.直线回归:如果回归分析中的残差服从正态分布(大样本时无需正态性),残差与自变量无趋势变化,则直线回归(单个自变量的线性回归,称为简单回归),否则应作适当的变换,使其满足上述条件。
2.多重线性回归:应变量(Y)为连续型变量(即计量资料),自变量(X1,X2,…,Xp)可以为连续型变量、有序分类变量或二分类变量。如果回归分析中的残差服从正态分布(大样本时无需正态性),残差与自变量无趋势变化,可以作多重线性回归。
1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
3.二分类的Logistic回归:应变量为二分类变量,自变量(X1,X2,…,Xp)可以为连续型变量、有序分类变量或二分类变量。
1)非配对的情况:用非条件Logistic回归
(1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
(2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
2)配对的情况:用条件Logistic回归
(1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
(2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
4.有序多分类有序的Logistic回归:应变量为有序多分类变量,自变量(X1,X2,…,Xp)可以为连续型
变量、有序分类变量或二分类变量。
1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用
5.无序多分类有序的Logistic回归:应变量为无序多分类变量,自变量(X1,X2,…,Xp)可以为连续型变量、有序分类变量或二分类变量。
1)观察性研究:可以用逐步线性回归寻找(拟)主要的影响因素
2)实验性研究:在保持主要研究因素变量(干预变量)外,可以适当地引入一些其它可能的混杂因素变量,以校正这些混杂因素对结果的混杂作用