文献读后感——基于动态计量经济学模型的房地产周期研究
丁毅 1
(南京财经大学 国民经济学 MG11001049)
摘要:本文作者参见清华大学学报20##年第47卷第12期《基于动态计量经济学模型的房地产周期研究》一问,研究了动态计量经济学模型在现实的应用方法。参考文献对所涉及的内容包括自回归分布滞后的ARMAX模型,使用了ADF检验和多重协整JJ检验,求出了误差修正序列(ECM)。
关键词:动态经济学模型 ECM ARMAX模型 JJ检验
0 文献内容
本文是研究张红教授等《基于动态计量经济学模型的房地产周期研究》一文后的读后笔记。原文是以北京市1989年至20##年的时间序列数据为基础,建立了用于分析和判别房地产周期的动态计量经济学模型。原文作者使用的动态计量经济学模型,是有别于传统计量经济学模型的理论先导方法。张红教授认为如果后者先验理论的不准确,将导致传统计量经济学模型参数的错误。这与《中级计量经济学》中所认为的伪拟合问题含义相同。原文采用了误差修正模型和协整理论基础上的动态经济学模型,建立了北京房地产市场模型。经过系列分析后,得出结论:20##年北京房地产市场继续稳步上升。这与事实现今基本相同,因此本文作者认为该模型拟合过程正确。同时,张红教授指出,模型后期修正可以构建房地产周期识别指标和复杂性指标体系,时期合理体现市场的真实情况,而且可以考虑应用广义脉冲函数等分析某单独因素对房地产市场的周期的冲击性影响。[1]
1 原文解读
1.1 选择动态经济学模型原因
中国房地产各种非理性因素对房地产有着深刻的影响能力,同时房地产行业的统计数据质量和时间序列长度无法满足分析需要,因此传统计量经济学模型效果差,应当考虑动态计量经济学模型。使用一个代表数据生成过程的自回归分布整合模型,然后推出包含变量间长期稳定关系的简单模型。这种模型使用了经济理论和统计数据,充分利用数据所包含的全部信息,适合于房地产市场周期分析。
1.2 建模思路
1. 确定房地产周期变量相关的时间序列,建立指标体系;
2. 建立ARMAX模型;
3. 确定模型参数,及ARMAX的滞后阶数;
4. 对参数进行检验,ADF和多重协整JJ检验;
5. 求出ECM,以此表明周期实际表征数据;
6. 建立包含修正项的ARMAX模型;
7. 模型的预测和分析;
1.3 ARMAX模型
Eq1表示ARMAX模型。其中,RD表示销售率,INVT表示年度完成投资额,PRIE表示年度商品房平均销售价格,EARN表示家庭年均可支配收入;因为原文中,指标体系是通过经验判断和行业规范建立的,因此本文作者在此不进行叙述。
1.4 JJ检验[2]
Johansen和Juselius的似然比检验方法,简称JJ检验,主要用来分析诸多变量组成的VAR系统,借助典型相关理论在VAR模型基础上使用似然比检验进行协整检验的同时确定协整关系。其中,要注意的问题有
1. 根据时间序列的数据生成过程正确选择确定成分,正确处理好截距项和趋势项;
2. 在实证分析阶段的结果上选择临界值;
3. 协整关系非唯一性问题,当检验结果出现多个
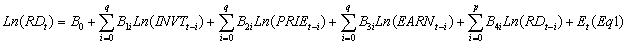
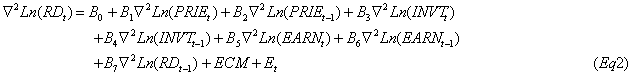
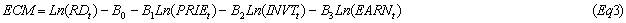
协整关系,用经济理论对协整进行识别;
1.5 ARMAX(p.q)参数估计
文献作者根据房产平均建设周期,选定了(p,q)=(1,1);
1. 对Ln(RD),Ln(INVT), Ln(PRIE)和Ln(EARN)四个变量进行ADF检验,其检验条件均为二阶差分、一阶滞后和不含趋势想和常数项,检验都通过。
2. 因为所有变量都是二阶单整的,所以符合多重协整的检验条件。
3. 对变量进行JJ检验,发现在假定协整关系数量为1时,才能接受原假设H0=1;得出Eq2.
1.6 ARMAX模型修正
至此,文章求得了长期均衡时误差的。结合前面所得到的滞后阶数和差分阶数,最终模型为Eq2
ECM表达式为Eq3,反映了房地产行业的周期状况如图 1。这个模型可以精确描述Ln(RD)的情况。在Eq2中加上ECM,就把长期均衡的信息量加到了模型中,使得模型拟合性更好。
2 个人总结
对特定经济现象的研究,选择的计量经济模型要根据客观条件进行选择。在本文中,由于时间序列数据的质量原因和经济系统自身因素,在比较若干个模型的有确定后,最终确定研究所选模型。
按照教科书,计算出样本自相关系数和偏自相关系数的值之后,要根据它们表现出来的性质,选自适当的模型拟合观察值序列。这个过程实际上就是要根据样本自相关系数和偏自相关系数的性质估计自相关阶数和移动平均阶数 ,因此,模型的识别过程其实也是模型的定阶过程。
模型定阶的基本原则如下表所示:
表2-1ARMA模型的定阶原则

但是在这里,原文作者采用定性分析来确定自相关阶数,其依据让人难以信服。毕竟,通过常识得出来的结论也许是错误的。
其次对于文章的预测结果,读者会感到失望的。因为,预测结果和经验推断类似。而建立ARMAX模型,一般来说可以对未来几年的被解释变量的值做出一个大致的预测。而通过这几年数据初步判断,此模型不准确。20##年北京房价出现大幅度增长。如果进一步分析,可以肯定模型误差很大。
最后,实际此模型必定是不准确的。究其原因,是原文作者选取的样本点太少。一般来说,时间序列分析样本点取30个以上。过少的样本,带来的信息量不足以建立一个准确的模型[3]。

参考文献
[1] 张红,马进军,孔沛.清华大学学报(自然科学版)[J].20##年.第47卷.第12期:2111-2113.
[2] 钟志威,雷钦礼.统计与信息论坛[J].20##年..第23卷.第10期:80-85.
[3] 王燕.SPSS统计分析方法及应用[M].北京:电子工业出版社,2004.
图 1 ECM描述的北京房地产周期变化
第二篇:计量经济学论文
浅析我国进出口贸易对我国GDP的影响
● 摘要:加工贸易一直在我国进出口贸易中占很大比重,而且对我国GDP的影响较大, 这是我国一直以来“重出口“的结果。为此,我们想了解这种说法是否属实并进行分析。
● 关键词:进出口 加工贸易 GDP
● 理论依据:GDP由4个部分组成,消费,投资,政府购买以及净出口。净出口是出口减去进口。进出口额对我国经济发展有至关重要的作用。
● 问题的提出
我国已发展成为一个对外经贸大国,但是还算不上一个对外经贸强国。在新的世纪里,我国的目标应当是从一个对外经贸大国发展成为对外经贸强国。但与世界贸易强国相比,现时还有许多差距。主要表现在中国出口产品和服务贸易竞争优势不大,加工贸易占半壁江山,造成贸易条件不利。对此,我们进行一些实证分析。
我们按贸易方式把进出口贸易分为一般贸易,加工贸易和其他贸易。其中加工贸易,主要指对外加工装配、中小型补偿贸易和进料加工贸易。发展加工贸易的好处是投资少,时间短,见效快,有利于充分利用我国丰富的劳动力资源,有利于扩大出口,增加外汇收入。一般贸易是与加工贸易相对而言的贸易方式。一般贸易指单边输入关境或单边输出关境的进出口贸易方式,其交易的货物是企业单边售定的正常贸易的进出口货物。其他贸易为除了一般贸易和加工贸易以外的进出口贸易。
1. 模型的建立:设定 Y=GDP X1=一般贸易 X2=加工贸易 X3=其他贸易,由于没有进出口贸易对GDP的经济理论模型,我们简单的以
Y=B1+B2X1+B3X2+B4X3+U 当做我们的理论模型。
2. 数据的收集。以下是我们得到的数据:
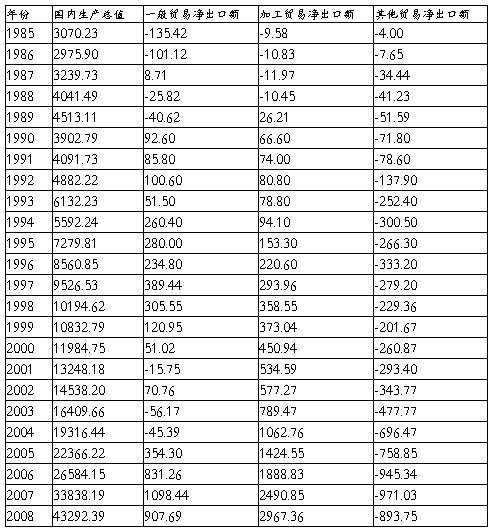
3. 对模型的经济检验。
对模型进行初步回归得如下结果:
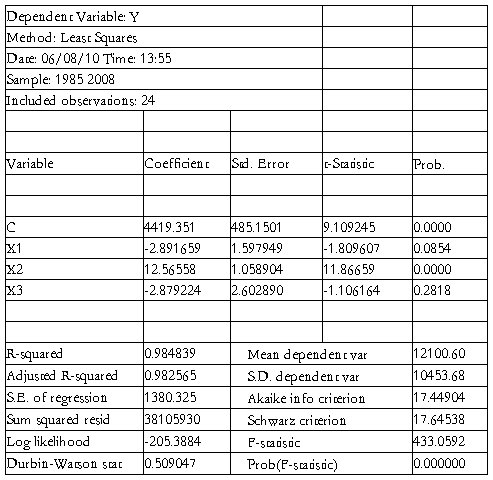
由此数据看出,可决系数和修正可决系数为0.984839和0.982565,F的检验值为433.0592,明显显著,拟合效果还可以。但当a=0.05时,ta/2(n-k)=2.080,说明x1与x3的t检验不显著,而且x1与x3系数的符号与经济解释相反。可能存在多重共线性。
我们查看一下相关系数矩阵:
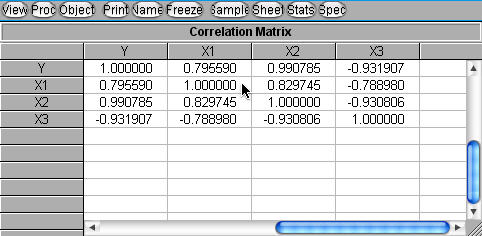
由相关系数矩阵可以看出,各解释变量之间的相关系数很高,证实确实存在多重共线性。
4. 修正多重共线性
采用逐步回归的方法,去解决多重共线性的问题。分别做y对x1,x2,x3的一元回归,结果如下:

其中x2的可决系数最大,以x2为基础,加入其它变量逐步回归,结果如下:

可见,加入x1或加入x3对可决系数几乎没有改变,因此把x1和x3剔除。最终得:
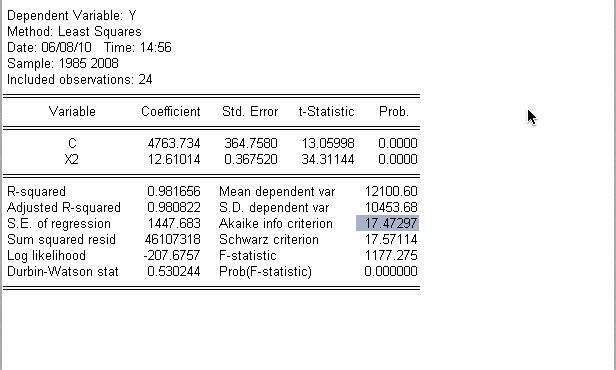
Y=4763.734+12.61014X2
(13.05998) (34.31144)
可决系数=0.981656 修正可决系数=0.980822 f值=1177.275
D-W值=0.530244
5. 在以上基础上,进行异方差检验,利用white检验的方法:
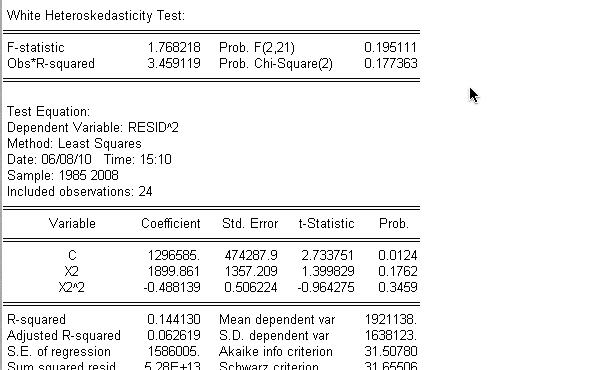
由上表可知,NR2=24*0.144130=3.45912<5.9915,所以不存在异方差。
6. 检验自相关,利用D-W值,D-W值=0.530244,在5%的显著水平下,通过查表得dl=1.273,du=1.446,DW值小于dl的值,所以模型中有自相关。这一点也可以从残差图中看出: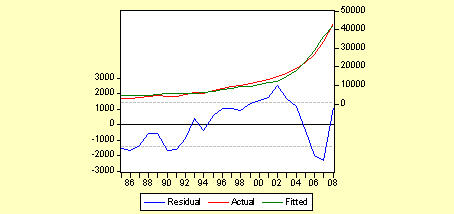
7. 自相关的补救。因此我们需要对自相关问题进行补救,采用广义差分法:生产残差序列Et,使用et进行滞后一期的自回归得:
Et=0.713767Et-1
由上式可知,p=0.713767,对原模型进行广义差分,得广义差分方程:
Y-0.713767Yt-1=c(1-0.713767)+b3(X-0.713767Xt-1)+u
对广义差分方程进行回归,结果如下:
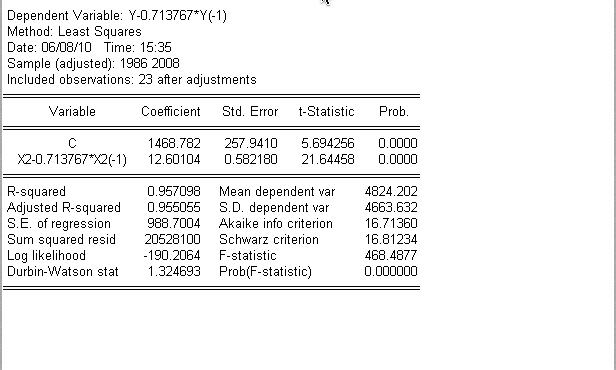
回归方程为:
Y*=1468.782+12.60104X*
(5.694256) (21.64458)
可决系数=9.57098 F值=468.4877
使用广义差分数据,样本减少至23个,在显著水平5%下,dl=1.257,du=1.437,此时DW值=1.324693大于dl的值,但接近du的值,我们认为自相关已消除。由于样本量较大,不使用普莱斯-温思腾变化。
由差分方程可得:
C=1468.782/1-0.713767=5131.4209
所以我们的最终模型为:
Y=5131.4209+12.60104X2
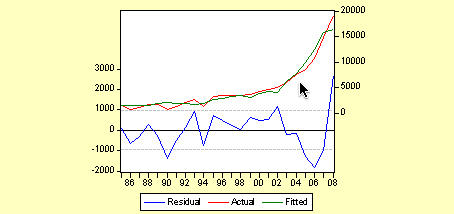
模型的最终拟合效果还算不错。
8. 经济意义的分析及模型的评价。
由模型可知,加工贸易的净出口额每增加1亿美元,我国GDP增加12.60104亿美元。我国的进出口贸易对加工贸易的依赖很重,而且对GDP的贡献很大。这显示出了我国贸易结构的缺陷,加快调整和优化出口商品结构,改善产业结构和贸易结构是我国提高贸易竞争力的重要一环。国际经验表明,一个国家的贸易结构将发生有以出口劳动密集型产品为主、进口资本密集型产品为主向以出口资本密集型产品和服务产品为主、进口劳动密集型为主的转变。而一国欲从国际竞争中获得更大的利益,就应使本国具有高附加值的产业具有较强的国际竞争力。
我国出口商品中技术含量和附加值较高的产品所占比重偏低在结构上,我国出口商品中高科技含量、高附加值的产品的比重偏低。目前,在我国的出口结构中,劳动密集型产品的比重较高,而资本密集型产品(如机械及运输设备)的比重比较低;在进口结构中,劳动密集型产品比较低,资本密集型产品的比重较高。这说明我国的贸易结构还处于不发达阶段。另外,从产业的贸易依存度来看,我国贸易结构也处于不发达阶段。一般来说,贸易结构越发达,资本密集型产品越具有国际竞争力。目前,由于加工贸易已占我国对外贸易的较大比重,总量层次上的贸易结构难以反映我国的国际竞争力,而一般贸易进口结构和一般贸易结构出口结构能更好地反映贸易结构的发达程度和国际竞争力的高低。
9. 模型的不足
模型的主要不足在自相关的修正上,在进行一次广义差分后,DW值只在dl值和du值之间,此时不能确定自相关的存在与否。由于时间与能力问题,我们不进行多次的迭代,仅以第一次迭代的值为最终结果。
还有更多的问题,希望同学和老师能给我们指正和帮助,希望大家就我们的模型提出宝贵的意见和建议,以使我们的模型能够完善。