在老公的大力支持下,我参加了在首医举办的第八届cochrane培训班,好久没有坐在教室里认真的听课了,感觉真好!
以前也在网上看到过循证医学的介绍,真的不知道如何下手。cochrane很适合急功近利的中国人,如同Medical Hypotheses 也是SCI一样。搞科研前要写综述,做临床要懂meta分析。cochrane的meta分析系统,有着非常规范的操作。仅其handbook就有600多页。首先它选择的是最严谨的随机对照实验(RCT, randomized controlled experiment)作为实验的证据,从题目的选择就开始进行注册,题目合理且无重复时才可以进,每一步都需要按照严格的步骤进行,至少需要三个作者进行讨论,还要跟所注册的编辑小组反复进行沟通,修改,才能不断的完善写作。还要学会对收集的资料进行分析,筛选,去除偏倚,制作森林图及漏斗图,估计一篇文章可能要花半年左右的文章,可能像博士论文那样上百页。
对于cochrane我仅仅摸到了门口,里面非常博大精深,很高兴认识这么多新同学,大家一起讨论。在介绍题目时,我是唯一一个用汉语介绍的,当我把题目说出来时,夏老师很遗憾她不会翻译,大家哄堂大笑,不知是笑我,还是笑她,我当然可以用英语讲,只是这样大家就可以听清我的题目了。最后,很遗憾夏老师没有选我的题目进行课堂讨论,因为我的口语不够好,不能直接与Mahesh Jarayam进行交流,好羡慕那个被选中题目的老哥,估计他一定在国外待过。
二天主要学习了检索策略、endnote之应用和revman软件管理三大块内容。下面主要介绍检索策略,只有我讲清楚了,才是我真正学会了:
1. cochrane检索策略的设计:有关传统的pubmed应用见我以前转的帖子。
Cochrane的系统评价对文献检索要求非常高,每一步都要求有记录,都需要信息检索官的参与,需要不同的修改及讨论检索策略。
(1)根据构建临床问题的国际PICO格式确定检索策略(identify concepts)
e.g.insecticide-treated vs no insecticide-treated bed nets and curtains for preventing malaria
比较杀虫剂和非杀虫剂对疟疾的预防
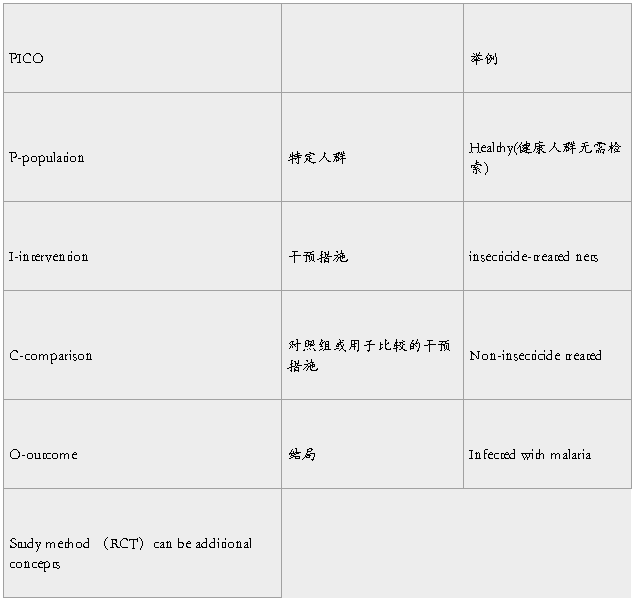
(2)为每一个concepts寻找一个关键词或mesh(medical subject headings )
一定要用头脑风暴法(brain storm)将每一个text word的不同写法想出来,如malaria,有的作者有写为plasmodium,blackwater fever 或marsh fever 。
①同时应利用些小技巧查全,如用net*(*为上标,是拓展符合)可以查到 net、nettles、netting、nether、network、nets等词语,避免查不全
②“mosquito net”加上引号表示这两个单词在一起才能查到,不加引号表明即使分开,只要在该文献出现这两个词就能查到。
③?和$可以替代拼写不同、英美语差别及拼写错误,如tumo?r可以查到tumor及tumour。
④Random* near/3 assign* 可以查到Random 和assign及其拓展的相关词之间间隔1-3个单词的文章,在Ovid中near用adj代替,而pubmed则没有near功能。
⑤MeSH可用于medline及cochrane library中。
(3)合并所有的检索策略(overall search strategy)

Malaria search and ITN search and RCT search
(3)我总结的pubmed之新经验
①原来pubmed和medline不是一回事,medline不同的版本(Version)有不同的方法寻找和使用MeSH。Pubmed可根据关键词(text words)自动寻找MeSH。二者大概有90%的重复文献,因此,两个数据库都要进行检索,然后导入到endnote中去,再删除重复的。同时补充查询embase数据库及cochrane library基本可以查全。当然还要检索google scholar 及会议文献。
②在pubmed注册一个账号后可以保存查询结果,并为这个save search起个名字。并可以定制自动更新查询,并发送到邮箱中,非常方便。
③检索时,最好每一个text word单独查,然后再用#1 and #3,或者#3 or #5 等布尔逻辑值进行组合,便于调整检索策略时重新组合。
④如查询文章太多,可选择restrict to MeSH major topic进行设定。
(4)其他收获
cochrane是一个有严密游戏规则的meta,必须按照它的规则来才能写出符合cochrane八股的系统评价文章来。但是真的写起来规则很晦涩,即使经过培训,最好也要有写过的人一起写。只有质量控制好,所以它影响因子才能6.18。由于每个专业组的编辑回信不一,只要能注册protocol并能完成就能发表,但是太难了!
先写篇质量差的中文meta熟悉软件及方法,在写篇非cochrane的meta分析,有位过来人说,为了找到适合RCT的文章,可能得读上千篇文献。O,my god,有点让人崩溃啊!
Endnote试用版只有1个月的期限,**版有被识别甚至毁坏文件的可能性,可以用notepress等软件代替。
所有的meta均应该在revman软件中写,其中涉及多次文件的导入及转换。
熟练应用cochrane library进行查询,目前只看了演示,还没有试用。
Cochrane之第三日听刘关键老师讲统计(一)
丁香园上讲,刘关键老师是meta分析统计的关键,这一天我一点都没有打瞌睡,感觉好像听懂了,只是还有些知识点,在我以往的学习中是空白,还需要进一步补充,与统计无关。
刘关键老师举了最简单通俗的例子,网络上经常提到的“被涨工资”,有10个人每人工资1000元,大家的平均工资即为1000元,而由一个人工资涨到了2000,他们的平均工资应为“1100”?这是国家统计局报道的结果。实际上呢?任何统计都是有条件的,这10个人的工资数据明显不符合正态分布,应该使用中位数,而不适合用均数来表述,这就是大家“被涨工资”的原因。加减法有条件吗?1kg+1cm?只用同质的东西才能相加,1个香蕉+1个香蕉=2个香蕉,而1个苹果+1个桔子=?这就引出了我们在做meta分析时要做异质性的检验。同时提醒大家小学数学很重要,中小学的任何知识是人类最基本的知识和文明。
以下为统计授课内容
一、临床实验中的统计指标
1. 单个试验的率差(RD,rate difference,risk difference):两个发生率的差即为率差,反应实验组发生率比对照组多或少的绝对量。RD=EER(试验组发生率)-CER(对照组发生率),RD值根据指标的不一而解释不同,如指标为死亡,RD>0代表病死率高。如为服药RD>0代表药物有效。(临床医生一定要区分病死率及死亡率的概念)。RD的可信区间,只要不包括0,认为有意义。
2. 单个试验的RR(relative risk,risk ratio )两个率的比值叫做相对危险度,是前瞻性研究中比较常用的指标,说明试验组的发生率是对照组的多少倍。RR=1认为试验组与对照组的发生率相同,RR=1与RD=0意义一致。RR的可信区间用自然对数进行计算(原始数据不能满足正态,用正态近似法计算可信区间),结果计算出来后用反对数将结果变为非对数。RR的可信区间(CI)只要不包括1,认为有意义。
3. 单个试验的OR在回顾:在回顾性研究(如病例对照研究)中,往往无法得到某事件的发生率CER或EER,也无法计算出RR,但是当发生率很低时(如小于5%),可以计算出一个RR的近似值,即OR(odds ratio)。
4. 数值变量的指标:均数差(MD,mean difference or WMD weighted mean difference)为两个均数的差值,以试验原有的测量单位,真实的反映了试验效果,消除了绝对值大小对结果的影响。
5. 数值变量的指标:标准化标准差(SMD,standarddised mean difference)简单理解为两均数的差值再除以合并标准差的商,不仅消除了某研究绝对值大小的影响,还消除了测量单位对结果的影响。对SMD分析的结果解释要慎重,大小无用,只存在有或没有。
6. 若选择MD和SMD为合并统计量时,其95%CI与假设检验的关系如下:若其95%的CI包含了0,等价于P>0.05,即合并统计量无统计学意义。若其95%CI的上下限均大于0或小于0,等价于P<0.05,即合并效应量有统计学意义。




MD与SMD的森林图示意
二、临床试验中的缺少数据及处理
1、统计分析数据集包括:全分析数据集(Full analysis set,FAS),符合方案数据集(per protocol,PPS),安全性评价数据集(safety set,SS)。
2. 安全性评价数据集(safety set,SS)通常是指所有随机分配后至少接受一次治疗的受试者,包括至少服过一次药物,接受过一次治疗后的安全性评估的受试者的数据。
3. 符合方案数据集(per protocol,PPS)亦称“可评价病例”的数据,满足以下条件:有完整的主要变量基线值。符合试验方案,不违背实验方案中的规定的纳入与排除标准,完成全部实验评估。依从性良好(80%~120%)。
4.PP分析:符合纳入标准的观察对象常常会因为各种原因脱落或失访,在分析时,不考虑脱落或失访病例只对完成了整个实验的观察对象的数据(PPS)进行的分析叫PP分析(per protocol analysis)。PP分析存在的问题:脱落或失访的受试对象,往往是试验效果不理想、依从性差、甚至可能是严重不良事件的受试者,忽略了脱落或失访对象的信息,造成了试验信息的损失和分析偏倚,可能会破坏试验分组的随机性,从而破坏由随机分配而建立的基线一致性,降低了结论的可靠性。因此PP分析有可能夸大了试验的效应,高估了依从性,低估了不良事件或不良反应的发生率。
5.全分析集(FAS数据集,Full analysis set)指分析包括几乎所有的随机分配后的受试对象。只有在纳入期中被排除而未入组或入组后没有任何随访的数据才能从FAS人群中排除。FAS数据集满足以下条件:至少使用过一次干预措施,且至少接受过一次干预后有效性评估的受试对象数据。
6.ITT分析:对FAS数据集所进行的分析叫ITT分析(intention to treat analysis,意向性分析),是对包含了PPS数据集和脱落或失访对象数据的分析,其分析所使用的方法与PP分析完全相同。ITT分析可放置试验信息的损失和分析偏倚,可防止试验分组的随机性和由随机分配而建立的基线一致性的破坏。ITT分析的结果比PP分析更全面、真实的反映了临床试验的结果,增加了结论的可靠性。
举例:有100名患者通过一系列化验及检查,有1例化验结果不符合条件,剔除1例,其余99例接受干预,可能有2例不能耐受干预脱落,其中97例接受了至少一次有效性评价,8例失访,最后有89例完成了试验。因此PPS=89,FAS=PPS+脱落=89+10=99,SS=97








7.缺失值(missing value)临床试验的病例报告表中原则上不应有缺失值,尤其是重要的指标与基本数据,不得缺失。而试验中观察的阴性结果,测得结果为零和未测出者,均应有相应的符号或数据表示,不能空缺,以便与缺失值区分。缺失值的估计:(1)采用最接近一次观察的结果进行结转(last observation carry forword,LOCF)。(2)最差效果演示(worst-case scenario analysis):即试验组脱落数据按“最差”估计,对照组脱落数据按“最好”估计。前者较符合实际,也较为真实,是统计界较为推荐的方法。后者可能会低估了试验效果,是最为保守的估计,单一旦出现统计意义,其可靠性更好。
8.PP分析与ITT分析:为了提高临床实验分析的可靠性,主张同时采用ITT和PP分析。其意义如果ITT和PP两种分析结论一致,该临床试验受脱落率和失访偏倚的影响较小,其结论较为可信。结果不一致时,认为该临床试验受脱落和失访的影响较大,该实验可靠性不好,应谨慎对待其结论。
Cochrane之第三日听刘关键老师讲统计二
刘老师讲完后,感觉menta分析的统计过程好像并不难,森林图和漏斗图也很好理解,真的用起来可能…老师的讲授真的很神奇!如果你没有听过刘老师教课,以下内容就和普通的书籍一样,如果你是听了课的cochrane班的同学,你一定也全部都懂了。
Meta分析的统计学过程
一、meta分析的定义
meta源于希腊文,意为“more comprehensive”即更广泛、更全面,英国心理学家G.V,Glass 1976年首先将这种多个同类研究的统计量合并方法称为“meta analysis”。
The cochrane library 中的定义:meta分析是文献评价中,将若干个研究结果合并成一个单独数字估计的统计学方法。(meta-analysis is statistical technique for assembling the results of several studies in a review into a single numerical estimate)
二、meta分析的统计目的
1. 传统文献综述的主要问题:传统的文献综述处理同一问题的多个结果报道时,是平等(等权重)的对待每个研究结果而得出的结论,不进行文献评价,也不考虑文献质量。必然存在两个问题:多个同类研究的质量不相同;各个研究样本含量的大小不相等。当多个研究的结果不一致时,其结论容易使人产生误解或困惑。
2. meta分析的统计目的:对多个同类独立研究的结果进行汇总和合并分析,以达到增大样本含量,提高检验效能的目的,尤其是当多个研究结果不一致或都没有统计学意义时,采用meta分析可得到更加接近真实情况的统计分析结果。
三、meta分析的统计学过程
1. meta分析统计过程的主要内容:异质性分析;计算合并效应量;合并效应量的检验(可信区间,Z区间)。
2. 异质性及处理
(1) 什么是异质性:在meta分析过程中,纳入的多个研究尽管都是对同一临床问题或具有相同研究假设的研究。但是,这些研究在纳入和排除标准、样本含量、质量控制等方面很可能不相同,从而导致了同一结局指标在多个研究间有差异,该差异即为异质性。
(2) 异质性的定义:广义上用于描述试验的参与者、试验的干预措施和多个研究测量结果的变异,即各研究的内在真实性变异。专指统计学异质性,用于描述多个研究中效应量的变异程度,也可以用于描述除偶然机会外,多个研究间存在的差异。
(3) 异质性的种类:临床异质性、方法学异质性和统计学异质性
临床异质性:指受试对象不同,干预措施的差异和结局指标的变异所致的偏倚。
方法学异质性:由于试验设计和研究质量的差异引起的,如盲法的应用和分配隐藏的运用,或由于试验过程对结局指标的定义或测量的不一致出现的偏倚。
统计学异质性:干预效果的评价在不同试验间的变异,它是研究见的临床和方法学上变异联合作用的结果。
(4) 统计学异质性:将统计学异质性简称为“异质性”它是以各研究之间可信区间(CI)的合并程度来度量异质性的大小。多个研究间的CI重合程度越大,存在统计异质性的可能性就而笑,反之,各研究之间存在统计学异质性的可能性就越大。
(5) 异质性分析的意义:meta分析的核心计算是合并(相加),按统计原理,只有同质的资料才能进行合并或比较等统计分析。正如1kg不能与1cm相加一样。
(6) 异质性检验(test for heterogeneity)又称为同质性检验(test for homogenenty):用假设检验的方法检验多个独立研究的异质性(同质性)是否具有统计学意义。具体公式不详述。该检验的统计量Q服从自由度为K-1的卡方(x2)分布,因此,当计算得到Q后,需由卡方分析获取概率,故又将此检验叫做卡方检验(Chi square test)。注:不同于计量资料的卡方检验,其统计学界限也不同。当异质性检验结果为P>0.10时,多个研究的异质性无统计学意义,若多个研究结果为P≤0.10时,多个研究的异质性有统计学意义。
(7) I2的计算:描述多个研究间的异质性大小。I2计算公式如下I2=(Q-(k-1))/Q*100%,Q为异质性检验的卡方值x2,k为纳入meta分析的研究个数。
(8) I2的意义:可用于衡量多个研究结果异质性程度的大小,用于描述各个研究间由非抽样误差所引起的变异(异质性)占总变异的百分比。在cochrane系统评价中,只要I2不大于50%,其异质性可以接受。因此I2只能衡量有无,不能区分大小。
(9) 异质性分析与处理的方法:当异质性检验出现P≤0.10时的处理方法
①首先,检查每个研究的原始数据是否正确,检验提取数据的方法是否正确。
②如果产生异质性的原因可能是由于疗程长短、用药剂量、病情轻重及对照选择等所致,可使亚组分析(subgroup analysis)或meta回归。
③敏感性分析,排除某个可能都只异质性的某个研究后,重新做meta分析,与未排除这些研究的meta分析结果比较,探讨被去除的研究对合并效应的影响,通过比较了解其异质性的来源。(必要时与作者取得联系,了解差异产生的原因)
④通过临床知识、统计学知识和前述的异质性分析方法,仍然无法解释产生异质性的原因,可采用随机效应模型(random effect model)进行meta分析。
⑤不做meta分析的几种情况:研究间的异质性无法得到合理的解释;多个研究的合并结果无临床意义;没有足够的、真是的相关研究结果。Meta分析不是必备的,宁愿没有结果,也不要错误的结果!
3. 合并计算效应量的计算
(1) 多个实验效应的合并:将多个独立研究的结果合并成为一个汇总的统计量(overall effect、effect size)或效应尺度(effect magnitude)即用多个独立研究的某个指标的合并机理反映其试验效应。
(2) 合并统计量的两种统计模型:
固定效应模型(fixed effect model):若多个研究具有同质性(无异质性)时,可使用固定效应模型。
随机效应模型(random effect modle):若多个研究不具有同质性时,先对异质性原因进行处理,若异质性分析与处理后仍无法解决异质性时,可使用随机效应模型。
(3) 关于随机效应模型:一种对异质性资料进行meta分析的方法,但是该方法不能控制混杂,也不能校正偏倚或减少异质性,更不能消除产生异质性的原因。(为有了异质性后的解决方法)随机效应模型多采用D-L法,该法不仅可用于分类变量,也适用于数值变量,主要是对权重Wi进行校正。通过增大小样本资料的权重,减少大样本资料的权重来处理资料间的异质性,这种处理存在较大风险。因为小样本资料往往质量较差,偏倚较大,而大样本资料往往质量较好,偏倚较少。因此,经随机效应模型处理的结果,可能削弱了质量好的大样本信息,增大了质量差的小样本信息,故应谨慎使用随机效应模型,对其结论也应当较为委婉。
4. 合并效应量的检验:用假设检验(hypothesis test)的方法检验多个独立研究的总效应量(效应尺度)是否具有统计学意义,其原来与常规的假设检验完全相同。两种方法:u检验(Z test)、卡方检验(Chi square test)。根据z或(u)值或卡方值得到该统计量的概率值,若P≤0.05,多个研究的合并效应量有统计学意义,若P>0.05,多个研究的合并效应量没有统计学意义。
(1)合并效应量的可信区间CI:在meta分析中,常用可信区间进行假设检验,95%的可信区间与α为0.05的假设检验等价,99%的可信区间与α为0.01的假设检验等价。
此外,森林图即是分级各个独立研究的95%可信区间及合并效应量的95%的可信区间绘制的。可信区间的用途:假设检验、参数评估。
(2)RR和OR的森林图(forest plots):无效线竖线的横轴尺度为1,每条横线为该研究的95%可信区间上下限的连线,其线条长短直观地表示了可信区间范围的大小,线条中央的小方块为该研究权重的大小。若某个研究95%的可信区间的线条横跨为无效竖线,即该研究无统计学意义,反之,若横线落在无效竖线的左侧或右侧,该研究有统计学意义。
(3)漏斗图(funnel plots)及用途:最初是用每个研究的处理效应估计值为X值,样本含量的大小为Y轴的简单散点图(scatter plots)。对处理效应的估计,其准确性是随样本含量的增加而增加,小样本研究的效应估计值分布于图的底部,其分布范围较宽,大样本研究的效应估计值分布范围较窄,当没有发表偏倚时,其图形呈对称的倒漏斗状,故称之为“漏斗图”。
Revman中的漏斗图是采用RR或OR对数值(logOR或logRR)为横坐标,OR或RR对数值标准误的倒数1/SE(logRR)为纵坐标沪指的,然后,以真数表明横坐标的标尺,而以SE(logRR)表明纵坐标的标尺。
漏斗图的用途:主要用于观察某个系统评价或meta分析结果是否存在偏倚,如果资料存在偏倚,会出现不对称的漏斗图,不对称越明显,偏倚程度也就越大。
(4)漏斗图不对称的主要原因:发表偏倚pubulication bias、选择性偏倚selection bias、语言偏倚language bias、引用偏倚citation bias、重复发表偏倚multiple pubulication bias
5.关于meta分析的争论:固定与随机效应模型的争论、权重计算方法的不同。
正确应用meta分析:既不能扩大也不能否定meta分析的用途。正确解释menta分析的结果:对任何统计分析的结果,都需结合医学专业知识和统计学知识,对研究结果做出尽可能客观真实的解释。
Cochrane之第四日meta分析所需软件知识及给我们的学术经验
1. 文献检索的基本技能
PubMed、Embase、 Cochrane图书馆、中国学术期刊全文数据库(CNKI)、中文科技期刊全文数据库(VIP)、中国生物医学文献数据库(CBM)。手工检索灰色文献包括会议、毕业论文等。
2. endnote对参考文献的处理及编辑
收费软件,试用版下载地址 http://www.endnote.com/endemo.asp
3. revman软件书写cochrane系统评价及统计学处理
免费软件 http://ims.cochrane.org/reman/download
4. gradeprfile软件评价文献的质量
免费软件 http://ims.cochrane.org/reman/gradepro
5. 安装gradeprfile之前需安装MS network2.0
http://ims.cochrane.org/reman/gradepro中点击microsoft NET framework Version 2.0
如果能真正的写出一篇cochrane的系统评价,以下技能一定运用的非常熟练
1. 文献检索的技能非常强
2. 文献管理及投稿时参考文献的格式规范
3. 参考文献在endnote、revman、gradeprfile等软件中导入导出及转换格式
4. 对RCT试验的设计、书写要点熟练掌握,为以后做RCT试验打下良好的基础。
5. 阅读大量的文献后,对英文的格式及写作再也不发愁了。
6. 培养了严谨、求实的临床科研思维。