编译原理实验报告
姓名:李宏涛 班级:计科(2) 学号:E10620217
基于C语言词法分析器的设计
摘要
首先对编译原理进行概括的介绍,1主要是描写设计内容及设计要求,2介绍设计的基本原理,3对程序设计的总体方案及各模块设计做了介绍,4对程序进行测试。
引言:
《编译原理》是国内外各高等院校计算机科学技术类专业,特别是计算机软件专业的一门重要专业课程。该课程系统地向学生介绍编译程序的结构、工作流程及编译程序各组成部分的设计原理和实现技术。由于该课程理论性和实践性都比较强,内容较为抽象复杂,涉及到大量的软件设计算法,因此,一直是一门比较难学的课程。为了使学生更好地理解和掌握编译技术的基本概念、基本原理和实现方法,实践环节非常重要,只有通过上机进行程序设计,才能使学生对比较抽象的教学内容产生具体的感性认识,增强学生综合分析问题、解决问题的能力,并对提高学生软件设计水平大有益处。
编译原理涉及词法分析,语法分析,语义分析及优化设计等各方面。词法分析(英语:lexical analysis)是计算机科学中将字符序列转换为单词(Token)序列的过程。进行语法分析的程序或者函数被称为词法分析器(Lexical analyzer简称Lexer),也叫扫描器(Scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
词法分析阶段是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符接着一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。词法分析程序实现这个任务。词法分析程序可以使用Lex等工具自动生成。词法分析是所有分析优化的基础,涉及的知识较少,比如状态转换图等,易于实现。本次实验程序设计语言是C语言。
1. 实验内容:
设计一个程序,调试、编译,实现词法分析的功能,识别各单词或字符所属类别,并显示在屏幕上。
(1). 运行词法分析实验一,学习样例程序。
(2). 通过理解正规式、有限自动机原理,编制程序。此程序应具有如下功能:
l 将样例程序中所有注释字母均大写;(即在注释对/*…*/之间的所有字母。);
l 将样例程序加行号。
2.设计方法:
词法分析器:
逐个读入源程序字符并按照构词规则切分成一系列单词。单词是语言中具有独立意义的最小单位,包括保留字、标识符、运算符、标点符号和常量等。词法分析是编译过程中的一个阶段,在语法分析前进行 。也可以和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
要求:利用该词法分析器完成对源程序字符串的词法分析。输出形式是源程序的单词符号二元式的代码,并保存到自己命名的文件中。
单词符号及种别编码

单词符号分类:
单词是程序设计语言的基本语法单位和最小语义单位。单词符号一般分为五大类
(1) 关键字"begin","end","if","then","else","while","write","read",
"do", "call","const","char","until","procedure","repeat"等
(2) 运算符:"+","-","*","/","="等
(3) 界符:"{","}","[","]",";",",",".","(",")",":"等
(4) 标识符
(5) 常量
3. 实验结果图:
初始界面:

显示分析结果:
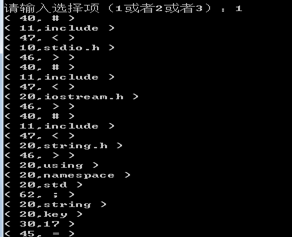
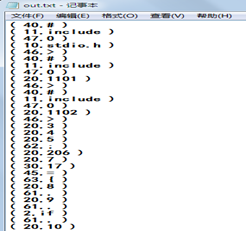
out.txt结果:
换行操作:

结果如图:

实现了显示行号和注释大写
4. 实验代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
struct keywords //关键字结构体
{
char name[10];
int num;
};
struct relation //运算符、关系运算符结构体
{
char name[4];
int num;
};
struct keywords test[18]={
{"main",1},{"if",2},{"int",3},{"for",4},{"while",5},{"do",6},
{"retuen",7},{"break",8},{"continue",9},{"stdio.h",10},
{"include",11},{"case",12},{"float",13},{"switch",14},
{"void",15},{"else",16},{"for",17}
};
struct relation relation[18]={
{"#",40},{"+",41},{"-",42},{"*",43},{"/",44},{"=",45},{">",46},
{"<",47},{">=",48},{"<=",49},{"==",50},{"!",51},{"%",52},{"&",53},
{"&&",54},{"|",55},{"||",56},{"!=",58}
};
struct value //处理变量的结构体
{
int type;
int no;
char str[20];
}value[100];
void options(); //菜单
void analyse(); //分析结果显示
void showcol(); //添加行号
void getch(char ch); //读取为字母
void getnum(char ch); //读取为数字
void getspace(char ch); //读取空格、跳格、回车、换行等等(包括界限符)
void getelse(char ch); //其他类型字符
int variable(char str[10]); //变量处理
char ch='1';
char str[10];
int k=0,i=0;
char sourcefile[30]; //源文件名
char objectfile[30]; //目标文件名
char changefile[30];
FILE *fp,*hp,*cf;
int count=-1;
int flag=-1; //标志
int col;
int main(int argc,char *argv[])
{
int choice;
options(); //显示菜单
printf("输入进行词法分析的源文件名:");
scanf("%s",sourcefile);
printf("\n输入分析结果存入的文件名:");
scanf("%s",objectfile);
printf("\n输入分行结果存入的文件名:");
scanf("%s",changefile);
printf("\n");
printf("请输入选择项(1或者2或者3):");
//printf("\n输入选项:");
scanf("%d",&choice);
for(; ;)
{
switch(choice)
{
case 1:
analyse();
break;
case 2:
showcol();
break;
case 3:
exit(1);
break;
}
break;
}
return 0;
}
void options()
{
printf("***************************\n");
printf("***");
printf(" 《词法分析器》");
printf(" ***\n");
printf("***");
printf(" 1.分析结果:");
printf(" ***\n");
printf("***");
printf(" 2.显示行号:");
printf(" ***\n");
printf("***");
printf(" 3.退出程序:");
printf(" ***\n");
printf("***************************\n");
}
void showcol()
{
if((fp=fopen(sourcefile,"r"))==NULL)
{
printf("读文件打开错误!\n");
exit(1);
}
if((cf=fopen(changefile,"w"))==NULL)
{
printf("写文件打开错误!\n");
exit(1);
}
ch = '1';
col = 1;
fprintf(cf,"%d: ",col++);
while(ch!=EOF)
{
ch = fgetc(fp);
if(ch=='\n') //显示行号
{
fputc(ch,cf);
fprintf(cf,"%d: ",col++);
}
else if(ch=='/') //在/**/内大写
{
fputc(ch,cf);
ch = fgetc(fp);
fputc(ch,cf);
if(ch=='*')
{
do
{
ch = fgetc(fp);
if(ch<='z'&&ch>='a')
{
ch='A'+ch-'a';
fputc(ch,cf);
}
else if(ch=='*')
{
fputc(ch,cf);
ch = fgetc(fp);
if(ch=='/')
{
fputc(ch,cf);
break;
}
else
{
fseek(fp,-1L,1);
}
}
else
fputc(ch,cf);
}while(1);
}
}
else
fputc(ch,cf);
}
fclose(fp);
fclose(cf);
printf("显示行数及大写成功!\n");
system("pause");
}
void analyse()
{
if((fp=fopen(sourcefile,"r"))==NULL) //读取文件
{
printf("读文件打开错误!\n");
exit(1);
}
if((hp=fopen(objectfile,"w"))==NULL) //写入文件
{
printf("写入文件打开错误!\n");
exit(1);
}
/*
if((cf=fopen(changefile,"w"))==NULL) //写入文件
{
printf("写入文件打开错误!\n");
exit(1);
}
*/
while(ch!=EOF) //判断是否到文件结尾
{
ch=fgetc(fp); //读取磁盘字符串
if(((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z')))
{
getch(ch);
}
else
if((ch>='0')&&(ch<='9')) //如果读取的是数字
{
getnum(ch);
}
else
if((ch==' ')||(ch=='\r')||(ch=='\n')||(ch=='\t'))
{
getspace(ch);
}
else //其他情况
{
getelse(ch);
}
k=0; //单个字符标志
str[k]='\0';
};
fclose(fp); //关闭读文件
fclose(hp); //关闭写文件
printf("\n");
system("pause");
}
void getch(char ch)
{
for(; ;)
{
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if( !(( (ch>='a') && (ch<='z') ) || ( (ch>='A') && (ch<='Z') ) || ( (ch>='0') && (ch<='9') )||ch=='.'))
{
fseek(fp,-1L,1);
for(i=0;i<11;i++)
{
if(strcmp(str,test[i].name)==0)
//测试是否为保留字
{
printf("( %d,%s )\n",test[i].num,test[i].name);
fprintf(hp,"( %d,%s )\n",test[i].num,test[i].name);
k=0;
flag=1;
value[count+1].type=test[i].num;
break;
}
}
if(i==11) //否则为变量
{
int tem;
tem=variable(str);
printf("( 20,%s ) \n",str);
fprintf(hp,"( 20,%d )\n",tem);
break;
}
break;
}
}
}
void getnum(char ch)
{
for(; ;)
{
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if( !((ch>='0') && (ch<='9')) )
{
fseek(fp,-1L,1);
printf("( 30,%s ) \n",str);
fprintf(hp,"( 30,%s )\n",str);
break;
}
}
}
void getspace(char ch)
//判断时候是空格、跳格、回车、换行等等
{
for(; ;)
{
ch=fgetc(fp); //检测读取字符
//---换行写序号
//---
if(!((ch==' ')||(ch=='\n')||(ch=='\t')||(ch=='\r')))
{
fseek(fp,-1L,1);
break;
}
}
}
void getelse(char ch)
//其他字符,包括界限符
{
switch(ch)
{
case '.':
printf("( 60, . )\n");
fprintf(hp,"( 60,. )\n");
break;
case '#':
printf("( 40, # )\n");
fprintf(hp,"( 40,# )\n");
break;
case ',':
if(flag==1)
value[count+1].type=value[count].type;
printf("( 61, , )\n");
fprintf(hp,"( 61,, )\n");
break;
case ';':
flag=0;
value[count+1].type=2;
printf("( 62, ; )\n");
fprintf(hp,"( 62,; )\n");
break;
case '{':
printf("( 63, { )\n");
fprintf(hp,"( 63,{ )\n");
break;
case '}':
printf("( 64, } )\n");
fprintf(hp,"( 64,} )\n");
break;
case '(':
printf("( 65, ( )\n");
fprintf(hp,"( 65,( )\n");
break;
case ')':
printf("( 66, ) )\n");
fprintf(hp,"( 66,) )\n");
break;
case '+':
printf("( 41, + )\n");
fprintf(hp,"( 41,+ )\n");
break;
case '-':
printf("( 42, - )\n");
fprintf(hp,"( 42,- )\n");
break;
case '*':
printf("( 43, * )\n");
fprintf(hp,"( 43,* )\n");
break;
case '/':
printf("( 44, / )\n");
fprintf(hp,"( 44,/ )\n");
break;
case '=':
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if(ch!='=')
{
fseek(fp,-1L,1);
printf("( 45, = )\n");
fprintf(hp,"( 45,= )\n");
}
else
if(ch=='=')
{
printf("( 50, = )\n");
fprintf(hp,"( 50,= )\n");
}
break;
case '>':
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if(ch!='=')
{
fseek(fp,-1L,1);
printf("( 46, > )\n");
fprintf(hp,"( 46,> )\n");
}
else if(ch=='=')
{
printf("( 48, > )\n");
fprintf(hp,"( 48,> )\n");
}
break;
case '<':
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if(ch!='=')
{
fseek(fp,-1L,1);
printf("( 47, < )\n");
fprintf(hp,"( 47,0 )\n");
}
else
if(ch=='=')
{
printf("( 49,0 )\n");
fprintf(hp,"( 49,0 )\n");
}
break;
case '!':
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if(ch!='=')
{
fseek(fp,-1L,1);
printf("( 51, != )\n");
fprintf(hp,"( 51,!= )\n");
}
else
if(ch=='=')
{
printf("( 58, != )\n");
fprintf(hp,"( 58,0 )\n");
}
break;
case '%':
printf("( 52, % )\n");
fprintf(hp,"( 52,% )\n");
break;
case '&':
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if(ch!='&')
{
fseek(fp,-1L,1);
printf("( 53, & )\n");
fprintf(hp,"( 53,& )\n");
}
else
if(ch=='&')
{
printf("( 54, && )\n");
fprintf(hp,"( 54,&& )\n");
}
break;
case '|':
str[k]=ch;
str[++k]='\0';
ch=fgetc(fp);
if(ch!='|')
{
fseek(fp,-1L,1);
printf("( 55, | )\n");
fprintf(hp,"( 55,0 )\n");
}
else if(ch=='|')
{
printf("( 56, || )\n");
fprintf(hp,"( 56,|| )\n");
}
break;
}
}
int variable(char str[10])
{
int j;
for(j=0;j<count+1;j++)
if(strcmp(str,value[j].str)==0)
break;
if(j<count+1)
return (value[j].type*100+value[j].no);
else
{
count++;
if(flag==-1)
value[count].type=20;
for(int i=0;i<9;i++)
value[count].str[i]=str[i];
value[count].no=count+1;
return (value[count].type*100+value[count].no);
}
}
5. 实验心得:
通过本次实验,我对词法分析有了更进一步的了解,词法分析阶段是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符接着一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。