案例分析
成员:**
一、研究的目的要求
作为各国经济政策的核心目标,经济增长将意味着就业的扩大,收入的增多,人民生活水平的提高。影响我国经济增长的因素很多,但主要有:(1)消费。(2)投资。(3)出口等因素
二.模型设定
为了了解我国经济增长的影响因素,我们选择国内生产总值GDP作为被解释变量,以反映我国经济的增长;选择我国居民的消费总量反映我过的消费水平的代表;选择我国的投资总额作为反映我国投资水平的代表。
从《中国统计年鉴》中得到一下数据;
下表是1988-20##年间总产出(用国内生产总值GDP度量,单位:亿元),最终消费CS(单位:亿元),投资总额I(用固定资产投资总额度量,单位:亿元):

其中:Y为GDP X:消费支出 T:投资总量
模型假定为:Y=β1+β2Xi+β3Ti+Ui
三、参数估计
进入EViews软件包,确定时间范围;编辑输入数据;选择估计方程菜单,估计样本回归函数如下:
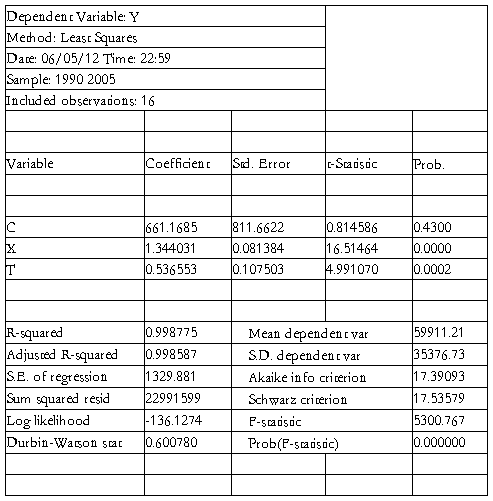
? = 661.1685 + 1.344X + 0.5366T
(0.8146) (16.5146) (4.9911)
R2=0.9988  2=0.9986 F=5301
2=0.9986 F=5301
查t分布表得t0.025(16-3)=2.160,根据运行结果,知X和T的值都大于2.160,只有常数值小于2.160,故可先剔除常数。结果如下。
?=1.344X+0.5366T
可见投资额的回归系数仍然不显著。在此我们剔除T进行回归得结果如下:
?=1.344X
该回归结果表明,投资额虽然对经济增长有很大影响,但实证分析表明,我国经济增长主要取决于消费的增长。
四、模型检验
1、经济意义检验
模型估计结果说明,消费每增加1亿元,我国的GDP就会增长1.344亿元。这与理论分析和经验判断相一致。
2、统计检验
1、(1)拟合优度:由表中数据可以得到:修正的可决系数为0.9986,这说明模型对样本的拟合很好。
2、(2)t检验:给定显著性水平,查t分布表得t0.025(16-2)=2.1448,根据运行结果,知X和T的值分别为16.5146和4.9911,均大于2.1448,说明截距和两个偏斜率均通过显著性检验。
第二篇:eviews课程报告(20xx年度) - 副本
应用时间序列实训
(EVIEWS)(STAN33210P)
课程报告
院 系
专 业
班 级
学生姓名
学 号
任课教师
年 月 日
一、EVIEWS文件的建立(10分)
1、变量的建立,变量中数据的录入
2、删除变量或观察值
3、样本区间的调整
4、变量的排序
5、通过数学运算生成新的变量(取自然对数,一阶差分等常见运算)
二、掌握EVIEWS图形 (10分)
1、单变量的折线图,钉形图、柱形图。
2、对于图形的修饰(给图形设置背景,给图形添加网格线,改变折线图的颜色,在图形中添加文本、直线和阴影)
3、多变量折线图(左右两个纵坐标显示不同的变量,做变量标准化后的折线图,折线交叉或不交叉的设置,如何编辑图例)
4、多变量的扇形图
5、做多变量的散点图(如何修改横轴和纵轴的标签)
6、做多变量的面积图(直观的看人口增长率)
三、单变量描述性统计分析(10分)
1、如何以建立组对象的方式将数据导入到Eviews 中去。
2、如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态分布曲线叠加在一起,从而更直观地观察数据的分布特征。(如何将EViews 图形复制粘贴到word 中)
3、如何在序列窗口下实现描述性统计量的假设检验
4、如何实现将单序列按某一变量分类后再进行描述性统计分析
5、如何实现将单序列按某一变量分类后再进行假设检验
6、如何画上证综指日对数收益率的QQ 图
7、如何估计数据的经验分布函数的参数
8、如何通过打开excel 文件的方式将数据导入到Eviews 中去。
四、多变量描述统计(10分)
1、如何实现多变量的描述性统计量
2、如何实现多变量描述性统计量的假设检验
3、如何计算当前序列组的相关系数矩阵,协方差矩阵
五、一元线性回归模型(10分)
1、做两个变量的散点图,从而看两个变量是否具有线性关系。
2、通过建立方程对象的方式来估计一个方程,并保存我们建立的方程对象。
3、对方程估计结果的解释与评价(拟合优度评价,估计参数和方程的显著性检验)
4、在回归估计结果中显示方程的三种形式(估计命令,回归方程的一般表达式,带有系数估计值的表达式)
5、如何根据我们估计的回归方程计算需求的价格弹性
6、如何查看因变量的实际值、拟合值和回归方程的残差(包括表的形式还有图的形式)
7、如何用建立的方程进行预测,可以进行样本内预测,也可以进行样本外预测。
六、多元回归模型(10分)
1、做以因变量为横轴,多个自变量为纵轴的散点图,简单看一下多个自变量和因变量的关系。为了尽可能多的从散点图里获得信息,1 看标准化后的图。2.左纵坐标显示几个变量,右纵坐标显示几个变量。3.做多个散点图。
2、建立组对象查看自变量的相关系数矩阵。
3、以建立方程对象的方式来建立多元线性回归模型。
4、对模型结果的解释和评价。
5、逐步回归分向前回归和向后回归两种。
6、对消除共线性后的模型进行Wald 系数约束性检验,冗余变量检验,遗漏变量检验,残差的异方差性检验和正态性检验,最后对模型进行解释和评价,查看包含系数估计值的回归方程。
七、非线性模型(10分)
1、通过生成新变量的办法来估计双对数模型。
2、不用生成新变量直接估计双对数模型的线性最小二乘法。估计模型之后对模型进行评价和解释,并做wald 系数约束性检验。
3、直接用非线性最小二乘法估计非线性模型。
4、半对数模型。
5、倒数模型。
八、趋势模型、季节调整、分解与平滑(10分)
1、趋势模型
2、季节调整方法
3、指数平滑方法
九、离散因变量与受限因变量模型(10分)
1、二元选择模型
2、排序选择模型
3、计数模型
4、删截回归模型
5、截尾回归模型
十、时间序列 ARIMA 模型(10分)
1、如何通过观察时间序列的自相关图和偏自相关图来判断时间序列的平稳性。
2、检验序列是否可以通过差分的方式来实现平稳性。
3、通过观察自相关图和偏自相关图对平稳的序列确定AR 和MA 和SAR 的阶数。
4、对估计的模型进行检验,包括显著性检验和残差序列的相关性检验。
5、用我们建立的ARIMA 或SARIMA 模型进行预测。
要求:在计算机EVIEWS程序,能够熟练操作出上述要求,数据可以利用系统逻辑库中自带的数据、可以利用课堂讲义数据,文件自己命名。考试期间随机考核十条知识点,把简要步骤与结果截图复制如下,按要求对结果进行解释。
课程报告评分表
