《 计量经济学》课程综合性实验报告
开课实验室:数学实验室 2012年 12 月 13 日

第二篇:计量学实验报告
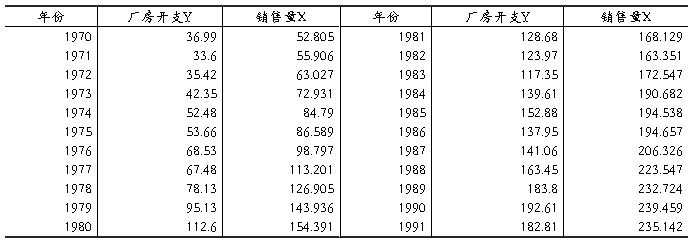
v1970~1991年美国制造业固定厂房设备投资Y和销售量X的相关数据如下表所示。
单位:10 亿美元
1,以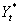 代表理想的货长期的新建厂房设备企业开支,估计如下模型
代表理想的货长期的新建厂房设备企业开支,估计如下模型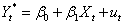
2,如果模型设定为 ,请用存量调整模型进行估计,同(1)中的结果相比,你会选择哪个模型?
,请用存量调整模型进行估计,同(1)中的结果相比,你会选择哪个模型?
3,以 代表理想的销售量,请估计如下的模型:
代表理想的销售量,请估计如下的模型:
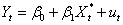
与(1)中的模型相比,你认为哪个模型更合适一些?
【实验步骤】
1,首先打开eview,由于厂房的长期开支是不可预测量,则我们进行如下的局部调整假设:

则原模型变换成为
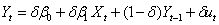
则在模型中进行估计:
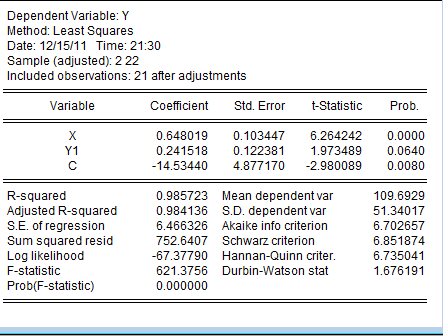
则可以见到如下的数值:
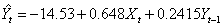
-2.98 6.26 1.97
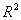 =0.9857
=0.9857 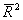 =0.9841 F=621.38 DW= 1.676
=0.9841 F=621.38 DW= 1.676
我们可以发现此时的DW>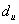 =1.43.但是由于模型之中含有被解释变量的滞后期作为解释变量,姑不能就此判断模型不具有序列相关性,到我们依据拉格朗日乘数方法,得出检验结果中我们发现:
=1.43.但是由于模型之中含有被解释变量的滞后期作为解释变量,姑不能就此判断模型不具有序列相关性,到我们依据拉格朗日乘数方法,得出检验结果中我们发现:

表明该模型确实不存在一阶序列相关性
2,对于原模型进行调整,两边取对数进行局部调整分析,得出如下的模型:
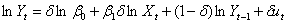
则进行回归分析:
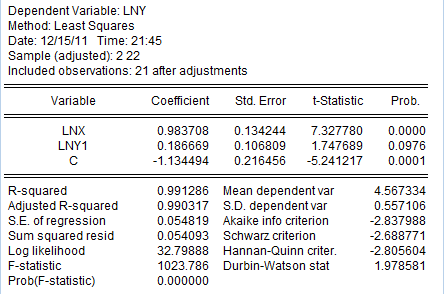
据估计值我们可以看到:
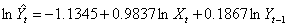
-5.24 7.33 1.75
=0.9912 =0.9903 F=1023.78 DW=1.979
同样的,进行LM检验
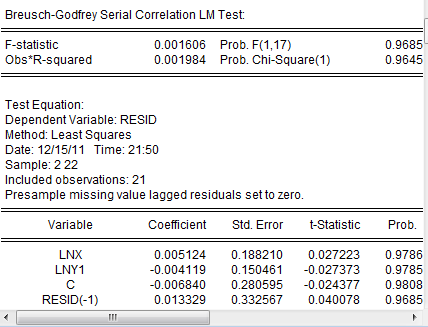
可见模型不存在一阶序列相关性
虽然这里的模型比(1)中的模型的拟合优度高,但是不能就此认为这里的模型就一定要比(1)中的模型,因为二者的被解释变量不一样。为了比较二者,就行如下的变化
首先计算被解释变量的新序列 ,并用它替代原序列,分估计双双对数线性模型与线性模型:
,并用它替代原序列,分估计双双对数线性模型与线性模型:
-0.298 6.26 1.97
=0.9857 =0.9841 F=621.38 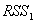 =0.088577
=0.088577
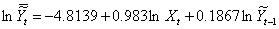
-7.21 7.33 1.75
=0.9912 =0.9903 F=1023.78 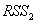 0.054093
0.054093
计算下面服从自由度为1的 分布的统计量:
分布的统计量:
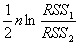 =5.42
=5.42
该数值大于5%显著性水平下自由度为1的分布的临界值为3.84,由此可以知道2中的模型由于1中的模型
3,由于设计解释变量的预期水平,可以作出如下自适应预期假定:
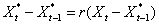
则原模型变成如下的形式:
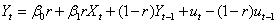
由于该模型存在随机解释变量与滞后期的被解释变量同期相关的问题,无法直接使用OLS进行估计,需采用工具变量法,用 作为
作为 的工具变量,这是因为他们是高度相关的,其次原模型之中的最小二乘假设之中有X和u不存在相关性的假设,则选择Quick→estimate equation 选择equation specification 输入 Y C X Y(-1)选择TSLS,在出现的新结果里面instrument list输入C X X(-1),得到:
的工具变量,这是因为他们是高度相关的,其次原模型之中的最小二乘假设之中有X和u不存在相关性的假设,则选择Quick→estimate equation 选择equation specification 输入 Y C X Y(-1)选择TSLS,在出现的新结果里面instrument list输入C X X(-1),得到:
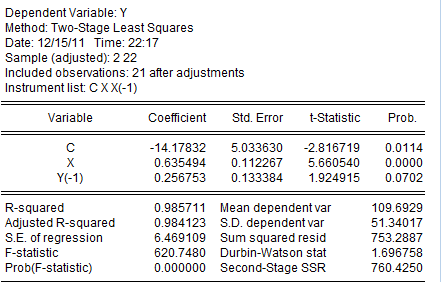
即模型的工具变量法估计结果如下:
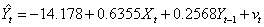
-2.82 5.66 1.92
=0.9857 =0.9841 F=620.75 DW=1.697
再加上LM检验:
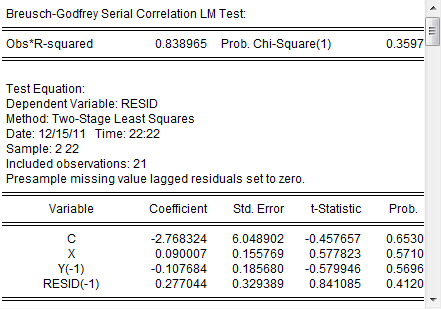
可见此模型已经不存在序列相关性。
从总体上面看来,(1)中的模型不涉及随机解释变量与随机干扰项的同期相关性,而这里涉及,采用了工具变量法,因此综合评定(1)中的模型更加合适一些。