实验1:霍夫曼信源编码综合设计
【实验目的】
通过本专题设计,掌握霍夫曼编码的原理和实现方法,并熟悉利用C语言进行程序设计,对典型的文本数据和图像数据进行霍夫曼编解码。
【预备知识】
1、熵的概念,霍夫曼编码原则
2、数据结构和算法设计
3、C(或C++)编程语言
【实验环境】
1、设备:计算机一台
2、软件:C程序编译器
【设计要求】
根据霍夫曼编码原则,利用C语言设计并实现霍夫曼编码和解码程序,要求能够对给出的典型文本数据和图像数据进行霍夫曼编解码,并计算相应的熵和压缩比。
【实验原理】
Huffman编码属于熵编码的方法之一,是根据信源符号出现概率的分布特性而进行的压缩编码。
Huffman编码的主要思想是:出现概率大的符号用长的码字表示;反之,出现概率小的符号用短的码字表示。
Huffman编码过程描述:
1. 初始化:
将信源符号按出现频率进行递增顺序排列,输入集合L;
2. 重复如下操作直至L中只有1个节点:
(a) 从L中取得两个具有最低频率的节点,为它们创建一个父节点;
(b) 将它们的频率和赋给父结点,并将其插入L;
3. 进行编码 :
从根节点开始,左子节点赋予1,右节点赋予0,直到叶子节点。
【基本定义】
1. 熵和平均编码符号长度
熵是信息量的度量方法,它表示某一事件出现的概率越小,则该事件包含的信息就越多。根据Shannon理论,信源S的熵定义为 ,其中
,其中 是符号
是符号 在S中出现的概率;
在S中出现的概率; 表示包含在中的信息量,也就是编码所需要的位数
表示包含在中的信息量,也就是编码所需要的位数
假设符号编码后长度为li (i=1,…,n),则平均编码符号长度L为:
2. 压缩比
设原始字符串的总长度为Lorig位,编码后的总长度为Lcoded位,则压缩比R为
R = (Lorig - Lcoded)/ Lorig
【例子】
有一幅40个象素组成的灰度图像,灰度共有5级,分别用符号A、B、C、D和E表示,40个象素中出现灰度A的象素数有15个,出现灰度B的象素数有7个,出现灰度C的象素数有7个等等,如表1所示。如果用3个位表示5个等级的灰度值,也就是每个象素用3位表示,编码这幅图像总共需要120位。
表1 符号在图像中出现的数目

根据Shannon理论,这幅图像的熵为
H(S) = (15/40)´ (40/15)+(7/40)´(40/7)+???+(5/40)´(40/5)=2.196
(40/15)+(7/40)´(40/7)+???+(5/40)´(40/5)=2.196
平均编码符号长度L为(15/40)*1+(7/40)*3+(7/40)*3+(6/40)*3+(5/40)*3 = 2.25
根据霍夫曼编码原则可以得到如下的霍夫曼编码表。
表2 霍夫曼编码举例

因而,这副图采用霍夫曼编码的压缩比R为1.3333:1(120:90)。
霍夫曼码的码长虽然是可变的,但却不需要另外附加同步代码。例如,码串中的第1位为0,那末肯定是符号A,因为表示其他符号的代码没有一个是以0开始的,因此下一位就表示下一个符号代码的第1位。同样,如果出现“110”,那么它就代表符号D。如果事先编写出一本解释各种代码意义的“词典”,即码簿,那么就可以根据码簿一个码一个码地依次进行译码。
【实验步骤】(16学时)
根据提供的示例Huffman编译码器源程序,利用VC++6.0进行编译生成可执行文件,阅读并运行程序。
1、用Microsoft Office Vision分别画出Huffman编码和译码程序流程图,写出用到的主要数据结构并加以说明。
2、在Huffman编码器合适位置加入4个函数:calcProbability,calcEntropy,calcAvgSymbolLength,calcCompressionRatio,分别计算信源各符号出现的概率、信源的熵、平均编码符号长度以及压缩比。(自定义函数的参数)
3、分析霍夫曼编译码码的计算复杂度,定量说明Huffman编码和译码哪种操作更耗时?
4、设计中遇到的问题,怎样解决问题的。在设计过程中的心得体会。
思考题:
1、霍夫曼编码是否具有唯一性?
2、个人对霍夫曼编码方式的不足之处的思考以及怎么样在进行压缩时避免这些问题。
3、分析霍夫曼编码对文本数据以及图象数据的编码效率,观察与对应信源概率分布的关系。
4、参考静止图像压缩编码国际标准JPEG,为了提高对图像编码的效率,通常要在霍夫曼编码之前进行什么操作?
5、。
【实验结果】
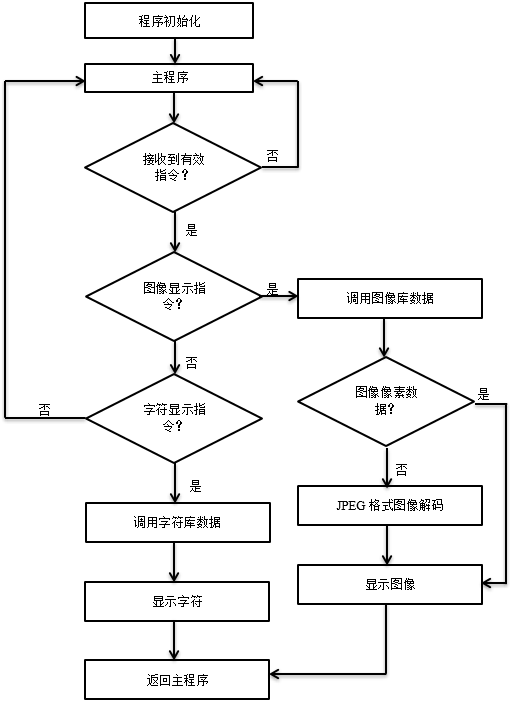
一.译码与编码流程图如下所示:
1.译码流程图
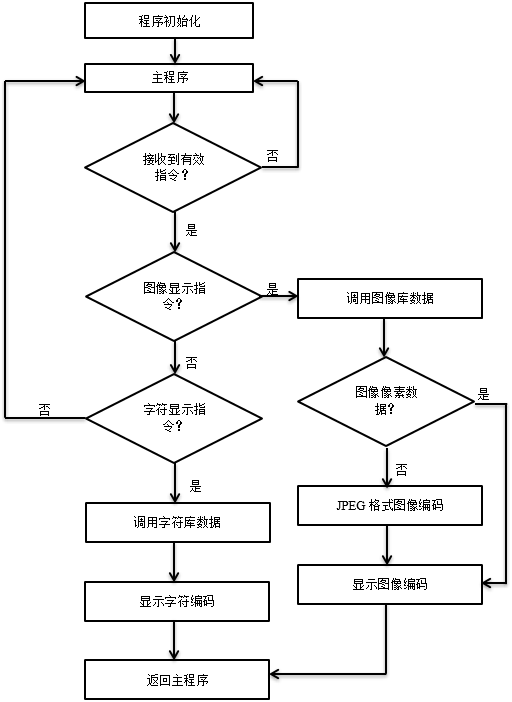
2.编码流程图
二.四个部分的程序
1.计算每个个符号出现的概率
void calcProbability(int total, SymbolFrequencies *pSF)
{
int i;
float prob[MAX_SYMBOLS];
memset(prob, 0, sizeof(prob));
for(i = 0; i < MAX_SYMBOLS; ++i)
{
if((*pSF)[i])
{
prob[i] = (float)(*pSF)[i]->count / total;
printf("%c, %f\n", (*pSF)[i]->symbol, prob[i]);
}
}
}
2.计算熵
void calcEntrop(SymbolFrequencies *pSF)
{
int i;
float prob[MAX_SYMBOLS];
double entropy;
double difference;
double difference1;
double difference2;
entropy = 0;
for(i = 0; i < MAX_SYMBOLS; ++i)
{
difference1 = log(prob[i]);
difference2 = log(2);
difference = difference1/difference2;
entropy = entropy - prob[i]*difference;
}
printf(" %f\n", entropy);
}
3.计算平均长度
void calcAvgSymbolLength(SymbolFrequencies *pSF, *bits[MAX_SYMBOLS])
{
int i;
double AvgSymbolLength;
AvgSymbolLength = 0;
for(i = 0; i < MAX_SYMBOLS; ++i)
{
AvgSymbolLength = AvgSymbolLength + prob[i]*numbytes[i];
}
printf(" %f\n", AvgSymbolLength);
}
4.计算压缩比
void calcCompressionRatio(int total, AvgSymbolLength)
{
doubule Ratio;
doubule CompressionRatio;
Ratio = total – AvgSymbolLength* MAX_SYMBOLS;
CompressionRatio = Ratio/total;
}
三. 分析耗时
从Huffman编码和译码的代码相比较,可以看出译码的操作更加耗时。
四.遇到的问题
在这次实验中,由于以前并没有学过C++,所以在编程期间遇到很多基础性的问题,对于语言的运用不熟悉,所以导致在写出代码之后编译很久都不成功,但是在老师的辅导下,还是可以做出来一些成果,对于C++的运用有了一定的了解和运用。虽然在这次实验中,并没有将老师所布置的任务全部完成,但是在经过了将近三个星期的反复调试,将最基础最简单的任务完成了。其中或许有些错误,但是已经是尽了全力去完成的。
五.思考题
1.霍夫曼编码是否具有唯一性?
答:霍夫曼信源不具有唯一性,可将1与0交换。
2.参考静止图像压缩编码国际标准JPEG,为了提高对图像编码的效率,通常要在霍夫曼编码之前进行什么操作?
答:参考静止图像压缩编码国际标准JPEG,为了提高对图像编码的效率,通常要在霍夫曼编码之前进行数据压缩。
3.通过本综合设计,谈谈对“算法+数据结构=程序”的认识
答:程序是计算机指令的某种组合,控制计算机的工作流程,完成一定的逻辑功能,以实现某种任务;算法是程序的逻辑抽象,是解决某类客观问题的数学过程;在这里,数据结构具有两个层面上的涵义--逻辑结构和物理结构:客观事物自身所具有的结构特点,我们将其称之为逻辑结构。算法的确定依赖于数据结构的选择,数据结构的选择制约于算法设计的复杂程度--算法 + 数据结构 = 程序。
第二篇:霍夫曼编码的matlab实现(信源编码实验)
重庆交通大学信息科学与工程学院
综合性设计性实验报告
专 业 班 级:通信工程2012级1班
学 号: 631206040118
姓 名: 王松
实验所属课程: 信息论与编码
实验室(中心): 软件与通信实验中心
指 导 教 师 : 黄大荣
20##年4月

霍夫曼编码的matlab实现
一、实验目的和要求。
利用哈夫曼编码进行通信可以大大提高信道的利用率,缩短信息传输的时间,降低传输成本。
本实验用Matlab语言编程实现霍夫曼(Huffman)编码。
二、实验原理。
霍夫曼(Huffman)编码算法是满足前缀条件的平均二进制码长最短的编-源输出符号,而将较短的编码码字分配给较大概率的信源输出。算法是:在信源符号集合中,首先将两个最小概率的信源输出合并为新的输出,其概率是两个相应输出符号概率之和。这一过程重复下去,直到只剩下一个合并输出为止,这个最后的合并输出符号的概率为1。这样就得到了一张树图,从树根开始,将编码符号1 和0 分配在同一节点的任意两分支上,这一分配过程重复直到树叶。从树根到树叶途经支路上的编码最后就构成了一组异前置码,就是霍夫曼编码输出。
离散无记忆信源:
例如

U u1 u2 u3 u4 u5
P(U) = 0.4 0.2 0.2 0.1 0.1

通过上表的对信源缩减合并过程,从而完成了对信源的霍夫曼编码。
三、实验步骤
分为两步,首先是码树形成过程:对信源概率进行合并形成编码码树。然后是码树回溯过程:在码树上分配编码码字并最终得到霍夫曼编码。
1、码树形成过程:将信源概率按照从小到大顺序排序并建立相应的位置索引。然后按上述规则进行信源合并,再对信源进行排序并建立新的位置索引,直到合并结束。在这一过程中每一次都把排序后的信源概率存入矩阵G中,位置索引存入矩阵Index中。这样,由排序之后的概率矩阵 G以及索引矩阵Index就可以恢复原概率矩阵P了,从而保证了回溯过程能够进行下去。
2、码树回溯过程:在码树上分配编码码字并最终得到Huffman 编码。从索引矩阵M 的末行开始回溯。
(1) 在Index的末行2元素位置填入0和1。
(2) 根据该行索引1 位置指示,将索引1 位置的编码(‘1’)填入上一行的第一、第二元素位置,并在它们之后分别添加‘0’和‘1’。
(3) 将索引不为‘1’的位置的编码值(‘0’)填入上一行的相应位置(第3 列)。
(4) 以Index的倒数第二行开始向上,重复步骤(1) ~ (3),直到计算至Index的首行为止。
四、程序代码:
%取得信源概率矩阵,并进行合法性判断
clear;
P=input('请输入信源概率向量P=');
N=length(P);
for component=1:1:N
if(P(component)<0)
error('信源概率不能小于0');
end
end
if((sum(P)-1)>0.0001)
error('信源概率之和必须为1');
end
%建立各概率符号的位置索引矩阵Index,利于编码后从树根进行回溯,从而得出对应的编码
Q=P
Index=zeros(N-1,N); %初始化Index
for i=1:N-1
[Q,L]=sort(Q);
Index(i,:)=[L(1:N-i+1),zeros(1,i-1)];
G(i,:)=Q;
Q=[Q(1)+Q(2),Q(3:N),1]; %将Q中概率最小的两个元素合并,元素不足的地方补1
end
%根据以上建立的Index矩阵,进行回溯,获取信源编码
for i=1:N-1
Char(i,:)=blanks(N*N);%初始化一个由空格符组成的字符矩阵N*N,用于存放编码
end
%从码树的树根向树叶回溯,即从G矩阵的最后一行按与Index中的索引位置的对应关系向其第一行进行编码
Char(N-1,N)='0';%G中的N-1行即最后一行第一个元素赋为0,存到Char中N-1行的N列位置
Char(N-1,2*N)='1';%G中的N-1行即最后一行第二个元素赋为1,存到Char中N-1行的2*N列位置
%以下从G的倒数第二行开始向前编码
for i=2:N-1
Char(N-i,1:N-1)=Char(N-i+1,N*(find(Index(N-i+1,:)==1)) -(N-2):N*(find(Index(N-i+1,:)==1)));
%将Index后一行中索引为1的编码码字填入到当前行的第一个编码位置
Char(N-i,N)='0'; %然后在当前行的第一个编码位置末尾填入'0'
Char(N-i,N+1:2*N-1)=Char(N-i,1:N-1); %将G后一行中索引为1的编码码字填入到当前行的第二个编码位置
Char(N-i,2*N)='1'; %然后在当前行的第二个编码位置末尾填入'1'
for j=1:i-1
%内循环作用:将Index后一行中索引不为1处的编码按照左右顺序填入当前行的第3个位置开始的地方,最后计算到Index的首行为止
Char(N-i,(j+1)*N+1:(j+2)*N)=Char(N-i+1,N*(find(Index(N-i+1,:)==j+1)-1)+1:N*find(Index(N-i+1,:)==j+1));
end
end
%Char中第一行的编码结果就是所需的Huffman 编码输出,通过Index中第一行索引将编码对应到相应概率的信源符号上。
for i=1:N
Result(i,1:N)=Char(1,N*(find(Index(1,:)==i)-1)+1:find(Index(1,:)==i)*N);
end
%打印编码结果
String='信源概率及其对应的Huffman编码如下';
disp(String);disp(P);disp(Result);
五、对比分析,通过给给定不同的信源,对结果进行分析对比验证,并得出相应分分析报告。
以[0.1,0.2,0.3,0.2,0.1,0.1]为例:
运行程序,结果如下

以[0.3 0.3 0.2 0.1 0.1]为例:
运行程序,结果如下
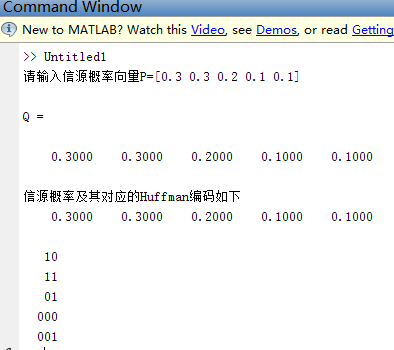
分析:由上图可知程序已完成了Huffman编码的功能,但是霍夫曼编码是不唯一的.因为:信源符号合并中遇到最小概率相同的情况时可任意选择来做合并;在码树分配编码码字的时候1 和0 的位置可以是任意的。
六:提交实验报告。
1、在该实验的过程中,利用一个矩阵记录每次排序前概率的所在位置,是该实验的关键,在编码的过程中利用该矩阵就能比较容易进行huffman编码。
2、通过这个实验,对huffman编码的具体实现原理了解的更加深刻,在实验的过程中也遇到了一些问题,通过查找资料和相关书籍得到了解决,通过此次试验,了解了Huffman编码的特点,能够运用Huffman编码的基本原理及编码算法的来设计与实现程序。收获颇多,为以后更进一步学习奠定了基础, 总的来说,在完成该实验的过程中,学到了比较多的知识,包括使对一些matlab语句的掌握的更加熟练,完成一个算法必须要有一个整体的把握等等。
3、通过本次课程设计,我对二叉树和huffman编码树有了更深的了解,在做课程设计的过程中我掌握了二元huffman编码树的构造方法,哈夫曼编码是一种变长的编码方案。它由最优二叉树既哈夫曼树得到编码,码元内容为到根结点的路径中与父结点的左右子树的标识。所以哈夫曼在编码在数字通信中有着重要的意义。可以根据信源符号的使用概率的高低来确定码元的长度。既实现了信源的无失真地编码,又使得编码的效率最高。