数据结构实验报告
实验名称: 实验3——树(哈夫曼编/解码器)
学生姓名:
班 级:
班内序号:
学 号:
日 期: 20##年12月5日
1. 实验要求
利用二叉树结构实现哈夫曼编/解码器。
基本要求:
1、 初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立哈夫曼树
2、 建立编码表(CreateTable):利用已经建好的哈夫曼树进行编码,并将每个字符的编码输出。
3、 编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4、 译码(Decoding):利用已经建好的哈夫曼树对编码后的字符串进行译码,并输出译码结果。
5、 打印(Print):以直观的方式打印哈夫曼树(选作)
计算输入的字符串编码前和编码后的长度,并进行分析,讨论哈夫曼编码的压缩效果。
并用I love data Structure, I love Computer。I will try my best to study data Structure.进行测试。
2. 程序分析
哈夫曼树结点的存储结构包括双亲域parent,左子树lchild,右子树rchild,还有字符word,权重weight,编码code
对用户输入的信息进行统计,将每个字符作为哈夫曼树的叶子结点。统计每个字符出现的次数作为叶子的权重,统计次数可以根据每个字符不同的ASCII码,根据叶子结点的权重建立一个哈夫曼树。
建立每个叶子的编码从根结点开始,规定通往左子树路径记为0,通往右子树路径记为1。由于编码要求从根结点开始,所以需要前序遍历哈夫曼树,故编码过程是以前序遍历二叉树为基础的。同时注意递归函数中能否直接对结点的编码域进行操作。
编码信息只要遍历字符串中每个字符,从哈夫曼树中找到相应的叶子结点,取得相应的编码。最后再将所有找到的编码连接起来即可。
译码则是将编码串从左到右逐位判别,直到确定一个字符。这就是哈夫曼树的逆过程。遍历编码串,从哈夫曼树中找到相应的叶子结点,取得相应的字符再将找到的字符连接起来即可。
2.1 存储结构
哈夫曼树结点存储结构

2.2 关键算法分析
1.统计字符频度
自然语言描述:
(1) 取出字符串中的一个字符
(2) 遍历所有初始化的哈夫曼树结点
(3) 如果结点中有记录代表的字符且字符等于取出的字符,说明该字符的叶子存在,则将该结点的权值加1
(4) 如果所有结点记录的字符均没有与取出的字符一致,说明该字符的叶子不存在,则将结点的字符记为取出字符,并将权重设为1
(5) 重复以上步骤,直至字符串中所有字符全部遍历
伪代码描述:
1. for(int i=0;i
1.1 for (int j=0;j
1.1.1if (WordStr[i]==HuffTree[j].word)//若字符已被统计,则增加权值即可
1.1.1.1 权重++;
1.1.1.2 break;
1.1.2 else if(!HuffTree[j].word)//否则需要一个新结点储存这个字符
1.1.2.1 HuffTree[j].word=WordStr[i];
1.1.2.2 HuffTree[j].weight=1;
1.1.2.3 叶子结点个数++;
1.1.2.4 break;
时间复杂度O(n2),空间复杂度S(0)
2. 构造哈夫曼树
自然语言描述:
(1) 选出权值最小的两个结点,其权值和作为其根结点的权值,最小的结点作为左子树,次小的作为右子树,不断将两棵子树合并为一棵树。
(2) 重复上述过程,直至所有结点全被遍历完
伪代码描述:
1. int leaves=n;
2.for (int j=n;j<2*n-1;j++)
2.1 int j1=0;int j2=0;
2.2 Select(HuffTree,leaves,j,j1,j2);//选出两个权值最小结点
2.3 HuffTree[j1].parent=j;HuffTree[j2].parent=j;
2.4 HuffTree[j].weight=HuffTree[j1].weight+HuffTree[j2].weight;//根结点权值等于两个结点权值和
2.5 HuffTree[j].lchild=j1;HuffTree[j].rchild=j2;//左子树为权值最小,右子树权值次小
2.6 叶子数--;
时间复杂度O(n),空间复杂度S(2)
3. 为每个叶子结点编码
自然语言描述:
(1) 初始化一个字符数组Code暂存每个叶子结点的编码。
(2) 前序遍历哈夫曼树
(3) 若结点左右子树都为-1,则将code复制到编码的code串,准备返回上一层,编码相应少一位,code长度减1,返回
(4) 否则按照从左到右的顺序前序遍历根结点的所有子树
(5) 若访问左子树,则进入下一层,编码相应多一位,code长度加1并将最后一位赋0;访问右子树,进入下一层,code长度加1并将最后一位赋为0
伪代码描述:
1.if 结点左右孩子均为-1
1.1.将Code复制到huffTree的code
1.2.return;
1.3.否则
1.3.1.if结点左子树存在
1.3.1.1.Code长度增一
1.3.1.2.Code最后一位赋0;
1.3.1.3.访问左子树;
1.3.1.4.层数减一;
1.3.2.If结点右子树存在
1.3.2.1.Code长度增一
1.3.2.2.Code最后一位赋1;
1.3.2.3.访问右子树;
1.3.2.4.层数减一;
算法时间复杂度O(n2),空间复杂度S(60)
4. 编码
自然语言描述:
(1) 定义字符串CodeStr储存编码
(2) 遍历输入字符串的每一个字符
(3) 对每一个字符,将其与HuffTree前n个叶子结点的word逐个比较,相同则将该结点的编码串code连接到CodeStr的末尾
(4) 遍历结束后,输出CodeStr
伪代码描述:
1. while(字符串字符不为0)
1.1 while(叶子结点word不为空)
1.1.1 if(字符等于word中的字符)
1.1.1.1 strcat(CodeStr,code);
1.1.1.2.break;
2. cout<
算法时间复杂度O(n2) ,空间复杂度S(2)
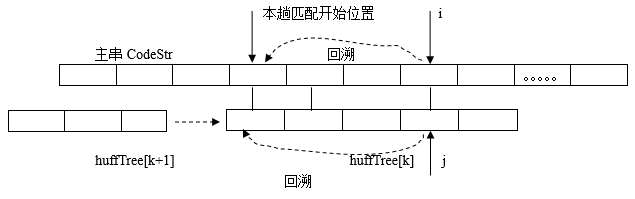
5. 译码
自然语言描述:
(1) 从编码串CodeStr的第一个字符开始与HuffTree第一个结点的编码域第一个字符比较
(2) 相等则继续比较后面的字符
(3) 否则,从CodeStr第一个字符与HuffTree第二个结点的编码比较
(4) 重复上述过程,将CodeStr中的所有字符比较完毕
伪代码描述:
1.在CodeStr和huffTree.code中设比较的起始下标i和j
2.遍历数组huffTree
2.1.循环至CodeStr或huffTree.code全部的字符均比较完
2.1.1.如果CodeStr[i]=huffTree[k].code,继续比较下一个字符,否则
2.1.2.将i和j回溯,跳出该层循环
2.2如果huffTree[k].code全比较完,输出huffTree[k].word。否则取huffTree下一个结点继续循环
时间复杂度O(n2),空间复杂度S(3)
3. 程序运行结果

测试条件:问题规模n的数量级为1。
测试内容:I love data Structure, I love Computer. I will try my best to study data Structure.
测试结论:测试的功能有:建立哈夫曼树、对每个字符进行编码、对信息字符串进行编码、对编码串进行译码,重新进行编码。各项功能均能正常运行。界面的跳转也能实现。
编码前信息总长度为664bits,编码后的长度为339bits。由于哈夫曼编码采用不等长编码,有效缩短了编码长度,节省了空间。
4. 总结
调试时出现的问题及解决的方法
递归函数中的参数传递
在给每个字符编码时,由于编码是从根结点开始,所以选用与前序遍历相似的递归遍历形式。其中需要一个字符型数组来记录路径和编码,由于递归一次才有一位编码,所以这个数组也要随着递归函数的进行而不断修改。开始时我没有用指针最为参数而是直接将数组作为参数,结果发现每次调用递归函数时数组都是空。原来我用的是值传递,数组就算修改了也无法返回。这提醒了我之后运用递归函数时如果需要某个变量随函数递归而修改时应该使用地址传递而非值传递。
心得体会
哈夫曼树又称做最优二叉树,它是n个带权叶子结点构成的所有二叉树中,带权路径长度WPL最小的二叉树。在n个带权叶子结点所构成的二叉树中,满二叉树或完全二叉树不一定是最优二叉树。权值越大的结点离树根越近的二叉树才是最优二叉树。哈夫曼树是根据字符出现的概率来构造平均长度最短的编码。它是一种变长的编码。在编码中,若各码字长度严格按照码字所对应符号出现概率的大小的逆序排列,则编码的平均长度是最小的。
哈夫曼树的应用非常广泛,在通信中,采用0,1的不同排列来表示不同的字符,而哈夫曼树在数据编码中的应用,若每个字符出现的频率相同,则可以采用等长的二进制编码,若频率不同,则可以采用不等长的二进编码,频率较大的采用位数较少的编码,频率较小的字符采用位数较多的编码,这样可以使字符的整体编码长度最小,哈夫曼编码就是一种不等长的二进制编码,且哈夫曼树是一种最优二叉树,它的编码也是一种最优编码,在哈夫曼树中,规定往左编码为0,往右编码为1,则得到叶子结点编码为从根结点到叶子结点中所有路径中0和1的顺序排列。
下一步的改进
程序中多次使用了遍历数组或对数据进行逐个比对,循环的次数可以通过计算再减少,提高时间效率。