实验3:霍夫曼编码

第二篇:哈夫曼编码-信息论课程设计
信 息 论 课 程 设 计 实 验 报 告 1 专业班级:信计0802 姓名:刘建勋 学号:0808060217
目录:
1.课题描述-----------------------------------------------------------------------------------------3
2.信源编码的相关介绍---------------------------------------------------------------------3
3.哈夫曼编码-------------------------------------------------------------------------------------3
3.1 哈夫曼编码算法-----------------------------------------------------------------------3
3.2 哈弗曼编码的特点--------------------------------------------------------------------4
3.3 哈夫曼实验原理----------------------------------------------------------------------- 4
4.哈夫曼编码的C++实现-----------------------------------------------------------------5
4.1 程序设计-----------------------------------------------------------------------------------5
4.2 运行结果-----------------------------------------------------------------------------------8
总结-----------------------------------------------------------------------------------------------------8
参考文献-------------------------------------------------------------------------------------------------8
2
1.课题描述
实验类别:
设计性实验
实验目的:
掌握哈夫曼编码原理;
了解哈夫曼码的最佳性;
实验内容:
编程实现二元huffman编码;
2.信源编码的相关介绍:
信源编码的基础是信息论中的两个编码定理:无失真编码定理和限失真编码定理,前者是可逆编码定理的基础。可逆是指当信源符号转换成代码后,可从代码无失真的恢复信源符号。当已知信源符号的概率特性时,可计算它的符号熵,这表示每个信源符号所载的信息量。编码定理不仅证明了必定存在一种编码方法,可是代码的平均长度可任意接近但不低于符号熵,而且还阐明达到这目标的途径,这就是使概率和码长相匹配。无失真编码和可逆编码只适用于离散信源。对于连续信源,编程代码后就无法无失真的恢复原来的连续值,因为后者的取值可有无限多个。此时只能根据率失真编码定理在失真受限制的情况下进行限失真编码。信源编码定理出现以后,编码方法就趋于合理化。
3.哈夫曼编码:
3.1哈夫曼编码算法:
递归算法
void HFMCoding(Tree &HFMnode, HFMCode, int *m2, int n) {
int i, j, m1, m2 ,x1, x2, Init;
char *cd;
unsigned int c, f;
if (n<=1) return;
m1 = 2 * n - 1;
HFMnode = (Tree)malloc((m+1) * sizeof(HTNode));
for (i=1; i<=n; i++) { //初始化
HFMnode [i].probability=m2[i-1];
HFMnode [i].parent=0;
HFMnode [i].lchild=0;
HFMnode [i].rchild=0;
}
for (i=n+1; i<=m; i++) { //初始化
HFMnode [i].probability=0;
HFMnode [i].parent=-1;
HFMnode [i].lchild=-1;
HFMnode [i].rchild=-1; }
printf("\n哈夫曼树的构造过程如下所示:\n");
printf("HT初态:\n 结点 probability parent lchild rchild");
for (i=1; i<=m; i++)
printf("\n%f%f%f%f%f",i,HT[i]. probability
HFMnode [i].parent, HFMnode[i].lchild, HFMnode [i].rchild);
3
getch();
for (i=n+1; i<=m; i++) { // 建哈夫曼树
Select( HFMnode, i-1, x1, x2);
HFMnode [x1].parent = i; HFMnode [x2].parent = i;
HFMnode [i].lchild = x1; HFMnode [i].rchild = x2;
HFMnode [i]. probability = HFMnode [x1]. probability+ HFMnode [x2]. probability; printf("\nselect: x1=%f x2=%f\n", x1, x2);
printf(" 结点 probability parent lchild rchild");
for (j=1; j<=i; j++)
printf("\n%f%f%f%f%f",j,HT[j]. probability t,
HT[j].parent,HT[j].lchild, HT[j].rchild);
}
cd = (char *)malloc(n*sizeof(char)); // 分配求编码的工作空间
cd[n-1] = '\0'; // 编码结束符。
for (i=1; i<=n; ++i) { // 逐个字符求哈夫曼编码
Init = n-1; // 编码结束符位置
for (c=i, f=probability [i].parent; f!=0; c=f, f=probability [f].parent)
// 从叶子到根逆向求编码
if (probability [f].lchild==c) cd[--Init] = '0';
else cd[--Init] = '1';
HFMCode [i] = (char *)malloc((n- Init)*sizeof(char));
// 为第i个字符编码分配空间
strcpy(HFMCode [i], &cd[Init]);
}
free(cd); // 释放工作空间
}
3.2哈夫曼编码的特点:
(1)利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
(2)编出来的码都是异字头码,保证了码的唯一可译性。
(3) 由于编码长度可变。因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。
(4) 编码长度不统一,硬件实现有难度。
(5) 对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。
(6) 由于"0"与"1"的指定是任意的,故由上述过程编出的最佳码不是唯一的,但其平均码长是一样的,故不影响编码效率与数据压缩性能。
3.3哈夫曼实验原理:
二元哈夫曼码编码:
(1)将q个信源符号按概率分布P(si)的大小,以递减次序排列起来,设p1≥p2≥p3≥…≥pq
(2)用0和1码符号分别代表概率最小的两个信源符号,并将这两个概率最小的信源符号合并成一个符号,从而得到只包含q-1个符号的信源,称为S信源的缩减信源S1。
(3)把缩减信源S的符号仍按概率大小以递减次序排列,再将其最后二个概率最小的符 4
号合并成一个符号,并分别用0和1码符号表示,这样又形成了q-2个符号的缩减信源S2。
(4)依此继续下去,直至信源最后只剩两个符号为止。将这两个最后的信源符号分别用0和1码符号表示然后从最后一级缩减信源开始,向前返回,就得出各信源符号所对应的码符号序列,即得对应的码字。
4.哈夫曼编码的c++实现
4.1程序设计:
#include <iostream>
#include<math.h>
using namespace std;
#define leafnode 10 //叶子节点个数
#define node 2*leafnode-1 //结点数
#define maxbit 10
#define maxvalue 1
using namespace std;
float a[10];
typedef struct { //信息结构
int type[maxbit];
int Init; //节点的初始位置
}HFMcodetype;
typedef struct { //树结点结构
float probability; //概率
float parent;
float lchild;
float rchild;
}HFMnodetype;
void tree(HFMnodetype HFMnode[node],int n) //构造哈夫曼树的函数
{
int i,j,m1,m2,x1,x2;
float a[10];
for(i=0;i<2*n-1;i++)
{
HFMnode[i].probability=0;
HFMnode[i].parent=-1;
HFMnode[i].lchild=-1;
HFMnode[i].rchild=-1;
}
for(i=0;i<n;i++)
{
cout<<"a["<<i<<"]的概率=";
cin>>HFMnode[i].probability;
float Ia,Hp;
5
Ia=-log10(a[i])/log10(2);
Hp=a[i]*Ia;
}
for(i=0;i<n-1;i++)
{
m1=m2=maxvalue;
x1=x2=0;
for(j=0;j<n+i;j++)
{
if(HFMnode[j].probability<m1&&HFMnode[j].parent==-1)
{
m2=m1;x2=x1;m1=HFMnode[j].probability;x1=j;
}
else if(HFMnode[j].probability<m2&&HFMnode[j].parent==-1)
{
m2=HFMnode[j].probability;x2=j;
}
}
HFMnode[x1].parent=n+i;
HFMnode[x2].parent=n+i;
HFMnode[n+i].probability=HFMnode[x1].probability+HFMnode[x2].probability; HFMnode[n+i].lchild=x1;
HFMnode[n+i].rchild=x2;
}
}
void main()
{
cout<<"*****************************************"<<endl;
cout<<"编写者:刘建勋"<<endl;
cout<<"题目:编程实现二元huffman编码"<<endl;
cout<<"*****************************************"<<endl;
float Hp,k=0,y;
HFMnodetype HFMnode[node];
HFMcodetype HFMcode[leafnode],cd;
int i,j,c,p,m,mz;
cout<<"信源的符号数:\n";
cout<<"m=";
cin>>m;
tree(HFMnode,m);
for(i=0;i<m;i++)
{
cd.Init=m-1;c=i;
6
p=HFMnode[c].parent;
while(p!=-1)
{
if(HFMnode[p].lchild==c) cd.type[cd.Init]=0; else cd.type[cd.Init]=1;
cd.Init--;c=p;
p=HFMnode[c].parent;
}
for(j=cd.Init+1;j<m;j++)
HFMcode[i].type[j]=cd.type[j];
HFMcode[i].Init=cd.Init;
}
for(i=0;i<m;i++)
{
cout<<"a["<<i<<"]=的码符号序列为:"; for(j=HFMcode[i].Init+1;j<m;j++) cout<<HFMcode[i].type[j];
cout<<"\n";
//cout<<"mz="<<mz<<endl;
mz=sizeof(HFMcode[i].type[j]);
k=k+a[i]*mz;
}
y=Hp/k;
cout<<"编码效率\ny="<<y<<endl; } HFMcode[i].type[j]=cd.type[j];
HFMcode[i].Init=cd.Init;
}
for(i=0;i<m;i++)
{
cout<<"a["<<i<<"]=的码符号序列为:"; for(j=HFMcode[i].Init+1;j<m;j++) cout<<HFMcode[i].type[j];
cout<<"\n";
//cout<<"mz="<<mz<<endl;
mz=sizeof(HFMcode[i].type[j]);
k=k+a[i]*mz;
}
y=Hp/k;
cout<<"编码效率\ny="<<y<<endl; }
7
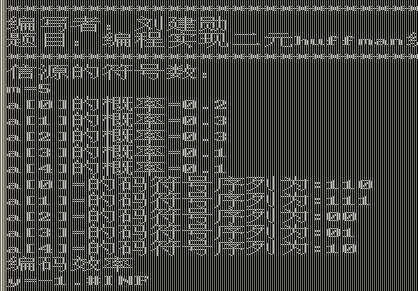
4.2运行结果:
总结:
哈夫曼的具体实现,在信息论及其相关相关课程做相应的实验,所以无论在理解上或是实现上,都不是很困难,程序上实现哈夫曼的编码与译码,由于哈夫曼自身的特点,编码与译码均不是唯一,但是相同的编译码规则还是能实现正确的译码的。总的来说,通过本次实验,对哈夫曼的编译码有了一个更好的认识。
通过本次试验,对书上的理论知识有了进一步的认识,但是由于对编程软件的知识欠缺,导致有很多地方还是搞不懂,只能向同学学习,讨论。当然最终还是有一定的欠缺。
对于哈夫曼编码的认识,是在以前的数据结构课程中就接触到的,但是当时只是知道哈夫曼树的编码而已。仅限于表面上的只是,并未曾想过用程序来实现它。所以对于此次试验并未有太大的帮助。
通过实验,学到了很多东西,相信对以后的学习会更有帮助的。
参考文献:曹雪虹,张宗橙,2009,信息论与编码,清华大学出版社,85—100 8