数据结构实验报告
实验名称:实验3——哈夫曼树
学生姓名:XXX
班 级:
班内序号:
学 号:
日 期: 20##年12月1日
1.实验要求
【实验目的】
通过选择下面两个题目之一进行实现,掌握如下内容:
Ø 掌握二叉树基本操作的实现方法
Ø 了解赫夫曼树的思想和相关概念
Ø 学习使用二叉树解决实际问题的能力
【题目】
利用二叉树结构实现赫夫曼编/解码器。
【基本要求】
1、 初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立赫夫曼树
2、 建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符的编码输出。
3、 编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4、 译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结果。
5、 打印(Print):以直观的方式打印赫夫曼树(选作)
6、 计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。
【测试数据】
I love data Structure, I love Computer。I will try my best to study data Structure.
提示:
1、用户界面可以设计为“菜单”方式:能够进行交互。
2、根据输入的字符串中每个字符出现的次数统计频度,对没有出现的
字符一律不用编码。
【代码要求】
1、必须要有异常处理,比如删除空链表时需要抛出异常;
2、保持良好的编程的风格:
Ø 代码段与段之间要有空行和缩近
Ø 标识符名称应该与其代表的意义一致
Ø 函数名之前应该添加注释说明该函数的功能
Ø 关键代码应说明其功能
3、递归程序注意调用的过程,防止栈溢出
2. 程序分析
2.1 存储结构
用二叉树的结构建立哈夫曼树,每个节点的结构是
struct HNode
{
int weight;
int lchild;
int rchild;
int parent;
};
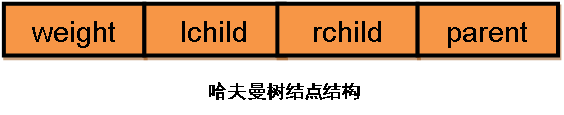
哈夫曼树的特点:只有度为2的结点和叶子结点,所以具有n个叶子结点的哈夫曼树的结点总数为2n-1
顺序存储结构: 设置一个的Tree[2*n-1]数组
2.2 关键算法分析
程序第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并把树的信息保存起来,以便解压时创建同样的哈夫曼树进行解压;第二遍,根据第一遍扫描得到的哈夫曼树进行编码,并把编码后的码字存储。
哈弗曼树的c++描述如下:
class Huffman
{
public:
void selectmin(int &x,int &y,int a);
void CreateHTree(int a[],int n);
void CreateTable(char code[],int n);
void encode(char string[],char code[]);
void decoding(char*s,char*d,int n);
void print(int length);
private:
HNode * HTree;
HCode * HCodeTable;
};
【存储算法】
对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立赫夫曼树
void Huffman::CreateHTree(int a[],int n)
{
HTree=new HNode[2*n-1];
for(int i=0;i<n;i++)
{
HTree[i].weight=a[i];
HTree[i].lchild=-1;
HTree[i].rchild=-1;
HTree[i].parent=-1;
}
int x,y;
for(int i=n;i<2*n-1;i++)
{
selectmin(x,y,i);
HTree[x].parent=HTree[y].parent=i;
HTree[i].weight=HTree[x].weight+HTree[y].weight;
HTree[i].lchild=x;
HTree[i].rchild=y;
HTree[i].parent=-1;
}
}
哈夫曼树是一棵正则二叉树。根据二叉树的性质,一棵有n个叶子的哈夫曼树共有2n-1个结点,可以用一个大小为2n-1的一维数组存放哈夫曼树的各个结点。由于每个结点同时还包含其双亲信息和孩子结点的信息,我们可以用一个静态三叉链表来存储哈夫曼树。
【初始化哈夫曼树】

【创建好的哈夫曼树】
【编码】
void Huffman::CreateTable(char code[],int n)
{
HCodeTable=new HCode[n];
for(int i=0;i<n;i++)
{
HCodeTable[i].data=code[i];
int child=i;
int parent=HTree[i].parent;
int k=0;
while(parent!=-1)
{
if(child==HTree[parent].lchild)
HCodeTable[i].code[k]='0';
else
HCodeTable[i].code[k]='1';
k++;
child=parent;
parent=HTree[child].parent;
}
HCodeTable[i].code[k]='\0';
char *b=new char[k];
for(int j=0;j<k;j++)
{
b[j]=HCodeTable[i].code[k-1-j];
}
b[k]='\0';
for(int m=0;m<=k;m++)
{
HCodeTable[i].code[m]=b[m];
}
cout<<endl;
}
}
【解码】
void Huffman::decoding(char*s,char*d,int n)
{
cout<<"解a码?过y后¨®的Ì?字Á?符¤?串ä?为a:êo"<<endl;
while(*s!='\0')
{
int parent=2*n-1-1;
while(HTree[parent].lchild!=-1)
{
if(*s=='0')
parent=HTree[parent].lchild;
else
parent=HTree[parent].rchild;
s++;
}
*d=HCodeTable[parent].data;
cout<<*d;
d++;
}
cout<<endl;
}
2.3 其他
增加菜单选项,可以重新开始程序或退出程序
3. 程序运行结果
1.程序流程图
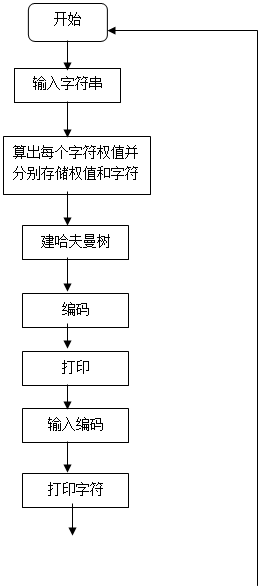
 是
是

否

2.运行结果
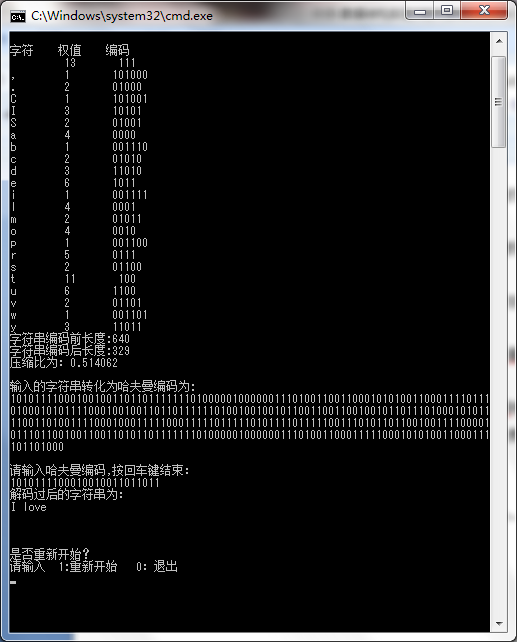
3.总结
本次实验难度比较大,还好课本给出了大部分关键语句。和老师PPT中的算法相比,这个算法还是略显稚嫩,有待改进的地方还有很多。
第二篇:哈弗曼编码数据结构实验报告
数据结构实验报告 ----约瑟夫环
一、需求分析:
约瑟夫环是程序的一道经典例题,可以使用数据结构的单链表进行编写。
二、概要设计:
大体上可以使用单链表通过节点的创建和删除来达到人数出列的效果,可以大大缩短程序量。
三、详细设计:
1、首先定义一个单链表,然后分别做创建链表、以及对应的输入数据,删除节点对应的删除数据,以及输出功能。最后用主函数实现上述功能。
下为程序源代码:
#include<stdio.h>
#include<malloc.h>
typedef struct Lnode //创建一个单链表
{
int num;
int key;
struct Lnode *next;
}Joseph;
struct Lnode *head,*p,*p1;
int creatlinklist(int n) //为节点分配内存,创建节点
{
int i=0;
head = (struct Lnode*)malloc(sizeof(struct Lnode));
if(!head)
{
return 0;
}
p=head;
for(i = 0;i<n-1;i++)
{
p1=(struct Lnode*)malloc(sizeof(struct Lnode));
if(!p1)
{
return 0;
}
p->next=p1;
p=p1;
}
p->next=head;
p1=head;
return 0;
}
int input(int n) //在分配的节点上输入数据
{
int i=0;
int j=0;
printf("please input the keys:\n");
for(i =1;i<n+1;i++)
{
scanf("%d",&j);
p1->num=i;
p1->key=j;
p1=p1->next;
}
p1=p;
return j;
}
int output(int m,int n) \\在约瑟夫环的规定上输出数据删除节点
{
int i=0;
int a=0;
for(i =0;i <n;i++)
{
for(a=0;a<m-1;a++)
{
p1=p1->next;
}
p=p1->next;
m=p->key;
printf("%d\n",p->num);
p1->next=p->next;
free(p);
}
return 0;
}
void main()
{
int m=0;
int n=0;
printf("请输入上限值和人数值:\n");
scanf("%d%d",&m,&n);
creatlinklist(n);
input(n);
printf("出对的人:\n");
output(m,n);
}
四、调试分析:
程序仅能使用一次,并且输入格式没有提示,容易犯错。大数据耗时比较长。
五、用户手册:
请根据提示输入数据。
六、测试结果:
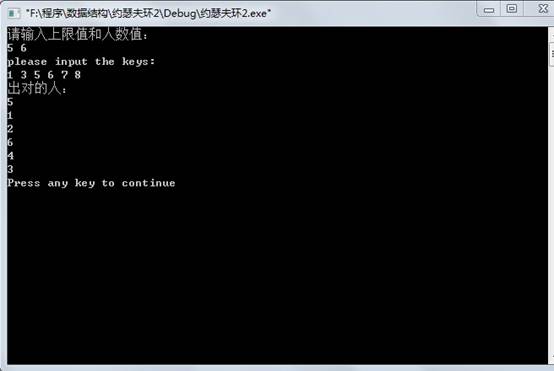
七、附录:
此程序仅能计算一次约瑟夫环,实用性较差,且大数据耗时也比较长。