编译原理实验报告
词法分析器
实验目的
1.熟练掌握词法分析程序的基本原理
2.掌握词法分析程序的设计和实现
实验内容
1.针对一个简化的C语言子集完成对它的词法分析程序的设计与实现
2.C语言子集的单词符号挤内码值
程序代码:
#include "stdio.h"
#include "string.h"
int i,j,k;
char s;
char a[20],token[20];
int letter()
{
if((s>=97)&&(s<=122))
return 1;
else return 0;
}
int digit()
{if((s>=48)&&(s<=57))
return 1;
else return 0;
}
void get()
{
s=a[i];
i=i+1;
}
void retract()
{i=i-1;}
int lookup()
{
if(strcmp(token, "while")==0)return 1;
else if(strcmp(token, "if")==0)return 2;
else if(strcmp(token,"else")==0)return 3;
else if(strcmp(token,"switch")==0)return 4;
else if(strcmp(token,"case")==0)return 5;
else return 0;
}
void main()
{printf("输入源程序,结束用'#':\n");
i=0;
do{i++;
scanf("%c",&a[i]);
}while(a[i]!='#');
i=1;
memset(token,0,sizeof(char)*20);
j=0;
get();
while(s!='#')
{if(s==' ')
get();
else
{switch(s){
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
case'g':
case'h':
case'i':
case'j':
case'k':
case'l':
case'm':
case'n':
case'o':
case'p':
case'q':
case'r':
case's':
case't':
case'u':
case'v':
case'w':
case'x':
case'y':
case'z':
while(letter(s)||digit(s))
{token[j]=s;
j++;
get();
}
retract();
k=lookup();
if(k==0)printf("(%d,%s)\n",6,token);
else printf("(%d,unll)\n",k);
break;
case'0':
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
while(digit(s)){
token[j]=s;
j=j+1;
get();
}
retract();
printf("(%d,%s)\n",7,token);
break;
case'+':printf("(+,null)\n");
break;
case'-':printf("(-,null)\n");
break;
case'*':printf("(*,null)\n");
break;
case'<':
get();
if(s=='=')
printf("(relop,LE)\n");
else {
retract();
printf("(relop,LT)\n");
}
break;
case'=':
get();
if(s=='=')printf("(relop,EQ)\n");
else{
retract();
printf("(=,null)\n");
}
break;
case';':printf("(;,null)\n");
break;
default:printf("(%c,error)\n",s);
break;
}
memset(token,0,sizeof(char)*10);
j=0;
get();
}
}
}
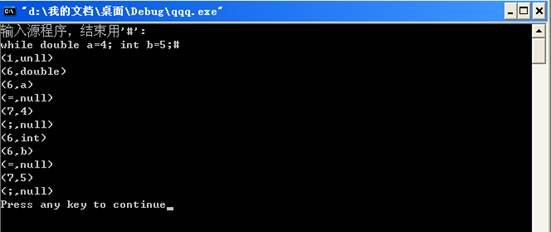
运行结果:
编译原理实验报告
语法分析器
实验目的
1.熟练掌握语法分析程序的基本原理
2.掌握用算符优先分析法来构造,设计优先函数
3.掌握语法分析程序的设计与实现
实验内容
1. 针对一个简单文法完成对它的语法分析程序的设计与实现
2. 通过语法分析程序来完成多输入的算数表达式进行计算并相应得到的对应四元式
程序代码:
#include <stdio.h>
char a[20],optr[10],s,op;
int i,j,k,opnd[10],x1,x2,x3;
int operand(char s)
{
if((s>='0')&&(s<='9'))
return 1;
else
return 0;
}
int f(char s)
{
switch(s)
{
case'+':return 6;
case'-':return 8;
case'*':return 10;
case'/':return 12;
case'(':return 2;
case')':return 12;
case'#':return 2;
default:printf("error!\n");
}
}
int g(char s)
{
switch(s)
{
case'+':return 5;
case'-':return 7;
case'*':return 9;
case'/':return 11;
case'(':return 13;
case')':return 2;
case'#':return 2;
default:printf("error!\n");
}
}
void get()
{
i=i+1;
s=a[i];
}
void main()
{
printf("请输入算数表达式,以 '#'结束:\n");
i=0;
do
{
i=i+1;
scanf("%c",&a[i]);
}while(a[i]!='#');
i=0;
j=0;
k=0;
optr[j]='#';
get();
while((optr[j] != '#')||(s != '#'))
{
if(operand(s))
{
opnd[k]=s-'0';
k=k+1;
get();
}
else if(f(optr[j])>g(s))
{
op=optr[j];
j=j-1;
x2=opnd[k-1];
x1=opnd[k-2];
k=k-2;
switch(op){
case'+':x3=x1+x2;break;
case'-':x3=x1-x2;break;
case'*':x3=x1*x2;break;
case'/':x3=x1/x2;break;
}
opnd[k]=x3;
k=k+1;
printf("(%c,%d,%d,%d)\n",op,x1,x2,x3);
}
else if(f(optr[j]) < g(s))
{
j=j+1;
optr[j]=s;
get();
}
else if(f(optr[j]) == g(s))
{
j=j-1;
get();
}
else
printf("error!");
}
}
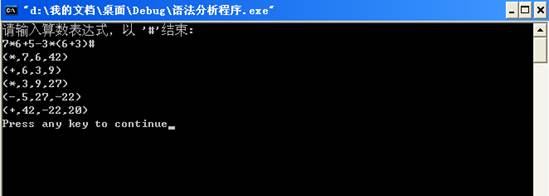
运行结果:
第二篇:编译原理词法分析器
一、实验目的
了解词法分析程序的两种设计方法:1.根据状态转换图直接编程的方式;2.利用DFA编写通用的词法分析程序。
二、实验内容及要求
1.根据状态转换图直接编程
编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。

具体任务有:
(1)组织源程序的输入
(2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件
(3)删除注释、空格和无用符号
(4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。
(5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。
标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址
注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。
常量表结构:常量名,常量值
2.编写DFA模拟程序
算法如下:
DFA(S=S0,MOVE[][],F[],ALPHABET[])
/*S为状态,初值为DFA的初态,MOVE[][]为状态转换矩阵,F[] 为终态集,ALPHABET[] 为字母表,其中的字母顺序与MOVE[][] 中列标题的字母顺序一致。*/
{
Char Wordbuffer[10]=“”//单词缓冲区置空
Nextchar=getchar();//读
i=0;
while(nextchar!=NULL)//NULL代表此类单词
{ if (nextchar!∈ALPHABET[]) {ERROR(“非法字符”),return(“非法字符”);} S=MOVE[S][nextchar] //下一状态
if(S=NULL)return(“不接受”);//下一状态为空,不能识别,单词错误
wordbuffer[i]=nextchar ; //保存单词符号
i++;
nextchar=getchar();
}
Wordbuffer[i]=‘\0’;
1
If(S∈F)return(wordbuffer); //接受
Else return(“不接受”);
}
该算法要求:实现DFA算法,给定一个DFA(初态、状态转换矩阵、终态集、字母表),调用DFA(),识别给定源程序中的单词,查看结果是否正确。
1.能对任何S语言源程序进行分析
在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。
2.能检查并处理某些词法分析错误
词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。
本实验要求处理以下两种错误(编号分别为1,2):
1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。
2:源程序文件结束而注释未结束。注释格式为:/* …… */
三、实验程序设计说明
1.实验方案设计
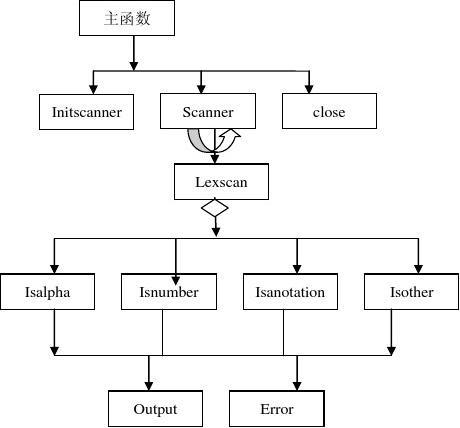
包括设计词法分析器模块调用结构图和各模块流程图。
2
模块结构:

1.Initscanner函数:程序初始化:输入并打开源程序文件和目标程序文件,初始化保留字表
2.Scanner函数:若文件未结束,反复调用lexscan函数识别单词。
3.Lexscan函数:根据读入的单词的第一个字符确定调用不同的单词识别函数
4.Isalpha函数:识别保留字和标识符
5.Isnumber函数:识别整数,如有精力,可加入识别实数部分工功能
6.Isanotation函数:处理除号/和注释
7.Isother函数识别其他特殊字符
8.Output函数:输出单词的二元式到目标文件,输出格式(单词助记符,单词内码值),如(int,-)(rlop,>)……
9.Error函数:输出错误信息到屏幕
10.除此之外,还可以设置查符号表,填写符号表等函数,学生可自行设计。
2.程序源代码
3
#include<stdio.h> #include<string.h> #include<stdlib.h> #define LENGTH 46 #define N 100
//************************ typedef struct token { char name[30]; int code; int addr; }token;
typedef struct KeyWord { char name[30]; int code; }KeyWord;
typedef struct symble { char name[30];//字符名字 int number;//字符编码 int type; }symble;
//********************************** char ch;
int error_count; //错误出现的个数 int var_count; // int num_count; // int label_count; int code_count; //
int addr_count; //内码编址
int LineOfPro; //错误出现的行号 char filename[30];
FILE *SourceFin; //源文件 FILE *TokenFout; //输出文件 FILE *SymbleFout; //符号表 FILE *NumFout; //常量表
KeyWord
key[14]={{"void",1},{"main",2},{"int",3},{"f
loat",4},{"const",5},{"for",6},
{"if",7},{"else",8},{"then",9},{"while",10},{"switch",11},{"break",12},{"begin",13},{"end",14}};
token CurrentToken; token zancun;
symble CurrentSimble; symble SymbleList[N]; symble NumList[N];
//*********************************** void Scanner(); //主程序 void IsAlpha(); //关键字 void IsNumber(); //数字 void IsAnotation(); //注释 void IsOther(); //其它 void OutPut(); //输出 void Error(int a); //错误类型
int Flag_WordHave(); //查添符号表 int Flag_NumHave(); //查添常量表
//*************************************
int main() { int i=0,j=0; code_count=0; var_count=1; label_count=1; addr_count=0; num_count=0;
LineOfPro=0; //行号 Scanner(); printf("输出标识符表:\n"); for(i=0;i<var_count-1;i++) printf("<%s,%d>",SymbleList[i].name,i+1); printf("\n"); printf("输出数字表:\n"); for(i=0;i<num_count;i++) printf("<%s,%d>",NumList[i-1].name,i+1);
4
return 0; }
//*************主程序*************** void Scanner() { int i=0; if((SourceFin=fopen("sun.txt","r"))==NULL) { printf("无法打开文件%s!\n",filename); exit(1); } if((TokenFout=fopen("输出文件.txt","w"))==NULL) { printf("无法打开文件输出文件.txt!\n"); exit(1); } if((SymbleFout=fopen("符号文件.txt","w"))==NULL) { printf("无法打开符号文件.txt!\n"); exit(1); } if((NumFout=fopen("常量文件.txt","w"))==NULL) { printf("无法打开文件常量.txt!\n"); exit(1); } ch=fgetc(SourceFin); while(ch!=EOF) { for(i=0;i<30;i++) CurrentToken.name[i]='\0';//将单词缓冲区初始化 if((ch>47)&&(ch<58)) IsNumber(); if(((ch>='a')&&(ch<='z'))||((ch>='A')&&(
5
ch<='Z'))||(ch=='_'))
{IsAlpha();} if(ch=='/') IsAnotation(); else IsOther(); } fclose(TokenFout); fclose(SymbleFout); fclose(NumFout); printf("词法分析完毕。\n"); }
//************数字处理**************** void IsNumber() { int k=0; while(((ch>='0')&&(ch<='9'))) { CurrentToken.name[k++]=ch;//将数字放入单词缓冲区 ch=fgetc(SourceFin); } CurrentToken.code=18;//数字的机内码是18 OutPut(); }
//************是否为关键字**************** void IsAlpha() { int i,h; h=0; i=0; while(((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||ch=='_')//将完整的单词放入单词缓冲区 { CurrentToken.name[i++]=ch; ch=fgetc(SourceFin); } zancun=CurrentToken; for(i=0;i<14;i++)//将单词缓冲区中的词
和关键字数组中的词比较,看是不是关键字 { for(int j=0;j<30;j++) { if(CurrentToken.name[j]==key[i].name[j]) h=0; else {h=1;break;} } if(h==0) break; }
if(h==0) { CurrentToken.code=key[i].code;//将第i个关键字的机内码给单词缓冲区中现有单词的机内码 CurrentToken.addr=-1;//关键字地址为-1 OutPut(); } else { CurrentToken.code=17; CurrentToken.addr=addr_count++; //如果不是关键字就是普通标识符,地址加1 OutPut(); } }
//**************处理注释***************** void IsAnotation() { char ch1; ch1=ch; ch=fgetc(SourceFin); if(ch=='*') { for(;;) {
6
ch=fgetc(SourceFin);
if(ch==EOF) {Error(2);break;}//到最后没有*说明注释不完全,有错误 if(ch=='*') { ch1=ch; ch=fgetc(SourceFin); if(ch=='/')//如果最后有*/说明注释完整 {ch=fgetc(SourceFin);break;} } } } else { error_count++; Error(2); CurrentToken.name[0]='/';//如果注释不完整,将第一个字母看成/ CurrentToken.code=22; CurrentToken.addr=-1;//符号的地址是-1 OutPut(); } }
//***************其它 ************ void IsOther() { char ch1; int i; for(i=0;i<30;i++) { CurrentToken.name[i]='\0';}//将缓冲区初始化 switch(ch) { case'+': { ch1=fgetc(SourceFin); if(ch1=='=') {
CurrentToken.name[0]='+'; CurrentToken.name[1]='='; CurrentToken.code=38; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else { CurrentToken.name[0]='+'; CurrentToken.code=19; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case'-': { ch1=fgetc(SourceFin); if(ch1=='=') { CurrentToken.name[0]='-'; CurrentToken.name[1]='='; CurrentToken.code=39; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else { CurrentToken.name[0]='-'; CurrentToken.code=20; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case'*':
{
ch1=fgetc(SourceFin); if(ch1=='=') {
CurrentToken.name[0]='*'; CurrentToken.name[1]='='; CurrentToken.code=40; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else { CurrentToken.name[0]='*'; CurrentToken.code=21; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case'%': { if(ch1=='=') {
CurrentToken.name[0]='%'; CurrentToken.name[1]='='; CurrentToken.code=41; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else { CurrentToken.name[0]='%'; CurrentToken.code=23; CurrentToken.addr=-1; OutPut();
7
ch=fgetc(SourceFin); break; } } case'(': { CurrentToken.name[0]='('; CurrentToken.code=24; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } case')': { CurrentToken.name[0]=')'; CurrentToken.code=25; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } case'[': { CurrentToken.name[0]='['; CurrentToken.code=26; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } case']': { CurrentToken.name[0]=']'; CurrentToken.code=27; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } case'<': { ch1=fgetc(SourceFin); if(ch1=='=')
{
CurrentToken.name[0]='<'; CurrentToken.name[1]='='; CurrentToken.code=31; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else {
CurrentToken.name[0]='<'; CurrentToken.code=29; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case'>': { ch1=fgetc(SourceFin); if(ch1=='=') {
CurrentToken.name[0]='>'; CurrentToken.name[1]='='; CurrentToken.code=32; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else {
CurrentToken.name[0]='>'; CurrentToken.code=30; CurrentToken.addr=-1; OutPut();
8
ch=fgetc(SourceFin); break; } } case'=': { CurrentToken.name[0]='='; CurrentToken.code=33; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } case'!': { ch1=fgetc(SourceFin); if(ch1=='=') { CurrentToken.name[0]='!'; CurrentToken.name[1]='='; CurrentToken.code=34; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } else {
CurrentToken.name[0]='n';
CurrentToken.name[1]='o'; CurrentToken.name[2]='t'; CurrentToken.code=44; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case';': { CurrentToken.name[0]=';';
CurrentToken.code=35;
CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } case'|': { ch1=fgetc(SourceFin); if(ch1=='|') {
CurrentToken.name[0]='O'; CurrentToken.name[1]='R'; CurrentToken.code=42; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case'&': { ch1=fgetc(SourceFin); if(ch1=='&') {
CurrentToken.name[0]='A'; CurrentToken.name[1]='N';
CurrentToken.name[2]='D'; CurrentToken.code=43; CurrentToken.addr=-1; OutPut(); ch=fgetc(SourceFin); break; } } case 10: // /n换行 { LineOfPro++;
9
ch=fgetc(SourceFin); 标志符输出
break; {
}
case 13: // CurrentSimble.number=CurrentToken.ad
dr; 回车换行
{
LineOfPro++; CurrentSimble.type=CurrentToken.code; ch=fgetc(SourceFin);
break; strcpy(CurrentSimble.name,CurrentToke } n.name);
case' ': // Flag_WordHave();
空格
CurrentToken.code=60; fprintf(TokenFout,"<id,%d>",addr_count ch=fgetc(SourceFin); );
break; printf("<id,%d>",addr_count); }
default:Error(1); else
ch=fgetc(SourceFin); if(CurrentToken.code==18) break; // 数字输出
} {
}
CurrentSimble.number=CurrentToken.addr; //************错误类型************
void Error(int a)
{ CurrentSimble.type=CurrentToken.code; error_count++;
switch(a) strcpy(CurrentSimble.name,CurrentToken.na { me);
case 1: Flag_NumHave();
{printf("error %2d 非法字符 %3d
fprintf(TokenFout,"<num , %s>",CurrentToke行.\n",error_count,LineOfPro+1);break;}
n.name);
case 2:
printf("<num , %d>",num_count); {printf("error %2d 没有匹配的注
释符 %3d
} 行.\n",error_count,LineOfPro+1);break;}
else
}
return; if((CurrentToken.code>=1)&&(CurrentToken.} code<=14))//关键字的输出
void OutPut() {
{
int i=0; fprintf(TokenFout,"<%s,_>",zancun.nam
e); //输出形式
if(CurrentToken.code==17) //
10
printf("<%s ,_>",zancun.name); } else//符号的输出 { fprintf(TokenFout,"<%s,_>",CurrentToken.name); printf("<%s ,_>",CurrentToken.name); } }
//查添符号
int Flag_WordHave() { int flag,i=0; //用缓冲符号表中的符号和符号数组中的比较 for(i=0;i<(var_count-1);i++) { flag=strcmp(CurrentSimble.name,SymbleList[i].name); if(flag==0) { CurrentToken.addr=var_count;//如果存在,将符号数组的地址返回 return 0; } } SymbleList[var_count-1].number=CurrentToken.addr;
SymbleList[var_count-1].type=CurrentToken.code; strcpy(SymbleList[var_count-1].name,CurrentToken.name);//不存在写入 fprintf(SymbleFout,"<%s ,%3d >",SymbleList[var_count-1].name,var_count);//符号的输出模式 //
printf("<%s ,%3d >",SymbleList[var_count-1].name,var_count); var_count=var_count+1; return 1; }
//常量
int Flag_NumHave() { int flag,i=0; //用缓冲常量表中的常量和常量数组中的比较 for(i=0;i<(num_count-1);i++) { flag=strcmp(CurrentSimble.name,NumList[i].name); if(flag==0) { CurrentToken.addr=num_count;//如果存在,将符号数组的地址返回 return 0; } } NumList[num_count-1].number=CurrentToken.addr;
NumList[num_count-1].type=CurrentToken.code; strcpy(NumList[num_count-1].name,CurrentToken.name);//不存在写入 fprintf(NumFout,"<%s ,%3d >",NumList[num_count-1].name,num_count);//符号的输出模式 num_count=num_count+1; return 1; }
3.程序的执行结果
11
输入文件,输出结果文件及屏幕信息
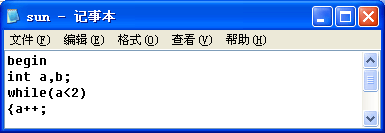
:
输入文件如图

1-1
屏幕显示结果
1-2
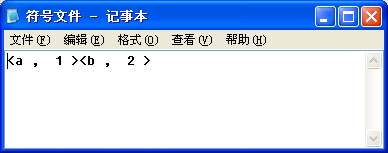
符号文件
1-3
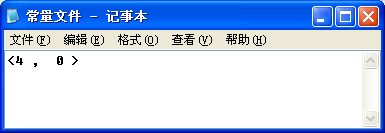
常量文件
1-4
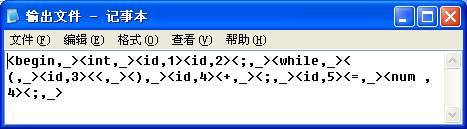
输出文件1-5
12
4.实验程序的优点和特色
从输入的源程序中,识别出各个具有独立意义的单词,即关键字、其他标识符、整型常数、运算符、界符五大类。并依次输出各个单词的内部编码及单词符号自身值。遇到错误时可显示“Error”,然后跳过错误部分继续显示。对注释加以识别 。
四、实验中出现的问题及解决方法
1.参考书的代码出现了细微的错误,经过同学的帮助努力修改得以运行。
2.C语言的文件操作基础不牢,重拾课本得以解决。
五、体会、意见或建议
1.通过这次用C语言对词法分析程序的编制,回顾了C语言的编程方法。
2.加深了对词法分析原理的理解和词法分析的实现过程,掌握了编译程序的实现方法和技术。
13