计算机与信息工程学院综合性实验报告
专业:通信工程 年级/班级:20##级 20##—20##学年第一学期

一、实验目的
根据霍夫曼编码的原理,用MATLAB设计进行霍夫曼编码的程序,并得出正确的结果。
二、实验仪器或设备
1、一台计算机。
2、MATLAB r2013a。
三、二元霍夫曼编码原理
1、将信源消息符号按其出现的概率大小依次排列,p1>p2>…>pq
2、取两个概率最小的字母分别配以0和1两个码元,并将这两个概率相加作为一个新字母的概率,从而得到只包含q-1个符号的新信源S1。
3、对重排后的缩减信源S1重新以递减次序排序,两个概率最小符号重复步骤(2)的过程。
4、不断继续上述过程,直到最后两个符号配以0和1为止。
5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
四、霍夫曼编码实现程序
function [outnum]=lml_huffman(a)
%主程序,输入一组概率,输出此组概率的霍夫曼编码
%a:一组概率值,如a=[0.2 0.3 0.1 0.4]等
%outnum:输出的霍夫曼码,以cell中的字符数组表示
if sum(a)~=1
warning('输入概率之和不为“1”,但程序仍将继续运行')
end
[cho,sequ,i,l]=probality(a);
global lmlcode %用于输出霍夫曼码,定义为cell型
global cellnum %用于编码的累加计算
cellnum=1;
lmlcode=cell(l,1);
j=1; %第一部分
add_num=char;
[l_add]=addnum(add_num,i,j,l);
[output,m]=disgress(sequ,i,j,l,l_add);
dealnum(output,m); %在全局变量中输出霍夫曼码
j=2; %第二部分
[l_add]=addnum(add_num,i,j,l);
[output,n]=disgress(sequ,i,j,l,l_add);
dealnum(output,n);
[outnum]=comset(lmlcode,cho(1,:));%将概率和编码进行关联
function [output]=addnum(input,i,j,l)
%对概率矩阵中每一行最后两个不为0的数进行编码,即在某个编码后添加0,1或空
%输出:
% input:输入的某个未完成的编码
% (i,j):当前检索目标在sequ矩阵中的位置
% l:sequ矩阵的列数
%PS: sequ矩阵在此函数中未用到
%PS:此函数为编码第一步
if j==(l-i)
output=[input '0'];
else if j==(l-i+1)
output=[input '1'];
else
output=input;
end
end
function [ecode]=comset(code,pro)
%将概率和编码进行关联
%code:已编成的霍夫曼码
%pro:输入的一组概率
%ecode:最终完成的码
l=length(code);
ecode=cell(l,2);
for i=1:l
lang(i)=length(code{i});
end
[a,b]=sort(lang);
for i=1:l
ecode{i,1}=code{b(i)};
ecode{i,2}=pro(i);
end
function [final,a]=dealnum(imput,m)
%整理并在全局变量中输出已完成的霍夫曼码
%输入: imput:程序运算后的生成cell型矩阵
% m:标识数
%输出: final:整理后的霍夫曼码
% a:标识数
global lmlcode
global cellnum
if m==1
lmlcode{cellnum}=imput;
cellnum=cellnum+1;
final='';
a='';
else if m==2
[final1,a1]=dealnum(imput{1,1},imput{1,2});
[final2,a2]=dealnum(imput{2,1},imput{2,2});
[final3,a3]=dealnum(final1,a1);
[final4,a4]=dealnum(final2,a2);
final=[final3 final4];
a=[a3 a4];
else
final=imput;
a=m;
end
end
function [outnum,p]=findsumother(sequ,i,j,l,add_num)
%当前检索目标在sequ(i,j)处为非1时的处理程序,即跳转到下一级进行整理
%输入: sequ:概率转移矩阵
% (i,j):当前检索目标在sequ矩阵中的位置
% l:sequ矩阵的列数
% add_num:当前进行的编码
%输出:(与disgress类同)
% outnum:进行霍夫曼编码,用cell型表示
% p:标识数
j=l-i+2-sequ(i,j);
i=i-1;
[add_num1]=addnum(add_num,i,j,l);
[outnum,p]=disgress(sequ,i,j,l,add_num1);
function [outnum1,outnum2,p,q]=findsumis1(sequ,i,j,l,add_num)
%当前检索目标在sequ(i,j)处为1时的处理程序,
%即对下一级的最小两概率进行求和移位编码整理
%输入: sequ:概率转移
% (i,j):当前检索目标在sequ矩阵中的位置
% l:sequ矩阵的列数
% add_num:当前进行的编码
%输出:(与disgress类同)
% outnum1&[outnum2:进行霍夫曼编码,用cell型表示
% p&q:标识数
i=i-1;
j1=l-i;
j2=l-i+1;
[add_num1]=addnum(add_num,i,j1,l);
[outnum1,p]=disgress(sequ,i,j1,l,add_num1);
[add_num2]=addnum(add_num,i,j2,l);
[outnum2,q]=disgress(sequ,i,j2,l,add_num2);
function [output,m]=disgress(sequ,i,j,l,add_num)
%当前检索目标,累加数,输出下一级霍夫曼码及其个数,此函数被调用次数最多
%输入:sequ:概率转移矩阵
% (i,j):当前检索目标在sequ矩阵中的位置
% l:sequ矩阵的列数
% add_num:当前进行的编码
%输出:output:进行霍夫曼编码,用cell型表示
% m:标识数
%PS:此函数为编码第二步
if i~=1
if sequ(i,j)==1
[output1,output2,p,q]=findsumis1(sequ,i,j,l,add_num);
output=cell(2);
output{1,1}=output1;
output{1,2}=p;
output{2,1}=output2;
output{2,2}=q;
m=2;
else if sequ(i,j)~=1
[output1,p]=findsumother(sequ,i,j,l,add_num);
output=output1;
m=p;
end
end
else
output=add_num;
m=1;
end
五、实验程序实现方法演示
若在command window中输入的概率数组为p=[0.1 0.15 0.20 0.25 0.30]使用子函数[output,sequ,i,j]=probality(p)对此组概率进行预处理,处理结果如下图所示:
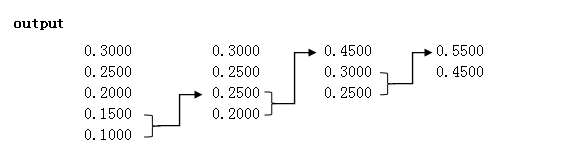
图5.1 概率数据处理过程简图

图5.2 对图1中数据的转移方式标示图
图2标明了对图1中各数据的位置转移过程。图1中每一列最后两个数据标为1,其他数据从下到上依次标为2、3、4...如第一列最后两个数据标为1,则其上依次为2、3、4。故在第二列中sequ(2,3)=1的含义是:output(2,3)=0.25为第一列中标为1的数据转移而来;sequ(2,2)=3的含义是:output(2,2)=0.25为第一列中标为3的数据转移而来;在第三列中sequ(2,3)=3的含义是:output(2,3)=0.3为第二列中标为3的数据转移而来,等等。
依据矩阵output及sequ可以得到霍夫曼编码的码树图如下:
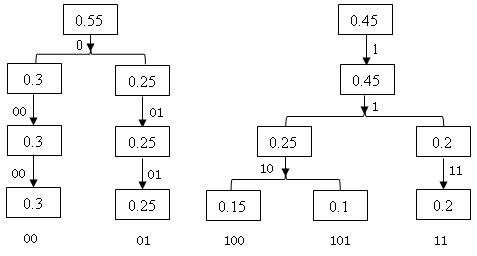
图5.3 特定概率数组的编码码树
六、结果分析与总结
(1)实验结果分析
1、在command window中输入:p=[0.1 0.15 0.20 0.25 0.30],生成数组p
2、之后在command window中输入:[a]=lml_huffman(p),输出结果为:
a =
'00' [0.3000]
'01' [0.2500]
'11' [0.2000]
'100' [0.1500]
'101' [0.1000]
其中outnum为cell型,第一列为字符型,输出的是霍夫曼码,第二列为输入的概率数组,与第一列中的霍夫曼码相对应。
将以上输出结果在下表中统计。
表6.1 编码分析表
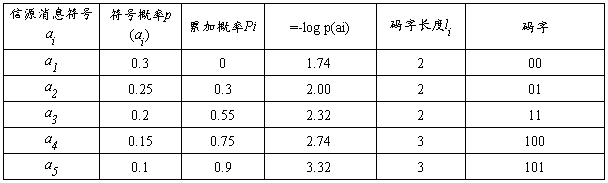
则

(2)实验小结
1、从实验结果可以看出,霍夫曼编码的效率很高,但是并未达到可以达到100%
2、从实验程序可以看出,每次对信源缩减时,赋予信源最后两个概率最小的符号,用0和1是可以任意的,所以可以得到不同的霍夫曼码,但不会影响码字的平均长度。
教师签名:
年 月 日
第二篇:编码理论实验报告实验一霍夫曼编码中信息熵及编码效率的实验
实验名称 实验一 霍夫曼编码中信息熵及编码效率的实验
一、 实验目的
1. 掌握霍夫曼编码中信息熵的定义、性质和计算;
2. 掌握霍夫曼编码中平均码字长度的定义和计算;
3. 掌握霍夫曼编码中编码效率的定义和计算;
4. 正确使用C语言实现霍夫曼编码中信息熵、平均码长和编码效率的求取。
二、实验内容
1. 熟练列出霍夫曼编码中信息熵、平均码长和编码效率各自的计算公式;
2. 正确使用C语言实现计算霍夫曼编码中信息熵、平均码长和编码效率的程序,并在Visual C++环境中验证。
三、 实验原理
1. 霍夫曼编码的基本原理
按照概率大小顺序排列信源符号,并设法按逆顺序分配码字字长,使编码的码字为可辨识的。
2. 平均码长:L=∑p(si)*li (单位为:码符号/信源符号)
其中,p(si)为信源si在q个信源中出现的概率,li为信源si的二进制霍夫曼编码。
3. 信息熵:H(S)=- ∑p(si) *log2 p(si) (单位为:比特/信源符号)
其中,p(si)为信源si在q个信源中出现的概率。
4. 编码效率:η= H(S)/ L
其中,H(S)为信息熵,L为平均码长。
四、 实验步骤:
1. Huffman编码示例如下图:

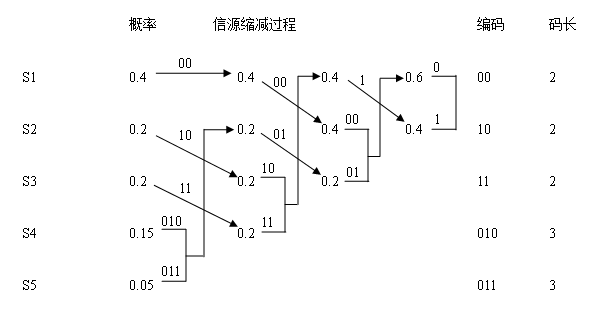 2. 根据Huffman编码的例子,用C语言完成计算霍夫曼编码中信息熵的程序的编写,并在Visual C++环境中验证;
2. 根据Huffman编码的例子,用C语言完成计算霍夫曼编码中信息熵的程序的编写,并在Visual C++环境中验证;
3. 根据Huffman编码的例子,用C语言完成计算霍夫曼编码中平均码长的程序的编写,并在Visual C++环境中验证;
4. 根据Huffman编码的例子,用C语言完成计算霍夫曼编码中编码效率的程序的编写,并在Visual C++环境中验证;
实验程序:
/*********** 霍夫曼编码信息熵、平均码长及编码效率的计算 ************
//按照实验步骤的要求完成程序,正确计算霍夫曼编码的信息熵、
//平均码长以及编码效率,并通过printf函数将三者的计算结果
//打印出来
#include<stdio.h>
#include<string.h>
#include<math.h>
#define CH_Num 5 //信源符号个数
//主函数
void main()
{
//编程1:定义double型数组gailv存放各信源符号出现的概率
double gailv[CH_Num]={0.4,0.2,0.2,0.15,0.05};
//编程2:定义int型数组code_len存放各信源符号的霍夫曼编码
int code_len[CH_Num]={2,2,2,3,3};
//编程3:定义double型变量aver_Len、Hs和code_ratio,分别
//对应信息熵、平均码长及编码效率,并初始化为0
double aver_Len=0,Hs=0,code_ratio=0;
int i;
//编程4:利用for循环计算平均码长aver_Len
for(i=0;i<CH_Num;i++)
aver_Len+=gailv[i]*code_len[i];
//编程5:利用for循环计算信息熵Hs
for(i=0;i<CH_Num;++i)
Hs+=-(gailv[i]*(log(gailv[i])/log(2)));
//编程6:计算编码效率code_ratio
code_ratio=Hs/aver_Len;
//编程7:利用三条printf语句分别打印平均码长、信息熵和编码效率
printf("平均码长=%lf 比特/信源符号\n",aver_Len);
printf("信源熵=%lf 码符号/信源符号\n",Hs);
printf("编码效率=%lf\n",code_ratio);
}
运行结果如下图: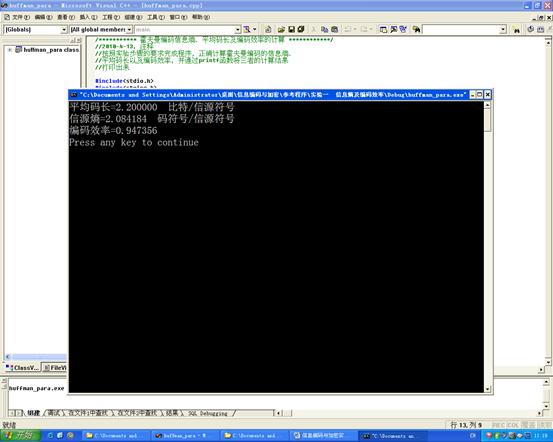
实验心得:通过本次试验加深了对霍夫曼编码的基本原理的理解以及计算公式的记忆。并使用C语言实现计算霍夫曼编码中信息熵、平均码长和编码效率的程
序,并在Visual C++环境中验证,且结果正确。