各种排序算法的总结和比较
1 快速排序(QuickSort)
/* 快速排序(quick sort)。在这种方法中,
* n 个元素被分成三段(组):左段left,
* 右段right和中段middle。中段
* 仅包含一个元素。左段中各元素都小于等
* 于中段元素,右段中各元素都大于等于中
* 段元素。因此left和right中的元
* 素可以独立排序,并且不必对left和
* right的排序结果进行合并。
* 使用快速排序方法对a[0:n-1]排序
* 从a[0:n-1]中选择一个元素作为middle,
* 该元素为支点把余下的元素分割为两段left
* 和right,使得left中的元素都小于
* 等于支点,而right 中的元素都大于等于支点
* 递归地使用快速排序方法对left 进行排序
* 递归地使用快速排序方法对right 进行排序
* 所得结果为left+middle+right
*/
/* 要注意看清楚下面的数据之间是如何替换的,
* 首先选一个中间值,就是第一个元素data[low],
* 然后从该元素的最右侧开始找到比它小的元素,把
* 该元素复制到它中间值原来的位置(data[low]=data[high]),
* 然后从该元素的最左侧开始找到比它大的元素,把
* 该元素复制到上边刚刚找到的那个元素的位置(data[high]=data[low]),
* 最后将这个刚空出来的位置装入中间值(data[low]=data[0]),
* 这样一来比mid大的都会跑到mid的右侧,小于mid的会在左侧,
* 最后一行,返回的low是中间元素的位置,左右分别递归就可以排好序了。
*/
快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序可以由下面四步组成。
(1) 如果不多于1个数据,直接返回。
(2) 一般选择序列最左边的值作为支点数据。
(3) 将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。
(4) 对两边利用递归排序数列。
快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。
2 归并排序(MergeSort)
归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。
3 堆排序(HeapSort)
/**************************************************************
* 堆的定义 n 个元素的序列 {k1,k2,...,kn}当且仅当满足下列关系时,
* 称为堆:
* ki<=k2i ki<=k2i+1 (i=1,2,...,n/2) (小顶堆)
* 或
* ki>=k2i ki>=k2i+1 (i=1,2,...,n/2)(大顶堆)
* 堆排序思路:
* 建立在树形选择排序基础上;
* 将待排序列建成堆(初始堆生成)后,序列的第一个元素(堆顶元素)就一定是序列中的最大元素; * 将其与序列的最后一个元素交换,将序列长度减一;
* 再将序列建成堆(堆调整)后,堆顶元素仍是序列中的最大元素,再次将其与序列最后一个元素交换并缩短序列长度;
* 反复此过程,直至序列长度为一,所得序列即为排序后结果。
************************************************************************ 堆排序适合于数据量非常大的场合(百万数据)。
堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
4 Shell排序(ShellSort)
Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。
Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。
oid sort(int v[],int n)
{
int gap,i,j,temp;
for(gap=n/2;gap>0;gap /= 2) /* 设置排序的步长,步长gap每次减半,直到减到1 */ {
for(i=gap;i<n;i++) /* 定位到每一个元素 */
{
for(j=i-gap;(j >= 0) && (v[j] > v[j+gap]);j -= gap ) /* 比较相距gap远的两个元素的大小,根据排序方向决定如何调换 */
{
temp=v[j];
v[j]=v[j+gap];
v[j+gap]=temp;
}
}
}
}
5 插入排序(InsertSort)
插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。
6 冒泡排序(BubbleSort)
冒泡排序是最慢的排序算法。在实际运用中它是效率最低的算法。它通过一趟又一趟地比较数组中的每一个元素,使较大的数据下沉,较小的数据上升。它是O(n^2)的算法。
7 交换排序(ExchangeSort)和选择排序(SelectSort)
这两种排序方法都是交换方法的排序算法,效率都是 O(n2)。在实际应用中处于和冒泡排序基本相同的地位。它们只是排序算法发展的初级阶段,在实际中使用较少。
算法原理:首先以一个元素为基准,从一个方向开始扫描,
* 比如从左至右扫描,以A[0]为基准。接下来从A[0]...A[9]
* 中找出最小的元素,将其与A[0]交换。然后将基准位置右
* 移一位,重复上面的动作,比如,以A[1]为基准,找出
* A[1]~A[9]中最小的,将其与A[1]交换。一直进行到基准位
* 置移到数组最后一个元素时排序结束(此时基准左边所有元素
* 均递增有序,而基准为最后一个元素,故完成排序)。
*/
8 基数排序(RadixSort)
基数排序和通常的排序算法并不走同样的路线。它是一种比较新颖的算法,但是它只能用于整数的排序,如果我们要把同样的办法运用到浮点数上,我们必须了解浮点数的存储格式,并通过特殊的方式将浮点数映射到整数上,然后再映射回去,这是非常麻烦的事情,因此,它的使用同样也不多。而且,最重要的是,这样算法也需要较多的存储空间。
9 总结
下面是一个总的表格,大致总结了我们常见的所有的排序算法的特点。
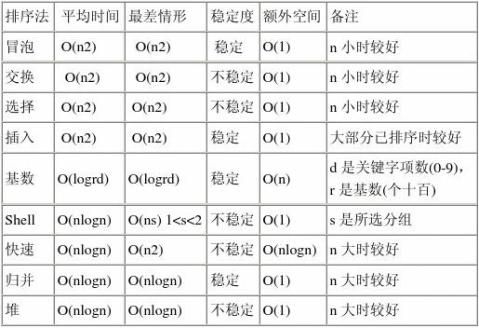
第二篇:经典排序算法总结(代码)
经典排序算法总结(代码)
--fly分享
目录
/*冒泡法.......................................................................................................................................... 2 /*快速排序 ................................................................................................................................... 3 /*插入排序 ................................................................................................................................... 4 /*希尔(shell)排序 ............................................................................................................ 5 /*选择排序 ................................................................................................................................... 6 /*堆排序.......................................................................................................................................... 7 /*归并排序 ................................................................................................................................... 9
附:
排序算法原理:flash演示:
#include <iostream> #include <string>
using namespace std;
/* 冒泡法
左右元素相比,往后冒泡 */
template<typename T> void BubbleSort(T* r, int n) {
T temp;
int i,j;
for (i=0;i<n-1;i++) {
for (j=0;j<n-i-1;j++) {
if (r[j] > r[j+1]) {
temp = r[j]; r[j] = r[j+1]; r[j+1] = temp; }
}
}
}
/*快速排序
左边比他小,右边比他大,每次得到一个最左边数据的位置*/
template<typename T>
void QuickSort(T a[],int low,int high)
{
if(low < high)
{
T elem = a[low];
int l = low, r = high;
while(l < r)
{
while(l < r && a[r] >= elem) r--;
if (l < r)
{
a[l++] = a[r];
}
while(l< r && a[l] <= elem) l++;
if (l < r)
{
a[r--] = a[l];
}
}
a[r] = elem;
QuickSort(a,low,r-1);
QuickSort(a,r+1,high);
}
}
/*插入排序
向右移,a[j+1]=a[j]*/ template<typename T> void insert_sort(T a[],int n) {
int i,j;
T elem;
for (i= 1;i<n ;++i)
{
j = i- 1;
elem = a[i];
while(j>=0 && elem < a[j] ) {
a[j+1] = a[j]; j--; }
a[j+1] = elem;
}
}
/*希尔(shell)排序
把插入排序的改成d即可*/
template<typename T>
void shell_insert(T array[],int d,int len) {
int i,j;
T elem;
for ( i = d;i < len;i++)
{
j = i - d;
elem = array[i]; while (j >= 0 && elem < array[j]) {
array[j+d] = array[j]; j = j - d;
}
array[j+d] = elem; }
}
template<typename T>
void shell_sort(T array[],int len)
{
int inc = len;
do
{
inc = inc/2;
shell_insert(array,inc,len);
}
while (inc > 1);
}
/*选择排序
逐一比较,最小的放前面*/ template <typename T> void SelectSort(T a[],int n) {
int i,j,elemNum; T elem;
for (i=0;i<n-1;i++) {
elemNum = i;
for (j= i+1;j<n;j++) {
if (a[j] < a[elemNum]) {
elemNum = j; }
}
if (elemNum != i) {
elem = a[i];
a[i] = a[elemNum]; a[elemNum] = elem;
}
}
}
/*堆排序
a[s]>=a[2*s] && a[s]>=a[2*s+1]*/ template<typename T>
void Max_heap(T a[],int S,int len) {
int l = 2*S;
int r = 2*S+1;
int maxI = S;
T elem;
if (l < len && a[l] > a[maxI]) {
maxI = l;
}
if (r < len && a[r] > a[maxI]) {
maxI = r;
}
if (maxI != S)
{
elem = a[S];
a[S] = a[maxI];
a[maxI] = elem;
Max_heap(a,maxI,len); }
}
template<typename T> void HeapSort(T a[],int n) {
int i;
T elem;
} for (i = n/2;i>=0;i--) { Max_heap(a,i,n); } for (i= n-1;i>=1;i--) { elem = a[0]; a[0] = a[i]; a[i] = elem; n = n-1; Max_heap(a,0,n); }
/*归并排序
左边小左边,左边++;右边小取右边,右边++*/ template<typename T>
void merge(T array[], int low, int mid, int high) {
int k;
T *temp = new T[high-low+1]; //申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
int begin1 = low;
int end1 = mid;
int begin2 = mid + 1;
int end2 = high;
for (k = 0; begin1 <= end1 && begin2 <= end2; ++k) //比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
{
if(array[begin1]<=array[begin2])
temp[k] = array[begin1++];
else
temp[k] = array[begin2++];
}
if(begin1 <= end1) //若第一个序列有剩余,直接拷贝出来粘到合并序列尾
memcpy(temp+k, array+begin1,
(end1-begin1+1)*sizeof(T));
if(begin2 <= end2) //若第二个序列有剩余,直接拷贝
出来粘到合并序列尾
memcpy(temp+k, array+begin2,
(end2-begin2+1)*sizeof(T));
memcpy(array+low, temp, (high-low+1)*sizeof(T));//将排序好的序列拷贝回数组中
delete temp;
}
template<typename T>
void merge_sort(T array[], unsigned int first, unsigned int last)
{
int mid = 0;
if(first<last)
{
//mid = (first+last)/2; /*注意防止溢出*/ mid = first/2 + last/2;
//mid = (first & last) + ((first ^ last) >> 1); merge_sort(array, first, mid);
merge_sort(array, mid+1,last);
merge(array,first,mid,last);
}
}
template<typename T>
void Print(T* r,int n)
{
for (int i=0;i<n;i++)
{
cout << r[i] << endl;
}
}
int main()
{
cout << "Welcome..." << endl;
double r[] = {1.5,3.2,5,6,9.2,7,2,4,8}; //BubbleSort(r,9);
QuickSort(r,0,8);
//insert_sort(r,9);
//shell_sort(r,9);
//SelectSort(r,9);
//HeapSort(r,9);
// merge_sort(r,0,8);
Print(r,9);
return 0;
}