地图中最短路径的搜索算法研究
学生:李小坤 导师:董峦
摘要:目前为止, 国内外大量专家学者对“最短路径问题”进行了深入的研究。本文通过理论分析, 结合实际应用,从各个方面较系统的比较广度优先搜索算法(BFS)、深度优先搜索算法(DFS)、A* 算法的优缺点。
关键词:最短路径算法;广度优先算法;深度优先算法;A*算法;
The shortest path of map's search algorithm
Abstract:So far, a large number of domestic and foreign experts and scholars on the" shortest path problem" in-depth study. In this paper, through theoretical analysis and practical application, comprise with the breadth-first search algorithm ( BFS ), depth-first search algorithm ( DFS ) and the A * algorithms from any aspects of systematic.
Key words: shortest path algorithm; breadth-first algorithm; algorithm; A * algorithm;
前言:
最短路径问题是地理信息系统(GIS)网络分析的重要内容之一,而且在图论中也有着重要的意义。实际生活中许多问题都与“最短路径问题”有关, 比如: 网络路由选择, 集成电路设计、布线问题、电子导航、交通旅游等。本文应用深度优先算法,广度优先算法和A*算法,对一具体问题进行讨论和分析,比较三种算的的优缺点。
在地图中最短路径的搜索算法研究中,每种算法的优劣的比较原则主要遵循以下三点:[1]
(1)算法的完全性:提出一个问题,该问题存在答案,该算法能够保证找到相应的答案。算法的完全性强是算法性能优秀的指标之一。
(2)算法的时间复杂性: 提出一个问题,该算法需要多长时间可以找到相应的答案。算法速度的快慢是算法优劣的重要体现。
(3)算法的空间复杂性:算法在执行搜索问题答案的同时,需要多少存储空间。算法占用资源越少,算法的性能越好。
地图中最短路径的搜索算法:
1、广度优先算法
广度优先算法(Breadth-First-Search),又称作宽度优先搜索,或横向优先搜索,是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型,Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。广度优先算法其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位址,彻底地搜索整张图,直到找到结果为止。BFS并不使用经验法则算法。
广度优先搜索算法伪代码如下:[2-3]
BFS(v)//广度优先搜索G,从顶点v开始执行
//所有已搜索的顶点i都标记为Visited(i)=1.
//Visited的初始分量值全为0
Visited(v)=1;
Q=[];//将Q初始化为只含有一个元素v的队列
while Q not null do
u=DelHead(Q);
for 邻接于u的所有顶点w do
if Visited(w)=0 then
AddQ(w,Q); //将w放于队列Q之尾
Visited(w)=1;
endif
endfor
endwhile
end BFS
这里调用了两个函数:AddQ(w,Q)是将w放于队列Q之尾;DelHead(Q)是从队列Q取第一个顶点,并将其从Q中删除。重复DelHead(Q)过程,直到队列Q空为止。
完全性:广度优先搜索算法具有完全性。这意指无论图形的种类如何,只要目标存在,则BFS一定会找到。然而,若目标不存在,且图为无限大,则BFS将不收敛(不会结束)。
时间复杂度:最差情形下,BFS必须寻找所有到可能节点的所有路径,因此其时间复杂度为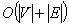 ,其中|V|是节点的数目,而 |E| 是图中边的数目。
,其中|V|是节点的数目,而 |E| 是图中边的数目。
空间复杂度:因为所有节点都必须被储存,因此BFS的空间复杂度为,其中|V|是节点的数目,而|E|是图中边的数目。另一种说法称BFS的空间复杂度为O(B),其中B是最大分支系数,而M是树的最长路径长度。由于对空间的大量需求,因此BFS并不适合解非常大的问题。[4-5]
2、深度优先算法
深度优先搜索算法(Depth First Search)英文缩写为DFS,属于一种回溯算法,正如算法名称那样,深度优先搜索所遵循的搜索策略是尽可能“深”地搜索图。[6]其过程简要来说是沿着顶点的邻点一直搜索下去,直到当前被搜索的顶点不再有未被访问的邻点为止,此时,从当前辈搜索的顶点原路返回到在它之前被搜索的访问的顶点,并以此顶点作为当前被搜索顶点。继续这样的过程,直至不能执行为止。
深度优先搜索算法的伪代码如下:[7]
DFS(v) //访问由v到达的所有顶点
Visited(v)=1;
for邻接于v的每个顶点w do
if Visited(w)=0 then
DFS(w);
endif
endfor
end DFS
作为搜索算法的一种,DFS对于寻找一个解的NP(包括NPC)问题作用很大。但是,搜索算法毕竟是时间复杂度是O(n!)的阶乘级算法,它的效率比较低,在数据规模变大时,这种算法就显得力不从心了。[8]关于深度优先搜索的效率问题,有多种解决方法。最具有通用性的是剪枝,也就是去除没有用的搜索分支。有可行性剪枝和最优性剪枝两种。
BFS:对于解决最短或最少问题特别有效,而且寻找深度小,但缺点是内存耗费量大(需要开大量的数组单元用来存储状态)。
DFS:对于解决遍历和求所有问题有效,对于问题搜索深度小的时候处理速度迅速,然而在深度很大的情况下效率不高。
3、A*算法
1968年的一篇论文,“P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths in graphs. IEEE Trans. Syst. Sci. and Cybernetics, SSC-4(2):100-107, 1968”。[9]从此,一种精巧、高效的算法——A*算法问世了,并在相关领域得到了广泛的应用。A* 算法其实是在宽度优先搜索的基础上引入了一个估价函数,每次并不是把所有可扩展的结点展开,而是利用估价函数对所有未展开的结点进行估价, 从而找出最应该被展开的结点,将其展开,直到找到目标节点为止。
A*算法主要搜索过程伪代码如下:[10]
创建两个表,OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。
算起点的估价值;
将起点放入OPEN表;
while(OPEN!=NULL) //从OPEN表中取估价值f最小的节点n;
if(n节点==目标节点) break;
endif
for(当前节点n 的每个子节点X)
算X的估价值;
if(X in OPEN)
if(X的估价值小于OPEN表的估价值)
把n设置为X的父亲;
更新OPEN表中的估价值; //取最小路径的估价值;
endif
endif
if(X inCLOSE)
if( X的估价值小于CLOSE表的估价值)
把n设置为X的父亲;
更新CLOSE表中的估价值;
把X节点放入OPEN //取最小路径的估价值
endif
endif
if(X not inboth)
把n设置为X的父亲;
求X的估价值;
并将X插入OPEN表中; //还没有排序
endif
end for
将n节点插入CLOSE表中;
按照估价值将OPEN表中的节点排序; //实际上是比较OPEN表内节点f的大小,从最小路径的节点向下进行。
end while(OPEN!=NULL)
保存路径,即 从终点开始,每个节点沿着父节点移动直至起点,这就是你的路径;
A *算法分析:
DFS和BFS在展开子结点时均属于盲目型搜索,也就是说,它不会选择哪个结点在下一次搜索中更优而去跳转到该结点进行下一步的搜索。在运气不好的情形中,均需要试探完整个解集空间, 显然,只能适用于问题规模不大的搜索问题中。而A*算法与DFS和BFS这类盲目型搜索最大的不同,就在于当前搜索结点往下选择下一步结点时,可以通过一个启发函数来进行选择,选择代价最少的结点作为下一步搜索结点而跳转其上。[11]A *算法就是利用对问题的了解和对问题求解过程的了解, 寻求某种有利于问题求解的启发信息, 从而利用这些启发信息去搜索最优路径.它不用遍历整个地图, 而是每一步搜索都根据启发函数朝着某个方向搜索.当地图很大很复杂时, 它的计算复杂度大大优于D ijks tr a算法, 是一种搜索速度非常快、效率非常高的算法.但是, 相应的A*算法也有它的缺点.启发性信息是人为加入的, 有很大的主观性, 直接取决于操作者的经验, 对于不同的情形要用不同的启发信息和启发函数, 且他们的选取难度比较大,很大程度上找不到最优路径。
总结:
本文描述了最短路径算法的一些步骤,总结了每个算法的一些优缺点,以及算法之间的一些关系。对于BFS还是DFS,它们虽然好用,但由于时间和空间的局限性,以至于它们只能解决规模不大的问题,而最短或最少问题应该选用BFS,遍历和求所有问题时候则应该选用DFS。至于A*算法,它是一种启发式搜索算法,也是一种最好优先的算法,它适合于小规模、大规模以及超大规模的问题,但启发式搜索算法具有很大的主观性,它的优劣取决于编程者的经验,以及选用的启发式函数,所以用A*算法编写一个优秀的程序,难度相应是比较大的。每种算法都有自己的优缺点,对于不同的问题选择合理的算法,才是最好的方法。
参考文献:
[1]陈圣群,滕忠坚,洪亲,陈清华.四种最短路径算法实例分析[J].电脑知识与技术(学术交流),2007(16):1030-1032
[2]刘树林,尹玉妹.图的最短路径算法及其在网络中的应用[J].软件导刊,2011(07):51-53
[3]刘文海,徐荣聪.几种最短路径的算法及比较[J].福建电脑,2008(02):9-12
[4]邓春燕.两种最短路径算法的比较[J].电脑知识与技术,2008(12):511-513
[5]王苏男,宋伟,姜文生.最短路径算法的比较[J].系统工程与电子技术,1994(05):43-49
[6]徐凤生,李天志.所有最短路径的求解算法[J].计算机工程与科学,2006(12):83-84
[7]李臣波,刘润涛.一种基于Dijkstra的最短路径算法[J].哈尔滨理工大学学报,2008(03):35-37
[8]徐凤生.求最短路径的新算法[J].计算机工程与科学,2006(02).
[9] YanchunShen . An improved Graph-based Depth-First algorithm and Dijkstra algorithm program of police patrol [J] . 20## International Conference on Electrical Engineering and Automatic Control , 2010(3) : 73-77
[10]部亚松.VC++实现基于Dijkstra算法的最短路径[J].科技信息(科学教研),2008(18):36-37
[11] 杨长保,王开义,马生忠.一种最短路径分析优化算法的实现[J]. 吉林大学学报(信息科学版),2002(02):70-74
第二篇:基于启发式搜索算法的地图寻径的研究
北京工业大学
硕士学位论文
基于启发式搜索算法的地图寻径的研究
姓名:许鹏
申请学位级别:硕士
专业:计算机应用技术
指导教师:许向众
20090401
摘要
摘要
随着计算机技术及因特网技术在中国的发展,中国游戏产业逐渐形成规模。尤其是这几年,国家提倡电脑游戏软件的自主研发,因此各种游戏引擎软件中的技术和算法成为了人们研发的热点,其中地图寻径算法是游戏引擎软件中最重要的算法之一。最常用的地图寻径算法是一种启发式搜索算法——^,Ic算法。而传统的A木算法在数据结构优化方面没有做足够的研究,因此在这方面还有优化的余地。其次,各种对A木算法的研究过于理论化,而将A水算法实际的使用在项目当中的研究极少,这也是地图寻径算法研究的一个欠缺。
本文针对以上所述的两点不足进行了研究和探讨。首先,通过设计算法演示程序研究了A水算法在地图寻径中的执行过程,对其整个过程中的各种操作进行了详细分析,针对分析结果提出了几种数据结构的设计,并将新设计的数据结构用于算法当中,通过算法的执行,对各种优化结果做比较,得到最优的数据结构设计。其次,本文将抽象的胁算法实例化,对算法进行适应实际应用的扩展,并对实际中出现的各种问题进行研究和探讨,设计出相应的解决方案,并设计一个小型的演示程序,使优化后的胁算法应用于实际的地图寻径中,实现真实的地图寻径程序,对理论做出验证,达到本文所提出的目标,弥补目前对这方面研究的欠缺,对后人有一定的借鉴意义。,关键词启发式搜索;地图寻径;胁算法
Abstract
曼曼皇蔓曼皇鼍皇曼鼍曼曼!皇曼曼曼曼!曼I|
一
I鼍曼曼曼!!曼皇鼍!曼蔓曼!量曼寰!皇
Abstract
With
thedevelopmentofcomputertechnologyandthe
Interacttechnology
in
China,theChinesecomputergameindustryformsthescalegradually.EspeciallyIIl
recentyears。national
advocatecomputergames
sofhNare’sindependentresearch,
thereforethealgorithmsinthethe
game
enginesoftwarehavebecomethe
focus
which
research,themappathfindingalgorithmisoneofmostimportant
algorithmsinthegameenginesoftware.Themostcommonlyusedpathfinding
people
algorithmis
a
heuristicsearch
algorithm-A*algorithm.TraditionalA串algorithm’S
too
datastructureoptimizationisnotenough,SOitexistsroomforoptimization.Secondly,
theresearchaboutA?algorithmistheprojectisalackofresearch.algorithmdemo
entire
course
theoretical,theA?algorithm’Sapplicationin
Inthispaper,twopointsabovehavebeenstudied.Firstofall,throughthedesign
program
tostudythe
A?algorithm’Simplementation
a
a
process,The
on
ofthevariousoperationsiscarriedoutdetailedanalysis,based
analysisoftheresults,thepaperdesigned
the
newdatastructure,andputthenew
to
designed
algorithm’s
implementationandthecomparisonofthevariousdatastructures,thepapergotthebestdesignofthedatastructure.Secondly,thisarticleputtheabstractA?algorithm
intothepractical
datastructuresinto
algorithm.According
A?algorithm
a
the
application,andexpandthe
accordingtopractical,
smalldcmoprogram,SOthatthe
optimizedA?algorithmisappliedtotheactualpathfinding,verifythetheory,achievetheobjectofthispaper,makeupthelackofresearchinthisarea,havereferential
designedthecorrespondingsolutions,anddesigned
significance
Keywords
forotherpeople.
heuristicsearch;mappathfind;A?algorithm
ⅡI
独创性声明
本人声明所呈交的论文是我个人在导师指导下进行的研究工作及取得的研究成果。尽我所知,除了文中特别加以标注和致谢的地方外,论文中不包含其他人已经发表或撰写过的研究成果,也不包含为获得北京工业大学或其它教育机构的学位或证书而使用过的材料。与我~同工作的同志对本研究所做的任何贡献均已在论文中作了明确的说明并表示了谢意。
签名:
关于论文使用授权的说明
本人完全了解北京工业大学有关保留、使用学位论文的规定,即:学校有权保留送交论文的复印件,允许论文被查阅和借阅:学校可以公布论文的全部或部分内容,可以采用影印、缩印或其他复制手段保存论文。
签名:单导师签名:(保密的论文在解密后应遵守此规定)眺帮
第1章绪论
第1章绪论
1.1课题的背景及意义
随着计算机多媒体技术的发展,计算机游戏逐渐成为了人们数字娱乐生活中重要的一部份。近几年,中国的计算机游戏产业逐渐发展成熟,行业已经形成了一定的规模。但是中国的游戏软件研发能力薄弱,技术研发仍远落后于发达国家水平。国家相关部门在最近提出了要发展民族游戏产业,通过多项措施和政策来提倡国人的自主研发能力。因为游戏软件的本质就是多媒体技术和人工智能算法的应用,所以这为多媒体技术和人工智能技术的发展提供了很好的发展机遇。多媒体技术的研发和人工智能已经成为了人们研发的热点。
本课题就是关于人工智能中启发式搜索算法在地图寻径中的应用。地图寻径问题就是人工智能搜索技术的一个重要应用领域。在图论中,寻径问题通常是人们研究的热点问题之一.
其所要解决的问题是如何设法从图中寻找到一条从起点到目标点的通路,算法中需要解决的最基本问题是如何避开障碍物:而在游戏软件中,地图寻径问题并非如此简单,必须考虑多方面的因素,比如算法的运行效率、动态障碍物等。启发式搜索算法有多种,他们的搜索原理都是一样的,都是利用启发信息进行图
本课题的研发很有意义,从大的环境来说,随着国家提倡自主研发和中国游其次在学术研究方面有以下的意义:从算法效率方面讲,本课题将对算法原同于其他的应用软件,游戏软件是实时性的,对算法的效率要求很高。而原有的
从应用的方面讲。把A木算法应用到实际的地图寻径当中,会有很多实际问搜索,只是搜索的策略不同而取不同的名字。本课题中使用的是启发式搜索中最具有代表性和效率最高的A水算法。戏产业的成熟,游戏引擎研发中的各种技术的研发成为热点。有的未优化过的数据结构进行优化,使得算法的效率得到提高。因为游戏软件不胁算法中使用的数据结构需要实时的分配内存、对队列进行排序查找等操作,这些操作随着节点的增加而变得越来越慢,算法的效率于是变得很低。本课题将使用时间复杂度低的数据结构进行操作,这将在一定程度上提高效率,使得这个算法更加适应于游戏软件的应用。题需要解决。例如游戏中电子地图是表格化的,而路径应该是像素化的,这就需要对寻找到的路径进行细化和处理。还有一些其它问题,如地图地形的改变,动态障碍物等问题需要处理。在这些问题上的研究较少,可借鉴的资料也不多。本课题将对实际的应用进行研究,对各种问题进行处理。
北京工业大学工学硕士学位论文
1.2研究现状
1968年,P.E.Hart,N.J.Nilsson和B.Raphael共同发表了一篇在启发式搜索方面具有深远影响力的论文:“P.E.Hart,N.J.NilssonandB.Raphael.Aformalbasisfortheheuristicdeterminationofminimumcostpathsingraphs.IEEETrans.Syst.Sci.andCybernetics,SSC一4(2):100—107,1968"。从此,一种精巧、高效的算法斛算法诞生了,并在相关领域得到了广泛的应用。最初斛算法被用来解决各类数学问题n,。
随着人工智能的发展,A木算法被用来解决寻路问题。在此之后的时间里,对A,Ic算法的研究和改进成为一个热门的课题。研究的兴趣主要表现在对其数据结构的优化。主要表现在以下几个方面:对开启队列和关闭队列分别采用数组、链表等来提高操作的效率;对内存进行提前分配来避免运行期间分配堆内存的时间;对地图进行预处理来提高某些操作的效率等等。各种各样的优化和设计对提高算法的效率起到了很大的作用。未排序数组或者链表使插入操作很快而集体关系检查和删除操作非常慢。排序数组或者链表使集体关系检查稍微快一些,删除(最佳元素)操作非常快而插入操作非常慢。二元堆让插入和删除操作稍微快一些,而集体关系检查则很慢。伸展树让所有操作都快一些。HOT队列让插入操作很快,删除操作相当快,而集体关系检查操作稍微快一些。索引数组让集体关系检查和插入操作非常快,但是删除操作不可置信地慢,同时还需要花费很多内存空间。.在应用方面的研究多为实际的项目设计,比如微软公司的AGE游戏软件使用
的就是A半算法。而纯粹的研究较少。实际中的又有些问题有一定的研究,如组运动。一种解决方案是利用胁算法的中间状态。这个状态可以被朝着相同目标移动的多个物体共享,只要物体共享相同的启发式函数和代价函数。当主循环退出时,不要消除oPEN和CLoSED集;用斛上一次的OPEN和CLoSED集开始下一次的循环馏1。
1.3研究目的及内容
本课题有两个研究目的。第一个是对算法中使用的数据结构进行重新设计和使之适应于具体应用,并运用于实际的地图寻径中。
本课题研究内容是启发式搜索算法以及地图寻径。
首先引入状态空间搜索的概念。状态空间搜索,就是将问题求解过程表示为从初始状态到目标状态的路径寻找过程。由于求解问题的过程中有很多的分支,求解过程中存在求解条件的不确定性,不完备性,从而使得求解的路径也很多,这就构成了一个图,我们称这个图为状态空间图。问题的求解实际上就是在这个图中找到一条最短路径,可以从开始到结果。而这个寻找的过程就是状态空间搜优化,使得优化后算法的效率得到提高。第二个是对抽象的算法进行实例化研究,
第1章绪论.
索嘲。
启发式搜索中的对启发信息的利用是用通过估价函数体现的。估价函数的任务就是估计待搜索结点的重要程度,给它们排定次序。估价函数f(x)可以是任意一种函数,如定义它是结点x处于最佳路径上的概率,或是X结点和目标结点之间的距离等等。一般来说,评价一个结点的价值,必须综合考虑两方面的因素:已付出的代价和将要付出的代价。因此,估计函数f(n)定义为从初始结点经过n结点到达目标结点的最小代价路径的代价估计值。它的一般形式是:
f(n)=g(n)+h(n)
其中f(n)是结点n的估价函数,g(n)是在状态空间中从初始结点到n结点的实际代价,h(n)是从n结点到目标结点最短路径的估计代价。其中主要是h(n)体现了搜索的启发信息,因为实际代价g(n)可以根据生成的搜索树实际计算出来,而估计代价h(n)却依赖于某种经验估计,它来源于我们对问题的解的某些特性的认识,这些特性可以帮助我们更快地找到问题的解H1。
地图寻径问题要解决的问题是如何从图中找到一条从起点到目标点的通路。在游戏中,人物或车辆从一个位置A移动到另外一个位置B,就必须找出A到B之间的通路,因为AB之间的直接连线可能会穿过障碍物,而人物或车辆不能穿透障碍物。人物或车辆的移动在游戏中又非常普遍,所以游戏地图的寻径算法就成了游戏中一个至关重要的基础性算法。本课题是利用启发式搜索算法进行地图寻径。
利用启发式搜索算法进行地图寻径就是把地图中的每一个瓷砖看成是一个状态,每次移动都是从一个状态进入另一个状态。在这个状态空间图中,我们的目的就是找到目标状态,从而完成寻径哺1。这就是基于启发式搜索算法的地图寻径的基本思路,也是本课题研究的主要内容。
1.4论文的组织结构
本论文分为四章。
第一章是绪论,介绍本课题的研究背景、研究意义、研究目的以及研究内容。
第二章是对搜索算法的简介,阐述了非启发式搜索算法与启发式搜索算法的内容,如状态空间、产生式系统、状态图示法、回溯法、宽度优先搜索、深度优先搜索等,最后引出了本课题所使用的启发式搜索算法A木算法,对A术算法的基本原理和应用情况进行了介绍。
第三章是对于A木算法数据结构的优化问题,在这章节中,首先通过运行演示软件来分析胁算法的执行过程,包括单步执行和正常执行,在执行结束后,记录下来各种执行期间的数据统计,并以图表的形式反映出来。之后根据分析结果提出两个原理并加以证明,为之后数据结构的优化提供了设计基础。接着进行数据结构的优化。具体的优化方案是:第一,将哈希表的数据结构作为A水算法的
北京工业大学工学硕士学位论文
OPEN集合,使用估计值作为哈希表的关键字,采用链地址法进行冲突的处理;第二,使用二维数组对每个结点进行标记,使得查找每个结点的集合归属运算效率大大提高。最后,通过运行测试软件进行测试,经过多个地图多次测试后证明之前优化方案的正确与否。
第四章是胁算法的实际应用。在这章节中,首先分析了A术算法在具体应用中可能会出现的问题。为了解决这些问题,在这章节中设计了协调算法。接着,通过设计一个演示模型软件,将斛算法和协调算法运用到了实际的寻径当中,对章节中所设计的算法进行测试,并得出测试结论。
第2章搜索算法简介
第2章搜索算法简介
2.1概述
搜索技术是人工智能的基本技术之一,在人工智能各应用领域中被广泛地使用。早期的人工智能程序与搜索技术联系就更为紧密,几乎所有的早期的人工智能程序都是以搜索为基础的。例如,A.Nwelel和H.A.Simno等人编写的TL(LogicTheorist)程序,J.Slagle编写的符号积分程序SAINT,A.Newell和H.A.Simon编写的GPS(General
theoremprovingProblemSolver)程序,H.Gelernter编写的Geometrymachine程序,R.Pikes和N.Nilsson编写的STRIPS(Stanford
Solver)程序以及A.Samuel编写的ChecherS程序ResearchInstituteProblem
等,都使用了各种搜索技术。现在,搜索技术渗透在各种人工智能系统中,可以说没有哪一种人工智能的应用不用搜索方法,在专家系统、自然语言理解、自动程序设计、模式识别、机器人学、信息检索和博弈都广泛使用搜索技术∞1。
搜索问题是AI核心理论问题之一。一般一个问题可以用好几种搜索技术解决,选择一种好的搜索技术对解决问题的效率很有关系,甚至关系到求解问题有没有解。
2.2状态空间
我们所碰到的每种问题的求解方法都需要某种对解答的搜索。不过,在搜索过程开始之前,必须先用某种方法或某几种方法的混合来表示问题。这些表示问题的方法,可能涉及状态空间、问题归约或谓词公式,或者把问题表示为一条要证明的定理,等等。任何比较复杂的求解技术都离不开两方面的内容:表示与搜索。
问题求解涉及归约、推断、决策、规划、常识推理、定理证明和相关过程的核心概念。在分析了人工智能研究中运用的问题求解方法之后,就会发现许多问题求解方法是采用试探搜索方法的。也就是说,这些方法是通过在某个可能的解空间内寻找一个解来求解问题的。这种基于解答空间的问题表示和求解方法就是状态空间法,它是以状态和算符为基础来表示和求解问题的。
2.2.1状态空间描述
首先对状态和状态空间下个定义:
状态是为描述某类不同事物间的差别而引入的一组最少变量qO,ql,…,qn的有序集合,其矢量形式如下:Q=[qO,ql,???,qn]
北京工业大学工学硕士掌位论文
上式中每个元素qi(i=O,1,…,n)为集合的分量,称之状态变量。给定每个分量的一组值就得到一个具体的状态,如:
Q=[qOk,qlk,…,qnk]
使问题从一种状态变化为另一种状态的手段称为操作符或算符。操作符可为走步、过程、规则、数学算子、运算符号或逻辑符号等。
问题的状态空间是一个表示该问题全部可能状态及其关系的图,它包含三种说明的集合,即所有可能的问题初始状态集合S、操作符集合F以及目标状态集合G。因此,可把状态空间记为三元状态(S,F,G)口1。
2.2.2状态图示法
为了对状态空间图有更深入的了解,这里介绍一下图论中的几个术语和图的正式表示法。
图有节点的集合构成,节点可能是有限的或无限的。一对节点用弧线连接起来,从一个节点指向另一个节点,这种图叫做有向图。如果某条弧线从节点ni,指向节点nj,那么节点nj就叫做节点ni的后继节点或后裔,而节点ni叫做节点nj的父辈节点或祖先。在各种图中,一个节点只有有限个后继节点。一对节点可能互为后裔,这时,该对有向弧线就用一条棱线代替。当用一个图来表示某个状态空间时,图中各节点标上相应的状态描述,而有向弧线旁边标有算符。
如果从节点ni至节点nj存在有一条路径,那么就称为节点nj是从节点ni可达到的节点,或者称节点nj为节点ni的后裔,而且称ni为节点nj的祖先。可以发觉,寻找从一种状态变换为另一种状态的某个算符序列问题等价于寻求图的某一路径问题阻,。
给各弧线指定代价以表示加在相应算符上的代价常常是方便的。用c(ni,nj)来表示节点ni指向节点nj的那段弧线的代价。两节点间路径的代价等于连接该路径上各节点的所有弧线代价之和。对于最优化问题,要找到两节点间具有最小代价的路径。
对于最简单的一类问题,需要求得某指定节点,即初始状态节点与另一节点,即目标状态节点之间的一条路径,可能具有最小代价。
一个图可由显式说明也可由隐式说明。对于显式说明,各节点及其具有代价的弧线由一张表明确给出。此表可能列出该图中的每一节点、它的后继节点以及连接弧线的代价。
2.2.3显式状态空间搜索。
显式图搜索方法涉及到在图节点上传播“标记”。我们把开始节点标记为O,然后顺着图的边,连续传播更大的整数直至遇到目标节点。然后,顺着数字下降序列从目标点回溯到开始节点。顺着开始点到目标点路径上的动作序列就是获得
第2章搜索算法简介
目标应该采取的动作。这种方法需要0(n)步,n是图中的节点数目,如果只有一个目标节点,这个过程也可以从相反方向实现,从目标节点开始,直到某个整数遇到了开始节点。搜索过程中放在节点上的数字可以作为该节点上的一个函数,并且开始节点有一个全局最小值。相反路径,从目标到开始顺着这个函数的“梯度"下降。
把标记一个节点的后继节点的过程称为扩展。扩展将标记放在所有己标记过的节点的未标一记的相邻节点上。应将哪一个已标记但还没有扩展的节点作为下一个扩展点是一个很重要的效率问题。在广度优先搜索中,下一个要扩展的节点是其节点标识数不大于任何其他没有扩展的节点标识数的节点。也就是说,在扩展标识为j的节点之前,先要扩展标识为j的所有节点,条件是i<j。其他搜索算法有不同的节点扩展选择,这些将在后面详细讨论。
因此,所谓状态空间搜索,就是将问题的求解过程表示为从初始状态直到目标状态的全过程。由于求解过程中求解条件的不确定性及不完备性,一般会出现多条求解路径,所有求解路径构成的图即所谓的状态空间。问题的求解过程实际上是要在状态空间中寻找一条从起点到目标点的路径,称该寻找过程为状态空间搜索。状态空间搜索法存在着一个自身缺陷:需要在一个给定的状态空间中实施穷举嘲。
2.3传统搜索算法
搜索算法是利用计算机的高性能来有目的的穷举一个问题的部分或所有的可能情况,从而求出问题的解的一种方法。搜索过程实际上是根据初始条件和扩展规则构造一棵解答树并寻找符合目标状态的节点的过程。
所有的搜索算法从其最终的算法实现上来看,都可以划分成两个部分:控制结构和产生系统,而所有的算法的优化和改进主要都是通过修改其控制结构来完成的。
传统搜索技术是不利用问题的有关信息,而根据事先确定好的某种固定的搜索方法进行搜索。典型的传统搜索方法是宽度优先搜索,亦称广度优先搜索,和深度优先搜索,这是两种基本搜索方法。这里先介绍回溯策略的一般策略,然后再介绍宽度优先搜索和深度优先搜索。
2.3.1回溯法
回溯算法是所有搜索算法中最为基本的一种算法。优先搜索法按条件向前搜索以达到目的.但当搜索到某一步时,发现原先选择并不优或达不到目标,就退回上一步重新选择,这种走不通退回再走的技术称为回溯法n们。
其采用了一种“走不通就掉头”思想作为其控制结构,其相当于采用了先根遍历的方法来构造解答树,可用于找解或所有解以及最优解。
北京工业大学工学硕士学位论文
回溯算法也叫试探法,它是一种系统地搜索问题的解的方法。回溯算法的基本思想是:不是按某种固定的计算方法来设计算法,而是通过尝试和纠正错误来寻找答案。用回溯算法解决问题的一般步骤为:
1.定义一个解空间,它包含问题的解。
2.利用适于搜索的方法组织解空间。
3.利用深度优先法搜索解空间。
4.利用限界函数避免移动到不可能产生解的子空间。
回溯算法的一个重要特性是问题的解空间通常在搜索问题的解的过程中动态产生的。它对空间的消耗较少,当其与分枝定界法一起使用时,对于所求解在解答树中层次较深的问题有较好的效果。但应避免在后继节点可能与前继节点相同的问题中使用,以免产生循环n11。
2.3.2宽度优先搜索
宽度优先搜索算法是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。
如果搜索是以接近起始节点的程度依次扩展节点的,那么这种搜索算法就叫做宽度优先搜索,如图2一l所示。从图2-1可见,这种搜索是逐层进行的,在对下一层的任一节点进行搜索之前,必须搜索完本层的所有节点。
图2-1宽度优先搜索示意图
Figure2-?1breadth??searchdiagram
己知图G=(V,。E)和一个源顶点s,宽度优先搜索以一种系统的方式探寻G的边,从而发现s所能到达的所有顶点,并计算s到所有这些顶点的距离,即最少边数,该算法同时能生成一棵根为s且包括所有可达顶点的宽度优先树。对从s可达的任意顶点v,宽度优先树中从s到v的路径对应于图G中从s到v的最
第2章搜索算法简介
短路径,即包含最小边数的路径。该算法对有向图和无向图同样适用。
之所以称之为宽度优先算法,是因为算法自始至终一直通过己找到和未找到顶点之间的边界向外扩展,就是说,算法首先搜索和S距离为k的所有顶点,然后再去搜索和s距离为k+l的其他顶点。
宽度优先搜索算法如下:
1.把起始节点放到未扩展节点OPNE表中(如果该起始节点为一目标节点,则求得一个解答)。
2.如果OPEN是个空表,则没有解,失败退出,否则继续。
3.把第一个节点n从OPNE表移出,并把它放入己扩展节点CLOSED表中。4.扩展节点n,如果没有后继节点,则转向上述第2步。
5.把n的所有后继节点放到OPEN表的末端,并提供从这些后继节点回到n的指针。
6.如果n的任一个后继节点是个目标节点,则找到一个解答,成功退出,否则转向第2步。
宽度优先搜索算法流程图如图2-2所示:
图2-2宽度优先算法流程图
Figure2-2breadth??searchflowchart
这一算法假定起始节点本身不是目标节点,要检索起始节点是目标节点的可能性,只要在第1步的末了,加上一句“如果起始节点为一目标节点,则求得一
北京工业大学工学硕士学位论文
个解答”即可做到,正如第l步括号内所写的。这个搜索过程产生的节点和指针构成一棵隐式定义的状态空间树的子树,我们称之为搜索树n刳。
显而易见,宽度优先搜索方法能够保证在搜索树中找到~条通向目标节点的最短路径,这棵搜索树提供了所有存在的路径,如果没有路径存在,那么对有限图来说,我们就说该法失败退出,对于无限图来说,则永远不会终止。2.3.3深度优先搜索
另一种盲目搜索叫做深度优先搜索。正如算法名称那样,深度优先搜索所遵循的搜索策略是尽可能深的搜索图。在深度优先搜索中,对于最新发现的顶点,如果它还有以此为起点而未探测到的边,就沿此边继续探下去。当结点v的所有边都己被探寻过,搜索将回溯到发现结点v有那条边的始结点。这一过程一直到已发现从源结点可达的所有结点为止。如果还存在未被发现的结点,则选择其中一个作为源结点并重复以卜过程,整个进程反复进行直到所有结点都被发现为止。
在深度优先搜索中,首先扩展最新产生的节点,即最深的,如图2-3所示。深度相等的节点可以任意排列。定义节点的深度如下:
1.起始节点(即根节点)的深度为0。
2.任何其它节点的深度等于其父辈节点深度加l。
首先,扩展最深节点的结果使得搜索沿着状态空间某条单一的路径从起始节点向下进行下去,只有当搜索到达一个没有后裔的状态时,它才考虑另一条替代的路径。替代路径前面已经试过的路径不同之处仅仅在于改变最后n步,而且保持n尽可能小。
第2章搜索算法简介
图2-3深度优先搜索示意图
Figure2?3depth-searchdiagram
对于许多问题,其状态空间搜索树的深度可能为无限深,或者可能至少要比某个可接的解答序列的已知深度上限深度还要深。为了避免考虑太长的路径,防止搜索过程沿着无益的路径扩展下去,往往给出一个节点扩展的最大深度:深度界限。任何节点如果到了深度界限,那么都将把它们作为没有后继节点处理。值得说明的是,即使应用了深界限的规定,所求得的解答路径并不一定就是最短路径。
和宽度优先搜索类似,每当扫描己发现结点u的邻接表从而发现新结点v时,深度优搜索将置v的先辈域为u。和宽度优先搜索不同的是,前者的先辈子图形成一棵树,后者产生的先辈子图可以由几棵树组成,因为搜索可能由多个源顶点开始重复进行n钉。
有深度界限的深度优先搜索算法如下:
1.把起始节点s放到未扩展节点OPNE表中,如果此节点为一目标节点,则得到一解。
2.如果OPEN为空表,则失败退出。
3.把第一个节点n从OPEN表移到已扩展节点CLOSED表中。
4.如果节点n的深度等于最大深度,则转向(2)。
5.扩展节点n,产生其全部后裔,并把它们放入OPEN表的前头。如果没有后裔,则转向(2)。
6.如果后继节点中有任一个为目标节点,则求得一个解,成功退出,否则,转向(2)。’有界深度优先搜索算法的程序框图如图2-4所示:
北京工业大学工学硕士学位论文
图2—4深度优先搜索流程图
Figure2-4depth-searchflowchart
2.4启发式搜索算法
上面讲的深度优先搜索和宽度优先搜索都没有用到本身的信息,搜索完全是盲目的按照固定顺序进行。盲目搜索的效率低.耗费过多的计算空间与时间。如果能够找到一种方法用于排列待扩展节点的顺序,即选择最有希望的节点加以扩展,那么,搜索效率将会大大提高。在许多情况下,能够通过检测来确定合理的顺序,称这类搜索为启发搜索或有信息搜索。因此,从有无信息导引这个角度,可将搜索方法分为以下三大类:1.无信息导引搜索,它可分为深度优先搜索和宽度优先搜索,其搜索与所给
第2章搜索算法简介
题信息无关,是人为安排的固定顺序,毫无根据的。
2.信息导引搜索,它可分为爬山策略和最小代价搜索,其搜索是利用向目标搜索的好坏来判断向哪个方向搜索,即搜索的顺序是有根据的。
3.启发式信息搜索,其搜索是利用具体领域的知识(具体体现在评价函数中),以提高算法的效率。
2.4.1启发式搜索的必要性
从理论上说,如果计算机可以使用的时间和空间是无限的,那么仅仅有盲目搜索算法也许就己经满足了,但实际情况并不是这样,更何况还有个搜索速度问题。现在己经发现了许多计算复杂性很高的问题,如旅行推销员问题,布尔表达式的化简问题等等。这些问题的现有算法都是具有指数复杂性的。
现实的困难迫使人们转而求援于启发式算法。这种算法的本质是部分地放弃算法“一般化,通用化’’的概念,把所要解的问题的具体领域的知识加进算法中去,’以提高算法的效率。如宽度优先算法几乎可以用于解一切搜索问题,比如九宫图(八数码难题),河内塔(焚塔问题),旅行推销员,华容道,以及魔方等等。但是实际使用时,效率也许低得惊人,甚至根本解不出来(例如魔方问题).但如果为每类问题找出一些特殊规则,和宽度优先法配合起来使用,那结果就可能完全不一样m1。
根据启发信息,在生成各种搜索树时可以考虑种种可能的选择,如:
1.下一步展开哪个节点?
2.是部分展开还是完全展开?
3.使用哪个规则(或算子)9
4.怎样决定舍弃还是保留新生成的节点?
5.怎样决定停止或继续搜索?
6.如何定义评价函数?
7.如何决定搜索方向?
等等。由于这些选择的不同,就得到了不同的启发式搜索算法。
启发式搜索是利用问题拥有的启发信息来引导搜索,达到减少搜索范围,降低问题复杂度的目的,这种利用启发信息的搜索过程都称为启发式搜索方法。在研究启发式搜索方法时,先说明一下启发信息应用,启发能力度量及如何获得启发信息这几个问题,然后再来讨论算法及一些理论问题。
一般来说启发信息过弱,产生式系统在找到一条路径前将扩展过多的节点,即求得解路径所需搜索的耗散值,也就是搜索花费的工作量较大,相反引入强的启发信息,有可能大大降低搜索工作量,但不能保证找到最小耗散值的解路径(最佳路径)。因此实际应用中,希望最好能引入降低搜索工作量的启发信息而不牺牲找到最佳路径的保证。这是一个重要而又困难的问题,从理论上要研究启发信
北京工业大学工学硕士学位论文
息和最佳路径的关系,从实际上则要解决获得启发信息方法的问题。
比较不同搜索方法的效果可用启发能力的强弱来度量。在大多数实际问题中,笔者认为感兴趣的是使路径的耗散值和求得路径所需搜索的耗散值两者的某种组合最小,更一般的情况是考虑搜索方法对求解所有可能遇见的问题,其平均的组合耗散值最小。如果搜索方法1的平均组合耗散值比方法2的平均组合耗散值低,则认为方法l比方法2有更强的启发能力。
启发式搜索过程中,要对OPEN表进行排序,这就需要有一种方法来计算待扩展节点有希望通向目标节点的不同程度,总是希望能找到最有希望通向目标节点的待扩展节点优先扩展。一种最常用法是定义一个评价函数f(EvaluationFunction)对各个节点进行计算,其目的就是用来估算出“有希望”的节点来。如何定义一个评价函数呢?通常参考的原则有:一个节点处在最佳路径上的概率:求出任意一个节点与目标节点集之间的距离度量或差异度量:根据格局或状态的特点来打分。即根据问题的启发信息,从概率角度、差异角度或记分法给出计算评价函数的方法n副。
2.4.2评价函数
评价函数的任务就是估计待搜索结点的重要程度,给它们排定次序。评价函数f(x)可以是任意一种函数,如定义它是结点x处于最佳路径上的概率,或是x结点和目标结点之间的距离,或是x格局的得分等等。一般来说,评价一个结点的价值,必须综合考虑两方面的因素:已付出的代价和将要付出的代价。在此,我们把评价函数f(n)定义为从初始结点经过n结点到达目标结点的最小代价路径的代价估计值。它的一般形式是:
f(n)=g(n)+h(n)
其中g(n)是从初始结点到n结点的实际代价,h(n)是从n结点到目标结点的最佳路径的估计代价,主要是h(n)体现了搜索的启发信息。因为实际代价g(n)可以根据生成的搜索树实际计算出来,而估计代价h(n)却依赖于某种经验估计,它来源于我们对问题的解的某些特性的认识,这些特性可以帮助我们更快地找到问题的解n引。
2.4.3有序搜索算法
用评价函数士、来排列OPEN表上的节点。根据习惯,OPEN表上的节点按照它们f函数值的递增顺序排列。根据推测,某个具有低的估价值的节点较有可能处在最佳路径上。应用某个算法选择OPEN表上具有最小f值的节点作为下一个要扩展的节点。这种搜索方法叫做有序搜索或最佳优先搜索,而其算法叫做有序搜索算法或最佳优先算法。可见它总是选择最有希望的节点作为下一个要扩展的节点。有序搜索又称为最好优先搜索。
第2苹搜索算法简介
有序状态空间搜索算法如下:
1.把起始节点S放到OPNE表中,计算f(S)并把其值与节点S联系起来。
2.如果OPEN是个空表,则失败退出,无解。
3.从OPEN表中选择一个f值最小的节点i。结果有几个节点合格,当其中有一个为目标节点时,则选择此目标节点,否则就选择其中任一个节点作为节点i.
4.把节点i从OPEN表中移出,并把它放入CLOSED的扩展节点表中。
5.如果i是个目标节点,则成功退出,求得一个解。
6.扩展节点i,生成其全部后继节点。对于i的每一个后继节点j:
(1)计算f(j)。
(2)如果j既不在OPEN表中,又不在CLOSED表中,则用评价函数f把它添入OPEN表。从j加一指向其父辈节点i的指针,以便一旦找到目标节点时记住一个解答路径。
(3)如果j已在OPEN表上或CLOSED表上,则比较刚刚对j计算过的f值和前面计算过的该节点在表中的f值。如果新的f值较小,则
①以此新值取代旧值。
②从j指向i,而不是指向它的父辈节点。
③如果节点j在CLOSED表中,则把它移回OPNE表。
7.转向(2),即GOTO(2)。
宽度优先搜索、等代价搜索和深度优先搜索统统是有序搜索技术的特例。对于宽度优先搜索,我们选择f(i)作为节点i的深度。对于等代价搜索,f(i)是从起始节点至节点i这段路径的代价。
有序搜索的有效性直接取决于f的选择,如果选择的f不合适,有序搜索就可能失去一个最好的解甚至全部的解。如果没有适用的准确的希望量度,那么f的选择将涉及两个方面的内容,一方面是一个时间和空间之间的折衷方案,另一方面是保证有一个最优的解或任意解㈣。
2.4.4斛算法
A木算法是一项古老的技术,最初它被用来解决各类数学问题。在人工智能研究的早期它被用来解决寻路问题。
目前常用寻路算法是A水方式,原理是通过不断搜索逼近目的地的路点来获得。¨搜寻法是是一种最佳化的搜寻方法,是当前用的最多也是最先进的算法,在比较简单的地图上它的速度非常快,能很快找到最短路径(确切说是时间代价最小路径),而且使用张算法可以很方便地控制搜索规模以防止程序堵塞。
A木算法是一种有序搜索算法,其特点在于对评价函数的定义上。对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。因此,f是根据需要找到一
北京工业大学工学硕士学位论文
条最小代价路径的观点来估算节点的,所以,可考虑每个节点n的评价函数值为两个分量:从起始节点到节点n的代价以及从节点13到达目标节点的代价。
具体的A水算法步骤如下:
1、生成一个只包含开始节点n0的搜索图G,把nO放在一个叫OPNE的列表里。
2、生成一个列表CLOSED,它的初始化为空。
3、如果OPEN为空,则失败退出。
4、选择OPEN上的第一个节点,把它从OPNE中移入CLOSED,称该节点为n0。5、如果rl是目标节点,顺着G中,从13到nO的指针找到一条路径,获得解决方案,成功退出(该指针定义了一个搜索树,在第7步建立)。
6、扩展节点n,生成其后继节点集M,在G中,I"I的祖先不能再M中。在G中安置的成员,使它们成为n的后继。
7、从M的每一个不在G中的成员建立一个指向n的指针(例如,既不在OPEN中,也不在CLOSED中)。把M的这些成员加到OPEN中。对M的每一个已在oPEN中或CLOSED中的成员m,如果到目前为止找到的到达m的最好路径通过n,就把它的指针指向n.对已在CLOSED中的M的每一个成员,重定向它在G中的每一个后继,以使它们顺着到目前为止发现的最好路径指向它们的祖先。
8、按递增f值,重排OPEN(相同最小f值可根据搜索树中的最深节点来解决)。
9、返回第3步。
在第7步中,如果搜索过程发现一条路径到达一个节点的代价比现存的路径代价低,一就要重定向指向该节点的指针。己经在CLOSED中的节点子孙的重定向保存了后面的搜索结果,但是可能需要指数级的计算代价。因此.第7步常常不会实现。随着搜索的向前推进,
其中有些指针最终将会被重定向。
A术算法本身表述起来很简单,关键是在代码优化上,基本的思路一般都是以空间(即内存的占用)换取时间(搜索速度),另外还有诸如多级地图精度和地图分区域搜索等一些地图预处理的技术“引。
2.5斛算法在地图寻径中的应用
在游戏软件中,地图一般是由一块块小的方格图片拼接而成的,组成地图的图片元素被称为“瓷砖”。地图编辑器将瓷砖按一定的规则“铺"成一张完整的地图,并将地图组成规则保存在一个文件中,此文件被称为地图文件。游戏软件运行过程中,当切换到某个场景时,首先需要读取地图文件,其次按文件所提供的数据,在地图方格内放入相应的瓷砖;最后把铺好瓷砖的游戏地图显示在屏幕上。游戏角色在地图上行走时,应随时判断周边的瓷砖是否可通,以便计算出下
第2章搜索算法衙介
一步行走路线n钔。
地图的这种组织形式正好可以看成是图结构,而地图寻径的原始的朴素的模型就是图,其中图的节点代表地图中瓷砖,图的边代表路径。地图寻径的过程就是在这图上寻找一条最短路径。把A术算法应用到游戏地图的搜索,就可以快速的、高效的找到从起始点到目标点的一条最短路径,从而完成寻径工作。因胁算法的高效性和准确性,因此现今游戏地图就使用这个算法进行地图寻径。在现在的游戏引擎软件中,胁算法已经广泛的应用在地图的寻径当中。本论文所优化的启发式搜索算法就是A水算法啪1。
2.6本章小结
本章首先简单地介绍了人工智能中常用的一种知识表示方法一状态空间法,接着主要从人工智能的角度介绍了传统的搜索技术,包括回溯法、宽度优先搜索、深度优先搜索,最后详细分析了启发式搜索算法—A木算法的算法思想、特性及实现方法,同时讨论了评价函数的启发能力和搜索效率。本章所介绍的概念和术语将会在本文的后面使用到。
北京工业大学工学硕士学位论文
第3章A木算法数据结构的改进
3.1胁算法过程分析
3.1.1地图结构设计
为了测试A木算法,我们首先要设计地图。在游戏引擎中,地图都是由一块一块的“瓷砖"构成。我们在设计算法演示程序时,也把地图设计成由一块块矩形方块组成的结构,与真实的游戏引擎中的地图结构一致。地图采用文档视图的架构进行设计,文档部分保存地图的各种数据,视图部分用于显示地图信息、路径信息等。
首先介绍文档部分,即数据结构部分。在每一块“瓷砖”中,需要有很多变量保存记录每一块地图的状态。例如是否有障碍物,用于判断游戏角色是否可以通过、寻径估值变量,用于保存A木算法执行中的临时变量、地图指针,用于指向父节点,等等变量,在不同的算法数据结构中还有可能根据实际需要添加一些变量。一般来说,通用的结构如图3-1所定义:
c.1assMapnode
{一.”
public■.’,
,CPointpos:
:’int.g,o:
iP。?:i:..。,inth:7{一;,,',,,,。’:
,+j
intfi’.。…
o。
Mapnode*pMapnode:
l’:一:,,一…,。:
图3-I地图结点结构
Figure3一Imapnodestructure
其中pos变量表示当前结点的坐标,g、h、f分别表示胁算法中的估值,pMapnode可以指向其他的地图结点。
下面介绍视图部分。视图使用windowsGDI绘制。地图由一块一块的矩形方块组成,每一个方块对应一个Mapnode结点。一个地图结点的矩形阵列就构成了一张地图。用户可以在地图上进行编辑,设置障碍物、起始结点、目标结点。如图3—2所示:
茎i茎::圣彗圣耋堑堡墼呈耋
圈3-2地图视田
Figure3-2mapview
图3—2中红色的圆点表示起始结点,蓝色的圆点表示目标结点,深色结点表示障碍物。当使用A+算法寻径时,计算机就会找出从红色圆点到蓝色圆点的一条路径。
如上所述的地图是最基本的地图结构。因为本课题需要设计几个不同的演示版本.如演示^}算法细节的版本、地图面积大的版本、比较不同数据结构算法速度的版本、多角色协调寻径的版本等。每个版本的地图都是基本按上述结构设计的,只是视图的表现形式不同.根据地图块数的大小有不同的表现形式。
A}算法是对图结构进行搜索的,而这里是网格形式的结构,那么需要把网格结构转化为图结构。转化的方案如下:把每一个结点看成是图结构的一个结点,每个结点周围有八个方向,每个方向通向一个新的结点,我们把这个看成是一条通路,通向另一个结点。这样,斛算法的目的就是寻找从一个结点到另一个结点的通路。
那么现在,我们只需要解决A{算法中的评估函数的问题了,之后,我们就可以进行寻径的实验了。前面我们已经讨论过了,A#算法的评估函数如下:f(n)=g(n)+h(n),用g(n)表述从开始结点到当前结点已经耗费的值,用h(n)表示从当前结点到目标结点的估计值。那么,这两个值如何计算,针对网格地图有很多种计算方法。
第一种方法:曼哈顿距离。
标准的启发式函数是使用曼哈顿距离计算法。所谓的曼哈顿距离就是两点在南北方向上的距离加上在东西方向上的距离.即D(I.J)=xI—XJ{+lYIYJ。对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离因此曼哈顿距离又称为出租车距离,曼哈顿距离不是距离不变量,当坐标轴变动时,点间的距离就会不同““。
H(n)=D}(abs(nx—goalx)+abs(n.Y—goal.y))使用这个方法不能走斜线,这会造成一定程度的失真。
北京工业大学工学硕士学位论文
第二种方法:对角线距离
如果在地图中允许对角运动那么需要一个不同的启发函数。曼哈顿距离将变成八个方向。我们在可以走斜线的情况下走斜线,这样就显得更加真实。看下面几行代码:
int
intw=abs(_Dos.x—mend.X):h=abs(_Dos.y-mend.Y):
intmin=w<h?w:h:
inthn=min木14+(abs(w—h))*i0:.这正是我们计算估计值的方法,使用的就是对角线距离的计算方法,其实也就是八个方向的曼哈顿距离,是对曼哈顿距离的改进。程序中的14与10就是具体的值,我们定义直线距离为10,斜线距离为14,这样计算起来简单,也符合实际的比例。
第三种方法:欧几里得距离
如果角色可以沿着任意角度移动,而不是网格方向,那么应该使用直线距离:h(n)=D*sqrt((n.x—goal.X)‘2+(n.y-goal.Y)‘2)
然而,如果是这样的话,直接使用A木时将会遇到麻烦,因为代价函数g不会符合启发函数h。因为欧几里得距离比曼哈顿距离和对角线距离都短,仍可以得到最短路径,不过胁运行的更慢一些。
3.1.2A木算法过程
现在,我们可以成功的运行A木算法了,这个算法可以快速的给我们找到一条最短路径。我们的目标是对算法进行数据结构优化,所以,接下来,我们应该对算法的具体实施过程进行仔细的分析,找出哪里是瓶颈,哪里无关紧要,哪个操作执行的次数多,哪个操作执行的次数少。
从理论上分析,A水算法的执行速度取决于OPEN与CLOSE使用的数据结构,因为这两个数据结构决定着具体的每一步的操作。我们可以通过设计一个更加优化的数据结构来提高算法执行的效率。至于怎么样设计这个数据结构,这在后面讲,在设计新的数据结构之前,我们首先应该对A木算法的执行过程进行分析,从而针对性的设计新的数据结构。
A,I:算法的基本操作包括:插入、删除、找最小值、排序、查找等。在程序中,我们已经设计了很多变量用于计数,计算这些基本操作的频率,然后对数据进行分析。A木算法对于不同的地图有着不同的表现,因此实验时要设计不同类的地图进行测试,以达到科学、合理、全面。
我们根据实际情况,可以设计以下几种地图:无障碍地图、一个大障碍物的地图、凹形障碍物的地图、点阵障碍物地图。如图3—3所示:
篓i董皇:量茎彗堡薹堡塑彗耋
l黧l缫≥甏弱iii翁§§溺l鍪嚣藿羹妻馨霹耄誊囊蕃碧簧翥薹妻耄耄i臻l臻0§鬻i§《麓≥g剿
§潮§魏≤≤i嚣i≥i2翁鳍嚣蔷嚣舞誊墓冀譬翁蠢誓蓦嚣嚣蠹鬟翥篓霾ilg》《§i§§g§g§魏ig瀚
;§冀g§≤§#萋§镕黧§》§gll口i∞§§§§;《iiii{li弱§;翳≤《§馨gl§i§3囊il疆曩i§§雾§I
0嚣舞黔i魏嚣蕊硼霸霭端日蠲疆豁穗两§Ig§g§i霸§§g捌ili《≥黎麓igi绷i缫器i{翥{薹目;}两垂iiiiiii两猫薷最蟊曩4j
i黼i《gi燃l《g嚣魏g女戮
£l;::::::::::§l黝瀚i誉翼善零鬟嚣攀蔫墓薹焉鬻毳纂簧蕈蚕禹
§§::::;:器:::i鬻i囊篓
l囊囊亳要霹鋈警囊差餐鎏要篓露零鬟妻翌
i銎萋霪萋篓囊霸壁焉曩鬟委翟鏊鏊受妻翅
簦美暑暑暑暑置暑宣暑暑昌萎鼙磊嚣蠡妻嚣
墓箬昌暑昌;昌昌昌暑昌昌昌墨翥茧鲞篓篓
§蔼西强§磁盘翟翟孽强镭爨鳆g潮弱蒯刳
薹誊iiiiiiii墨荔鬻囊蠢鋈嚣塞弱
&璃掣●一一■■滔甜葫弼箍露藕露两露两
li§§i≥≤g羹£gi≥ii溪g黥il釜≥il§§型giggg§§委gi
;§誉#i《i镕§l§2§§ggi§l
§i镕§螽§i§;iig嚣igi§i
£#§§ig§瀚i藕霸翳£§鬻§§目§嬲《≤l∞g§§※§基女《≈
a)无障碍地图
b)大障碍物地图
a)noobstacle
map
b)bigblock
map
:二?*’,+?。1j
:
:皇j
。
:曼。_鼍
≤ii..:!;i?-_一
_.I”“。
:詈¨。詈.:曙’
.参J
量’。
?、’mimm?_’
’.一一?-。_、--,一.j?。
^■。¨:.i基j?T:‘m’:÷:r?;一。一叠.
’.+曩暑?’~。。!。
j
’
j●llIi二三■
■一j,
I一■一一
1一…■,一一t;t暑:1i‘
in:,‘j
?。一■一■■■一”■:
●一
■
■+_.i
c)凹形障碍物地图d)点阵障碍物地图
c)u
scyleobszacl
e
map
d)dot
arrav
map
圈33四种类型的地图
Figure3?3fourmaps
这四种地图是最常用的几种地图,也是完全不用类型的地图,A雌#法在不同类的地图上有着完全不同的表现。用这四种类型的地图测试算法是非常客观的,是由代表性的,如表3-1所示:
北京工业大学工学硕士学位论文
表3-i四种地图的测试数据
Table3-1testdataoffourmaps
无障碍l无障碍2一大障碍l一大障碍2一大障碍3凹形障碍1凹形障碍2随机点阵障碍l随机点阵障碍2
步数
处理结点数在open中结点数在close中结点数不在集合结点数opendP更新数取最小值删除插入有序插入末端查找是否存在查找/插入查找/删除查找/取最小值插入/删除更新/查找
52382100502320
j240520050Ijj0
31424579121068477238
37528871070132l496182
288218382898037513l
187313770502l681019391319
9ll6688245432271007626
3972078638936504140
28l150646666l379i03
5252232j2400
5252ljj52700
3145527153144872
3755576783755852
2884195062884444
187331923258187328683
911153716339U13816
3975376443973786
28l38448228l2720
1.7241384.5161297.69230813.46154
6.8139868.63126848.78260878.80386748.460502148.82608710.506284lO.6062058.98590238.98893949
5.8788819887.050279339.5365239291.19925512l0.03697834l
5.6431535277.0833333339.6797153021.2552083330.037867647
7.69230813.46154lj.515924lj.605333lj.43055615.31393515.16575194.4615382.9807691.29528991.21723521.20763721.02067671.06245934
O
O0.0488506O.03110050.02947790.0459854O.04530979
3.1.3分析结论
下面我们对测试算法过程的数据进行一下分析。首先要了解A木算法是分若干步的,每一步都执行同样的操作。具体每一步是这样的:
1.取OPEN中的最小估值结点。
2.将取出的最小估值结点插入到CLOSED中。
3.如果这个点不是目标结点,那么扩展它,取得它的若干个符合条件的扩
展点。
4.处理这些扩展点:如果在OPEN中,判断是否估值更小,小就更新;如果
在CLOSED中,什么也不做:都不在,插入到OPEN中。5.一步完成,转到1。
从上述步骤中我们可以看到,每一步取一次最小值结点,插入到CLOSED中一次,根据扩展结点的具体情况插入删除若干次。有了这个概念,我们再分析数
据就更有深入的理解。
从数据中我们可以看到:
在无障碍的地图中,由于路线明确,直接到达目的点,所以不需要更新操作,更新操作为零,而插入操作却比删除操作多很多,这是因为没有障碍物的话,不会走错误的路径,因此,路径周围就会扩展出很多没有被处理的结点。
在凹形地图中和大障碍物地图中,步数很多,因为障碍物复杂,它扩展了很
第3章A+算法数据结构的改进
多错误的路径。步数多,那么查找操作也随之巨增,尤其是凹形地图,更是如此。
随机点阵地图算是简单障碍物的地图,因此,它的数据接近于大障碍物的地图。
根据理论分析与实践测试,我们可以得出以下结论:
1.
2.
3.
4.
‘取集合中最小值的算法执行次数最少。删除元素运算执行次数第二少。插入元素运算执行次数略高于删除运算执行次数。查找元素是否在集合中的算法执行次数最多。
那么我们可以根据上述结论进行优化设计,应该首先优化查找一个元素是否在集合中的运算,使查找时速度更快一些,其次应该在插入删除的操作上考虑,使之更快,最后考虑取最小值的运算。
3.2传统的数据结构设计
3.2.1‘’常用数据结构简介
在传统的胁算法数据结构设计中,OPEN集合和CLOSED集合使用的数据结构一般是未排序数组、排序数组、链表、二元堆等。它们都有这样那样的优点缺点,下面我们对这几种常用的数据结构进行介绍。
数组是一种物理存储单元上连续的存储结构,存储同一类型的数据。可以用数组下标,即每个数组元素相对于数组首元素的物理位置来访问。数组结构是物理连续的,在数组中间添加或删除元素都需要移动其他数组的位置,而在末端添加或删除元素则不需要移动其他数组元素的位置。
未排序数组就是数组的元素没有经过排序,无序的分布成一条线形结构。排序数组,顾名思义,数组中的每个元素在加入数组时是严格按照关键字的顺序进行插入的,删除数组元素时也要调整其他的数组元素,使之保持有序。
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。线性表的链式存储表示的特点是用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。因此,为了表示每个数据元素与其直接后继数据元素之间的逻辑关系,对数据元素来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。由这两部分信息组成一个结点,表示线性表中一个数据元素。
二元堆是一种特殊的堆,二元堆是完全二叉树或者是近似完全二叉树。二元堆满足堆特性:父结点的键值总是大于或等于(小于或等于)任何一个子节点的
北京工业大学工学硕士学位论文
键值,且每个结点的左子树和右子树都是一个二元堆(都是最大堆或最小堆)。当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。二元堆一般用数组来表示。例如,根节点在数组中的位置是l,第n个位置的子节点分别在2n和2n+l。因此,第1个位置的子节点在2和3,第2个位置的子节点在4和5。以此类推。这种存储方式便于寻找父节点和子节点。在二元堆上可以进行插入节点、删除节点、取出值最小的节点、减小节点的值等基本操作口引。
3.2.2传统斛算法数据结构的分析
现在我们对这几种常用的数据结构在A,Ic算法中的应用进行一下分析。胁算法的基本操作包括插入、删除、查找等,这些操作的效率完全取决于这几种数据结构。不同的数据结构,这些基本操作有着不同的表现。
最简单的数据结构是未排序数组。集合关系检查操作很慢,需要扫描整个结构花费0(n)。插入操作很快,添加到末尾花费0(1)。查找最佳元素很慢,扫描整个结构花费O(n)。对于数组,删除最佳元素(Removingthebestelement)花费O(n)。调整操作中,查找结点花费0(n),改变值花费O(1-)。
为了加快删除最挂操作,可以对数组进行排序。集合关系检查操作将变成0(109n),因为我们可以使用折半查找。插入操作会很慢,为了给新元素腾出空间,需要花费0(n)以移动所有的元素。查找最佳元素操作会很快,因为它已经在末尾了所以花费是O(1)。如果我们保证最佳排序至数组的尾部,删除最佳元素操作花费将是0(1)。调整操作中,查找结点花费.0(109n),改变值/位置花费0(n)。
对于链表结构,集合关系检查操作很慢,扫描整个结构花费0(n)。插入操作很快,添加到末尾花费0(1)。查找最佳元素很慢,扫描整个结构花费o(11)。对于数组,删除最佳元素花费0(1)。调整操作中,查找结点花费0(n),改变值花费O(1)。.
一个二元堆是一种保存在数组中的树结构。和许多普通的树通过指针指向子结点所不同,二元堆使用索引来查找子结点。C++STL包含了一个二元堆的高效实现。在二元堆中,集体关系检查花费0(n),因为你必须扫描整个结构。插入操作花费0(109n)而删除最佳操作花费也是0(109n)。调整操作很微妙,花费0(n)时间找到节点,并且很神奇,只用0(109F)来调整瞄1。下面我们总结成一个表格分析比较一下,如表3—2:
第3章A?算法数据结构的改进
表3-2时间复杂度的比较
未排序数组排序数组
O(1)
O(n)
0(n)
0(109n)链表0(n)0(1)0(1)0(n)一元堆O(1)0(109n)0(109n)0(n)取最小值插入删除0(n)0(1)0(n)集合关系判断O(n)
注意有一点很重要,我们并不是仅仅关心渐近的行为(大0符号).我们也需要关心小常数下的行为。为了说明原因,考虑一个0(109n)的算法,和另一个0(n)的算法,其中F是堆中元素的个数。也许在机器上,第一个算法的实现花费10000*log(n)秒,而另一个的实现花费2*n秒。当n=256时,第一个算法将花费80000秒而第二个算法花费512秒。在这种情况下,“更快”的算法花费更多的时间,而且只有在当n>200000时才能运行得更快。不能仅仅比较两个算法。你还要比较算法的实现。同时你还需要知道你的数据的大小。在上面的例子中,第一种实现在n>200000时更快,但如果在地图中,n小于30000,那么第二种实现好一些。基本数据结构没有一种是完全合适的。未排序数组或者链表使插入操作很快而集体关系检查和删除操作非常慢。排序数组或者链表使集体关系检查稍微快一些,删除(最佳元素)操作非常快而插入操作非常慢。二元堆让插入和删除操作稍微快一些,而集体关系检查则很慢吩引。
3.3数据结构的改进
3.3.1设置标志代替查找
在传统的A木算法中,执行算法时耗时最多的是查找运算,即查找一个元素是否在一个集合里面。在算法刚开始执行时,集合中的元素个数很少,查找运算并不会占用过多的时间,但是,随着算法执行步数的增加,集合中的元素个数越来越多,而查找运算仍然很频繁,所以大量的时间被查找运算耗费掉。前面我们已经测试了,如表3—3所示:
北京工业大学工学硕士学位论文
表3-3测试数据
Table3.3testdata
无障碍I无障碍2一大障碍l一大障碍2一大障碍3凹形障碍l凹形障碍2随机点阵障碍l随机点阵障碍2
步数525231437528818739ll39728l处理结点数3824052457288721831377066882078l弧在open中结点数1002009121070828502l2454638466在close中结点数50501068132l9806810322793666l不在集合结点数23215547749637519391007504379oDen中更新数O023818213l1319626l如103取最小值52523143752船18739ll39728l删除525255255741931921537537384插入有序23215571567850632581633644482插入末端525231431528818739Il39728l查找是否存在40070048725852“44286831381637862720
表3-3中所示,查找运算的次数远多于其他的运算,也就是说,查找运算是一个大的瓶颈,我们首先应当解决这个瓶颈,使得查找运算变得更快一些。
在这里,我们采用设置二维数组标志位的方法来解决这个问题,提高查找速度。对于地图上的每一个结点,当它们被扩展时,都要查找这个结点是否在OPEN、CLOSED里,按常理,应该遍历这两个集合,这就使得速度变得很慢。我们可以考虑,为每一个结点设置一个标志位,这个标志位记录着当前的结点是在OPEN中还是在CLOSED中,还是不在任何集合中。这样,当我们需要判断某一个结点是否在集合中的时候,只需要检索这个标志位就可以得到答案了,从而大大得节省了时间。如图3—4所示:
2
广—]lopenl
II_._......-..-....一l口曰口
图3—4标记数组示意图
Figure3-4Tagarraydiagram
例如,当我们要查找(1,1)结点是否在OPEN集合中时,我们直接检索这个结点的标志位是open,即可判断出这个结点在OPEN中。而传统的方法,算法将遍历OPEN结点,这将浪费很多的时间。
在程序中,我们采用char来表示这个标志位,整个地图也就将要建立一个char类型的二维数组。程序代码如下:
第3苹A+算法数据结构的改进
char和kppstat:
ppstat=newchar*[m_nheight]:
for(inti=O:i<m_nheight:i++)
ppstat[i]=newchar[m_nwidth]:
for(i=O:i<m_nheight:i++)
for(intj:o:j<m__nwidth:j++)
ppstat[i][j]=(char)0:
在这里,我们定义,使用0表示不在任何集合中,用l表示在OPEN集合中,用2表示在CLOSED集合中。这样,我们很容易定义两个查找运算的函数接口:IsInOpen(Mapnode):IsInClosed(Mapnode):这样,查找运算耗时的问题就解决了,查找的效率得到了提高,在后面的章节中,我们将测试程序,用实践验证我们的设计。
3.3.2哈希表简介
查找的操作我们通过建立二维标志数组解决了效率低下的问题。接下来,我们要提高插入、删除、找最小值的效率。这些操作和OPEN与CLOSED所使用的数据结构密切相关,因此,我们必须摒弃原来低效的数据结构,采用新的数据结构。在本课题中,我们采用哈希表的结构。在这一章节中,我们首先介绍一下哈希表的有关概念和性质。
一般的线性表、树中,记录在结构中的相对位置是随机的即和记录的关键字之间不存在确定的关系,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较”的基础上,查找的效率与比较次数密切相关。理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。因而查找时,只需根据这个对应关系f找到给定值K的像f(K)。若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,由此不需要进行比较便可直接取得所查记录。在此,称这个对应关系f为哈希函数,按这个思想建立的表为哈希表(又称为杂凑法或哈希表)口副。
常用的构造哈希函数的方法
1.直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
地址0l02…252627…100
年龄l2…252627……
人数30002000…1050……………2.数字分析法
北京工业大学工学硕士学位论文
有学生的生日数据如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
3.平方取中法
取关键字平方后的中间几位为哈希地址。
4.折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个lO位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到lO,000时,可采用此法构造一个四位数的哈希函数。如果一本书的编号为0-442-20586—4,则:
5864
422058640224
+)04+)04
100886092
H(key)=0088H(key)=6092
(b)间界叠加(a)移位叠加
5.除留余数法
取关键字被某个不大于哈希表表长m的数P除后所得余数为哈希地址。H(key)‘=keyMODP(p<=m)
6.随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random(key),其中random为随机函数。通常用于关键字长度不等时采用此法。哈希表不可避免冲突现象:对不同的关键字可能得到同一哈希地址即
第3章A?算法数据结构的改进
keyl:≠key2,而f(keyl)=f(key2)。具有相同函数值的关键字对该哈希函数来说称为同义词。因此,在建造哈希表时不仅要设定一个好的哈希函数,而且要设定一种处理冲突的方法。处理冲突的方法:
1.开放寻址法:Hi=(H(key)+di)MODm,i=I,2,…,k(k<=m一1),其中H(key)为哈希函数,m为哈希表长,di为增量序列,可有下列三种取法:
di=l,2,3,…,m-1,称线性探测再散列:
di=l‘2,(一1)‘2,2‘2,(一2)‘2,(3)‘2,…,±(k)‘2,(k<=m/2)称二次探测再散列:
di=伪随机数序列,称伪随机探测再散列。
2.再哈希法:Hi=RHi(key),i=1,2,…,kRHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到冲突不再发生,这种方法不易产生“聚集",但增加了计算时间。
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中,如图3-5:
O
I
2
3
t
S
5了8
q
O
l2
图3—5链地址法
Figure3-5listAddressdiagram
4.建立一个公共溢出区
假设哈希函数的值域为[O.1lrl],则设向量HashTable[O..m_1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
要把哈希表使用到胁算法中,需要考虑以下几个问题:
如何选取关键字?
如何选取哈希函数?
如何处理冲突?
这几个问题,我们在下面章节将给出答案。我们首先要证明两个原理,这两
北京I业太学工学砸士学位论文
个原理对解决这几个问题有着很重要的作用脚1。
333两个原理
在测试A¥寻径的试验中,通过对算法执行数据的分析.可以发现两个规律。第一.随着执行步数的增加,OPEN集合中的结点的估值逐渐增高.第二,OPEN集合中的结点的估值的最大值和最小值之间的差总是局限在一个范围内。
下面是一个算法执行分析的截图,如图3-6:
图3—6估值分布
Figure3-6Valuationdistribution
截图36中的横坐标表示步数,纵坐标表示OPEN中的估值,红色竖线表示每一步OPEN集合中的估值的范围。从图中我们可以看到,随着执行步数的增加.OPEN集合中的结点的估值逐渐增高,且结点的估值的最大值和最小值之间的差总是局限在一个范围内,这个范围根据数据统计是28。这只是其中的一个例子,其他的不同的地图也有此陛质。我们经过分析证明,可以总结出两个原理。
原理一:在A}算法执行过程中,当扩展一个结点的时候,扩展出的结点的估值总是大于等于被扩展的结点。证明:如图3—7所示
第3章A?算法数据结构的改进
(n)=g(n)+hCn)
n0
f(nO)=g(n)+t+
h(n0)
图3—7原理一示意图
Figure3-7principle1diagram
图3"7中红色的结点n是被扩展的结点,从红色的结点扩展出绿色的结点n0,程序的目标结点是蓝色的结点。根据胁算法的原理,红色结点的估值是f(n)=g(n)+h(fi),其中g(n)是从开始结点到当前结点n的路程耗费值,h(n)是结点13到目标结点的直线距离。扩展出绿色结点后,同样计算估值f(n0)=g(nO)+h(nO),其中g(nO)等于之前的红色结点耗费值g(n)加上n到nO的耗费值t。那么我们需要证明的就是f(n0)大于等于f(n)。既证明
g(n)+t+h(nO)>=g(n)+h(n)
t+h(nO)>=+h(n)
.这是显然的,因为两点之间直线最短,而我们定义的h函数就是两点之间的最短距离。这样,这个原理就证明出来了。
原理二:在算法执行的每一步中,OPEN中的结点的估值的最大值与最小值之差总是不大于扩展结点较大的耗费值的两倍。
这个比较难懂,比如前面我们已经定义了,移动一步需要耗费10或者14,直线是10,斜线是14,那么较大的耗费值就是14,两倍就是28。那么,OPEN中的最大值与最小值之间的差不会超过28的。下面将证明。证明:如图3—8所示
北京工业大学工学硕士学位论文
图3—8原理二不慈图
Figure3-8principle2diagram
图3-8中红色的结点11是被扩展的结点,从红色的结点扩展出绿色的结点nO,程序的目标结点是蓝色的结点。根据胁算法的原理,h(n)是结点n到目标结点的直线距离。扩展出绿色结点后,h(nO)是结点n到目标结点的直线距离,t是耗费的路程。
前面我们已经证明了,扩展出的结点,即绿色结点的估值是大于等于被扩展的结点的,即红色结点。那么到底大多少?我们要在这里证明,大的值最多是28,即两倍的路程耗费值。
当从红色结点扩展到绿色结点后,绿色结点的值首先要加上一个t值,即耗费值,这个值我们假设是最大的,即要耗费值是14。同时,绿色结点还要加上它到蓝色目标结点的直线距离,我们假设距离增加了一个最大值,即增加了14。也就是说,我们把情况假设到了最坏的形式,离目标结点更远了,自己也走的更多了,那么也就是估值多了两倍的14。再联系到条件,被扩展的结点的估值是从OPEN选出的最小值,因此,扩展最小值最坏情况也不过是加了两倍的耗费值。这也就证明了原理。
3.3.4新的数据结构的设计
现在我们可以为胁算法设计新的数据结构了。首先定义结点:
classListMapnode
(
public:
CPoint
intg:
inth:
intf:pos:
第3章A?算法数据结构的改进
ListMapnode*father:
ListMapnode*pListMapnode:
}:
在这个结构里,定义了两个重要的指针。一个是father,用来指向本结点的父结点,即被扩展的结点,另一个是pListMapnode,用来做链表连接用。当需要插入删除时,只需要改动结点的指针即可,而不需要移动复制每个结点,整个结点呈矩阵形式,如图3-9:
0l2
0
2
图3—9地图结点结构
Figure3—9mapnodestructure
每个结点的位置是固定的,记录着寻径时的各种信息。
同时我们采用二维数组的形式定义标志位,即:char**ppstat,用于记录每个结点的集合所属的情况,这样可以提高查找的效率。标志位的数组和结点是一一对应的,在算法执行的时候记录相关信息,在需要初始化的时候全部初始化为0。
对于OPEN集合,我们采用哈希表的数据结构来实现。对于使用哈希表需要解决的三个问题:如何选取关键字?如何选取哈希函数?如何处理冲突?我们现在开始解决。
关键字采用结点的估值来实现。但是结点的估值是递增的,在这里,我们可以考虑前面提到的原理二,估值的范围总是在一个数字之内,在我们的算法中就是28。也就是说,可以利用估值的求余数的方法匹配关键字,这样,哈希函数也得出来了,就是估值求余数。无论估值增加到多大,它的余数总是在一个范围内,通过哈希函数映射到哈希表上。处理冲突的方法是链地址法,同样的估值将被挂到同一个链表中。最后的结构如图3-10所示:
曼曼鼍蔓曼曼曼曼曼曼曼曼曼曼曼曼蔓曼曼曼曼曼蔓曼!曼皇曼曼苎!曼曼曼!曼鼍曼曼!曼曼曼曼皇皇舅皇Illl曼曼曼曼曼曼曼曼曼鼍曼笪!皇!蔓曼皇曼曼曼曼曼曼曼曼曼曼鼍曼!曼皇北京工业大学工学硕士学位论文
哈希表\、
广]l
图3一lO哈希表结构示意图
Figure3—10hashtablestructurediagram
我们首先定义指向结点的指针数组,也就是哈希表。
ListMapnode木pOpenHash[54]
在这里,我们将数组的个数定义成了64,这是为了防止同样的估值结点的重叠,再者,64是2的整数次幂,可以使用移位的方法代替除法运算,提高了效率。
接下来,需要一个标志记录当前最小的结点所在在纵列,我们定义了一个整数。
intminflag
这个变量始终记录着最小估值的结点的下标,当每一步开始时,直接从这个下标中取值即可,使得取最小值的运算的效率也大大提高。当算法一步执行结束的时候,整个标志将检测当前是否还存在最小值,如果不存在,它就会向后滑动,直到检测出最小值为止。当然,通过算法执行过程可以看出,大部分情况都会产生很多同样的最小估值结点,标志位向后滑动的可能性很小,次数很少。就算向后滑动检测,也不会超过28的,因为这是估值的最大范围了。
当算法需要做更新操作的时候,即使用最佳结点替换OPEN中的结点,只需在结点所在的链表中检索坐标,找出结点,更改估值,然后删除这个结点,之后重新插入即可。这个操作也是出现的比较少。
对于CLOSED结点,根本不需要建立一个集合。只需要按照算法执行挂接好相应的父结点就可以了。当寻径结束时,从目标结点向上返回,一直就可以回到初始结点,所经过的路径就是所求的最佳路径。现在我们对新设计的算法的数据结构进行一个理论的分析,如表3—4:
二:!::!i些!!!墼
表3—4对同复杂度比较
Table3-4CompadsonoftimecompWxity
,“jy,
未排序数组排序数组链袁二元堆暗希表‘
取最小值0(n)o(1)0(n)0(1)i簿纛鏊插入0(1)o(n)0(1)0(10En)ot—i1¨|蔓删除o(n)0(n)0(1)0(109n)霸j兽瓣
集合关系判断0(n)0(109n)0(n)0(n);{露譬辫从图表中我们可以看到.三个常出现的操作都是非常高效的.另外删除操作没有统计。因为它是不确定的.但是可以肯定的是删除操作的效率高于其他的数据结构,因为它只需要在相同的估值结点中遍历.而不需要在所有的结点中遍历。3.4算法测试
3.41测试软件的设计
在上一章节中,我们已经设计好了新的数据结构,并且进行了理论上的时间复杂度的分析。在这一章节中,我们将进行实际的程序测试,验证前面所做的工作。
首先要设计一个测试程序。程序界面如图3-ii所示:
Ij鍪》鬣爹一㈣
图3一u算法铡试程序界面
Figure3-11Algorithmtestingprograminterface
北京工业大学工学硕士学位论文
程序界面的左边是地图区域,采用300*300的巨大地图。之所以使用大面积的地图是因为大面积地图更能表现出程序的优劣来。在地图上可以编辑障碍物,如控制栏所示,障碍物分为大中小三种尺寸,可以根据实际情况进行编辑。同时,自行指定起始结点和目标结点。图形编辑完成之后可以存储,同样,也可以读取文件,直接载入已经编辑好的地图。这就是测试程序的地图部分乜"。
程序界面的右边区域是算法计时的面板。如图,程序中使用了五种数据结构不同的A水算法,分别是:未使用结点标志位的数组,使用结点标志位的数组,排序数组,链表,哈希表。每个算法的前面都有对勾或叉号,表示是否执行当前所标示的算法。算法后边是计时数字,单位是秒,当算法执行结束的时候,数字将显示算法的实际用时,精确到微秒级别㈣。
当测试算法的时候,首先选择所要测试的算法数据结构,变成对勾状态,然后设置好地图障碍物、起始点、目标点,之后选择执行,算法就会依次执行,地图中会以黄线显示出路径来,计数数字也会显示结果。
3.4.2测试结论
首先我们测试使用结点标志位和未使用结点标志位的差异。
前面试验分析得出,在A水算法执行过程中,执行运算频率最高的就是查找运算,即查找一个元素是否在一个集合中。我们在前面使用了设置结点标志位的方法进行了优化,现在测试优化的结果。
在地图中选择未使用结点标志位的数组和使用结点标志位的数组,然后在地图中设置各种不同类型的地图进行测试。经过试验,得出以下数据,如表3—5:
表3—5测试数据
Table3.5restdam
遍历查找
使用标志
倍数0.0129440.005990.056890.01575618.154271.5156148.7323650.44315l0.0758030.2658972.16093493.61068840.9663319.9941232.84116
遍历查找
使用标志
倍数0.3536740.0308120.4065l0.0403660.0090220.003297.5458020.0192680.34216l0.005976l1.4784510.0706042.742249222.053373.22423
遍历查找
使用标志
倍数0.065696O.0106770.0001094.9219882.252820.0535670.0000871.25287360.4343250.09621l0.0108116.153039211.332523.415414.954861
从这15组测试数据可以看出,使用结点标志位的算法比未使用结点标志位的算法快很多,有的只快几倍,有的快几十倍,这个结果完全验证了我们之前的
第3苹A?算法数据结构的改进
理论。
接下来我们要测试前面所设计的新的数据结构,即使用哈希表的A木算法。在测试软件中,选择算法:数组,链表,哈希表。这三个算法都已经使用了结点标志位,在查找时都是非常快的。这里主要测试其他的性能,如插入、删除、更新、寻找最小值等,测试数据如下,如表3-6:
表3—6测试数据
Table3-6testdata
list
array
0.0144230.00490l0.001167
0.0038910.07696l0.0057170.0019410.0016240.000669
0.5333970.1630420.046161
0.1904740.0664020.023795
hash
list/hasharray/hash
1ist
array
12.359042.395936115.038911.5551442.9013453.5320292
8.0047912.790586
4.19965723.5203202
0.2424880.093516O.031767
0.29842l0.1636620.500440.0845030.282560.0397260.082799
O.01417
0.2725460.1296310.0806040.040875
hash
1ist/hash
7.633332.9438l
3.7023l4.0039636.0440345.9635143.4126022.803529
array/hash
1ist
array
3.3812963.171401
0.2067430.0584140.3894140.9376590.2144950.0438780.049734
0.01409
0.03856
0.7284881.4326720.0173750.3073050.2143330.006431
hash1ist/hash
4.1569754.1457774.3128443.114123
1.2671914.3747775.995957
array/hash
1ist
array
2.370576.6843282.701757
0.046120.9945620.031829
1.0769550.0254970.2747390.008557
0.0990090.067152
0.0025140。0054030.0179070.000758O.0015880.005971
hashlist/hash
130.618742.287153.3166233.402393
7.7239993.6200253.7196452.998995
3.91992
2.979666
array/hash
从上面几组数据可以看出,使用哈希表作为数据结构后,算法的时间明显的减少了,效率得到了提高。使用数组数据结构的算法执行的时间大概是使用哈希表数据结构的算法的几倍,而使用链表数据结构的算法使用的时间一般情况下更
长一些。
3.5本章小结
本章首先对A水算法的执行过程进行了详细的分析,通过开发一个演示分析
北京工业大学工学硕士学位论文
软件来分析其过程,包括单步执行和正常执行,在执行结束后,记录下来各种执行期间的数据统计,并以图表的形式反映出来。在通过这个软件详细地分析了A木算法之后,总结了两个基本原理并对原理进行了证明,这两个基本原理是后面优化数据结构的基础。之后开始优化,使用的优化方案是:第一,将哈希表的数据结构作为A木算法的OPEN集合,使用估计值作为哈希表的关键字,采用链地址法进行冲突的处理;第二,使用二维数组对每个结点进行标记,使得查找每个结点的集合归属运算效率大大提高。最后本章开发了测试软件,就是算法时间的比较软件,用来测试未优化数据结构的A木算法和优化数据结构后的胁算法的时间,经过多个地图多次测试后证明本章设计的优化方案是可以提高效率的。
第4章A?算法的应用
第4章斛算法的应用
4.1寻径协调算法
4.1.1寻径协调算法的需要性
在图论中人们研究了通过怎样的计算才能找到一条从A点到B点的通路,以图论本身来说这已经解决了从A到B的问题,剩下的只是从A沿着找到的路线移动到B就可以了。这样的认识基于一个默认的假设:道路中的一切障碍物都是固定的,但是在现在已经广泛流行的游戏中问题却远远不止这些。举个例子说上下班高峰期的时候,路上的每一个人都清楚地知道自己的目的地和所要走的路径,但是由于某些个人不遵守规则或其他人为原因还是会造成堵车现象。而如果这样的事情发生在一个游戏中,那么带给玩家的沮丧感和愤怒将远超过现实中的堵车现象。当游戏中的一个对象接到玩家的命令要从基地的一侧移动到另一侧时,它需要一个计划,更明确的说是一条寻找出来的路线,使它能够到达目的地,但很可能在它移动的过程中预定的路线上出现了变化,例如玩家让工人们在士兵的必经之路上修建一个建筑或另外一批士兵出现在路上,从而堵塞了道路,这时如果没有一个优秀的移动系统,那么之前的寻径工作等于是白费工夫。本章节将研究一种有效的个体移动系统,以从另一个角度探讨寻径中的自动移动问题啪1。
首先需要解决的问题是碰撞检测问题,只有检测出对象之间的碰撞,才可以以此为基础进行协调算法的设计。
还有一种情况,当用户命令多个对象同时向一个目标结点移动的时候,实际上只有一个结点可以到达目标结点,其他的对象只能在那个目标结点周围徘徊而不能到达目标结点,因为目标结点已经被先到达的结点占领了。这个情况也需要一种协调算法来控制其他的多个结点的移动,控制它们应该在什么地方停止。4.1.2寻径协调算法的设计
首先设计碰撞检测的算法。所有碰撞检测系统的基本目标都是判断两个个体是否发生了碰撞。这次我们所介绍的碰撞检测都是假设两个物体的碰撞,将来我们会专门介绍大量物体互相碰撞的检测问题。但无论是两个物体还是多个物体发生碰撞有一点是共同的:每个物体都要收到碰撞信息以便作出适当的响应,分开彼此‘矧。
大部分即时战略游戏中使用的简单的碰撞判断实际上是将每一个个体看作一个球体(2D中是圆),再进行简单的球体碰撞检测,而不在意这样简单的判断是否能够满足游戏对于碰撞的要求。这样做确实有利于提升性能,即使一个游戏
北京工业大学工学硕士学位论文
要进行非常复杂的碰撞判断一例如判断击出的拳头是否击中敌人,或者甚至是低精度的多边形交叉判断,这时为可能出现的碰撞保有一个球体区域往往也能够提升程序的性能口¨。
当我们设计一个碰撞检测系统时要注意面对3种截然不同的实体:单个的个体、一群个体的集合以及经过队形编制的个体群。事实上对所有这3种类型使用简单的球形判断都能工作得很好,单个个体可以简单的使用单个球体进行它的全部碰撞判断,而对于其它两种情况只需要再稍微增加一点工作量。
对于一群个体的简单集合来说,可以接受的碰撞检测下限是对整个组中的每个个体进行检测。这种方法将允许那些不属于你所选定的组的个体轻松的混入你的组队中。相对来说,对编队所要进行的碰撞检测就要更加复杂一些了。我们还应该认识到这种简单的组群还有一种特殊的性质决定了我们应该尽可能的简化对它所采用的碰撞检测方法一这种组群应该能够随时随地的将排列方式变换成任何可能的适应当地空间大小的阵形口副。
对于编队来说,不仅仅要进行如上面的组群那样简单的个体碰撞检测,还要进行大量更加复杂的检测操作。首先要保证编队中的个体之间不能互相碰撞,同时如果编队中的各个个体之间有一定的缝隙,还要保证任何一个不属于该编队的个体不能占用这一空间。另外,一个编队应该不能改变队形或重组,但是游戏的规则又可能规定当没有足够大的通路提供给整个编队保持队形穿越某一障碍物时,编队可以先散开,待各个体越过障碍物之后再重新组成编队,这样的设计更加体贴玩家啪,。
我们可以尝试使用基于时间的碰撞描述机制。立即碰撞用来描述当前正发生在两个个体之间的碰撞;未来碰撞用来记录预计在程序运行的后续时间中将会发生在预定地点的碰撞(当然,前提是将要碰撞的对象都不改变各自的移动路线)。在任何情况下立即碰撞的情况都应该比未来碰撞的情况更优先被处理口u。
我们对地图中的对象定义了几个状态。代码如下:
enumROLESTATUS(STOP,MOVED,MOVING,WAITl
STOP表示静止的对象,对于此类对象,完全可以把它当作一个静止的障碍物来处理。
MOVED表示形式上静止的对象,实际上正要移动。对象即将要移动的结点也存储在了一个结点中:intnextx,nexty。
MOVING表示正在移动的对象,这类对象有着最高的优先级,当别的对象检测出即将碰撞MoVING对象的时候,应该立即停止,让MOVING对象先移动。
WAIT表示暂停,表示此对象正在静止一段时间,这段时间过了之后,再继续移动,移动的下一个目标结点也存储在intnextx,nexty中。这四种状态在对象的移动中根据具体的形式做相应的转化,四种状态的转化
第4章A+算法的应用
可以用一个状态转化图来表示,如图4-1:
图4一l状态转换图
Figure4-1Statetransitiondiagram
从状态转化图中可以看到,并不是每两种状态之间都可以自由转化,而是某些特定状态之间才可以转化。
对于一个静态的对象,它的状态是STOP,那么当它被命令移动的时候,它的状态转化为MOVED状态,反之,当一个对象移动结束的时候,它的状态转化为STOP状态,静止下来。
对于状态是WAIT的对象,和状态是STOP的对象相似,它也可以和MOVED状态互相转化,区别在于,状态是WAIT的对象并非真正的静止下来,而是要临时停顿若干秒钟的时间,之后自动地转化为MOVED状态,继续移动。
而状态是MOVING的对象比较特殊,因为它的优先级最高,即状态是MOVING的对象在移动时不能被任何情况所停止,只有在移动一步结束时才停下来,转化为转化为MOVED状态,然后为下一步进行碰撞检测。
从这个状态转化图可以看出来,我们要进行碰撞检测其实是很简单的。只需要对于状态是MOVED的对象进行碰撞检测即可。而其他的对象,状态是STOP的对象与状态是WAIT的对象并没有移动,不需要进行碰撞检测,而状态是MOVING的对象虽然正在移动,但是它是已经经过碰撞检测之后才进行移动的,所以也不需要进行碰撞检测。那么在这个寻径的问题中,只需要对于状态是MOVED的对象进行测试,测试它的intnextx,nexty两个变量是否与其它的对象所在位置或是即将所在位置进行判断即可。
在解决碰撞检测问题的基础上,接下来就是设计协调算法了。常用的协调算法有以下几种:
北京工业大学工学硕士学位论文
1.重新计算路径
当时间渐渐过去,我们希望地图有所改变。以前搜索到的一条路径到现在也许不再是最佳的了。对旧的路径用新的信息进行更新是有价值的。以下规则可以用于决定什么时候需要重新计算路径:
每N步:这保证用于计算路径的信息不会旧于N步。
任何可以使用额外的CPU时间的时候:这允许动态调整路径的性质:在物体数量多时,或者运行游戏的机器比较慢时,每个物体对CPU的使用可得到减少。
当物体拐弯或者跨越一个导航点(waypoint)的时候。
当物体附近的世界改变了的时候。
重计算路径的主要缺点是许多路径信息被丢弃了。例如,如果路径是100步长,每10步重新计算一次,路径的总步数将是100+90+80+70+60+50+40+30+20+10=550。对M步长的路径,大约需要计算M‘2步。因此如果你希望有许多很长的路径,重计算不是个好主意。重新使用路径信息比丢弃它更好口引。
2.路径拼接
当一条路径需要被重新计算时,意味着世界正在改变。对于一个正在改变的世界,对地图中当前邻近的区域总是比对远处的区域了解得更多。因此,我们应该集中于在附近寻找好的路径,同时假设远处的路径不需要重新计算,除非我们接近它。与重新计算整个路径不同,我们可以重新计算路径的前M步:
令P[1]..pEN]为路径(N步)的剩余部分
为p[1]到prM]计算一条新的路径
把这条新路径拼接(Splice)到旧路径:把pr1]..P[M]用新的路径值代替因为Pr1]和P[M]比分开的M步小,看起来新路径不会很长。不幸的是,新的路径也许很长而且不够好。通常可以通过查看新路径的长度检测到坏的路径。如果这严格大于M,就可能是不好的。一个简单的解决方法是,为搜索算法设置一个最大路径长度。如果找不到一条短的路径,算法返回错误代码;这种情况下,用重计算路径取代路径拼接。
对于其它情况,对于N步的路径,路径拼接会计算2N或者3N步,这取决于拼接新路径的频率。对于对世界的改变作反应的能力而言,这个代价是相当低的。令人吃惊的是这个代价和拼接的步数M无关。M不影响CPU时间,而控制了响应和路径质量的折衷。如果M太大,物体的移动将不能快速对地图的改变作出反应。如果M太小,拼接的路径可能太短以致不能正确地绕过障碍物;许多不理想的路径将被找到。尝试不同的M值和不同的拼接标准(如每3/4M步),看看哪一种情况对你的地图最合适。
路径拼接确实比重计算路径要快,但它不能对路径的改变作出很好的反应。经常可以发现这种情况并用路径重计算来取代。也可以调整一些变量,如M和寻
第4章A‘算法的应用
找新路径的时机,所以可以对该方法进行调整(甚至在运行时)以用于不同的情况[弱】
●
3.监视地图变化
与间隔一段时间重计算全部或部分路径不同的是,可以让地图的改变触发一次重计算。地图可以分成区域,每个物体都可以对某些区域感兴趣(可以是包含部分路径的所有区域,也可以只是包含部分路径的邻近区域)。当一个障碍物进入或者离开一个区域,该区域将被标识为已改变,所有对该区域感兴趣的物体都被通知到,所以路径将被重新计算以适应障碍物的改变。
这种技术有许多变种。例如,可以每隔一定时间通知物体,而不是立即通知物体。多个改变可以成组地触发一个通知,因此避免了额外的重计算。另一个例子是,让物体检查区域,而不是让区域通知物体。
监视地图变化允许当障碍物不改变时物体避免重计算路径,所以当你有许多区域并不经常改变时,考虑这种方法姗。
4.预测障碍物的运动
如果障碍物的运动可以预测,就能为路径搜索考虑障碍物的未来位置。一个诸如胁的算法有一个代价函数用以检查穿过地图上一点的代价有多难。A水可以被改进从而知道到达一点的时间需求(通过当前路径长度来检查),而现在则轮到代价函数了。代价函数可以考虑时间,并用预测的障碍物位置检查在某个时刻地图某个位置是否可以通过。这个改进不是完美的,然而,因为它并不考虑在某个点等待障碍物自动离开的可能性,同时胁并不区分到达相同目的地的不同的路径,而是针对不同的目的地,所以还是可以接受的m1。
在本课题中,我们采用混合的几种方法,一个是重新寻找路径,一个是预测障碍物的运动,还有就是采用等待方法。
重新寻找路径:这个方案最为简单,只需要清除旧的寻径信息,重新运行胁算法,找到一条新的路径即可。这里需要解决的一个问题是,如何把当前的一个障碍物对象让胁算法检测的到?因为A:Ic算法检测障碍物时只针对地图上的固定障碍物。为了解决这个问题,我们需要修改A,I:算法的检测函数的实现,增加一个动态障碍物链表,在需要重新寻径的时候,可以把当前所碰到的障碍物插入到链表当中,这样就可以被A术算法所检测到。在需要的时候,可以初始化这个动态障碍物链表,重新定义动态障碍物。
预测障碍物的运动:这个比较简单,就是前面所定义的两个变量intnextx,nexty,在进行碰撞检测的时候,同时检测这两个变量,就可以做到预测障碍物的运动。
采用等待方法:这个方法就是前面所描述的WAIT状态,当对象发现即将移动的位置被其他正在移动的对象所占有时,可以采取等待方法,等到挡住它去路的
北京工业大学工学硕士学位论文
对象移走时再继续前行。
在地图中,对象运动的时候,会出现不同的碰撞形式。在检测出碰撞之后,算法会根据具体的形式给出不同的处理策略,是重新寻找路径还是原地暂停等待,采取那种方案取决于对方动态障碍物的当前位置和状态。
在算法中,我们根据地图中可能碰到的实际情况总结了几十种不同的碰撞形式。每次发生碰撞时,程序都都自动地匹配一种定义好的形式,然后再根据动态障碍物对象的当前状态采取不同的处理策略。在这里,举两个例子简单说明,如图4-2所示:
A●一_A点
T
IB●一文,
、●
图4—2碰撞形式
Figure4-2collisionform#
图4—2中的红色结点是状态为MOVED的结点,而蓝色结点充当障碍物结点。左边和右边是两种不同的碰撞形式。
在图4-2左边,状态为MOVED的红色结点正要准备往A点移动,而蓝色结点也要往A点移动。当处理A点时,碰撞检测程序会检测出未来有可能和蓝色结点发生碰撞,因为两个结点的目标结点重合了。这个时候,就需要检测蓝色结点的状态了。分为三种状态:
MOVED:和红色结点相同的状态,由于处理的是红色结点,那么,强行命令蓝色结点等待若干秒,等待的时间和红色结点移动到A点的时间相同,而红色结点本身变为MOVING状态,继续前进。
MOVING:蓝色结点正在移动,拥有最高的优先级,那么.红色结点只能被迫等待一段时间,等到蓝色结点移动结束后在处理。
WAIT:这个相当于表面静止,实际蓝色结点处于等待状态,那么红色结点直接变为MOVING状态,向前移动即可。
在图4-2右边,状态为MOVED的红色结点正要往A点移动,而蓝色结点已经占领了A点。当处理A点时,碰撞检测程序会检测出红色结点和蓝色结点立刻会发生碰撞,因为蓝色结点直接挡住了红色结点。这个时候,也需要检测蓝色结点的状态了。分为三种状态:
第4苹A+算法的应用
MOVED:和红色结点相同的状态,由于蓝色结点直接挡住了红色结点,那么,命令红色结点停住等待若干秒,等待的时间和蓝色结点移出A点的时间相同,也可以让红色结点重新寻找路径,不过这样会更浪费时间。
MOVING:蓝色结点正在移动,拥有最高的优先级,那么,红色结点只能被迫等待一段时间,等到蓝色结点移动结束后在处理。
WAIT:这个蓝色结点处于静止状态,那么红色结点只能重新寻找路径,绕过蓝色结点继续移动,或是红色结点也变成WAIT状态,这样,等待的时间有可能过长。
上述两种碰撞形式只是几十种不同碰撞形式的缩影,其他的不同形式处理方式和上述的处理方法类似。这样一个庞大的处理系统就建立起来了,无论程序碰到什么形式的碰撞,都可以通过这个系统来协调解决。
下面说明多个对象移动到同一目标结点的问题,本程序使用的解决方法是:对于同一批命令运动的多个对象进行组编号,当碰到同一编号的已到达对象的时候,就算到达目的地。这样,多个对象就会在目标结点附近聚集,基本可以达到要求。如图4-3所示:
A
●
●●
●●B●
图4—3到达算法示意图
Figure4—3arrivalalgorithmdiagram
假设途中所有的对象是属于同一批命令的,它们的目的是到达B点,从图中可以看出,红色结点首先到达了B点,成为到达结点,其他的结点就无法在占领B点了,那么只需要接触到到达结点就算到达了,这样,B点周围可以聚集大批结点,而A点位置的对象并未接触到到达结点,所以它将继续移动。
4.2测试软件的设计
4.2.1界面设计
这个章节讲述的是测试软件的设计方案。设计这个测试软件的目的是将A木算法真实的应用到对象的实际寻径当中,并按照前一章节所设计的协调算法进行
]匕gT业女§I{《±{&kZ
多个对象之训的协调,测试寻径的结果是否能达到我们的需求,测试之前设计的协调算法是否能起到作用。
首先我们进行界面设计。界而设计的要求是:有多个对象,对象可以接受用户控制,到达地图的任何可到选的区域,地图中有若干障碍物。最终界面如图4a所示
曲4-4测试程序界面
Figure4?4TestProgramInterface
图中的灰色部分表示空白区域,即可通行区域,图中的黑色句型块表示障碍物,对象无法通行,红色和蓝色的圆点表示人物角色,即可移动的对象,这些对象是可控制的,使用鼠标左键可以画出绿色矩形选择框,将所要选择的对象包含在其中即可选中,之后可以点击任何可通行的位置即可命令它们移动,如图中大部分红色的结点被选中。其中红色对象和蓝色对象是一样的,只是颜色不同而己,之所以区别出两种不同的颜色,是为了在测试的时候容易识别。
422程序设计
这个测试程序是使用WINDOWSAPI编写的,在消息的主循环中,采取了固定频率刷新的方法来保持程序的运行和刷新。代码如下:
staric
staticintintt1=0t2=0
t1=::GetTickCount0:
while(1)
f
(消息循环部分)
t2-:GetTlckcount0:
if((t2t1)>40)
第4章A?算法的应用
tl=tl+40:
framecount++:
maihprocess0:
}
else‘‘
::Sleep(t2一t1):
}
程序使用了两个变量tl和t2来记录循环的当前时间和前一次循环的时间,mainprocess函数是整个程序的主循环处理函数,在每次运行主处理函数前都要计算一下时间,保证一秒钟执行主处理函数的次数是一定的,这样就保证了程序速度的均衡,如果时间还早,计算机将执行Sleep函数,暂时挂起本程序啪1。
主处理程序mainprocess较为简单,就是先调用程序的更新game.GameUpdate(),再调用程序的渲染game.GameRender(),具体的更新和渲染都在每个具体的类当中。
程序中定义了三个最基本的类:地图类、控制类、角色类。
地图类:负责生成地图,设置地图中的障碍物,再将数据存储起来,通过一个渲染接口在屏幕上凰出地图来。
控制类:管理鼠标选中对象、下命令移动的类,通过消息机制对鼠标的单击、移动进行监测和控制,并渲染出绿色矩形框来。
角色类:这个类是最为复杂的一个类,也是最为核心的一个类。在类中,包括最基本的渲染部分和最核心的更新部分。更新部分每次循环都被调用,也就是说每个对象都要更新一次。更新的内容主要就是之前所设计的协调算法,根据每个对象的当前位置和当前状态来决定下一循环中对象的位置和状态。
最后还有一个CGame类,用于组合封装前面的几个基本的类,使之保持一个接口即可。.
程序的渲染部分使用GDI绘图。为了防止闪烁的发生,程序中使用了双缓冲的技术,就是在内存中创建一个与显示图形的窗口区域一样大的位图,先用GDI函数绘制位图,然后在绘制完成一帧的时候从内存中一次性地显示出来。因为位图已经绘制好,不象平时编程一样边绘制边显示,所以,显示一帧图形时,减少了闪烁,从而实现平滑动画“01。
4.3测试结论
我们已经把之前所设计的协调算法应用到了程序当中,现在就可以进行测试了。测试的具体方法是将地图一端的一群红色结点移动到另一端,而将地图另一端的一群蓝色结点移动到它们的另一端去,这些结点在中间移动时将会发生多次碰撞,协调算法将会分开它们,最后使得每一个结点到达目的地。下面这个图片
:!圣三些奎兰±茎堑圭耋些耋圣
是初始状态下的隋况.如图45:
眦二
我们现在利用鼠标选
在的位置,它们需要躲开
然后还要躲开其他移动的
爨潮图46运行时界面
Figure445Run-timeintcrfaze
图4—6就是两个不同颜色的集团在互相移动过程中的截图,图中可以看出大部分对象都在不时的发生碰撞,它们始终处于协调状态,或者原地等待几秒钟或者重新寻径,CPU也出于非常忙碌的状态。下面图4—7是CPU使用率的情况:
图4—7运行时cP【I使用宰
Figure4—7Run-timeCPUutilization
最后,经过一段时间后,各个结点都到达了目的地,原先混在一起红色和蓝色也很自然的分开了。
一¨.
~..一..
...
...
.¨....
图4—8运行结果后界团
Figure4?8arrivalinterface..一....
图48就是移动后的结果,从大体上看,红色结点和蓝色结点成功的分开了,但是有一点缺陷就是到达目的地之后它们的排列显得很不规则。这是因为我们使用了最简单的组运动到达算法,只要接触到已经到达的结点就算到达。从总体上讲,在多个对象同时运动的时候,这个协调算法还是基本可以满足我们的需要的。44本章小结
本章研究的是A}算法的应用。首先对于A丰算法的具体应用进行了分析和研究,提出了在具体应用中可能会出现的问题。为了解决这些问题,本章中设计了一种协调算法,来协调多个对象的移动。接着,课题中设计了一个演示软件,将A}算法和所设计协调算法运用到了实际的寻径当中。通过软件的测试证明,本章所设计的协调算法基本上可行。
结论
本课题首先介绍了选题的背景及研究意义。启发式搜索算法A水算法是游戏引擎中的重要算法之一,它是用来在地图上寻找路径的。在传统的A木算法设计中,针对算法本身需要的数据结构并没有做足够的优化,还有很大的优化余地,还可以在一定程度上提高算法的效率。其次,将A术算法应用到实际当中还需要一些协调性的算法。
本课题对上述两个问题进行了深入的研究。在研究之前,对于基础性的理论知识进行了系统性的回顾和总结,主要包括搜索算法的基本知识,如状态空间法、产生式系统理论、状态图示表示法等;接着,对一些传统的图搜索算法进行了简单的介绍和分析,包括回溯法、宽度优先搜索算法、深度优先搜索算法等,最后引出了本课题所使用的启发式搜索算法A木算法,对A木算法的基本原理和应用情况进行了介绍。
对于胁算法数据结构的优化问题,本课题开发了两个演示软件。第一个是演示胁算法的执行过程,包括单步执行和正常执行,在执行结束后,记录下来各种执行期间的数据统计,并以图表的形式反映出来。这个软件是优化A木算法的基础。在通过这个软件详细地分析了A牢算法之后,优化工作就开始了。本课题使用的优化方案是:第一,将哈希表的数据结构作为A水算法的OPEN集合,使用估计值作为哈希表的关键字,采用链地址法进行冲突的处理;第二,使用二维数组对每个结点进行标记,使得查找每个结点的集合归属运算效率大大提高。本课题开发的第二个软件就是算法时间的比较软件,用来测试未优化数据结构的A木算法和优化数据结构后的A,I:算法的时间,经过多个地图多次测试后证明,本课题中的优化方案是成功的。
本课题的最后~部分是A水算法的应用。首先对于A,lc算法的具体应用进行了分析和研究,提出了在具体应用中可能会出现的问题。为了解决这些问题,课题设计了协调算法。接着,课题中设计了一个演示模型软件,将胁算法和协调算法运用到了实际的寻径当中。通过软件的测试证明,课题所设计的协调算法基本可以达到寻径的要求。此外,由于时间所限,本课题在A木的具体应用方面还存在一些可以改进的
北京工业大学工学硕士学位论文
地方,例如组运动到达算法、协调算法策略等方面,希望在以后的研究中能够将算法改进的更加完善。
参考文献
参考文献
蔡自兴。佑.人工智能及其应用.清华大学出版社.2002:10--30
Ryanl2Leigll,SushilJ.Louis,ChrisMiles.UsingaGeneticAlgorithmtoExploreA?likePathtindingAlgorithms.1-4244—0709-5/072007IEEE
3陈和平。张前哨.A.c算法在游戏地图寻径中的应用与实现.计算机软件与应用.2005:
26—28
4
5
6
7
8高济.人工智能基础.高等教育出版社.2002:71-77朱福喜.人工智能原理.武汉大学出版社.2002:44---45NoelLlopis.C++forGameProgrammers.DelmarThomsonLearning.2003:19—24方约翰.人工智能在计算机游戏和动画中的应用.班晓娟.清华大学出版社.2004:33—35ThorAlexander,Massively.MultiplayerGameDevelopment.DelmarThomsonLearning.
2003:12-13
9王敬东。李佳.A?算法在地图寻径中的实用性优化.计算机开发与应用:32~34
voll.29No.1l:18-1910赵建民朱信忠.即时战略游戏中寻径问题的算法及实现技术研究.计算机科学2002
ll赵建宏,杨建宇,雷维礼.一种新的最短路径算法.电子科技大学学报第34卷第6期:
7 ̄10
TristanCazenave.Optimizationsofdatastructures,heuristicsandalgorithmsfor
on12path?血dir培maps.1?4244—0464-9/062006IEEE
Bin,ChenHeping.ANearOptimizationAlgorithmFor13WangJingcun,WangQin,Chen
Pathf'mding.1?4244-0517-3/062006IEEE
14侯俊杰.深入浅出MFC.华中科技大学出版社.2004:156--163
15谢志鹏。蔡灿辉.游戏地图最短路径搜索设计与实现.计算机工程与应用2005:5—816徐洪智,李仁发,颜一鸣.分支限界法在游戏地图寻径中的应用.计算机工程与应用
2007:27-30
17
18
19AndreHerbIamothe.Windows游戏编程大师技巧.中国电力出版社.2001:207---209ExceptionalC++.AddisonSutter.MoreWesleyLongman,Ine.2001:55-56WesleyLongman,Inc.2004:35---38
20严蔚敏。吴伟民.数据结构.清华大学出版社.1997:121~125HerbSutter.ExceptionalC++Style.Addison
21伽玛,李英军.设计模式.机械工业出版社.2000:38--44
22BjalTleStroustrup.TheC++ProgrammingLanguage(Special3mEdition).AddisonWesley
Longman,Inc.1997:54--66
Lippman.C++Primer(3rdEdition).AddisonWesleyLongman,Inc.1998:97—102
24苏羽.VisualC++网络游戏建模与实现.北京科海电子出版社.2003:133—13723TanleyB25StanleyBLippman.Insidethe
77-84C抖ObjectModel.AddisonWesleyLongman,Inc.1996:
26戈德。陈为.面向对象的游戏开发.电子工业出版社.2005:5~12
27
28
29ScottScoaMeyers.EffectiveC++中文版2ndEdition.侯捷.华中科技大学出版社.2001:99—112Meyers.MoreEffectiveC++中文版.侯捷.华中科技大学出版社.2001:23~29JimBeveridge。RobertWienenWin32多线程程序设计.侯捷.华中科技大学出版社.1997:
44“7.53.
北京工业大学工学硕士学位论文
如
儿NicolaiMJosuttis.C++StandardLibrary.ATutorialandReference.AddisonWesleyLongman,Inc.1999:87-93AntonyJones.NetworkProgrammingforMicrosoftWindows.MicrosoftPress.2000:
194~197
罗比斯.C++游戏编程.清华大学出版社.2004:34~42
弛驺JeffreyRichter.ProgrammingApplicationsfor
192—20lMicrosoftWindows.MicrosoftPress.1999:
钱潘德.人工智能游戏开发.中国环境科学出版社.2004:12~23弘"ThorAlexander.MassivelyMultiplayerGameDevelopment2.DelmarThomsonLearning.
2005:3l~37
罗斯.游戏设计原理与实践.尤晓东.电子工业出版社.2003:56--61弘卯JessicaMulligan,Bridgette
Games.2003:l1-14Patrovsky.DevelopingOnlineGames:AnInsider'sGuide.NewRiders
德洛拉.游戏编程精粹1.王淑礼.人民邮电出版社.2004:122~131德洛拉.游戏编程精粹2.袁国忠.人民邮电出版社.2003:45~53弛的∞MarkADeloura.GameProgrammingGems.DelmarThomsonLearning.2004:84,--89
.54.
致谢
致谢
首先感谢我的导师许向众老师和于书举老师。在研究生三年的时间里,两位老师一直关心着我的学习和生活情况,尤其是在奥组委实习的一年当中,仍不忘指导和鼓励着我的论文研究工作,使我能够顺利完成论文。老师们渊博的知识、丰富的经验、在学术上的严谨都给了我很大的影响。在此对两位老师致以崇高的敬意和诚挚的感谢。
感谢我的父母,他们一直寄予我厚望,默默地支持着我。
感谢我的同学们,他们在这三年中,关心帮助着我,让我体会着奥运班级的温暖。
感谢奥组委的同事们,他们为我论文的完成也提供了很多帮助,同时也教我很多工作经验。

基于启发式搜索算法的地图寻径的研究作者:
学位授予单位:许鹏北京工业大学
本文链接:http://d..cn/Thesis_Y1569721.aspx