建模十大算法总结:
1、蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时通过模拟可以来检验自己模型的正确性。
2、数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具。
3、线性规划、整数规划、多元规划、二次规划等规划类问题。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo、MATLAB软件实现。
4、图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。
5、动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中。
6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法。这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。
7、网格算法和穷举法。网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。
8、一些连续离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。
9、数值分析算法。如果在比赛中采用高级语言进行编程的话,那一些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。
10、图象处理算法。赛题中有一类问题与图形有关,即使与图形无关,论文中也应该要不乏图片的,这些图形如何展示以及如何处理就是需要解决的问题,通常使用Matlab进行处理。
从历年竞赛题来看,常用的方法:
线性规划 整数规划 非线性规划 动态规划 层次分析法
图论方法 拟合方法 插值方法 随机方法 微分方程方法
一、蒙特卡洛算法
1、含义的理解
以概率和统计理论方法为基础的一种计算方法。也称统计模拟方法,是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法,它是将所求解的问题同一定的概率模型相联系,用计算机实现统计模拟或抽样,以获得问题的近似解。
2、算法实例(有很多相似的例题,包括平行线等)
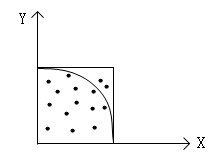
在数值积分法中,利用求单位圆的1/4的面积来求得Pi/4从而得到Pi。单位圆的1/4面积是一个扇形,它是边长为1单位正方形的一部分。只要能求出扇形面积S1在正方形面积S中占的比例K=S1/S就立即能得到S1,从而得到Pi的值。怎样求出扇形面积在正方形面积中占的比例K呢?一个办法是在正方形中随机投入很多点,使所投的点落在正方形中每一个位置的机会相等看其中有多少个点落在扇形内。将落在扇形内的点数m与所投点的总数n的比m/n作为k的近似值。P落在扇形内的充要条件是 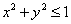 。
。
已知:K= ,K
,K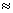
 ,s=1,s1=
,s=1,s1= ,求Pi。
,求Pi。
由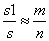 ,知s1
,知s1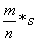 =,
=,
而s1=,则Pi=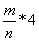
程序:(该算法可以修改后用Mathematica计算或者Matlab)
/* 利用蒙特卡洛算法近似求圆周率Pi*/
/*程序使用:VC++6.0 */
#include<stdio.h>
#include<math.h>
#include<stdlib.h>
#define COUNT 800 /*循环取样次数,每次取样范围依次变大*/
void main()
{
double x,y;
int num=0;
int i;
for(i=0;i<COUNT;i++)
{
x=rand()*1.0/RAND_MAX;/*RAND_MAX=32767,包含在<stdio.h>中*/
y=rand()*1.0/RAND_MAX;
if((x*x+y*y)<=1)
num++; /*统计落在四分之一圆之内的点数*/
}
printf("Pi值等于:%f\n",num*4.0/COUNT);
}
结果:
测试6次的结果显示:
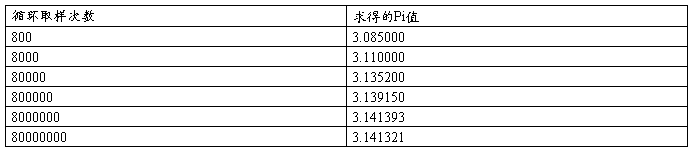
可以看出:随着点数的增加,求得的Pi值渐渐接近真实值。
如果加入程序:srand(time(NULL)); ,同时循环取样次数一定,让取样结果随时间变化,当取样次数为80000000时,可得6次的结果显示:
3.141290 3.141400 3.141268 3.141484 3.141358 3.141462
3、应用的范围
蒙特·卡罗方法在金融工程学,宏观经济学,计算物理学(如粒子输运
计算、量子热力学计算、空气动力学计算)等领域应用广泛。
4、参考书籍
[1]蒙特卡罗方法及其在粒子输运问题中的应用 [2]蒙特卡罗方法引论
二、数据拟合、参数估计、插值等数据处理算法
(1)数据拟合
在Mathematica中,用Fit对数据进行最小二乘拟合:Fit[data,funs,vars]
在Matlab中,工具箱(toolboxes)中有曲线拟合工具(curve Fitting)。
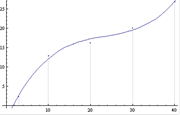
实例:
20##年苏北赛B题 温室中的绿色生态臭氧病虫害防治 中关于中华稻蝗密度与水稻减产率之间的关系可以通过数据拟合来观察(简单举例,没有考虑全部数据)
数据:

程序(Mathematica):
data={{3,2.4},{10,12.9},{20,16.3},{30,20.1},{40,26.8}};
a1=Fit[data,{1,x,x^2,x^3},x]
Show[ListPlot[data,Filling->Axis],Plot[{a1},{x,0,60}]]
结果:
-3.68428+2.38529 x-0.0934637 x2+0.00132433 x3
(2)参数估计(参考书:概率论与数理统计)
参数估计为统计推断的基本问题,分为点估计和区间估计。
点估计:
①矩估计法
X连续型随机变量,概率密度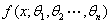
X为离散型随机变量 分布律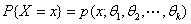
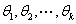 为待估参数,
为待估参数,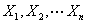 是来自X的样本,假设总体X的前
是来自X的样本,假设总体X的前 阶矩存在,为
阶矩存在,为
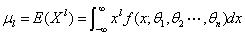 (X连续型)
(X连续型)
或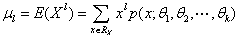 (X离散型)
(X离散型)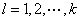 (其中
(其中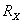 是X可能取值的范围)。一般来说,它们是的函数。基于样本矩
是X可能取值的范围)。一般来说,它们是的函数。基于样本矩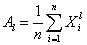 依概率收敛于相应的总体矩
依概率收敛于相应的总体矩 ,样本矩的连续函数依概率收敛于相应的总体矩的连续函数,我们就用样本矩作为相应的总体矩的估计量,而以样本矩的连续函数作为相应的总体矩的连续函数的估计量。这种估计方法成为矩估计法。
,样本矩的连续函数依概率收敛于相应的总体矩的连续函数,我们就用样本矩作为相应的总体矩的估计量,而以样本矩的连续函数作为相应的总体矩的连续函数的估计量。这种估计方法成为矩估计法。
②最大似然估计法
X连续型随机变量 似然函数 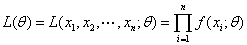 其中
其中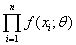 是来自X的样本的联合密度。
是来自X的样本的联合密度。
X为离散型随机变量 似然函数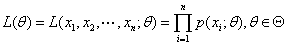 其中
其中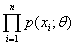 是来自X的样本的联合分布律。
是来自X的样本的联合分布律。
若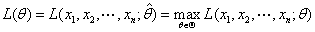
则称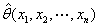 为
为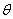 的最大似然估计值,称
的最大似然估计值,称 为的最大似然估计量。
为的最大似然估计量。
这样,确定最大似然估计量的问题就归结为微分学中的求最大值的问题了。
估计量的评选标准为:(1)无偏性(2)有效性(3)相合性
区间估计:
对于一个未知量,人们在测量或计算时,常不以得到近似值为满足,还需要估计误差,即要求知道近似值的精确程度(亦即所求真值所在的范围)。这样的范围常以区间的形式给出,同时还给出此区间包含参数真值的可信度,这种形式的估计称为区间估计,这样的区间即所谓置信区间。
正态总体均值、方差的置信区间与单侧置信限(置信水平为1-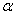 )
)

另外还包括两个正态总体的情况,
其他区间估计:(0-1)分布参数的区间估计
(3)插值
1、含义的理解
在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点。插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值(与拟合的不同点在于拟合的函数不需通过每一个离散点)。
插值问题的提法是:假定区间[a,b]上的实值函数f(x)在该区间上 n+1个互不相同点x0,x1…xn 处的值是f [x0],…f(xn),要求估算f(x)在[a,b]中某点的值。其做法是:在事先选定的一个由简单函数构成的有n+1个参数C0,C1,…Cn的函数类Φ(C0,C1,…Cn)中求出满足条件P(xi)=f(xi)(i=0,1,… n)的函数P(x),并以P()作为f()的估值。此处f(x)称为被插值函数,x0,x1,…xn称为插值结(节)点,Φ(C0,C1,…Cn)称为插值函数类,上面等式称为插值条件,Φ(C0,…Cn)中满足上式的函数称为插值函数,R(x)= f(x)-P(x)称为插值余项。当估算点属于包含x0,x1…xn的最小闭区间时,相应的插值称为内插,否则称为外插。
2、基本类型
多项式插值
在一般插值问题中,若选取Φ为n次多项式类,由插值条件可以唯一确定一个n次插值多项式满足上述条件。拉格朗日插值和牛顿插值都属于多项式插值。
拉格朗日插值:
设连续函数y = f(x)在[a, b]上对给定n + 1 个不同结点:
 分别取函数值
分别取函数值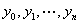
其中 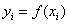
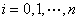 (1)
(1)
试构造一个次数不超过 n的插值多项式
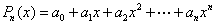 (2)
(2)
使之满足条件 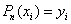
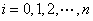 (3)
(3)
构造n次多项式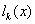
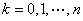 使
使
=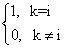 (4)
(4)
由 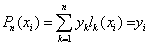 (5)
(5)
即 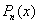 满足插值条件,于是问题归结为具体求出基本插值多项式。
满足插值条件,于是问题归结为具体求出基本插值多项式。
根据(4)式以外所有的节点都是的根,因此令
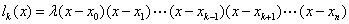
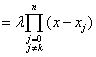
又由=1,得:
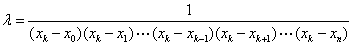
所以有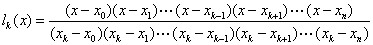
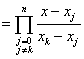
代入(5)得 拉格朗日插值多项式为:

牛顿插值:
(拉格朗日插值的缺点)拉格朗日插值公式的形式虽然有一定的规律, 但是当增加一个节点时,不仅要增加项数,而且以前各项也必须重新全部计算,不能利用已有的结果。为克服这一缺点,我们取用另一种形式——牛顿插值公式。
牛顿插值公式中用到了差商。一般称:
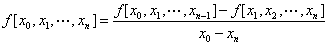
为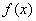 在处的n阶差商。
在处的n阶差商。
差商可列表计算:
xi yi 一阶差商 二阶差商 三阶差商 四阶差商
x0 f (x0)
x1 f (x1) f [x0, x1]
x2 f (x2) f [x1, x2] f [x0, x1, x2]
x3 f (x3) f [x2, x3] f [x1, x2, x3] f [x0, x1, x2, x3]
x4 f (x4) f [x3, x4] f [x2, x3, x4] f [x1, x2, x3, x4] f [x0,?, x4]
由差商定义可知
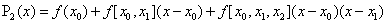
由差商定义可求得
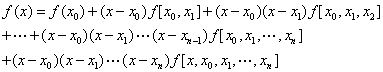
记

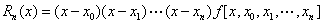
则 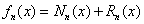
其中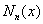 称为n次牛顿插值多项式,
称为n次牛顿插值多项式,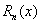 是截断误差。
是截断误差。
最终我们可以证明满足插值条件
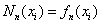
因此有 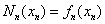
牛顿插值公式的优点是:当增加一个节点时,只要再增加一项就行了,即有递推式
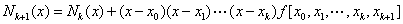
当然,与拉格朗日插值相比它还有节省运算次数的优点(尤其是节省乘法运算次数)。
分段插值与样条插值
为了避免高次插值可能出现的大幅度波动现象,在实际应用中通常采用分段低次插值来提高近似程度
埃尔米特插值
许多实际插值问题中,为使插值函数能更好地和原来的函数重合,不但要求二者在节点上函数值相等,而且还要求相切,对应的导数值也相等,甚至要求高阶导数也相等。这类插值称作切触插值,或埃尔米特(Hermite)插值。满足这种要求的插值多项式就是埃尔米特插值多项式
三角函数插值
当被插函数是以2π为周期的函数时,通常用n阶三角多项式作为插值函数,并通过高斯三角插值表出。
三、线性规划、整数规划、多元规划、二次规划
(1)线性规划
1、含义的理解
线性规划是运筹学中研究较早、发展较快、应用广泛、方法较成熟的一个重要分支,它是辅助人们进行科学管理的一种数学方法.研究线性约束条件下线性目标函数的极值问题的数学理论和方法,英文缩写LP。它是运筹学的一个重要分支。
在经济管理、交通运输、工农业生产等经济活动中,提高经济效果是人们不可缺少的要求,而提高经济效果一般通过两种途径:一是技术方面的改进,例如改善生产工艺,使用新设备和新型原材料.二是生产组织与计划的改进,即合理安排人力物力资源.线性规划所研究的是:在一定条件下,合理安排人力物力等资源,使经济效果达到最好.一般地,求线性目标函数在线性约束条件下的最大值或最小值的问题,统称为线性规划问题。满足线性约束条件的解叫做可行解,由所有可行解组成的集合叫做可行域。决策变量、约束条件、目标函数是线性规划的三要素。
2、线性规划问题的数学模型的一般形式和模型建立
(1)列出约束条件及目标函数 (2)画出约束条件所表示的可行域 (3)在可行域内求目标函数的最优解及最优值(实际问题中建立数学模型一般有以下三个步骤:根据影响所要达到目的的因素找到决策变量;2.由决策变量和所在达到目的之间的函数关系确定目标函数;3.由决策变量所受的限制条件确定决策变量所要满足的约束条件。)
所建立的数学模型具有以下特点:
(1)、每个模型都有若干个决策变量(x1,x2,x3……,xn),其中n为决策变量个数。决策变量的一组值表示一种方案,同时决策变量一般是非负的。
(2)、目标函数是决策变量的线性函数,根据具体问题可以是最大化(max)或最小化(min),二者统称为最优化(opt)。
(3)、约束条件也是决策变量的线性函数。当我们得到的数学模型的目标函数为线性函数,约束条件为线性等式或不等式时称此数学模型为线性规划模型。
3、实例
生产计划问题
问题:
某企业要在计划期内安排生产甲、乙两种产品,这个企业现有的生产资料是:设备18台时,原材料A :4吨,原材料 B: 12吨;已知单位产品所需消耗生产资料及利润如下表。问应如何确定生产计划使企业获利最多?

设x1为甲产品分配的设备台数,x2为乙产品分配的台数。则
条件限制为:
3*x1+2*x2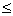 18
18
1*x1+0*x24
0*x1+2*x212
x1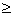 0,x20
0,x20
求max z=3*x1+5*x2
用lingo编程,程序如下:
max=3*x1+5*x2;
3*x1+2*x2<=18;
x1<=4;
x2<=6;
x1>=0;
x2>=0;
结果为:
Global optimal solution found.
Objective value: 36.00000
Total solver iterations: 1
Variable Value Reduced Cost
X1 2.000000 0.000000
X2 6.000000 0.000000
Row Slack or Surplus Dual Price
1 36.00000 1.000000
2 0.000000 1.000000
3 2.000000 0.000000
4 0.000000 3.000000
5 2.000000 0.000000
6 6.000000 0.000000
即在x1=2,x2=6时,企业获利最多,为36万元。
4、线性规划的应用
在企业的各项管理活动中,例如计划、生产、运输、技术等问题,线性规划是指从各种限制条件的组合中,选择出最为合理的计算方法,建立线性规划模型从而求得最佳结果. 广泛应用于军事作战、经济分析、经营管理和工程技术等方面。为合理地利用有限的人力、物力、财力等资源作出的最优决策,提供科学的依据。
(2)整数规划
一类要求问题的解中的全部或一部分变量为整数的数学规划。从约束条件的构成又可细分为线性,二次和非线性的整数规划。 在线性规划问题中,有些最优解可能是分数或小数,但对于某些具体问题,常要求某些变量的解必须是整数。例如,当变量代表的是机器的台数,工作的人数或装货的车数等。为了满足整数的要求,初看起来似乎只要把已得的非整数解舍入化整就可以了。实际上化整后的数不见得是可行解和最优解,所以应该有特殊的方法来求解整数规划。在整数规划中,如果所有变量都限制为整数,则称为纯整数规划;如果仅一部分变量限制为整数,则称为混合整数规划。整数规划的一种特殊情形是0-1规划,它的变数仅限于0或1。不同于线性规划问题,整数和0-1规划问题至今尚未找到一般的多项式解法。
组合最优化通常都可表述为整数规划问题。两者都是在有限个可供选择的方案中,寻找满足一定约束的最好方案。有许多典型的问题反映整数规划的广泛背景。例如,背袋(或装载)问题、固定费用问题、和睦探险队问题(组合学的对集问题)、有效探险队问题(组合学的覆盖问题)、旅行推销员问题, 车辆路径问题等。因此整数规划的应用范围也是极其广泛的。它不仅在工业和工程设计和科学研究方面有许多应用,而且在计算机设计、系统可靠性、编码和经济分析等方面也有新的应用。
整数规划是从1958年由R.E.戈莫里提出割平面法之后形成独立分支的 。解整数规划最典型的做法是逐步生成一个相关的问题,称它是原问题的衍生问题。对每个衍生问题又伴随一个比它更易于求解的松弛问题(衍生问题称为松弛问题的源问题)。通过松弛问题的解来确定它的源问题的归宿,即源问题应被舍弃,还是再生成一个或多个它本身的衍生问题来替代它。随即再选择一个尚未被舍弃的或替代的原问题的衍生问题,重复以上步骤直至不再剩有未解决的衍生问题为止。目前比较成功又流行的方法是分枝定界法和割平面法,它们都是在上述框架下形成的。
0-1规划在整数规划中占有重要地位,一方面因为许多实际问题,例如指派问题、选地问题、送货问题都可归结为此类规划,另一方面任何有界变量的整数规划都与0-1规划等价,用0-1规划方法还可以把多种非线性规划问题表示成整数规划问题,所以不少人致力于这个方向的研究。求解0-1规划的常用方法是分枝定界法,对各种特殊问题还有一些特殊方法,例如求解指派问题用匈牙利方法就比较方便。
(4)二次规划
二次规划是非线形规划中一类特殊的数学规划问题,它的解是可以通过求解得到的。通常通过解其库恩—塔克条件(KT条件),获取一个KT条件的解称为KT对,其中与原问题的变量对应的部分称为KT点。
二次规划分为凸二次规划与非凸二次规划,前者的KT点便是其全局极小值点,而后者的KT点可能连局部极小值点都不是。若它的目标函数是二次函数,则约束条件是线性的。由于求解二次规划的方法很多,所以较为复杂;其较简便易行的是沃尔夫法,它是依据库恩-塔克条件,在线性规划单纯形法的基础上加以修正而成的。此外还有莱姆基法、毕尔法、凯勒法等。
四、图论:(参考资料:建模教程(图与网络))
(1)含义的理解
图论是专门研究图的理论的一门数学分支,属于离散数学范畴,与运筹学有交叉。
图论中常用点和点之间的线所构成的图,反映实际生产和生活中的某些特定对象之间的特定关系。一般来说,通常用点表示研究对象、用点与点之间的线表示研究对象之间的特定关系。
在一般情况下,图中的相对位置如何,点与点之间线的长短曲直,对于反映研究对象之间的关系,显的并不重要。
因此,图论中的图与几何图,工程图等本质上是不同的。
(2)历史(包括应用范围)
它有200多年历史,大体可划分为三个阶段:
第一阶段是从十八世纪中叶到十九世纪中叶,处于萌芽阶段,多数问题围游戏而产生,最有代表性的工作是所谓的Euler七桥问题,即一笔画问题。
第二阶段是从十九世纪中叶到二十世纪中叶,这时,图论问题大量出现,如Hamilton问题,地图染色的四色问题以及可平面性问题等,这时,也出现用图解决实际问题,如Cayley把树应用于化学领域,Kirchhoff用树去研究电网络等.
第三阶段是二十世纪中叶以后,由生产管理、军事、交通、运输、计算机网络等方面提出实际问题,以及大型计算机使大规模问题的求解成为可能,特别是以Ford和Fulkerson建立的网络流理论,与线性规划、动态规划等优化理论和方法相互渗透,促进了图论对实际问题的应用。
算法
重要的算法
1、求有向图的强连通分支 (Strongerst Connected Component)
(1)Kosaraju算法
(2)Gabow算法
(3)Tarjan算法
2、求最小生成树 (Minimal Spanning Trees)
(1)Kruskal算法
(2)Prim算法
3、最小树形图
(1)朱永津刘振宏算法
4、最短路径问题
(1)SSSP(Single-source Shortest Paths)
①Dijkstra算法
②Bellman-Ford算法(SPFA算法)
(2)APSP(All-pairs Shortest Paths)
①Floyd-Warshall算法
②Johnson算法
5、网络流问题
(1)最大网络流
①增广路算法
⒈Ford-Fulkerson算法
⒉Edmonds-Karp算法
⒊最短路径增殖EK-2(MPLA)
⒋Dinic
②预流推进算法
(2)最小费用流
6、图匹配问题
(1)匈牙利算法
(2)Hopcroft Karp算法
(3)Kuhn-Munkres算法
(4)Edmonds' blossom-contraction 算法
(有关资料网址:http://www.nocow.cn/index.php/%E5%9B%BE%E8%AE%BA)
(1)基本概念
无向图
一个无向图(undirected graph) 是由一个非空有限集合
是由一个非空有限集合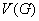 和中某些元素的无序对集合
和中某些元素的无序对集合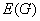 构成的二元组,记为
构成的二元组,记为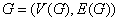 。其中
。其中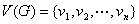 称为图的顶点集(vertex set)或节点集(node set), 中的每一个元素
称为图的顶点集(vertex set)或节点集(node set), 中的每一个元素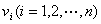 称为该图的一个顶点(vertex)或节点(node);
称为该图的一个顶点(vertex)或节点(node); 称为图的边集(edge set),中的每一个元素
称为图的边集(edge set),中的每一个元素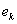 (即中某两个元素
(即中某两个元素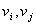 的无序对) 记为
的无序对) 记为 或
或
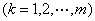 ,被称为该图的一条从
,被称为该图的一条从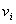 到
到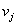 的边(edge)。
的边(edge)。
当边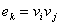 时,称为边的端点,并称与相邻(adjacent);边称为与顶点关联(incident)。如果某两条边至少有一个公共端点,则称这两条边在图中相邻。
时,称为边的端点,并称与相邻(adjacent);边称为与顶点关联(incident)。如果某两条边至少有一个公共端点,则称这两条边在图中相邻。
边上赋权的无向图称为赋权无向图或无向网络(undirected network)。我们对图和网络不作严格区分,因为任何图总是可以赋权的
有向图
一个有向图(directed graph或 digraph)是由一个非空有限集合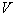 和中某些元素的有序对集合
和中某些元素的有序对集合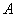 构成的二元组,记为
构成的二元组,记为 。其中
。其中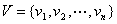 称为图的顶点集或节点集, 中的每一个元素称为该图的一个顶点或节点;
称为图的顶点集或节点集, 中的每一个元素称为该图的一个顶点或节点;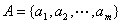 称为图的弧集(arc set),中的每一个元素
称为图的弧集(arc set),中的每一个元素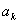 (即中某两个元素的有序对) 记为
(即中某两个元素的有序对) 记为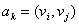 或
或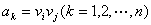 ,被称为该图的一条从到的弧(arc)。
,被称为该图的一条从到的弧(arc)。
当弧 时,称为的尾(tail),为的头(head),并称弧为的出弧(outgoing arc),为的入弧(incoming arc)。
时,称为的尾(tail),为的头(head),并称弧为的出弧(outgoing arc),为的入弧(incoming arc)。
对应于每个有向图 ,可以在相同顶点集上作一个图,使得对于的每条弧,有一条有相同端点的边与之相对应。这个图称为的基础图。反之,给定任意图,对于它的每个边,给其端点指定一个顺序,从而确定一条弧,由此得到一个有向图,这样的有向图称为的一个定向图。
,可以在相同顶点集上作一个图,使得对于的每条弧,有一条有相同端点的边与之相对应。这个图称为的基础图。反之,给定任意图,对于它的每个边,给其端点指定一个顺序,从而确定一条弧,由此得到一个有向图,这样的有向图称为的一个定向图。
完全图、二分图
每一对不同的顶点都有一条边相连的简单图称为完全图(complete graph)。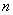 个顶点的完全图记为
个顶点的完全图记为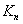 。
。
若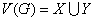 ,
,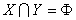 ,
,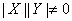 (这里
(这里 表示集合
表示集合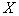 中的元素个数),中无相邻顶点对,
中的元素个数),中无相邻顶点对,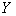 中亦然,则称为二分图(bipartite graph);特别地,若
中亦然,则称为二分图(bipartite graph);特别地,若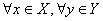 ,则
,则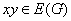 ,则称为完全二分图,记成
,则称为完全二分图,记成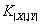 。
。
最短路、网络流、二分图
1、 最短路问题(SPP-shortest path problem)
最短路径问题是图论中十分重要的最优化问题之一,它作为一个经常被用到的基本工具,可以解决生产实际中的许多问题,比如城市中的管道铺设,线路安排,工厂布局,设备更新等等。也可以用于解决其它的最优化问题。
若网络中的每条边都有一个数值(长度、成本、时间等),则找出两节点(通常是源节点和阱节点)之间总权和最小的路径就是最短路问题。最短路问题是网络理论解决的典型问题之一,可用来解决管路铺设、线路安装、厂区布局和设备更新等实际问题。最短路问题,我们通常归属为三类
单源最短路径问题
包括起点的最短路径问题,确定终点的最短路径问题(与确定起点的问题相反,该问题是已知终结结点,求最短路径的问题。在无向图中该问题与确定起点的问题完全相同,在有向图中该问题等同于把所有路径方向反转的确定起点的问题。)
确定起点终点的最短路径问题
即已知起点和终点,求两点之间的最短路径。
全局最短路径问题
求图中所有的最短路径。算法只要采用Floyed-Warshall算法(这是弗洛伊德利用动态规划(dynamic programming)的原理设计的一个高效算法)。
Floyed-Warshall 算法用来找出每对点之间的最短距离。它需要用邻接矩阵来储存边,这个算法通过考虑最佳子路径来得到最佳路径。
注意单独一条边的路径也不一定是最佳路径。
从任意一条单边路径开始。所有两点之间的距离是边的权,或者无穷大,如果两点之间没有边相连。
对于每一对顶点 u 和 v,看看是否存在一个顶点 w 使得从 u 到 w 再到 v 比己知的路径更短。如果是更新它。
不可思议的是,只要按排适当,就能得到结果。
最短路算法:
Dijkstra算法
Dijkstra复杂度是O(N^2),如果用binary heap优化可以达到O((E+N)logN),用fibonacci heap可以优化到O(NlogN+E)
其基本思想是采用贪心法,对于每个节点v[i],维护估计最短路长度最大值,每次取出一个使得该估计值最小的t,并采用与t相连的边对其余点的估计值进行更新,更新后不再考虑t。
在此过程中,估计值单调递减,所以可以得到确切的最短路。
Dijkstra 程序:
void Dijkstra(){
for(int i=1;i<=n;i++)
dis[i] = map[1][i];
int k;
for(int i=1;i<n;i++){
int tmin = maxint;
for(int j=1;j<=n;j++)
if( !used[j] && tmin > dis[j] ){
tmin = dis[j];
k = j;
}
used[k] = 1;
for(int j=1;j<=n;j++)
if( dis[k] + map[k][j] < dis[j] )
dis[j] = dis[k] + map[k][j];
}
printf("%d",dis[n]);
}
/* 求1到N的最短路,dis[i] 表示第i个点到第一个点的最短路 By Ping*/
还有其他算法:
Floyd-Warshall算法 Bellman-Ford算法 Johnson算法
实例:
某公司在六个城市 中有分公司,从
中有分公司,从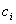 到
到 的直接航程票价记在下述矩阵的
的直接航程票价记在下述矩阵的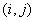 位置上。(
位置上。( 表示无直接航路),请帮助该公司设计一张城市
表示无直接航路),请帮助该公司设计一张城市 到其它城市间的票价最便宜的路线图。
到其它城市间的票价最便宜的路线图。
用矩阵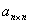 (为顶点个数)存放各边权的邻接矩阵,行向量
(为顶点个数)存放各边权的邻接矩阵,行向量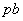 、
、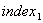 、
、 、
、 分别用来存放
分别用来存放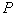 标号信息、标号顶点顺序、标号顶点索引、最短通路的值。其中分量
标号信息、标号顶点顺序、标号顶点索引、最短通路的值。其中分量
 ;
;
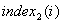 存放始点到第
存放始点到第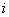 点最短通路中第顶点前一顶点的序号;
点最短通路中第顶点前一顶点的序号;
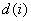 存放由始点到第点最短通路的值。
存放由始点到第点最短通路的值。
求第一个城市到其它城市的最短路径的Matlab程序如下:
clear;
clc;
M=10000;
a(1,:)=[0,50,M,40,25,10];
a(2,:)=[zeros(1,2),15,20,M,25];
a(3,:)=[zeros(1,3),10,20,M];
a(4,:)=[zeros(1,4),10,25];
a(5,:)=[zeros(1,5),55];
a(6,:)=zeros(1,6);
a=a+a';
pb(1:length(a))=0;pb(1)=1;index1=1;index2=ones(1,length(a));
d(1:length(a))=M;d(1)=0;temp=1;
while sum(pb)<length(a)
tb=find(pb==0);
d(tb)=min(d(tb),d(temp)+a(temp,tb));
tmpb=find(d(tb)==min(d(tb)));
temp=tb(tmpb(1));
pb(temp)=1;
index1=[index1,temp];
index=index1(find(d(index1)==d(temp)-a(temp,index1)));
if length(index)>=2
index=index(1);
end
index2(temp)=index;
end
d, index1, index2
运行结果为:
d =
0 35 45 35 25 10
index1 =
1 6 5 2 4 3
index2 =
1 6 5 6 1 1
即:

2、 网络流
(1)含义的理解
网络流(network flows)是图论中的一种理论与方法,研究网络上的一类最优化问题 。
(2)历史及应用
1955年 ,T.E. 哈里斯在研究铁路最大通量时首先提出在一个给定的网络上寻求两点间最大运输量的问题。1956年,L.R. 福特和 D.R. 富尔克森等人给出了解决这类问题的算法,从而建立了网络流理论。所谓网络或容量网络指的是一个连通的赋权有向图 D= (V、E、C) , 其中V 是该图的顶点集,E是有向边(即弧)集,C是弧上的容量。此外顶点集中包括一个起点和一个终点。网络上的流就是由起点流向终点的可行流,这是定义在网络上的非负函数,它一方面受到容量的限制,另一方面除去起点和终点以外,在所有中途点要求保持流入量和流出量是平衡的。
最大流理论是由福特和富尔克森于 1956 年创立的 ,他们指出最大流的流值等于最小割(截集)的容量这个重要的事实,并根据这一原理设计了用标号法求最大流的方法,后来又有人加以改进,使得求解最大流的方法更加丰富和完善 。最大流问题的研究密切了图论和运筹学,特别是与线性规划的联系,开辟了图论应用的新途径。
最大流问题仅注意网络流的流通能力,没有考虑流通的费用。实际上费用因素是很重要的。例如在交通运输问题中,往往要求在完成运输任务的前提下,寻求一个使总运输费用最省的运输方案,这就是最小费用流问题。如果只考虑单位货物的运输费用,那么这个问题就变成最短路问题。由此可见,最短路问题是最小费用流问题的基础。现已有一系列求最短路的成功方法。最小费用流(或最小费用最大流)问题 ,可以交替使用求解最大流和最短路两种方法,通过迭代得到解决。
目前网络流的理论和应用在不断发展,出现了具有增益的流、多终端流、多商品流以及网络流的分解与合成等新课题。网络流的应用已遍及通讯、运输、电力、工程规划、任务分派、设备更新以及计算机辅助设计等众多领域。
(3)算法的实现
Edmonds-Karp 算法
建立在Ford-Fulkerson方法上的增广路算法,与一般的Ford-Fulkerson算法不同的是,它用广度搜索实现对增广路的寻找. 以下为代码:
int n;
long int c[128][128];
long maxflow(int s, int t)
{
int p, q, queue[128], u, v, pre[128];
long int flow, aug;
flow = 0;
while(true)
{
memset(pre, -1, sizeof(pre));
for(queue[p = q = 0] = s; p <= q; p++)
{
u = queue[p];
for(v = 0; (v < n) && (pre[t]) < 0; v++)
{
if((c[u][v] > 0) && (pre[v] < 0))
{
pre[v] = u;
queue[++q] = v;
}
}
if(pre[t] >= 0)
{
break;
}
}
if(pre[t] < 0)
{
break;
}
aug = 0x7fff;
for(u = pre[v = t]; v != s; (v = u), (u=pre[u]))
{
if(c[u][v] < aug)
{
aug = c[u][v];
}
}
for(u = pre[v = t]; v != s; (v = u), (u = pre[u]))
{
c[u][v] -= aug;
c[v][u] += aug;
}
flow += aug;
}
return flow;
}
3、 二分图
(1) 含义的理解
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
2、相关应用
作为一种数学模型,二分用途是十分有用的,许多问题可以用它来刻划。例如“资源匹配”、“工作安排”、“人员择偶”等等。而这就需要考虑匹配问题。
匹配:给定一个二分图G,在G的一个子图M中,M的边集中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
而二分图最大匹配可以用最大流或者匈牙利算法。
最大流在网络流中有介绍。
匈牙利算法为:(资料:百度百科)
匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理(此定理使用于组合问题中。二部图G中的两部分顶点组成的集合分别为X, Y, Z,={X1, X2, X3,X4, .........,Xm} , Y={y1, y2, y3, y4 , .........,yn},G中有一组无公共点的边,一端恰好为组成X的点的充分必要条件是: X中的任意k个点至少与Y中的k个点相邻。(1≤k≤m))中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
算法的思路:
不停的找增广轨,并增加匹配的个数,增广轨顾名思义是指一条可以使匹配数变多的路径,在匹配问题中,增广轨的表现形式是一条"交错轨",也就是说这条由图的边组成的路径,它的第一条边是目前还没有参与匹配的,第二条边参与了匹配,第三条边没有..最后一条边没有参与匹配,并且始点和终点还没有被选择过.这样交错进行,显然他有奇数条边.那么对于这样一条路径,我们可以将第一条边改为已匹配,第二条边改为未匹配...以此类推.也就是将所有的边进行"反色",容易发现这样修改以后,匹配仍然是合法的,但是匹配数增加了一对.另外,单独的一条连接两个未匹配点的边显然也是交错轨.可以证明,当不能再找到增广轨时,就得到了一个最大匹配.这也就是匈牙利算法的思路.
资料来源:http://www.nocow.cn/index.php/%E5%8C%88%E7%89%99%E5%88%A9%E7%AE%97%E6%B3%95
求最大匹配的一种显而易见的算法是:先找出全部匹配,然后保留匹配数最多的。但是这个算法的复杂度为边数的指数级函数。因此,需要寻求一种更加高效的算法。
增广路的定义(也称增广轨或交错轨):若P是图G中一条连通两个未匹配顶点的路径,并且属M的边和不属M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。(M为一个匹配)
由增广路的定义可以推出下述三个结论:
1. P的路径长度必定为奇数,第一条边和最后一条边都不属于M。
2. P经过取反操作可以得到一个更大的匹配M’。
3. M为G的最大匹配当且仅当不存在相对于M的增广路径。
用增广路求最大匹配(称作匈牙利算法,匈牙利数学家Edmonds于1965年提出)
算法轮廓:
1. 置M为空
2. 找出一条增广路径P,通过取反操作获得更大的匹配M’代替M
3. 重复(2)操作直到找不出增广路径为止
程序清单:
const maxm=200; maxn=200;
var i,j,k,m,n:longint;
g:array[1..maxm,1..maxn]of boolean;
y:array[1..maxn]of boolean;
lk:array[1..maxn]of longint;
function find(x:longint):boolean;
var i:longint;
begin
for i:=1 to n do
if g[x,i] and (not y[i])
then begin
y[i]:=true;
if (lk[i]=0)or find(lk[i])
then begin
lk[i]:=x;
find:=true;
exit;
end;
end;
find:=false;
end;
#include<stdio.h>
#include<string.h>
bool g[201][201];
int n,m,ans;
bool b[201];
int link[201];
bool init()
{
int _x,_y;
memset(g,0,sizeof(g));
memset(link,0,sizeof(link));
ans=0;
if(scanf("%d%d",&n,&m)==EOF)return false;
for(int i=1;i<=n;i++)
{
scanf("%d",&_x);
for(int j=0;j<_x;j++)
{
scanf("%d",&_y);
g[ i ][_y]=true;
}
}
return true;
}
bool find(int a)
{
for(int i=1;i<=m;i++)
{
if(g[a][ i ]==1&&!b[ i ])
{
b[ i ]=true;
if(link[ i ]==0||find(link[ i ]))
{
link[ i ]=a;
return true;
}
}
}
return false;
}
int main()
{
while(init())
{
for(int i=1;i<=n;i++)
{
memset(b,0,sizeof(b));
if(find(i))ans++;
}
printf("%d\n",ans);
}
}
每次增广时间为O(E),最多进行O(V)次迭代,时间复杂度为O(VE).
五、动态规划、回溯搜索、分治算法、分支定界等计算机算法
一、动态规划
(http://www.nocow.cn/index.php/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92)
1、 含义的理解
动态规划(dynamic programming)是运筹学的一个分支,是求解多阶段决策问题的最优化方法。20世纪50年代初R. E. Bellman等人在研究多阶段决策过程(multistep decision process)的优化问题时,提出了著名的最优性原理(principle of optimality),把多阶段过程转化为一系列单阶段问题,逐个求解,创立了解决这类过程优化问题的新方法—动态规划。1957年出版了他的名著《Dynamic Programming》,这是该领域的第一本著作。
2、动态规划模型的分类:
以“时间”角度可分成: 离散型和连续型。
从信息确定与否可分成:确定型和随机型。
从目标函数的个数可分成:单目标型和多目标型
3、应用范围
动态规划问世以来,在经济管理、生产调度、工程技术和最优控制等方面得到了广泛的应用。例如最短路线、库存管理、资源分配、设备更新、排序、装载等问题,用动态规划方法比用其它方法求解更为方便。
虽然动态规划主要用于求解以时间划分阶段的动态过程的优化问题,但是一些与时间无关的静态规划(如线性规划、非线性规划),只要人为地引进时间因素,把它视为多阶段决策过程,也可以用动态规划方法方便地求解。
应指出,动态规划是求解某类问题的一种方法,是考察问题的一种途径,而不是一种特殊算法(如线性规划是一种算法)。因而,它不象线性规划那样有一个标准的数学表达式和明确定义的一组规则,而必须对具体问题进行具体分析处理。因此,在学习时,除了要对基本概念和方法正确理解外,应以丰富的想象力去建立模型,用创造性的技巧去求解。
4、动态规划的基本原理
多阶段决策过程最优化:
多阶段决策过程是指这样一类特殊的活动过程,他们可以按时间顺序分解成若干相互联系的阶段,在每个阶段都要做出决策,全部过程的决策是一个决策序列,所以多阶段决策问题也称为序贯决策问题
5、基本概念、基本方程和计算方法
(见资料《建模教程—动态规划》)
6、动态规划优缺点:
动态规划的优点:
可把一个N维优化问题化成N个一维优化问题求解。
DP方程中附加某些约束条件,可使求解更加容易。
求得最优解以后,可得所有子问题的最优解。
动态规划的缺点:
“一个”问题,“一个”模型,“一个”求解方法。且求解技巧要求比较高,没有统一处理方法。
状态变量维数不能太高,一般要求小于6
7、实例
机器可以在高、低两种负荷下生产。 台机器在高负荷下的年产量是
台机器在高负荷下的年产量是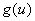 ,在低负荷下的年产量是
,在低负荷下的年产量是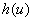 ,高、低负荷下机器的年损耗率分别是
,高、低负荷下机器的年损耗率分别是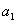 和
和 (
(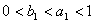 )。现有
)。现有 台机器,要安排一个
台机器,要安排一个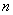 年的负荷分配计划,即 每年初决定多少台机器投入高、低负荷运行,使年的总产量最大。如果进一步假设
年的负荷分配计划,即 每年初决定多少台机器投入高、低负荷运行,使年的总产量最大。如果进一步假设 ,
,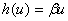 (
(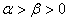 ),即高、低负荷下每台机器的年产量分别为
),即高、低负荷下每台机器的年产量分别为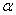 和
和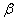 ,结果将有什么特点。
,结果将有什么特点。
解 年度为阶段变量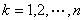 。状态
。状态 为第
为第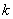 年初完好的机器数,决策
年初完好的机器数,决策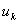 为第年投入高负荷运行的台数。当或不是整数时,将小数部分理解为一年中正常工作时间或投入高负荷运行时间的比例。
为第年投入高负荷运行的台数。当或不是整数时,将小数部分理解为一年中正常工作时间或投入高负荷运行时间的比例。
机器在高、低负荷下的年完好率分别记为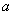 和
和 ,则
,则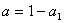 ,
,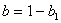 ,有
,有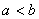 。因为第年投入低负荷运行的机器台数为
。因为第年投入低负荷运行的机器台数为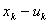 ,所以状态转移方程是
,所以状态转移方程是
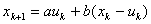 (1)
(1)
阶段指标 是第年的产量,有
是第年的产量,有
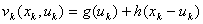 (2)
(2)
指标函数是阶段指标之和,最优值函数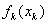 满足
满足
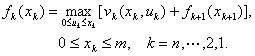 (3)
(3)
及自由终端条件
 (4)
(4)
当中的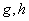 用较简单的函数表达式给出时,对于每个可以用解析方法求解极值问题。特别,若,,(3)中的
用较简单的函数表达式给出时,对于每个可以用解析方法求解极值问题。特别,若,,(3)中的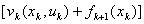 将是的线性函数,最大值点必在区间
将是的线性函数,最大值点必在区间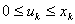 的左端点
的左端点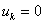 或右端点
或右端点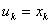 取得,即每年初将完好的机器全部投入低负荷或高负荷运行。
取得,即每年初将完好的机器全部投入低负荷或高负荷运行。
二、回溯搜索
1、含义的理解
回溯算法也叫试探法,它是一种系统地搜索问题的解的方法。回溯算法的基本思想是:从一条路往前走,能进则进,不能进则退回来,换一条路再试。用回溯算法解决问题的一般步骤为:
(1)定义一个解空间,它包含问题的解。
(2)利用适于搜索的方法组织解空间。
(3)利用深度优先法搜索解空间。
(4)利用限界函数避免移动到不可能产生解的子空间。
问题的解空间通常是在搜索问题的解的过程中动态产生的,这是回溯算法的一个重要特性。
例:
1、骑士游历为题、八皇后问题、地图着色问题
2、跳棋问题:
33个方格顶点摆放着32枚棋子,仅中央的顶点空着未摆放棋子。下棋的规则是任一棋子可以沿水平或成垂直方向跳过与其相邻的棋子,进入空着的顶点并吃掉被跳过的棋子。试设计一个算法找出一种下棋方法,使得最终棋盘上只剩下一个棋子在棋盘中央。
算法实现提示
利用回溯算法,每次找到一个可以走的棋子走动,并吃掉。若走到无子可走还是剩余多颗,则回溯,走下一颗可以走动的棋子。当吃掉31颗时说明只剩一颗,程序结束。
2、 中国象棋马行线问题
中国象棋半张棋盘如图1(a)所示。马自左下角往右上角跳。今规定只许往右跳,不许往左跳。比如
图4(a)中所示为一种跳行路线,并将所经路线打印出来。打印格式为:
0,0->2,1->3,3->1,4->3,5->2,7->4,8…
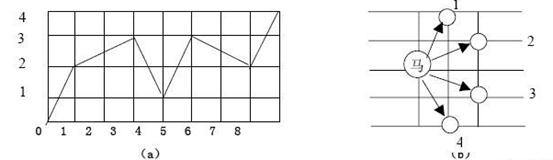
算法分析:
如图1(b),马最多有四个方向,若原来的横坐标为j、纵坐标为i,则四个方向的移动可表示为:
1: (i,j)→(i+2,j+1); (i<3,j<8) 2: (i,j)→(i+1,j+2); (i<4,j<7)
3: (i,j)→(i-1,j+2); (i>0,j<7) 4: (i,j)→(i-2,j+1); (i>1,j<8)
搜索策略:
S1:A[1]:=(0,0);
S2:从A[1]出发,按移动规则依次选定某个方向,如果达到的是(4,8)则转向S3,否则继续搜索下
一个到达的顶点;
S3:打印路径。
程序:
program exam2;
const x:array[1..4,1..2] of integer=((2,1),(1,2),(-1,2),(-2,1)); {四种移动规则}
var t:integer; {路径总数}
a:array[1..9,1..2] of integer; {路径}
procedure print(ii:integer); {打印}
var i:integer;
begin
inc(t); {路径总数}
for i:=1 to ii-1 do
write(a[i,1],’,’,a[i,2],’-->’);
writeln(’4,8’,t:5);
readln;
end;
procedure try(i:integer); {搜索}
var j:integer;
begin
for j:=1 to 4 do
if (a[i-1,1]+x[j,1]>=0) and (a[i-1,1]+x[j,1]=0) and (a[i-1,2]+x[j,2]<=8) then
begin
a[i,1]:=a[i-1,1]+x[j,1];
a[i,2]:=a[i-1,2]+x[j,2];
if (a[i,1]=4) and (a[i,2]=8) then print(i)
else try(i+1); {搜索下一步}
a[i,1]:=0;a[i,2]:=0
end;
end;
BEGIN {主程序}
try(2);
END.
三、分治算法
1、含义的理解(基本思想)
分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。
当我们求解某些问题时,由于这些问题要处理的数据相当多,或求解过程相当复杂,使得直接求解法在时间上相当长,或者根本无法直接求出。对于这类问题,我们往往先把它分解成几个子问题,找到求出这几个子问题的解法后,再找到合适的方法,把它们组合成求整个问题的解法。如果这些子问题还较大,难以解决,可以再把它们分成几个更小的子问题,以此类推,直至可以直接求出解为止。这就是分治策略的基本思想。
2、 分治法解题的一般步骤
(1) 分解,将要解决的问题划分成若干规模较小的同类问题;
(2)求解,当子问题划分得足够小时,用较简单的方法解决;
(3)合并,按原问题的要求,将子问题的解逐层合并构成原问题的解。
3、几种分治方法
1.二分法 dichotomy一种每次将原问题分解为两个子问题的分治法,是一分为二的哲学思想的应用。这种方法很常用,由此法产生了许多经典的算法和数据结构。
2.分解并在解决之前合并法 divide and marriage before conquest一种分治法的变形,其特点是将分解出的子问题在解决之前合并。
3.管道传输分治法 pipelined divide and conquer一种分治法的变形,它利用某种称为“管道”的数据结构在递归调用结束前将其中的某些结果返回。此方法经常用来减少算法的深度
4、举例
国际象棋棋盘上某个位置的一只马它是否可能只走63步正好走过除起点外的其他63个位置各一次?试设计一个分治算法
算法步骤:
1 :从左上角起,给棋盘编号(1,1),(1,2),。。。。。。(8,8),计为集合qp。tracks记录走过的每个点. (可以想象为坐标(x,y))
2:设起点为(1,1),记为 当前位置 cp,
3:搜索所有可走的下一步,根据“马行日”的走步规则,可行的点的坐标是x坐标加减1,y坐标加减2,
或是x加减2,y加减1; (例如起点(1,1),可计算出(1+1,1+2),(1+1,1-2),(1-1,1+2),(1-1,1-2),(1+2,1+1),(1+2,1-1),(1-2,1+1),(1-2,1-1) 共8个点), 如果没有搜到可行点,程序结束。
4:判断计算出的点是否在棋盘内,即是否在集合qp中;判断点是否已经走过,即是否在集合tracts中,不在才是合法的点。(在上面的举例起点(1,1),则合法的下一步是(2,3)和 (3,2))
5:将前一步的位置记录到集合tracts中,即tracts.add(cp);选择一个可行点,cp=所选择点的坐标。
6:如果tracts里的点个数等于63,退出程序,否则回到步骤3继续执行。
四、分支定界算法
1、含义的理解
与贪婪算法一样,这种方法也是用来为组合优化问题设计求解算法的,所不同的是它在问题的整个可能解空间搜索,所设计出来的算法虽其时间复杂度比贪婪算法高,但它的优点是与穷举法类似,都能保证求出问题的最佳解,而且这种方法不是盲目的穷举搜索,而是在搜索过程中通过限界,可以中途停止对某些不可能得到最优解的子空间进一步搜索(类似于人工智能中的剪枝),故它比穷举法效率更高。
2、 举例
背包问题
所谓的背包问题,可以描述如下:
一个小偷打劫一个保险箱,发现柜子里有N类不同大小与价值的物品,但小偷只有一个容积为M的背包来装东西,背包问题就是要找出一个小偷选择所偷物品的组合,以使偷走的物品总价值最大。
如有4件物品,容积分别为: 3 4 5 8
对应的价值分别为: 4 5 7 10
小偷背包的载重量为: 12
则取编号为1 2 3的物品,得到最大价值为16。
程序:
/* 0/1背包问题的分支定界法算法*/
#include<stdio.h>
#include<stdlib.h>
#define MAXNUM 100
struct node
{
int step ;
double price ;
double weight ;
double max,min ;
unsigned long po ;
};
typedef struct node DataType ;
struct SeqQueue
{
/* 顺序队列类型定义 */
int f,r ;
DataType q[MAXNUM];
}
;
typedef struct SeqQueue*PSeqQueue ;
PSeqQueue createEmptyQueue_seq(void)
{
PSeqQueue paqu ;
paqu=(PSeqQueue)malloc(sizeof(struct SeqQueue));
if(paqu==NULL)
printf("Out of space!! \n");
else
paqu->f=paqu->r=0 ;
return paqu ;
}
int isEmptyQueue_seq(PSeqQueue paqu)
{
return paqu->f==paqu->r ;
}
/* 在队列中插入一元素x */
void enQueue_seq(PSeqQueue paqu,DataType x)
{
if((paqu->r+1)%MAXNUM==paqu->f)
printf("Full queue.\n");
else
{
paqu->q[paqu->r]=x ;
paqu->r=(paqu->r+1)%MAXNUM ;
}
}
/* 删除队列头元素 */
void deQueue_seq(PSeqQueue paqu)
{
if(paqu->f==paqu->r)
printf("Empty Queue.\n");
else
paqu->f=(paqu->f+1)%MAXNUM ;
}
/* 对非空队列,求队列头部元素 */
DataType frontQueue_seq(PSeqQueue paqu)
{
return(paqu->q[paqu->f]);
}
/* 物品按性价比从新排序*/
void sort(int n,double p[],double w[])
{
int i,j ;
for(i=0;i<n-1;i++)
for(j=i;j<n-1;j++)
{
double a=p[j]/w[j];
double b=p[j+1]/w[j+1];
if(a!=b)
{
double temp=p[j];
p[j]=p[j+1];
p[j+1]=temp;
temp=w[j];
w[j]=w[j+1];
w[j+1]=temp;
}
}
}
/*求最大可能值*/
double up(int k,double m,int n,double p[],double w[])
{
int i=k;
double s=0;
while(i!=n&&w[i]!=m)
{
m-=w[i];
s+=p[i];
i++;
}
if(i!=n&&m>0)
{
s+=p[i]*m/w[i];
i++;
}
return s;
}
/* 求最小可能值*/
double down(int k,double m,int n,double p[],double w[])
{
int i=k ;
double s=0 ;
while(i<n&&w[i]!=m)
{
m-=w[i];
s+=p[i];
i++;
}
return s ;
}
/* 用队列实现分支定界算法*/
double solve(double m,int n,double p[],double w[],unsigned long*po)
{
double min ;
PSeqQueue q=createEmptyQueue_seq();
DataType x=
{
0,0,0,0,0,0
};
sort(n,p,w);
x.max=up(0,m,n,p,w);
x.min=min=down(0,m,n,p,w);
if(min==0)return-1 ;
enQueue_seq(q,x);
while(!isEmptyQueue_seq(q))
{
int step ;
DataType y ;
x=frontQueue_seq(q);
deQueue_seq(q);
if(x.max<min) continue;
step=x.step+1;
if(step==n+1) continue;
y.max=x.price+up(step,m-x.weight,n,p,w);
if(y.max>=min)
{
y.min=x.price+down(step,m-x.weight,n,p,w);
y.price=x.price ;
y.weight=x.weight ;
y.step=step ;
y.po=x.po<<1;
if(y.min>=min)
{
min=y.min;
if(step==n)*po=y.po;
}
enQueue_seq(q,y);
if(x.weight+w[step-1]<=m)
{
y.max=x.price+p[step-1]+
up(step,m-x.weight-w[step-1],n,p,w);
if(y.max>=min)
{
y.min=x.price+p[step-1]+down(step,m-x.weight-w[step-1],n,p,w);
y.price=x.price+p[step-1];
y.weight=x.weight+w[step-1];
y.step=step;
y.po=(x.po<<1)+1;
if(y.min>=min)
{
min=y.min;
if(step==n)*po=y.po;
}
enQueue_seq(q,y);
}
}
}
return min ;
}
#define n 4
double a=15 ;
double b[n]=
{
10,10,12,18
};
double c[n]=
{
2,4,6,9
};
int main()
{
int i ;
double d ;
unsigned long po ;
d=solve(a,n,b,c,&po);
if(d==-1)
printf("No solution!\n");
else
{
for(i=0;i<n;i++)
printf("x%d is %d\n",i+1,((po&(1!=(n-i-1)))!=0));
printf("The max weight is %f\n",d);
}
getchar();
return 0 ;
}
(程序已用VC++6.0运行过,存在错误,原程序已修正一部分但没修改过来。
error C2601: 'main' : local function definitions are illegal
fatal error C1004: unexpected end of file found执行 cl.exe 时出错.)
六、模拟退火法、神经网络、遗传算法
一、模拟退火法
1、含义的理解
模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小。
2、原理
根据Metropolis准则,粒子在温度T时趋于平衡的概率为e-ΔE/(kT),其中E为温度T时的内能,ΔE为其改变量,k为Boltzmann 常数。用固体退火模拟组合优化问题,将内能E模拟为目标函数值f,温度T演化成控制参数t,即得到解组合优化问题的模拟退火算法:由初始解i和控制参数初值t开始,对当前解重复“产生新解→计算目标函数差→接受或舍弃”的迭代,并逐步衰减t值,算法终止时的当前解即为所得近似最优解,这是基于蒙特卡罗迭代求解法的一种启发式随机搜索过程。退火过程由冷却进度表(Cooling Schedule)控制,包括控制参数的初值t及其衰减因子Δt、每个t值时的迭代次数L和停止条件S。
3、模拟退火的基本思想:
(1) 初始化:初始温度T(充分大),初始解状态S(是算法迭代的起点), 每个T值的迭代次数L
(2) 对k=1,……,L做第(3)至第6步:
(3) 产生新解S′
(4) 计算增量Δt′=C(S′)-C(S),其中C(S)为评价函数
(5) 若Δt′<0则接受S′作为新的当前解,否则以概率exp(-Δt′/T)接受S′作为新的当前解.
(6) 如果满足终止条件则输出当前解作为最优解,结束程序。
终止条件通常取为连续若干个新解都没有被接受时终止算法。
(7) T逐渐减少,且T->0,然后转第2步。
4、步骤:
模拟退火算法新解的产生和接受可分为如下四个步骤:第一步是由一个产生函数从当前解产生一个位于解空间的新解;为便于后续的计算和接受,减少算法耗时,通常选择由当前新解经过简单地变换即可产生新解的方法,如对构成新解的全部或部分元素进行置换、互换等,注意到产生新解的变换方法决定了当前新解的邻域结构,因而对冷却进度表的选取有一定的影响。第二步是计算与新解所对应的目标函数差。因为目标函数差仅由变换部分产生,所以目标函数差的计算最好按增量计算。事实表明,对大多数应用而言,这是计算目标函数差的最快方法。 第三步是判断新解是否被接受,判断的依据是一个接受准则,最常用的接受准则是Metropo1is准则: 若Δt′<0则接受S′作为新的当前解S,否则以概率exp(-Δt′/T)接受S′作为新的当前解S。第四步是当新解被确定接受时,用新解代替当前解,这只需将当前解中对应于产生新解时的变换部分予以实现,同时修正目标函数值即可。此时,当前解实现了一次迭代。可在此基础上开始下一轮试验。而当新解被判定为舍弃时,则在原当前解的基础上继续下一轮试验。模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率l 收敛于全局最优解的全局优化算法;模拟退火算法具有并行性。
5、例子(但只是java程序)
http://nopainnogain.javaeye.com/blog/852002
二、神经网络(参考资料:山东精品课程—神经网络模型)
1、含义的理解
人工神经网络就是模拟人思维的第二种方式。这是一个非线性动力学系统,其特色在于信息的分布式存储和并行协同处理。虽然单个神经元的结构极其简单,功能有限,但大量神经元构成的网络系统所能实现的行为却是极其丰富多彩的。
2、人工神经网络的工作原理
人工神经网络首先要以一定的学习准则进行学习,然后才能工作。现以人工神经网络对手写“A”、“B”两个字母的识别为例进行说明,规定当“A”输入网络时,应该输出“1”,而当输入为“B”时,输出为“0”。
所以网络学习的准则应该是:如果网络作出错误的的判决,则通过网络的学习,应使得网络减少下次犯同样错误的可能性。首先,给网络的各连接权值赋予(0,1)区间内的随机值,将“A”所对应的图象模式输入给网络,网络将输入模式加权求和、与门限比较、再进行非线性运算,得到网络的输出。在此情况下,网络输出为“1”和“0”的概率各为50%,也就是说是完全随机的。这时如果输出为“1”(结果正确),则使连接权值增大,以便使网络再次遇到“A”模式输入时,仍然能作出正确的判断。
如果输出为“0”(即结果错误),则把网络连接权值朝着减小综合输入加权值的方向调整,其目的在于使网络下次再遇到“A”模式输入时,减小犯同样错误的可能性。如此操作调整,当给网络轮番输入若干个手写字母“A”、“B”后,经过网络按以上学习方法进行若干次学习后,网络判断的正确率将大大提高。这说明网络对这两个模式的学习已经获得了成功,它已将这两个模式分布地记忆在网络的各个连接权值上。当网络再次遇到其中任何一个模式时,能够作出迅速、准确的判断和识别。一般说来,网络中所含的神经元个数越多,则它能记忆、识别的模式也就越多。
3、应用范围
人工神经网络的研究取得了重大进展,有关的理论和方法已经发展成一门界于物理学、数学、计算机科学和神经生物学之间的交叉学科。 它在模式识别,图像处理,智能控制,组合优化,金融预测与管理,通信,机器人以及专家系统等领域得到广泛的应用,提出了40多种神经网络模型,其中比较著名的有感知机,Hopfield网络,Boltzman机,自适应共振理论及反向传播网络(BP)等。
神经网络的研究内容相当广泛,反映了多学科交叉技术领域的特点。目前,主要的研究工作集中在以下几个方面:
(1)生物原型研究。从生理学、心理学、解剖学、脑科学、病理学等生物科学方面研究神经细胞、神经网络、神经系统的生物原型结构及其功能机理。
(2)建立理论模型。根据生物原型的研究,建立神经元、神经网络的理论模型。其中包括概念模型、知识模型、物理化学模型、数学模型等。
(3)网络模型与算法研究。在理论模型研究的基础上构作具体的神经网络模型,以实现计算机馍拟或准备制作硬件,包括网络学习算法的研究。这方面的工作也称为技术模型研究。
(4)人工神经网络应用系统。在网络模型与算法研究的基础上,利用人工神经网络组成实际的应用系统,例如,完成某种信号处理或模式识别的功能、构作专家系统、制成机器人等等。
三、遗传算法
1、含义的理解
遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法,是一种通过模拟自然进化过程搜索最优解的方法。它是由美国的J.Holland教授1975年首先提出,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。遗传算法的这些性质,已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。它是现代有关智能计算中的关键技术。
2、应用
由于遗传算法的整体搜索策略和优化搜索方法在计算是不依赖于梯度信息或其它辅助知识,而只需要影响搜索方向的目标函数和相应的适应度函数,所以遗传算法提供了一种求解复杂系统问题的通用框架,它不依赖于问题的具体领域,对问题的种类有很强的鲁棒性,所以广泛应用于许多科学,下面我们将介绍遗传算法的一些主要应用领域:
(1) 函数优化。
函数优化是遗传算法的经典应用领域,也是遗传算法进行性能评价的常用算例,许多人构造出了各种各样复杂形式的测试函数:连续函数和离散函数、凸函数和凹函数、低维函数和高维函数、单峰函数和多峰函数等。对于一些非线性、多模型、多目标的函数优化问题,用其它优化方法较难求解,而遗传算法可以方便的得到较好的结果。
(2)组合优化
随着问题规模的增大,组合优化问题的搜索空间也急剧增大,有时在目前的计算上用枚举法很难求出最优解。对这类复杂的问题,人们已经意识到应把主要精力放在寻求满意解上,而遗传算法是寻求这种满意解的最佳工具之一。实践证明,遗传算法对于组合优化中的NP问题非常有效。例如遗传算法已经在求解旅行商问题、 背包问题、装箱问题、图形划分问题等方面得到成功的应用。
此外,GA也在生产调度问题、自动控制、机器人学、图象处理、人工生命、遗传编码和机器学习等方面获得了广泛的运用。
3、一般算法
遗传算法是基于生物学的,理解或编程都不太难。下面是遗传算法的一般算法:
创建一个随机的初始状态
初始种群是从解中随机选择出来的,将这些解比喻为染色体或基因,该种群被称为第一代,这和符号人工智能系统的情况不一样,在那里问题的初始状态已经给定了。
评估适应度
对每一个解(染色体)指定一个适应度的值,根据问题求解的实际接近程度来指定(以便逼近求解问题的答案)。不要把这些“解”与问题的“答案”混为一谈,可以把它理解成为要得到答案,系统可能需要利用的那些特性。
繁殖(包括子代突变)
带有较高适应度值的那些染色体更可能产生后代(后代产生后也将发生突变)。后代是父母的产物,他们由来自父母的基因结合而成,这个过程被称为“杂交”。
下一代
如果新的一代包含一个解,能产生一个充分接近或等于期望答案的输出,那么问题就已经解决了。如果情况并非如此,新的一代将重复他们父母所进行的繁衍过程,一代一代演化下去,直到达到期望的解为止。
并行计算
非常容易将遗传算法用到并行计算和群集环境中。一种方法是直接把每个节点当成一个并行的种群看待。然后有机体根据不同的繁殖方法从一个节点迁移到另一个节点。另一种方法是“农场主/劳工”体系结构,指定一个节点为“农场主”节点,负责选择有机体和分派适应度的值,另外的节点作为“劳工”节点,负责重新组合、变异和适应度函数的评估。
4、 基本框架 遗传操作 求解算法的特点分析 术语说明 参考资料
(资料见互动百科:http://www.hudong.com/wiki/%E9%81%97%E4%BC%A0%E7%AE%97%E6%B3%95)