空间数据统计分析实习报告
(ArcGIS Geostatistical Analyst模块)
一、 实习内容简介
本次实习的主要内容是利用地统计分析模块,根据一个点要素层中已测定采样点、栅格层或者利用多边形质心,轻而易举地生成一个连续表面。这些采样点的值可以是海拔高度、地下水位的深度或者污染值的浓度等。当与ArcMap一起使用时,地统计分析模块提供了一整套创建表面的工具,这些表面能够用来可视化、分析及理解各种空间现象。
在本实习中,利用现有的测量站获得的臭氧浓度值,根据检测所有采样点之间的关系, 生成一个关于臭氧浓度值、预测标准差(不确定性)以及超出临界值的概率的连续表面,从 而对其它点的浓度值进行最佳预测。 在实习中主要练习通过对算法参数的调整,生成最佳的预测图,并将预测结果制成专题 地图,并初步理解空间统计分析的相关概念和算法。
本次实习主要有6个练习:
练习1:使用缺省参数创建一个表面;
练习2:数据检查;
练习3:制作臭氧浓度图;
练习4:模型比较;
练习5:制作超出某一临界值的臭氧概率图;
练习6:生成最终成果图。
二、实习成果及分析
练习1:使用缺省参数创建一个表面
本次练习中,主要是利用ArcMap中的地统计模块,通过创建臭氧浓度表面的过程,我发现使用缺省参数创建表面是一件很容易的事情。
我在ArcMap中添加了Ca_ozone_pts和ca_outline数据集,并将ca_outline图层中的颜色改为无色,并将地图保存。
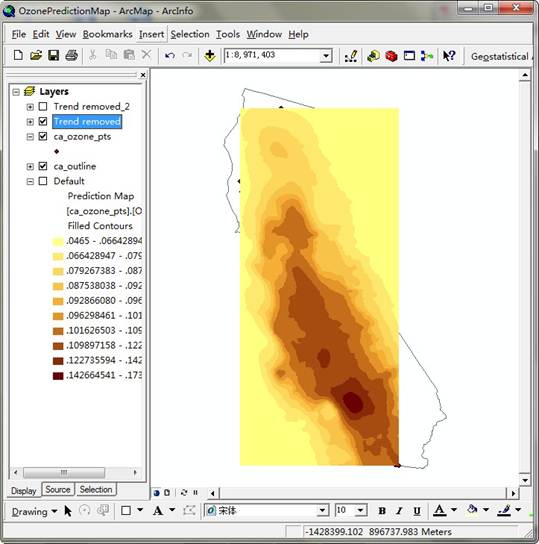
在本练习中,使用克里金算法,使用ArcGIS 默认的克里金算法参数创建臭氧浓度预测 图。使用克里金算法根据默认参数创建臭氧浓度预测图,从图中可以看出生成的预测图能够表达臭氧浓度分布,颜色越深的地方臭氧浓度越高,可以看出臭氧浓度高的地方非常集中,这应该是和城市的工业发展布局由紧密关系。同时可以看大预测图并没有很好的覆盖整个区域,因为预测图的范围是根据采样点的范围而定的,如果要契合地图边界,需要进行外延估计的计算。结果截图如下:
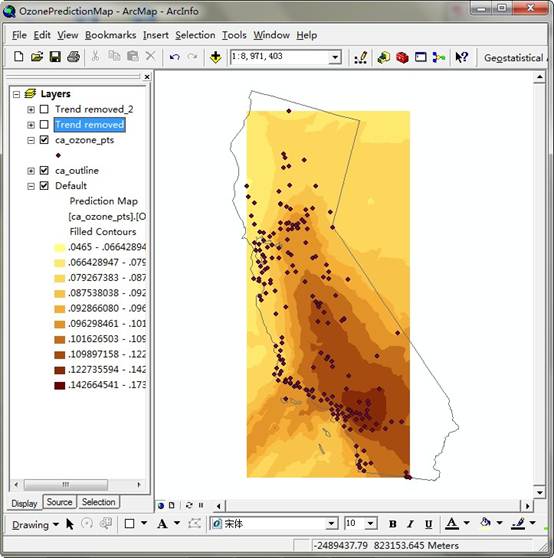
练习2:数据检查
数据检查的目的是为了找出数据中那些离群值并且发现数据中存在的趋势。
当数据服从正态分布时,用插值方法生成表面的效果最佳。如果数据是偏态分布的,即向一边倾斜,则可以选择数据变换使之服从正态分布。因此在创建表面之前了解数据的分布非常重要。Histogram工具描绘了数据属性的频率直方图,能够针对数据集的每一种属性检测其单变量分布。接下来,就是要检查图层ca_ozone_pts的臭氧分布情况。
臭氧属性的分布情况是用一个直方图来描述的,该直方图将浓度值分为10级,每一级别中的数量的相对比例(密度)通过每一个直方条柱子的高度来表示。通常,描述数据分布的重要特征包括中值、展布以及对称性。对于正态分布,有一个快速检验的方法:如果平均值与中值大致相等,就可以把它当作数据服从正态分布的证据之一。该直方图截图如下:
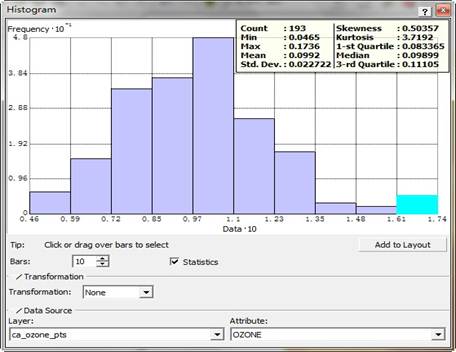
上面显示的直方图表面数据是单峰分布的,而且具有较好的对称性,接近于正态分布。直方图的右侧尾部表明,存在相对少量的具有较高臭氧浓度值的采样点。单击直方图臭氧值在0.162至0.175ppm之间的直方条,此范围的采样点在地图中被高亮显示。
正态QQ图提供了另外一种度量数据正态分布的方法,利用QQ图你可以将现有数据的分布与标准正态分布对比,如果数据点接近一条直线,则它们接近于服从正态分布。截图效果如下:
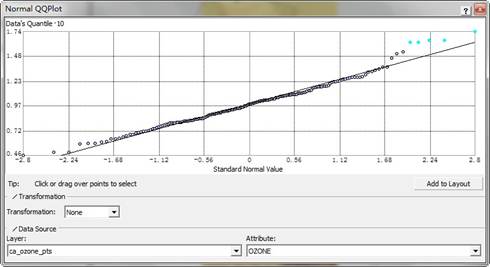
在一个普通的QQ图上,两种分布的对应点一一对应。对于两种相同类型的分布,QQ图应该是一条直线。因此通过绘制相对应的臭氧数据的分布点与标准正态分布的分布点,能够检查臭氧数据的正态分布情况。从上述正态QQ图可以看出,该图形非常接近于一条直线。而偏离直线的情况主要发生在臭氧浓度值较高时(因为这些偏离值在直方图中是高亮显示的,所以在这里它们也是被高亮显示的,如上图所示。)
如果在直方图中或在正态QQ图中,数据都没有显示出正态分布,那么就有必要在应用某种克里格插值之前对数据进行转换,使之服从正态分布。
对于趋势分析,只有数据中存在某种趋势时,才可能利用某些数学公式对表面的非随机(确定性的)成分进行表达。
例如,—个缓倾斜的山坡可以用一个平面来表达,而山谷则可以利用一个能够生成“u”字形的更加复杂的公式(一个二次多项式)来表示。数学公式有时或许能够生成想要的表面,但大多数时候,数学公式因为太过于平滑而不能精确地描述表面,因为没有哪个山坡是完完全全的平面,同样,也没有哪个山谷会是一个完美的“u” 形。如果趋势面不能精确地描绘实际需要的表面,可能想到将其移去,通过建立趋势剔除后的残差的模型来继续分析。在建立残差模型时,需要分析表面中的短程变异。这是理想平面或理想“u”型面所无法实现的内容。
Trend Analysis(趋势分析)工具能够找出在输入数据集中是否存在趋势。利用Trend Analysis工具得到的趋势分析图截图如下:
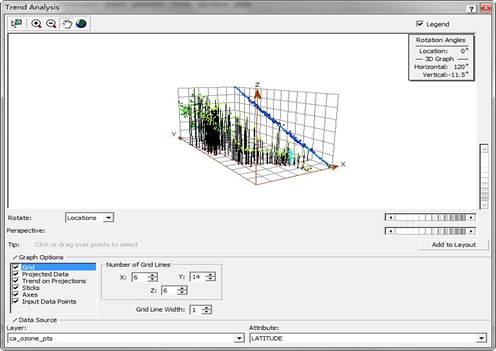
趋势分析图中的每一根竖棒代表了一个数据点的值(高度)和位置。这些点被投影到一个东西向的和一个南北向的正交平面上。通过投影点可以作出一条最佳拟合线(一个多项 式),并用它来模拟特定方向上存在的趋势。如果该线是平直的,则表明没有趋势存在。不过,如果注意看上图中的亮绿线,会发现这条线从较低的值开始,向东移动时逐渐增加直到变平稳。这表明该数据在东西向上显示出一个很强的趋势,而在南北向的趋势则较弱。
通过旋转,东西向趋势的形状可以看得更清楚。能看到投影后确实显示了一个倒置的“u”型。既然该趋势呈“U”形,所以可以选择一个二阶多项式对其全局趋势进行较好的模拟。尽管我把这个趋势显示在了东西向的投影平面上,但因为我把数据点旋转了30度,所以实际的趋势是北东-南西向。造成该趋势的一个可能的事实是,在沿海地区污染较轻,而在向内陆推进时,人口增多,污染增大。到了山区则人口又减少,污染也随之降低。
半变异函数/协方差函数云图能够检测已测样点间的空间自相关。空间自相关理论认为彼此之间距离越近的事物越相象。半变异函数/协方差函数云图能够对这种关系进行检测。为此,可以用y轴表示半变异函数值,即每一样点对间测量值之差的平方,而相应地用x轴表示每对样点之间的距离。半变异函数/协方差函数云图截图如下:
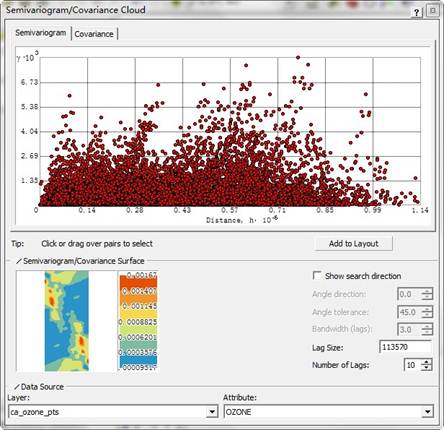
在半变异函数/协方差函数云图中,每个红点表示一对采样点。既然越近的点越相似,那么在半变异函数云图中邻近的点(在x轴的左边)应该有较小的半变异函数值(在y轴的下部)。随着样点对间距离的增加(在x轴上向右移动),半变异函数值也要相应增加(在y轴上向上移动)。然而,当到达一定的距离后,云图变平,这表明超出这个距离时,样点对之间不再具有相关关系了。
观察半变异函数图,如果某些靠得很近的数据点(在x轴上接近于零)具有一个异常的较高的半变异函数值(在y轴的上部)时,就应该仔细检杳这些样点对,看看是不是这些数据不准确。
在半变异函数图中选中的采样点将高亮显示在地图中,样点间通过直线相连,用以表示是一对采样点。有多种原因可以解释为什么洛杉矶地区的采样点数据值和其他地区相比差别很大。一种可能是洛杉矶地区的汽车比其它地区要多,这些汽车无疑将会造成更多的污染,从而在洛杉矶地区形成—个较高的臭氧累积。
除了前面讨论的全局趋势外,影响数据的还有方向效应。
这些方向效应的原因可能并不明了,但它们可以在统计上给予量化。这些方向效应将影响下一个练习中创建表面的精度。不过,—旦知道某种方向效应确实存在,则地统计分析模块提供的工具可以在创建表面的过程中对其给予解释。可以利用方向查找工具,在半变异函数云图中检测某个方向效应。
指针指向的方向决定了哪些样点对将会出现在半变异函数图中。如果指针是东西方向,那么只有那些处于彼此东西方向的点对才会在半变异函数图中显示,这就能够去除不感兴趣的那些点对从而来检查数据中的方向效应。
可以注意到,无论距离大小,大多数相连的样点对(代表了地图上的样点对)都会对应到洛杉矶地区的某一采样点上。对更多不同距离的点对的考虑结果表明,并非只有那些从洛杉矶地区延伸至海边的点对才具有很高的半变异函数值,许多从洛杉矶地区延伸到其它内陆地区的数据点对同样也有很高的半变异函数值。这是因为洛杉矶地区的臭氧值比加州其他任何地区都要高的多。
通过分析,现在已经知道数据集中没有离群值或错误的采样点,并且数据接近于正态分布,所以可以放心地进行表面插值。而且还知道了数据中存在某个趋势,所以在插值过程中通过某些调整,可以创建一个更加精确的表面。
练习3:制作臭氧浓度图
在练习2中,对数据进行检查时,你已经发现数据中存在一个全局趋势。利用Trend Analysis工具进行修正后,可知该趋势是南东-北西方向,并且可以用一个二阶多项式进行拟合。该趋势可以从数据中剔除,并可以用一个数学公式表达。一旦剔除全局趋势后,就可以对表面残差或表面的短程变异成分进行统计分析。在创建最终表面之前,该趋势还将自动添加回来以产生更有意义的结果。全局趋势剔除后所进行的分析将不再受其影响。而一旦将全局趋势再添加进来,就能够生成一个更加精确的表面。
因为在练习2的Trend Analysis对话框中已经检测到一条南西-北东方向的“u”型曲线,所以选择二阶多项式拟合是合适的。缺省情况下,地统计分析模块将绘制数据集中的全局趋势。从图中可以看出,南西-北东方向的变化最快,而北西-南东方向的变化则相对较缓慢,从而形成椭圆形。
趋势剔除必须合情合理。空气质量中的这种南西-北东向趋势可以归因于山区与沿海间的臭氧积累。山区的海拔高度以及在沿海地区占主导地位的风向导致山区与沿海地区的臭氧浓度值相对较低。人口密度过大导致在山区和沿海地区之间的污染程度较重。而北西-南东向的趋势变化较缓是由于洛杉矶附近的人口密度较高,而圣弗朗西斯科方向延伸时人口密度却降低。因此将这些趋势剔除是合理的。
在练习2的Semivariogram/Covsnance Cloud中,已经检测了已测点的所有的空间自相关。为此需要检查半变异函数,半变异函数显示了具有不同距离的样点对的方差。用半变异函数/协方差函数进行模拟的目的在于为其确定一个最佳拟合模型,该模型将穿过半变异函数图中的那些点。半变异函数是一个关于数据点的半变异值(或称变异性)与数据点间距离的函数。对它的图形表述可以得到一个数据点与其相邻数据点的空间相关关系图。在Semivariogram/Covariance Modeling对话框中你可以模拟数据集的空间关系。缺省情况下,将以球面半变异函数模型来计算其最佳参数值。首先,地统计分析模块要为半变异函数值的划分确定一个合适的步长大小。为了减少大量可能的合并而将数据点对分成不同的距离级,该距离级的大小就是步长。这种方法称为步长分组。步长分组后,半变异函数图中的点与练习2相比少了许多。一个好的步长大小也有助于揭示空间相关关系。该对话框用表面图和散点图的形式来显示半变异函数值与距离间的关系。然后拟合一个球面半变异函数模型(在各个方向都能拟合得很好)以及它们的相关参数值,这些参数通常被称为块金效应、自相关阈值及偏基台值 (结构方差)。 可以尝试用小的步长(距离)来拟合半变异函数。可以采取不同的步长分组值,通过改变步长的大小和步长组数目来重新拟合缺省球面模型。
方向效应会对半变异函数中的点以及将要拟合的模型产生影响。邻近的事物在某些方向上的相似性比其它方向的相似性更强。方向效应又被称为各向异性,地统计分析模块能够对它们进行解释。引起各向异性的因素可能是风、侵蚀、地质构造或者许多其它过程。
可以用Search Direction工具来分析某一方向上数据点的变异性,利用该工具可以在半变异函数图上检测方向效应,这并不影响输出的表面。
定义一个圆(或者椭圆),然后利用其内的点来预测那些未知点的值是一件简单的操作。 此外为避免某一特定方向上的偏差,可以把这个圆(或者椭圆)分为若干个小扇形,在各扇形内选取相同数目的点。利用Searching Neighborhood对话框,可以指定点的数目(最大为200)、半径(或者长/短轴)以及用来预测的圆(或者椭圆)中的扇形个数。
交叉验证可以知道模型对未知值的预测效果究竟怎样,对于所有的点,交叉验证按顺序每次省略一个点,再利用剩余的数据来对该点的值进行预测。然后在实测值与预测值之间进行比较,可以用计算后的统计数据来判断该模型用于生成地图是否合适。
除了可以对角平分线附近的散点进行可视化表达外,还有许多统计方法可用来评估模型的性能。交叉验证的目的就是帮你做出周全的决定,让你知道哪个模型提供的预测最精确。对于一个预测精确的模型,其均差应接近于0,其均方根误差和平均标准差应该尽可能地小(这在比较模型时很有用),并且其均方根标准误差应该接近于1。
效果截图如下:
练习4:模型比较
利用地统计分析模块,可以对两种成图结果进行对比。结合交叉验证统计表,可以判断哪个结果的预测更精确。
因为“Trend removed”层的均方根预测误差较小,其均方根标准预测误差更接近于1,而平均预测误差更接近于0,所以有理由相信“Trend removed”模型更有效。所以现在不再需要“Default”层了,可以把它移去。
练习5:制作超出某一临界值的臭氧概率图
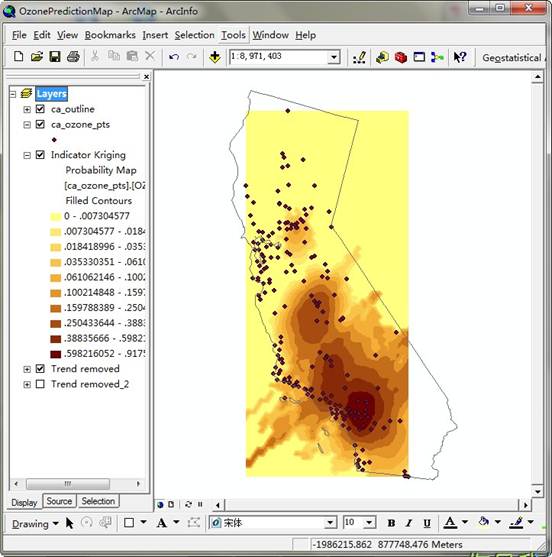
在本练习中使用指示克里金算法,创建臭氧超出临界值(0.12ppm)的概率图。 图中臭氧超出某一临界值的概率图在图中颜色越高的地方表示该地的臭氧浓度超出临界值的可能性越大,结合上面的预测可以看出臭氧浓度越高的部分超出的可能性越高。而指示克里金算法不要求数据集一定要服从某种特定分布。根据数据值是高于或者低于一个临界值来将数据值转换为一系列的0 和 l。如果利用 0.12ppm 作为临界值的话,任何低于它的数据值都将被赋予0,而高于它的值则被赋予 1。然后指示克里格法使用一个根据转换后的 0—1 数据集计算得到的半变异函数模型进行计算。效果截图如下:
练习6:生成最终成果图
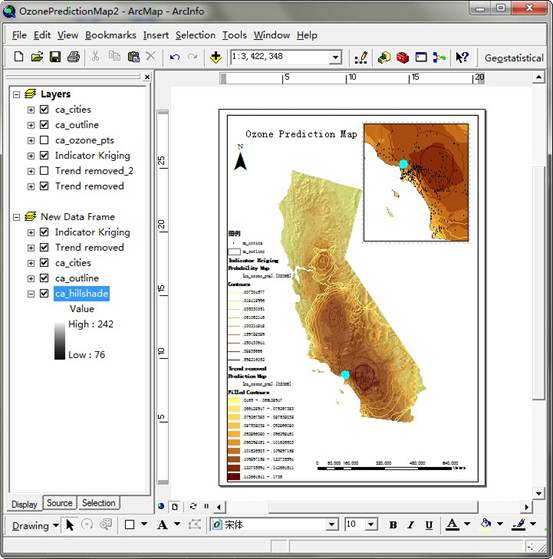
根据2.3 生成的臭氧超出临界值概率图,将其渲染方式添加一种为采用等值线的方式渲染,使边界更为清晰,同时将结果进行外延推导计算,并根据地区范围裁剪,生成该地区的 预测图,添加山体阴影图作为背景,添加相应图名、图例、比例尺、指北针等要素,生成一 副完整的地图。最终成果地图在图的右上角的区域将污染臭氧浓度超标地区放大显示,帮助读图人员更快的抓住重点。
我制作的地图截图如下:
三、实习体会
本次实习,我感觉学到了不少知识,主要学会了利用Trend Analysis工具可以看出数据显示出某种趋势,该趋势经过提取后,可以用一个南东-北西方向的二阶多项式对其进行最佳拟合。从半变异函数/协方差函数云图中可以发现洛杉矶地区距离很近的样点对,与其它地区那些相距较远的样点对一样具有较高的浓度值。半变异函数表面表明数据中存在空间自相关。
总之,通过本次实习,对于空间统计分析的算法和步骤有了初步的了解,对于课堂上教授的知 识,有了形象的了解。但是对于空间统计分析的算法和一些统计图所代表的具体的含义仍然 不是特别的清楚,需要在结合本次实习和课堂讲授的算法知识以及数理统计的知识进行进一 步学习。同时通过和前两次实习的对比,我也充分体会到空间统计分析更能够体现 GIS 作 为一门科学的必要性。对于学习GIS 的我而言,可以选择这个方面作为研究方向。
第二篇:统计分析与spss的应用实习报告
广东海洋大学
统计分析与spss的应用实习报告

姓名: 陈晓君
班级: 二班
学号: 201036614207
统计分析与spss的应用实习报告



注:请用A4纸书写,不够另附纸。 第 页,共 页