社会调查方法
第1讲 导论
本讲内容提要
u 科学研究的方法论基础
u 科学研究的基本流程
u 社会调查在科学研究中的地位
现代科学的起源
u 启蒙运动与科学革命
Ø 古代科学的特点:特权阶层把持;神秘主义传统
Ø 启蒙运动打破了长期以来宗教迷信对人类智慧的束缚,激起了人们对真理的渴望与追求
Ø 自然科学率先取得了革命性的突破
u 对真知(True Knowledge)的追求和科学研究方法
Ø 科学研究方法的分野:理性主义与经验主义(Rationalism vs. Empiricism)
科学研究方法论(1):理性主义
u 基本论点
Ø 真正的知识是高于感官的
Ø 要想获得真正的知识,必须超越感官的局限
ü 钟表的例子:我们的感官只能告诉我们表针的运动,但其背后的机械原理是无法通过感官来获得的
Ø 从一般到特殊:从最普适的公理出发,推广到具体的研究对象
Ø 科学的目的在于发现掌控自然界运转所隐含的、永恒的法则
u 真正知识的起点
Ø 笛卡尔(Descartes, 1596-1650):我思故我在
ü 几何学的例子:从几个基本公理推导出一个系统的学科
u 问题:
Ø 当不同的理论都可以合理地解释某种现象时,谁是对的?
? 科学研究方法论(2):经验主义
u 基本论点
Ø 所有的知识必须来源于经验
Ø 所有超出经验所及范围的东西都是无法检验的
Ø 从特殊到一般:从研究具体的现象中获取知识,并把它推广到经验所能达到了一般现象
u 经验主义与不可知论
Ø 休谟(Hume, 1711-1776)
ü 知识来源于客观世界事物之间联系的规律性(Regularity)
u 检验知识的唯一标准是它对现实世界的预测能力(Milton Friedman: Positive Economics)
u 问题:
Ø 理论本身的价值何在?
? 科学研究方法论(3):小结
u 培根(Bacon)的总结
Ø 理性主义好比蜘蛛:仅仅利用自身的分泌物结网
Ø 经验主义好比蚂蚁:不断地采集和堆积外物
Ø 第三条道路——蜜蜂:采集和消化外物,从中提炼出自己的产品
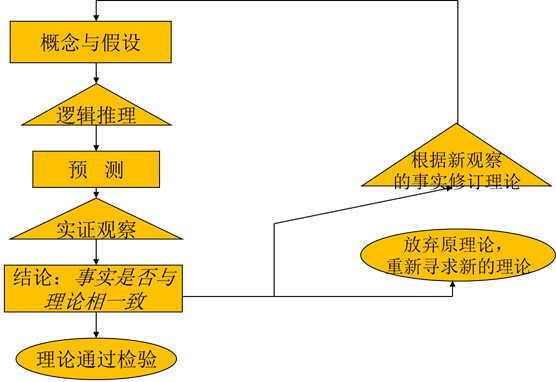
? 科学研究的基本流程
? 
? 社会调查在科学研究中的地位
u 收集经验材料、检验理论的重要工具
u 社会调查的应用
Ø 官方统计:人口、经济、社会变动指标
Ø 民意测验:政党支持率、选举预测
Ø 商业调查:收视率、产品满意度
Ø 学术研究:
ü (1)中国综合社会调查(CGSS)
ü (2)中国健康与营养调查(CHNS)
? CHNS简介(一)
u 网址:http://www.cpc.unc.edu/projects/china
u 调查背景:
p 20世纪80年代以来我国经济体制发生重大变化,工农业生产及服务行业普遍实现承包责任制,国家食物生产、供应及其价格体系发生了重大变化
p 人民经济收入逐步提高,其饮食结构、营养状况发生了变化
u 调查目的:
p 了解中国的社会经济变革对其人口的健康及营养状况的影响
p 研究各级政府的卫生、营养、计划生育等政策/项目的绩效
u 实施机构:
p 美国北卡大学人口中心
p 中国预防医学科学院营养与食品卫生研究所
? CHNS简介(二)
u 调查对象:
– 来自黑龙江(1997年起)、辽宁、山东、江苏、河南、湖北、湖南、广西、贵州九省的5000多个家庭户的17000个被调查对象
? CHNS简介(三)
u 调查设计与实施:
u 纵向跟踪调查,始于1989,初期的调查间隔为2年;
u 1993年起,调查中开始有新的样本加入;1997年,黑龙江被加入以替代辽宁;20##年,辽宁重返调查样本,此后,调查省数增加为9个
u 截至目前,调查已进行8期:1989、1991、1993、1997、20##、20##、20##、2011
u 调查内容:
– 家庭户问卷
– 健康服务
– 个人调查问卷
– 营养与体质测验
– 社区调查问卷
– 食品市场调查问卷
– 健康和计划生育资源
? CHNS的抽样设计
u 多阶段分层整群随机抽样(Multistage, stratified, random cluster sample)
p 抽样时先将每个省分为城市及县两层,每省选2个城市(一市为省会所在地,一市为经济收入一般的地级市),4个县(将所有县按1988年的经济情况分成上中下三层,在经济水平为上等及下等的层中各抽取1个县,在经济状况中等的层中抽取2个县)。
p 在抽到的每个市随机抽取2个市区居委会及2个郊区村;在抽到的每个县调查4个点,一个在县政府所在地居委会,再随机抽取3个乡,每个乡各抽取1个自然村。
p 这样,8个省共抽出190个调查点(32个居委会、30个郊区村、32个县城居委会和96个自然村),每点调查20户。
? CHNS的数据特征
u 样本构成:
? CHNS的研究成果
u 自1994年以来,CHNS已经成为研究中国公共卫生、经济、社会、人口问题的重要数据来源,发表论文一百多篇
p 健康资源、营养与健康状况、社会阶层差异及其与社会经济发展的关系
p 经济发展、贫困、贫富不平等与健康;家庭的劳动分工;教育的经济回报等
p 妇女地位、妇女教育程度与生育水平;地方计生政策差异与人口问题等
第2讲 社会研究基础
本讲内容提要
- 社会研究的特点
- 社会研究的理论基础
- 社会研究的基本元素
社会研究的特点
研究对象的特殊性
- 主体意识
- 选择偏误(Selection Bias)
- 研究本身对研究对象的干扰
- 霍桑效应:当被观察者知道自己成为被观察对象时而改变行为倾向的反应
- 研究手段的限制
- 研究伦理:1)知情选择;2)对研究对象无害
社会现象的复杂性
1因果关系复杂
- 多因多果;难以剥离
研究者的价值中立问题
价值中立vs.投入理解(Max Weber)
社会研究的理论基础(1)
概念(concept)
关于某个对象、某种特质或一定现象的抽象表述。
概念的功能
- 概念是主体间相互交流的基础
- 概念本身体现了一种对经验现象的认知方式
- 通过概念将经验知识进行分化和总结
- 概念是组成理论的核心元素
定义(definition)
概念性定义(conceptual definition)
- 通过其他概念来描述一个概念,是抽象的
- 概念性定义没有对错之分
操作性定义(operational definition)
- 关于如何确定一个概念所对应的经验现象的一系列程序
- 它将抽象概念与经验观察联系起来
社会研究的理论基础(2)
理论(theory)
理论不是什么?
- 理论不与实践相对立,它不是“试错(trial & error)”中的“错”
- 理论不等于哲学
- 理论不是价值判断,可以对它进行经验检验
理论的类型
- 特定的划分系统(ad hoc classificatory systoms)
- 分类系统(taxonomies)
- 概念结构(conceptual framework)
- 理论系统(theoretical systems)
理论与研究的关系
- 通过研究检验理论
- 通过研究获得理论
社会研究的基本元素(1)
研究问题
并不是所有问题都可以通过科学研究解决
- 无法进行经验检验的问题
- 主观偏好、信仰、价值、品味等问题
对研究问题的陈述必须明确、具体
- 例:a. 家庭背景会影响个人取得成功吗?
b. 父母的受教育程度会不会影响子女接受高等教育的机会?
社会研究的基本元素(2)
- 分析单位(unit of analysis)
- 在提出问题时需要严格界定它所对应的分析单位
- 常见分析单位:个人、家庭、群体/组织、社会
- 对分析单位的选择决定了相应的研究设计、研究操作以及研究结果的应用范围
- 针对不同分析单位,经常共用一些相似的概念,但其含义却大不相同
- 层次谬误:由于分析单位不明确、分析层次混乱所导致的错误
- 合成谬误/生态谬误(ecological fallacy):将集合层次上的关系/结论应用到个体层次上所导致的层次谬误
- 个体谬误(individualistic fallacy):将个体层次上的关系/结论应用到集合层次上所导致的层次谬误
生态谬误的例子:各国的基尼系数与预期寿命 (N = 130, r = -0.639)
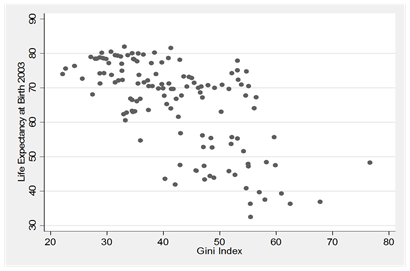
社会研究的基本元素(3)
变量
- 研究问题由概念组成,在研究过程中需要将概念转化为变量
- 自变量、因变量和控制变量
- 自变量与因变量的划分是相对于研究本身的
- 可能存在多个自变量/因变量
- 变量之间的关系
- 关系的方向
- 关系的强弱
社会研究的基本元素(3)
- 假设(hypothesis)
- 假设是对研究问题的尝试性回答,它通过指定变量之间的关系来表示
- 假设的来源
- 理论推导
- 经验观察
- 文献资料
- 对研究假设的四个基本要求
- 假设必须明确(clear)
- 假设必须价值中立(value-free)
- 假设必须具体(specific)
- 假设必须可通过既有方法检验(tested with available methods)
第3讲 实验设计
内容提要
u 研究设计(Research Design)
u 实验设计(Experimental Design)
Ø 一个例子:期望对行为的影响
Ø 经典实验设计
Ø 实验的效度
Ø 其他实验设计
? 研究设计
u 研究设计的意义
Ø “Good design beats statisticians.”
u 研究设计的内容
Ø 问题的提出
Ø 问题的界定:概念、定义与假设
Ø 经验材料的收集:研究对象、时间、地点、方式
Ø 分析计划
u 研究设计的核心问题:因果推断(Causal Inferences)
Ø 研究的目的:探索、描述、解释
Ø 判断因果关系的三个标准
p 相关/共变(Covariation)
p 非虚假相关(Nonspuriousness)
p 时间的先后(Time order)
u 参考书目
Ø Campbell, D. T., & Stanley, J. C. 1963. Experimental and Quasi-Experimental Designs for Research. Chicago: Rand McNally (Houghton-Mifflin).
? 实验设计:期望与行为的例子
u 参考文献
Ø Rosenthal R., and L. Jacobson. 1968. Pygmalion in the Classroom. New York: Holt, Rinehart & Winston.
u 研究问题
Ø 他人期望对个人行为的影响
p 伯纳德·肖(Bernard Shaw)的名剧:Pygmalion
p 对动物的实验研究
u 研究设计
Ø 一所公立小学(Oak School)中的学生
Ø 对学生进行随机分组,制造教师的不同“期望”
Ø 比较前后智商测试成绩的变化
u 研究结果
Ø 期望确实影响行为
? 经典实验设计
u 控制组前测-后测实验设计(The Pretest-Posttest Control Group Design)
Ø 实验组: R 01 X 02
控制组: R 03 04
p 随机分组(Randomization / Random Assignment)
p 实验前后对因变量进行两次测量
p 实验变量的效果:(02 - 01) - (04 - 03)
u 实验设计与因果推断
Ø 对照(comparison)
Ø 操纵(manipulation)
Ø 控制(control)
? 实验的效度
u 内部效度(Internal validity)
Ø 研究中所观测到的因变量的变化是否确实由自变量的变化所导致
Ø 影响内部效度的可能因素:
p 选择(Selection)
p 历史(History)
p 成长(Maturation)
p 测量工具(Instrument)
p 测验的影响(Testing)
p 实验样本的流失(Experimental Mortality)
p 向均值回归(Regression to the mean)
p 选择性交互效应(Interaction with selection)
u 外部效度(External validity)
Ø 研究中所观测到的因果关系是否可以 推广到更广泛的群体中去
Ø 影响外部效度的可能因素
p 样本的代表性(Representativeness)
p 研究过程所导致的反应性行为(Reactive Arrangement)
? 霍桑效应(Hawthorne Effect )
? 其他常见实验设计(1)
u 所罗门四组实验设计(The Solomon Four-Group Design)
Ø 实验组: R 01 X 02
控制组: R 03 04
实验组: R X 05
控制组: R 06
Ø 例子:政论电视节目对政治态度的影响
u 控制组后测实验设计(The Posttest Only Control Group Design)
Ø 实验组: R X 01
控制组: R 02
Ø 例子:申请者性别对大学入学申请结果的影响(Walster et al. 1971)
? 其他常见实验设计(2)
u 析因设计(Factorial Designs)
Ø 同时需要研究两个或多个自变量的情况
Ø 例:组织规模和组织结构对成员士气的影响

? 对实验设计的小结
u 优点:具有很强的内部效度
u 随机分组确保了对其他变量的控制;
u 对实验变量的操纵可以确定因果关系的方向
u 缺点:外部效度难以保证
Ø 实验环境是人为的,有别于现实生活;
Ø 研究对象的选取往往是非随机的,实验结论的外推性存在局限
第4讲 类实验与其他研究设计
内容提要
- 变量关系类型与研究设计
- 类实验设计(Quasi-Experimental Designs)
- 非实验研究设计(Nonexperimental Designs)
- 小结
变量关系类型与研究设计
变量关系类型
- 刺激-反应类型(stimulus-response type)
- 自变量与因变量之间的时间间隔相对较短
- 自变量通常具体而明确,可以从其他变量中分割出来
- 可以对两个相似的组进行对比
- 事件发生的序列相对清楚,因果关系的方向很明确
- 特征-分布类型(property-disposition type)
- 自变量与因变量之间的时间间隔可以很长
- 社会科学中的特征变量往往很宽泛,包括多种因素
- 难以找到两个相似的对照组,前测-后测也不现实
- 较难确定事件发生的时序
- 前者更适合应用纯实验设计,对后者而言实验设计往往是不现实的
类实验法
类实验法(quasi-experiment)主要是指在经验研究中利用现实观测的数据来推断因果关系的一种方法,有时也被称为观测研究(observational studies)。
- 它具有传统的实验研究的一些特点,如多个相似组别的比较、对结果变量的多次测量等;
- 但是,它往往缺乏实验研究所要求的随机化分组,研究者一般也无法操纵干预变量的发生。
类实验设计(1)
- 对照组设计(The Contrasted Groups Design)
- 01
- 02
- 03
- .
- .
- .
- 0k
- 实例:美国vs.加拿大的枪支管理研究(来源:Sloan et al. 1988. “Handgun regulations, crime, assaults, and homicide: A tale of two cities.” The New England Journal of Medicine 10: 1256-1262)
表1:西雅图和温哥华的主要社会特征
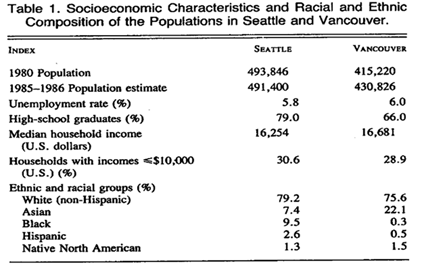
表2:西雅图和温哥华的各类犯罪情况

类实验设计(2)
时间序列设计(Time-Series Design)
01 02 03 04 05 X 06 07 08 09 010
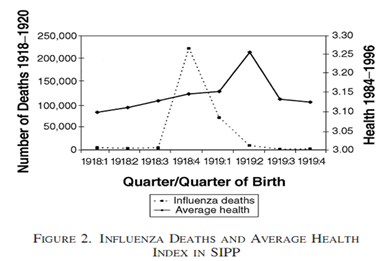
- 实例1:美国1918-19年大流感健康后果的研究
- 实例2:美国康涅狄格州致命车祸数量的研究(来源:Campbell, Donald T. & H. Laurence Ross. 1968. “The Connecticut Crackdown on Speeding: Time-Series Data in Quasi-Experimental Analysis.” Law and Society Review 3(1): 33-53.)
- 控制组时间序列设计(Controlled Time-Series Design)
- EG : 01 02 03 04 05 X 06 07 08 09 010
- CG : 01 02 03 04 05 06 07 08 09 010
- 实例:美国康涅狄格州致命车祸数量的研究
图1(来源:Almond&Mazumder 2005)
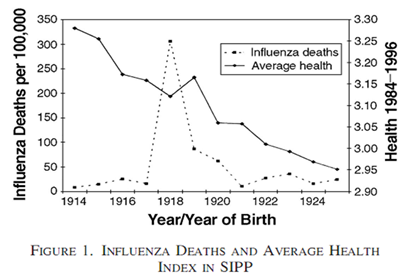
- 图2(来源:Almond&Mazumder 2005)
- 图3(来源:Campbell&Ross 1968)
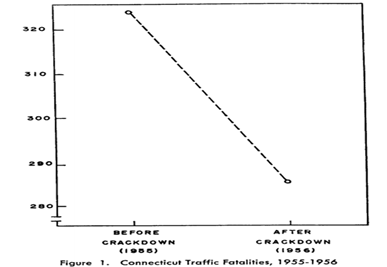
图4(来源:Campbell&Ross 1968)

- 图5(来源:Campbell&Ross 1968)

非实验设计
- 单一时点个案研究(The One Shot Case Study)
- X 01
- 只在实验后对因变量进行一次测量
- 实例:对美国Head Start项目的评估
- 单组前测/后测设计(One Group Pretest-Posttest Design)
- 01 X 02
- 在实验前后对因变量进行两次测量
- 实验变量的效果: 02 – 01
- 实例:对中国计划生育政策效果的评估
- 小结:实验设计与类实验设计的比较
第5讲 社会调查导论
内容提要
- 什么是社会调查
- 社会调查发展简史
- 社会调查的一般流程
- 社会调查的类型
什么是社会调查?
- 调查(survey)是一种系统地收集研究对象信息的方法,并通过这些信息对研究对象所属总体的特征进行定量化的描述。
- 信息主要通过对调查对象提问问题的方式来收集
- 提问和记录答案可以由调查员来完成,也可以由调查对象进行自填
- 一般只调查研究总体中的一小部分对象,即一个样本
社会调查发展简史
- 调查目的的变化
- 古代的行政统计
- 对社会问题的早期研究
- 例:查理斯?布思(Charles Booth)对伦敦工人阶级生活状况的研究
- 民意和商业研究的需要
标准化问卷的发展
- 市场调查和民意测验关注大量的观点与态度等主观问题
- 与客观问题相比,这些问题很容易受到措辞(question wording)的干扰
- 心理计量学的贡献——量表(scale)的编制与使用
社会调查发展简史(续)
抽样方法的发展
- 《文学摘要》(Literacy Digest)和盖洛普(Gallop)对1936年美国总统大选的预测
- 抽样理论的发展和完善
- 试图调查每一个对象vs.调查“典型”(typical)对象
- 概率抽样理论
- 数据收集方法的发展
- 邮件调查和面对面访问
- 电话调查在商业领域的广泛应用
- 计算机辅助调查技术的发展
- 数据分析技术的发展
- 控制变量和多元分析技术(Paul Lazarsfeld)
- 从连续变量到分类变量
- 对复杂抽样调查数据的分析
1936年美国总统大选

社会调查的一般流程
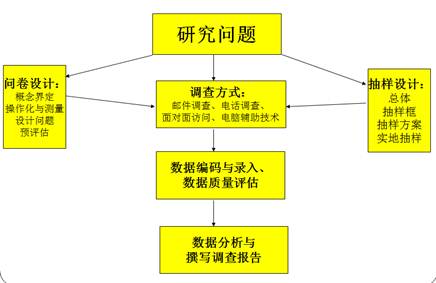
24. 社会调查的类型(1)
普查(census)
1. 对研究总体的每个对象都进行调查
抽样调查(sampling survey)
2. 只调查研究总体中的一部分对象
1. 概率抽样
2. 非概率抽样
普查与抽样调查的联系
3. 抽样调查可以作为对普查的补充和辅助
4. 抽样调查可以用来对普查进行评估和改进
5. 对普查数据进行抽样
6. 普查数据可以用作设计抽样调查的辅助信息
7. 联合使用普查和抽样调查数据进行研究
- 关于普查、抽样调查以及官方登记资料的比较
(Kish 1979) - 社会调查的类型(2)
横截面调查(cross-sectional survey)
- 只在某个时点对调查对象进行一次调查
纵向调查(longitudinal survey)
- 在多个时点对研究总体(的样本)进行多次调查
- 重复截面调查(repeated cross-sectional survey)
- 跟踪调查(panel survey)
- 混合调查(mixed survey)
比较
- 纵向调查的优点:1)提高调查质量;2)时间序列数据可以用来估计变化趋势;3)多次重复样本的平均或加总能更精确地估计总体
- 横截面调查的优点:1)成本低,易操作;2)时效性较好
社会调查的优缺点
- 优点:
- 程序的标准化具有可复制性(Replicability)
- 以统计理论为基础对较大规模群体进行研究
缺点:
- 所收集的信息往往不够具体、丰富,无法了解被访者的具体生活情境
- 标准化的程式对于一些内部差异很大的群体不一定适用
- 较易受到人为因素的干扰
第6讲 抽样理论
? 抽样的基本原理(1)
u 基本概念
Ø 总体(Population)----- 理论上具有研究者所考察特征的全体元素的集合
p 界定原则:(1)内容; (2)单位; (3)空间;(4)时间
Ø 抽样框(Sampling frame)-----关于总体中所有元素的列表/名册,或是指定总体中所有元素的一系列程序
p 完美的抽样框:总体的每个元素出现并且仅出现一次
p 问题:1)不完整(incomplete);
2)有错误(ineligible);
3)有重复(duplicate);
4)群组现象(cluster)
Ø 样本(Sample)-----从总体的元素中按照一定原则被选中的一部分元素的集合
? 抽样的基本原理(2)
u 总体参数
Ø 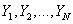 元素:
元素:
Ø 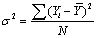
 均值:
均值:
Ø 方差:
u 样本统计量
Ø 元素:
Ø 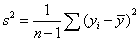 均值:
均值:
Ø 方差:
抽样的基本原理(3)
u 概率抽样(Probability sampling)
Ø 严格按照概率的原则来抽取样本,如使用随机数表
Ø 总体中每个单位被选中的概率是已知的并且非零
Ø 每个单位被选中的概率不一定要相等
? 抽样的基本原理(4)
u 非概率抽样(Non-probability sampling)
Ø 便利抽样(Convenience sampling):依据方便的原则抽取样本,如“偶遇法”、“街头拦人法”等
Ø 目的性抽样(Purposive sampling):由研究者根据知识和经验主观确定的样本
Ø 配额抽样(Quota sampling):将总体中的所有单位按照一定标准划分成不同类别,分别在每个类别内任意抽取指定数量的样本
Ø 滚雪球抽样(Snowball sampling):先随机选择一定数量的被访者并对其实施访问,再请他们提供另外一些属于所研究目标总体的调查对象,根据所形成的线索选择此后的调查对象
? The Republican bias in Gallop Polls
? 抽样的基本原理(5)
u 简单随机样本(Simple Random Sampling)
Ø 严格按照随机原则从N个总体单位中抽取n个单位作为样本(N > n),在抽样过程中确保每个单位都有同等的机会入选样本,而且每个单位的抽取都是相互独立的
Ø 理论意义大于现实意义
Ø 有放回的抽样vs.无放回的抽样
Ø 有放回的抽样(Sampling with replacement)
p 将已经被抽中的单位放回抽样框,参与抽取下一个单位
Ø 无放回的抽样(Sampling without replacement)
p 已经被抽中的单位不再参与抽取下一个单位
? 抽样的基本原理(6)
u 系统抽样(Systematic sampling)
Ø 将N个总体单位按一定顺序排列,然后先随机抽取一个单位作为起始单位,再按某种确定的规则抽取其他n-1个样本单位。以等距抽样最为常见。
Ø 系统抽样不等同于随机抽样:当总体单位的排列存在某种周期性时,系统抽样可能会出现很大的偏差
? 抽样误差与非抽样误差
u 抽样误差(Sampling error)
Ø 由于样本范围与总体范围的差异而引起的误差,它是一种随机误差
Ø 在概率抽样中,抽样误差的大小是可以估算的
Ø 简单随机样本的抽样误差:
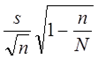
u 非抽样误差(Non-Sampling error)
Ø 在调查过程中,由于其他原因所导致的误差,一般难以识别和测量
p 抽样框误差(Coverage error)
p 无应答误差(Non-response error)
p 测量误差(Measurement error)
? 常见抽样设计(1)
u 分层抽样(Stratified sampling)
Ø 先将N个总体单位按某种已知特征划分为若干个子总体,称为层,然后再在每个层中分别独立的进行概率抽样,最后将抽出的子样本合并起来构成总体的样本
Ø 样本量在各层之间的分配
p 等比例分配(Proportional allocation)
p 不等比例分配(Disproportional allocation)
l 最优分配(Optimum allocation):综合考虑层内样本差异性和单位调查成本,追求单位成本的最大效率
Ø 为什么要分层?
p 确保某些子总体在样本中的代表性
p 提高样本精度,即在样本规模不变的条件下降低抽样误差
Ø 分层的主要原则:层内同质,层间异质
? 等比例分层抽样示例:
从1000名大学教师中抽取一个100人的样本
? 不等比例分层抽样示例:
从8000名员工中抽取一个480人的样本
? 常见抽样设计(2)
u 整群抽样(Cluster sampling)
Ø 先将总体划分为若干个群(初级抽样单位),然后以一定方式从总体中抽取一部分群,并由中选群中的所有个体单位构成总体的样本
Ø 为什么进行整群抽样?
p 降低调查的成本
p 当抽样框存在群组问题时,也采用整群抽样
Ø 群的划分:群内异质、群间同质
Ø 群的规模
p 规模相等的群
p 规模不等的群:
l 对群进行重新划分
l 按照群的大小分层
l PPS 抽样
? 常见抽样设计(3)
u 多阶抽样(Multistage sampling)
Ø 按总体中个体单位的层次关系,将抽样过程分为若干阶段进行的抽样方式
Ø 初级抽样单位(Primary sampling unit, PSU)
p 在多阶抽样中,最初从总体中抽出的群
Ø 次级抽样单位(Secondary sampling unit, SSU)
p 从PSU中进一步抽取的群
Ø 常见抽样设计(4)
u PPS抽样(Probability proportional to size)
Ø 概率与规模成比例,即赋予规模不等的群与其规模成比例的入样概率
Ø 既保证了各个体单位被抽中的概率相等,又保证了每个PSU内子样本的规模相等
? PPS抽样示例:
从9个班级的315名学生中选取21名学生
? 样本规模的确定
u 决定所需样本规模的因素
Ø 抽样精度:所能容忍的最大抽样误差
Ø 总体各单位之间的异质性程度:总体方差/标准差
Ø 成本以及可操作性
u 简单随机抽样情况下样本规模的计算
Ø 计算公式:

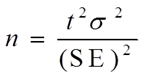
第7讲 抽样案例
? 按PPS抽样抽取调查点
u PPS抽样(Probability proportional to size)
Ø 概率与规模成比例,即赋予规模不等的群与其规模成比例的入样概率
Ø 既保证了各个体单位被抽中的概率相等,又保证了每个PSU内子样本的规模相等
u 一般步骤
Ø 获取抽样框,确定各级抽样单位及样本规模
Ø 对PSU进行分层,确定层内计划样本规模
Ø 在层内按照PPS原则抽取PSU
Ø 在PSU内按照PPS原则抽取次级抽样单位(SSU)
Ø ……
Ø 在选定的调查点内按照住户名单抽取住户和被访者
? 按照PPS方法抽取PSU
(从10个PSU中抽取4个,k=1935851/4=483963)
? 在调查点内抽取住户
u 一般步骤
Ø 获取调查点中所有住户的名单
p 户籍登记资料或其他既有名册
p 列举(Enumeration)
Ø 从住户名单中抽取指定数量的住户
p 随机抽样或系统抽样
u 如何列举?
Ø 绘制调查点地图,标出所有的建筑
p 确认包括了所有的建筑以及调查员能够定位这些建筑
Ø 创建一个完整的住户名单
p 确认包括了所有可能的住户
? 在户内抽取被访者
u 一般步骤
Ø 获取户内成员登记表
p 确认包括所有成员
p 标记出符合调查条件的成员
p 对符合条件的成员进行编号
Ø 根据随机数表从符合条件的成员中抽取一名或多名成员作为被访者
? 案例1:CGSS2003的抽样设计
u 目标总体:中国大陆地区(除西藏外)的18-69岁的居民
u 抽样框:各地户籍登记资料
u 样本规模:10,000(其中6000城镇居民,4000农村居民;实际只调查了城镇部分,最终样本量为5,894)
u 抽样步骤
Ø 按照居住地类型进行分层
p 将全国县级单位(PSU)划分为5个层,分别为:(1)三大直辖市市辖区;(2)省会城市市辖区;(3)东部地区区县;(4)中部地区区县;(5)西部地区区县
Ø 按照PPS原则分别在各层抽取PSU,共抽取125个PSU
Ø 在每个中选的PSU内,按照PPS原则抽取4个乡镇/街道(SSU)
Ø 在每个中选的SSU内,按照PPS原则抽取2个村/居委会
Ø 在每个村/居委会内,按照系统抽样原则抽取10个住户
Ø 在每户内,按照随机抽样原则抽取一名符合条件的被访者
? CGSS2003入户抽样(1)
? CGSS2003入户抽样(2)
? CGSS2003入户抽样(3)
? CGSS2003入户抽样(4)
? 案例2:CHARLS2011的抽样设计
u 目标总体:中国大陆28省年龄在45岁以上的家庭户居民
u 抽样设计:四阶段分层整群抽样
u 样本规模:150个区县、450个村/居委会中的约1万户家庭,最终实际完成样本量为10,257个家庭
u 抽样步骤
Ø 按照地区、城乡、人均GDP分层抽取共150个区县单位
Ø 在每个区县内,按照PPS原则抽取3个村/居委会
Ø 在每个村居内,利用GIS软件进行完全列举(enumeration),然后根据列举名单随机抽取80个住户(目标调查24户)
Ø 对每个住户,先筛查是否存在符合条件的被访者,如是从中选取一名被访者,同时其配偶也自动成为调查对象
u 更多信息:http://charls.ccer.edu.cn
? CHARLS所选取的150个区县分布情况
? 利用GIS软件进行住户名单的列举(1)
? 利用GIS软件进行住户名单的列举(2)
? 利用GIS软件进行住户名单的列举(3)
? 利用GIS软件进行住户名单的列举(4)
? 利用GIS软件进行住户名单的列举(5)
? 利用GIS软件进行住户名单的列举(6)
? 利用GIS软件进行住户名单的列举(7)
? 备选样本(Backup sample)
u 在抽样的每一个阶段,应根据需要,在抽取正选样本的同时,按一定比例多抽取一定数量的额外样本
u 当因为一定原因无法对正选样本进行调查时,可以按照一定规则使用备选样本来替代
Ø 例1:所选定的调查点是军事禁区,无法进入
Ø 例2:当试图入户调查时,尝试超过3次都无法成功。这时,可以考虑放弃该户,从备选的住户名单中按次序选出备选样本中的第一户,继续调查
第8讲 测量
? 本讲内容提要
u 测量的概念
u 测量尺度
测量的效度和信度
? 测量的概念
u 测量
Ø 对所确定的研究内容或调查指标进行有效地观测和度量
Ø 根据一定的规则将数字或符号分派于研究对象的特征(即研究变量)之上,从而使社会现象数量化或类型化
Ø 难点:数字/符号分派的规则
p 准确:所分派的数字/符号能真实、有效地反映调查对象在属性和特征上的差异
p 完备:分派规则必须能包括研究变量的各种状态和变异
p 互斥:每个观测对象的属性和特征都能以一个而且只能以一个数字或符号来表示
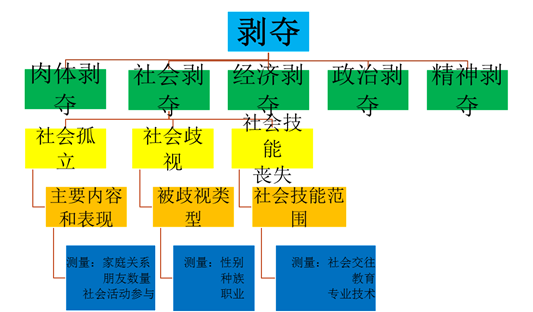
? 例:从概念到测量(来源:袁方,1997)
? 
? 测量尺度(1)
u 常见的测量尺度(level of measurement)
Ø 定类/名义尺度(nominal level)
p 通过数字或符号将观察对象进行分类,各类别之间不存在自然的排序。例:性别、种族等
Ø 定序/排序尺度(ordinal level)
p 不仅将观察对象进行分类,而且每两类之间都存在完整的排序。例:满意度、幸福感等
Ø 定距/等距尺度(interval level)
p 除了可以对不同观测值进行排序外,还知道不同取值之间的精确距离(exact distance)。例:体温、智商等
Ø 定比/比例尺度(ratio level)
p 存在绝对意义上的零点,例:重量、长度、面积、速度等
测量尺度(2)

? 测量尺度(3)
u 测量尺度的选择
Ø 社会现象大多只能以定类或定序尺度进行测量
Ø 较高尺度的测量可以获得更多、更精确的信息,但调查和分析的工作量也可能更大
Ø 不能用较高尺度的统计方法来处理较低尺度的变量
Ø 有的变量可以用多种尺度来测量,如何选择取决于研究所要求的精度
? 效度(validity)
u 效度的定义
Ø 正确性程度,即测量工具是否确实测出其所要测量的特质
u 效度的分类
Ø 内容效度(content validity)
p 表面效度(face validity):研究者对测量工具效度的主观判断
p 样本效度(sampling validity):测量工具是否充分反映了所测量特性的内容总体(content population)
Ø 经验效度(empirical validity)
p 测量工具与所测量的结果之间的关系
p 预测效度(predictive validity):测量工具对一个外在效标(criterion)的预测结果
Ø 建构效度(construct validity)
p 测量工具与一般性概念/理论的内部结构的一致性
? 信度(reliability)
u 信度的定义
Ø 稳定性程度,即测量工具能否稳定地测出所要测量的特质
Ø 信度
Ø 信度的取值范围为[0, 1]
u 信度的估计
Ø 重测信度(test-retest method)
p 用同一测量工具对同一人群前后进行两次测量
Ø 平行信度(parallel-forms technique)
p 利用一种测量工具的两种等价的形式对同一人群同时进行测量
Ø 折半信度(split-half method)
p 将一次测量中所使用的测量工具分为两半
第9讲 问卷设计与评估
? 问卷在调查中的重要性
作为社会过程的调查访问
Ø 调查访谈与一般社会交谈具有很多相似之处。事实上,问卷调查可以看作是有目的的交谈过程。
Ø 问卷调查依赖于被访者的自愿参与。如果问题是不成熟的、尴尬的、令人不愉快的,被访者就有可能终止访谈或伪造答案。
细微的措辞变化可能造成显著的差异
Ø 例1:祈祷与吸烟的故事
Ø 例2:比较下面两个问题
p “你是否觉得你的工作得到了公正的报偿?”
p “你的雇主或代理人是否用花招来骗取你的部分收入?”
? 问卷的结构
封面信(cover letter)
Ø 例:
u 指导语(instructions)
Ø 例:接下来,我想了解一下关于您上学的情况。请您从上过的第一所小学(包括私塾)开始谈起,详细地告诉我您每一次上学的经历,如果有转学、退学、复学的情况,前后应算作两次不同的经历。 [访谈员注意:按照被访者受教育的时间顺序,将回答记录在表A1中。针对每一段教育经历,逐一提问A4-A9。在问完所有教育经历之后,再继续提问A10-A11。如果被访者忘记了一段教育经历,后来想要加入(不按时间顺序),这是允许的。]
u 主体:题目与答案
u 结束语
? 题目设计
u 题目:问卷的主体
Ø 将研究目的转化成具体的题目
p 对题目的回答将提供检验假设的材料
p 题目应激励被访者提供必要的信息
u 题目设计需要考虑的问题
Ø 题目的内容
Ø 题目的类型
Ø 答案的形式
Ø 题目的次序
? 题目设计应遵循的基本原则
u 明确测量目标,详细界定实现测量目标所需要的信息类型;
u 对问题的概念和术语予以澄清,确保所有被访者对问题有共同的、一致的理解;
u 确保所问的问题是被访者知道答案的问题,尽量降低被访者回答问题的负担;
u 询问被访者愿意准确回答的问题。
? 题目的内容(1)
u 事实和行为题目
Ø 询问被访者的个体特征、背景、经历、行为等客观信息
p 例:年龄、性别、婚姻状况、教育水平、收入、生活习惯等
CGSS2006


? 题目的内容(2)
u 事实和行为题目的注意事项
Ø 明确测量目标
p 谁的行为?什么行为?发生在什么时间?
例:在过去12个月,您总共看过几次医生?
Ø 澄清概念和术语(clear definition)
p 通过定义澄清用词含糊不清的题目
例:1a 您家一共有几个房间?
1b 您家一共有几个房间(包括所有卧室、客厅和厨房,但请不要包括卫生间)?
p 用多个题目来分解复杂的概念定义
p 避免使用生僻的术语
Ø 帮助被访者确定信息
p 确定被访者拥有相关信息
p 保证被访者愿意提供相关信息
? 题目的内容(3)
u 敏感性的事实和行为题目
Ø 调查中的社会期望效应(social desirability effect)
p 被访者在回答问题时倾向于给出符合社会预期的答案,比如过度报告好的行为,而选择低报不好的行为。
p 当调查题目具有明确的社会期望性质时,如果不进行特殊的处理,调查结果可能会出现较大的偏误。
Ø 处理敏感性题目的常用方法
p 使用自填的调查方式
p 卡片分类法(Belson et al. 1968)
通过卡片记录一系列行为,让被访者分别投入标有“是”和“否”的两个箱子内
p 随机回答技术(randomized response technique)
例:先让被访者掷一枚硬币,然后问被访者如果上个月曾经醉酒驾车或硬币正面朝上请选“是”,否则选“否”
p 通过增加导语降低问题的敏感性
例:“即使最冷静的父母也会偶尔对子女发脾气,那么自(日期)算起,您的子女做过什么让您生气的事没有?”
? 题目的内容(4)
u 主观题目:观点与态度
Ø 态度(attitude):对某一具体主题的喜好、厌恶、恐惧等倾向
Ø 观点(opinion):对态度的语言表达
u 主观题目的特点:
Ø 与事实/行为题目不同,观点/态度题目不存在唯一正确的答案
Ø 对于事实和行为问题,我们可以合理地认为被访者拥有相关方面的信息;对于观点和态度,被访者并不一定具有相关的信息
Ø 观点和态度具有多维性(multidimentionality)
p 例:“您认为我们应该鼓励与日本的经济贸易往来吗?”
1 是 2 否
Ø 对于题目的措辞、形式和顺序更敏感(参见表1和表2)
p 例:“一般来说,您认为您的健康状况怎么样?”
1 很好 2 好 3 一般 4 差 5 很差
? 表1. 在同一次调查中被访者对自评一般健康问题的回答结果(CMHS, 2008)
? 表2. 措辞差异对自评一 般健康问题的影响(IFLS, 2000)
? 题目的类型(1)
u 封闭式题目(Closed-ended questions)
Ø 题目后面附有具体选项,要求被访者从给定的答案中选择
Ø 优点:问答容易、无需大量记录、可直接进行数据分析
Ø 缺点:容易导致偏差(强迫被访者从给定的答案中选择)
u 开放式题目(Open-ended questions)
Ø 题目后面不带有具体选项,对被访者的回答进行完整记录
Ø 优点:被访者可针对问题用自己的语言进行自由的表述;访员在必要的时候可以对问题进行追问以消除可能的误解
Ø 缺点:难于回答、难于分析(对答案进行编码)
? 题目的类型(2)
u 例:询问职业?
Ø 封闭式:BI6. 被访者的工作种类?
专业技术人员 (老师,工程师,医生,护士,经济策划,艺术家) 01
主要领导或管理人员(包括国有和私有) 02
办公室人员(秘书,行政助理,等等) 03
销售人员(商店职员,街道小贩,收银员,等等) 04
服务行业工作人员(服务员,理发师,清洁员,等等) 05
技术工人(电器工,木工,等等) 06
非技术工人(搬运工,建筑工人,等等) 07
农业活动者(农民,拖拉机驾驶员,牧民,渔民,等等) 08
公共安全人员(警察,消防员,等等) 09
其他(请注明___________________________) 10
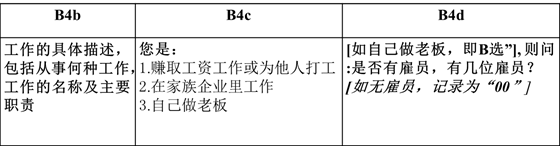
Ø 开放式:
? 
? 题目的类型(3)
u 题目类型的选择标准(Lazarsfeld 1944)
Ø 题目的目的
Ø 被访者对该主题的知识水平
Ø 被访者对该主题的思考程度
Ø 被访者回答问题的意愿
? 答案的形式(1)
u 答案的形式
Ø 封闭式题目中备选答案的结构
Ø 常见形式:评定尺度、语义差异、排序
u 评定尺度(rating)
Ø 要求被访者从一系列序列性选项中做出选择
Ø 注意事项:选项的数目、选项之间的距离
Ø 例:
? 答案的形式(2)
u 语义差异(semantic differential)
Ø 将评定尺度中的文字用数字代替,只对两极加以文字说明
Ø 例:
1 总的来说,您觉得您的生活幸不幸福?
(非常不幸福) 0 1 2 3 4 5 6 7 8 9 10(非常幸福)
2 总的来说,您觉得您的儿女对您好不好?
(好)3 2 1 0 1 2 3(不好)
? 答案的形式(3)
u 排序(ranking)
Ø 获取被访者对一系列替代性选择的偏好程度
Ø 注意事项:排序只提供了相对的次序,并不反映次序之间的距离
Ø 例:
您认为我们国家目前最急需解决的四项社会问题是什么?请按问 题的急迫性依次回答:
第一项 ————
第二项 ————
第三项 ————
第四项 ————
? 题目编排的次序
u 题目在问卷中出现的先后顺序
Ø 漏斗型(the funnel sequence)
p 相关联的问题按照从大到小、从一般到具体的次序提出
p 帮助被访者更好地回忆细节、避免对被访者思考进行限制
p 例:1 您认为我们国家目前所面临的最重要的问题有哪些?
2 在您提到的这些问题中,哪一个您认为最重要?
3 您是通过什么方式了解这一问题的?
Ø 反漏斗型(the inverted funnel sequence)
p 相关联的问题按照从小到大、从具体到一般的次序提出
p 帮助被访者对具体的情形或不熟悉的事件形成一个总体的判断
u 次序效应(order effect)
Ø 题目编排的次序影响被访者的合作程度以及答案的可靠性
p 对一组相似题目中列在第一个的题目认同程度更高
p 倾向于选择题目中给出的第一项选项
p 将简单的和有趣的题目放在前面,敏感题目放在后面
? 题目设计中的常见问题
u 题目的措辞(wording)
Ø 明确、避免歧义、简单易懂
u 回答惯性(response set)
Ø 被访者按统一的方式回答所有题目而不考虑题目的内容
u 导向性题目(leading questions)
Ø 使被访者认为调查者期待他做出某种回答
u 紧张问题(threatening questions)
Ø 使被访者感到尴尬因而难以回答的问题
u 复合问题(double-barreled questions)
Ø 一个题目包含了两个或多个问题
? 问卷的评估(1)
u 焦点小组讨论(focus group)
Ø 采用小型座谈会的形式,在一名主持人的引导下,对某一主题进行深入讨论
Ø 群体互动(group dynamics)是焦点小组讨论成功的关键
Ø 帮助研究者明确调查目标、形成题目以及对草拟的题目进行评估
u 深度访谈
Ø 无结构的一对一面谈,目的在于探查被访者在理解和回答问题时的思考过程
Ø 认知访谈技术(cognitive interviewing, Belson 1968)
p 要求被访者用自己的语言重新陈述某个问题,类似于回译(back translation)
p 要求被访者描述他们在整个回答过程中的完整思维活动
? 问卷的评估(2)
u 实地试调查(pretest)
Ø 通过对一小部分类似正式调查对象的被访者进行访谈,对问卷的内容、长度以及可能出现的错误进行评估
Ø 评估方法
p 行为编码技术
p 题目评级表
p 例:行为编码表
p 例:题目评分表
第10讲 调查方式
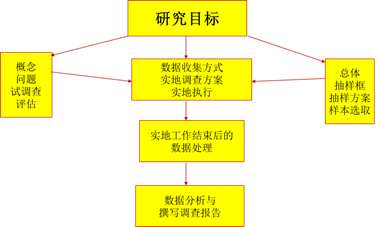
? 调查方式简介(1)
? 
? 调查方式简介(2)
u 针对某个具体的研究问题,哪一种调查方式最适合?
Ø 资源、时间、调查对象、调查主题
Ø 选取某一具体的调查方式对于调查质量和成本的影响?
Ø 每一种具体调查方式会产生怎样的后果以及如何克服所存在的问题
? 调查方式简介(3)
? 邮件调查:简介
u 一种自填问卷
u 具体操作
u 向被访者寄送通知函
u 寄送问卷
u 记录问卷回收的情况
u 对未回应的被访者寄送后续邮件
? 邮件调查:优点
u 成本低
u 可以降低调查员误差(interviewer error)
u 匿名性较好
u 不受调查地域的限制
? 不同调查方式下对敏感问题的回答
(来源:O’Reilly et al. 1994)
? 邮件调查:缺点
u 要求问卷内容简单
u 无法进行追问(probe)
u 难以控制问卷填答质量
u 回答率较低
? 邮件调查:影响回答率的因素
u 调查机构(sponsorship)
u 激励机制(inducement)
u 问卷的长度与格式
u 封面信(cover letter)
u 调查对象的特点
u 追访(follow-up)
? 当面调查:简介
u 调查员
u 具体操作
Ø 调查员培训
Ø 获取样本的住址
Ø 调查员入户
Ø 调查员户内抽样
Ø 对选中的被访者进行面对面访问
? 当面调查:优点
u 问卷内容可以比较复杂
u 对访问的情形控制较好
u 高回答率
u 收集额外的相关信息
? 当面调查:缺点
u 成本高
u 调查员误差
u 匿名性差
? 当面调查:基本原则
(来源:Interviewer’s Manual, Survey Research Center, University of Michigan)
u 确保被访者乐于与调查员互动
u 确保被访者认识到研究的价值
u 消除被访者对参与调查的所有顾虑
? 电话调查:简介
u 随机数字拨号技术(RDD, Random digit dialing)
u 具体操作
Ø 确定和拨打电话号码
Ø 调查员通过电话通话进行户内抽样
Ø 对选中的被访者进行电话访问
? 电话调查:优点
u 速度快,周期短
u 控制调查员误差
u 高回答率
u 抽样便捷
? 电话调查:缺点
u 样本的代表性问题
u 问卷内容不能太复杂
u 中断访问的问题突出
u 调查的主题不能太敏感
u 不同调查方式的比较
? 电脑辅助调查
u 电脑辅助当面调查(Computer-assisted personal interviewing, CAPI)
u 电脑辅助电话调查(Computer-assisted telephone interviewing, CATI)
u 电脑辅助自填问卷(Computerized self-administered questionnaires, CSAQ)
? 电脑辅助当面调查(CAPI)
u 访谈员在入户访谈时携带便携式电脑,并使用电脑进行面对面访谈。
u 在访谈完成后,数据可以通过电子网络或者是邮寄数据盘的方式发送回一个中心计算机(central computer)。
? CAPI与PAPI的比较(1)
u 技术上的优势
Ø 可以避免访问中回答问题的次序和跳答错误。
Ø 可以对数据进行即时检查。
Ø 电脑为问卷设计提供了新的可能性。例如,问题的随机排序可以消除次序效应(order effect)。
Ø 不需要再单独进行数据录入。
Ø 电脑系统可以精确记录调查的全过程,从而避免了访谈员的欺诈行为。
? CAPI与PAPI的比较(2)
u 电脑在访谈过程中出现的影响
Ø 被访者的顾虑
p 降低了还是增强了对隐私的保护?
Ø 对访谈员的影响
p 专业与自信
Ø 对访谈过程的影响
p 访谈员与被访者的互动
Ø 对跟踪调查而言,电脑的存在有助于使被访者同意继续参与调查
? CAPI与PAPI的比较(3)
u 时间和成本的变化
Ø CAPI需要较大的初期投入
p 购置设备和软件
p 对调查员进行额外的培训
Ø CAPI可以节省后期的投入
p 降低数据检查、清理和录入成本
Ø 在时间上,调查所需的总体时间大体相当。
p CAPI需要更长的问卷设计和评估的时间,但是可以节省数据处理的时间
第11讲 数据处理与调查质量
数据检查
u 目的
Ø 保证数据完整、准确、真实
u 方法
Ø 问卷检查
p 问卷填答的完整性
p 访问过程是否符合要求
p 一般应在调查地点完成,以方便及时改正
Ø 回访
p 调查结束后,由督导或复查员随机抽取一部分被访者进行再次访问
p 通常采用电话和邮件访问的形式
? 数据编码(1)
u 目的
Ø 将被访者的回答归结为有意义的有限类别,从而可以对数据进行简单描述和统计分析
Ø 例:职业编码
p 被访者对职业的原始回答:律师、理发师、木匠、经纪人、电梯操作员、种地的农民、临床护士、经理、高中教师、电工、广告代理人
p 一种可行的编码方法:
1 专业技术和管理人员:律师、经理、高中教师
2 技术和销售人员:广告代理人、经纪人
3 服务人员和熟练工人:临床护士、理发师、木匠、电工 、电梯操作员
4 非熟练工人:种地的农民
? 数据编码(2)
u 方法
Ø 归纳式编码(inductive coding)
p 尽可能的保留原始数据中的具体信息,推迟对类别的合并
p 多用于对开放式问题的编码以及对文献资料的编码
Ø 演绎式编码(deductive coding)
p 将原始数据按照某种预先构建的概念体系进行编码
p 一般的预编码都属于演绎式编码
Ø 比较
p 演绎式编码违背了关于行为的持续性和复杂性理论
p 预编码容易忽略掉调查中出现的新问题,缺乏具体描述使数据分析存在着一定的局限性
p 演绎式编码使研究者直视理论概念本身,避免细枝末节的干扰
p 归纳式编码最大的优点在于它的灵活性和丰富性
p 归纳式编码的缺点在于研究者要面对大量的细节和具体描述
? 数据编码(3)
u 标准
Ø 与理论相一致
p 编码框应该与理论和研究问题相结合
Ø 穷尽性(exhaustiveness)
p 每一种可能的回答、每一种情况都应包括在编码框里面
Ø 排他性(mutual exclusiveness)
p 各个类别相互排他,每个可能回答仅被划分到某一个类别
Ø 细节
p 编码框需要具体到怎样的程度
p 一般来说,种类多比少好
u 数据处理过程中所产生的错误,以编码阶段最多
? 数据编码(4)
u 编码手册(codebook)
Ø 作用
p 提供一套标准化的编码程序
p 数据分析的指南
Ø 内容
p 编号
p 变量名称和变量标签
p 变量数值及标签
p 对缺失值的编码
? 数据录入与清理
u 录入方式
Ø 人工输入
Ø 光电输入
Ø 计算机辅助系统转换
Ø 数据清理
Ø 数值范围的清理
p 单变量分布
Ø 内在一致性的清理
p 多变量对比
? 数据加权
u 对不同入样概率进行调整
u 对无回答情况进行调整
u 事后的分层调整(post-stratification)
? 质量的概念
u 什么是质量——“fitness to use”(Juran & Gryna 1980)
Ø 达到用户所要求的目标,满足用户需要
u 调查质量概念的多维性
Ø 长期以来,调查质量被等同于调查的精度
Ø 在过去10-15年间,调查质量的概念进一步扩展,包括了对数据用户来说非常重要的其他维度,如时效性、可得性等
Ø 例:欧洲统计中心(Eurostat 2000)对调查质量的界定
p 切实(relevance)、精确(accuracy)、及时(timeliness)、可得(accessibility)、可比(comparability)、一致(coherence)
u 调查质量的不同维度之间常常存在冲突
Ø 例:时效vs.精确;切实vs.可比
? 调查误差(Survey Errors)
u 与代表性(representativeness)有关的误差
Ø 抽样框误差(Coverage error)
Ø 抽样误差(Sampling error)
Ø 无回答误差(Non-response error)
u 与测量过程有关的误差
Ø 测量误差(Measurement error)
p 可能来源:(1) 调查员; (2) 被访者;(3) 问卷;(4) 调查方式
? 抽样调查中的误差
(Groves et al. 2004: Pp.48)
? 抽样框误差(Coverage error)
u 概念
Ø 由于目标总体中的一部分个体没有被包括在抽样框中而导致的调查结果与总体指标的不一致
u 对抽样框误差的估计
Ø 抽样框误差的大小取决于两个因素
p 抽样框遗漏的比例
p 目标总体中被涵盖群体与遗漏群体之间的平均差异
Ø 一般而言,家庭户调查倾向于遗漏穷人、社会孤立群体、流动性强的群体
Ø 可以对抽样框遗漏的部分进行专门研究,包括一些定性方法的研究
Ø 一般试图去降低抽样框误差,而很少去度量它
p 应用最新的抽样框和总体估计数据
p 对要进行推断的目标总体加以限定
? 抽样误差(Sampling error)
u 概念
Ø 由于所抽取样本与目标总体范围不一致而导致的样本指标与总体指标的差别。在概率抽样中,抽样误差是一种随机误差。
u 对抽样误差的估计
Ø 决定抽样误差的因素
p 样本量
p 总体的差异性
p 抽样设计
Ø 非简单随机抽样设计对数据分析的影响
p 描述性研究:统计计算应反映抽样过程
p 分析性研究:存在争论
? 无回答误差(Nonresponse error)
u 概念
Ø 由于一部分被抽中的个体没有参与调查而导致的调查结果与总体指标的不一致
Ø 导致无回答的主要原因:无法进入;无人在家;拒访;被访者无法完成访谈
u 对无回答误差的估计
Ø 长期以来,应答率(response rate)一直被视为与无回答误差相等同的指标,但是无回答误差还取决于回答样本与无回答样本之间的差异
Ø 应答率的持续下降是目前社会调查所面临的主要问题
Ø 处理无回答误差的统计方法
p 建立无回答似然函数模型(nonresponse likelihood),对回答样本进行加权调整(Rubin 1987)
p 选择偏差模型(selection bias model,Heckman 1979)
? 测量误差(Measurement error)
u 概念:
Ø 由于被访者实际特性与他们在调查中的回答结果不一致所导致的误差
Ø 测量误差在调查质量研究中最受关注
p 与其他几种误差(由于部分对象未被观测所致)不同,测量误差可用现有数据进行分析
p 统计工具的发展提供了技术支持
u 与调查员有关的测量误差
Ø 如何提高调查员表现?
p 调查员之间的差异
p 访问过程的标准化
Ø 对访问过程标准化的重新思考
p 标准化并不必然保证一致性
? 测量误差(续)
u 与被访者有关的测量误差
Ø 激励机制(motivation)
Ø 社会偏好效应(social desirability effect)
Ø 访谈的认知负担(cognitive demand)
p 生命史回忆及其可靠性
u 与问卷有关的测量误差
Ø 问题:问卷结构、题目措辞、题目次序
Ø 对策:针对同一个概念设计多个题目,考察其变动性
u 与调查方式有关的测量误差
Ø 对调查题目的理解以及访问环境的控制
Ø 常常与调查员误差交互影响
? 调查质量的核心问题
u 降低误差对成本的影响
Ø 花费效率最大化(maximum cost efficiency)
Ø 各类误差之间的关系
Ø 各类误差之间存在一定的冲突
Ø 调查既是一门科学,也是一门艺术
Ø “We could live with some errors.”
社会调查方法
第12讲 数据分析基础
课程回顾
u 数据处理
Ø 检查
Ø 编码
Ø 录入与清理
Ø 加权
u 调查质量
Ø 质量概念的多维性
Ø 调查误差
内容提要
u 单变量分析
Ø 频数分布表
Ø 集中趋势和离散趋势
u 双变量分析
Ø 关系的概念和测度
Ø 不同类型变量的关系
u 多变量分析
Ø 调查数据中的因果分析
Ø 控制
Ø 详析
Ø 因果模型
单变量分析
u 简介:统计分析
Ø 描述和分析数据
p 以一种有效、有意义的方式来总结和呈现数据
Ø 统计推断
p 通过解释数据之间的模式来进行推论
u 单变量分析
Ø 纯描述性
Ø 检验每个单一变量的分布模式
频数分布表(1)
u 频数分布
Ø 列出变量的所有分类,并统计选择每一类的样本数(频数)
频数分布表(2)
u 定距变量的频数分布
Ø 将定距变量划分为通常间距相等的一定组别
Ø 间距的大小
频数分布表(3)
u 百分比
Ø 将频数转化成更为直观的统计量
Ø 百分比可以对两个或多个频数分布进行直观比较
集中趋势(1)
u 集中趋势
Ø 有时需要利用一个数字来对数据进行总结
Ø 样本取值向其中心值靠拢的倾向和程度
Ø 集中趋势度量一个频数分布的典型值或平均值
u 反映集中趋势的度量指标
Ø 众数(mode)
p 频数分布最集中的一个值或类别,即样本中出现次数最多的变量值
p 多用于描述定类变量的分布
Ø 中位数(median)
p 将一个分布排序后处于中间位置上的值
p 其他的位置指标:四分位点、百分位点
Ø 均值(mean):所有样本取值之和除以总样本量
集中趋势(2)
u 众数、中位数和均值的比较
Ø 众数表示一个分布的最集中的值;中位数表示一个分布的中点;均值表示一个分布的所有取值之和的平均数
Ø 众数和中位数并不考虑一个分布的所有取值,而均值考虑了所有的取值
Ø 众数有可能不唯一
Ø 均值更容易受到极端值(extreme values)的影响
Ø 各有优劣,选取哪一个指标取决于:
p 研究目的
p 变量的测量尺度
离散趋势
u 离散趋势
Ø 度量一个分布远离中心值的程度
u 离散趋势的度量指标
Ø 定性差异指标(measure of qualitative variation)
p 用于测度定类变量的分布的离散趋势
Ø 极差
Ø 四分位距
Ø 方差和标准差
Ø 变异系数(coefficient of variation)
双变量分析
u 关系
Ø 关系(relationship):两个变量共同变动的趋势
Ø X和Y有关是指当X取某些值的时候,Y也会倾向于取一定的值
Ø 问题:关系是否存在?方向?强度?类型?
双变量分析——交叉列联表
u 二维表(bivariate table)
Ø 两个变量的交叉分布(cross-classified)
Ø 共同变动原理(principle of covariation)
Ø 二维表可以看作为一系列的单变量频数分布表
表1 教育程度与社会阶层(完全相关)
表2 教育程度与社会阶层(部分相关)
表3 教育程度与社会阶级(不相关)
关系的测度
u 预测
Ø 当两个变量存在共同变动的趋势时,我们可以用一个变量的取值去预测另一个变量的取值;反之,则不能
Ø 消减预测误差的原则(proportional reduction of error principle)
p 两个变量关系的强弱可以由当用一个变量去预测另一个变量时所导致的预测误差减少的比例来估计
p b =最初的预测错误(引入自变量之前)
a =新的预测错误(引入自变量之后)
定类变量关系的测度
u 格特曼可预测性系数(Guttman Coefficient of Predictability)
为在给定的自变量的每一类别内因变量的众数分布;
为因变量本身的众数分布;
N 为总样本量;
表4 1956和1960年的政党认同
定序变量关系的测度(1)
u 可以通过度量任意两个样本单位在定序尺度上的相对位置来估计两个变量的关系
u 配对(pair)的概念
Ø 样本总量为N的配对数为N(N-1)/2
Ø 配对的分类
p 同序对:针对X和Y有相同的排序,表示为Ns
p 异序对:针对X和Y有相反的排序,表示为Nd
p X的取值相同,Y的取值不同,表示为Tx
p Y的取值相同,X的取值不同,表示为Ty
p X和Y的取值都相同,表示为Txy
定序变量关系的测度(2)
u Gamma指标
u Kendall’s Tau-b指标
表5 收入与工作满意度
定距变量关系的测度
u 在利用一个定距变量预测另一个定距变量时,我们可以将两个变量的关系表示成数学函数的形式
u 线性回归模型
Ø 简单线性回归:
Ø 最小二乘法(Ordinary Least Squares,OLS)
u Pearson相关系数
两个变量间的因果关系
u 四种可能性
Ø X Y:X影响Y,Y不影响X
Ø X Y:X不影响Y,Y影响X
Ø X Y:X和Y相互影响
Ø X Y:X和Y可能统计上相关,但影响机理未知
u 决定双变量因果的基本原则
Ø 如果X的值给定之后Y才发生,箭头由X指向Y
Ø 如果X和一个已知过程的较早环节相联系,箭头由X指向Y
Ø 如果X的值恒定,而Y的值可变,箭头由X指向Y
Ø 如果X相对稳定,而Y相对多变,箭头由X指向Y
多变量间的因果关系系统
u 完全排序的系统
u 部分排序的系统
u 循环系统
统计控制(control)
u 多变量分析的必要性
Ø 双变量分析只是数据分析的基础,解释和评估所观测到的两个变量的关系需要引入其他的变量
Ø 统计控制的概念
Ø 为了检验两个变量之间的关系是不是真实的,有必要考虑同时影响这两个变量的外在因素的作用
Ø 在实验设计中,控制可以通过随机分组来实现
Ø 在非实验设计中,控制一般通过统计方法来实现
p 列联表分析
p 偏相关分析
p 多元回归分析
统计控制的必要性——辛普森悖论
u 辛普森悖论(Simpson’s paradox)
Ø 与未进行统计控制的情况相比,在控制了其他变量后,两个变量之间的关系完全相反。
通过列联表分析实现统计控制
u 基本思路
Ø 类似于研究设计中匹配(matching)的原则
Ø 将样本按照控制变量的类别进行分组,在每一组内估测两个变量的初始关系是否仍然存在
Ø 一般而言,只有既与自变量又与因变量相关的变量才有可能影响两个变量间的关系
表6 居住地与思想开放程度
表7 教育程度与居住地
表8 教育程度与思想开放程度
表9a 控制教育程度后居住地与思想开放程度的列联表
表9b 控制教育程度后居住地与思想开放程度的列联表
偏相关分析
u 列联表分析存在着相当的局限性
Ø 当需要控制的变量数目和类别增加时,表中每个单元格所基于的样本数量会变得非常小
u 偏相关分析
Ø 通过对双变量相关系数的数学调整,来消除控制变量的可能影响
Ø 偏相关系数的公式
多元回归分析
u 多元线性回归
Ø 公式:
Ø 标准化回归系数
详析(elaboration)
u 详析的概念
Ø 在确认自变量和因变量的关系确实存在后,可以进一步分析为什么这两个变量相关
u 中介变量
Ø 自变量通过直接影响中介变量进而影响因变量
u 条件变量
Ø 自变量在一定条件下影响因变量
Ø 三组常见的条件变量
p 时间和地点
p 背景特征
p 兴趣和关注
表10 性别和投票行为
(Lazarsfeld et al. 1968)
表11 按政治兴趣划分的性别和投票行为
因果模型和路径分析
u 因果模型(Lazarsfeld 1959)
Ø 有限数量个明确定义的变量
Ø 这些变量之间存在怎样的因果关系
Ø 外在变量对模型中的变量的影响
u 路径分析(path analysis)
Ø 按照理论假设绘制路径图
Ø 通过回归分析估算各个路径系数(直接效应)
Ø 计算间接效应和总效应
例:布劳-邓肯模型 (1967:图5.1)