预备实验 C语言的函数数组指针结构体知识
一、实验目的
1、复习C语言中函数、数组、指针、结构体与共用体等的概念。
2、熟悉利用C语言进行程序设计的一般方法。
二、实验预习
说明以下C语言中的概念
1、 函数:
2、 数组:
3、指针:
4、结构体
5、共用体
三、实验内容和要求
1、调试程序:输出100以内所有的素数(用函数实现)。
#include<stdio.h>
int isprime(int n){ /*判断一个数是否为素数*/
int m;
for(m=2;m*m<=n;m++)
if(n%m==0) return 0;
return 1;
}
int main(){ /*输出100以内所有素数*/
int i; printf("\n");
for(i=2;i<100;i++)
if(isprime(i)==1) printf("%4d",i);
return 0;
}
运行结果:
2、 调试程序:对一维数组中的元素进行逆序排列。
#include<stdio.h>
#define N 10
int main(){
int a[N]={0,1,2,3,4,5,6,7,8,9},i,temp;
printf("\nthe original Array is:\n ");
for(i=0;i<N;i++)
printf("%4d",a[i]);
for(i=0;i<N/2;i++){ /*交换数组元素使之逆序*/
temp=a[i];
a[i]=a[N-i-1];
a[N-i-1]=temp;
}
printf("\nthe changed Array is:\n");
for(i=0;i<N;i++)
printf("%4d",a[i]);
return 0;
}
运行结果:
3、 调试程序:在二维数组中,若某一位置上的元素在该行中最大,而在该列中最小,则该元素即为该二维数组的一个鞍点。要求从键盘上输入一个二维数组,当鞍点存在时,把鞍点找出来。
#include<stdio.h>
#define M 3
#define N 4
int main(){
int a[M][N],i,j,k;
printf("\n请输入二维数组的数据:\n");
for(i=0;i<M;i++)
for(j=0;j<N;j++)
scanf("%d",&a[i][j]);
for(i=0;i<M;i++){ /*输出矩阵*/
for(j=0;j<N;j++)
printf("%4d",a[i][j]);
printf("\n");
}
for(i=0;i<M;i++){
k=0;
for(j=1;j<N;j++) /*找出第i行的最大值*/
if(a[i][j]>a[i][k])
k=j;
for(j=0;j<M;j++) /*判断第i行的最大值是否为该列的最小值*/
if(a[j][k]<a[i][k])
break;
if(j==M) /*在第i行找到鞍点*/
printf("%d,%d,%d\n",a[i][k],i,k);
}
return 0;
}
运行结果:
4、 调试程序:利用指针输出二维数组的元素。
#include<stdio.h>
int main(){
int a[3][4]={1,3,5,7,9,11,13,15,17,19,21,23};
int *p;
for(p=a[0];p<a[0]+12;p++){
if((p-a[0])%4==0) printf("\n");
printf("%4d",*p);
}
return 0;
}
运行结果:
5、 调试程序:设有一个教师与学生通用的表格,教师的数据有姓名、年龄、职业、教研室四项,学生有姓名、年龄、专业、班级四项,编程输入人员的数据,再以表格输出。
#include <stdio.h>
#define N 10
struct student{
char name[8]; /*姓名*/
int age; /*年龄*/
char job; /*职业或专业,用s或t表示学生或教师*/
union {
int class; /*班级*/
char office[10]; /*教研室*/
}depa;
}stu[N];
int main(){
int i; int n;
printf(“\n请输入人员数(<10):\n”);
scanf(“%d”,&n);
for(i=0;i<n;i++){ /*输入n个人员的信息*/
printf("\n请输入第%d人员的信息:(name age job class/office)\n",i+1);
scanf("%s,%d,%c",stu[i].name, &stu[i].age, &stu[i].job);
if(stu[i].job==’s’)
scanf("%d",&stu[i].depa.class);
else
scanf("%s",stu[i].depa.office);
}
printf(“name age job class/office”);
for(i=0;i<n;i++){ /*输出*/
if(stu[i].job==’s’)
printf("%s %3d %3c %d\n",stu[i].name, stu[i].age, stu[i].job, stu[i].depa.class);
else
printf("%s %3d %3c %s\n",stu[i].name, stu[i].age, stu[i].job, stu[i].depa.office);
}
}
输入的数据:2
Wang 19 s 99061
Li 36 t computer
运行结果:
四、实验小结
五、教师评语
实验一 顺序表与链表
一、实验目的
1、掌握线性表中元素的前驱、后续的概念。
2、掌握顺序表与链表的建立、插入元素、删除表中某元素的算法。
3、对线性表相应算法的时间复杂度进行分析。
4、理解顺序表、链表数据结构的特点(优缺点)。
二、实验预习
说明以下概念
1、线性表:
2、顺序表:
3、链表:
三、实验内容和要求
1、阅读下面程序,在横线处填写函数的基本功能。并运行程序,写出结果。
#include<stdio.h>
#include<malloc.h>
#define ERROR 0
#define OK 1
#define INIT_SIZE 5 /*初始分配的顺序表长度*/
#define INCREM 5 /*溢出时,顺序表长度的增量*/
typedef int ElemType; /*定义表元素的类型*/
typedef struct Sqlist{
ElemType *slist; /*存储空间的基地址*/
int length; /*顺序表的当前长度*/
int listsize; /*当前分配的存储空间*/
}Sqlist;
int InitList_sq(Sqlist *L); /* */
int CreateList_sq(Sqlist *L,int n); /* */
int ListInsert_sq(Sqlist *L,int i,ElemType e);/* */
int PrintList_sq(Sqlist *L); /*输出顺序表的元素*/
int ListDelete_sq(Sqlist *L,int i); /*删除第i个元素*/
int ListLocate(Sqlist *L,ElemType e); /*查找值为e的元素*/
int InitList_sq(Sqlist *L){
L->slist=(ElemType*)malloc(INIT_SIZE*sizeof(ElemType));
if(!L->slist) return ERROR;
L->length=0;
L->listsize=INIT_SIZE;
return OK;
}/*InitList*/
int CreateList_sq(Sqlist *L,int n){
ElemType e;
int i;
for(i=0;i<n;i++){
printf("input data %d",i+1);
scanf("%d",&e);
if(!ListInsert_sq(L,i+1,e))
return ERROR;
}
return OK;
}/*CreateList*/
/*输出顺序表中的元素*/
int PrintList_sq(Sqlist *L){
int i;
for(i=1;i<=L->length;i++)
printf("%5d",L->slist[i-1]);
return OK;
}/*PrintList*/
int ListInsert_sq(Sqlist *L,int i,ElemType e){
int k;
if(i<1||i>L->length+1)
return ERROR;
if(L->length>=L->listsize){
L->slist=(ElemType*)realloc(L->slist,
(INIT_SIZE+INCREM)*sizeof(ElemType));
if(!L->slist)
return ERROR;
L->listsize+=INCREM;
}
for(k=L->length-1;k>=i-1;k--){
L->slist[k+1]= L->slist[k];
}
L->slist[i-1]=e;
L->length++;
return OK;
}/*ListInsert*/
/*在顺序表中删除第i个元素*/
int ListDelete_sq(Sqlist *L,int i){
}
/*在顺序表中查找指定值元素,返回其序号*/
int ListLocate(Sqlist *L,ElemType e){
}
int main(){
Sqlist sl;
int n,m,k;
printf("please input n:"); /*输入顺序表的元素个数*/
scanf("%d",&n);
if(n>0){
printf("\n1-Create Sqlist:\n");
InitList_sq(&sl);
CreateList_sq(&sl,n);
printf("\n2-Print Sqlist:\n");
PrintList_sq(&sl);
printf("\nplease input insert location and data:(location,data)\n");
scanf("%d,%d",&m,&k);
ListInsert_sq(&sl,m,k);
printf("\n3-Print Sqlist:\n");
PrintList_sq(&sl);
printf("\n");
}
else
printf("ERROR");
return 0;
}
l 运行结果
l 算法分析
2、为第1题补充删除和查找功能函数,并在主函数中补充代码验证算法的正确性。
删除算法代码:
l 运行结果
l 算法分析
查找算法代码:
l 运行结果
l 算法分析
3、阅读下面程序,在横线处填写函数的基本功能。并运行程序,写出结果。
#include<stdio.h>
#include<malloc.h>
#define ERROR 0
#define OK 1
typedef int ElemType; /*定义表元素的类型*/
typedef struct LNode{ /*线性表的单链表存储*/
ElemType data;
struct LNode *next;
}LNode,*LinkList;
LinkList CreateList(int n); /* */
void PrintList(LinkList L); /*输出带头结点单链表的所有元素*/
int GetElem(LinkList L,int i,ElemType *e); /* */
LinkList CreateList(int n){
LNode *p,*q,*head;
int i;
head=(LinkList)malloc(sizeof(LNode)); head->next=NULL;
p=head;
for(i=0;i<n;i++){
q=(LinkList)malloc(sizeof(LNode)); printf("input data %i:",i+1);
scanf("%d",&q->data); /*输入元素值*/
q->next=NULL; /*结点指针域置空*/
p->next=q; /*新结点连在表末尾*/
p=q;
}
return head;
}/*CreateList*/
void PrintList(LinkList L){
LNode *p;
p=L->next; /*p指向单链表的第1个元素*/
while(p!=NULL){
printf("%5d",p->data);
p=p->next;
}
}/*PrintList*/
int GetElem(LinkList L,int i,ElemType *e){
LNode *p;int j=1;
p=L->next;
while(p&&j<i){
p=p->next;j++;
}
if(!p||j>i)
return ERROR;
*e=p->data;
return OK;
}/*GetElem*/
int main(){
int n,i;ElemType e;
LinkList L=NULL; /*定义指向单链表的指针*/
printf("please input n:"); /*输入单链表的元素个数*/
scanf("%d",&n);
if(n>0){
printf("\n1-Create LinkList:\n");
L=CreateList(n);
printf("\n2-Print LinkList:\n");
PrintList(L);
printf("\n3-GetElem from LinkList:\n");
printf("input i=");
scanf("%d",&i);
if(GetElem(L,i,&e))
printf("No%i is %d",i,e);
else
printf("not exists");
}else
printf("ERROR");
return 0;
}
l 运行结果
l 算法分析
4、为第3题补充插入功能函数和删除功能函数。并在主函数中补充代码验证算法的正确性。
插入算法代码:
l 运行结果
l 算法分析
删除算法代码:
l 运行结果
l 算法分析
以下为选做实验:
5、循环链表的应用(约瑟夫回环问题)
n个数据元素构成一个环,从环中任意位置开始计数,计到m将该元素从表中取出,重复上述过程,直至表中只剩下一个元素。
提示:用一个无头结点的循环单链表来实现n个元素的存储。
l 算法代码
6、设一带头结点的单链表,设计算法将表中值相同的元素仅保留一个结点。
提示:指针p从链表的第一个元素开始,利用指针q从指针p位置开始向后搜索整个链表,删除与之值相同的元素;指针p继续指向下一个元素,开始下一轮的删除,直至p==null为至,既完成了对整个链表元素的删除相同值。
l 算法代码
四、实验小结
五、教师评语
实验二 栈和队列
一、实验目的
1、掌握栈的结构特性及其入栈,出栈操作;
2、掌握队列的结构特性及其入队、出队的操作,掌握循环队列的特点及其操作。
二、实验预习
说明以下概念
1、顺序栈:
2、链栈:
3、循环队列:
4、链队
三、实验内容和要求
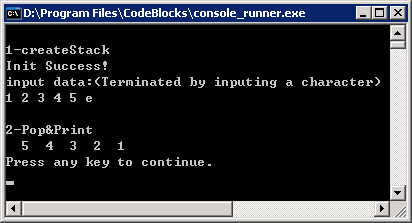
1、阅读下面程序,将函数Push和函数Pop补充完整。要求输入元素序列1 2 3 4 5 e,运行结果如下所示。
#include<stdio.h>
#include<malloc.h>
#define ERROR 0
#define OK 1
#define STACK_INT_SIZE 10 /*存储空间初始分配量*/
#define STACKINCREMENT 5 /*存储空间分配增量*/
typedef int ElemType; /*定义元素的类型*/
typedef struct{
ElemType *base;
ElemType *top;
int stacksize; /*当前已分配的存储空间*/
}SqStack;
int InitStack(SqStack *S); /*构造空栈*/
int push(SqStack *S,ElemType e); /*入栈*/
int Pop(SqStack *S,ElemType *e); /*出栈*/
int CreateStack(SqStack *S); /*创建栈*/
void PrintStack(SqStack *S); /*出栈并输出栈中元素*/
int InitStack(SqStack *S){
S->base=(ElemType *)malloc(STACK_INT_SIZE *sizeof(ElemType));
if(!S->base) return ERROR;
S->top=S->base;
S->stacksize=STACK_INT_SIZE;
return OK;
}/*InitStack*/
int Push(SqStack *S,ElemType e){
}/*Push*/
int Pop(SqStack *S,ElemType *e){
}/*Pop*/
int CreateStack(SqStack *S){
int e;
if(InitStack(S))
printf("Init Success!\n");
else{
printf("Init Fail!\n");
return ERROR;
}
printf("input data:(Terminated by inputing a character)\n");
while(scanf("%d",&e))
Push(S,e);
return OK;
}/*CreateStack*/
void PrintStack(SqStack *S){
ElemType e;
while(Pop(S,&e))
printf("%3d",e);
}/*Pop_and_Print*/
int main(){
SqStack ss;
printf("\n1-createStack\n");
CreateStack(&ss);
printf("\n2-Pop&Print\n");
PrintStack(&ss);
return 0;
}
l 算法分析:输入元素序列1 2 3 4 5,为什么输出序列为5 4 3 2 1?体现了栈的什么特性?
2、在第1题的程序中,编写一个十进制转换为二进制的数制转换算法函数(要求利用栈来实现),并验证其正确性。
l 实现代码
l 验证
3、阅读并运行程序,并分析程序功能。
#include<stdio.h>
#include<malloc.h>
#include<string.h>
#define M 20
#define elemtype char
typedef struct
{
elemtype stack[M];
int top;
}
stacknode;
void init(stacknode *st);
void push(stacknode *st,elemtype x);
void pop(stacknode *st);
void init(stacknode *st)
{
st->top=0;
}
void push(stacknode *st,elemtype x)
{
if(st->top==M)
printf("the stack is overflow!\n");
else
{
st->top=st->top+1;
st->stack[st->top]=x;
}
}
void pop(stacknode *st)
{
if(st->top>0) st->top--;
else printf(“Stack is Empty!\n”);
}
int main()
{
char s[M];
int i;
stacknode *sp;
printf("create a empty stack!\n");
sp=malloc(sizeof(stacknode));
init(sp);
printf("input a expression:\n");
gets(s);
for(i=0;i<strlen(s);i++)
{
if(s[i]=='(')
push(sp,s[i]);
if(s[i]==')')
pop(sp);
}
if(sp->top==0)
printf("'('match')'!\n");
else
printf("'('not match')'!\n");
return 0;
}
l 输入:2+((c-d)*6-(f-7)*a)/6
l 运行结果:
l 输入:a-((c-d)*6-(s/3-x)/2
l 运行结果:
l 程序的基本功能:
以下为选做实验:
4、设计算法,将一个表达式转换为后缀表达式,并按照后缀表达式进行计算,得出表达式得结果。
l 实现代码
5、假设以带头结点的循环链表表示队列,并且只设一个指针指向队尾结点(不设队头指针),试编写相应的置空队列、入队列、出队列的算法。
实现代码:
四、实验小结
五、教师评语
实验三 串的模式匹配
一、实验目的
1、了解串的基本概念
2、掌握串的模式匹配算法的实现
二、实验预习
说明以下概念
1、模式匹配:
2、BF算法:
3、KMP算法:
三、实验内容和要求
1、阅读并运行下面程序,根据输入写出运行结果。
#include<stdio.h>
#include<string.h>
#define MAXSIZE 100
typedef struct{
char data[MAXSIZE];
int length;
}SqString;
int strCompare(SqString *s1,SqString *s2); /*串的比较*/
void show_strCompare();
void strSub(SqString *s,int start,int sublen,SqString *sub);
/*求子串*/
void show_subString();
int strCompare(SqString *s1,SqString *s2){
int i;
for(i=0;i<s1->length&&i<s2->length;i++)
if(s1->data[i]!=s2->data[i])
return s1->data[i]-s2->data[i];
return s1->length-s2->length;
}
void show_strCompare(){
SqString s1,s2;
int k;
printf("\n***show Compare***\n");
printf("input string s1:");
gets(s1.data);
s1.length=strlen(s1.data);
printf("input string s2:");
gets(s2.data);
s2.length=strlen(s2.data);
if((k=strCompare(&s1,&s2))==0)
printf("s1=s2\n");
else if(k<0)
printf("s1<s2\n");
else
printf("s1>s2\n");
printf("\n***show over***\n");
}
void strSub(SqString *s,int start,int sublen,SqString *sub){
int i;
if(start<1||start>s->length||sublen>s->length-start+1){
sub->length=0;
}
for(i=0;i<sublen;i++)
sub->data[i]=s->data[start+i-1];
sub->length=sublen;
}
void show_subString(){
SqString s,sub;
int start,sublen,i;
printf("\n***show subString***\n");
printf("input string s:");
gets(s.data);
s.length=strlen(s.data);
printf("input start:");
scanf("%d",&start);
printf("input sublen:");
scanf("%d",&sublen);
strSub(&s,start,sublen,&sub);
if(sub.length==0)
printf("ERROR!\n");
else{
printf("subString is :");
for(i=0;i<sublen;i++)
printf("%c",sub.data[i]);
}
printf("\n***show over***\n");
}
int main(){
int n;
do {
printf("\n---String---\n");
printf("1. strCompare\n");
printf("2. subString\n");
printf("0. EXIT\n");
printf("\ninput choice:");
scanf("%d",&n);
getchar();
switch(n){
case 1:show_strCompare();break;
case 2:show_subString();break;
default:n=0;break;
}
}while(n);
return 0;
}
l 运行程序
输入:
1
student
students
2
Computer Data Stuctures
10
4
运行结果:
2、实现串的模式匹配算法。补充下面程序,实现串的BF和KMP算法。
#include<stdio.h>
#include<string.h>
#define MAXSIZE 100
typedef struct{
char data[MAXSIZE];
int length;
}SqString;
int index_bf(SqString *s,SqString *t,int start);
void getNext(SqString *t,int next[]);
int index_kmp(SqString *s,SqString *t,int start,int next[]);
void show_index();
int index_bf(SqString *s,SqString *t,int start){
补充代码.....
}
void getNext(SqString *t,int next[]){
int i=0,j=-1;
next[0]=-1;
while(i<t->length){
if((j==-1)||(t->data[i]==t->data[j])){
i++;j++;next[i]=j;
}else
j=next[j];
}
}
int index_kmp(SqString *s,SqString *t,int start,int next[]){
补充代码.....
}
void show_index(){
SqString s,t;
int k,next[MAXSIZE]={0},i;
printf("\n***show index***\n");
printf("input string s:");
gets(s.data);
s.length=strlen(s.data);
printf("input string t:");
gets(t.data);
t.length=strlen(t.data);
printf("input start position:");
scanf("%d",&k);
printf("BF:\nthe result of BF is %d\n",index_bf(&s,&t,k));
getNext(&t,next);
printf("KMP:\n");
printf("next[]:");
for(i=0;i<t.length;i++)
printf("%3d",next[i]);
printf("\n");
printf("the result of KMP is %d\n",index_kmp(&s,&t,k,next));
printf("\n***show over***\n");
}
int main(){
show_index();
return 0;
}
输入:
abcaabbabcabaacbacba
abcabaa
1
运行结果:
四、实验小结
五、教师评语
实验四 二叉树
一、实验目的
1、掌握二叉树的基本特性
2、掌握二叉树的先序、中序、后序的递归遍历算法
3、理解二叉树的先序、中序、后序的非递归遍历算法
4、通过求二叉树的深度、叶子结点数和层序遍历等算法,理解二叉树的基本特性
二、实验预习
说明以下概念
1、二叉树:
2、递归遍历:
3、 非递归遍历:
4、层序遍历:
三、实验内容和要求
1、阅读并运行下面程序,根据输入写出运行结果,并画出二叉树的形态。
#include<stdio.h>
#include<malloc.h>
#define MAX 20
typedef struct BTNode{ /*节点结构声明*/
char data ; /*节点数据*/
struct BTNode *lchild;
struct BTNode *rchild ; /*指针*/
}*BiTree;
void createBiTree(BiTree *t){ /* 先序遍历创建二叉树*/
char s;
BiTree q;
printf("\nplease input data:(exit for #)");
s=getche();
if(s=='#'){*t=NULL; return;}
q=(BiTree)malloc(sizeof(struct BTNode));
if(q==NULL){printf("Memory alloc failure!"); exit(0);}
q->data=s;
*t=q;
createBiTree(&q->lchild); /*递归建立左子树*/
createBiTree(&q->rchild); /*递归建立右子树*/
}
void PreOrder(BiTree p){ /* 先序遍历二叉树*/
if ( p!= NULL ) {
printf("%c", p->data);
PreOrder( p->lchild ) ;
PreOrder( p->rchild) ;
}
}
void InOrder(BiTree p){ /* 中序遍历二叉树*/
if( p!= NULL ) {
InOrder( p->lchild ) ;
printf("%c", p->data);
InOrder( p->rchild) ;
}
}
void PostOrder(BiTree p){ /* 后序遍历二叉树*/
if ( p!= NULL ) {
PostOrder( p->lchild ) ;
PostOrder( p->rchild) ;
printf("%c", p->data);
}
}
void Preorder_n(BiTree p){ /*先序遍历的非递归算法*/
BiTree stack[MAX],q;
int top=0,i;
for(i=0;i<MAX;i++) stack[i]=NULL;/*初始化栈*/
q=p;
while(q!=NULL){
printf("%c",q->data);
if(q->rchild!=NULL) stack[top++]=q->rchild;
if(q->lchild!=NULL) q=q->lchild;
else
if(top>0) q=stack[--top];
else q=NULL;
}
}
void release(BiTree t){ /*释放二叉树空间*/
if(t!=NULL){
release(t->lchild);
release(t->rchild);
free(t);
}
}
int main(){
BiTree t=NULL;
createBiTree(&t);
printf("\n\nPreOrder the tree is:");
PreOrder(t);
printf("\n\nInOrder the tree is:");
InOrder(t);
printf("\n\nPostOrder the tree is:");
PostOrder(t);
printf("\n\n先序遍历序列(非递归):");
Preorder_n(t);
release(t);
return 0;
}
l 运行程序
输入:
ABC##DE#G##F###
运行结果:
2、在上题中补充求二叉树中求结点总数算法(提示:可在某种遍历过程中统计遍历的结点数),并在主函数中补充相应的调用验证正确性。
算法代码:
3、在上题中补充求二叉树中求叶子结点总数算法(提示:可在某种遍历过程中统计遍历的叶子结点数),并在主函数中补充相应的调用验证正确性。
算法代码:
4、在上题中补充求二叉树深度算法,并在主函数中补充相应的调用验证正确性。
算法代码:
选做实验:(代码可另附纸)
4、 补充二叉树层次遍历算法。(提示:利用队列实现)
5、补充二叉树中序、后序非递归算法。
四、实验小结
五、教师评语
实验五 图的表示与遍历
一、实验目的
1、掌握图的邻接矩阵和邻接表表示
2、掌握图的深度优先和广度优先搜索方法
3、理解图的应用方法
二、实验预习
说明以下概念
1、深度优先搜索遍历:
2、广度优先搜索遍历:
3、拓扑排序:
4、最小生成树:
5、最短路径:
三、实验内容和要求
1、阅读并运行下面程序,根据输入写出运行结果。
#include<stdio.h>
#define N 20
#define TRUE 1
#define FALSE 0
int visited[N];
typedef struct /*队列的定义*/
{
int data[N];
int front,rear;
}queue;
typedef struct /*图的邻接矩阵*/
{
int vexnum,arcnum;
char vexs[N];
int arcs[N][N];
}
graph;
void createGraph(graph *g); /*建立一个无向图的邻接矩阵*/
void dfs(int i,graph *g); /*从第i个顶点出发深度优先搜索*/
void tdfs(graph *g); /*深度优先搜索整个图*/
void bfs(int k,graph *g); /*从第k个顶点广度优先搜索*/
void tbfs(graph *g); /*广度优先搜索整个图*/
void init_visit(); /*初始化访问标识数组*/
void createGraph(graph *g) /*建立一个无向图的邻接矩阵*/
{ int i,j;
char v;
g->vexnum=0;
g->arcnum=0;
i=0;
printf("输入顶点序列(以#结束):\n");
while((v=getchar())!='#')
{
g->vexs[i]=v; /*读入顶点信息*/
i++;
}
g->vexnum=i; /*顶点数目*/
for(i=0;i<g->vexnum;i++) /*邻接矩阵初始化*/
for(j=0;j<g->vexnum;j++)
g->arcs[i][j]=0;
printf("输入边的信息:\n");
scanf("%d,%d",&i,&j); /*读入边i,j*/
while(i!=-1) /*读入i,j为-1时结束*/
{
g->arcs[i][j]=1;
g->arcs[j][i]=1;
scanf("%d,%d",&i,&j);
}
}
void dfs(int i,graph *g) /*从第i个顶点出发深度优先搜索*/
{
int j;
printf("%c",g->vexs[i]);
visited[i]=TRUE;
for(j=0;j<g->vexnum;j++)
if((g->arcs[i][j]==1)&&(!visited[j]))
dfs(j,g);
}
void tdfs(graph *g) /*深度优先搜索整个图*/
{
int i;
printf("\n从顶点%C开始深度优先搜索序列:",g->vexs[0]);
for(i=0;i<g->vexnum;i++)
if(visited[i]!=TRUE)
dfs(i,g);
}
void bfs(int k,graph *g) /*从第k个顶点广度优先搜索*/
{
int i,j;
queue qlist,*q;
q=&qlist;
q->rear=0;
q->front=0;
printf("%c",g->vexs[k]);
visited[k]=TRUE;
q->data[q->rear]=k;
q->rear=(q->rear+1)%N;
while(q->rear!=q->front)
{
i=q->data[q->front];
q->front=(q->front+1)%N;
for(j=0;j<g->vexnum;j++)
if((g->arcs[i][j]==1)&&(!visited[j]))
{
printf("%c",g->vexs[j]);
visited[j]=TRUE;
q->data[q->rear]=j;
q->rear=(q->rear+1)%N;
}
}
}
void tbfs(graph *g) /*广度优先搜索整个图*/
{
int i;
printf("\n从顶点%C开始广度优先搜索序列:",g->vexs[0]);
for(i=0;i<g->vexnum;i++)
if(visited[i]!=TRUE)
bfs(i,g);
}
void init_visit() /*初始化访问标识数组*/
{
int i;
for(i=0;i<N;i++)
visited[i]=FALSE;
}
int main()
{
graph ga;
int i,j;
createGraph(&ga);
printf("无向图的邻接矩阵:\n");
for(i=0;i<ga.vexnum;i++)
{
for(j=0;j<ga.vexnum;j++)
printf("%3d",ga.arcs[i][j]);
printf("\n");
}
init_visit();
tdfs(&ga);
init_visit();
tbfs(&ga);
return 0;
}
§ 根据右图的结构验证实验,输入:
ABCDEFGH#
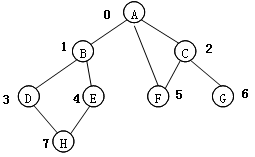 0,1
0,1
0,2
0,5
1,3
1,4
2,5
2,6
3,7
4,7
-1,-1
§ 运行结果:
2、阅读并运行下面程序,补充拓扑排序算法。
#include<stdio.h>
#include<malloc.h>
#define N 20
typedef struct edgenode{ /*图的邻接表:邻接链表结点*/
int adjvex; /*顶点序号*/
struct edgenode *next; /*下一个结点的指针*/
}edgenode;
typedef struct vnode{ /*图的邻接表:邻接表*/
char data; /*顶点信息*/
int ind; /*顶点入度*/
struct edgenode *link; /*指向邻接链表指针*/
}vnode;
void createGraph_list(vnode adjlist[],int *p); /*建立有向图的邻接表*/
void topSort(vnode g[],int n); /*拓扑排序*/
void createGraph_list(vnode adjlist[],int *p){ /*建立有向图的邻接表*/
int i,j,n,e;
char v;
edgenode *s;
i=0;n=0;e=0;
printf("输入顶点序列(以#结束):\n");
while((v=getchar())!='#')
{
adjlist[i].data=v; /*读入顶点信息*/
adjlist[i].link=NULL;
adjlist[i].ind=0;
i++;
}
n=i;
*p=n;
/*建立邻接链表*/
printf("\n请输入弧的信息(i=-1结束):i,j:\n");
scanf("%d,%d",&i,&j);
while(i!=-1){
s=(struct edgenode*)malloc(sizeof(edgenode));
s->adjvex=j;
s->next=adjlist[i].link;
adjlist[i].link=s;
adjlist[j].ind++; /*顶点j的入度加1*/
e++;
scanf("%d,%d",&i,&j);
}
printf("邻接表:");
for(i=0;i<n;i++){ /*输出邻接表*/
printf("\n%c,%d:",adjlist[i].data,adjlist[i].ind);
s=adjlist[i].link;
while(s!=NULL){
printf("->%d",s->adjvex);
s=s->next;
}
}
}
void topSort(vnode g[],int n){ /*拓扑排序*/
}
int main(){
vnode adjlist[N];
int n,*p;
p=&n;
createGraph_list(adjlist,p);
return 0;
}
§ 根据输入,输出有向图的拓扑排序序列。并画出有向图。输入:
ABCDEF#
0,1
1,2
2,3
4,1
4,5
-1,-1
§ 运行结果:
3、阅读并运行下面程序。
#include<stdio.h>
#define N 20
#define TRUE 1
#define INF 32766 /*邻接矩阵中的无穷大元素*/
#define INFIN 32767 /*比无穷大元素大的数*/
typedef struct
{ /*图的邻接矩阵*/
int vexnum,arcnum;
char vexs[N];
int arcs[N][N];
}
graph;
void createGraph_w(graph *g,int flag);
void prim(graph *g,int u);
void dijkstra(graph g,int v);
void showprim();
void showdij();
/*建带权图的邻接矩阵,若flag为1则为无向图,flag为0为有向图*/
void createGraph_w(graph *g,int flag)
{
int i,j,w;
char v;
g->vexnum=0;
g->arcnum=0;
i=0;
printf("输入顶点序列(以#结束):\n");
while((v=getchar())!='#')
{
g->vexs[i]=v; /*读入顶点信息*/
i++;
}
g->vexnum=i;
for(i=0;i<6;i++) /*邻接矩阵初始化*/
for(j=0;j<6;j++)
g->arcs[i][j]=INF;
printf("输入边的信息:\n");
scanf("%d,%d,%d",&i,&j,&w); /*读入边(i,j,w)*/
while(i!=-1) /*读入i为-1时结束*/
{
g->arcs[i][j]=w;
if(flag==1)
g->arcs[j][i]=w;
scanf("%d,%d,%d",&i,&j,&w);
}
}
void prim(graph *g,int u)/*出发顶点u*/
{
int lowcost[N],closest[N],i,j,k,min;
for(i=0;i<g->vexnum;i++) /*求其他顶点到出发顶点u的权*/
{
lowcost[i]=g->arcs[u][i];
closest[i]=u;
}
lowcost[u]=0;
for(i=1;i<g->vexnum;i++) /*循环求最小生成树中的各条边*/
{ min=INFIN;
for(j=0;j<g->vexnum;j++) /*选择得到一条代价最小的边*/
if(lowcost[j]!=0&&lowcost[j]<min)
{
min=lowcost[j];
k=j;
}
printf("(%c,%c)--%d\n",g->vexs[closest[k]],g->vexs[k],lowcost[k]); /*输出该边*/
lowcost[k]=0; /*顶点k纳入最小生成树 */
for(j=0;j<g->vexnum;j++) /*求其他顶点到顶点k 的权*/
if(g->arcs[k][j]!=0&&g->arcs[k][j]<lowcost[j])
{
lowcost[j]=g->arcs[k][j];
closest[j]=k;
}
}
}
void printPath(graph g,int startVex,int EndVex)
{
int stack[N],top=0; /*堆栈*/
int i,k,j;
int flag[N]; /*输出路径顶点标志*/
k=EndVex;
for (i=0;i<g.vexnum;i++) flag[i]=0;
j=startVex;
printf("%c",g.vexs[j]);
flag[j]=1;
stack[top++]=k;
while (top>0) /*找j到k的路径*/
{
for (i=0;i<g.vexnum;i++)
{
if (path[k][i]==1 && flag[i]==0) /*j到k的路径含有i顶点*/
{
if (g.arcs[j][i]!=INF ) /*j到i的路径含有中间顶点*/
{
printf("-> %c(%d) ",g.vexs[i],g.arcs[j][i]);
/*输出j到k的路径的顶点i*/
flag[i]=1;
j=i;
k=stack[--top];
break;
}
else
{
if (i!=k) stack[top++]=i; /*break;*/
}
}
}
}
void dijkstra(graph g,int v){ /*dijkstra算法求单源最短路径*/
int path[N][N],dist[N],s[N];
int mindis,i,j,u,k;
for(i=0;i<g.vexnum;i++){
dist[i]=g.arcs[v][i];
s[i]=0;
for(j=0;j<g.vexnum;j++)
path[i][j]=0;
if(dist[i]<INF){
path[i][v]=1;
path[i][i]=1;
}
}
dist[v]=0;
s[v]=1;
for(i=0,u=1;i<g.vexnum;i++){
mindis=INFIN;
for(j=0;j<g.vexnum;j++)
if(s[j]==0)
if(dist[j]<mindis){
u=j;
mindis=dist[j];
}
s[u]=1;
for(j=0;j<g.vexnum;j++)
if((s[j]==0)&&dist[u]+g.arcs[u][j]<dist[j]){
dist[j]=dist[u]+g.arcs[u][j];
for(k=0;k<g.vexnum;k++)
path[j][k]=path[u][k];
path[j][j]=1;
}
}
printf("\n顶点%c->到各顶点的最短路径\n",g.vexs[v]);
for(i=0;i<g.vexnum;i++){
printf("\n顶点%c->顶点%c:",g.vexs[v],g.vexs[i]);
if(dist[i]==INF||dist[i]==0)
printf("无路径");
else{
printf("%d ",dist[i]);
printf("经过顶点:");
printPath(g,v,i); /*输出v到i的路径*/
}
}
}
void showprim()/*最小生成树prim算法演示*/
{
graph ga;
createGraph_w(&ga,1);
prim(&ga,0);
}
void showdij(){ /*dijstra算法演示*/
graph ga;
createGraph_w(&ga,0);
dijkstra(ga,0);
}
int main(){
showprim(); /*prim算法演示*/
getchar();
showdij(); /*dijstra算法演示*/
return 0;
}
§ 下面的输入分别验证prim算法和dijstra算法。输入实例的第一部分为无向图,求其最小生成树;输入的第二部分为有向图,求其最短路径。
最小生成树 最短路径
ABCDEF#
0,1,6
0,2,1
0,3,5
1,2,5
1,4,3
2,3,5
2,4,6
2,5,4
3,5,2
4,5,6
-1,-1,-1
ABCDEF#
0,2,10
0,5,100
0,4,30
1,2,5
2,3,50
3,4,20
3,5,10
4,3,20
4,5,60
-1,-1,-1
§ 运行结果:(并画出两个图)
最小生成树 最短路径
四、实验小结
五、教师评语
实验六 查找
一、实验目的
1、掌握查找表、动态查找表、静态查找表和平均查找长度的概念。
2、掌握线性表中顺序查找和折半查找的方法。
3、学会哈希函数的构造方法,处理冲突的机制以及哈希表的查找。
二、实验预习
说明以下概念
1、顺序查找:
2、折半查找:
3、哈希函数:
4、冲突及处理:
三、实验内容和要求
1. 静态查找表技术
依据顺序查找算法和折半查找算法的特点,对下面的两个查找表选择一个合适的算法,设计出完整的C源程序。并完成问题:
查找表1 : { 8 ,15 ,19 ,26 ,33 ,41 ,47 ,52 ,64 ,90 } ,查找key = 41
查找表2 : {12 ,76 ,29 ,15 ,62 ,35 ,33 ,89 ,48 ,20 } ,查找key =35
查找key=41的算法: 比较次数:
查找key=35的算法: 比较次数:
l 顺序查找算法算法实现代码
l 折半查找算法算法实现代码
2、哈希表的构造与查找
/* 采用开放地址法构造哈希表*/
#include<stdio.h>
#include<malloc.h>
#define MAXSIZE 25
#define P 13
#define OK 1
#define ERROR 0
#define DUPLICATE -1
#define TRUE 1
#define FALSE 0
typedef struct{ /*哈希表元素结构*/
int key; /*关键字值*/
int flag; /*是否存放元素*/
}ElemType;
typedef struct {
ElemType data[MAXSIZE];
int count; /*元素个数*/
int sizeindex; /*当前哈希表容量*/
}HashTable;
int d1[15]={0,1,2,3,4,5,6,7,8,9,10,11,12,13,14}; /*线性探测序列*/
int d2[15]={0,1,-1,2*2,-2*2,3*3,-3*3,4*4,-4*4,5*5,-5*5,6*6,-6*6,7*7,-7*7}; /*二次探测序列*/
void dataset(int ds[],int *len);
int InsertHash(HashTable *H,int e,int d[]);
int CreateHash(HashTable *H,int ds[],int len,int d[]);
int SearchHash(HashTable *H, int e,int d[]);
void menu();
/*输入查找表*/
void dataset(int ds[],int *len){
int n,m;
n=0;
printf("\n查找表输入:");
while(scanf("%d",&m)==1){ /*以输入一个非整数作为结束*/
ds[n]=m;
n++;
}
*len=n;
}
/*计算哈希地址,插入哈希表*/
int InsertHash(HashTable *H,int e,int d[]){
int k,i=1;
k=e%P;
while(H->data[k].flag==TRUE||k<0){
k=(e%P+d[i])%MAXSIZE;i++;
if(i>=15)
return ERROR;
}
H->data[k].key=e;
H->data[k].flag=TRUE;
H->count++;
return OK;
}
/*构造哈希表*/
int CreateHash(HashTable *H,int ds[],int len,int d[]){
int i;
for(i=0;i<len;i++){
if(SearchHash(H,ds[i],d)!=-1)
return DUPLICATE;
InsertHash(H,ds[i],d);
if(H->count>=MAXSIZE)
return ERROR;
}
return OK;
}
/*初始化哈希表*/
void InitHash(HashTable *H){
int i;
for(i=0;i<MAXSIZE;i++){
H->data[i].key=0;
H->data[i].flag=FALSE;
}
}
/*在哈希表中查找*/
int SearchHash(HashTable *H, int e,int d[]){
int k,i=1;
k=e%P;
while(H->data[k].key!=e){
k=(e%P+d[i])%MAXSIZE;i++;
if(i>=15)
return -1;
}
return k;
}
/*演示菜单*/
void menu(){
int choice;int *p;
HashTable h;
h.count=0;h.sizeindex=MAXSIZE;
int a[MAXSIZE]={0};
int i,n,e;
dataset(a,&n); /*建立查找表*/
getchar();
printf("\n");
do{
printf("\n----哈希查找演示----\n");
printf("\n1.线性探测构造哈希表\n");
printf("\n2.二分探测构造哈希表\n");
printf("\n3.退出\n");
printf("\n输入选择:");
scanf("%d",&choice);
if(choice==1)
p=d1;
else if(choice==2)
p=d2;
else
return;
InitHash(&h); /*初始化哈希表*/
if(!(i=CreateHash(&h,a,n,p))) /*构造哈希表*/
printf("\n哈希表构造失败!\n");
else if(i==DUPLICATE)
printf("\n哈希表具有重复关键字!\n");
else{
printf("\n哈希表:\n");
for(i=0;i<h.sizeindex;i++)
printf("%3d",h.data[i].key);
printf("\n\n哈希查找\n输入要查找的key值:");
getchar();
scanf("%d",&e);
if((i=SearchHash(&h,e,p))==-1)
printf("\n%d未找到\n",e);
else
printf("\n%d在哈希表中下标为%d\n",e,i);
}
getchar();
}while(1);
}
int main(){
menu();
return 0;
}
输入查找表为:19 14 23 1 68 20 84 27 55 11 10 79(注意以输入一个非整数结束)。
运行结果:
1)线性探测散列:
哈希表形态:
84在哈希表中的位置:
2)二次探测散列:
哈希表形态:
84在哈希表中的位置:
四、实验小结
五、教师评语
实验七 排序
一、实验目的
1、掌握内部排序的基本算法;
2、分析比较内部排序算法的效率。
二、实验预习
说明以下概念
1、简单排序:
2、希尔排序:
3、快速排序:
4、堆排序:
三、实验内容和要求
1. 运行下面程序:
#include <stdlib.h>
#include <stdio.h>
#define MAX 50
int slist[MAX]; /*待排序序列*/
void insertSort(int list[], int n);
void createList(int list[], int *n);
void printList(int list[], int n);
void heapAdjust(int list[], int u, int v);
void heapSort(int list[], int n);
/*直接插入排序*/
void insertSort(int list[], int n)
{
int i = 1, j = 0, node = 0, count = 1;
printf("对序列进行直接插入排序:\n");
printf("初始序列为:");
printList(list, n);
for(i = 2; i <= n; i++)
{
node = list[i];
j = i - 1;
while(j >= 0 && node < list[j])
{
list[j+1] = list[j];
--j;
}
list[j+1] = node;
printf("第%d次排序结果:", count++);
printList(list, n);
}
}
/*堆排序*/
void heapAdjust(int list[], int u, int v)
{
int i = u, j , temp = list[i];
j = 2 * i;
while (j <= v)
{
if(j < v && list[j] < list[j+1])
j++; /*若右孩子较大,则把j修改为右孩子的下标*/
if(temp < list[j])
{
list[i] = list[j]; /*将list[j]调到父亲的位置上*/
i = j;
j = 2 * i; /*修改i和j的值,以便继续向下筛选*/
}
else
break; /*筛选完成,终止循环*/
}
list[i] = temp; /*被筛结点的值放入最终位置*/
}
void heapSort(int list[], int n)
{
int i = 0, temp = 0, count = 1;
printf("对序列进行堆排序:\n");
printf("初始序列为:");
printList(list, n);
for (i = n / 2; i > 0; i--)
heapAdjust(list, i, n); /*建立初始堆*/
printf("建立的初始堆为:");
printList(list, n);
for(i = n ; i > 1; i--)
{/*循环,完成堆排序*/
temp = list[1];
list[1] = list[i];
list[i] = temp; /*将第一个元素同当前区间内最后一个元素对换*/
heapAdjust(list, 1 , i-1); /*筛选出list[1]结点*/
printf("第%d次排序结果:", count++);
printList(list, n);
}
}
/*生成待排序序列*/
void createList(int list[], int *n)
{
int i = 1,a;
printf("请输入待排序序列(长度小于50,以输入一个字符结束):\n");
while(scanf("%d",&a)==1)
{
list[i] = a;
i++;
}
*n=i-1;
getchar();
}
/*输出排序结果*/
void printList(int list[], int n)
{
int i = 1;
for(; i <= n; i++)
{
printf(" %d ", list[i]);
if(i % 10 ==0 && i != 0)
printf("\n");
}
printf("\n");
}
int main()
{
int choice=1,length;
while(choice!=0)
{
printf("\n");
printf("***** 内部排序算法演示程序 *****\n");
printf("\n1. 直接插入排序 \n");
printf("\n2. 堆排序 \n");
printf("\n0. 退出\n");
printf("\n请选择:");
scanf("%d", &choice);
getchar();
switch(choice)
{
case 1:
{
createList(slist, &length);
insertSort(slist, length);
break;
}
case 2:
{
createList(slist, &length);
heapSort(slist, length);
break;
}
default:choice=0;
}
printf("\n");
}
return 0;
}
输入待排序序列:49 38 65 97 13 27 49(以输入一个字符作为结束)
1)直接插入排序运行结果(写出每一趟的状态):
2)堆排序运行结果(写出每一趟的状态):
2、在1题中补充希尔排序算法。
算法代码:
输入待排序序列:49 38 65 97 13 27 49(以输入一个字符作为结束)
运行结果(写出每一趟的状态):
3、在1题中补充快速排序算法。
算法代码:
输入待排序序列:49 38 65 97 13 27 49(以输入一个字符作为结束)
运行结果(写出每一趟的状态):
四、实验小结
请比较各个排序算法的性能。