数据结构实验报告
学院:
班级:
姓名:
学号:
实验一 线性链表的实现与操作
题目:设计一个100位以内的长整数加减运算的程序
班级: 姓名: 学号: 完成日期:
一、需求分析
1、 本实验中,100位长整数的每位上的数字必须为数字[0——9]之间,长整数的位数并要求100位以内。测试的时候输入数据,当输入回车键的时候结束输入,如果输入的字符不符合题目要求,则程序能过滤这些不符合要求的字符。
2、演示程序以用户和计算机的对话方式执行,即在计算机显示“提示信息”后之后,由用户在键盘上输入演示程序中规定的运算命令;相应的输入数据(滤去输入中不符合要求的字符)和运算结果显示在其后。
3、程序执行的命令包括:
(1)创建第一个整数(100以内);(2)执行加法或者减法;(3)创建第二个整数(100以内);(4)结束。
二、概要设计
为实现上述程序功能,可以用链表或者长数组表示长整数,如果用数组表示长整数有个缺点就是长整数不能无限长,而链表能动态开辟空间,它克服了这个缺点,所以次试验用链表来表示长整数。
1、链表的抽象数据类型定义为:
ADT Number{
数据对象:D={ai| ai∈(0,1,…,9),i=0,1,2,…,n,n≥0}
数据关系:R={< ai-1, ai >| ai-1, ai∈D,i=1,2,…,n}
基本操作:
CreateList(&L)
操作结果:创建一个链表L。
PrintList(L)
初始条件:链表L已存在。
操作结果:在屏幕上输出链表的值。
PlusList(L1,L2,a)
初始条件:链表L1,L2已存在,a为+ or – 表示加减。
操作结果:将两链表的值相加然后在屏幕上输出。
DestroyList(&L)
初始条件:链表L已存在。
操作结果:销毁链表L。
} ADT Number
2、本程序包含五个模块:
int main(){
定义变量;
接受命令;
处理命令;
return 0;
}
各模块之间的调用关系如下:

 L1 L2
L1 L2

 +or - :
+or - :

L2 L1

 +or -
+or -
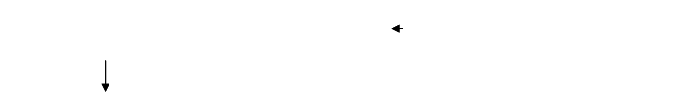
=

L1 L2

三、详细设计
1、定义头文件
#include<stdio.h>
#include<stdlib.h>
#define LEN sizeof(Number)
typedef struct number Number;
struct number
{
int data;
Number *next;
Number *prior;
};
///////////////////////////////////////////////////////////////////////////////////////////////////////
void main()
{
void DestoryList(Number *); //释放链表
void PutNumber(Number *); //将求得的结果输出
Number *GetNumber(); //创建链表,放被加数与加数
Number *JiaFa(Number *num_1,Number *num_2); //加法函数
Number *JianFa(Number *num_1,Number *num_2); //减法函数
Number *number_1,*number_2,*number;
char ch; //存放运算符号
printf("Enter the first long number:");
number_1=GetNumber();
printf("put +or-:");
ch=getchar();
fflush(stdin); //吸收不相关的字符
printf("Enter the second long number:");
number_2=GetNumber();
if(ch=='+')
number=JiaFa(number_1,number_2);
else
if(ch=='-')
number=JianFa(number_1,number_2);
printf("\n=\n");
PutNumber(number);
DestoryList(number);
DestoryList(number_1);
DestoryList(number_2);
printf("链表释放完成。\n");
}
Number *GetNumber() //得到两个链表
{
Number *p,*q,*List;
char ch;
p=(Number *)malloc(LEN);
List=p;
List->prior=NULL;
List->data=0; //加法时,放最高位进的1,否者999+1=000
ch=getchar();
while(ch!='\n')
{
if(ch>='0'&&ch<='9') //过滤非数字字符
{
q=(Number *)malloc(LEN);
q->data=ch-'0';
p->next=q;
q->prior=p;
p=q;
}
ch=getchar();
}
p->next=NULL;
List->prior=NULL;
return List;
} //加法分两种情况长度相同与不同
Number *JiaFa(Number *num_1,Number *num_2) //返回的数据为逆序
{
Number *p,*q,*r,*s,*num=NULL;
int i=0,j=0;
r=num;
p=num_1;
while(p->next!=NULL)
{
i++;
p=p->next;
} //i表示number1数字的长度 p指向number节点
q=num_2;
while(q->next!=NULL)
{
j++;
q=q->next;
} //j表示number2数字的长度 q指向number节点
s=(Number *)malloc(LEN);
s->prior=NULL;
s->next=NULL;
num=s;
while(i--&&j--)
{
s->data=p->data+q->data;
if(s->data>9)
{
s->data-=10; //**处理两数相加大于9的情况,后面还有
if(i>j) //在长的数据上调整
p->prior->data++;
else
q->prior->data++;
}
r=(Number *)malloc(LEN);
s->next=r;
r->prior=s;
s=r;
p=p->prior;
q=q->prior;
}
r=s=s->prior; //去掉最后一个没数据的节点
free(s->next);
s->next=NULL;
if(i>j)
{
while(i--)
{
if(p->data>9)
{
p->data-=10; //**
p->prior->data++;
}
s=(Number *)malloc(LEN);
s->data=p->data;
p=p->prior;
r->next=s;
s->prior=r;
r=s;
}
if(p->data>0) //**
{
s=(Number *)malloc(LEN);
s->data=p->data;
r->next=s;
s->prior=r;
r=s;
}
}
else
{
while(j--)
{
if(q->data>9) //**
{
q->data-=10;
q->prior->data++;
}
s=(Number *)malloc(LEN);
s->data=q->data;
q=q->prior;
r->next=s;
s->prior=r;
r=s;
}
if(q->data>0) //**
{
s=(Number *)malloc(LEN);
s->data=q->data;
r->next=s;
s->prior=r;
r=s;
}
}
s->next=NULL; //将最后一个next置空
return num;
} //减法分3中情况:被减数长度大于、小于、等于减数长度
Number *JianFa(Number *num_1,Number *num_2) //返回的数据也为逆序
{
Number *p,*q,*r,*s,*num=NULL;
int i=0,j=0;
r=num;
p=num_1;
while(p->next!=NULL) //i表示number1数字的长度 p指向number节点
{
i++;
p=p->next;
}
q=num_2;
while(q->next!=NULL) //j表示number2数字的长度 q指向number节点
{
j++;
q=q->next;
}
s=(Number *)malloc(LEN);
s->prior=NULL;
s->next=NULL;
num=s;
if(i<j) //对于被减数长度小于减数的,用减数减去被减数,最后反号
{
while(i--)
{
s->data=q->data-p->data;
if(s->data<0) //**
{
s->data+=10;
q->prior->data--;
}
r=(Number *)malloc(LEN);
s->next=r;
r->prior=s;
s=r;
p=p->prior;
q=q->prior;
j--; //使i,j同时变化
}
r=s=s->prior; //去掉最后一个没数据的节点
free(s->next);
s->next=NULL;
while(j--)
{
if(q->data<0) //**
{
q->data+=10;
q->prior->data--;
}
s=(Number *)malloc(LEN);
s->data=q->data;
q=q->prior;
r->next=s;
s->prior=r;
r=s;
}
s->data=0-s->data; //反号,因为节点里不能放符号,而直接在最高位前加负号最简单
s->next=NULL;
}
else
if(i==j)
{
i=j=1;
p=num_1;q=num_2;
while(p->data==q->data)
{
p=p->next;
q=q->next;
}
num_1=(Number *)malloc(LEN);
num_1->prior=NULL;
num_1->data=0;
num_1->next=p;
num_2=(Number *)malloc(LEN);
num_2->prior=NULL;
num_2->data=0;
num_2->next=q;
while(p->next!=NULL) //i表示number1数字的长度 p指向number节点
{
i++;
p=p->next;
}
q=num_2;
while(q->next!=NULL) //j表示number2数字的长度 q指向number节点
{
j++;
q=q->next;
}
if(num_1->next->data>num_2->next->data)
{
while(i--)
{
s->data=p->data-q->data;
if(s->data<0) //**
{
s->data+=10;
p->prior->data--;
}
r=(Number *)malloc(LEN);
s->next=r;
r->prior=s;
s=r;
p=p->prior;
q=q->prior;
}
r=s=s->prior; //去掉最后一个没数据的节点
free(s->next);
while(s->data==0&&s->prior!=NULL) //去掉前面多余的0,否则111112-111111=000001
{
s=s->prior;
free(s->next);
}
}
if(num_1->next->data<num_2->next->data)
{
while(i--)
{
s->data=q->data-p->data;
if(s->data<0) //**
{
s->data+=10;
q->prior->data--;
}
r=(Number *)malloc(LEN);
s->next=r;
r->prior=s;
s=r;
p=p->prior;
q=q->prior;
}
r=s=s->prior; //去掉最后一个没数据的节点
free(s->next);
while(s->data==0&&s->prior!=NULL) //去掉前面多余的0,否则111112-111111=000001
{
s=s->prior;
free(s->next);
}
}
s->data=0-s->data; //反号,因为节点里不能放符号,而直接在最高位前加负号最简单
s->next=NULL;
}
else
if(i>j)
{
while(j--)
{
s->data=p->data-q->data;
if(s->data<0) //**
{
s->data+=10;
p->prior->data--;
}
r=(Number *)malloc(LEN);
s->next=r;
r->prior=s;
s=r;
p=p->prior;
q=q->prior;
i--;
}
r=s=s->prior; //去掉最后一个没数据的节点
free(s->next);
s->next=NULL;
while(i--)
{
if(p->data<0) //**
{
p->data+=10;
p->prior->data--;
}
s=(Number *)malloc(LEN);
s->data=p->data;
p=p->prior;
r->next=s;
s->prior=r;
r=s;
}
while(s->data==0&&s->prior!=NULL)//去掉前面多余的0,否则1000-1=0999
{
s=s->prior;
free(s->next);
}
// s->data=0-s->data; //反号,因为节点里不能放符号,而直接在最高位前加负号最简单
s->next=NULL;
}
return num;
}
void PutNumber(Number *num) //链表的合并
{
Number *p;
int k=1,i; //k为数据长度,i控制‘,’
p=num;
while(p->next!=NULL)
{
p=p->next;
k++;
}
i=4-k%4;
while(k--)
{
i++;
printf("%d",p->data);
p=p->prior;
if(k!=0&&i%4==0) //长度为k的数据,在k%4个数字后开始输出‘,’数据输出完后不输出‘,’
putchar(',');
}
putchar('\n');
}
void DestoryList(Number *list) //销毁链表
{
Number *p,*q;
p=list;
while(p)
{
q=p->next;
free(p);
p=q;
}
}
四、调试分析
1、这个程序是看了原模版的分析才了解到具体是怎样去存储长整数。进位的部分很纠结,不知道用什么去移动,然后才知道直接用指针去操作就好了。
2、本程序有些代码重复出现,影响了代码的编译效率。
3、本程序模块划分比较合理,且把指针全部封装在链表模块中,操作方便。
五.运行结果

六、实验环境
(1)Win8系统,兼容
(2)编程环境:VC6.0++简体中文版
七、实验体会
通过此次实验,我理解了线性链表的逻辑结构和链式存储结构并一定程度的掌握了线性链表的基本操作及应用。这是一个培养学生灵活使用结构解决实际问题的能力。开始想的是要用数组去存储长整数,但是看过实验报告的模版后,了解到原来还可以用链表来存如此大的长整数。这个思路很大的启发了我。觉得以后编程时也是可以运用的一种重要思想。
而且我了解到,在编写程序的时候养成良好编程风格很重要,这样可以使以后自己或者他人阅读这个程序的难度大大降低。
实验二 栈和队列的应用
题目:利用队列宽度优先进行迷宫求解
班级: 姓名: 学号: 完成日期:
一、需求分析
1.本实验中,要求用数组表示迷宫,并建立队列,利用队列实现宽度优先搜索。从而得到迷宫的解。
2. 队列是顺序存储结构,其存储结构示意图如下:
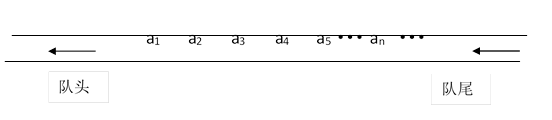
3、程序执行的命令包括:
(1)输出迷宫,并介绍迷宫规则;(2)输入测试数据;(3)输出迷宫解答方案;
4、测试数据
Please input the start point:
0 0
Wrong start point,please input again:
2 3
Output: 图示;
2、算法概要设计
1.建立如下函数,抽象数据类型定义为:
ADT sqllist{
void EnterQ(int i,int j,int k);定义一个入队的函数
void DelectQ(int *i,int *j,int *k);获取当前结点的序号和对应的迷宫坐标,然后出列,返回函数值;
bool GetNextPos(int *i ,int *j,int count);布尔值,得到下一个邻接点的位置。
void ShortestPath_BFS(int i,int j);利用广度优先遍历寻找最短路径的函数;
void ShortestPath();输出最短路径
}
2.
函数声明;
void main(){
初始化;
建立变量;
调用函数;
}
本程序分为以下三个模块:
 变量声明模块
变量声明模块
调用
构建函数模块
调用
主程序模块;
三、 详细设计
#include<iostream.h>
void EnterQ(int i,int j,int k); //定义一个入队的函数
void DelectQ(int *i,int *j,int *k); //出列函数,获取当前结点的序号和对应的迷宫坐标,然后出列,返回函数值
bool GetNextPos(int *i ,int *j,int count); //布尔值,得到下一个邻接点的位置。
void ShortestPath_BFS(int i,int j); //利用广度优先遍历寻找最短路径的函数
void ShortestPath(); //输出最短路径
void Print();
int Map[10][10] = {{1,1,1,1,1,1,1,1,1,1},
{1,0,0,1,0,0,0,1,0,1},
{1,0,0,1,0,0,0,1,0,1},
{1,0,0,0,0,1,1,0,0,1},
{1,0,1,1,1,0,0,0,0,1},
{1,0,0,0,1,0,0,0,0,1},
{1,0,1,0,0,0,1,0,0,1},
{1,0,1,1,1,0,1,1,0,1},
{1,1,0,0,0,0,0,0,0,0},
{1,1,1,1,1,1,1,1,1,1}};
struct Node
{
int parent_id; //保存父结点的位置
int node_id; //当前结点的序号
int x,y; //当前结点对应的坐标
}Q[10*10];
int front = 0,rear = 0; //队列头指针和尾指针
void main()
{
cout<<"progamming introduce:"<<'\n'<<"1.output the shortest path;"<<'\n'<<"2.the exit is at the right botom,adjust it if you like."<<'\n'<<'\n';
cout<<"start maps:"<<endl;
Print();
int i,j;
reinput:
cout<<"please input the start point(x,y)[example:x y]:"<<endl;
cin>>i>>j;
if(Map[i][j])
{cout<<"Wrong start point,please input again!"<<endl;goto reinput;}
ShortestPath_BFS(i,j);
cout<<"the shortest path to get out:"<<endl;
ShortestPath();
}
void EnterQ(int i,int j,int k)
{
Q[rear].x = i;
Q[rear].y = j; //保存当前结点对应的坐标位置
Q[rear].parent_id = k; //保存父结点的序号
Q[rear].node_id = rear; //保存当前结点序号
rear++;
}
void DelectQ(int *i,int *j,int *k)
{
*i = Q[front].x;
*j = Q[front].y;
*k = Q[front].node_id;
front++; //一个节点出列
}
bool GetNextPos(int *i ,int *j,int count)
{
switch(count)
{
case 1:(*j)++; return 1; //向右走
case 2:(*i)++; return 1; //向下走
case 3:(*j)--; return 1; //向左走
case 4:(*i)--; return 1; //向上走
default: return 0;
}
}
void ShortestPath_BFS(int i ,int j)
{
int count,m,n,k;
EnterQ(i,j,-1); Map[1][1] = 1; //入队起点,标记已走过的起点
while(true)
{
count = 1;
DelectQ(&i,&j,&k);
n = i,m = j;
while(GetNextPos(&i,&j,count))
{
count++;
if(!Map[i][j])
{
EnterQ(i,j,k); Map[i][j] = 1;
if(i == 8 && j == 9) return; //到达终点,(8,9)是默认终点,可以任意修改
}
i = n; j = m; //遍历当前坐标的所有相邻位置
}
}
}
void ShortestPath()
{
int i,j,k,sum(0) ;
k = rear-1;
while(k != -1)
{
i = Q[k].x; j = Q[k].y;
Map[i][j] = 2;
k = Q[k].parent_id;
}
cout<<" 0 1 2 3 4 5 6 7 8 9"<<endl;
for(i = 0;i < 10;i++)
{
cout<<i;
for(j = 0;j < 10;j++)
if(Map[i][j]==2)
{sum++; cout<<"■";}
else
cout<<"□";
cout<<endl;
}
cout<<"最短路径长度:"<<sum<<endl;
}
void Print()
{
cout<<" 0 1 2 3 4 5 6 7 8 9"<<endl;
for(int i = 0;i < 10;i++)
{
cout<<i;
for(int j = 0;j < 10;j++)
if(Map[i][j]) cout<<"□";
else cout<<"■";
cout<<endl;
}
}
四.程序调试
1.对迷宫图进行了测试,用点(0,0),(4,2)(2,2)作为起点,在终点位置相同的情况下进行了测试,看程序运行后输出的结果是否正确。
测试结论:对于测试地图在不同起始位置输出完全正确。
2.测试时也有输入错误的数据,结果显示可以判别出来。
五、运行结果
截图如下:
1.初始界面:
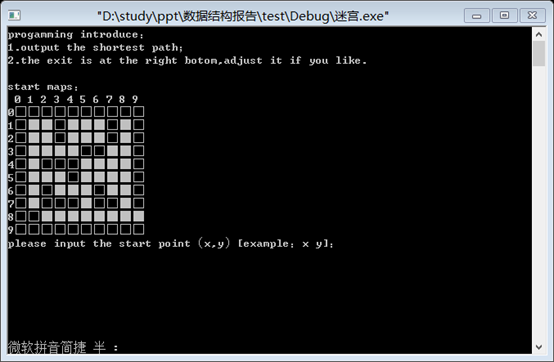
2.输入错误的起点时:
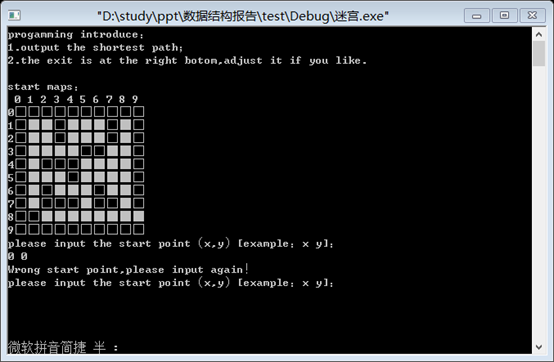
3.输入正确的起点时:

给出了正确走出迷宫的路径。
六.实验环境
1.win8操作系统,兼容。
2.vc++6.0简体中文版
七、实验体会
这个迷宫的实验很有意思,虽然代码是在网上找到的,但是我了解了算法。并在此次编程中体会到了运用的乐趣。由于不太理解代码的含义,当初编译时有很多错误,调试了很长时间。
第一次运行这个程序是在c-free5上,可能由于mingw编译器与vc不同,有很多不能识别的c语言keywords出现,导致不能执行代码。至此,我知道了不同的编译器所支持的语言标准或是库函数是有一定差异的。
实验三: 二叉树的实现及遍历
题目:二叉树的实现与遍历
班级: 姓名: 学号: 完成日期:
一、需求分析
1.本实验要求构建二叉树,并完成二叉树的先序、中序和后序以及按层次遍历的操作,求所有叶子及结点总数的操作。
2.输出树的深度,最大元,最小元。
3.了解二叉树的特点及其存储结构。
二、概要设计
1.二叉树的抽象数据类型定义为:
ADT BinaryTree{
D:D是具有相同特性的数据元素的集合
R:若D为空集,则R也为空,称BinaryTree为空二叉树
若D不为空集,则R={H},H是如下二元关系:

p:
InitBiTree(&T);
DestoryBiTree(&T);
CreateBiTree(&T, definiation);
ClearBiTree(&T); //将树清为空树
BiTreeEmpty(T); //判断树是否为空
BiTreeDepth(T); //返回树的深度
Root(T); //返回树的根
Value(T, e); //取出结点e的值
Assign(T, &e, value); //给结点e赋值为value
Parent(T, e); //若e为根结点返回空,否则返回其双亲
LeftChild(T, e); //返回e的左孩子,若e无左孩子返回空
RightChild(T, e); //返回e的右孩子,若e无右孩子返回空
LeftSibling(T, e); //返回e的左兄弟,若e是T的左孩子或无左兄弟返回空
RightSibling(T, e); //返回e的右兄弟,若e是T的右孩子或无右兄弟返回空
InsertChild(&T, &p, LR, c); //根据LR为0或1,插入c为T中p指结点的左或右子树,p所指结点的原有左或右子树则成为c的右子树
DeleteChild(&T, &p, LR); //根据LR为0或1,删除T中p所指结点的左或右子树
PreOrderTraverse(T, visit()); //先序遍历T
InOrderTraverse(T, visit()); //中序遍历T
PostOrderTraverse(T, visit()); //后序遍历T
LevelOrderTraverse(T, visit()); //层序遍历T
}ADT Tree;
2.基本操作:
函数定义;
void mian(){
初始化;
接受命令;
处理命令;
}
3.各模块间关系如下:
 二叉树的构建
二叉树的构建

 主程序模块 二叉树的遍历
主程序模块 二叉树的遍历

Info的输出
三.详细设计
1.定义头文件
#include<stdio.h>
#include<string.h>
#include<malloc.h>
#define Max 30 //宏定义,设置结点的最大个数
2.构建二叉树结构
typedef struct node{
char data;
struct node *lchild,*rchild;
}BinTNode; //自定义二叉树的结点类型
typedef BinTNode *BinTree; //定义二叉树的指针
int NodeNum,leaf; //NodeNum为结点数,leaf为叶子数
3.基于先序遍历算法创建二叉树
BinTree CreatBinTree(void)
{
BinTree T;
char ch;
if((ch=getchar())=='#')
return(NULL); else{
T=(BinTNode *)malloc(sizeof(BinTNode)); //生成结点
T->data=ch;
T->lchild=CreatBinTree(); //构造左子树
T->rchild=CreatBinTree(); //构造右子树
return(T);
}
}//要求输入先序序列,其中加入虚结点"#"以示空指针的位置
void Preorder(BinTree T)
{
if(T)
{
printf("%c",T->data);
Preorder(T->lchild);
Preorder(T->rchild);
}
}//NLR先序
void Inorder(BinTree T)
{
if(T)
{
Inorder(T->lchild);
printf("%c",T->data);
Inorder(T->rchild);
}
}//LNR中序
void Postorder(BinTree T)
{
if(T)
{
Postorder(T->lchild);
Postorder(T->rchild);
printf("%c",T->data);
}
} //LRN后序
4.采用后序遍历求二叉树的深度、结点数及叶子数:递归算法
int TreeDepth(BinTree T)
{
int hl,hr,max;
if(T)
{
hl=TreeDepth(T->lchild);
hr=TreeDepth(T->rchild);
max=hl>hr? hl:hr; //depth(T)=max{depth(LT),depth(RT)}
NodeNum=NodeNum+1;
if(hl==0&&hr==0)
leaf=leaf+1; //若左右深度为0,即为叶子。
return(max+1);
}
else return(0);
}
void Levelorder(BinTree T)
{
int front=0,rear=1;
BinTNode *cq[Max],*p; //定义结点的指针数组cq
cq[1]=T; //根入队
while(front!=rear)
{
front=(front+1)%NodeNum;
p=cq[front]; //出队
printf("%c",p->data); //出队,输出结点的值
if(p->lchild!=NULL)
{
rear=(rear+1)%NodeNum;
cq[rear]=p->lchild; //左子树入队
}
if(p->rchild!=NULL)
{
rear=(rear+1)%NodeNum;
cq[rear]=p->rchild; //右子树入队
}
}
}//利用栈实现二叉树的层次遍历
5.主函数
void main()
{
BinTree root;
int i,depth;
printf("\n");
printf("Creat Bin_Tree; Input preorder:"); //输入完全二叉树的先序序列,
// 用#代表虚结点,如ABD###CE##F##
root=CreatBinTree(); //创建二叉树,返回根结点
do { //从菜单中选择遍历方式,输入序号。
printf("\t********** select ************\n");
printf("\t1: Preorder Traversal\n");
printf("\t2: Iorder Traversal\n");
printf("\t3: Postorder traversal\n");
printf("\t4: PostTreeDepth,Node number,Leaf number\n");
printf("\t5: Level Depth\n"); //按层次遍历之前,先选择4,求出该树的结点数。
printf("\t0: Exit\n");
printf("\t*******************************\n");
scanf("%d",&i); //输入菜单序号(0-5)
switch (i)
{
case 1:
printf("Print Bin_tree Preorder: ");
Preorder(root); //先序遍历
break;
case 2:
printf("Print Bin_Tree Inorder: ");
Inorder(root); //中序遍历
break;
case 3:
printf("Print Bin_Tree Postorder: ");
Postorder(root); //后序遍历
break;
case 4:
depth=TreeDepth(root); //求树的深度及叶子数
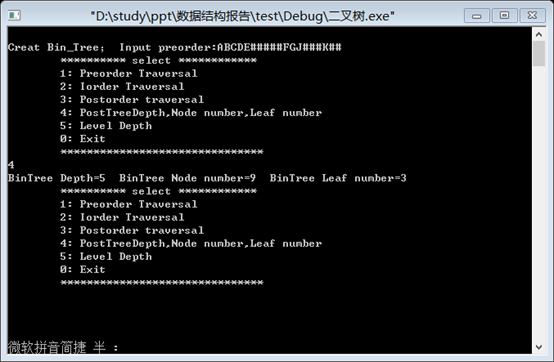
printf("BinTree Depth=%d BinTree Node number=%d",depth,NodeNum);
printf(" BinTree Leaf number=%d",leaf);
break;
case 5:
printf("LevePrint Bin_Tree: ");
Levelorder(root); //按层次遍历
break;
default:
exit(1);
}
printf("\n");
} while(i!=0);
}
四.调试分析
1.先输入abc##cd#f##(最后一个#代表结束),发现不能继续输入下面的程序了。解决方案:一个#代表前面数字所对应的一个结点,所以要让输入的结点数与#对应,并让每个结点的info项对应。再次进行测试,程序正常运行。
五.运行结果
1. 按先序遍历的顺序,输入测试二叉树ABCDE#####FGJ##K##: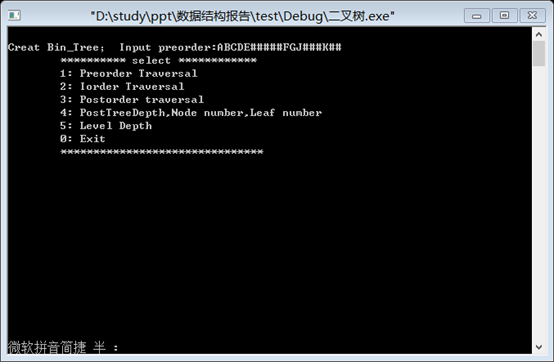
2. 测试先序.中序遍历,其预计结果分别为:ABCDEFGJK; DEDCBAJGFK
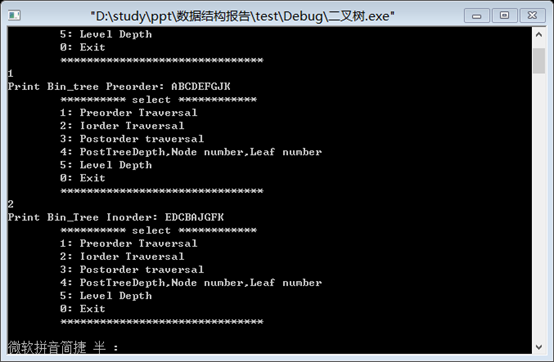
3. 测试后序,层次遍历,预计结果分别为:EDBJKFA; ABCDEFGJK
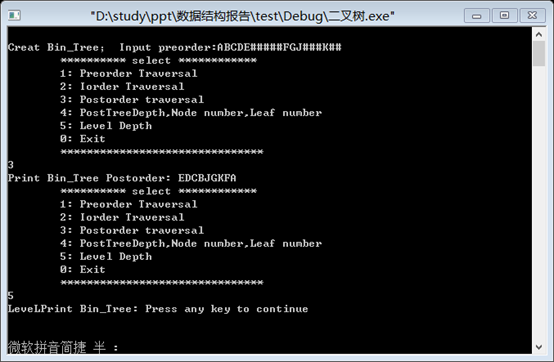
4. 输出该二叉树的深度,节点数,叶子树:
五、实验环境
(1)Win8系统,兼容模式
(2)编程环境:VC6.0++
六、实验体会
通过本次试验我了解二叉树的结构,深度,叶子,左右子树的定义。然后我认识到了树的遍历算法:先序遍历(NLR).中序遍历(LNR).后序遍历(LRN)。在一定程度上掌握了二叉树的定义、结构特征,以及各种存储结构的特点及使用范围。并能运用指针去描述,构建二叉树,处理二叉树的相关问题。
实验四 图的实现及遍历
题目:图的实现与遍历
班级: 姓名: 学号: 完成日期:
一、需求分析
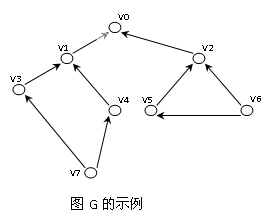
1.在客观世界和计算机程序设计中应用广泛如网络、可应用于语言学、逻辑学、计算机科学、电讯工程等。
2. 采用邻接矩阵作为图的存储结构,完成有向图和无向图的DFS和BFS操作;
3. 采用邻接链表作为图的存储结构,完成有向图和无向图的DFS和BFS操作。4.图的定义:图是非线性结构之一。元素间的关系是任意的,图中任意两个数据元素之间都可能相关(线性结构中元素间具有前驱/后继的线性关系,树形结构中元素间具有层次关系)。
二、概要设计
1.图的抽象数据定义为:
ADT Graph{
D:D是具有相同特性的数据元素的集合,称为顶点集
R:R={VR}
VR={<v,w>|v,w V且P(v,w), <v,w>表示从v到w的弧,
P(v,w)则定义了弧<v,w>的意义或信息}
P:
CreateGraph(&G, V, VR) 建立一个图
DestoryGraph(&G) 销毁一个图
LocateVex(G,u) 定义有向图
GetVex(G,v) 获得点的信息
PutVex(&G,v,value) 输出点的信息
FirstAdjVex(G,v)
NextAdjVex(G, v, w)
InsertVex(&G, v) 插入一个点
DeleteVex(&G, v) 销毁一个点
InsertArc(&G, v, w)
DeleteArc(&G, v, w)
DFSTraverse(G, v, Visit())
BFSTraverse(G, v, Visit())
}ADT Graph;
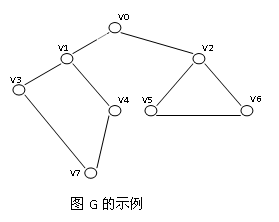
3.测试数据:
1)以邻接矩阵
2)以邻接链表:(构成有向图)
三、详细设计
1. 邻接矩阵作为存储结构的程序:
1.定义头文件
#include<stdio.h>
#include<stdlib.h>
#define MaxVertexNum 100 //定义最大顶点数
2.定义邻接矩阵,表示图的类型
typedef struct{
char vexs[MaxVertexNum];
int edges[MaxVertexNum][MaxVertexNum]; //邻接矩阵,存储边的信息
int n,e; //图中的顶点数n和边数e
}MGraph;
3.建立邻接矩阵
void CreatMGraph(MGraph *G)
{
int i,j,k;
char a;
printf("Input VertexNum(n) and EdgesNum(e): ");
scanf("%d,%d",&G->n,&G->e);
scanf("%c",&a);
printf("Input Vertex string:");
for(i=0;i<G->n;i++)
{
scanf("%c",&a);
G->vexs[i]=a; //读入顶点信息,建立数组
}
for(i=0;i<G->n;i++)
for(j=0;j<G->n;j++)
G->edges[i][j]=0; //初始化邻接矩阵
printf("Input edges,Creat Adjacency Matrix\n");
for(k=0;k<G->e;k++) { //读入e条边,建立邻接矩阵
scanf("%d%d",&i,&j); //输入边(Vi,Vj)的顶点序号
G->edges[i][j]=1;
G->edges[j][i]=1; //若为无向图,矩阵为对称矩阵;若建立有向图,去掉该条语句
}
}
4.建立dfs,bfs遍历算法函数
typedef enum{FALSE,TRUE} Boolean; //定义标志向量,为全局变量
Boolean visited[MaxVertexNum];
void DFSM(MGraph *G,int i)
{ int j;
printf("%c",G->vexs[i]); //访问顶点Vi
visited[i]=TRUE; //标志已访问过的点
for(j=0;j<G->n;j++) //依次搜索Vi的邻接点
if(G->edges[i][j]==1 && ! visited[j])
DFSM(G,j); //(Vi,Vj)∈E,且Vj未访问过,故Vj为新出发点
}//以Vi为出发点对邻接矩阵表示的图G进行DFS搜索,邻接矩阵是0,1矩阵
void DFS(MGraph *G)
{
int i;
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
if(!visited[i])
DFSM(G,i); //如果Vi未访问过,则以Vi为源点开始DFS搜索
}//DFS:深度优先遍历
void BFS(MGraph *G,int k)
{ //以Vk为源点对用邻接矩阵表示的图G进行广度优先搜索
int i,j,f=0,r=0;
int cq[MaxVertexNum]; //定义队列
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
cq[i]=-1; //队列初始化
printf("%c",G->vexs[k]); //访问源点Vk
visited[k]=TRUE;
cq[r]=k; //Vk已访问,将其入队。注意,实际上是将其序号入队
while(cq[f]!=-1) { //队非空则执行
i=cq[f]; f=f+1; //Vf出队
for(j=0;j<G->n;j++) //依次Vi的邻接点Vj
if(G->edges[i][j]==1 && !visited[j]) { //Vj未访问
printf("%c",G->vexs[j]); //访问Vj
visited[j]=TRUE;
r=r+1; cq[r]=j; //访问过Vj入队
}
}
}//BFS:广度优先遍历
5.主函数
void main()
{
int i;
MGraph *G;
G=(MGraph *)malloc(sizeof(MGraph)); //为图G申请内存空间
CreatMGraph(G); //建立邻接矩阵
printf("Print Graph DFS: ");
DFS(G); //深度优先遍历
printf("\n");
printf("Print Graph BFS: ");
BFS(G,3); //以序号为3的顶点开始广度优先遍历
printf("\n");
}
2、邻接链表作为存储结构程序示例
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#define MaxVertexNum 50
typedef struct node{ //边表结点
int adjvex; //邻接点域
struct node *next; //链域
}EdgeNode;
typedef struct vnode{ //顶点表结点
char vertex; //顶点域
EdgeNode *firstedge; //边表头指针
}VertexNode;
typedef VertexNode AdjList[MaxVertexNum]; //AdjList是邻接表类型
typedef struct {
AdjList adjlist; //邻接表
int n,e; //图中当前顶点数和边数
} ALGraph;
2. 建立图的邻接表
void CreatALGraph(ALGraph *G)
{
int i,j,k;
char a;
EdgeNode *s; //定义边表结点
printf("Input VertexNum(n) and EdgesNum(e): ");
scanf("%d,%d",&G->n,&G->e); //读入顶点数和边数
scanf("%c",&a);
printf("Input Vertex string:");
for(i=0;i<G->n;i++) //建立边表
{
scanf("%c",&a);
G->adjlist[i].vertex=a; //读入顶点信息
G->adjlist[i].firstedge=NULL; //边表置为空表
}
printf("Input edges,Creat Adjacency List\n");
for(k=0;k<G->e;k++) { //建立边表
scanf("%d%d",&i,&j); //读入边(Vi,Vj)的顶点对序号
s=(EdgeNode *)malloc(sizeof(EdgeNode)); //生成边表结点
s->adjvex=j; //邻接点序号为j
s->next=G->adjlist[i].firstedge;
G->adjlist[i].firstedge=s; //将新结点*S插入顶点Vi的边表头部
s=(EdgeNode *)malloc(sizeof(EdgeNode));
s->adjvex=i; //邻接点序号为i
s->next=G->adjlist[j].firstedge;
G->adjlist[j].firstedge=s; //将新结点*S插入顶点Vj的边表头部
}
}
typedef enum{FALSE,TRUE} Boolean;
Boolean visited[MaxVertexNum];
void DFSM(ALGraph *G,int i)
{ //以Vi为出发点对邻接链表表示的图G进行DFS搜索
EdgeNode *p;
printf("%c",G->adjlist[i].vertex); //访问顶点Vi
visited[i]=TRUE; //标记Vi已访问
p=G->adjlist[i].firstedge; //取Vi边表的头指针
while(p) { //依次搜索Vi的邻接点Vj,这里j=p->adjvex
if(! visited[p->adjvex]) //若Vj尚未被访问
DFSM(G,p->adjvex); //则以Vj为出发点向纵深搜索
p=p->next; //找Vi的下一个邻接点
}
}
void DFS(ALGraph *G)
{
int i;
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
if(!visited[i]) //Vi未访问过
DFSM(G,i); //以Vi为源点开始DFS搜索
}//DFS:深度优先遍历的递归算法
void BFS(ALGraph *G,int k) {
//以Vk为源点对用邻接链表表示的图G进行广度优先搜索
int i,f=0,r=0; EdgeNode *p;
int cq[MaxVertexNum]; //定义FIFO队列
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<=G->n;i++)
cq[i]=-1; //初始化标志向量
printf("%c",G->adjlist[k].vertex); //访问源点Vk
visited[k]=TRUE;
cq[r]=k; //Vk已访问,将其入队。注意,实际上是将其序号入队
while(cq[f]!=-1) { //队列非空则执行
i=cq[f]; f=f+1; //Vi出队
p=G->adjlist[i].firstedge; //取Vi的边表头指针
while(p) { //依次搜索Vi的邻接点Vj(令p->adjvex=j)
if(!visited[p->adjvex]) { //若Vj未访问过
printf("%c",G->adjlist[p->adjvex].vertex); //访问Vj
visited[p->adjvex]=TRUE;
r=r+1; cq[r]=p->adjvex; //访问过的Vj入队
}
p=p->next; //找Vi的下一个邻接点
}
}//endwhile
} //BFS:广度优先遍历
3.主函数
void main()
{
int i;
ALGraph *G;
G=(ALGraph *)malloc(sizeof(ALGraph));
CreatALGraph(G);
printf("Print Graph DFS: ");
DFS(G);
printf("\n");
printf("Print Graph BFS: ");
BFS(G,3);
printf("\n");
}
五.运行结果
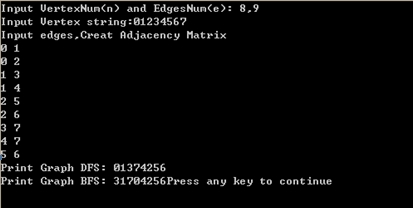
1. 采用邻接矩阵作为图的存储结构,进行的测试:
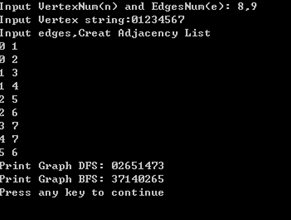
2.采用邻接链表作为图的存储结构,进行测试:
六、实验环境
(1)Win8系统,兼容
(2)编程环境:VC++ 6.0简体中文版
七、实验体会
通过此次实验,我掌握了有向图和无向图的概念;掌握邻接矩阵和邻接链表建立图的存储结构。了解了图的基本存储方法,有关图的操作算法。而且还熟悉了图的各种存储结构及其构造算法,并掌握DFS及BFS对图的遍历操作和过程。
实验五 查找算法的实现及比较
题目:查找算法的实现及比较
班级: 姓名:姚尧 学号: 完成日期:
一、需求分析
1) 有序表的二分查找
? 建立有序表,然后进行二分查找
2) 二叉排序树的查找
? 建立二叉排序树,然后查找
二、概要设计
1.查找:在表中根据关键字找出特定的数据元素的操作,返回对应数据元素在查询表中的位置。如果表中没有该对应的元素,则返回空记录或空指针
2.查找分类:1)静态查找:查找表事先已确定。对查询表除了创建和销毁操作外,只有查找或遍历操作
2)动态查找:查找表本身在查找过程中动态生成,即若没有找到,则插入该元素。对查询表除了创建、销毁、查找、遍历操作外,还能进行插入和删除操作
3)有序表查找(折半查找):要求查找表中的数据元素已按关键字值排序。只适用于有序表且限于顺序存储结构(不能用于链表存储结构)。
3.二叉排序树及二叉排序树的特点:通过中序遍历二叉排序树可得到一个含有关键字的有序序列。具有相同n个结点的二叉排序树会因为构造的时候关键字插入的顺序不同而不同。二叉排序树的查找算法具有折半查找的特性,同时又采用了链式存储结构,因此是动态查找表的适宜表示。
三、详细设计
1.定义头文件
#include<stdlib.h>
#include<stdio.h>
2.建立有序列表
typedef struct {
int key;
}elemType; //自定义结构体类型
typedef struct{
elemType* init;
int length;
}SSTable;
2.建立一个有序表
int createSTable(SSTable *t, int len)
{
int i;
if(!(t->init = (elemType*) malloc(sizeof(elemType)*len)))
return -1;
t->length = len;
printf("输入有序表的序列值:\n");
for(i = 0; i < t->length; ++i)
scanf("%d",&t->init[i].key);
} //在有序表中查找关键字
int BinarySearch(SSTable* t, int key){
int low = 0,high = t->length-1,mid;
while(low <= high){ //保证区间长度大于或者等于0
mid = (low+high)/2;
if(t->init[mid].key == key)
return mid;
else if(t->init[mid].key < key)
low = mid +1;
else
high = mid -1;
}
return -1; //未查找到key在表中的下标返回-1
}
3.测试函数
int main(void)
{
int n,key;
SSTable t;
printf("please input the length of the orderlist:\n");
scanf("%d",&n);
createSTable(&t,n);
do{
printf("input the key words:\n");
scanf("%d",&key);
printf("the underclass symbol of keyis:%d",++BinarySearch(&t,key));
system("pause");
}while(getchar()!=‘#’);
return 0;
}
2. 建立二叉排序树,然后查找 .
1)定义头文件
#include<stdio.h>
#include<string.h>
#include<malloc.h>
2)变量声明,函数声明
typedef struct node{
int key;
struct node *lchild,*rchild;
}BSTNode;
typedef BSTNode *BSTree; //BSTree是二叉排序树的类型
void InsertBST(BSTree *Tptr,int k)
{
BSTNode *f,*p=*Tptr;
while(p){
if(p->key==k)
return; //树中已有k,无须插入
f=p; //f保存当前查找的结点
p=(k<p->key)? p->lchild:p->rchild;
//若k小于p->key,则在左子树中查找,否则在右子树中查找。
}
p=(BSTNode *)malloc(sizeof(BSTNode));
p->key=k; p->lchild=p->rchild=NULL; //生成新结点
if(*Tptr==NULL) //原树为空,新插入的结点为新的根
*Tptr=p;
else //原树不空时,将新结点*p作为*f的左孩子插入
if(k<f->key)
f->lchild=p;
else
f->rchild=p;
} //将K插入二叉排序树(BST)中,生成二叉排序树
BSTree CreatBST(void)
{
BSTree T=NULL;
int k;
scanf("%d",&k); //读入一个关键字
while(k){
InsertBST(&T,k); //将k插入二叉排序树T
scanf("%d",&k);
}
return T; //返回建立的二叉排序树的根指针
}//输入一个结点序列,建立一棵二叉排序树,将根结点指针返回。
BSTNode *SearchBST(BSTree T,int k)
{
if(T==NULL||k==T->key)
return T; //若T为空,查找失败;否则成功,返回找到的结点位置
if(k<T->key) //若k小于T->key在左子树上找;否则在右子树上找。
return SearchBST(T->lchild,k);
else
return SearchBST(T->rchild,k);
}//二叉排序树上的查找,成功时返回该结点的位置,否则返回NULL
void Preorder(BSTree T)
{
if(T) {
printf("%4d",T->key);
Preorder(T->lchild);
Preorder(T->rchild);
}
}
3.主函数测试
void main()
{
BSTree root,P;
int key;
printf("Input InsertNode,'0' to end\n");
root=CreatBST();
printf("Output Preorder:\n");
Preorder(root); //先序遍历输出二叉树的结点
printf("\nInput Search key:");
scanf("%d",&key);
P=SearchBST(root,key); //先序遍历输出二叉树的结点
if(P)
printf("I finde it in this list.\n");
else
printf("NO such words exist this in list !\n");
}
四.调试分析
在进行调试的时候发现一个非常郁闷的问题,就是在进行一次查找后,该程序就不能继续运行了,于是再添加了一个do{…}while();循环,再输入‘#’时再退出。这样就可以第一步不经判断先执行一次,然后如果想要查找几个数字都可以了。
五.运行结果
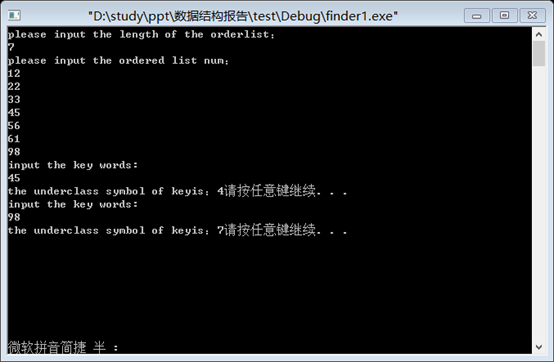
1.输入有序表,用二分法进行查找,结果如下:
2.将输入的元素放入二叉排序树中,再进行查找。结果如下:
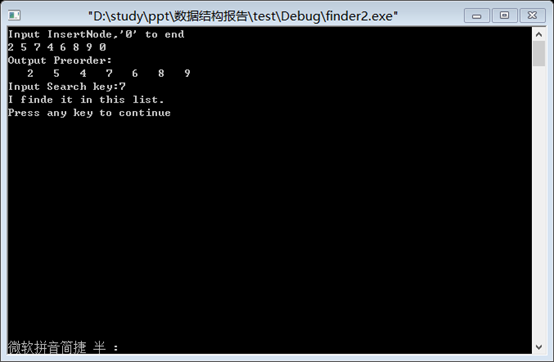
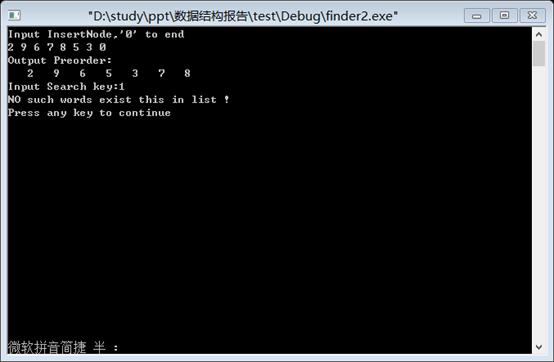
五、实验环境
(1)Win8 系统,兼容
(2)编程环境:VC++6.0简体中文版
六、实验体会
在这次试验中,我掌握了线性结构(顺序查找、折半查找)上查找的基本思想和算法实现,了解怎样对各种查找方法进行时间性能(平均查找长度)分析并掌握了树形结构(二叉排序树)实现查找的基本思想和算法实现,了解怎样对各种查找方法进行时间性能(平均查找长度)分析。
特别的我体会到在存储数据时运用二叉树的结构,可以在以后查找过程节省很多时间。不好的地方是不知道几个数的大小顺序,要知道大小顺序,只能对其进行比较才行。