1、选题符合行政管理专业培养目标要求,也体现出较强的时代特色性与实践应 用性,全文结构基本合理,思路比较清晰,语言比较通顺,层次分明,观点表达 基本准确,论据与论点基本上保持一致,参考的文献资料与论题和论文内容结合 紧密,能综合运用行政管理专业原理知识并结合社会实际来分析文中的主要问 题,但格式还不是很规范,创新点不够,部分论点的论证还缺乏说服力,语言凝 练的还不够,总体上说,基本达到毕业论文的要求。 以…….为主题, 全文首先分析了……, 然后再分析….., 最后重点探讨了……
2、 全文结构基本合理科学,逻辑思路清晰,观点表达准确,语言流畅,论证方法较 合理,参考的文献资料符合主题要求,从主题到内容符合专业要求,部分与本分 之间衔接的比较紧密,但个别引文没有标著出来,真正属于自己创新的内容还不 是很多,个别概念比较模糊,总体上达到毕业论文要求。
3、研究内容具有现实性和可操作性。选题社会热点问题,逻辑结构严谨。观点 表达清楚,论述全面。语言平实简洁,通俗易懂。在论证过程中也能较好地将专 业知识原理与现实问题结合起来。但论据还不够。总体上符合毕业论文要求。
4、选题较具时代性和现实性。全文结构安排合理。观点表达基本准确。全文内 容紧扣行政管理专业要求来写,充分体现出行政管理专业特色。查阅的相关资料 较多。 但不足之处主要是属于自己创新的东西还不多。 总体上符合毕业论文要求。
5、研究-------为题,充分的体现时代特色性。能为中国行政管理问题的解决提供 参考价值。全文结构合理,思路清晰,观点明显。在论证过程中能教好的将论证 与案例论证结合起来。不足之处是部分论点的论据还缺乏说服力。
6、以-------为题进行研究。能为解决--------的问题提供参考和借鉴作用。在全文 结构中,首先要调整基本概念提出问题,然后在对问题进行深入的分析,最后为 ------提出有效的建议。 全文体现专业特色要求, 部分与本分之间衔接的比较紧密, 真正属于自己创新的内容还不是很多。总体上达到毕业论文要求。
7、选题符合行政管理专业培养目标目标,能较好地综合运用社会理论和专业知 识。论文写作态度认真负责。论文内容教充分,参考的相关资料比较充分,层次 结构较合理。主要观点突出,逻辑观点清晰,语言表达流畅。但论证的深度还不 够。
8、本文选题符合行政管理专业要求,又充分反映出社会现实的需要性。全 文结构安排合理,思路清晰,观点正确,能很好的将行政管理专业知识与要分析 论证的问题有机地结合起来。 该文在写作的过程中查阅的资料不仅充分而且与主 题结合紧密。但格式欠规范,案例论证不够。
9、本文立意新颖。全文以-------为线索,结合各地的准规较全面的分析了------的问题和原因。 并针对存在的问题提出解决问题的对策。 内容论证也教科学合理。 全文充分体现行政管理专业特色,格式规范。但创新点不够。
10、本文符合专业要求,反映社会热点问题。因此,该主题的研究有利于推进我 国-------的进一步发展。全文首先-------的问题,然后分析--------的原因。在此基 础上又分析出相关的------。全文结构恰当,思路清晰,观点基本正确。
11、论文思路清晰,语句通顺。能很好的调查--------存在的问题。作者对于论文 内容有一定的了解和熟悉。 思路清晰, 层次清晰, 逻辑结构合理。 观点表达准确。 研究原理采用恰当。在论证过程中能有效的将专业原理与要研究的主题结合起 来。个别地方论证的观点不是很明确,总体上达到毕业论文要求。
12、 全文以-------为题。 重点探讨出--------的问题, 然后针对问题提出有效的建议。 全文结构符合要求,逻辑思路清晰,论据较充分,观点表达准确,语言流畅,论 证方法教合理。参考的资料与主题结合紧密。
13、全文以-------为题。重点探讨分析--------的问题及原因,然后针对问题提出一 些具有可操作性的对策。 全文选题新颖, 具有很强的研究性。 全文结构符合要求, 逻辑结构严谨,思路清晰,观点鲜明,论据具有较强的说服力。论证方法合理, 了大量的数据来论证,更增加了论证的可靠性。能综合运用行政管理专业知识来 分析--------,但不足之处主要是语言不是很精炼。
14、该文参考的文献资料充分且符合论题的需要。该文以--------为例,重点探讨 --------。该文选题符合行政管理专业要求,结构完整,思路清晰,观点表达准确, 格式规范,能较好的将行政管理专业知识运用来分析现实中的行政管理实践问 题。但个别观点论证还不充分。总体上符合毕业论文要求。
15、该文选题具有较强的现实性、针对性和实用性。结构安排科学合理,思路清 晰, 层次分明。 各部分之间联系紧密, 观点表述准确, 论证内容比较具有说服力, 但文章缺乏自己原创的内容。
16、本文以--------为题,重点探讨--------。选题符合符合行政管理专业培养目标 目标与专业特色,而且选题具有很强的针对性和现实意义。文章结构安排合理, 层次清晰,写作时参考的相关文献资料与主题联系紧密,而且参考的资料较新, 在写作过程中作者能较好地运用行政管理专业基本知识原来来分析行政-------, 在论证过程中,主要用理论论证和事实论证。但文章不足之处在与部分语句表达 不清晰,论证还不够深刻充分,创新点不够。总体上符合毕业论文要求。
17、全文以-------为题,选题具有较强的新颖性和实用性。全文结构科学合理, 逻辑性强,思路清晰,查阅的参考文献资料符合论文要求。论证方法较合理。论 证内容较有说服力。对问题的分析比较透彻。该生在论证过程中也能很好的将行 政管理专业知识原理与社会现实结合起来。 无论从选题上还是观点论证上都符合 行政管理专业培养目标要
求。但创新点不够。
18、本文以--------为题,首先对---------的论述,然后在重点分析-------的原因,并 针对原因提出解决问题的有效对策。因此该文在选题上紧扣专业要求,文章结构 科学合理,文章观点表达准确,用词正确,语句通顺,思路清晰。部分与部分之 间联系非常紧密, 在论证方法上采用事例论证与案例论证。 查阅的资料充分合理。 不足之处解决问题的对策还缺少可操作性。
19、该文以--------为主题,充分体现出时代性和现实的社会价值。全文分------个大部分。首先对-------进行了论述,然后重点分析---------。全文基本上都是紧 扣主题来展开论述。 在论述过程中该生较好的运用了行政管理专业知识来分析解 决--------问题。语言较流畅,但观点不够精炼。在论证过程中能恰到好处地运用 理论论证方法与实践论证方法。观点表达准确,思路清晰,文章整体性较强。整 体上符合行政管理专业培养目标要求。
20、本文以-------为主题,选题具有很强的现实性和应用性且符合行政管理专业 培养目标要求。该论文结构基本合理,全文共分-------大部分。其中第一部分 ---------,在此基础上重点探讨--------。在论证过程中,该生的参考文献资料与所 要论证的观点及内容结合紧密,运用的研究方法主要是理论研究与事例研究法。 用词基本准确。但存在的问题主要是论据不够充分,还缺乏说服力,个别引用内 容没有标明出处。
21. 选题较具时代性和现实性,全文结构安排合理,观点表达基本准确,思路基 本清晰,全文内容基本上按照行政管理专业培养要求来写,查阅的相关资料也较 多,但行政管理专业特色体现的还不够充分,属于自己创新的东西也还不多。总 体上符合毕业论文要求。
22. 本文以官员问责制为题进行研究,能为解决我国官员问责制存在的问题提供 参考和借鉴作用。 在全文结构中, 首先对官员问责制的基本原理问题进行了分析, 然后再对我国官员问责制存在的问题进行深入的分析, 最后为解决前面的问题提 出有效的建议。全文体现专业特色要求,部分与本分之间衔接的比较紧密,真正 属于自己创新的内容还不是很多。总体上达到毕业论文要求。
23.该文选题符合行政管理专业培养目标要求,能较好地综合运用行政管理知识 来分析企业行政管理实践问题,论文写作态度比较认真负责,论文内容较充分, 参考的相关资料比较切合论题的需要,层次结构比较合理,主要观点表达的比较 明确,逻辑思路基本符合要求,语言表达基本通顺。但论证的深度还不够,创新 点不足。
24. 本文选题较合理,符合行政管理专业要求。全文以……为主题来分析论证, 对提高我国行政管理的…………..具有参考与借鉴意义。 内容论证也较科学合理, 格式较规范,参考的资料紧扣文章主题需要,但创新点不够,论证不够,尤其文 章最后一部分论证太薄弱,缺乏说服力。总体上基本达到毕业论文的要求。
25 本文以……为主题,重点探讨……..问题,选题基本符合行政管理专业范畴, 充分体现出专业特色。全文结构符合要求,逻辑思路清晰,论据较充分,观点表 达准确,语言流畅,论证方法也较合理,但创新点不够,部分观点论证不充分, 格式还不是非常的规范,真正属于自己的思想不多。总体上基本合格。
26. 该文选题具有较强的现实性、针对性和实用性。结构安排科学合理,思路清 晰,层次分明。各部分之间联系比较紧密,观点表述也基本准确,论证内容比较 具有说服力。 在论证过程中基本上运用了行政管理专业基本知识原理来分析文中 的主要问题,但参考的资料还欠充分,文章缺乏自己原创的内容,少数观点论证 不深刻和全面。
27 本文以官员问责制为题进行研究,能为解决我国官员问责制存在的问题提供 参考和借鉴作用。在全文结构中,首先对官员问责制的现实意义进行了分析,然 后再对我国官员问责制的困境进行深入的分析,最后提出化解困境的有效建议。 全文体现专业特色要求,符合行政管理专业培养要求,参考的文献资料符合论文 观点与主题的需要, 实践论证还不够, 但, 真正属于自己创新的内容还不是很多。 总体上达到毕业论文要求。
28 论文思路比较清晰,语句基本通顺,层次清晰,观点表达准确。作者比较很 好的将行政管理专业基本原理知识与党内监督实践问题有机结合起来进行分析, 并针对党内监督的现实问题提出了一些比较好的解决建议, 查阅与参考的文献资 料与主题结合的比较紧密,但个别地方论证的观点不是很明确和有说服力,总体 上达到毕业论文要求,部分内容与主题结合的还不是很好,逻辑结构也存在一点 小问题。总体上说,基本达到毕业论文的基本要求。
29 论文主题明确,语句基本通顺,层次基本清晰,观点表达基本准确。作者比较很好的将 行政管理专业基本原理知识与邓小平关于行政改革的思想有机结合起来进行分析, 格式基本 规范,选题符合行政管理专业培养要求,但查阅与参考的文献资料太少,部分论证内容与主 题结合不紧密,逻辑结构也存在一点小问题。总体上说,基本达到毕业论文的基本要求。
第二篇:本科毕业论文评语
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
本科毕业论文评语

1
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 摘要
在信息检索领域中,信息检索系统评估对于信息检索系统的研究、开发和应用有着显著的影响。大规模的测试集被认为是信息检索系统评估工作的基础,其质量决定着评估工作的效率和评估结果的准确定。
CWT系列测试集是北京大学网络实验室面向中文信息检索评估而制作的大规模网络测试集。该测试集的第二版CWT200g不仅相对于CWT100在容量上提高一倍,还针对CWT100g中存在的主要问题,加入垃圾站点过滤和网页级别的重复内容过滤,并采取新的网页抓取策略,在提供更高的信息量的同时,保证整个数据集的内容质量。本文首先对Web、搜索引擎以及当前被广泛使用的Web测试集进行介绍,然后在对Web上网页分布特点进行分析的基础上,系统介绍了CWT200g的种子站点列表制作、垃圾站点消除、抓取策略和后期的消重、采样工作进行介绍。特别对于CWT200g制作过程中不同于CWT100g的步骤进行了重点分析与讨论。最后,本文对以上工作进行了总结和展望。
关键词
信息检索,CWT200g, 测试集, 文档集.
2
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
On the Construction of the Document Set of a Large
Scale Collection -- CWT200g
Abstract
In the field of IR (Information Retrieval), the evaluation of IR systems plays an important role and has significant impact on researches, development and applications within the field of IR. Because a large scale test collection is the basis of the evaluation, the quality of the test collection is considered to be a key factor of the effectiveness of the evaluation and the correctness of the results of such evaluation.
The CWT is a series of large scale web test collections presented by the Net Lab of the Peking University which focuses on the Chinese IR researches and evaluation. The CWT200g, the second edition of Chinese Web Test collection, not only has greater volume than CWT100g, but also integrates spam filtering, redundancy filtering and new crawling strategies in to its construction process, in order to deliver quality as well as quantity. With the introduction of World Wide Web, Search Engine and some web test collections that have been widely used, this paper explains the feature of the distribution of the web pages and illustrates the construction of the seed sites, spam filtering, crawling strategies, redundancy filtering and site sampling all in detail. A conclusion is summarized at the end of the paper.
Keywords
Information Retrieval, CWT200g, Test Collection, Document Set.
3
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 目录
第一章 引言 .................................................................................................................... 5
1.1 Web与搜索引擎 .................................................................................................. 5
1.2 测试集 ................................................................................................................... 6
1.3 TREC和.GOV 测试集 ......................................................................................... 7
1.4 CWT100g中文Web测试集................................................................................ 8
第二章 CWT200g文档集的设计原则 ........................................................................ 10
2.1 文档集构造的几点考虑 ..................................................................................... 10
2.2 CWT200g文档集的概况 ................................................................................... 11
第三章 CWT200g文档集的构造 ................................................................................ 12
3.1 中文网页分布特点 ............................................................................................. 12
3.2种子站点的基本选取 ......................................................................................... 14
3.3垃圾站点过滤 ..................................................................................................... 18
3.4 网页的抓取 ......................................................................................................... 21
3.5 后期处理 ............................................................................................................. 22
第四章 CWT200g的统计数据 .................................................................................... 24
4.1 规模统计 ............................................................................................................. 24
4.2 网站域名统计 ..................................................................................................... 24
4.3. 网页形式分类 .................................................................................................... 25
4.4 分省网页统计 ..................................................................................................... 25
第五章 总结 .................................................................................................................. 27
参考文献 ....................................................................................................................... 28
致谢 ............................................................................................................................... 29
4
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
第一章 引言
1.1 Web与搜索引擎
Web是World Wide Web (WWW) 的简称,中文名字为“万维网”。它是一种基于Internet的主从结构分布式网络信息系统,也是目前应用范围最广且最为成功的Internet服务。Web最初是在19xx年3月,由欧洲量子物理实验室CERN(the European Laboratory for Particle Physics)的物理学家Tim Berners-Lee提出的。Tim Berners-Lee于19xx年在自己编写的图形化Web浏览器“WorldWideWeb”上显示了最早的Web页面。随后在19xx年,CERN正式发布了Web技术。
Web的核心是超文本(Hypertext)和超媒体(Hypermedia)技术。超文本与普通文本的不同点就在于超文本中加入了指向其他超文本的超链接(Hyperlink),打破了传统文本的线性组织方式,使超文本之间能够以链接组织到一起。通过超链接用户可以很方便的在超文本之间进行跳转,浏览相关的内容。这种文本的组织方式更接近人们的思维方式和工作方式。超媒体不仅可以包含文字,还可以包含图形、图像、动画、声音和视频片断,这些媒体之间也使用超链接来组织。超文本和超媒体技术为用户浏览信息提供了极大的便利,它使得用户在通过Web浏览器访问信息资源的过程中,无须再关心一些技术细节。只需通过简单的方法就可以迅速的取得丰富的信息资料。这种便利也促成了Web在日后的飞速发展。
在最近几年中,Web的规模一直以极快的速度扩大着。19xx年12月,互联网上大约有3亿2000万网页[1]。而根据Google 搜索引擎在2002 年4 月索引网页表明,网页数已经超过20 亿。根据CNNIC截止到20xx年12月31日的统计表示,我国网站数已经达到694, 200个,一年增加25, 300个,增长率为3.8% [2] 。百度于20xx年7月27日正式宣布,百度索引的网页数量已经达到8亿。天网实验室在今年年初的统计结果显示,目前中国国内的网页数量已经达到11亿。如此大规模的信息资源,没有统一的组织和规划,很难迅速有效的找到有用的信息。IR(Information Retrieval,即信息检索 )技术和搜索引擎则为这些问题提供了最有效的解决方法。搜索引擎通过维护一个大规模的再现资源数据库来为用户提供搜索服
5
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 务,它通常由搜集系统,索引系统以及相关性判断系统组成。当前最具代表性的搜索引擎有Google, Yahoo,百度和天网等。
1.2 测试集
测试集是用来测试信息检索系统性能的一套标准数据的集合。大规模数据集是加速信息提取领域研究的基础。任何信息检索系统在大规模测试集上的性能表现能够从一定程度上体现出该系统在实际应用中的性能。任何信息系统只有在通过大规模测试集上的测试并给出满意的结果后,才能进入实际应用。由此也可看出,大规模测试集和评测是改进信息检索技术和信息检索系统的关键。
一个完整的测试集由三部分组成:文档集、查询集和相关判断集。文档集是一组文档的集合,该组文档的内容用来被信息检索系统进行文字分析。它是信息系统评估的数据基础。查询集是向信息检索系统提出的问题的集合。这些问题依据信息检索系统和所需进行评估的项目不同,可以是一个或一组关键词,也可以是一段描述。通常这些问题由建立相关判断集的人员来制作。由于相关判断集的制作非常耗费时间,所以这些问题的数量通常控制在几百个左右。相关判断集是对应查询集中问题所给的一组标准答案的集合,它被用来对比信息检索系统对于查询集中的问题所给出的答案。信息系统所给出的答案和相关判断集中的答案越相近,则证明该信息检索系统的质量越高。因此,相关判断集的正确性和权威性至关重要。通常,相关判断集通过人为手动判断获得。
由于当今Web规模的飞速发展,Web上的信息已经能够覆盖很广泛的范围,因此最常用的一个构造测试集的方法就是构造一个Web的子集,使用这种方法所获得的集合叫做Web测试集。目前,世界上已经有TREC和NII分别提供了面向英文和日文检索系统的Web测试集。CWT100g是由北京大学提供的第一个面向中文信息检索系统的中文Web测试集。对于Web测试集来说,采用何种方法来构造大规模的Web子集,以使其能够很好的体现出实际Web系统的特点是最重要的问题。文档集质量的高低直接决定了整个测试集的质量和信息检索系统评估工作的效果。
6
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
1.3 TREC和.GOV 测试集
为了促进信息检索的研究与应用的发展,美国国防部高等研究计划局(Defense Advanced Research Projects Agency,简称DARPA)与美国国家标准技术局(National Institute of Standards and Technology,简称NIST)共同举办了TREC(Text REtreival Conference)。TREC通过自己制作的大型测试集,定制各种测试项目、测试程序及测量标准,组合成一套评估检索系统的机制。TREC在19xx年举办了第一届会议,其后持续每年年底举办。除了与会者依据大会提供的测试集送回各个测试项目的资料以进行评估之外,还会有为期三天的研讨会,与会者可以在会中发表信息检索系统的架构、评估结果,并相互讨论切磋[3]。
TREC将自身的目标归结如下:
1. 以大规模测试集为基础,推动信息检索领域的研究;
2. 通过开放式的论坛,促进与会者交流研究成果与心得,以增进学术界、产业界与政府的交流互通;
3. 通过展示在处理实际问题的检索方法上的实质改进,加快技术从研究到商业化的转变速度;
4. 发展适当缺据应用性的评估技术,供各界遵循采用,包括开发更加适用于现有系统的新的评估技术。
从TREC-2002开始,TREC开始使用.GOV测试集完成评估工作。.GOV测试集的特征如下:
? 抓取.gov域名下的网站(20xx年早期);
? 在抓取一百万text/html格式的网页后停止;
? 还包括text/plain格式的文本和从pdf,doc和ps文件中提取的文本;
? 为像基于链接的排序这样的应用提供了重复表(URL==URL)和重定向表(URL->URL);
? 单文件大小限定在100KB以内(从35GB降低到18GB);
? 严格的文件检查(没有二进制文件);
7
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 ? 比wt10g的文档数更少,但更大的平均文当大小。
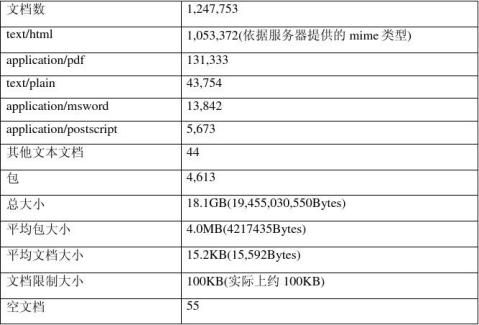
测试集统计信息[4]
1.4 CWT100g中文Web测试集
CWT100g(Chinese Web Test collection with 100GB web pages)是由北京大学网络与分布式实验室天网组制作的针对于中文信息检索领域的中文Web测试集。它根据天网搜索引擎截止20xx年2月1日发现的中国范围内提供 Web服务的1,000,614个主机, 从中采样17,683个站点,在20xx年6月搜集获得5,712,710个网页, 包括网页内容和Web服务器返回的信息,容量为90GB。 其中每个网页对应的服务器返回信息中的MIME类型都是"text/html"或者"text/plain"。
CWT100g数据集从20xx年6月16日开始提供下载。在中文信息检索领域,CWT100g得到了广泛的应用,截至20xx年3月申请该测试集的研究机构已经
8
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 超过30家,连续两年(20xx年和20xx年)被SEWM中文Web信息检索评测和863信息检索评测指定为测试集。
9
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
第二章 CWT200g文档集的设计原则
2.1 文档集构造的几点考虑
通常来说,文档集相比Web测试集的其他组成部分起着更至关重要的作用。由于当今IR领域的技术应用基本都面对Web,因此选取制作的文档集应该能够很好的体现出真实Web环境所具有的特点。从而一个高质量的文档集应该具有非常广的主题范围,同时又具有相当的规模。一般来讲,这两点在实际当中是相辅相成的。Kennedy和Huang[5,6]等人针对文档集的代表性提出了三个问题:
1) 文档集应该使用静态的采集还是应该使用动态采集? 2) 这个文档集相对于父集的代表性有多大? 3) 能够满足一般和特殊IR应用和研究的文档集的大小是多少? 对于第一个问题,我们倾向于采用静态的方式来采集构造大规模文档集的网页。所谓静态的采集是指所有的网页在特定的一段时间内抓取的;而动态采集指的是动态增量的搜集,即在任何时间搜集到的网页都可以随时添加到大的文档集当中。虽然对于搜索引擎来说,动态增量的采集方法更为灵活并且效果更好,但是动态的采集策略却会给文档集的构造带来麻烦。首先,增量搜集会给文档集消除冗余带来麻烦。在下文将可以看到,CWT200g的构造过程中,采用了MD5来判断和消除数据集内重复的网页。由于需要对比所有网页的MD5值来判断数据集内网页是否重复,因此这种方法的计算量是非常大的。如果采用动态的采集方法,对于每次的增量采集,采集到的集合中都可能包含与文档集中相重复的网页。因此,每当要把搜集到的网页添加到文档集当中,都必须进行一次消重操做,这会导致数据集构造构成对系统资源的需求增加,同时延长数据集构造的时间跨度。其次,增量采集很可能导致对网站大小的错误估计,因而影响采样。文档集构造的一个核心问题就是对于文档的采样策略。当前的采样策略都是基于网站规模的,如果采用增量搜集的话,每次加入的网页可能会影响到站点下网页的多少,因而会影响到采样的结果。对于整个文档集的构造来说,我们希望能够在通过一定的搜集策略下,很好的描绘出网站的大小,然后再针对于文档集进行采样。然而,增量采集的过程会使特
10
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 定搜集策略对网站规模的估计失效,从而给文档集的构造带来意想不到的结果。再次,增量采集的时间跨度比静态采集的时间跨度更大,因此制作出来的文档集更容易被网站内容在时间上的变化所影响。而实际中,我们更希望文档集是Web在某一特定时间点上的子集,因此时间跨度相对较小的静态采集才是首选。
对于第二个问题,要使文档集能够具有代表性,首先要让文档集具有一定规模,能够容纳下相当数量的网页。天网实验室孟涛同学在20xx年初已经收集到的属于中国的网页已经达到11亿之多。因此我们新的数据集也必须能在容量上跟上Web的发展速度。然而,从另一个角度说,如果一味增大测试集的规模,将会使相关判断集的制作非常消耗人力。因此我们必须在代表性和规模之间作出权衡。其次,这个大规模的数据集必须能够比覆盖尽可能多的主体,保持内容上的多样性。相比TREC的GOV数据集的抓取仅仅局限在.gov的域名下,CWT数据集的抓取范围仅仅做了很小的约束。目前CWT所搜集的网页都是在中国范围内的网页(包含英文网页)。仅从这一点上,就保证了CWT能有更好的主题覆盖范围。另外,相对于CWT100g,CWT200g在网页采集过程中还加入了动态网页的搜集,并采用了一系列策略来保证能够很好的体现网站规模的同时,避免抓取的网页全部集中在很少的网站上。从而尽可能覆盖更多的网站,以达到提高内容多样性的目的。
对于第三个问题,CWT文档集大小的设定,更多的是考虑到数据易用性。由于在20xx年初,200G – 300G的IDE硬盘的价格已经达到可以接受的范围,因此,我们将数据集的规模设定在200GB,同时为了能提供更多的信息,我们在保存的时候使用了压缩的天网格式。
2.2 CWT200g文档集的概况
根据天网搜索引擎在20xx年11月份搜集网页所发现的中国范围内提供Web服务的627,036个主机,通过一系列处理和过滤后得到 88,303站点。然后对这些站点进行网页搜集,每个网站的搜集深度为3,单个网站搜集的数据量不限,得到初始数据集。所有搜集的网页都具有text/html或者text/plain的MIME属性。然后针对得到的原始数据集进行后期处理和采样,得到容量为197GB的CWT200g的测试集,共包括29,100个站点,37,482,913个网页。
11
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
第三章 CWT200g文档集的构造
3.1 中文网页分布特点
在构造CWT200g测试集文档集的过程中,最首要的任务就是要保证所构造的文档集有足够的代表性,能够体现出中文Web的实际特点,从而给中文信息检索系统的研究提供一个高质量的测试环境。这一切又归结为两个核心问题,一个是如何采样Web站点,另一个是如何抓取采样站点上的网页。而站点采样的策略又是和中文网页分布特点紧密相连,因此在确定采样策略之前,有必要对中文网页的分布特点加以总结。
在Internet上,网页的分布呈现Zipf法则[9]。Zipf法则通常被用来描述一个事物的一个事物出现的频率“大小”y和这个事物的排序位置有关。哈佛大学的语言学教授George Kingsley Zipf曾试图决定第三个、第八个和第一百个常用的单词的“大小”。这里的大小实际上指的是单词在英文中的使用频率,而不是单词的长短。Zipf法则的可以表述为发生频率排在第r位的事物的大小反比与他的位置r,或: y ~ r。对于网页分布来说,这里的位置r指的是网站大小,而发生频率指的是这个大小的网站的数量。在此,我们定义一个网站的大小等于属于这个网站的网页的个数。因而,网页的分布符合Zipf法则就意味着拥有越多网页的网站,即越大的网站,个数往往越小;而拥有越少网页的网站,则会越多。
对于中文网页的分布和规模,已经作过很多的工作来证实它的分布是符合Zipf法则的。根据天网截止到20xx年2月的搜集工作,天王搜索引擎一共在1, 000, 614个网站中搜集了2亿网页,其具体的分布图如下: -b
12
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建

可以很明显的看到,这个网站大小的分布图整体上呈现出一个L字的形状。根据数据统计结果,仅有1.9%的网站拥有500或者更多的网页,而大多数的网站只有不到300个网页。
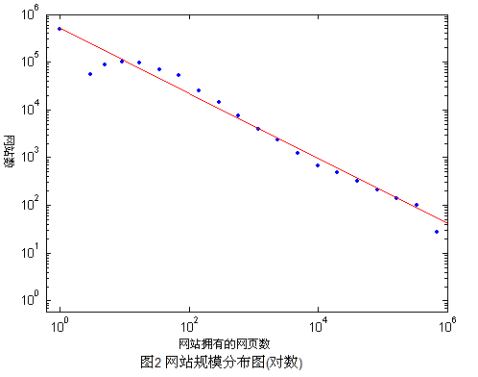
为了检验这个分布是服从指数分布的[10],我们将网站数量和网站规模分别取对数后,得到下图:
13
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
可以看到我们得到了一条比较平整的线,线的斜率为-0.68。由此,中文网页的分布是服从指数分布(等同于Zipf法则)的。中文网页的分布特点将对我们的采样策略和抓取策率起到重要的作用。
3.2种子站点的基本选取
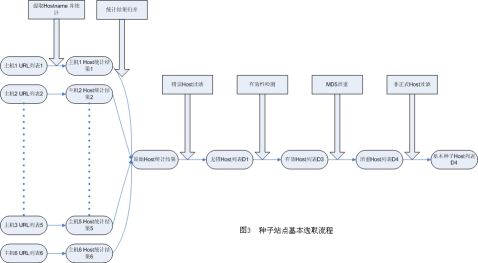
种子站点是将在后面网页抓取阶段进行网页抓取的网站。为了得到良好的种 子站点,我们首先针对天网的搜集系统在20xx年11月份所收集的约四亿网页数据进行了处理。这四亿网页数据被分别保存在6台主机上,所有的数据文件都按照天网格式保存。首先,我们根据天网数据格式,将所有网页的URL提取出来,然后保存在相应的主机中,从而对于每个主机,我们获得了一个URL列表。随后,我们通过使用BekerleyDB,制作了一个统计程序,它负责从URL中提取主机名称,然后将对应的主机名插入到BekerleyDB数据库中,并设置计数为1。如果对应的主机名已经存在,则将数据库中的主机名称的计数加1,最终统计出每个主机名称下的网页数,程序的流程如图3所示。最后,因为统计出来的主机规模数据分别存放在6台机器上,我们还需要将六份单独的统计结果进行归并。然而由于不能保证6台机器之间没有重复的主机名,因此为保证统计结果的正确定,程序按照与前面
14
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
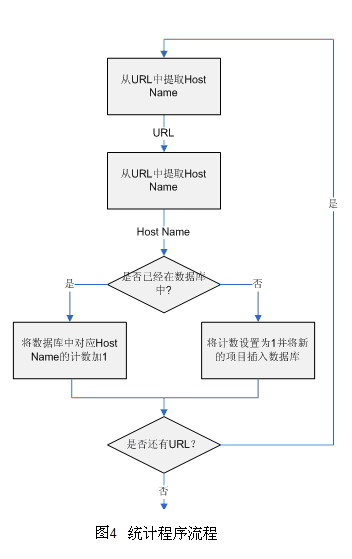
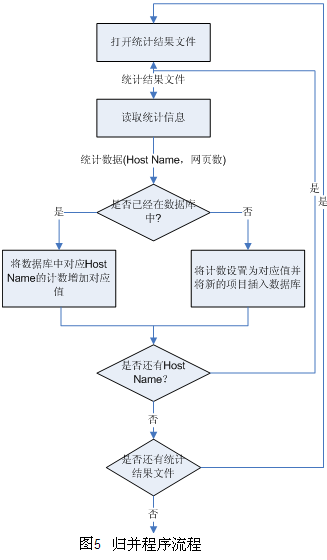
统计程序相类似的方法来进行归并。不同之处在于,对于未曾在数据库中出现的主机名,需要根据已有的统计结果设置初值;当主机名已经报数据库中时,需要根据要添加的项目的计数来修改数据库中项目的计数,如图4所示。
通过对分布在6台机器上主机上的网站规模统计信息的合并,我们便获得了初始主机统计结果,我们称这个主机列表为中的主机集合为D0。通过统计,我们一共获得了627,036个独立主机地址,所有的主机名称都按照“协议://主机名:端口/”的格式进行保存。
在接下来的处理过程中,我们要对D0中的所有主机的有效性进行检验。在有效性的检验中,我们主要处理如下几类问题:1) 处理并消除由程序或网络传输
15
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 原因所造成的错误的主机名称,2) 主机访问有效性的测试,并去除掉网络访问失败的主机名称,3) 最后通过MD5来消除掉网络主机的别名,4) 去除所有非正式服务的主机。
如前所述,D0表示我们通过统计和归并所获得初始主机名称集合,随着每一步的处理,我们或获得新的主机名称集合,我们一次命名为Di,i=1, 2, 3, 4。下面的任何一步所获得的主机名称集合Di都是在前一步获得的主机集合Di?i上经过处理后得到的。对主机名称的具体处理过程如下:
1) 在程序处理的过程中,由于网络连接的问题,有可能造成抓取的网页和在网站上的网页不符,因此有可能造成网页内部所包含的链接信息发生错误,从而给出错误的主机名称。同时由于程序自身存在的问题,也会造成主机名称发生错误。由于这部分的错误非常明显,我们通过程序对一些常发生错误的判断和手动的判断,可以去除大部分的主机名称错误。少量未能在这个阶段去除的错误主机名,则可以在网络访问测试阶段去除掉。最终,我们得到了无格式错误的主机地址列表D1。
2) 在去除明显的主机名成错误后,我们希望进一步验证这些主机是可以访问的。所以验证有效性这一过程中,首要面对的问题就是通过什么手段来确认这些主机是可以访问的。在CWT100g的制作过程中,主机名称网络访问测试由两部组成:a. DNS验证。在这一步中,程序通过向DNS服务器发送主机名成,让DNS查找对应的主机的IP地址来判断这个站点是否有效。如果该站点无效,则DNS服务器会返回错误信息。b. 实际访问网站。通常来说,程序会以主机名来直接进行访问,这样访问的便是该网站的首页。然而,在测试中发现虽然大部分的主机名称都能通过DNS检测,只有很少的返回错误信息,但在访问首页的过程中,仍有很多网站访问失败。所以在CWT200g的实际制作过程中,我决定通过Linux下的wget程序直接访问主机名称地址抓取网站首页来代替CWT100g中的两步验证。这样做的好处一是可以省去单独的DNS检验环节,提高效率。因为DNS检测这步仅能消除很少的无效主机名,且在抓取首页的过程中还要再次通过DNS检验。而DNS访问却很消耗时间,因此没有必要单独设立DNS检验。二是wget程序对于http的访
16
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 问有很好的支持,通过对其参数的调整,可以很方便的控制对主机访问的方式。因此,最终放案是通过wget程序访问主机名对应的地址,抓取主机的首页来确认该主机可以访问。在程序中,我们使用如下方式来运行wget:
wget -T 20 -t 2
其中,-T 20指将抓取网页的超时设置为20秒,-t 2指对于抓取不成功的网页,重试2次。
在抓取网站首页中面对的另外一个很重要的问题就是访问网站的速度很慢,将一个主机的首页保存下来往往需要几秒到几十秒的时间。然而对于无效的主机地址,则只能让程序触发超时错误,并完成相应的重试次数才可以结束。根据我们设置的参数,这一过程至少需要40秒的时间。能够提高整个验证过程速度的最佳方法就是使用多线程。我们让每一个线程的对应一个主机名称,同时打开200个线程,即同时访问200个主机。通过这种方式,能够增大对网络带宽的利用,不必因为一个主机地址无效而导致其他任务为此等待。通过使用多线程,我们只需4个小时就可以在一台服务器上完成60多万主机有效性的检测。
然而在多线程抓取的过程中,还有一个问题需要处理,就是抓取回来的主机首页如何保存。因为wget程序在使用过程中,需要将抓取回来的网页保存在指定名称的文件中。如果对于所有线程指定同一个文件名,那么由于线程可以并发,那么可能造成多个线程对同一个文件的交叉读写,破环文件内容,并对后一步的MD5消重产生严重影响。为了解决这一问题,程序中对于每一个线程给定了一个唯一的编号(实际为线程的序号),使wget根据这一编号来命名临时的文件。由于这一编号对于所有线程来说是唯一的,因此就消除了多个线程读写同一个文件的可能。
通过排除不能访问的无效主机地址,我们获得了有效主机地址列表D2。 3) 在实际的Web中,同一个网站有可能会有多个名字与它对应。在访问时,对于这个网站的每个名字,我们获得的信息是相同的。实际上,这种情况往往是多个主机名所对应的服务器是相同的。由于这种冗余信息对于提高数据集的质量
17
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 是毫无意义的,因此有必要在抓取之前将这些网站的别名过滤掉。对于确定两个主机名所对应的站点是否相同最基本的办法是比较这两台主机上的所有页面,然而由于客观资源的限制,这种方法很难实现。由于Web的特点就是通过超链接彼此相连,而这些超链接信息都保存在网页当中,因此我们只需判断两个主机名称所对应的服务器的首页是否相同,即可判断出两个网站是否相同。
MD5算法是一种在网络和信息安全领域广为应用的算法。由于其自身重复的可能极低,因此在计算机网络中往往使用MD5来作为一个文件或网页的唯一标识符。为了避免在消重的过程中保存大量无用的网页并且进一步提高效率,在网页抓取完毕后,程序自动根据网页的内容计算出这个网页所对应的MD5值。保存的在临时文件中的网页在计算完MD5值后便被删除,以释放磁盘空间。接下来,我们再次通过BekerleyDB来消除网站的别名。我们将主机的MD5值作为数据库的键值,将主机名称作为记录中的数据项,将所有通过网络访问的所有主机的信息输入到数据库中。在插入的过程中,如果有任何两个主机的MD5值相同,则表示他们指向的是同一个网站,因此只需在其中选择一个主机名称保存下来即可。最后将数据库中的所有记录输出到文件中,就得到了没有重复的主机列表D3。
4) 通过以上处理,我们已经获得了确定可以访问的没有重复的主机名成列表,但是这些主机中还会有很多主机是我们不希望收集到文档集当中的。根据制作CWT100g的经验,通过非默认端口(80端口)提供http服务的站点主要是为测试使用,这些网站的信息量很少,对于测试集来说意义不大。因而,所有标注非80端口的主机名成都被从我们的主机名列表中去掉。另外,以IP作为主机名称的网站由于没有DNS的验证过程,也被认为是非正式的网站。为了保证文档集的质量,我们将这些主机地址也从我们的列表中删除。通过这一步我们最终获得D4。
3.3垃圾站点过滤
虽然通过3.2中所述过程,我们已经把大部分不符合要求的网站清除掉,但是还有一类网站对于文档集的构造来说是毫无意义的,那就是垃圾网站。垃圾网站的一大特点就是虽然它有很丰富的链接资源,但是这些网页本身的内容是没有意义的,而且很多这样的网站都是由特定的模版生成的,他们的网页中的链接往往是链
18
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 向其他网站的广告或者是其他垃圾网站自动生成的网页。虽然这类网站的实际内容很少,但数量上却具有相当规模。比如提供个人域名的网站“fangwen.com”,他下面的网站“”和“”虽然他们的首页拥有不同的MD5值,但是通过浏览可以发现这两个站的首页非常相近,而且首页上几乎没有对于构造测试集有用的信息。因此这些无用的网站必须能够被识别出来,并从列表中除去。去除垃圾网站我们分别使用了自动和手动两种方法,具体如下:
1) 自动垃圾过滤:天网实验室孟涛同学在1月份进行10亿网页的过程中,根据实践积累了一个垃圾网站的主机地址列表。这个列表中包含了一些常见的垃圾网站和有用信息很低的网站的域名,共3,349个。根据这一列表,我们通过正则表达式对包含列表中的域名的所有主机地址进行了过滤。通过这一过程,我们从D4中的285,470个网页中去掉了71,059个主机地址。
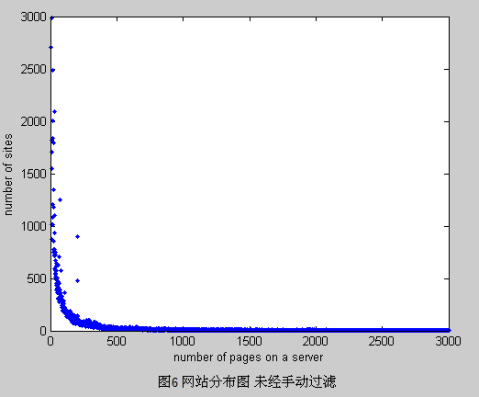
2) 手动垃圾处理:通过上述过程,我们已经去除掉了大部分的垃圾网站,然而还是会有一些垃圾站点包含在列表中。为了提高文档集的质量,这些网站只能通过认为的手动判断。这些主机的分布如图6。可以看到在网站规模小于500处有几个脱
19
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 离周围点过多的点,在此称为异点。根据互联网网页分布的规律,这些异点很可能是因为对应了大量自动生成的无用站点而高于其他分布点。于是我们将这些异点所对应的网站列表进行单独分析,发现这些网站列表中包含很多拥有共同域名的网站,因此推测这些网站应该是垃圾网站。为了进一步确认,我们随机选取这些域名下的5个网站进行访问。通过认为的识别最终确定了这些网站确为垃圾网站。另外,通过人工浏览站点列表来检查是否存在大量相同域的站点,可以进一步发现异点没能表现出来的垃圾网站。通过这两种方法,大部分具有相同域名的垃圾都可以被有效清除。我们在实际中共清除了6,728个主机地址。另外,我们还进一步过滤了使用数字开头(在第一个主机名中的点之前)的主机地址,因为这种主机通常都是程序自动生成或无用的网站,共过滤掉39,419个主机地址。过滤后分布图如下:
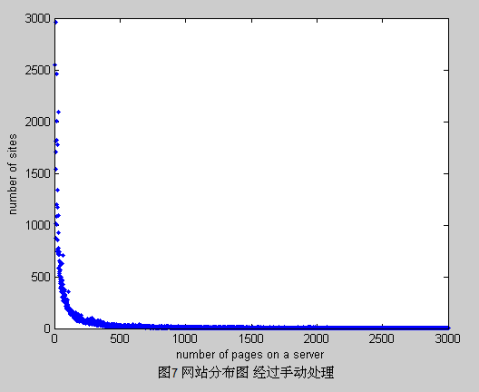
通过上述处理,可以看到图形上不够平整的点已经基本消除,然而在接近于零的位置,图形依然很不平滑。因此考虑到这些网站所包含的页面链接很少,搜集
20
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 他们对于文档集能提供的信息和链接关系不多,而且通过人为随机采样验证这些站点中大多数都属于垃圾站点,因此我们将所有页面数小于10的主机地址全部清除,共除去17,244个主机地址。
3.4 网页的抓取
经过一系列的过滤和处理,我们得到了88,303个种子站点地址来进行网页的抓取。网页的抓取的过程中,并不是所有的网页都需要从网站上抓取下来。因为目前的信息检索系统主要面对的都是具有“text/plain”和“text/html”类型的文档,因此在抓取过程中,我们仅保存服务器返回类型为上述两种类型的文档。其次,由于中文Web中有很多网站采用了动态页面技术,因此在网页抓取过程中,我们保留了所有具有动态生成的网页(CWT100g中未收录此类网页)。
抓取过程中面对的两个主要的问题是原始网页的保存格式和对于网页抓取的策略。对于原始网页的保存格式,我们采用如下策略:
1) 所有的网页都按照压缩的天网格式。服务器传回的http头信息和网页的原文经过gzip压缩算法压缩后,追加在天网格式头的后面。
2) 对于同一个主机名下的网页,都保存在以主机名(http://与之后的第一个/之间的部分)命名的文件夹下的page.dat中。
3) 所有以主机命名的文件夹都根据主机名称计算的哈希值分别存放在data_0到data_255这256个文件夹中。哈希算法采用的是C++的STL类库中的Hash类自带的算法。分配方法为,使用Hash类计算出主机名称的哈希值之后,将该哈希值模256,所得结果前面加上“data_”即为该主机文件夹所在的文件夹。经过这样的映射之后,使得每一个“data_”开头的文件夹下的数据都保持在约180-220G左右。
通过这样的存储结构,能够很快的确定一个主机对应的数据文件的位置。同时,通过将网页数据进行压缩,也有效的减低了对磁盘空间的需求。
抓取过程中,我采用了全新的Simple Crawler程序进行抓取,该程序采用了与抓取初始数据的程序相类似的策率。具体如下:
21
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
取;
3) 每个主机上的网页采用广度优先的抓取侧率,抓取三层,抓完即停,不1) 对于每一个主机地址,都单独创建一个线程进行抓取; 2) 抓取过程中,对于每张网页内的链接,仅对在该主机下的链接继续抓对主机抓取的大小做限制;
4) 仅保存服务器返类信息中类型为“text/plain”和“text/html”的页面进行保存。
通过将CWT100g中每个主机抓取程序的纪录文件达到2GB后自动停止改为广度优先,抓取三层,容量不限,使得我们抓回的网页能够很好的体现出该网站的规模与链接特点。另外,通过加入动态网页抓取,CWT200g能够覆盖更多的网页资源和网上的信息。这两点是CWT200g对于CWT100g最重要的改变。通过上述抓取过程,我们得到了约500GB的原始网页数据。
3.5 后期处理
在完成抓取原始网页数据后,还需要一些后期处理才能正式完成CWT200g的制作,即全局消重和采样。
所谓全局消重,主要是针对种子站点制作中网站消重的扩展与补充。全局消重首先要计算出每个网页的MD5值,然后按照与主机消重类似的方法将,用网页的MD5值作为数据库的键值,用网页的URL作为数据库中的数据项组成纪录插入到数据库中。如果遇到有相同MD5值得网页,则说明这两个网页的内容是相同的,因此只需在两个URL中任意选择一个就可以。这么做的目的是完成在网页一级的消重。因为在实际情况中,会有两种主要的问题引入重复的网页。第一,对于动态网页,网页URL中问号后面是向http访问处理程序提出的参数。但是有时两个URL会在一个参数上存在差异,但实际上仍然指向同一个网页。第二,很多网站对于某些地址往往会有一个默认的页面,这样在链接中不用写出具体的页面文件就可以直接访问到页面。这种情况通常出现在网站的首页。比如,和/default.htm指向的是同一个页面。通过全局消重,以上两种问题都可以迎刃而解。
22
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 然而实际处理过程中并不能将所有的MD5和URL信息放在一个数据库中。因为抓回的原始网页已经大约有7千万,如过只是用一个数据库来处理,会造成数据库非常庞大,使得数据库无法保持在内存中。而如果在这样的数据库中查找或者插入数据将需要频繁的内存换页和硬盘读取,导致系统效率低下。为此,我们网页的MD5的值模1024,然后根据余数将MD5和URL信息存放到对应1024个小的数据库中。这样的好处是可以很好的控制数据库的规模和效率,使数据库能够保持在内存中,从而提高效率。通过实际对比,保存到同一个数据库中消重需要7天时间,而使用1024个小数据库则只需1小时。
CWT200g文档集的最后一步就是采样。根据消重后的结果,我们所需的采样率为1:2,即每两个网页选择一个。我们的具体采用过程如下:
1) 确定网站规模的范围 2) 将网站的规模数每20个分为一组, 3) 从每组中随机的抽取10个网站规模数, 4) 根据选出的网站规模数,找到对应的主机名, 5) 根据主机名,确定出网页的URL 6) 根据URL从原始网页数据中,抽取出网页,并按照前面制定的保存规则保存。
通过上述的采样策略,我们共选出29,100个站点,37,482,913个网页,并按照3.4中所述的方式存储。至此,CWT200g的制作完成。
23
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
第四章 CWT200g的统计数据
4.1 规模统计
个数 大小
网页 37, 453, 813 880,164,374 KB
网站 29, 100 1, 287 pages/site
4.2 网站域名统计
域名类型 百分比 网页数 动态网页数
.com 63.750% 23,452,494 14,979,733
.net 13.106% 4,821,358 3,416,647
.cn 9.282% 3,414,675 2,538,710
com.cn 8.081% 2,972,910 1,756,685
.org 1.633% 600,642 433,243
province.cn 1.508% 554,817 297,032
gov.cn 1.414% 520,205 293,237
edu.cn 1.057% 388,910 232,858
net.cn 1.036% 381,225 305,157
org.cn 0.504% 185,558 134,945
ac.cn 0.243% 89,266 51,252
其他 0.195% 71,753 49,583
平均大小 23 KB/page 30, 246 KB/site 网站数 19,132 2,621 2,290 1,993 323 513 832 821 204 185 149 37
24
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
4.3. 网页形式分类
页面类型 页面数量 asp 13,339,431 php 8,896,099 html 5,574,326 htm 5,160,105 aspx 1,416,117 shtml 1,149,007 cgi 797,277 jsp 317,803 php3 49,689 / 48,502 xml 13,929 txt 11,994 shtm 5,566 nsf 4,438 pl 3,596 torrent
81
4.4 分省网页统计
省份 百分比 北京 21.311% 上海 16.671% 广东 11.765% 江苏 6.513% 天津 5.828% 浙江 5.254% 福建 4.463% 河南 4.211% 山东 2.751% 重庆
2.578%
百分比 36.260% 24.182% 15.153% 14.027% 3.849% 3.123% 2.167% 0.864% 0.135% 0.132% 0.038% 0.033% 0.015% 0.012% 0.010% 0.000%
网页数 7,839,928 6,132,767 4,327,996 2,396,118 2,143,851 1,932,805 1,641,690 1,549,175 1,011,989 948,398
动态网页数
4,699,620 3,797,834 2,700,457 1,887,689 1,129,233 1,424,461 1,200,724 1,171,634 675,684 629,491
网站数 12,664 4,950 1,935 1,037 287 962 1,447 531 560 536
25
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
湖北 2.570% 四川 2.238% 河北 2.191% 辽宁 1.467% 湖南 1.328% 广西 1.000% 江西 0.890% 黑龙江 0.879% 陕西 0.731% 安徽 0.718% 云南 0.374% 甘肃 0.251% 吉林 0.240% 内蒙 0.206% 山西 0.194% 贵州 0.167% 新疆 0.129% 海南 0.078% 宁夏 0.051% 青海 0.008% 西藏 0.002% 其他
4.753%
945,425 823,236 805,913 539,784 488,633 368,049 327,277 323,247 268,792 264,042 137,758 92,326 88,285 75,959 71,447 61,616 47,546 28,720 18,749 2,804 897 682,601 476,613 563,806 306,253 351,989 314,937 185,063 265,314 199,906 173,290 85,418 47,792 56,005 47,989 51,874 49,155 33,693 26,675 9,174 1,559 378 472 557 500 252 239 116 104 208 141 220 74 52 97 45 44 34 42 30 13 5 2 944
26
1,748,591
1,242,771
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建
第五章 总结
CWT200g文档集是在CWT100g的构造经验的基础上,针对CWT100g中所存在的问题进行改进并构造的新的Web测试集,它不仅在容量上对CWT200g进行了扩展,相比CWT100g它还有如下特征:
1. 分别采用了自动和手动的垃圾站点消除来提高文档集中数据的质量;
2. 采用了全新的抓取程序和抓取策略。新的抓取程序避免了对单个主机抓取的容量限制,采用广度优先,抓取三层的方式进行抓取,不仅能够充分的抓取网站上的网页,还可以很好的体现出网站的规模和结构特点。
3. 采用了全局MD5消重来进一步消除数据集内的重复网页,避免数据集出现冗余信息;
4. 采用了先抓取后采样的制作方法,使得采样能够依据实际抓取所确定的网站规模进行,提高了采样的准确性;
5. 采用压缩的天网格式,提供更高的信息量。
通过如上改进,我相信CWT200g能够更好的为信息检索评测工作服务。
27
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 参考文献
[1]
[2] CNNIC, “第17次中国互联网发展状况统计报告”, CNNIC, Steve Lawrence and C.Lee Giles, “Searching the World Wide Web”, Science, 280(5360): 98~100, Apr. 1998. .cn/index/0E/00/11/index.htm, 20xx年1月17日。
[3] 江玉婷 和 陳光華, "TREC現況及其對資訊檢索研究之影響”, 圖書與資訊學刊, pp. 36-59, 1998.
[4]
[5]
[6]
[7]
[8]
[9]
[10] L. A. Adamic, "Zipf, power-laws, and pareto - a ranking tutorial," Tech. Rep., Xerox Palo Alto Research Center 2000. L. A. Adamic and B. A. Huberman, "Zipf's law and the Internet", Glottometrics 3, pp. 143-150, 2002 T. Meng, H. F. Yan, and X. Li, "An Evaluation Model on Information Coverage of Search Engines", ACTA Electronica Sinaca, vol. 31, pp. 1168-1172, 2003. H. F. Yan and X. Li, "On the Structure of Chinese Web 2002", Journal of Computer Research and Development, vol. 39, pp. 958-967, 2002. C. Huang and J. Li, “Linguistic corpse”, Business publisher, 2002. G. Kennedy, “An Introduction to Corpus Linguistics”, London, Longman, 1998. TREC, “The .GOV Test Collection”, http://es.csiro.au/TRECWeb/govinfo.html.
28
北京大学本科生毕业论文 中文Web测试集CWT200g之文档集的构建 致谢
首先,我向在我整个毕业设计过程中,给予很大帮助的指导老师闫宏飞老师表示感谢!他指导我进行了网页测试集和CWT100g的相关资料,对我关于CWT100g构造的问题进行了详细的解答,与我讨论CWT200g的构造方法,给我在CWT200g文档集构建的想法提出建议。闫老师丰富的知识和经验使我受益匪浅。在这里谨向他表示诚挚的感谢。
另外,还要感谢天网实验室的孟涛和李静静同学。他们在我的实习中的问题也给予了我很大帮助。他们过硬的专业知识,严谨的求学精神和诚恳的待人态度让我体会很深。没有他们的帮助,我是无法完成此次毕业设计的。
最后,感谢我所在的天网组的成员们。他们给我大学最后一年的学习生活带来了很多不同,他们勤奋的精神不断激励着我,让我能够以积极的态度面对每一天。
29