NBA球队战绩的影响因素(得分、篮板球、失误)
NBA team on the influence factors of record
作者:卓上鼎 韩金波 李东山
Author:Zhuo shang-ding, Han jin-bo, Li dong-shan
摘要:运用一些统计分析方法对2010—2011赛季NBA季后赛参赛球队整个赛季战绩进行影响因素研究。实证结果表明,季后赛中;;通过在模型中加入主客场虚拟变量后受到许多因素的影响;替补运动员能力和常规赛战绩也是季后赛战绩的重要影响因素。以NBA为参考,对我国CBA的发展和球队建设提出了一些有针对性的建议。
关键词:NBA;战绩;影响因素;统计分析
引言
NBA,即全美职业篮球大联盟,创办于19xx年,已有60多年的历史,现已成为全球范围最职业化、最市场化的大联盟之一。NBA于19xx年首次由中央电视台录播进入中国,并且随着姚明、易建联等的相继加入,使得这个世界上最高水平的篮球职业联赛越来越为中国人所了解和喜爱。近年来,NBA在中国的发展受到人们越来越多的关注,其体育文化价值、商业价值等得到了充分的显现。NBA比赛的看点不仅在于其速度、力量、对抗、激情和联赛中运动员高超娴熟的技术、良好的意识和过人的身体素质,还在于NBA科学细致的选秀制度、转会制度和限薪制度等制衡体系保障各球队的实力较平均,没有哪一支球队有绝对的把握能战胜另一支球队,比赛的胜负往往充满悬念,正如NBA的口号一样“Where Amazing Happen”。NBA的发展为篮球运动在全球的普及和推广做出了突出的贡献。
球赛越是激烈,结果悬念越大,球迷就越想预测球赛的结果。然而。球迷对球赛结果的预测基本上都是基于主观推断,有时还受个人对球队或运动员偏好的影响,预测的科学性、准确性往往较差。球队中核心运动员的作用如何?人们常说的主场优势是否显著存在?季后赛与常规赛的主要影响因素分别是什么?这些都是体育界专业人士和广大球迷关心的热门话题。我们在参考了别人研究的基础上,试图充分利用各种统计分析方法对其进行较深入的研究,目的在于通过对NBA的球队战绩影响因素(这里给出场均得分、篮板球、失误数据)的统计建模分析,揭秘或者在一定程度上能够预测比赛发展的趋势。
数据来源和指标选择:
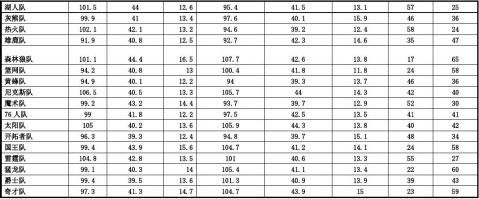
本文涉及2010--2011赛季NBA的以下指标数据:30支球队每队82场比赛的各项统计指标。有关数据来自NBA官方网站(20xx年6月23日)。
指标选择:30支球队整个赛季几项数据(场均得分、篮板球、失误)的统计,统计数据如下:
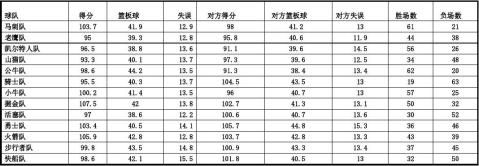
一、描述性统计
各支球队得分、篮板球数、失误数趋势示意图:

图1
从图中可以看出,整体上各支球队场均得分在85~110分之间,同时对各支球队来讲当场均得分高于对手时,胜场数处于较高水平;但是,篮板球数量以及失误数量的对比上无法判断他们对球队胜负影响程度及相关性。
二、相关与回归分析(篮板球、失误、分差
)
回归分析结果示意图 2


胜率失误相关系数示意图3 胜率篮板球相关系数示意图4 胜率分差相关系数示意图5
1、相关性分析:
通过相关系数示意图可知失误数与胜率两个变量为负的相关性,且相关系数为—0.446(示意图3);篮板球数与胜率两个变量为正的相关性,且相关系数为0.128(示意图4);分差与胜率为正的相关性,且相关系数为0.972(示意图5),二者关系程度明显大于胜率与失误的关联程度。
2、回归分析:
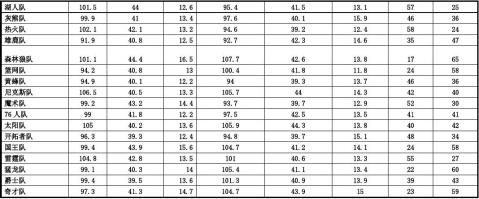
可设球队胜率为变量?,得分数、篮板球数、失误数分别为变量x1、x2 、x3
三元线性回归方程为?=b0+b1 x1+b2 x2+b3 x3
由图2可知线性回归方程为?=—0.623+ 0.012x1+0.031 x2—0.098x3
因为x3的系数为负值,易知失误数(x3)与球队比赛胜率呈现反方向关系,失误数越多,则比赛胜率越低。
回归模型的评估:
(1)假设
H0: ? 1 ? ? 2 ? ? ? m ? 0 , ?
H1:至少有一个回归系数不等于0 。
(2)计算检验统计量
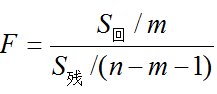
F
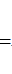
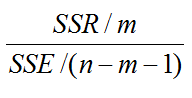

22??SSR?(y?)SSE?(y?y)回归平方和 =0.711;残差平方和 =0.032;
(3)确定显著性水平a=0.05和分子自由度m=3、分母自由度n-m-1=30-3-1=26。找出临界值查表得到Fa =F0.05(3,26)=6.382;
(4)作出决策:
易知Fa > F,则拒绝原假设,说明至少有一个自变量能增加预测因变量y的显著性。
回归系数的显著性检验:
(1)提出假设
H0:自变量与 因变量没有线性关系 ;
H1:自变量与 因变量有线性关系;
(2)计算检验的统计量
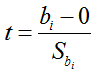
t

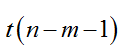
??
对于分差:t1=19.067
对于篮板球数:t2=-2.055
对于失误数:t3=0.073
在0.05显著性水平下查表得t0.025(26)=2.056
可知,∣t1∣>2.056,据绝原假设;∣t2∣<2.056,∣t3∣<2.056,接受原假设。
说明分差与胜率有线性关系,失误数、篮板球数与胜率不存在线性关系。(散点图如下) 失误与胜率散点图:
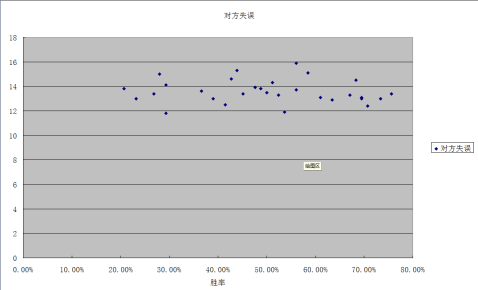
从上图中可看出,战绩偏好的球队,平均每场失误数与战机比较差的球队
每场失误数基本上持平,除个别情况下,例如,篮网队战绩为29.3%,明
显靠后,但其场均失误数却为11.8个,而凯尔特人队战绩为68.3%,失误
数却高达14.5个。同时,根据显著性检验可得知失误数与球队胜率不存在
线性关系,二者虽有影响,但却不可预测。
篮板球与胜率散点图:
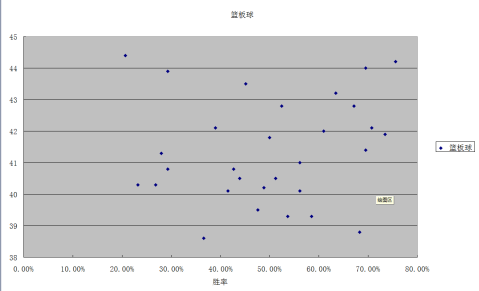
从上图可以得知,球队战绩不同,篮板球数偏幅较大,因此可以得知篮板球 数事决定球队战绩的主要原因之一。同时,由显著性检验可得,篮板球数与 球队战绩二者不存在线性关系。
分差与胜率散点图:
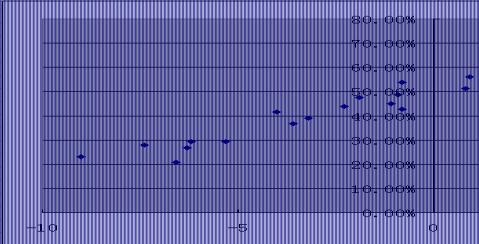
同篮板球数对球队战绩的影响,分差数与战绩存在线性
关系,且二者是正的线性关系。同时,各种不同的得分
手段使得得分也是篮球备受关注的因素之一。
三、具体数据分析
从以上数据可得到,对于比赛的战绩,篮板球数、得分数、失误数这三个影响因素在影响程度方面和正负影响方面不尽相同。对于失误数来讲,失误数越多,比赛战绩越是不理想,但二者不存在绝对的线性关系,即根据失误数很大程度上不可以判断球队战绩排
名;对于篮板球数,对比赛影响较大,且篮板球数越多,赢得比赛的几率越大,同时战绩则越好,一般情况下可以预测比赛结果,二者存在线性关系;对于得分,可以说是三者之中影响比赛结果以及球队战绩最大的因素,二者相关性明显高于篮板球数对战绩的影响,并且可以根据球队场均得分数与对手的分数的比较预测球队战绩。因此,为取得更好的赛季战绩,应该避免过多的失误,并在比赛中抢到更多的篮板,更多得分。
但是,在实际中,这三者往往是相互关联的,例如,失误更多的给对手创造得分机会,篮板球会给自己创造得分及会。因此,不能忽视将三者相互协调,在比赛中,三者缺一不可。
对CBA的启示:NBA是目前世界上顶级的篮球赛事,在运营管理、球队建设等方面已非常完善。中国职业化的CBA赛事起步
较晚,在很多方面存在不足。CBA与NBA均是篮球运动,虽然有一些差异,但共同点不少。因此,NBA在各方面的许多经验值得CI讼借鉴和学习。
1.主场文化。NBA球队主场优势特别明显,主要得益于其健全的主场文化。主场观众有组织的加油助威对主队各方面指标影响显著,直接影响到球队战绩。而CBA由于发展得较晚,主场文化尚未形成,各球队打球时主客场差异较不显著,这样将直接影响比赛的观赏性,尤其难以调动当地球迷观看比的热情。建立健全的主场文化,充分发挥主场优势,不仅有助于主场文化的形成,更有利于整个CBA的发展。
2.教练员执教能力。NBA球队胜率跟教练员执教能力关系显著,而这点可能没有得到CBA球队足够的重视。在选择教练员的时候,CBA不仅应注重教练员的执教经验,同时要兼顾教练员对球队的了解程度,可以鼓励从球队退役的优秀运动员留教、派送优秀教练员到国外学习或者聘请一些国外知名的教练到球队任教,让运动员接触新
3.核心运动员能力。Q认核心运动员尽管没有NBA运动员能力那么强,但是一个球队的核心运动员的作不在能力多强,重点在于引进或培养高水平运动员来整个球队打好比赛,鼓舞球队士气。鉴于NBA中核动员对球队取得胜利影响显著,CBA各球队应该尽量拥有一位具有一定影响力的核心运动员,在球队里面到领衔作用,更好地组织球队打球;同时,依靠核心运的知名度也能得到观众更多的关注,增加整个CBA的观赏性。
4.球队防守。在NBA中,战绩较好的球队都是防守强的队(如湖人队和魔术队),而且NBA观赏性很高因之一也在于其高强度的防守。然而,在目前的CBA比赛中,各队都过于注重进攻、追求比分,而忽视了球队防守,使得比赛看起来得分很高,但观赏性不高。可见,为了提高球队的整体实力以及比赛观赏性,各队应该增强防守力度,让观众真正感受到比赛的紧张、激烈。
5.年轻运动员。NBA球队都比较重视年轻运动员的培养和选拔,从NBA选秀制度和其年轻运动员上场时问都可以体现出来,这是NBA联盟长期保持高水平的源泉。建议CBA各队要注重对年轻运动员的培养和选拔,尽管CBA的选秀制度短期内没法达到NBA的水平,但较完善的制度总能选到一些较优秀的年轻运动员,这将有利于球队以及整个CBA的健康发展。相信CBA若能参考NBA在各方面的成功经验,并针对自身存在的问题给予改进,将极大地促进各球队的发展,推动整个CBA联赛的长久健康发展。CBA的健康发展,必能为提升篮球在我国的进一步普及和中国国家篮球
队的良好战绩做出应有的贡献。
第二篇:地统计学论文
在逻辑回归和克里金该方法的基础上研究土壤污染和人类活动的相关性
关键词:回归克里金 逻辑回归 指示克里金 重金属 土壤污染
摘要:在台湾的中心地区,量化土壤的污染和长期土地利用的相关性是一个管理土壤资源的非常有效地方式。定义有害的地区为重金属含量超过相应的可控标准的地区,此项研究不仅估算了有害地区概率分布的空间格局,有害地区的概率是使用指示克里金方法而且只基于那些可观测的重金属数据得出,还通过逻辑回归和回归克里金法考虑辅助变量来估算可能有害地区的空间格局。估算结果显示通过指示克里金法和回归克里金法估算的有害空间格局比用指示克里金法估算的还要零碎。此外,指示克里金和回归克里金能够确定污染源和污染途径的关系。在结果的基础上,受害地区和工长的位置以及研究区灌溉系统的位置有着极为密切的关系。这些方式为未来检测土壤污染提供了一个探索危害性的有效方式。逻辑克里金和回归克里金不仅能识别土壤污染的自然和人为的因素,而且提高了辨别受害区域土壤污染的超微性。特别是,回归克里金法考虑到用空间残差来改善逻辑克里金中的优势。
1. 介绍
金属离子位于饮食来源必须提供的关键营养当中。一些重金属元素是人类每分每秒必不可少的,然而那些超过限制的不是致癌的就是有毒的。此外,由于重金属在人体内不能被降解或是摧毁,所以他们具有持久性。重金属污染和人类活动有密切的关系。化学和冶金行业是重金属在自然中最重要的来源。还有,由于人类的活动土壤的重金属污染已占主导趋势。重金属集中的热点地区是离台湾中部近的工厂和灌溉系统。工厂被怀疑往台湾中部的灌溉渠道排放废水,当地的站点可能被这种途径污染。由于人类的行为活动,不合理的废水处置,农业土壤的重金属污染在全世界范围内快速增长。
在逻辑回归的基础上,许多研究已经分析出推动力因素和土壤污染是怎样相互关系着来决定土壤污染发生的可能性。逻辑回归分析检查出污染集中区的概率超出了一系列资源的极限值。使用逻辑回归,tesoriero 和voss估计普吉声音盆地硝酸盐污染的含水层脆弱性。使用同样的方式,twarakavi 和 kaldarachchi sumas-blaine 预测含水层重金属污染物的敏感性。也是使用逻辑回归,lee 量化出砷浓度和水化学参数的污染敏感性是怎样相关联的。他们的研究在基于推动力的点上确定出决定污染公害的概率。为了增加逻辑回归模型的准确率,这个研究通过套用回归克里金法建模而得出重金属的危害概率。回归克里金法包含着对辅助变量的因变量的回归分析和回归残差的简单克里金。大多数研究证实回归克里金对于实际应用中的空间估计是一种灵活但又稳健的方式。基于回归克里金法,趋势估计与残余插值是分离的,趋势估计涉及到任意复杂形式的回归。通过使用回归克里金,基于已建立的过程模型staceyetal改善了土壤中氧化亚氮的预测能力。Hengletal讨论回归克里金的特征,优点和极限,用一个简单的例子和三个案例研究举例说明了这些特征。众所周知,回归克里金是一种混合残差的方式。回归克里金起初在辅助信息上使用回归分析,后来使用简单的克里金并用一个非常出名的方式向回归分析模型中插入残差。
此外,土壤污染监测在弄明白环境的危险性方面,是一个必须的和过高花费的过程。不用测量整个区域内的土壤数据,克里金模型就能被用来估计土壤污染的空间格局。指示克里金法除了划定有危害的区域,还能确定区域内重金属污染的概率分布。指示克里金法提供了一个非参数分布,估计非抽样位置直接使用固定扩值和澄清公害危险的空间格局。通过使用指示克里金,goovaert 估计并绘制出镉和铜污染的危害程度,引入了瑞士岸区域的表土层。基于指示克里金法,van meihe goovaert评估出重金属集中区污染元素的概率,那些元素超过了比利时空气传播的镉污染区域的环境极限值。以上这个模型通过观察土壤集中区和测量研究区域的数据,而适用于评估重金属污染区域的有害危险程度。
进一步,此项研究的目的是:1.辨别土壤污染中包括人类行为多变性的因素2.提高估计的准确性3.评估有土壤重金属污染的空间有害地图4.强调土壤中带有金属的热点地区的分布率。
2.方法和材料
研究评估台湾中部地区工厂附近的一个农业区的空间地图,特别强调土壤中金属元素的分布和关系。在逻辑回归和克里金的基础上,重金属的空间分布格局被予以分析。讨论台湾长华村人类行为和重金属的抽样调查。
2.1研究区域
区域是台湾一个非常重要的农业区的长华村。东边是长华市,西边是鹿港镇。此区域的农业用地是461ha,占整个区域的百分之六十二。在1970年以后,政府鼓励轻工业。将近106家工厂聚集在这个研究区。在这个研究区的工厂包括金属业,电镀业,纺织业以及金属表面处理业,些工厂被怀疑往研究区的灌溉渠道排放污水。
2.2抽样调查和化学分析
20##年的2月到8月之间,台湾的环境保护管理会在这个研究区开展了一个土壤重金属调查项目,调查了1309个表土层的例子(包括铬,铜,镍,锌,铅,砷,镉和汞的集中区),并得出了数据。由于研究区农地的不规则性,抽样战略地点是不一致的。研究区不是一个规则的区域,它是由于灌溉系统的地形决定的。这些抽样的地方在图一(b)里显示。使用不锈钢铲子和再生障碍性勺子从每一个样区采集接近1公斤的土壤,然后储藏在塑料食物袋。在室温下将空气晾干后,每一份样土有3克被分解,筛到0.85毫米,地面的0.15毫米是细粉。每3克研磨样品在室温条件下加入7毫升硝酸和21毫升盐酸吸收2小时,慢慢地氧化土壤中的有机物。接下来,这个100毫升的王水将被过滤。最后,电感偶合Plasma-Optical发射光谱仪确定样品集中区的重金属水平。
图一(b)
2.3逻辑回归法
逻辑回归提供了基于推动力基础上每一个位置每一种污染危害出现的概率。逻辑回归法定量危害发生和推动力之间的关系,规定如下:
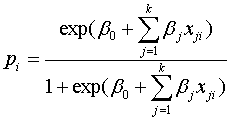 (1)
(1)
and
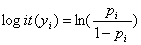 (2)
(2)
 表示在网格单元
表示在网格单元 中超过可控标准集中区重金属元素的概率,
中超过可控标准集中区重金属元素的概率, 是推动力因素的个数,y
是推动力因素的个数,y 表示在网格单元中相互依存的指标变量,x
表示在网格单元中相互依存的指标变量,x 表示在
表示在 因素下的每一个因素的值,
因素下的每一个因素的值, 是估计系数,
是估计系数, 是逻辑模型中每一个推动力因素的系数。研究中的逻辑回归由SPSS统计软件执行,重要变量由卡方检验确定。
是逻辑模型中每一个推动力因素的系数。研究中的逻辑回归由SPSS统计软件执行,重要变量由卡方检验确定。
2.4回归克里金法
随机功能被模拟为是趋势和随机变量的结合物。回归克里金用两种方法去连接这些:回归法用于适应解释型变量,用期望值为零的简单克里金法去适应残差。
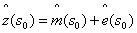
=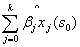 +
+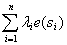 (3)
(3)
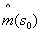 是拟合的趋势,
是拟合的趋势, 是剩余插值,
是剩余插值, 是推动力因素,
是推动力因素, 是估计的趋势模型系数,
是估计的趋势模型系数, 是残差的空间独立结构决定的克里金重量并且e(s)是在s处的残差值。回归系数用合适的方式从样本中估计。
是残差的空间独立结构决定的克里金重量并且e(s)是在s处的残差值。回归系数用合适的方式从样本中估计。
此外,回归克里金在数学上是与普遍克里金以及外部漂移克里金是一样的。回归克里金能够将辅助变量整合而构成关心属性的普遍趋势。克里金方式然后适用于模拟残差的空间分布。回归克里金中有害污染概率的估计由研究中逻辑回归提供。
2.5指示克里金
指示克里金估计的是一个给定的位置点超过特别极限值的污染物集中区的概率,数据z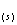 被定义为以下指标:
被定义为以下指标:
I(s,z)={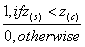 (4) 有问题
(4) 有问题
如果重金属的集中程度z超过了z 则指示值是0,否则为1.
则指示值是0,否则为1.
在n确定的条件下,I(s;z|(n))的估计值,如以下所示:
E[I(s;z|(n))]=Prob[z≤z|(n) ] (5)
超过z的概率如以下所示,
Prob[z>z|(n) ] =1- Prob[z≤z|(n) ] (6)
普遍克里金的概率分布为:
Prob[z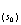 ≤z|(n) ]=
≤z|(n) ]=
 (7)
(7)
在(7)式中,I(s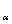 ;z
;z )代表在
)代表在 确定的情况下的指数值,
确定的情况下的指数值, =1,…,n;
=1,…,n; 是I(s;z)的权重,I(s;z)是由以下克里金体系确定的:
是I(s;z)的权重,I(s;z)是由以下克里金体系确定的:
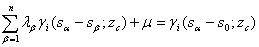 (8)
(8)
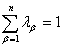 (9)
(9)
在(9)式中, 是拉格朗日乘数,
是拉格朗日乘数, 是在样本
是在样本 和
和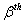 之间变化的指标值,
之间变化的指标值, 是在样本和s
是在样本和s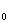 之间变化的指标值,=1,…,n;研究中的克里金和指标
之间变化的指标值,=1,…,n;研究中的克里金和指标
克里金是由GSLIB(地统计数据库)执行的。
3.结果和讨论
3.1基本的统计数据
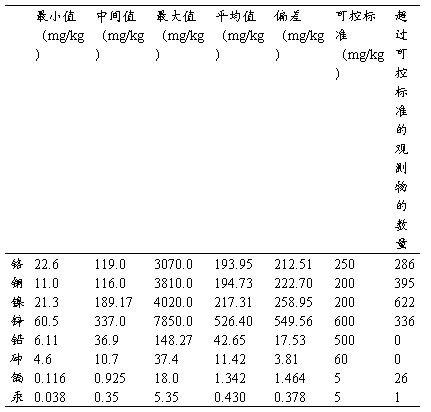
表1总结了八种被调查的重金属的统计数据。在台湾,污染控制标准如以下所示,该标准是由台湾环境保护组织通过对监管区土壤重金属调查所得:铬:250mg/kg,铜:200 mg/kg,镍:200 mg/kg,锌:600 mg/kg,铅:500 mg/kg,砷:60 mg/kg,镉:5 mg/kg,汞:5 mg/kg。表一列举了超过可控标准的例子,铬的286个,铜的395个,镍的622个,锌的336个。一些例子对于镉(26例)和汞(1例)是可利用的。在研究区没有砷和铅污染的出现。基于基本的统计分析,四种重金属元素(铬,铜,镍,锌)被选定来评估空间污染危害地图。
表一:原例中得重金属的描述性统计
3.2逻辑回归法估计的空间概率
基于逻辑回归模型,超过可控标准的重金属集中区的概率通过预测危害与污染源的关系被评估出来。表二列举了四种重金属元素的逻辑回归模型的系数。在回归结果的基础上,金属业的距离与确定此地铬污染的可疑性成正比例关系。同时,距渠道的距离,汽车修理厂的距离以及造纸业的距离与概率成反比例关系。水业的距离,所有工厂的距离以及化学业的距离有助于评估铜危害的危险性。然而,农业土地,距渠道的距离,距灌溉渠道的距离,距主要灌溉渠道的距离,表面处理业,纺织业电镀业以及其他行业的距离与铜危害性污染成负相关关系。为了估计镍污染发生的概率,合适的逻辑模型使用了三个正相关的系数因素(与金属业,纺织业的距离)和负相关因素(农用地,与渠道灌溉,渠道,皮革,橡胶业的距离)。为了估计锌危害发生的概率四个正相关因素(人口,与水产业化学工业金属业)和七个负相关因素(建设用地,农用地与渠道,主要灌溉渠道,排水渠道,造纸业,电镀业的距离)被用来适用逻辑模型。还有,人口密度,离主干道的距离,土壤水力传导系数和土壤流失因素不具有统计学意义,没有改善模型的利用。结果反映出在研究区人口密度以及土壤性质和土壤污染物没有直接的关系。
表二
图2在逻辑回归的基础上,显示出超过可控标准的土壤集中区的概率图,其中包括铬,铜,镍和锌。研究区重金属的可疑性显示出人类活动在这个地区占主导地位,人类活动导致了高的重金属积聚。结果也显示出逻辑回归是另一种实用的估计土壤污染发生率的方式,即使在没有直接测量各处污染物的每一个例子中都能实现。总的说来,地图指示出工厂和灌溉系统和高的可变性密切相关。和先前有关的估计结果指示出重金属的实用以及人类资源的分布与工厂和灌溉渠道有密切的关系。此外,来源于人类不同的活动的污染物影响着土壤。由于工业活动,重金属的农业土壤污染已经变得更严重而遍布整个研究区。重金属污染与像电镀业,金属业,金属表面处理,纺织业这样的工厂有关系。研究区,土壤集中区与化学原料使用的强度以及工业化的程度相关。由于研究区金属土壤集中区的分布,工业活动和农业活动是重金属污染的主要原因。土壤,特别是那些用污染的水灌溉的地区,含有非常高的重金属数量。
图二
3.3通过克里金方法得出的空间分布率
地统计学能通过变差函数描述环境数据的空间格局,预测非抽样地区有关属性的值。超过可控标准的任何一个非抽样点的重金属污染的概率由克里金模型所确定。有害物质概率的空间分布能够通过指示变差函数来确定。变差是变差函数模型的一种功能。表三列出了四种重金属元素的指示变差函数的参数。铬和铜是指数模型镍和锌是球状模型。模型中所有的R的平方都超过了0.92。在抽样点之中变差函数定量了有害物质地图的空间多变性。变差的结果指示出铬和铜的范围是57米和66米。然而镍和锌的范围是255米和252米。这个发现揭示出一种空间相关性,镍和锌的距离比铬和铜的距离远。以上结果也揭示出锌的变差模型有较高的块金值,显示出小规模的多变性。
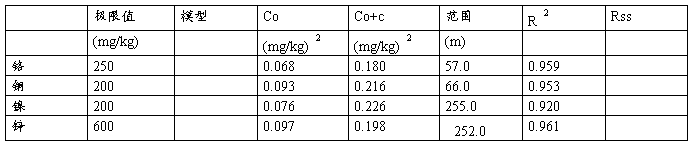
Rss代表面积减少的总量
图3显示了铬,铜,镍,锌的土壤污染的概率图,这四种元素都超过了逻辑克里金的可控标准。估计结果指示出镍污染的有害性超过了其他元素。图4显示了回归克里金下超过可控标准的重金属概率图,并且提高了逻辑回归的结果。然而,逻辑回归的空间的概率分布图缺少空间相关性。在观测的多个方面上,回归克里金和逻辑克里金的图表显示了多变性的相似形式和重金属的集中分布,但是锌不包括在内。采用克里金方法的图包括了观测点的特征,显示了研究区有害土壤的碎片形式。还有,回归克里金的结果显示通过增加克里金估计到回归预测值里去,是降低回归克里金预测方差的有效方式。当介绍空间趋势的确定性进程极大地影响土壤污染的可变性时,一个纯粹随机的地理统计学的假设是不能令人满足的。
在研究过程中,土壤污染物的的分布趋势的确定是通过把污染来源的信息纳入模型当中。明显的,人类可能影响着重金属的空间分布图。在大多数地点带有重金属特征的有害物通常污染来源加倍。此外,土壤污染物的结果可疑性地图提供了一种可替代方式,这种方式可以探索空间资源和未来环境管理工程的不确定污染物。
3.4逻辑回归和克里金方法的比较
表四
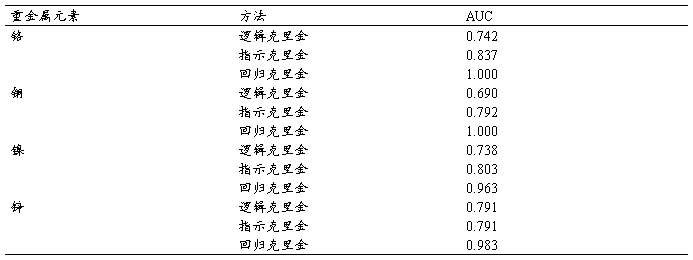
相对操作特征是衡量逻辑回归或者指示克里金适宜性的标准。低于ROC曲线的地区被估算着去测量模型中的解释性力量。AUC的估计值超过0.7的被普遍的认为是优良的,然而估计值超过0.9被认为是预示了一个极好的模型适宜性。表四总结了铬,铜,镍,锌在三种模型中的AUC。逻辑回归的AUC值从0.690到0.791,指示克里金的AUC值从到0.791到0.837,回归克里金的AUC值从0.963到1。AUC结果显示回归克里金的AUC比指示克里金和逻辑回归的AUC都高。这个发现暗示着回归克里金比指示克里金和逻辑回归有着较高的预测力。还有,回归克里金提供了任何一种重金属基于推动力因素在任何的位置危害可能性的概率。这个发现也预示着回归克里金产生一些益处,也定量着有害危险与推动力因素之间的关系。我们的研究结果和之前的一个研究相一致,回归克里金是一个很有效的空间预测方式,而且这种方式能在大的点设置时插入样本环境变量。此外,juanghe lee在辅助变量(协同克里金,回归克里金,有Q码因素分析的克里金)的基础上使用了三种插入方式在台湾的一个污染地插入了重金属集中区。这些插入方式更有效的使用辅助变量评估概率,以至于估计出重金属的空间分布。
表五

在研究当中,这三种方式除了提供每一种重金属元素危害的概率,而且在划定有害地区也是非常有效的。此外,0.95,0.85.0.75以及0.50的有害概率分布被用来划定土壤污染物的安全与有害区域,同时在多种概率的基础上描绘有害的状况。表五指示出有害区的百分比随着有害标准的不同而不同。多种方式决定的多种有害地区的结果为政策的制定者在更深的程度提供了一个有价值的参考。估计结果显示出有重金属污染等级的区域铬的含量是0到2.8%,铜的是3.%到4.4%,镍的是13.2%到18.3%,锌是2.5%到38.3%。这个发现提供了有害地区的信息,除了逻辑回归中的锌研究区域的四种重金属元素中,镍占有害污染的最大部分。这个研究在概率图的基础上,运用了三种方法去辨别安全的和有害的区域。和克里金方式相比较,通过逻辑回归的方法得出了锌的含量过高,通过逻辑回归的方法得出的铬铜镍的含量过低。更进一步,以上结果显著地作用于通过使用这三种方式而量化的有害区的成果。
4.结论
这个研究调查了模型方式的可行性,运用一个特别的案例研究探测污染和人类活动的关系。估计结果显示出回归克里金提高了预测效率,并在一个相对高程度的适宜环境中提供了可解释性力量。此外,像距渠道的距离,农业用地,工厂的距离这些推动力因素和土壤的重金属污染有着密切关系。这种提出的方式能够被延伸至包括土壤污染的交通运输。在研究区土壤污染和污染来源有密切的关系,来源包括工业工厂和灌溉系统。这些提倡的模型在人们没有确定土壤集中区而直接覆盖整个研究区域的情况下这是非常高端的,用来评估重金属的可疑性。通过空间地图,模型估计能够使土地利用的计划者帮着辨别有污染的区域。还有,逻辑回
5.致谢(未翻译)
报告