腾讯笔试题:
const的含义及实现机制const的含义及实现机制,比如:const int i,是怎么做到i只可读的?
const用来说明所定义的变量是只读的。这些在编译期间完成,编译器可能使用常数直接替换掉对此变量的引用。 腾讯笔试题:买200返100优惠券,实际上折扣是多少?到商店里买200的商品返还100优惠券(可以在本商店代替现金)。请问实际上折扣是多少?
由于优惠券可以代替现金,所以可以使用200元优惠券买东西,然后还可以获得100元的优惠券。假设开始时花了x元,那么可以买到x + x/2 + x/4 + ...的东西。所以实际上折扣是50%.(当然,大部分时候很难一直兑换下去,所以
50%是折扣的上限)如果使用优惠券买东西不能获得新的优惠券,那么总过花去了200元,可以买到200+100元的商品,所以实际折扣为200/300 = 67%.
腾讯笔试题:tcp三次握手的过程,accept发生在三次握手哪个阶段?
accept发生在三次握手之后。第一次握手:客户端发送syn包(syn=j)
到服务器。第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个
ASK包(ask=k)。第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1)。三次握手完成后,客户端和服务器就建立了tcp连接。这时可以调用accept函数获得此连接。
腾讯笔试题:用UDP协议通讯时怎样得知目标机是否获得了数据包用UDP协议通讯时怎样得知目标机是否获得了数据包?
可以在每个数据包中插入一个唯一的ID,比如timestamp或者递增的int。 发送方在发送数据时将此ID和发送时间记录在本地。接收方在收到数据后将ID再发给发送方作为回应。发送方如果收到回应,则知道接收方已经收到相应的数据包;如果在指定时间内没有收到回应,则数据包可能丢失,需要重复上面的过程重新发送一次,直到确定对方收到。
腾讯笔试题:统计论坛在线人数分布
求一个论坛的在线人数,假设有一个论坛,其注册ID有两亿个,每个ID从登陆到退出会向一个日志文件中记下登陆时间和退出时间,要求写一个算法统计一天中论坛的用户在线分布,取样粒度为秒。一天总共有3600*24 = 86400秒。定义一个长度为86400的整数数组int delta[86400],每个整数对应这一秒的人数变化值,可能为正也可能为负。开始时将数组元素都初始化为0。然后依次读入每个用户的登录时间和退出时间,将与登录时间对应的整数值加1,将与退 出时间对应的整数值减1。这样处理一遍后数组中存储了每秒中的人数变化情况。
定义另外一个长度为86400的整数数组
int online_num[86400],每个整数对应这一秒的论坛在线人数。 假设一天开始时论坛在线人数为0,则第1秒的人数online_num[0] = delta[0]。第n+1秒的
人数online_num[n] = online_num[n-1] + delta[n]。 这样我们就获得了一天中任意时间的在线人数。
腾讯笔试题:从10G个数中找到中数 在一个文件中有
10G 个整数,乱序排列,要求找出中位数。内存限制为2G。 不妨假设10G个整数是64bit的。 2G内存可以存放256M个64bit整数。我们可以将64bit的整数空间平均分成256M个取值范围,用2G的内存对每个取值范围内出现整数个数进行统计。这样遍历一边10G整数后,我们便知道中数在那个范围内出现,以及这个范围内总共出现了多少个整数。如果中数所在范围出现的整数比较少,我们就可以对这个范围内的整数进行排序,找到中数。如果这个范围内出现的整数比较多,我们还可以采用同样的方法将此范围再次分成多个更小的范围(256M=2^28,所以最多需要3次就可以将此范围缩小到1,也就找到了中数)。
腾讯笔试题:两个整数集合A和B,求其交集两个整数集合A和B,求其交集。1. 读取整数集合A中的整数,将读到的整数插入到map中,并将对应的值设为1。2. 读取整数集合B中的整数,如果该整数在map中并且值为1,则将此数加入到交集当中,并将在map中的对应值改为2。通过更改map中的值,避免了将同样的值输出两次。
腾讯笔试题:找出1到10w中没有出现的两个数字
有1到10w这10w个数,去除2个并打乱次序,如何找出那两个数?申请10w个bit的空间,每个bit代表一个数字是否出现过。开始时将这10w个bit都初始化为0,表示所有数字都没有出现过。然后依次读入已经打乱循序的数字,并将对应的bit设为1。当处理完所有数字后,根据为0的bit得出没有出现的数字。首先计算1到10w的和,平方和。然后计算给定数字的和,平方和。两次的到的数字相减,可以得到这两个数字的和,平方和。所以我们有
x + y = n x^2 + y^2 = m 解方程可以得到x和y的值。腾讯笔试题:需要多少只小白鼠才能在24小时内找到毒药有1000瓶水,其中有一瓶有毒,小白鼠只要尝一点带毒的
水24小时后就会死亡,至少要多少只小白鼠才能在24小时时鉴别出那瓶水有毒?最容易想到的就是用1000只小白鼠,每只喝一瓶。但显然这不是最好答案。既然每只小白鼠喝一瓶不是最好答案,那就应该每只小白鼠喝多瓶。那每只应该喝多少瓶呢?首先让我们换种问法,如果x小白鼠,那么24小时内可以从多少瓶水中找出那瓶有毒的?由于每只小白鼠都只有死或者活这两种结果,所以x只小白鼠最大可以表示2^x种结果。如 果让每种结果都对应到某瓶水有毒,那么也就可以从2^x瓶水中找到有毒的那瓶水。那如何来实现这种对应关系呢? 第一只小白鼠喝第1到2^(x-1)瓶,第二只小白鼠喝第1到第2^(x-2)和第2^(x-1)+1到第2^(x-1) + 2^(x-2)瓶....以此类推。回到此题,总过1000瓶水,所以需要最少10只小白鼠。腾讯笔试题:根据上排的数填写下排的数,并满足要求。根据上排给出十个数,在其下排填出对应的十个数, 要求下排每个数都是上排对应位置的数在下排出现的次数。上排的数:0,1,2,3,4,5,6,7,8,9。腾讯笔试题:判断数字是否出现在40亿个数中?给40亿个不重复的unsigned int的整数,没排过序的,然后再给几个数,如何快速判断这几个数是否在那40亿个数当中? 答案:unsigned int 的取值范围是0到2^32-
1。我们可以申请连续的2^32/8=512M的内存,用每一个bit对应一个unsigned int数字。首先将512M内存都初始化为0,然后每处理一个数字就将其对应的bit设置为1。当需要查询时,直接找到对应bit,看其值是0还是1即可。 填空题是补充完整程序。 附加题有写算法的、编程的、数据库sql语句查询的。还有一张c/c++开放性问题。腾讯c/c++笔试题如下:
1、请定义一个宏,比较两个数a、b的大小,不能使用大于、小于、if语句
#define Max(a,b) ( a/b)?a:b
2、如何输出源文件的标题和目前执行行的行数
int line = __LINE__; char *file = __FILE__;
cout<<"file name is "<<(file)<<",line is "<<LINE<<ENDL;< p>
3、两个数相乘,小数点后位数没有限制,请写一个高精度算法
4、写一个病毒
while (1) { int *p = new int[10000000]; }
5、不使用额外空间,将A,B两链表的元素交*归并
6、将树序列化转存在数组或链表中
struct st{ int i; short s; char c; };
sizeof(struct st);
7、 char * p1; void * p2; int p3; char p4[10]; sizeof(p1...p4) =?
8、4,4,4,10 二分查找快速排序,双向链表的删除结点 由于近来有些人都问我腾讯笔试和面试到底是考什么,问什么,所以就灌下这篇水文,也算是我自己复习一遍以及给有兴趣或者后来者嗤鼻一笑的机会:)其实应聘内容也真的很难说清楚,而且我也不知道我所经历的是不是有代表性,何况我还是找工作的新手(本科也没找过工作,之前也只是应聘过华为),所以如果下文有什么疏漏之处,尽管踩我好了:)1。笔试我想腾讯的笔试还是比较适中的,虽然广度与深度都不够,但是毕竟因为它只是笔试,只是用来筛选面试者的,而不是象学术竞赛一样一战决胜负,何况它
是笔试,所以也就有笔试的局限性。(啊哦,是不是离题?)笔试主要是C++的内容,然后还有一部分数据结构、系统平台(WIN32和LINUX都有)的编程知识(线程模型、共享内存、编译或对象模型等)、JAVA(这次笔试JAVA有一题,是填写同步的关键字的,当然题目没有明明白白告诉你写synchronized这个关键字啦,否则就要被人BS了,哈哈。好在JAVA下的同步基本实现机制相当简洁,只要刚才那个关键字申明一下就可以了,学过java多线程模型的人都应该知道填什么,可惜我那时我也拼写错误了,漏了一个字母。。。,好象是5分一题的,损失不小哦)等。可以说还是比较有代表性的。这里罗嗦几句,有的人总是问为什么都考C/C++,我想因为C/C++才能比较好的表现出你的编程的水平(包括风格、惯用法、技巧性、严谨性等),就象堆积木,给你不同形状的积木越多,那你就越能堆出更多的造型。还有就是是OOP(这里废话几句~~ OOP思想很重要,记得当年初次接触C++真的是只知其所然,而不知其所以然。特别是“虚拟—virtual”这个词,可以说是最最核心的了,理解了它,你会觉得这个词实在太优美了,哈哈~~你可以这样测试你自己的OOP能力,针对OOP的三个特点用程序写出对应的例程,如果能够写得正确且健壮,那么应该也就什么问题了)做比较大的项目现在一般都采用OOP来实现的了(当然对于特殊的需求、环境和人除)。VB和DELPHI虽然也很流行,一方面是他们没有国际标准,其次是由于它太高级了,一些传统的编程技术被隐藏了,姑且不论VB(6。0以前)不支持OOP,那就更难用它来考OOP了,DELPHI支持OOP,但是我想很多同学都只是用它进行OBP,而不是OOP,所以。。。至于JAVA,我本人也很喜欢,而且怎么说,JAVA也很接近C++,何况其API也比C/C++ Library更规范、全面,所以使用起来很方便。但是正如考数学分析比考高等数学往往会加深对数学的理解的道理一样,除此以外也有另一层寓意,假如你能徒手打败你的敌人,那么再给你一把利剑,我想你会在更短的时间内结束战斗,呵呵。所以考C/C++还是比较合适的,公平是相对的。。。2。
一面面试其实也挺难说的,因为这个环节很灵活,也许在面试之前连面试官自己都不知道他自己将要问什么,呵呵。这里也只是给出一个case(归 纳法不适用,呵呵)。一面时,我只带了两页纸简历,到了面试地点,才发现很多人都是一叠资料的,有的人还不断在复习资料。。。别提当时我有多狼狈了。。。根据外貌和谈吐可以推断出一面面试官是一个前线的技术专家。面试时首先自我介绍,我一向没刻意去背自我介绍,但是也事先想好了的。然后就是问你哪种编程技术比较拿手啊,项目经验啊,我想关键是深度一定要够,一定要体现你的参与价值和收获,不管是开发过程还是开发技术。面试时我分别从开发过程与开发技术两个方面说了两个项目,感觉面试官还是接受了的,然后小部分技术细节,比如说在一个项目里面为了解决一个问题,你采取了什么策略,采用了什么技术,这个可千万不能说错哦,不然你就是在自打嘴巴了。。。也许我的笔试成绩还可以,所以语言层面的问题基本没有了。总结,这个面试官很实在,也相当和蔼可亲。。。 3。二面二面的面试官比一面的少,应该都是部门经理。坐这个位置的人 都是技术和管理的大拿了,当然这是后来知道的啦。因此这次面试分技术和非技术两部分,不过主要还是技术的。首先还是自我介绍。。。然后面试官就开始设擂台了,问你觉得笔试试卷出得如何?我思考了2秒钟,说比较适中(如果我说难,那么如果是简单的话,那我就被BS了,实际上也不难吧,说容易吧,如果我考得不好,分数我倒是看到过,但是不知道那算高还是低,所以很容易被BS),看面试官表情,显然我的回答应该没有W/A掉。接着,他继续问到,你觉得你做错了或者没有把握的题目是哪题。我就说了两三题了,然后他奸诈的看看了我的试卷,从他的表情,我知道,嘿嘿,这个回合是我赢了。然后他就要我介绍一个有代表性的项目。显然这次跟一 面要有所变化才行,毕竟是二面了。于是我挑了一个比较容易表述的,简洁清晰,又有一定技术难度的(主要是系统架构方面)展开攻防战,
此情此景。。。恩,你猜对了,就象电视上看到的警察审讯嫌疑犯一样,呵呵,只是这个“警察”是面带笑容的。。。反正,他会象导弹一样追着你来“攻击”,如果你承受不了的话就要中弹了,等到你中得多了,游戏也就GAME OVER了。。。我想最好还是讲得高深一。
第二篇:(腾讯)后台开发面试题解答
linux和os:
netstat :显示网络状态
tcpdump:主要是截获通过本机网络接口的数据,用以分析。能够截获当前所有通过本机网卡的数据包。它拥有灵活的过滤机制,可以确保得到想要的数据。 ipcs:检查系统上共享内存的分配
ipcrm:手动解除系统上共享内存的分配
(如果这四个命令没听说过或者不能熟练使用,基本上可以回家,通过的概率较小 ^_^ ,这四个命令的熟练掌握程度基本上能体现面试者实际开发和调试程序的经验)
cpu 内存 硬盘 等等与系统性能调试相关的命令必须熟练掌握,设置修改权限 tcp网络状态查看 各进程状态 抓包相关等相关命令 必须熟练掌握
awk sed需掌握
共享内存的使用实现原理(必考必问,然后共享内存段被映射进进程空间之后,存在于进程空间的什么位置?共享内存段最大限制是多少?)
共享内存定义:共享内存是最快的可用IPC(进程间通信)形式。它允许多个不相关的进程去访问同一部分逻辑内存。共享内存是由IPC为一个进程创建的一个特殊的地址范围,它将出现在进程的地址空间中。其他进程可以把同一段共享内存段“连接到”它们自己的地址空间里去。所有进程都可以访问共享内存中的地址。如果一个进程向这段共享内存写了数据,所做的改动会立刻被有访问同一段共享内存的其他进程看到。因此共享内存对于数据的传输是非常高效的。 共享内存的原理:共享内存是最有用的进程间通信方式之一,也是最快的IPC形式。两个不同进程A、B共享内存的意思是,同一块物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存中数据的更新,反之亦然。
c++进程内存空间分布(注意各部分的内存地址谁高谁低,注意栈从高到低分配,堆从低到高分配)
ELF是什么?其大小与程序中全局变量的是否初始化有什么关系(注意未初始化的数据放在bss段)
可执行文件:包含了代码和数据。具有可执行的程序。
可重定位文件:包含了代码和数据(这些数据是和其他重定位文件和共享的 object文件一起连接时使用的)
共享object文件(又可叫做共享库):包含了代码和数据(这些数据是在连接 时候被连接器ld和运行时动态连接器使用的)。
使创建共享库容易,使动态装载和共享库的结合更加容易。在ELF下,在C++ 中,全局的构造函数和析构函数在共享库和静态库中用同样方法处理。 使用过哪些进程间通讯机制,并详细说明(重点)
makefile编写,虽然比较基础,但是会被问到
mkdir mf
cd mf
vim makefile
hello.o:hello.c hello.h
gcc –c hello.o -Lm
make
./hello
gdb调试相关的经验,会被问到
如何定位内存泄露?
内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的、大小任意的(内存块的大小可以在程序运行期决定)、使用完后必须显示释放的内存。应用程序一般使用malloc、realloc、new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块。否则,这块内存就不能被再次使用,我们就说这块内存泄漏了。
C++程序缺乏相应的手段来检测内存信息,只能使用top指令观察进程的动态内存总额。而且程序退出时,我们无法获知任何内存泄漏信息
使用Linux命令回收内存,可以使用ps、kill两个命令检测内存使用情况和进行回收。在使用超级用户权限时使用命令“ps”,它会列出所有正在运行的程序名称和对应的进程号(PID)。kill命令的工作原理是向Linux操作系统的内核送出一个系统操作信号和程序的进程号(PID)
动态链接和静态链接的区别
动态链接是指在生成可执行文件时不将所有程序用到的函数链接到一个文件,因为有许多函数在操作系统带的dll文件中,当程序运行时直接从操作系统中找。 而静态链接就是把所有用到的函数全部链接到exe文件中。
动态链接是只建立一个引用的接口,而真正的代码和数据存放在另外的可执行模块中,在运行时再装入;而静态链接是把所有的代码和数据都复制到本模块中,运行时就不再需要库了。
32位系统一个进程最多有多少堆内存
多线程和多进程的区别(重点 面试官最最关心的一个问题,必须从cpu调度,上下文切换,数据共享,多核cup利用率,资源占用,等等各方面回答,然后有一个问题必须会被问到:哪些东西是一个线程私有的?答案中必须包含寄存器,否则悲催)
写一个c程序辨别系统是16位or32位
法一:int k=~0;
if((unsigned int)k >63356) cout<<"at least 32 bits"<<endl;
else cout<<"16 bits"<<endl;
法二://32为系统
int i=65536;
cout<<i<<endl;
int j=65535;
cout<<j<<endl;
写一个c程序辨别系统是大端or小端字节序
用联合体:如char类型的,可以看他输出的是int的高字节还是低字节 信号:列出常见的信号,信号怎么处理?
i++是否原子操作?并解释为什么?
说出你所知道的linux系统的各类同步机制(重点),什么是死锁?如何避免死锁(每个技术面试官必问)
死锁的条件。(互斥条件(Mutual exclusion):1、资源不能被共享,只能由一个进程使用。2、请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。3、非剥夺条件(No pre-emption):已经分配的资源不能从相
应的进程中被强制地剥夺。4、循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。处理死锁的策略:1.忽略该问题。例如鸵鸟算法,该算法可以应用在极少发生死锁的的情况下。为什么叫鸵鸟算法呢,因为传说中鸵鸟看到危险就把头埋在地底下,可能鸵鸟觉得看不到危险也就没危险了吧。跟掩耳盗铃有点像。2.检测死锁并且恢复。3.仔细地对资源进行动态分配,以避免死锁。4.通过破除死锁四个必要条件之一,来防止死锁产生。)
列举说明linux系统的各类异步机制
exit()与_exit()的区别?
_exit终止调用进程,但不关闭文件,不清除输出缓存,也不调用出口函数。exit函数将终止调用进程。在退出程序之前,所有文件关闭,缓冲输出内容将刷新定义,并调用所有已刷新的“出口函数”(由atexit定义)。
?exit()?与?_exit()?有不少区别在使用?fork()?,特别是?vfork()?时变得很突出。 ‘exit()’与‘_exit()’的基本区别在于前一个调用实施与调用库里用户状态结构(user-mode constructs)有关的清除工作(clean-up),而且调用用户自定义的清除程序
如何实现守护进程?
守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。守护进程是一种很有用的进程。 Linux的大多数服务器就是用守护进程实现的。比如,Internet服务器inetd,Web服务器httpd等。同时,守护进程完成许多系统任务。比如,作业规划进程crond,打印进程lpd等。
守护进程的编程本身并不复杂,复杂的是各种版本的Unix的实现机制不尽相同,造成不同 Unix环境下守护进程的编程规则并不一致。需要注意,照搬某些书上的规则(特别是BSD4.3和低版本的System V)到Linux会出现错误的。下面将给出Linux下守护进程的编程要点和详细实例。
一. 守护进程及其特性
守护进程最重要的特性是后台运行。在这一点上DOS下的常驻内存程序TSR与之相似。其次,守护进程必须与其运行前的环境隔离开来。这些环境包括未关闭的文件描述符,控制终端,会话和进程组,工作目录以及文件创建掩模等。这些环境通常是守护进程从执行它的父进程(特别是shell)中继承下来的。最后,守护进程的启动方式有其特殊之处。它可以在Linux系统启动时从启动脚本
/etc/rc.d中启动,可以由作业规划进程crond启动,还可以由用户终端(shell)执行。
总之,除开这些特殊性以外,守护进程与普通进程基本上没有什么区别。因此,编写守护进程实际上是把一个普通进程按照上述的守护进程的特性改造成为守护进程。如果对进程有比较深入的认识就更容易理解和编程了。
二. 守护进程的编程要点
前面讲过,不同Unix环境下守护进程的编程规则并不一致。所幸的是守护进程的编程原则其实都一样,区别在于具体的实现细节不同。这个原则就是要满足守护进程的特性。同时,Linux是基于Syetem V的SVR4并遵循Posix标准,实现起来与BSD4相比更方便。编程要点如下;
1. 在后台运行。
为避免挂起控制终端将Daemon放入后台执行。方法是在进程中调用fork使父进程终止,让Daemon在子进程中后台执行。
if(pid=fork())
exit(0); //是父进程,结束父进程,子进程继续
2. 脱离控制终端,登录会话和进程组
有必要先介绍一下Linux中的进程与控制终端,登录会话和进程组之间的关系:进程属于一个进程组,进程组号(GID)就是进程组长的进程号(PID)。登录会话可以包含多个进程组。这些进程组共享一个控制终端。这个控制终端通常是创建进程的登录终端。控制终端,登录会话和进程组通常是从父进程继承下来的。我们的目的就是要摆脱它们,使之不受它们的影响。方法是在第1点的基础上,调用setsid()使进程成为会话组长:
setsid();
说明:当进程是会话组长时setsid()调用失败。但第一点已经保证进程不是会话组长。setsid()调用成功后,进程成为新的会话组长和新的进程组长,并与原来的登录会话和进程组脱离。由于会话过程对控制终端的独占性,进程同时与控制终端脱离。
3. 禁止进程重新打开控制终端
现在,进程已经成为无终端的会话组长。但它可以重新申请打开一个控制终端。可以通过使进程不再成为会话组长来禁止进程重新打开控制终端:
if(pid=fork()) exit(0); //结束第一子进程,第二子进程继续(第二子进程不再是会话组长)
4. 关闭打开的文件描述符
进程从创建它的父进程那里继承了打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。按如下方法关闭它们:
for(i=0;i 关闭打开的文件描述符close(i);>
5. 改变当前工作目录
进程活动时,其工作目录所在的文件系统不能卸下。一般需要将工作目录改变到根目录。对于需要转储核心,写运行日志的进程将工作目录改变到特定目录如 /tmpchdir("/")
6. 重设文件创建掩模
进程从创建它的父进程那里继承了文件创建掩模。它可能修改守护进程所创建的文件的存取位。为防止这一点,将文件创建掩模清除:umask(0);
7. 处理SIGCHLD信号
处理SIGCHLD信号并不是必须的。但对于某些进程,特别是服务器进程往往在请求到来时生成子进程处理请求。如果父进程不等待子进程结束,子进程将成为僵尸进程(zombie)从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将 SIGCHLD信号的操作设为SIG_IGN。
signal(SIGCHLD,SIG_IGN);
这样,内核在子进程结束时不会产生僵尸进程。这一点与BSD4不同,BSD4下必须显式等待子进程结束才能释放僵尸进程。
三. 守护进程实例
守护进程实例包括两部分:主程序test.c和初始化程序init.c。主程序每隔一分钟向/tmp目录中的日志test.log报告运行状态。初始化程序中的init_daemon函数负责生成守护进程。读者可以利用init_daemon函数生成自己的守护进程。
linux的内存管理机制是什么?
Linux虚拟内存的实现需要6种机制的支持:地址映射机制、内存分配回收机制、缓存和刷新机制、请求页机制、交换机制和内存共享机制
内存管理程序通过映射机制把用户程序的逻辑地址映射到物理地址。当用户程序运行时,如果发现程序中要用的虚地址没有对应的物理内存,就发出了请求页要求。如果有空闲的内存可供分配,就请求分配内存(于是用到了内存的分配和回
收),并把正在使用的物理页记录在缓存中(使用了缓存机制)。如果没有足够的内存可供分配,那么就调用交换机制;腾出一部分内存。另外,在地址映射中要通过TLB(翻译后援存储器)来寻找物理页;交换机制中也要用到交换缓存,并且把物理页内容交换到交换文件中,也要修改页表来映射文件地址。
linux的任务调度机制是什么?
标准库函数和系统调用的区别?
1、系统调用和库函数的关系
系统调用通过软中断int 0x80从用户态进入内核态。
函数库中的某些函数调用了系统调用。
函数库中的函数可以没有调用系统调用,也可以调用多个系统调用。 编程人员可以通过函数库调用系统调用。
高级编程也可以直接采用int 0x80进入系统调用,而不必通过函数库作为中介。 如果是在核心编程,也可以通过int 0x80进入系统调用,此时不能使用函数库。因为函数库中的函数是内核访问不到的。
2、从用户调用库函数到系统调用执行的流程。
1) 假设用户调用ssize_t write (int fields, cont void *buff, size_t nbytes);库函数。
2) 库函数会执行int 0x80中断。因为中断使得进程从用户态进入内核态,所以参数通过寄存器传送。
3) 0x80中断对应的中断例程被称为system call handler。其工作是:
i. 存储大多数寄存器到内核堆栈中。这是汇编代码写的。
ii. 执行真正的系统调用函数――system call service routine。这是C代码。 iii. 通过ret_from_sys_call ()返回,回到用户态的库函数。这是汇编代码。
1、系统调用
系统调用提供的函数如open, close, read, write, ioctl等,需包含头文件unistd.h。以write为例:其函数原型为 size_t write(int fd, const void *buf, size_t nbytes),其操作对象为文件描述符或文件句柄fd(file descriptor),要想写一个文件,必须先以可写权限用open系统调用打开一个文件,获得所打开文件的fd,例如 fd=open(/"/dev/video/", O_RDWR)。fd是一个整型值,每新打开一个文件,所获得的fd为当前最大fd加1。Linux系统默认分配了3个文件描述符值:0-standard input,1-standard output,2-standard error。 系统调用通常用于底层文件访问(low-level file access),例如在驱动程序中对设备文件的直接访问。
系统调用是操作系统相关的,因此一般没有跨操作系统的可移植性。
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。
这样的话,使用库函数也有系统调用的开销,为什么不直接使用系统调用呢?这是因为,读写文件通常是大量的数据(这种大量是相对于底层驱动的系统调用所实现的数据操作单位而言),这时,使用库函数就可以大大减少系统调用的次数。这一结果又缘于缓冲区技术。在用户空间和内核空间,对文件操作都使用了缓冲区,例如用fwrite写文件,都是先将内容写到用户空间缓冲区,当用户空间缓冲区满或者写操作结束时,才将用户缓冲区的内容写到内核缓冲区,同样的道理,当内核缓冲区满或写结束时才将内核缓冲区内容写到文件对应的硬件媒介。
2、库函数调用
标准C库函数提供的文件操作函数如fopen, fread, fwrite, fclose, fflush, fseek等,需包含头文件stdio.h。以fwrite为例,其函数原型为size_t fwrite(const void *buffer, size_t size, size_t item_num, FILE *pf),其操作对象为文件指针FILE *pf,要想写一个文件,必须先以可写权限用fopen函数打开一个文件,获得所打开文件的FILE结构指针pf,例如
pf=fopen(/"~/proj/filename/", /"w/")。实际上,由于库函数对文件的操作最终是通过系统调用实现的,因此,每打开一个文件所获得的FILE结构指针都有一个内核空间的文件描述符fd与之对应。同样有相应的预定义的FILE指针:stdin-standard input,stdout-standard output,stderr-standard error。 库函数调用通常用于应用程序中对一般文件的访问。
库函数调用是系统无关的,因此可移植性好。
由于库函数调用是基于C库的,因此也就不可能用于内核空间的驱动程序中对设备的操作
ping命令所利用的原理是这样的:网络上的机器都有唯一确定的IP地址,我们给目标IP地址发送一个数据包,对方就要返回一个同样大小的数据包,根据返回的数据包我们可以确定目标主机的存在,可以初步判断目标主机的操作系统等。
补充一个坑爹坑爹坑爹坑爹的问题:系统如何将一个信号通知到进程?(这一题哥没有答出来)
c语言:
宏定义和展开(必须精通)
位操作(必须精通)
指针操作和计算(必须精通)
内存分配(必须精通)
sizeof必考
各类库函数必须非常熟练的实现
哪些库函数属于高危函数,为什么?(strcpy等等)
c++:
一个String类的完整实现必须很快速写出来(注意:赋值构造,operator=是关键)
虚函数的作用和实现原理(必问必考,实现原理必须很熟)
有虚函数的类内部有一个称为“虚表”的指针(有多少个虚函数就有多少个指针),这个就是用来指向这个类虚函数。也就是用它来确定调用该那个函数。
实际上在编译的时候,编译器会自动加入“虚表”。虚表的使用方法是这样的:如果派生类在自己的定义中没有修改基类的虚函数,就指向基类的虚函数;如果派生类改写了基类的虚函数(就是自己重新定义),这时虚表则将原来指向基类的虚函数的地址替换为指向自身虚函数的指针。那些被virtual关键字修饰的成员函数,就是虚函数。虚函数的作用,用专业术语来解释就是实现多态性
(Polymorphism),多态性是将接口与实现进行分离;用形象的语言来解释就是实现以共同的方法,但因个体差异而采用不同的策略。
每个类都有自己的vtbl,vtbl的作用就是保存自己类中虚函数的地址,我们可以把vtbl形象地看成一个数组,这个数组的每个元素存放的就是虚函数的地址, 虚函数的效率低,其原因就是,在调用虚函数之前,还调用了获得虚函数地址的代码。
sizeof一个类求大小(注意成员变量,函数,虚函数,继承等等对大小的影响) 指针和引用的区别(一般都会问到)
相同点:1. 都是地址的概念;
指针指向一块内存,它的内容是所指内存的地址;引用是某块内存的别名。 区别:1. 指针是一个实体,而引用仅是个别名;
2. 引用使用时无需解引用(*),指针需要解引用;
3. 引用只能在定义时被初始化一次,之后不可变;指针可变;
4. 引用没有 const,指针有 const;
5. 引用不能为空,指针可以为空;
6. “sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身(所指向的变量或对象的地址)的大小;
7. 指针和引用的自增(++)运算意义不一样;
8.从内存分配上看:程序为指针变量分配内存区域,而引用不需要分配内存区域。 多重类构造和析构的顺序
先调用基类的构造函数,在调用派生类的构造函数
先构造的后析构,后构造的先析构
stl各容器的实现原理(必考)
STL共有六大组件
1、容器。2、算法。3、迭代器。4、仿函数。6、适配器。
序列式容器:
vector-数组,元素不够时再重新分配内存,拷贝原来数组的元素到新分配的数组中。
list-单链表。
deque-分配中央控制器map(并非map容器),map记录着一系列的固定长度的数组的地址.记住这个map仅仅保存的是数组的地址,真正的数据在数组中存放着.deque先从map中央的位置(因为双向队列,前后都可以插入元素)找到一个数组地址,向该数组中放入数据,数组不够时继续在map中找空闲的数组来存数据。当map也不够时重新分配内存当作新的map,把原来map中的内容copy的新map中。所以使用deque的复杂度要大于vector,尽量使用vector。 stack-基于deque。
queue-基于deque。
heap-完全二叉树,使用最大堆排序,以数组(vector)的形式存放。
priority_queue-基于heap。
slist-双向链表。
关联式容器:
set,map,multiset,multimap-基于红黑树(RB-tree),一种加上了额外平衡条件的二叉搜索树。
hash table-散列表。将待存数据的key经过映射函数变成一个数组(一般是vector)的索引,例如:数据的key%数组的大小=数组的索引(一般文本通过算法也可以转换为数字),然后将数据当作此索引的数组元素。有些数据的key经过算法的转换可能是同一个数组的索引值(碰撞问题,可以用线性探测,二次探测来解决),STL是用开链的方法来解决的,每一个数组的元素维护一个list,他把相同索引值的数据存入一个list,这样当list比较短时执行删除,插入,搜索等算法比较快。
hash_map,hash_set,hash_multiset,hash_multimap-基于hash table。
extern c 是干啥的,(必须将编译器的函数名修饰的机制解答的很透彻) volatile是干啥用的,(必须将cpu的寄存器缓存机制回答的很透彻)
volatile的本意是“易变的” 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用volatile,则编译器将对所声明的语句进行优化。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错) 5.volatile的本质:
1> 编译器的优化
在本次线程内, 当读取一个变量时,为提高存取速度,编译器优化时有时会先把变量读取到一个寄存器中;以后,再取变量值时,就直接从寄存器中取值;当变量值在本线程里改变时,会同时把变量的新值copy到该寄存器中,以便保持一致。
当变量在因别的线程等而改变了值,该寄存器的值不会相应改变,从而造成应用程序读取的值和实际的变量值不一致。
当该寄存器在因别的线程等而改变了值,原变量的值不会改变,从而造成应用程序读取的值和实际的变量值不一致。
2>volatile应该解释为“直接存取原始内存地址”比较合适,“易变的”这种解释简直有点误导人。
static const等等的用法,(能说出越多越好)
数据结构或者算法:
《离散数学》范围内的一切问题皆由可能被深入问到(这个最坑爹,最重要,最体现功底,最能加分,特别是各类树结构的实现和应用)
各类排序:大根堆的实现,快排(如何避免最糟糕的状态?),bitmap的运用等等
hash, 任何一个技术面试官必问(例如为什么一般hashtable的桶数会取一个素数?如何有效避免hash结果值的碰撞)
网络编程:
tcp与udp的区别(必问)
1.基于连接与无连接
2.对系统资源的要求(TCP较多,UDP少)
3.UDP程序结构较简单
4.流模式与数据报模式
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证 TCP---传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP---用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快
udp调用connect有什么作用?
1:UDP中可以使用connect系统调用2:UDP中connect操作与TCP中connect操作有着本质区别.TCP中调用connect会引起三次握手,client与server建立连结.UDP中调用connect内核仅仅把对端ip&port记录下来.3:UDP中可以多次调用connect,TCP只能调用一次connect.UDP多次调用connect有两种用途:1,指定一个新的ip&port连结.2,断开和之前的ip&port的连结.指定新连结,直接设置connect第二个参数即可.断开连结,需要将connect第二个参数中的
sin_family设置成 AF_UNSPEC即可. 4:UDP中使用connect可以提高效率.原因如下:普通的UDP发送两个报文内核做了如下:#1:建立连结#2:发送报文#3:断开连结#4:建立连结#5:发送报文#6:断开连结采用connect方式的UDP发送两个报文内核如下处理:#1:建立连结#2:发送报文#3:发送报文另外一点,每次发送报文内核都由可能要做路由查询.5:采用connect的UDP发送接受报文可以调用send,write和recv,read操作.当然也可以调用sendto,recvfrom.调用sendto的时候第五个参数必须是NULL,第六个参数是0.调用recvfrom,recv,read系统调用只能获取到先前connect的ip&port发送的报文.
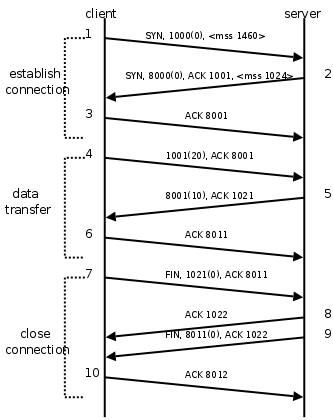
UDP中使用connect的好处:1:会提升效率.前面已经描述了.2:高并发服务中会增加系统稳定性.原因:假设client A 通过非connect的UDP与server B,C通信.B,C提供相同服务.为了负载均衡,我们让A与B,C交替通信.A 与 B通信IPa:PORTa <----> IPb:PORTbA 与 C通信IPa:PORTa' <---->IPc:PORTc 假设PORTa 与 PORTa'相同了(在大并发情况下会发生这种情况),那么就有可能出现A等待B的报文,却收到了C的报文.导致收报错误.解决方法内就是采用connect的UDP通信方式.在A中创建两个udp,然后分别connect到B,C. tcp连接中时序图,状态图,必须非常非常熟练
socket服务端的实现,select和epoll的区别(必问) select的本质是采用32个整数的32位,即32*32= 1024来标识,fd值为1-1024。当fd的值超过1024限制时,就必须修改FD_SETSIZE的大小。这个时候就可以标识32*max值范围的fd。
对于单进程多线程,每个线程处理多个fd的情况,select是不适合的。
1.所有的线程均是从1-32*max进行扫描,每个线程处理的均是一段fd值,这样做有点浪费
2.1024上限问题,一个处理多个用户的进程,fd值远远大于1024
所以这个时候应该采用poll,
poll传递的是数组头指针和该数组的长度,只要数组的长度不是很长,性能还是很不错的,因为poll一次在内核中申请4K(一个页的大小来存放fd),尽量控制在4K以内
epoll还是poll的一种优化,返回后不需要对所有的fd进行遍历,在内核中维持了fd的列表。select和poll是将这个内核列表维持在用户态,然后传递到内核中。但是只有在2.6的内核才支持。
epoll更适合于处理大量的fd ,且活跃fd不是很多的情况,毕竟fd较多还是一个串行的操作
epoll哪些触发模式,有啥区别?(必须非常详尽的解释水平触发和边缘触发的区别,以及边缘触发在编程中要做哪些更多的确认) epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
大规模连接上来,并发模型怎么设计
tcp结束连接怎么握手,time_wait状态是什么,为什么会有time_wait状态?哪一方会有time_wait状态,如何避免time_wait状态占用资源(必须回答的详细)
tcp头多少字节?哪些字段?(必问)
头20字节,选项12字节
什么是滑动窗口(必问)
动窗口(Sliding window )是一种流量控制技术。滑动窗口协议是用来改善吞吐量的一种技术,即容许发送方在接收任何应答之前传送附加的包。接收方告诉发送方在某一时刻能送多少包(称窗口尺寸)。TCP中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为0时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个1字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。滑动窗口协议的基本原理就是在任意时刻,发送方都维持了一个连续的允许发送的帧的序号,称为发送窗口;同时,接收方也维持了一个连续的允许接收的帧的序号,称为接收窗口。发送窗口和接收窗口的序号的上下界不一定要一样,甚至大小也可以不同。不同的滑动窗口协议窗口大小一般不同。发
送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧。
connect会阻塞,怎么解决?(必考必问)
最通常的方法最有效的是加定时器;也可以采用非阻塞模式。
设置非阻塞,返回之后用select检测状态)
如果select返回可读,结果只读到0字节,什么情况?
某个套接字集合中没有准备好,可能会select内存用FD_CLR清该位为0; keepalive 是什么东东?如何使用?
设置Keepalive参数,检测已中断的客户连接
Determine how long to wait before probing the connection. On most platforms the default is 2 hours.
? Determine how long to wait before retrying the probe.
? Determine how many times to probe the connection. ?
列举你所知道的tcp选项,并说明其作用。
1.窗口扩大因子TCP Window Scale Option (WSopt)
TCP窗口缩放选项是用来增加TCP接收窗口的大小而超过65536字节。
2.SACK选择确认选项
最大报文段长度(M S S)表示T C P传往另一端的最大块数据的长度。当建立一个连接时,每一方都有用于通告它期望接收的 M S S选项(M S S选项只能出现在S Y N报文段中)。通过MSS,应用数据被分割成TCP认为最适合发送的数据块,由TCP传递给IP的信息单位称为报文段或段(segment)。
TCP通信时,如果发送序列中间某个数据包丢失,TCP会通过重传最后确认的包开始的后续包,这样原先已经正确传输的包也可能重复发送,急剧降低了TCP性能。为改善这种情况,发展出SACK(Selective Acknowledgment, 选择性确认)技术,使TCP只重新发送丢失的包,不用发送后续所有的包,而且提供相应机制使接收方能告诉发送方哪些数据丢失,哪些数据重发了,哪些数 据已经提前收到等。
3.MSS: Maxitum Segment Size 最大分段大小
socket什么情况下可读?
a. The number of bytes of data in the socket receive buffer is greater than or equal to the current size of the low-water mark for the socket receive buffer.
A read operation on the socket will not block and will return a value greater than 0
b. The read half of the connections is closed (i.e., A TCP connection that has received a FIN).
A read operation on the socket will not block and will return 0 (i.e., EOF) c. The socket is a listening socket and the number of completed connection is nonzero.
An accept on the listening socket will normally not block, although we will describe a
d. A socket error is pending. A read operation on the socket will not block and will return
an error (-1) with errno set to the specific error condition
db:
mysql,会考sql语言,服务器数据库大规模数据怎么设计,db各种性能指标 最后:补充一个最最重要,最最坑爹,最最有难度的一个题目:一个每秒百万级访问量的互联网服务器,每个访问都有数据计算和I/O操作,如果让你设计,你怎么设计?