信息论报告
摘要:信息论是一门用概率论与数理统计方法来研究信息的度量、传递和交换规律的科学。它主要是研究通讯和控制系统中普遍存在着信息传递的共同规律以及研究最佳解决信息的获限、度量、变换、存储和传递等问题的基础理论。自香农在1948年发表奠定信息论基础的《通信的数学理论》一文以来,信息论学科迅速发展并延伸到许多领域中。信息理论不仅在通信、计算机、控制等领域中有直接指导意义,还渗透到经济学、生物学、医学等广泛领域。本文简要介绍信息论的基本原理和发展史,重点介绍信息论在数据压缩、密码学、信号处理及量子理论中的应用。
关键词:信息、信息论、密码学、数据压缩、量子理论、熵
1. 信息论原理
1.1信息论中的信息
信息是信息论中最重要最基本的概念。早期,人们对信息的理解是很肤浅的。最早把信息作为科学对象来加以研究的是通信领域,而这一领域的奠基之作当推哈特莱于1928年在《贝尔系统电话杂志》上发表的题为《信息传输》的论文。他把信息理解为选择通信符号的方式,并用选择的自由度来计量这种信息的大小。1948年,通信专家香农在《贝尔系统电话杂志》上发表了一篇名为《通信的数学理论》的论文,在文中他以概率论为工具,阐明了通信中的一系列基本理论问题,给出了计算信源信息量和信道容量的方法和一般公式,得到了一组表示信息传递重要关系的编码定理。香农在定量测度信息时,把信息定义为随机不确定性的减少,亦即信息是用来减少随机不确定性的东西。基于这一思想,布里渊直接指出,信息就是负熵[1]。而控制论的奠基人维纳则把信息看做广义通信的内容,他指出:“正如熵是无组织(无序)程度的度量一样,消息集合所包含的信息就是组织(有序)程度的度量。事实上完全可以将消息所包含的信息解释为负熵”[2]。
1.2信息论基础
(1)香农在论文《A Mathematical Theory of Communication》中给出了信息熵的定义:
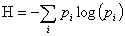 (1-2-1)
(1-2-1)
这一定义可以用来推算传递经二进制编码后的原信息所需的信道带宽。熵度量的是消息中所含的信息量,其中去除了由消息的固有结构决定的部分,比如语言结构的冗余性以及语言中字母、词的使用频度等统计特性。信息论中熵的概念与物理学中的热力学熵有着紧密的联系。波尔兹曼与吉布斯在统计物理学中对熵做了很多工作,信息论中的熵正是受此启发。但是热熵只能增加不能减少;而在通信中,信息熵只会减少不会增加。
(2)联合熵:
 (1-2-2)
(1-2-2)
联合熵 表示信源
表示信源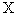 与信宿
与信宿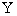 之间任意一对消息的共熵,即描述信源和信宿之间消息序列的平均不确定性。
之间任意一对消息的共熵,即描述信源和信宿之间消息序列的平均不确定性。
(3)互信息:它是另一有用的信息度量,指两个事件集合之间的相关性。两个事件和的互信息定义为:
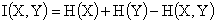 (1-2-3)
(1-2-3)
Shannon信息论的精髓在于将通信的内容抽象为信息,赋予信息以数学的形式,将通信过程中的信息加工变为严格的数学运算。如果一个信源的实际信息熵小于其占用的编码空间,那么就可以对信源参数做一种编码压缩的数学变换,使新编码所占用的空间可以压缩到接近甚至等于原始信息的信源熵。这样,就可以用较少的信道容量完成通信而不丢失信息。如信道中有干扰,则增加相应的监督码量来纠错而保证信息的无损传输。最后在接收端还要做一种译码的数学反变换以完整地恢复原信号。这就是Shannon的信源编码和信道编码的基本数学原理[3,4]。
2. 信息论的发展
信息论是在长期的通信工程实践和理论研究的基础上发展起来的。莫尔斯在1832-1835年间建立起了电报系统。1876年,贝尔发明了电话系统。接着在1895年英国的马可尼和俄国的波波夫就发明了无线通信。随着工程技术的发展,有关理论问题的研究也逐步深入。1832年莫尔斯电报系统中高效率的编码方法对后来香农的编码理论是有启发的。1885年L.Kclvin曾经研究过一条电缆的极限传信问题。1922年J.R.Carson对调幅信号的频谱结果进行了研究,并建立了信号频谱的概念。1924年奈圭斯特的论文《若干影响电报速度的因素》中已经包含了在可传输通信系统中量化“信息”和“线速度”的概念,并给出一个式子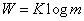 ,其中,W是情报的传输速度,m是每个时间可以选择发送不同的电压电平的数目,而K是一个常数。他指出:如果以一个确定的速度来传输电报信号,就需要一定的带宽,他把信息率与带宽联系起来。1928年哈莱特发展了奈圭斯特的工作并提出把消息考虑为代码或单语的序列。
,其中,W是情报的传输速度,m是每个时间可以选择发送不同的电压电平的数目,而K是一个常数。他指出:如果以一个确定的速度来传输电报信号,就需要一定的带宽,他把信息率与带宽联系起来。1928年哈莱特发展了奈圭斯特的工作并提出把消息考虑为代码或单语的序列。
信息论的创始人香农认为:“通信的基本问题就是精确地或近似地在一点复现另一点选择的信号" ,通信就是将信息由发信者传给受信者。他提出了通信系统的随机模型,把许多复杂的通信机构简化为由信源、编码、信道、噪声、译码及信宿组成的一个信息系统。香农的这一通信模型,不仅适用于技术系统,而且可以推广到生命和社会系统,具有普遍意义。
香农还把信息定量化,使通信科学由定性阶段进入定量阶段。他把信息看作是用以消除不确定的东西。信息数量的大小可以用被消除的不确定性多少来表示,而事物不确定性的多少用概率来描写。香农对通信的技术问题也作了全面的研究,解决了如何从信息接收端提取由信息源发来的消息的技术性问题。他还提出如何充分利用信道的信息容量问题,找到了如何在有限信道中以最大速率传送信息的基本途径,初步解决了怎样编码、译码才能使信源信息充分表达、信道被充分利用的问题。
香农的研究工作具有开创性的意义。信息论产生以后,一方面应用于多种学科和技术领域,另一方面不断完善本身的理论体系。
3. 信息论的应用
信息论是应用近代数理统计方法研究信息的传输、存储与处理的科学,其基本任务是为设计有效而可靠的通信系统提供理论依据,主要特点是理论的成功应用。下面将主要介绍信息论在数据压缩、密码学、量子理论和信号处理中的应用。
3.1信息论在数据压缩理论中的应用
香农在1948年发表的论文《通信的数学理论》一文中指出,任何信息都有冗余,冗余大小和信息中每个符号的出现概率有关[5]。香农把信息中排除了冗余后的平均信息量称为信息熵,并给出了计算信息熵的数学表达式,这为数据压缩奠定了基础。
数据压缩作为信息论研究中的一项内容,主要目的是力求用最少的数据表示信源发出的信号,使信号占用的存储空间尽可能小,以达到提高信号传输速度的目的。它主要是有关数据压缩比和各种编码方法的研究,即按某种方法对源数据流进行编码,使得经过编码的数据流比源数据流占有较少的空间。其中基于符号频率统计的哈夫曼编码效率高,运算速度快,实现方式灵活,使得其在数据压缩领域的到了广泛的应用。不过哈夫曼所得编码长度只是对信息熵计算结果的一种近似,还无法真正逼近信息熵的极限。所以尽管哈夫曼编码具有良好的压缩性能,也一直占据重要的地位,还是不断有基于哈夫曼编码的改进算法提出。
数据压缩技术的不断完善是依靠在信息论这门学科的成长上的,信息能否被压缩以及能在多大程度被压缩与信息的不确定性有直接关系,人工智能技术将会对数据压缩的未来产生重大影响。
3.2信息论在密码学中的应用
密码学是研究编制密码和破译密码的技术科学。从传统意义上说,密码学是研究如何把信息转换为一种隐蔽的方式并阻止他人得到它。密码术的研究和应用虽有很长的历史,但在信息论诞生以前,它还没有系统的理论,直到香农发表的保密通信的信息理论一文,为密码学确立了一系列的基本原则和指标,如加密运算中的完全性、剩余度等指标,它们与信息的度量有着密切相关。之后才产生了基于信息论的密码学理论,所以说信息论与密码学的关系十分密切。
近代密码学由于数据加密标准与公钥体制的出现与应用,使近代密码学所涉及的范围有了很大的发展,尤其是在网络认证方面得到广泛应用,但其中的安全性原理与测量标准仍未脱离香农保密系统所规定的要求,多种加密函数的构造,如相关免疫函数的构造仍以香农的完善保密性为基础。
3.3信息论在信号处理中的应用
信息处理包括影像、数据、语声或者其他信号的处理,从信息论的观点来看,信号则是观察客观事物表达其相应信息的技术手段,也就是特定信息的载体[6]。信息是通过信号来表达的,对信息的加工和处理,也就是对信号的加工和处理。所有处理过程无非是信源编码,变换,过滤或决策过程,其实变换也是一种编码过程。这些过程中的大部分的信息论基础是信息率失真理论。
譬如数字信号处理,其技术可以归结为以快速傅里叶变换和数字滤波器为核心,以逻辑电路为基础,以大规模集成电路为手段,利用软硬件来实现各种模拟信号的数字处理,其中要用到信息论中的信号检测、信号变换、信号调制和解调、信号的运算、信号的传输和交换等。
3.4量子理论
量子纠缠是量子系统内存在的一种特有的现象,它是各个子系统关联的属性,即对一个子系统的测量结果决定了其他子系统的状态。纠缠是量子力学独有的现象,具有纠缠性的量子比特称为纠缠比特,纠缠态是一种特殊的相干叠加态。
1935年,Einstein、Podolsky和Rosen一起在Physical Review上发表文章提出了著名的“EPR佯谬”。在发表的论文中,Einstein等给出了一个两粒子系统的纠缠态:
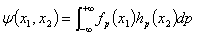 (3-4-1)
(3-4-1)
其中,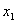 和
和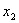 表示粒子1和2的坐标变量,
表示粒子1和2的坐标变量,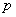 为系统的动量,而
为系统的动量,而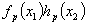 则表示粒子之间形成了纠缠态。研究表明,力学具有完备性。
则表示粒子之间形成了纠缠态。研究表明,力学具有完备性。
在一般情况下,量子力学不允许我们读出任意精度的一个量子系统状态。贝尔量子系统之间的纠缠态存在,不能被转换成经典的信息。这是唯一可能改变量子信息与量子系统的足够信息的能力。因为这个原因,消息 所含的信息,可以用贮存这个消息所需的最小二级系统的数量n来度量:包含了n个量子比特。在其原始的理论意义上的,术语量子比特是信息量的量度。两能级量子系统可以实现最多一个量子比特,在同样的意义上,一个经典的二进制数字可以携带至多有一个经典比特。
所含的信息,可以用贮存这个消息所需的最小二级系统的数量n来度量:包含了n个量子比特。在其原始的理论意义上的,术语量子比特是信息量的量度。两能级量子系统可以实现最多一个量子比特,在同样的意义上,一个经典的二进制数字可以携带至多有一个经典比特。
在量子信息系统中,常用量子位或量子比特(qubit)表示信息单元。量子计算机是用二态的量子力学系统来描述两位信息的,比如,光子的两个偏振方向,磁场中电子自旋或者核自旋向上和向下的两个方向,原子中电子的两个能级态等。量子计算机进行量子计算的过程就是这些量子力学系统的量子态的演化过程。
噪声信道编码定理指出,噪声限制了一个模拟信息载体所携带的信息内容是有限的,而在噪声下保护这些有限信息是很困难的。传统的模拟信息的例子表明,量子信息处理方案必然是对噪声有容限的,否则将没有实际使用价值。量子纠错编码和容错量子计算方式被发现时,这将会是一个巨大突破。
4. 总结
信息论方法的建立,不仅对自然科学有重要的意义,而且对社会科学的研究和发展也同样具有深远的意义。但是香农信息论虽然为目前的通信系统设计和编码都有不可忽视的指导意义,却也有不足的地方,一个局限是香农得出的大部分结果,都是在理论上得到的极限值,虽然为通信系统的设计给出了非常有指导意思的理论界限,但实际系统中应该如何去达到这些界限,香农并没有给出。但是我相信随着理论与技术的成熟,随着更多的专家与学者加入该领域的研究,信息论领域一定会得到突飞猛进的发展,并且对未来科学技术以及人类的发展与进步起到巨大的推动作用。
参考文献
[1].BRILLOUN L.Science and information theory [M]. New York Academic Press Inc. 1956.
[2].马费成等. 信息管理学基础 [M]. 武汉: 武汉大学出版社, 2000.
[3].Shannon C E.A mathematical theory of communication [J]. The Bell System Technical Journal, 1948, 27: 379-423, 623-656.
[4].Wiener N.Cybernetics [M]. 2nd ed. Cambridge: MIT Press, 1961.
[5].周叶林.科学研究中的信息论及其应用 [J]. 今日南国, 2009, 5: 201-202.
[6].周萌清.信息理论基础 [M]. 北京: 北京航空航天大学出版社: 2006.
第二篇:信息论与编码课程设计报告
信息论与编码课程设计报告
Huffman编码与译码
姓名:
学院:
班级:
学号:
指导老师:
2010 年 12 月
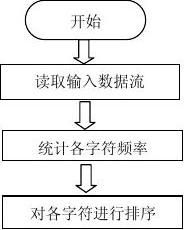
一、课程设计目的
掌握通过计算机编程实现Huffman编码
二、基本原理
Huffman编码又称哈夫曼编码,是一种可变长编码方式,是由美国数学家David Huffman创立的,是二叉树的一种特殊转化形式。编码的原理是:将使用次数多的代码转换成长度较短的代码,而使用次数少的可以使用较长的编码,并且保持编码的唯一可解性。Huffman算法的最根本的原则是:累计的(字符的统计数字*字符的编码长度)为最小,也就是权值(字符的统计数字*字符的编码长度)的和最小。
Huffman编码的步骤:
1) 把信源符号按概率大小顺序排列,并设法按逆次序分配码字的长度。
2) 在分配码字长度时,首先将出现概率最小的两个符号的概率相加合成一个概率。
3) 把这个合成概率看成是一个新组合符号地概率,重复上述做法直到最后只剩下两个符号概率为止。
11) 完成以上概率顺序排列后,再反过来逐步向前进行编码,每一次有二个分支各赋予一个二进制码,可以对概率大的赋为0,概率小的赋为1。
Huffman编码分析:
从以上编码步骤可以看出,Huffman码是用概率匹配的方法进行信源匹配方法进行信源。它有两个明显的特点:一是Huffman码的编码方法保证了概率大的符号对应于短码,概率小的符号对应于长码,充分应用了短码;二是缩减信源的最后二个码字总是最后一位不同,从而保证了Huffman编码是及时码。
Huffman变长码的效率是相当高的,它可以单个信源符号编码或用长度较小的信源序列编码,对编码的设计来说也将简单得多。
本次实验将采用C语言对Huffman编码的实现进行编程,主要实现的功能是对字符串编码(实现压缩的功能),而后进行相反译码过程(即解压的功能)。其中将使用数据结构中的Huffman树的知识,最后将基本功能进行扩展,从而实现对一个txt文档的压缩和解压功能。
本次实验中的编码过程的基本流程图如下所示:

三、方案实践与调试
本程序主要分为以下4部分:
1. 构造Huffman树
给定n个实数w1,w2,......,wn(n≥2),求一个具有n个结点的二叉数,使其带权路径长度最小。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的带权路径长度记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明Huffman树的WPL是最小的。
(1) 根据与n个权值{w1,w2…wn}对应的n个结点构成具有n棵二叉树的森林F={T1,T2…Tn},其中第i棵二叉树Ti(1 ≤ i ≤ n)都只有一个权值为wi的根结点,其左、右子树均为空
(2) 在森林F中选出两棵根结点的权值最小的树作为一棵新树的左、右子树,且置新树的根结点的权值为其左、右子树上根结点权值之和
(3) 从F中删除构成新树的那两棵,同时把新树加入F中
(4) 重复第(2)和第(3)步,直到F中只含有一棵为止,此树便为Huffman树
2. Huffman编码算法
根据最优二叉树构造Huffman编码,利用Huffman树很容易求出给定字符集及其概率(或频度)分布的最优前缀码。Huffman编码正是一种应用广泛且非常有效的数据压缩技术。该技术一般可将数据文件压缩掉20%至90%,其压缩效率取决于被压缩文件的特征。
(1)用字符s[i]作为叶子,count[i]做为叶子s[i]的权,构造一棵Huffman树,并将树中左分支和右分支分别标记为0和1;
(2)将从根到叶子的路径上的标号依次相连,作为该叶子所表示字符的编码。该编码即为最优前缀码(也称Huffman编码)。
3. Huffman译码算法
依次读人文件的二进制码,从Huffman树的根结点(即T[m-1])出发,若当前读人0,则走向左孩子,否则走向右孩子。一旦到达某一叶子T时便译出相应的字符H.ch。然后重新从根出发继续译码,直至文件结束。
4. 二进制转换算法
将Huffman编码存储为二进制文件以及将生成的二进制文件转换为Huffman编码以实现压缩的过程。
程序中主要定义了两个结构体:
1. 定义赫夫曼树节点结构体
typedef struct node {
int weight;
struct node *LChild,*RChild,*Parent; //分别指向该节点的左孩子,右孩子,和双亲节点 struct node *next;
}HFMNode,*HFMTree;
2. 定义赫夫曼编码的结构体
typedef struct {
char ch; //存储对应的字符 char code[N+1]; //存储对应字符的编码 int start; //存储编码的起始位置 //指向建立的赫夫曼树的下一个节点
}CodeNode;
详细设计
1.构造霍夫曼树
主要代码如下:
void CreatHFMTree(HFMTree *HT,int count[]){ //创建赫夫曼树
int i;
HFMTree p,HT1,HT2; //HT1,HT2分别存放权值最小和次小的节点的位置
p=*HT=(HFMTree)malloc(sizeof(HFMNode));
p->next=p->LChild=p->RChild=p->Parent=NULL; //初始化赫夫曼链表且有2n-1个节
点
for(i=1;i<2*n-1;i++)
{ p->next=(HFMTree)malloc(sizeof(HFMNode));
p=p->next;
p->next=p->LChild=p->RChild=p->Parent=NULL;
}
for(i=0,p=*HT;i<n;i++){ //将各个字符出现的次数作为权值 p->weight=count[i];
p=p->next;
}
for(i=n;i<2*n-1;i++){ //将后n-1个节点赋权值,建树
SelectMin(*HT,i,&HT1,&HT2); //每次从前i个节点中选取权值最小的两个节点
HT1->Parent=HT2->Parent=p;
p->LChild=HT1;
p->RChild=HT2;
p->weight=HT1->weight+HT2->weight;//将两个节点的权值相加存入一个节点
p=p->next; //p指向下一个没有存储权值的节点
}
}
2.霍夫曼编码算法
主要代码如下:
void TotalCoding(char s[],CodeNode HC[],char code[]){
//利用赫夫曼编码表对整个字符串进行编码
int i,j;code[0]='\0'; //编码数组初始化
for(i=0;s[i];i++)
for(j=0;j<n;j++)
if(s[i]==HC[j].ch)
strcpy(code+strlen(code),HC[j].code+HC[j].start);
}
给定字符集的赫夫曼树生成后,求赫夫曼编码的具体实现过程是:依次以叶子s[i](0≤i≤n-1)为出发点,向上回溯至根为止。上溯时走左分支则生成代码0,走右分支则生成代码1。
(1)由于生成的编码与要求的编码反序,将生成的代码先从后往前依次存放在一个临时向量中,并设一个指针start指示编码在该向量中的起始位置.
(2)当某字符编码完成时,从临时向量的start处将编码复制到该字符相应的位串中即可。
(3)因为字符集大小为n,故变长编码的长度不会超过n,加上一个结束符'\0' .
3.霍夫曼译码算法
主要代码如下:
void DeCoding(char code[],HFMTree HT,char str[],char s[]){
//对赫夫曼编码进行解码,放入字符串s中
int i,j,k=0;
HFMTree root,p,q;
for(root=HT;root->Parent;root=root->Parent); //用root指向赫夫曼树的根结点
for(i=0,p=root;code[i];i++){ //从根结点开始按编码顺序访问树
if(code[i]=='0')
p=p->LChild;
else p=p->RChild;
if(p->LChild==NULL&&p->RChild==NULL){
//到根节点时将该节点对应的字符输出
for(j=0,q=HT;q!=p;q=q->next,j++);
s[k++]=str[j];
p=root; //回溯到根结点
}
}
s[k]='\0'; //解码完毕,在字符串最后一个单元存入'\0' }
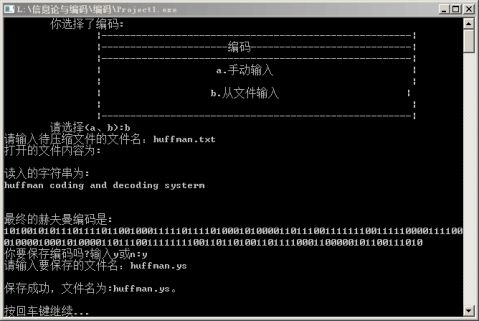
编码界面
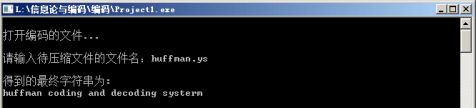
解码界面
四、总结体会
在这次课程设计中,通过对程序的编写,调试和运行,使我更好的掌握了Huffman树等数据结构方面的基本知识和各类基本程序问题的解决方法,熟悉了各种调用的数据类型,在调试和运行过程中,加深我对程序运行的环境了解和熟悉的程度,同时也提高了我对程序调试分析的能力和对错误纠正的能力。
这次信息论与编码的程序设计,对于我来说是一个挑战。我对数据结构的学习在程序的设计中也有所体现。课程设计是培养学生综合运用所学知识,发现问题、提出问题、分析问题和解决问题的过程,锻炼学生的逻辑思维能力和实践能力,是对学生实际工作能力的具体训练和考察过程。在整个课程程序中,我们充分应用和调用各个程序模块,从而部分实现了此次程序设计的所应该有的功能。就是我在课程设计是比较成功的方面,而在这个过程中,让我感觉收获最大的就是我们都能利用这次课程设计学到很多我们在课本上没有的知识,充分的发挥了我们的主动性,使我们学会了自主学习,和独立解决问题的能力。
很多程序在结构上是独立的,但是本此设计的程序功能不是零散的,它有一个连接是的程序是一个整体,达到这种统一体十分重要,因为这个输出连接是贯穿始终的。
这次的程序软件基本上运行成功,可以简单的输入进行压缩,并且运用简单的数字告诉程序的操作者下一步该如何进行,使得程序规模相对较小,即功能还不很全面,应用也不很普遍。原来数据结构可以涉及很多知识,而不是枯燥无聊的简单的代码部分而已,利用数据结构方面的知识,我们可以设计出更完善的软件。
总而言之,这次数据结构课程设计让我们感触很深,使我们每个人都了解到学习不应该只局限于课本,因为课本上告诉我们的只是很有限的一部分,只是理论上的死知识,所涉及的范围也是狭窄的。我们若想在有限的范围内学习到无限的知识,就要我们自己懂得争取,懂得自学,懂得充分利用身边的任何资源。
在我们的程序中有一部分查找许多该方面的资料,我竭力将所获得的信息变成自己的资源。我动手上机操作的同时,在了解和看懂的基础上对新学的知识进行改进和创新,但是在我们的程序软件中还有很多的不足,需要加以更新。通过这次课程设计,我们都意识到了自己动手实践的弱势,特别是在编程方面,于是我们知道了计算机的实践操作是很重要的,只有通过上机编程才能充分的了解自己的不足。
通过这次的课程设计,我们深刻意识到自己在学习中的弱点,同时也找到了克服这些弱点的方法,这是在此活动中得到的一笔很大的财富。在以后的时间中,我们应该利用更多的时间去上机实验,多编写程序,相信不久后我们的编程能力都会有很大的提高,能设计出更多的更有创新的软件。同时也感谢老师给我们这次机会,发现自身存在的缺点与不足,从而在以后的大学生活中更好的提升和完善自我。
参考书目:
[2] 严蔚敏, 吴伟民. 《数据结构》. 清华大学出版社, 2007.4
附录 源代码
#include <iostream.h> #include <stdio.h> #include <stdlib.h> #include <string.h>
#define M 10000 //定义字符串最大长度
#define N 128 义叶子节点个数
typedef struct node 义赫夫曼树节点结构体
{ int weight; struct node *LChild,*RChild,*Parent; 分别指向该节点的左孩子,右孩子,和双亲节点
struct node *next; //指向建立的赫夫曼树的下一个节点
}HNode,*HTree;
typedef struct 义赫夫曼编码的结构体
{ char ch; //存储对应的字符
char code[N+1]; //存储对应字符的编码
int start; //存储编码的起始位置
}CodeNode;
int n; 储真正叶子节点个数
void Open(char s[]){ 开存放字符或编码的文件,将其存入字符串数组中
char name[10]; FILE *fp; int i=0,j; printf("请输入待压缩文件的文件名:");getchar();
scanf("%s",name); //要打开的文件名
//定
//定
//
//定
//存
//打
if((fp=fopen(name,"rt"))==NULL){
printf("打开失败!\n");
//若打开失败,则直接退出
exit(1);
}
s[i++]=fgetc(fp);
while(s[i-1]!=EOF)
s[i++]=fgetc(fp);
s[i]='\0';
//存取字符串结束
fclose(fp);
}
void Save(char s[]){
存字符或编码到文件中
char name[10];
FILE *fp;
printf("请输入要保存的文件名:");
gets(name);
if((fp=fopen(name,"wt"))==NULL)
{
printf("存储失败!");
exit(1);
}
fputs(s,fp);
printf("\n保存成功,文件名为:%s。\n",name);
printf("\n按回车键继续...");
getchar();
fclose(fp);
}
void SearchStr(char s[],char str[],int count[]) {
中字符的个数和每个字符出现的次数
int i,j,k=0;
for(i=0;i<N;i++)
//初始化每个字符出现的次数
count[i]=0;
for(i=0;s[i];i++){
for(j=0;j<k;j++)
str[]中查找是否有该字符
if(str[j]==s[i]){
count[j]++;
break;
}
if(j==k){
str[]中无该字符,将其存入最后一个单元
str[k]=s[i];
count[k++]++;
}
}
str[k]='\0';
//将字符串结尾置“\0”
n=k;
//将实际的字符个数作为叶子节点个数存入n
} //保//查找字符串 //在 //在
void SelectMin(HTree HT,int k,HTree *HT1,HTree *HT2){
找赫夫曼链表中两个权值最小的节点
int i,min;
HTree p;
min=32767;
for(i=0,p=HT;i<k;i++,p=p->next)
if(p->weight<min&&p->Parent==0)
{
min=p->weight;
*HT1=p;
}
min=32767;
for(i=0,p=HT;i<k;i++,p=p->next)
if(p->weight<min&&p->Parent==0&&p!=*HT1)
第二个最小的节点不等于第一个节点
{
min=p->weight;
*HT2=p;
}
}
void CreatHFMTree(HTree *HT,int count[])
夫曼树
{
int i;
HTree p,HT1,HT2;
//HT1,HT2分别存放权值最小和次小的节点的位置
p=*HT=(HTree)malloc(sizeof(HNode));
p->next=p->LChild=p->RChild=p->Parent=NULL;
for(i=1;i<2*n-1;i++)
{
p->next=(HTree)malloc(sizeof(HNode));
p=p->next;
p->next=p->LChild=p->RChild=p->Parent=NULL;
各个字符出现的次数作为权值
}
for(i=0,p=*HT;i<n;i++)
{
p->weight=count[i];
p=p->next;
}
for(i=n;i<2*n-1;i++)
//将后n-1个节点赋权值,建树
{
SelectMin(*HT,i,&HT1,&HT2);
次从前i个节点中选取权值最小的两个节点
HT1->Parent=HT2->Parent=p;
p->LChild=HT1;
p->RChild=HT2;
p->weight=HT1->weight+HT2->weight;
//将两个节点的权值相加存入最后一个节点中
p=p->next;
//p指向下一个没有存储权值的节点
}
}
void HFMCode(HTree HT,CodeNode HC[],char str[]){ //查 //令//创建赫 //将 //每 //从
每个叶子节点开始,利用赫夫曼树对每个字符进行编码,最终建立一个赫夫曼表 int i;
HTree q,p=HT;
for(i=0;i<n;i++) //将字符存入赫夫曼编码结构体数组的字符单元中 {
HC[i].ch=str[i];
HC[i].code[n-1]='\0'; 始化编码的最后一位 }
for(i=0;i<n;i++){
HC[i].start=n-1;
for(q=p;q->Parent;q=q->Parent) 断q所指向的节点,左孩子置0,右孩子置1 if(q==q->Parent->LChild) HC[i].code[--HC[i].start]='0'; else HC[i].code[--HC[i].start]='1';
p=p->next; 断下一个叶子节点 }
}
void TotalCoding(char s[],CodeNode HC[],char code[])
夫曼编码表对整个字符串进行编码
{
int i,j;code[0]='\0';
码数组初始化
for(i=0;s[i];i++)
每个字符在赫夫曼编码表中对应的编码存入存放总编码的数组中
for(j=0;j<n;j++) if(s[i]==HC[j].ch)
strcpy(code+strlen(code),HC[j].code+HC[j].start); }
void DeCoding(char code[],HTree HT,char str[],char s[])
曼编码进行解码,放入字符串s中
{ int i,j,k=0; HTree root,p,q; for(root=HT;root->Parent;root=root->Parent);
root指向赫夫曼树的根结点
for(i=0,p=root;code[i];i++){
根结点开始按编码顺序访问树
if(code[i]=='0') p=p->LChild; else p=p->RChild; if(p->LChild==NULL&&p->RChild==NULL){
//到根节点时将该节点对应的字符输出
for(j=0,q=HT;q!=p;q=q->next,j++); s[k++]=str[j]; p=root;
溯到根结点
//初 //判 //判//利用赫
//编
//将
//对赫夫
//用
//从
//回
} }
s[k]='\0'; //解码完毕,在字符串最后一个单元存入'\0'
}
void TransCode(char code[],char str[],char ss[],HTree *HT,CodeNode HC[]) { char str_in; printf("\n打开编码的文件...\n\n"); Open(code);
//打开编码文件
DeCoding(code,*HT,str,ss); //将编码进行解码存入字符串数组ss[]中
printf("\n得到的最终字符串为:\n"); puts(ss); printf("你要保存译码吗?输入y或n:"); scanf("%c",&str_in); if(str_in=='y') Save(ss); //保存译码后的字符串
}
void showtip1(char s[M]) { char chr_in; printf("\t你选择了编码:\n"); cout<<"\t\t|------------------------------------------------------|"<<endl; cout<<"\t\t|----------------------编码----------------------------|"<<endl; cout<<"\t\t|------------------------------------------------------|"<<endl; cout<<"\t\t| a.手动输入 cout<<"\t\t| cout<<"\t\t| b.从文件输入 cout<<"\t\t| cout<<"\t\t|------------------------------------------------------|"<<endl; cout<<"\t请选择(a、b):"; cin>>chr_in; switch(chr_in) { case 'a':printf("请输入并以#号结束:\n"); cin.get(s,M,'#'); break; case 'b':Open(s); printf("打开的文件内容为:\n"); break; default : printf(" 输入错误!\n"); } }
void Coding(char s[],char str[],char code[],int count[],HTree *HT,CodeNode HC[]) { char str_in; showtip1(s); printf("\n读入的字符串为:\n"); puts(s);
|"<<endl; |"<<endl; |"<<endl; |"<<endl;
SearchStr(s,str,count); 找字符串中不同的字符及其出现的次数
CreatHFMTree(HT,count); //用每个字符出现的次数作为叶子节点的权值建立赫夫曼树
HFMCode(*HT,HC,str); //利用赫夫曼树对每个叶子节点进行编码,存入编码表中
TotalCoding(s,HC,code); //利用编码表对字符串进行最终编码
printf("\n最终的赫夫曼编码是:\n"); puts(code); printf("你要保存编码吗?输入y或n:"); cin>>str_in; getchar(); if(str_in=='y') Save(code); getchar(); 存最终的赫夫曼编码
// system("cls"); }
int main(){ //主函数
char choice; do{
char s[M],ss[M]; //定义字符串数组,s[]存放将要编码的字符串,ss[]存解码后的字符串
char str[N]; //存放输入的字符串中n个不同的字符
int count[N]; //存放n个不同字符对应的在原字符串中出现的次数
char code[M]; //存放最终编码完成后的编码
HTree HT; //定义一个赫夫曼树的链表
CodeNode HC[N]; //定义一个赫夫曼编码表的数组,存放每个字符对应的赫夫曼编码
cout<<"\t\t|-------------------------------------------------------|"<<endl; cout<<"\t\t|--------------------赫夫曼编译系统---------------------|"<<endl; cout<<"\t\t|-------------------------------------------------------|"<<endl; cout<<"\t\t| 1.编码 cout<<"\t\t| 2.解码 cout<<"\t\t| 3.说明 cout<<"\t\t| 0.退出 cout<<"\t\t|-------------------------------------------------------|"<<endl; cout<<"\t请选择你要的操作(0-3):"; cin>>choice; system("cls"); switch(choice) { case '1': Coding(s,str,code,count,&HT,HC);break; 串进行编码
//查
//保
|"<<endl; |"<<endl; |"<<endl; |"<<endl; //对字符
} case '2': TransCode(code,str,ss,&HT,HC);break; //对编码进行解码 case '3': printf("该系统最大输入字符为5000个!\n"); printf("译码必须是赫夫曼编译出的密码\n"); case '0': break; default : printf(" 输入错误!请重新输入!\n"); } } while(choice!='0'); return 0;