数据库连接及线程池
曾几何时,记住了一句话:“建立数据库连接是一个代价高昂的过程”,也从那时开始,我在构建系统时,一旦建立起了数据库连接,就保存起来,任何要用数据库的地方,都使用这个数据库连接对象进行操作。
这样的行为,在以前写的单线程程序中,倒也可以接受,但在这次写的多线程程序中,就出现问题了。在这次的程序中,最开始设计时,在工作线程类中,设置了一个SqlConnection的静态成员以接受系统中已经建立起的数据库连接对象。大致的代码如下:

在主程序中,使用下面的代码来启动工作线程

凭借以往的经验,满心期望着:NoPoolThread你给我好好干吧,成功就在眼前。殊不知,异常马上就出现,基本上是说:“已有打开的与此命令相关联的 DataReader,必须首先将它关闭。ExecuteNonQuery 要求已打开且可用的连接。连接的当前状态为已关闭”。
然后把threads数组长度改成1,即又恢复到只有一个线程使用数据库连接对象时,就又恢复正常。
这样就说明了,在多个线程中使用同一个SqlConnection对象进行数据库操作的想法是不现实的也是行不通的。
于是,就大着胆子,冒着“巨大的代价”,进行修改,在任何使用SqlConnection的地方,都临时创建的SqlConnection对象一个对象,但是要创建对象,需要连接字符串啊,怎么来呢,不想重新写一遍,就用现成的、已经传到线程对象里面的哪个数据库连接对象里面的连接字符串吧,于是修改代码如下:
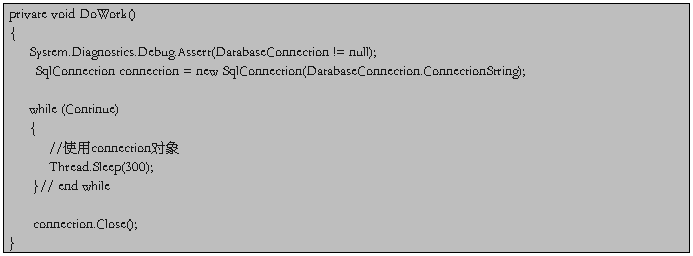
3.2 SqlConnection的连接
这样修改的结果,每个线程使用自己的SqlConnection对象对数据库进行操作,使各个线程之间互不影响。根据测试,程序可以顺畅运行,而且在性能上没有明显损失,这多少有些以为,于是继续查找资料。由于使用的时SqlConnection对象,所以就以它为线索,首先从MSDN开始,MSDN给出的解释有如下内容:

从上面的解释来看,我修改后的代码,无意间启用了数据库连接池——因为除非你在连接字符串里面明确禁用连接池功能,否则默认的数据库连接是从连接池中获得连接的。
3.3 连接池的相关概念
这里,既然提及了连接池,自己在这方面的认识又很模糊,于是就自己给自己了一个学习连接池的机会。
连接池及ADO.NET
连接到数据库服务器通常由几个需要很长时间的步骤组成。必须建立物理通道(例如套接字或命名管道),必须与服务器进行初次握手,必须分析连接字符串信息,必须由服务器对连接进行身份验证,必须运行检查以便在当前事务中登记,等等。——这就是建立数据库连接的代价,但仍然只是定性的描述。
实际上,大多数应用程序仅使用一个或几个不同的连接配置。这意味着在执行应用程序期间,许多相同的连接将反复地打开和关闭。为了使打开的连接成本最低,ADO.NET 使用称为连接池的优化方法。
连接池是一种在打开数据存储区的连接时提高应用程序性能的机制,可以显著提高应用程序的性能和可缩放性。使用连接池减少新连接需要打开的次数。
池进程保持物理连接的所有权。通过为每个给定的连接配置保留一组活动连接来管理连接。只要用户在连接上调用 Open,池进程就会检查池中是否有可用的连接。如果某个池连接可用,会将该连接返回给调用者,而不是打开新连接。应用程序在该连接上调用 Close 时,池进程会将连接返回到活动连接池集中,而不是真正关闭连接。连接返回到池中之后,即可在下一个 Open 调用中重复使用。
只有配置相同的连接可以建立池连接。ADO.NET 同时保留多个池,每个配置一个池。连接由连接字符串以及 Windows 标识(在使用集成的安全性时)分为多个池。
池连接可以大大提高应用程序的性能和可缩放性,考虑一个访问SQL Server数据库的典型ASP.NET或WebServices应用程序。客户端应用程序每次需要查询数据库时,就会在服务器端代码中进行往返,以打开SqlConnection来执行查询。在许多此类应用程序中,这一代码以相同凭据一次又一次地连接到相同数据库。理论上,这意味着客户端应用程序每次需要执行查询时,服务器端代码需要执行三个操作——登录到数据库(需要检查所提供的凭据)、执行查询、然后注销。连接池可以真正地提高此类应用程序的性能——通过将内部连接存储在池中,并在以后进行重复利用,就不再因为登录数据库以及从中注销而降低性能。对SqlConnection对象的Open和Close方法的调用可以短时间内返回,从而可以提高代码的性能和响应速度(请参见3.1图)。
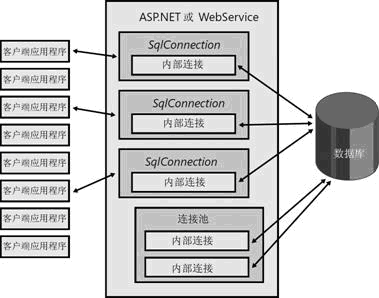
图3.1 典型ASP.NET或WebServices应用程序中的连接池
默认情况下,ADO.NET 中启用连接池。除非显式禁用,否则,连接在应用程序中打开和关闭时,池进程将对连接进行优化。还可以提供几个连接字符串修饰符来控制连接池的行为。有关更多信息,请参见MSDN中的“使用连接字符串关键字控制连接池”。
在调用SqlConnection对象的Close方法时,SQL Client .NET数据提供程序并不实际关闭内部连接。相反,数据提供程序将该内部连接存储到一个池中,以便在以后再次使用。甚至在SqlConnection对象被处理之后,该内部连接也保留在池中。如果在以后使用相同连接字符串和凭据调用SqlConnection对象的Open方法,将会再次使用同一内部连接与数据库进行通信。
因此,微软建议在使用完连接时一定要关闭或断开连接,以便连接可以返回池。要关闭连接,可以使用 Connection 对象的 Close 或 Dispose 方法,也可以通过在 C# 的 using 语句中或在 Visual Basic 的Using 语句中打开所有连接。不是显式关闭的连接可能不会添加或返回到池中。例如,如果连接已超出范围但没有显式关闭,则仅当达到最大池大小而该连接仍然有效时,该连接才会返回到连接池中。不是显式关闭的连接可能无法返回池。例如,如果连接已超出范围但没有显式关闭,则仅当达到最大池大小而该连接仍然有效时,该连接才会返回到连接池中。参见下面的示例。
另外,如果你希望确认是否真正再次利用了同一内部连接,可以使用.NET Reflection中的功能以可编程方式访问私有InnerConnection属性的内容。以下代码(其需要对System.Reflection命名空间的引用)在Using代码块中打开一个SqlConnection,并存储SqlConnection的InnerConnection属性的值。通过利用Using代码块,在该代码块的末尾隐式处理了SqlConnection。此代码在Using代码块中打开另一个SqlConnection,并存储SqlConnection的InnerConnection属性的值。最后,此代码对比InnerConnection属性的内容,确认它们实际上为同一对象。

连接池的创建和清除
在初次打数据库开连接时——例如调用SqlConnection.Open方法时,池进程将根据完全匹配算法创建连接池,该算法将池与连接中的连接字符串关联。每个连接池与不同的连接字符串关联。打开新连接时,如果连接字符串并非与现有池完全匹配,将创建一个新池。按进程、按应用程序域、按连接字符串以及(在使用集成的安全性时)按 Windows 标识来建立池连接。
ADO.NET 2.0 引入了两种新的方法来清除池:ClearAllPools 和 ClearPool。ClearAllPools 清除给定提供程序的连接池,ClearPool 清除与特定连接关联的连接池。如果在调用时连接正在使用,将进行相应的标记。连接关闭时,将被丢弃,而不是返回池中。
连接的添加和移除
连接池是为每个唯一的连接字符串创建的。当创建一个池后,将创建多个连接对象并将其添加到该池中,以满足最小池大小的要求。连接根据需要添加到池中,但是不能超过指定的最大池大小(默认值为 100)。连接在关闭或断开时释放回池中。
在请求 SqlConnection 对象时,如果存在可用的连接,将从池中获取该对象。连接要可用,必须未使用,具有匹配的事务上下文或未与任何事务上下文关联,并且具有与服务器的有效链接。
连接池进程通过在连接释放回池中时重新分配连接,来满足这些连接请求。如果已达到最大池大小且不存在可用的连接,则该请求将会排队。然后,池进程尝试重新建立任何连接,直到到达超时时间(默认值为 15 秒)。如果池进程在连接超时之前无法满足请求,将引发异常。
连接池进程定期扫描连接池,查找没有通过 Close 或 Dispose 关闭的未用连接,并重新建立找到的连接。如果应用程序没有显式关闭或断开其连接,连接池进程可能需要很长时间才能重新建立连接,所以,最好确保在连接中显式调用 Close 和 Dispose。
如果连接长时间空闲,或池进程检测到与服务器的连接已断开,连接池进程会将该连接从池中移除。注意,只有在尝试与服务器进行通信之后才能检测到断开的连接。如果发现某连接不再连接到服务器,则会将其标记为无效。无效连接只有在关闭或重新建立后,才会从连接池中移除。
如果存在与已消失的服务器的连接,那么即使连接池管理程序未检测到已断开的连接并将其标记为无效,仍有可能将此连接从池中取出。这种情况是因为检查连接是否仍有效的系统开销将造成与服务器的另一次往返,从而抵消了池进程的优势。发生此情况时,初次尝试使用该连接将检测连接是否曾断开,并引发异常。
上述连接的添加和移除,全都是由后台运行的池进程管理的。
禁用连接池
您可能不希望使用连接池。例如,如果正在使用一个直接与数据库进行通信的简单Windows应用程序,那么可能希望禁用连接池。在采用这一架构时,各个客户端应用程序需要自己的连接。在启用连接池时,每个应用程序的连接被放入池中,如果在清除连接池之前重新打开该连接,将重复利用放入池中的连接。所以,如果应用程序频繁重复使用连接,那么在启用连接池的情况下,对SqlConnection.Open的调用将会更快速地返回。但是,这种方法将会导致在任意给定时刻存在许多活动的数据库连接。禁用连接池将会降低任意时刻的活动数据库连接数目,但这样会强制所有对SqlConnection.Open的调用都建立一个新的数据库连接。
如果希望禁用连接池,可以通过向连接字符串中添加Pooling=False,逐个连接地禁用连接池。幸运的是,在ADO.NET 2.0中不再需要记忆诸如此类的属性。如果存在疑问,可以检查SqlConnectionStringBuilder类的选项。在这个类中可以找到一个Pooling属性,其取值为Boolean类型。默认情况下,此值被设置为True。将该值设置为False将会禁止将该连接放入池中。因此,在调用SqlConnection对象的Close方法时,将会关闭与数据库的实际连接。
注意 在“偶尔进行连接”的Windows应用程序中,使用连接池可能很有帮助,具体取决于应用程序。如果应用程序希望定期重新连接到数据库,则可以发挥连接池的作用,将与数据库的物理连接保持打开状态,至少暂时如此。如果在从池中删除该物理连接之前,应用程序尝试重新连接到该数据库,则连接池逻辑(pooling logic)将会重新使用与该数据库的物理连接。
查看数据库连接
在使用了数据库连接池的情况下,那么建立到数据库上的连接到底怎么样呢,这可以使用Windows的性能查看器来看。在运行SqlServer的服务器上,使用【管理工具】→【性能】就可以调出性能查看器,然后添加计数器:1、在性能对象下拉框中选择:SQLServer:General Statistics,然后选择User Connections计数器,这样就可以看到连接到SQL Server上的数据库连接数了。
为此,做了一个测试函数,该函数不断的建立数据库连接,读取userinfo表的总函数,然后返回,代码如下。

第二篇:线程池原理及创建
线程池原理及创建(C++实现)
本文给出了一个通用的线程池框架,该框架将与线程执行相关的任务进行了高层次的抽象,使之与具体的执行任务无关。另外该线程池具有动态伸缩性,它能根据执行
任务的轻重自动调整线程池中线程的数量。文章的最后,我们给出一个简单示例程序,通过该示例程序,我们会发现,通过该线程池框架执行多线程任务是多么的简
单。
为什么需要线程池
目前的大多数网络服务器,包括Web服务器、Email服务器以及数据库服务器等都具有一个共同点,就是单位时间内必须处理数目巨大的连接请求,但处理时间却相对较短。
传统多线程方案中我们采用的服务器模型则是一旦接受到请求之后,即创建一个新的线程,由该线程执行任务。任务执行完毕后,线程退出,这就是是“即时创建,即时销毁”的策略。尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器将处于不停的创建线程,销毁线程的状态。 我们将传统方案中的线程执行过程分为三个过程:T1、T2、T3。
T1:线程创建时间
T2:线程执行时间,包括线程的同步等时间
T3:线程销毁时间
那么我们可以看出,线程本身的开销所占的比例为(T1+T3) / (T1+T2+T3)。如果线程执行的时间很短的话,这比开销可能占到20%-50%左右。如果任务执行时间很频繁的话,这笔开销将是不可忽略的。
除此之外,线程池能够减少创建的线程个数。通常线程池所允许的并发线程是有上界的,如果同时需要并发的线程数超过上界,那么一部分线程将会等待。而传统方案中,如果同时请求数目为2000,那么最坏情况下,系统可能需要产生2000个线程。尽管这不是一个很大的数目,但是也有部分机器可能达不到这种要求。
因此线程池的出现正是着眼于减少线程池本身带来的开销。线程池采用预创建的技术,在应用程序启动之后,将立即创建一定数量的线程(N1),放入空闲队列中。这些线程都是处于阻塞(Suspended)状态,不消耗CPU,但占用较小的内存空间。当任务到来后,缓冲池选择一个空闲线程,把任务传入此线程中运行。当N1个线程都在处理任务后,缓冲池自动创建一定数量的新线程,用于处理更多的任务。在任务执行完毕后线程也不退出,而是继续保持在池中等待下一次的任务。当系统比较空闲时,大部分线程都一直处于暂停状态,线程池自动销毁一部分线程,回收系统资源。
基于这种预创建技术,线程池将线程创建和销毁本身所带来的开销分摊到了各个具体的任务上,执行次数越多,每个任务所分担到的线程本身开销则越小,不过我们另外可能需要考虑进去线程之间同步所带来的开销。
构建线程池框架
一般线程池都必须具备下面几个组成部分:
线程池管理器:用于创建并管理线程池
工作线程: 线程池中实际执行的线程
任务接口: 尽管线程池大多数情况下是用来支持网络服务器,但是我们将线程执行的任务抽象出来,形成任务接口,从而是的线程池与具体的任务无关。
任务队列:线程池的概念具体到实现则可能是队列,链表之类的数据结构,其中保存执行线
程。
我们实现的通用线程池框架由五个重要部分组成CThreadManage,CThreadPool,CThread,CJob,CWorkerThread,除此之外框架中还包括线程同步使用的类CThreadMutex和CCondition。
CJob是所有的任务的基类,其提供一个接口Run,所有的任务类都必须从该类继承,同时实现Run方法。该方法中实现具体的任务逻辑。
CThread是Linux中线程的包装,其封装了Linux线程最经常使用的属性和方法,它也是一个抽象类,是所有线程类的基类,具有一个接口Run。
CWorkerThread是实际被调度和执行的线程类,其从CThread继承而来,实现了CThread中的Run方法。
CThreadPool是线程池类,其负责保存线程,释放线程以及调度线程。
CThreadManage是线程池与用户的直接接口,其屏蔽了内部的具体实现。
CThreadMutex用于线程之间的互斥。
CCondition则是条件变量的封装,用于线程之间的同步。
它们的类的继承关系如下图所示:
线程池的时序很简单,如下图所示。CThreadManage直接跟客户端打交道,其接受需要创建的线程初始个数,并接受客户端提交的任务。这儿的任务是具体的非抽象的任务。CThreadManage的内部实际上调用的都是CThreadPool的相关操作。CThreadPool创建具体的线程,并把客户端提交的任务分发给CWorkerThread,CWorkerThread实际执行具体的任务。
理解系统组件
下面我们分开来了解系统中的各个组件。
CThreadManage
CThreadManage的功能非常简单,其提供最简单的方法,其类定义如下:
class CThreadManage
{
private:
CThreadPool* m_Pool;
int m_NumOfThread;
protected:
public:
void SetParallelNum(int num);
CThreadManage();
CThreadManage(int num);
virtual ~CThreadManage();
void Run(CJob* job,void* jobdata);
void TerminateAll(void);
};
其中m_Pool指向实际的线程池;m_NumOfThread是初始创建时候允许创建的并发的线程个数。另外Run和TerminateAll方法也非常简单,只是简单的调用CThreadPool的一些相关方法而已。其具体的实现如下:
CThreadManage::CThreadManage(){
m_NumOfThread = 10;
m_Pool = new CThreadPool(m_NumOfThread);
}
CThreadManage::CThreadManage(int num){
m_NumOfThread = num;
m_Pool = new CThreadPool(m_NumOfThread);
}
CThreadManage::~CThreadManage(){
if(NULL != m_Pool)
delete m_Pool;
}
void CThreadManage::SetParallelNum(int num){
m_NumOfThread = num;
}
void CThreadManage::Run(CJob* job,void* jobdata){
m_Pool->Run(job,jobdata);
}
void CThreadManage::TerminateAll(void){
m_Pool->TerminateAll();
}
CThread
CThread 类实现了对Linux中线程操作的封装,它是所有线程的基类,也是一个抽象类,提供了一个抽象接口Run,所有的CThread都必须实现该Run方法。CThread的定义如下所示: class CThread
{
private:
int m_ErrCode;
Semaphore m_ThreadSemaphore; //the inner semaphore, which is used to realize unsigned long m_ThreadID;
bool m_Detach; //The thread is detached
bool m_CreateSuspended; //if suspend after creating
char* m_ThreadName;
ThreadState m_ThreadState; //the state of the thread
protected:
void SetErrcode(int errcode){m_ErrCode = errcode;}
static void* ThreadFunction(void*);
public:
CThread();
CThread(bool createsuspended,bool detach);
virtual ~CThread();
virtual void Run(void) = 0;
void SetThreadState(ThreadState state){m_ThreadState = state;}
bool Terminate(void); //Terminate the threa
bool Start(void); //Start to execute the thread
void Exit(void);
bool Wakeup(void);
ThreadState GetThreadState(void){return m_ThreadState;}
int GetLastError(void){return m_ErrCode;}
void SetThreadName(char* thrname){strcpy(m_ThreadName,thrname);}
char* GetThreadName(void){return m_ThreadName;}
int GetThreadID(void){return m_ThreadID;}
bool SetPriority(int priority);
int GetPriority(void);
int GetConcurrency(void);
void SetConcurrency(int num);
bool Detach(void);
bool Join(void);
bool Yield(void);
int Self(void);
};
线程的状态可以分为四种,空闲、忙碌、挂起、终止(包括正常退出和非正常退出)。由于目前Linux线程库不支持挂起操作,因此,我们的此处的挂起操作类似于暂停。如果线程创建后不想立即执行任务,那么我们可以将其“暂停”,如果需要运行,则唤醒。有一点必须注意的是,一旦线程开始执行任务,将不能被挂起,其将一直执行任务至完毕。
线程类的相关操作均十分简单。线程的执行入口是从Start()函数开始,其将调用函数ThreadFunction,ThreadFunction再调用实际的Run函数,执行实际的任务。
CThreadPool[/b]
CThreadPool是线程的承载容器,一般可以将其实现为堆栈、单向队列或者双向队列。在我们的系统中我们使用STL Vector对线程进行保存。CThreadPool的实现代码如下: class CThreadPool
{
friend class CWorkerThread;
private:
unsigned int m_MaxNum; //the max thread num that can create at the same time unsigned int m_AvailLow; //The min num of idle thread that shoule kept
unsigned int m_AvailHigh; //The max num of idle thread that kept at the same time unsigned int m_AvailNum; //the normal thread num of idle num;
unsigned int m_InitNum; //Normal thread num;
protected:
CWorkerThread* GetIdleThread(void);
void AppendToIdleList(CWorkerThread* jobthread);
void MoveToBusyList(CWorkerThread* idlethread);
void MoveToIdleList(CWorkerThread* busythread);
void DeleteIdleThread(int num);
void CreateIdleThread(int num);
public:
CThreadMutex m_BusyMutex; //when visit busy list,use m_BusyMutex to lock and unlock
CThreadMutex m_IdleMutex; //when visit idle list,use m_IdleMutex to lock and unlock CThreadMutex m_JobMutex; //when visit job list,use m_JobMutex to lock and unlock CThreadMutex m_VarMutex;
CCondition m_BusyCond; //m_BusyCond is used to sync busy thread list CCondition m_IdleCond; //m_IdleCond is used to sync idle thread list CCondition m_IdleJobCond; //m_JobCond is used to sync job list
CCondition m_MaxNumCond;
vector m_ThreadList;
vector m_BusyList; //Thread List
vector m_IdleList; //Idle List
CThreadPool();
CThreadPool(int initnum);
virtual ~CThreadPool();
void SetMaxNum(int maxnum){m_MaxNum = maxnum;}
int GetMaxNum(void){return m_MaxNum;}
void SetAvailLowNum(int minnum){m_AvailLow = minnum;}
int GetAvailLowNum(void){return m_AvailLow;}
void SetAvailHighNum(int highnum){m_AvailHigh = highnum;}
int GetAvailHighNum(void){return m_AvailHigh;}
int GetActualAvailNum(void){return m_AvailNum;}
int GetAllNum(void){return m_ThreadList.size();}
int GetBusyNum(void){return m_BusyList.size();}
void SetInitNum(int initnum){m_InitNum = initnum;}
int GetInitNum(void){return m_InitNum;}
void TerminateAll(void);
void Run(CJob* job,void* jobdata);
};
CThreadPool::CThreadPool()
{
m_MaxNum = 50;
m_AvailLow = 5;
m_InitNum=m_AvailNum = 10 ;
m_AvailHigh = 20;
m_BusyList.clear();
m_IdleList.clear();
for(int i=0;i
CWorkerThread* thr = new CWorkerThread();
thr->SetThreadPool(this);
AppendToIdleList(thr);
thr->Start();
}
}
CThreadPool::CThreadPool(int initnum)
{
assert(initnum>0 && initnum
m_MaxNum = 30;
m_AvailLow = initnum-10>0?initnum-10:3;
m_InitNum=m_AvailNum = initnum ;
m_AvailHigh = initnum+10;
m_BusyList.clear();
m_IdleList.clear();
for(int i=0;i
CWorkerThread* thr = new CWorkerThread();
AppendToIdleList(thr);
thr->SetThreadPool(this);
thr->Start(); //begin the thread,the thread wait for job }
}
CThreadPool::~CThreadPool()
{
TerminateAll();
}
void CThreadPool::TerminateAll()
{
for(int i=0;i
CWorkerThread* thr = m_ThreadList[i];
thr->Join();
}
return;
}
CWorkerThread* CThreadPool::GetIdleThread(void)
{
while(m_IdleList.size() ==0 )
m_IdleCond.Wait();
m_IdleMutex.Lock();
if(m_IdleList.size() > 0 )
{
CWorkerThread* thr = (CWorkerThread*)m_IdleList.front(); printf("Get Idle thread %dn",thr->GetThreadID()); m_IdleMutex.Unlock();
return thr;
}
m_IdleMutex.Unlock();
return NULL;
}
//add an idle thread to idle list
void CThreadPool::AppendToIdleList(CWorkerThread* jobthread) {
m_IdleMutex.Lock();
m_IdleList.push_back(jobthread);
m_ThreadList.push_back(jobthread);
m_IdleMutex.Unlock();
}
//move and idle thread to busy thread
void CThreadPool::MoveToBusyList(CWorkerThread* idlethread) {
m_BusyMutex.Lock();
m_BusyList.push_back(idlethread);
m_AvailNum--;
m_BusyMutex.Unlock();
m_IdleMutex.Lock();
vector::iterator pos;
pos = find(m_IdleList.begin(),m_IdleList.end(),idlethread); if(pos !=m_IdleList.end())
m_IdleList.erase(pos);
m_IdleMutex.Unlock();
}
void CThreadPool::MoveToIdleList(CWorkerThread* busythread) {
m_IdleMutex.Lock();
m_IdleList.push_back(busythread);
m_AvailNum++;
m_IdleMutex.Unlock();
m_BusyMutex.Lock();
vector::iterator pos;
pos = find(m_BusyList.begin(),m_BusyList.end(),busythread); if(pos!=m_BusyList.end())
m_BusyList.erase(pos);
m_BusyMutex.Unlock();
m_IdleCond.Signal();
m_MaxNumCond.Signal();
}
//create num idle thread and put them to idlelist
void CThreadPool::CreateIdleThread(int num)
{
for(int i=0;i
CWorkerThread* thr = new CWorkerThread();
thr->SetThreadPool(this);
AppendToIdleList(thr);
m_VarMutex.Lock();
m_AvailNum++;
m_VarMutex.Unlock();
thr->Start(); //begin the thread,the thread wait for job }
}
void CThreadPool::DeleteIdleThread(int num)
{
printf("Enter into CThreadPool::DeleteIdleThreadn"); m_IdleMutex.Lock();
printf("Delete Num is %dn",num);
for(int i=0;i
CWorkerThread* thr;
if(m_IdleList.size() > 0 ){
thr = (CWorkerThread*)m_IdleList.front();
printf("Get Idle thread %dn",thr->GetThreadID()); }
vector::iterator pos;
pos = find(m_IdleList.begin(),m_IdleList.end(),thr);
if(pos!=m_IdleList.end())
m_IdleList.erase(pos);
m_AvailNum--;
printf("The idle thread available num:%d n",m_AvailNum);
printf("The idlelist num:%d n",m_IdleList.size());
}
m_IdleMutex.Unlock();
}
void CThreadPool::Run(CJob* job,void* jobdata)
{
assert(job!=NULL);
//if the busy thread num adds to m_MaxNum,so we should wait
if(GetBusyNum() == m_MaxNum)
m_MaxNumCond.Wait();
if(m_IdleList.size()
{
if(GetAllNum()+m_InitNum-m_IdleList.size()
CreateIdleThread(m_InitNum-m_IdleList.size());
else
CreateIdleThread(m_MaxNum-GetAllNum());
}
CWorkerThread* idlethr = GetIdleThread();
if(idlethr !=NULL)
{
idlethr->m_WorkMutex.Lock();
MoveToBusyList(idlethr);
idlethr->SetThreadPool(this);
job->SetWorkThread(idlethr);
printf("Job is set to thread %d n",idlethr->GetThreadID());
idlethr->SetJob(job,jobdata);
}
}
在CThreadPool中存在两个链表,一个是空闲链表,一个是忙碌链表。Idle链表中存放所有的空闲进程,当线程执行任务时候,其状态变为忙碌状态,同时从空闲链表中删除,并移至忙碌链表中。在CThreadPool的构造函数中,我们将执行下面的代码:
for(int i=0;i
{
CWorkerThread* thr = new CWorkerThread();
AppendToIdleList(thr);
thr->SetThreadPool(this);
thr->Start(); //begin the thread,the thread wait for job
}
在该代码中,我们将创建m_InitNum个线程,创建之后即调用AppendToIdleList放入Idle链表中,由于目前没有任务分发给这些线程,因此线程执行Start后将自己挂起。
事实上,线程池中容纳的线程数目并不是一成不变的,其会根据执行负载进行自动伸缩。为此在CThreadPool中设定四个变量:
m_InitNum:处世创建时线程池中的线程的个数。
m_MaxNum:当前线程池中所允许并发存在的线程的最大数目。
m_AvailLow:当前线程池中所允许存在的空闲线程的最小数目,如果空闲数目低于该值,表明负载可能过重,此时有必要增加空闲线程池的数目。实现中我们总是将线程调整为m_InitNum个。
m_AvailHigh:当前线程池中所允许的空闲的线程的最大数目,如果空闲数目高于该值,表明当前负载可能较轻,此时将删除多余的空闲线程,删除后调整数也为m_InitNum个。 m_AvailNum:目前线程池中实际存在的线程的个数,其值介于m_AvailHigh和m_AvailLow之间。如果线程的个数始终维持在m_AvailLow和m_AvailHigh之间,则线程既不需要创建,也不需要删除,保持平衡状态。因此如何设定m_AvailLow和m_AvailHigh的值,使得线程池最大可能的保持平衡态,是线程池设计必须考虑的问题。
线程池在接受到新的任务之后,线程池首先要检查是否有足够的空闲池可用。检查分为三个步骤:
(1)检查当前处于忙碌状态的线程是否达到了设定的最大值m_MaxNum,如果达到了,表明目前没有空闲线程可用,而且也不能创建新的线程,因此必须等待直到有线程执行完毕返回到空闲队列中。
(2)如果当前的空闲线程数目小于我们设定的最小的空闲数目m_AvailLow,则我们必须创建新的线程,默认情况下,创建后的线程数目应该为m_InitNum,因此创建的线程数目应该为( 当前空闲线程数与m_InitNum);但是有一种特殊情况必须考虑,就是现有的线程总数加上创建后的线程数可能超过m_MaxNum,因此我们必须对线程的创建区别对待。
if(GetAllNum()+m_InitNum-m_IdleList.size()
CreateIdleThread(m_InitNum-m_IdleList.size());
else
CreateIdleThread(m_MaxNum-GetAllNum());
如果创建后总数不超过m_MaxNum,则创建后的线程为m_InitNum;如果超过了,则只创建( m_MaxNum-当前线程总数 )个。
(3)调用GetIdleThread方法查找空闲线程。如果当前没有空闲线程,则挂起;否则将任务指派给该线程,同时将其移入忙碌队列。
当线程执行完毕后,其会调用MoveToIdleList方法移入空闲链表中,其中还调用m_IdleCond.Signal()方法,唤醒GetIdleThread()中可能阻塞的线程。
###################################################################################################################
服务器程序利用线程技术响应客户请求已经司空见惯,可能您认为这样做效率已经很高,但您有没有想过优化一下使用线程的方法。该文章将向您介绍服务器程序如何利用线程池来优化性能并提供一个简单的线程池实现。
线程池的技术背景
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。在Java中更是如此,虚拟机将试图跟踪每一个对象,以便能够在对象销毁后进行垃圾回收。所以提高服务程序效率的一个手段就是尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁。如何利用已有对象来服务就是一个需要解决的关键问题,其实这就是一些"池化资源"技术产生的原因。比如大家所熟悉的数据库连接池正是遵循这一思想而产生的,本文将介绍的线程池技术同样符合这一思想。
目前,一些著名的大公司都特别看好这项技术,并早已经在他们的产品中应用该技术。比如IBM的WebSphere,IONA的Orbix 2000在SUN的 Jini中,Microsoft的MTS(Microsoft Transaction Server 2.0),COM+等。
现在您是否也想在服务器程序应用该项技术?
线程池技术如何提高服务器程序的性能
我所提到服务器程序是指能够接受客户请求并能处理请求的程序,而不只是指那些接受网络客户请求的网络服务器程序。
多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力。但如果对多线程应用不当,会增加对单个任务的处理时间。可以举一个简单的例子:
假设在一台服务器完成一项任务的时间为T
T1 创建线程的时间
T2 在线程中执行任务的时间,包括线程间同步所需时间
T3 线程销毁的时间
显然T = T1+T2+T3。注意这是一个极度简化的假设。
可以看出T1,T3是多线程本身的带来的开销,我们渴望减少T1,T3所用的时间,从而减少T的时间。但一些线程的使用者并没有注意到这一点,所以在程序中频繁的创建或销毁线程,这导致T1和T3在T中占有相当比例。显然这是突出了线程的弱点(T1,T3),而不是优点(并发性)。
线程池技术正是关注如何缩短或调整T1,T3时间的技术,从而提高服务器程序性能的。它把T1,T3分别安排在服务器程序的启动和结束的时间段或者一些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1,T3的开销了。
线程池不仅调整T1,T3产生的时间段,而且它还显著减少了创建线程的数目。在看一个例子:
假设一个服务器一天要处理50000个请求,并且每个请求需要一个单独的线程完成。我们比较利用线程池技术和不利于线程池技术的服务器处理这些请求时所产生的线程总数。在线程池中,线程数一般是固定的,所以产生线程总数不会超过线程池中线程的数目或者上限(以下简称线程池尺寸),而如果服务器不利用线程池来处理这些请求则线程总数为50000。一般线程池尺寸是远小于50000。所以利用线程池的服务器程序不会为了创建50000而在处理请求时浪费时间,从而提高效率。
这些都是假设,不能充分说明问题,下面我将讨论线程池的简单实现并对该程序进行对比测试,以说明线程技术优点及应用领域。
现在来实现一下线程池
class ThreadPoolManage
{
private:
ThreadPoolManage();
virtual~ThreadPoolManage();
private:
static ThreadPoolManage *m_ThreadPool;
static CArray<TemporaryThread *,TemporaryThread *> m_Temporarily; //临时线程 static CArray<ManageThread *,ManageThread *> m_ManageThread; //最初线程 static CCriticalSection section;
public:
static ThreadPoolManage * GetThreadPoolManage();
static void CloseThreadPoolManage();
protected:
//线程回调函数
static DWORD WINAPI ExcuteMession(LPVOID n);
static DWORD WINAPI ExcuteLeisureMession(LPVOID n);
private:
//加入工作任务
bool AddTask(Task *inTask);
bool IsAddTask();
//起动与停止线程池
bool StartThreadPool(int inCount);
bool StopThreadPool();
///关闭一到多个空闲线程返回关闭的线程数
int CloseTemporarilyThread(int count);
//线程池中的总的线程数
int GetThreadPoolCount();
};
#endif
#include "Task.h"
class ManageThread
{
private:
HANDLE mhThread;//线程句柄
HANDLE mhEvent;//事件句柄(结束空闲线程通知)
CSemaphore *m_sesction;//信号量
Task *pTask;
public:
ManageThread();
virtual~ManageThread();
public:
//线程操作
bool ExcuteThread();
bool PostExitThread();
bool TerminateExitThread();
bool GetThreadIsLisure();//线程是否空闲
bool SetLockThread(int tm=0);//锁定当前线程(参数tm代表的是时间) //字柄操作
HANDLE GetThreadEvent();
HANDLE GetThreadHandle();
void SetThreadHandle(HANDLE handle);
//设置当前线程工作的任务
void SetThreadTask(Task *inTask);
};
#endif
class Task
{
public:
Task();
virtual ~Task();
public:
virtual void ExcuteTask()=0;
};
#endif
任务类说明:
这是我开发的一个UDP传输的类
class UdpTask :public Task
{
private:
SOCKET mSckSender;
HANDLE hRecThread;
UdpClientInfo mInfor;
bool mIsSend;
int mSlindindWin;//可滑动窗口数
list<WaitDefiniteData *> mWaitDefineList;
double SuperTime;//超时时间(最小不得小到2秒)(=传送前一个数据片的2倍)
FILE * pFlie;
byte * _svd;
public:
UdpTask();
virtual ~UdpTask();
void ExcuteTask();
void SetClientInfo(CString inPath,RemoteEP inEP);
protected:
private:
bool InitFile();
void SendFileLoop();//发送文件
void SendTcpConn();//转TCP连接
void SendSampleEnd();//发送完毕
BOOL HeavyspreadSample();//重传检索
void SendSpreadSample(WaitDefiniteData *inData);//重传一个数据包
void ConfirmSample(int inNum );//滑动窗口有关
//发送SOCKET打操作
bool CreateSender();
void DelecteSender();
bool Send(const char * inBuffer,int inLength);
//接受数据线程
BOOL StartReceiving();
void StopRecveiving();
void RecveivingLoop();
static DWORD WINAPI ReceivingThrd(void *pParam);
};
#####################################################################################################
一个VC线程池的实现
上一篇 / 下一篇 2007-03-18 10:06:10 / 个人分类:软件开发小贴士
查看( 237 ) / 评论( 0 ) / 评分( 0 / 0 )
类定义如下
// ThreadPoolImp.h: interface for the ThreadPoolImp class.
//
//////////////////////////////////////////////////////////////////////
#if !defined(AFX_THREADPOOLIMP_H__82F4FC7E_2DB4_4D2A_ACC8_2EFC787CAE42__INCLUDED_)
#define
AFX_THREADPOOLIMP_H__82F4FC7E_2DB4_4D2A_ACC8_2EFC787CAE42__INCLUDED_
#if _MSC_VER > 1000
#pragma once
#endif // _MSC_VER > 1000
#pragma warning( disable : 4705 4786)
#include <map>
#include "AutoLock.h"
using namespace std;
class IJobDesc;
class IWorker;
class CThreadPoolImp
{
public:
class ThreadInfo
{
public:
ThreadInfo() { m_hThread=0; m_bBusyWorking=false; }
ThreadInfo(HANDLE handle, bool bBusy) { m_hThread=handle; m_bBusyWorking=bBusy; }
ThreadInfo(const ThreadInfo& info) { m_hThread=info.m_hThread; m_bBusyWorking=info.m_bBusyWorking; }
////////
HANDLE m_hThread;
bool m_bBusyWorking;
};
typedef map<DWORD,ThreadInfo> ThreadInfoMap;
typedef ThreadInfoMap::iterator Iterator_ThreadInfoMap;
friend static unsigned int CThreadPoolImp::ManagerProc(void* p);
friend static unsigned int CThreadPoolImp::WorkerProc(void* p); protected:
enum ThreadPoolStatus { BUSY, IDLE, NORMAL }; public:
//interface to the outside
void Start(unsigned short nStatic, unsigned short nmax); void Stop(bool bHash=false);
void ProcessJob(IJobDesc* pJob, IWorker* pWorker) const;
//constructor and destructor
CThreadPoolImp();
virtual ~CThreadPoolImp();
protected:
//interfaces public:
HANDLE GetMgrIoPort() const { return m_hMgrIoPort; } UINT GetMgrWaitTime() const { return 1000; }
HANDLE GetWorkerIoPort() const { return m_hWorkerIoPort; }
private:
static DWORD WINAPI ManagerProc(void* p);
static DWORD WINAPI WorkerProc(void* p);
protected:
//manager thread
HANDLE m_hMgrThread;
HANDLE m_hMgrIoPort;
protected:
//configuration parameters
mutable unsigned short m_nNumberOfStaticThreads; mutable unsigned short m_nNumberOfTotalThreads;
protected:
//helper functions
void AddThreads();
void RemoveThreads();
ThreadPoolStatus GetThreadPoolStatus();
void ChangeStatus(DWORD threadId, bool status);
void RemoveThread(DWORD threadId);
protected:
//all the work threads
ThreadInfoMap m_threadMap;
CCriticalSection m_arrayCs;
HANDLE m_hWorkerIoPort;
};
#endif
// !defined(AFX_THREADPOOLIMP_H__82F4FC7E_2DB4_4D2A_ACC8_2EFC787CAE42__INCLUDED_)
实现如下
// ThreadPool.cpp: implementation of the CThreadPoolImp class.
//
//////////////////////////////////////////////////////////////////////
#include "stdafx.h"
#include "ThreadPoolimp.h"
#include "outdebug.h"
#include <assert.h>
#include "work.h"
#ifdef _DEBUG
#undef THIS_FILE
static char THIS_FILE[]=__FILE__;
//#define new DEBUG_NEW
#endif
CThreadPoolImp::CThreadPoolImp()
{
}
CThreadPoolImp::~CThreadPoolImp()
{
}
void CThreadPoolImp::Start(unsigned short nStatic, unsigned short nMax)
{
assert(nMax>=nStatic);
HANDLE hThread;
DWORD nThreadId;
m_nNumberOfStaticThreads=nStatic;
m_nNumberOfTotalThreads=nMax;
//lock the resource
CAutoLock AutoLock(m_arrayCs);
//create an IO port
m_hMgrIoPort = CreateIoCompletionPort((HANDLE)INVALID_HANDLE_VALUE, NULL, 0, 0);
hThread = CreateThread(
NULL, // SD
0, // initial stack size
(LPTHREAD_START_ROUTINE)ManagerProc, // thread function
(LPVOID)this, // thread argument
0, // creation option
&nThreadId ); // thread identifier
m_hMgrThread = hThread;
//now we start these worker threads
m_hWorkerIoPort = CreateIoCompletionPort((HANDLE)INVALID_HANDLE_VALUE, NULL, 0, 0);
for(long n = 0; n < nStatic; n++)
{
hThread = CreateThread(
NULL, // SD
0, // initial stack size
(LPTHREAD_START_ROUTINE)WorkerProc, // thread function (LPVOID)this, // thread argument
0, // creation option
&nThreadId );
ReportDebug("generate a worker thread handle id is %d.\n", nThreadId);
m_threadMap.insert(m_threadMap.end(),ThreadInfoMap::value_type
(nThreadId,ThreadInfo(hThread, false)));
}
}
void CThreadPoolImp::Stop(bool bHash)
{
CAutoLock Lock(m_arrayCs);
::PostQueuedCompletionStatus(m_hMgrIoPort, 0, 0, (OVERLAPPED*)0xFFFFFFFF); WaitForSingleObject(m_hMgrThread, INFINITE);
CloseHandle(m_hMgrThread);
CloseHandle(m_hMgrIoPort);
//shut down all the worker threads
UINT nCount=m_threadMap.size();
HANDLE* pThread = new HANDLE[nCount];
long n=0;
ThreadInfo info;
Iterator_ThreadInfoMap i=m_threadMap.begin();
while(i!=m_threadMap.end())
{
::PostQueuedCompletionStatus(m_hWorkerIoPort, 0, (OVERLAPPED*)0xFFFFFFFF);
info=i->second;
pThread[n++]=info.m_hThread;
i++;
}
DWORD rc=WaitForMultipleObjects(nCount, pThread, TRUE, 30000);
CloseHandle(m_hWorkerIoPort);
if(rc>=WAIT_OBJECT_0 && rc<WAIT_OBJECT_0+nCount)
{
for(unsigned int n=0;n<nCount;n++)
{
CloseHandle(pThread[n]);
}
}
else if(rc==WAIT_TIMEOUT&&bHash)
{
//some threads not terminated, we have to stop them.
DWORD exitCode;
for(unsigned int i=0; i<nCount; i++)
{
if (::GetExitCodeThread(pThread[i], &exitCode)==STILL_ACTIVE) {
TerminateThread(pThread[i], 99);
}
CloseHandle(pThread[i]);
}
}
delete[] pThread;
}
DWORD WINAPI CThreadPoolImp::ManagerProc(void* p)
{
//convert the parameter to the server pointer.
CThreadPoolImp* pServer=(CThreadPoolImp*)p; 0,
HANDLE IoPort = pServer->GetMgrIoPort();
unsigned long pN1, pN2;
OVERLAPPED* pOverLapped;
LABEL_MANAGER_PROCESSING:
while(::GetQueuedCompletionStatus(IoPort, &pN1, &pN2, &pOverLapped, pServer->GetMgrWaitTime() ))
{
if(pOverLapped == (OVERLAPPED*)0xFFFFFFFF) {
return 0;
}
else
{
ReportDebug("mgr events comes in!\n");
}
}
//time out processing
if (::GetLastError()==WAIT_TIMEOUT)
{
//time out processing
ReportDebug("Time out processing!\n");
//the manager will take a look at all the worker′s status. The if (pServer->GetThreadPoolStatus()==CThreadPoolImp::BUSY) pServer->AddThreads();
if (pServer->GetThreadPoolStatus()==CThreadPoolImp::IDLE) pServer->RemoveThreads();
goto LABEL_MANAGER_PROCESSING;
}
return 0;
}
DWORD WINAPI CThreadPoolImp::WorkerProc(void* p)
{
//convert the parameter to the server pointer.
CThreadPoolImp* pServer=(CThreadPoolImp*)p;
HANDLE IoPort = pServer->GetWorkerIoPort(); unsigned long pN1, pN2;
OVERLAPPED* pOverLapped;
DWORD threadId=::GetCurrentThreadId();
ReportDebug("worker thread id is %d.\n", threadId);
while(::GetQueuedCompletionStatus(IoPort, &pN1, &pN2, &pOverLapped, INFINITE ))
{
if(pOverLapped == (OVERLAPPED*)0xFFFFFFFE) {
pServer->RemoveThread(threadId);
break;
}
else if(pOverLapped == (OVERLAPPED*)0xFFFFFFFF) {
break;
}
else
{
ReportDebug("worker events comes in!\n");
//before processing, we need to change the status to busy. pServer->ChangeStatus(threadId, true);
//retrieve the job descrīption and agent pointer
IWorker* pIWorker = reinterpret_cast<IWorker*>(pN1); IJobDesc* pIJob= reinterpret_cast<IJobDesc*>(pN2); pIWorker->ProcessJob(pIJob);
pServer->ChangeStatus(threadId, false);
}
}
return 0;
}
void CThreadPoolImp::ChangeStatus(DWORD threadId, bool status) {
CAutoLock CAutoLock(m_arrayCs);
//retrieve the current thread handle
Iterator_ThreadInfoMap i;
ThreadInfo info;
i=m_threadMap.find(threadId);
info=i->second;
info.m_bBusyWorking=status;
m_threadMap.insert(m_threadMap.end(),ThreadInfoMap::value_type(threadId, info)); }
void CThreadPoolImp::ProcessJob(IJobDesc* pJob, IWorker* pWorker) const
{
::PostQueuedCompletionStatus(m_hWorkerIoPort, \
reinterpret_cast<DWORD>(pWorker), \
reinterpret_cast<DWORD>(pJob),\
NULL);
}
void CThreadPoolImp::AddThreads()
{
HANDLE hThread;
DWORD nThreadId;
unsigned int nCount=m_threadMap.size();
unsigned int nTotal=min(nCount+2, m_nNumberOfTotalThreads);
for(unsigned int i=0; i<nTotal-nCount; i++)
{
hThread = CreateThread(
NULL, // SD
0, // initial stack size
(LPTHREAD_START_ROUTINE)WorkerProc, // thread function
(LPVOID)this, // thread argument
0, // creation option
&nThreadId );
ReportDebug("generate a worker thread handle id is %d.\n", nThreadId);
m_threadMap.insert(m_threadMap.end(),ThreadInfoMap::value_type(nThreadId,ThreadInfo(hThread, false)));
}
}
void CThreadPoolImp::RemoveThread(DWORD threadId)
{
CAutoLock lock(m_arrayCs);
m_threadMap.erase(threadId);
}
void CThreadPoolImp::RemoveThreads()
{
unsigned int nCount=m_threadMap.size();
unsigned int nTotal=max(nCount-2, m_nNumberOfStaticThreads);
for(unsigned int i=0; i<nCount-nTotal; i++)
{
::PostQueuedCompletionStatus(m_hWorkerIoPort, 0, (OVERLAPPED*)0xFFFFFFFE);
}
}
CThreadPoolImp::ThreadPoolStatus CThreadPoolImp::GetThreadPoolStatus() {
int nTotal = m_threadMap.size();
ThreadInfo info;
int nCount=0;
Iterator_ThreadInfoMap i=m_threadMap.begin();
while(i!=m_threadMap.end())
{
info=i->second;
if (info.m_bBusyWorking==true) nCount++;
i++;
}
if ( nCount/(1.0*nTotal) > 0.8 )
return BUSY;
if ( nCount/ (1.0*nTotal) < 0.2 )
return IDLE;
return NORMAL;
}
0,