神经网络学习报告
一 神经网络的特点及其应用
神经网络是一种黑箱建模工具,所谓黑箱建模就是在对研究对象系统一无所知的情况下,将该系统看作“黑匣子”,借助已有的数据,通过数学计算得到系统输入与输出之间的关系。这一方法相对于其他的建模方式具有一下特点:
(1) 有很强的适应能力
(2) 有很强的学习能力
(3) 是多输入多输出的系统
随着人们对神经网络的深入的研究,神经网络得以在很多场合都有了应用。尤其是在模式识别,人工智能,信息处理,计算机科学等方面;
(1) 模式识别及图像处理
语音识别,人脸识别,指纹识别,签字识别,字符识别,目标检测与识别,图像压缩和图像还原等;
(2) 控制及优化
工业过程控制,机器人运动控制,家电智能控制,集成电路设计等;
(3) 预测和信息管理
股票市场数据预测,地震预测,证券管理,交通管理,IC卡管理等;
(4) 通信领域
自适应均衡,回波抵消,ATM网络中的呼叫接纳识别以及控制和路由选择等;
二 人工神经网络的基本模型及其实现
人工神经网络是由多个神经元构成的如下图1所示:
 ..
..
神经元的结构如下图2所示:
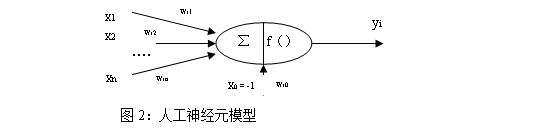
图中X1——Xn是该神经元的输入信号,当然此信号有可能来自系统的输入信号,也有可能来自前面的其他神经元。Wij表示从神经元i到神经元j的连接权值,Wi0表示一个阈值。所以神经元i的输入与输出的关系为:

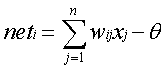 (1)
(1)
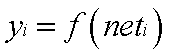 (2)
(2)
neti称为神经元i的净激活,若neti大于零则该神经元处于激活状态,若小于零则处于抑制状态。
三 BP神经网络的设计
BP神经网络的设计步骤如下图:
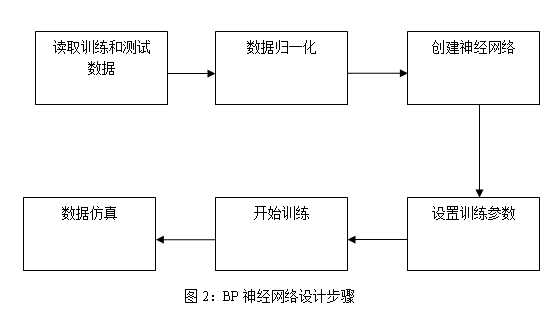
(1) 数据的读取
数据很少可以直接在程序中给出,则无需读取。若数据很多,可以另外存储在一个text,mat文件中使用load函数就这可以直接读取。
(2) 数据归一化
数据归一化就是把实验数据映射到[0,1]或[-1,1]或者更小的区间上。
Matlab数据归一化函数有premnmx,postmnmx,tramnmx三个函数;
语法为:[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t);
[pn]=tramnmx(p,minp,maxp)
[p,t]=postmnmx(pn,minp,maxp,tn,mint,maxt)
(3)创建神经网络
创建神经网络的函数有很多,常用的为newff函数语法为:net=newff(A,B,{C},’trainfun’)
其中A我n*2矩阵,第i行的最大值和最小值;B为k维行向量,其元素为网络中各层的神经元个数;C为各层对应的激活函数;trainfun为学习规则采用的学习方法;
(4)训练参数的设置
训练参数设置如下:
目标误差:net.trainparam.goal;
显示中间结果的周期:net.trainparam.show;
最大迭代次数:net.trainparam.epochs;
学习率:net.trainparam.Ir;
(5)训练函数的格式
语法:[net,tr,Y1,E]=train(net,X,Y)
X为网络输入;Y为网络应有输出;tr为训练跟踪信息;Y1为网络实际输出;E为误差矩阵;
(6)参数仿真
语法:Y=sim(net,X)
其中为网络,X为输入网络的 K*N矩阵,K为样本数,N为数据样本数;Y:输出矩阵Q*N,Q为网络输出个数;
四 Matlab BP神经网络实例
实例以Iris的特征和种类数据作为神经网络的测试数据。这种花有三种品种,不同品种之间花的花萼长度,宽度和花瓣长度,宽度不同,本实例目的是为了找到品种和花萼花瓣的特征的对应关系;本实例共150组数据其中75作为训练数据,其中三种花各25组数据;
75组数据作为检验样本,三种花依次编号为1,2,3.因此数据有四个输入,三个输出;
Matlab程序如下:
[f1,f2,f3,f4,class] = textread('trainData.txt' , '%f%f%f%f%f',150);
[input,minI,maxI] = premnmx( [f1 , f2 , f3 , f4 ]') ;
s = length( class ) ;
output = zeros( s , 3 ) ;
for i = 1 : s
output( i , class( i ) ) = 1 ;
end
net = newff( minmax(input) , [10 3] , { 'logsig' 'purelin' } , 'traingdx' ) ;
net.trainparam.show = 50 ;
net.trainparam.epochs = 500 ;
net.trainparam.goal = 0.01 ;
net.trainParam.lr = 0.01 ;
net = train( net, input , output' ) ;
[t1, t2, t3, t4, c] = textread('testData.txt' , '%f%f%f%f%f',150);
testInput = tramnmx ( [t1,t2,t3,t4]' , minI, maxI ) ;
Y = sim( net , testInput )
[s1 , s2] = size( Y ) ;
hitNum = 0 ;
for i = 1 : s2
[m , Index] = max( Y( : , i ) ) ;
if( Index == c(i) )
hitNum = hitNum + 1 ;
end
end
sprintf('识别率是 %3.3f%%',100 * hitNum / s2 )
程序运行结果
Y =
Columns 1 through 14
0.9423 0.9182 1.0313 1.0345 0.9841 0.9614 0.9306 1.0504 1.0096 0.9814 1.0416 1.0238 1.1002 0.9413
0.0398 0.0800 -0.0385 -0.0458 -0.0005 0.0216 0.0735 -0.0478 0.0051 -0.0019 -0.0668 -0.0230 -0.1206 0.0420
0.0057 -0.0007 0.0067 0.0130 -0.0030 0.0002 0.0060 0.0016 -0.0052 0.0126 0.0335 0.0069 0.0151 0.0168
Columns 15 through 28
1.0300 1.0227 0.5615 1.0105 0.8169 0.9469 0.8956 1.0403 1.0094 1.0293 1.0336 0.0308 -0.0060 -0.0119
-0.0424 -0.0351 0.4309 -0.0321 0.1934 0.0643 0.0862 -0.0426 -0.0315 -0.0288 -0.0526 0.9856 0.9269 0.6285
0.0092 0.0179 0.0409 0.0152 0.0007 -0.0221 0.0264 0.0003 0.0132 0.0023 0.0174 -0.0151 0.0968 0.3848
Columns 29 through 42
-0.0313 0.0654 -0.0097 0.0183 0.0060 -0.0479 -0.0356 0.0360 0.0172 -0.0158 0.0155 -0.0416 -0.0351 -0.0055
0.9000 1.0477 1.0745 1.0713 1.0943 0.3816 0.8551 0.8785 0.9105 0.9355 1.1062 1.0141 0.9958 0.9614
0.1333 -0.1197 -0.0611 -0.0938 -0.0876 0.6144 0.1911 0.0712 0.0765 0.0473 -0.0941 0.0432 0.0459 0.0393
Columns 43 through 56
-0.0131 0.0480 -0.0337 0.0431 -0.0026 0.0155 0.0359 -0.0146 -0.0108 -0.0238 -0.0371 0.0317 -0.0079 -0.0094
1.0773 1.0646 1.0405 1.0889 1.0817 1.0335 1.1353 1.0856 0.2547 0.4009 0.4324 -0.1223 0.4707 0.0772
-0.0606 -0.0717 0.0135 -0.1319 -0.0574 -0.0483 -0.1152 -0.0454 0.7803 0.5702 0.5565 1.0832 0.5758 0.9472
Columns 57 through 70
0.0907 0.0533 -0.0501 -0.0749 0.0307 -0.0140 -0.0380 -0.0401 0.0241 0.0523 0.0673 -0.0121 0.0178 0.0358
0.0478 -0.1695 0.6489 0.3663 -0.0417 -0.0188 0.2688 0.4635 0.1155 -0.1190 0.0460 0.0001 -0.0576 -0.0853
0.8417 1.1223 0.3753 0.6588 0.9847 0.9911 0.7115 0.5317 0.8517 1.0621 0.8414 0.9646 1.0601 1.0573
Columns 71 through 75
0.0604 0.0497 -0.0032 -0.0249 -0.0428
-0.0443 0.0760 0.1593 0.0409 0.2857
0.9340 0.8237 0.7980 0.9204 0.6907
ans =
识别率是 97.333%
第二篇:神经网络学习报告1
阶段学习报告
摘要:现阶段已学习过神经网络中的Hebb学习,感知器,自适应线性神经元和多层前向网络,本文对上述规则进行总结,分析各种规则之间的关系及它们之间的异同,并介绍它们各自的典型应用。
关键字:Hebb学习 感知器 自适应线性神经元 多层前向网络
引言
神经网络技术[1]中,对神经网络的优化一直是人们研究的热点问题。1943年心理学家Warren McCulloch和数理逻辑学家Walter Pitts首先提出人工神经元模型;1949年心理学家Donald O.Hebb提出了神经网络联想式学习规则,给出了神经网络的学习方法;1957年美国学者Frank Rosenblatt和其它研究人员提出了一种简单的且具有学习能力的神经网络——感知器(Perceptron),并给出了感知器学习规则;1960年Bernard Widrow和他的研究生Marcian Hoff提出了自适应线性神经元,并给出了Widrow-Hoff学习算法;之后神经网络研究陷入低潮,直至80年代,改进的(多层)感知器网络和相应学习规则的提出才为克服这些局限性开辟了新的途径。
本文结构如下:首先介绍感知器模型,Hebb学习,自适应线性神经元和多层前向网络;其次分析上述规则之间的关系和异同;最后给出它们的典型应用。
第一章 典型的神经网络学习方法
1.1 Hebb学习规则[2]
Hebb规则是最早的神经网络学习规则之一,是一种联想式学习方法,由Donald Hebb在1949年作为大脑的一种神经元突触调整的可能机制而提出,从那以后Hebb规则就一直用于人工神经网络的训练。这一学习规则可归纳为“当某一突触连接两端的神经元同时处于激活状态(或同为抑制)时,该连接的强度应增加,反之应减弱”。
学习信号简单的等于神经元的输出:
 (1-1)
(1-1)
权向量的调整公式为
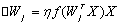 (1-2)
(1-2)
权值的调整量与输入输出的乘积成正比。经常出现的模式对权向量有最大的影响。为此,Hebb学习规则需先设定权饱和值,以防止输入和输出正负始终一致时出现权值无限制增长。
Hebb学习规则是一种无教师的学习方法,它只根据神经元连接间的激活水平改变权值,因此这种方法又称为相关学习或并联学习。
1.2 感知器学习规则[3]
感知器是第一个完整的人工神经网络,它具有联想记忆的功能。
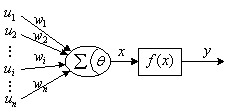
图1 单层感知器神经元模型
对于图1给出的感知器神经元,其净输入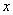 及输出
及输出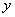 为:
为:
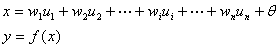 (1-3)
(1-3)
若令 ,则:
,则:
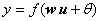 (1-4)
(1-4)
其中:和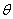 是感知器神经元的输出和阈值;是输入向量与神经元之间的连接权系数向量;
是感知器神经元的输出和阈值;是输入向量与神经元之间的连接权系数向量;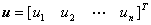 是感知器的输入向量;
是感知器的输入向量;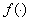 是感知器神经元的作用函数,这里取阶跃函数。即
是感知器神经元的作用函数,这里取阶跃函数。即
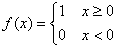 (1-5)
(1-5)
由于单神经元感知器的作用函数是阶跃函数,其输出只能是0或1。当神经元净输入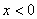 时
时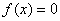 ,当净输入
,当净输入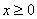 时
时 。可见,单神经元感知器可以将输入向量分为两类,类别界限为
。可见,单神经元感知器可以将输入向量分为两类,类别界限为
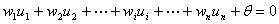 (1-6)
(1-6)
为了便于分析,以二输入单神经元感知器为例说明感知器的分类性能。此时,类别界限为:
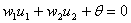 (1-7)
(1-7)
若将 、
、 和看作为确定的参数,那么式(2-7)实质上在输入向量空间
和看作为确定的参数,那么式(2-7)实质上在输入向量空间 中定义了一条直线。该直线一侧的输入向量对应的网络输出为0,而直线另一侧的输入向量对应的网络输出则为1。
中定义了一条直线。该直线一侧的输入向量对应的网络输出为0,而直线另一侧的输入向量对应的网络输出则为1。
由于单神经元感知器的输出只有0或1两种状态,所以只能将输入模式分为两类。而事实上输入向量模式的种类可能有许多种,为了将它们有效地分开,需要建立由多个神经元组成的感知器,其结构如图2。
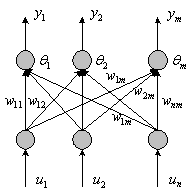
图2 感知器神经网络结构
图2所示的神经网络输出为
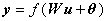 (1-8)
(1-8)
其中: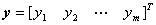 是感知器网络的输出向量;
是感知器网络的输出向量;
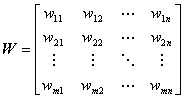 是各神经元之间的连接权系数矩阵;
是各神经元之间的连接权系数矩阵;
是感知器网络的输入向量;
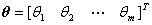 是感知器网络的阈值向量;
是感知器网络的阈值向量;
是感知器神经网络中的作用函数,由式(1-4)确定。
对于多神经元感知器而言,每个神经元都有一个类别界限。那么第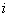 个神经元的类别界限为:
个神经元的类别界限为:
 (1-9)
(1-9)
其中: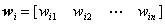 是输入向量与第个神经元间的连接权值;
是输入向量与第个神经元间的连接权值; 是第个神经元的阈值。
是第个神经元的阈值。
多神经元感知器可以将输入向量分为许多类,每一类由不同的向量表示。由于输出向量的每个元素可以取0或1两个值,所以一个由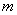 个神经元构成的感知器网络最多可以区分出
个神经元构成的感知器网络最多可以区分出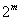 种输入模式。
种输入模式。
1.3 自适应线性神经元[4]
自适应线性元件(Adaptive Linear Element 简称Adaline),由威德罗(Widrow)和霍夫(Hoff)首先提出。自适应线性元件的主要用途是线性逼近一个函数式而进行模式联想,它与感知器的主要不同之处在于其神经元有一个线性激活函数,这允许输出可以是任意值,而不仅仅只是像感知器中那样只能取0或1,它采用的是W-H学习法则,也称最小均方差(LMS)规则对权值进行训练。图3给出了自适应线性神经元和网络的示意图。
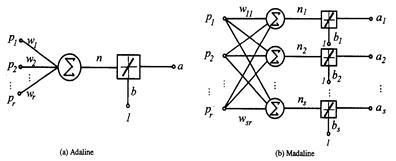
图3 (a)自适应线性神经元 (b)自适应线性神经网络
W-H学习法则:
采用W-H学习规则可以用来训练一层网络的权值和偏差使之线性地逼近一个函数式而进行模式联想。
定义一个线性网络的输出误差函数为:
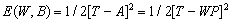 (1-10)
(1-10)
从式中可以看出线性网络具有抛物线型误差函数所形成的误差表面,所只有一个误差最小值,通过W-H学习规则来计算权值和偏差的变化,并使网络误差的平方和最小。
我们的目的是通过调节权矢量,使E(W,B)达到最小值。所以在给定E(W,B)后,利用W-H学习规则修正权矢量和偏差矢量,使E(W,B)从误差空间的某一点开始,沿着E(W,B)的斜面向下滑行。根据梯度下降法,权矢量的修正值正比于当前位置上E(W,B)的梯度,对于第i个输出节点有
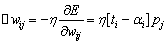 (1-11)
(1-11)
或表示为:
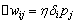 (1-12)
(1-12)
 (1-13)
(1-13)
这里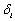 定义为第i个输出节点的误差。
定义为第i个输出节点的误差。
上式被称为W-H学习规则,又叫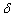 规则,或为最小均方算法(LMS)。W-H学习规则的权值变化量正比于网络的输出误差及网络的输入矢量,不需要求到处,所以算法简单;又具有收敛速度快和精度高的优点。
规则,或为最小均方算法(LMS)。W-H学习规则的权值变化量正比于网络的输出误差及网络的输入矢量,不需要求到处,所以算法简单;又具有收敛速度快和精度高的优点。
其中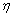 为学习速率。在一般的实际运用中,实践表明,通常取一接近1的数。
为学习速率。在一般的实际运用中,实践表明,通常取一接近1的数。
1.4 多层前向网络[5]
典型的多层前向网络包括BP(Back Propagation)网络和RBF(Radial Basis Function)网络。
1.4.1 BP(Back Propagation)网络
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,它是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer),如图4所示。同时,图5给出了单个的BP神经元。
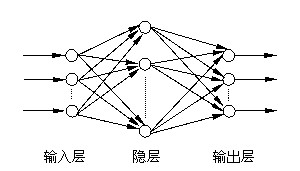
图4 BP神经网络结构示意图
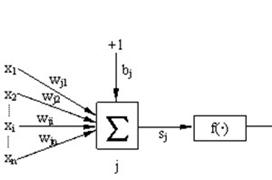
图5 BP神经元
BP神经网络的算法由工作信号的正向传播和误差信号的反向传播两个阶段组成。正向传播时,工作信号由输入层输入,经隐含层处理后再从输出层输出。在正向传播阶段,网络的权值和阈值是固定不变的,每一层神经元的状态只影响下一层神经元的状态。若输出层得不到期望输出,则转向反向传播,在反向传播阶段, 误差信号沿误差函数负梯度方向不断地修正各层的权值和阈值,使得误差信号最终达到输出精度要求, 从而实现输入和输出的非线性映射。具体算法描述如下:
(1) 正向传播阶段
1)输入节点的输入: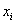 ;
;
2)隐含节点的输出: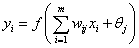 ;其中
;其中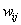 为连接权值,
为连接权值,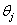 为节点阈值。
为节点阈值。
3)输出节点输出: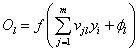 ;其中
;其中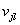 为连接权值,
为连接权值,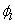 为节点阈值。
为节点阈值。
(2)反向传播阶段
在反向传播阶段,误差信号由输出端开始逐层向前传播,并沿误差函数负梯度方向对网络权值进行修正。设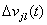 为输出层权值修正量,则:
为输出层权值修正量,则:
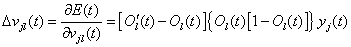 (1-14)
(1-14)
其中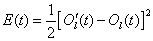 为误差函数,
为误差函数,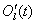 为期望输出。因此修正后的输出层权值为:
为期望输出。因此修正后的输出层权值为: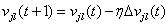 ,其中
,其中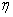 为步长或学习修正率。
为步长或学习修正率。
同理求得隐含层的权值修正量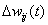 为:
为:
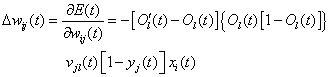 (1-15)
(1-15)
修正后的隐含层权值为: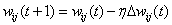 ,其中为步长或学习修正率。
,其中为步长或学习修正率。
1.4.2 RBF(Radial Basis Function)网络
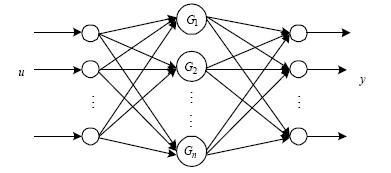
图6 RBF网络结构图
径向基函数(RBF-Radial Basis Function)神经网络,是在借鉴生物局部调节和交叠接受区域知识的基础上,提出的一种采用局部接受域来执行函数映射的人工神经网络。RBF网络结构是由一个隐含层(径向基层)和一个线性输出层组成的前向网络,隐含层采用径向基函数作为网络的激活函数。其结构如图6所示。
RBF网络第i个隐层节点的输出为:
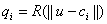 (1-16)
(1-16)
式中u为n 维输入向量;ci为第i 个隐节点的中心;|| × ||通常为欧氏范数;R(×) 为RBF 函数,具有局部感受的特性,它有多种形式,体现了RBF网络的非线性映射能力,通常取为高斯函数,其形式为:
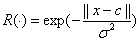 (1-17)
(1-17)
网络输出层第k 个节点的输出,为隐节点输出的线性组合:
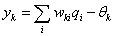 (1-18)
(1-18)
式中,wki 为qi 到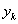 的联接权;qi为第k 个输出节点的阈值。
的联接权;qi为第k 个输出节点的阈值。
RBF网络的学习算法如下:设有p 组输入/输出样本, ,定义目标函数(L2 范数):
,定义目标函数(L2 范数):
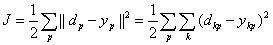 (1-19)
(1-19)
式中yp为在up 输入下网络的输出向量。
学习的目的是使
 (1-20)
(1-20)
RBF网络的学习算法由两部分组成:无导师学习、有导师学习。
(1)无导师学习:也称非监督学习,对所有样本的输入进行聚类,求得各隐层节点的RBF的中心ci。这里介绍用k 均值聚类算法,调整中心。(
(2)有导师学习:有导师学习也称监督学习。当ci 确定后,训练由隐层至输出层之间的权系值,由式(2-16)可知,它是一线性方程组,则求权系值就成为线性优化问题,可利用各种线性优化算法求得,如LMS 算法、最小二乘递推法、镜像映射最小二乘法等。
第二章 典型学习规则之间的比较及应用
Hebb学习规则是一切神经网络学习规则的基础,可以说,以后所有的学习规则都是基于Hebb规则的变形。
感知器学习规则在Hebb规则的基础上进行了改进,由感知器的网络结构,我们可以看出感知器的基本功能是将输入矢量转化成0或1的输出。
由于感知器的激活函数采用的是阀值函数,输出矢量只能取0或1,所以只能用它来解决简单的分类问题;感知器仅能够线性地将输入矢量进行分类。感知器还有另外一个问题,当输入矢量中有一个数比其他数都大或小得很多时,可能导致较慢的收敛速度。
自适应线性元件的主要用途是线性逼近一个函数式而进行模式联想。它与感知器的主要不同之处在于其神经元有一个线性激活函数,这允许输出可以是任意值,而不仅仅只是像感知器中那样只能取0或1。
自适应线性网络还有另一个潜在的困难,当学习速率取得较大时,可导致训练过程的不稳定采用W-H规则训练自适应线性元件使其能够得以收敛的必要条件是被训练的输入矢量必须是线性独立的,且应适当地选择学习速率以防止产生振荡现象。
因此,在网络模型结构上,感知器和自适应线性网络的主要区别在于激活函数,分别为二值型和线性。在学习算法上,感知器的算法是最早提出的可收敛的算法,它的自适应思想被威德罗和霍夫发展成使其误差最小的梯度下降法在BP算法中得到进一步的推广,它们属于同一类算法。它们各自的适用性与局限性在于,感知器仅能够进行简单的分类。感知器可以将输入分成两类或四类等,但仅能对线性可分的输入进行分类。自适应线性网络除了像感知器一样可以进行线性分类外,还可以实现线性逼近,因为其激活函数可以连续取值而不同于感知器的仅能取0或1的缘故。
BP网络是将W-H学习规则一般化,对非线性可微分函数进行权值训练的多层网络,权值的调整采用反向传播(Back-propagation)的学习算法,它是一种多层前向反馈神经网络,其神经元的变换函数是S型函数,输出量为0到1之间的连续量,它可实现从输入到输出的任意的非线性映射。但是BP网络拓扑结构的设计没有确定的规则,即网络隐层数、每层隐节点个数及其激活函数的选取,在理论上没有一个明确的规定;BP算法的收敛速度慢,且收敛速度和初始权值的选择有关;由于是非线性优化,不可避免的存在局部极小问题。
RBF与BP网络主要不同点是,在非线性映射上采用了不同的作用函数,分别为径向基与S 型函数,前者的作用函数是局部的,后者的作用函数是全局的。已证明RBF网络具有惟一最佳逼近的特性,且无局部极小。求RBF网络隐节点的中心标准化参数是一困难问题。径向基函数,即径向对称函数,有多种。对于一组样本,如何选择合适的径向基函数、如何确定隐节点数,以使网络学习达到要求的精度,这是尚未解决的问题。当前,用计算机选择、设计、再检验是一种通用的手段。
感知器的输出矢量可以取0或1,所以能用它来解决简单的分类问题。自适应线性网络除了像感知器一样可以进行线性分类外,还可以实现线性逼近。BP和RBF常用于非线性系统辨识与控制中。
总 结
本文就各种学习规则进行了学习和讨论,并给出了各种学习规则的优点和缺陷及各自的应用。
参考文献:
[1]黄德双,关于21世纪人工智能与神经网络技术发展的展望,[会议记录],1999
[2]袁曾任,人工神经元网络及其应用[M],北京:清华大学出版社,1999
[3]曹安照,田丽,陈俊,吕元峰,神经网络及其研究展望,自动化与仪器仪表,2006
[4]Krogh A,Vedeksby J,Neural network Ensembles,Cross Validation,and Active Leaning,In:Tesauro D,Touretzky D,Leen T,eds. Advances in Neural Information Processing System 7. Cambridge MIT Press,1995,231-238
[5] 古芳春,神经网络优化理论研究及应用,[硕士学位论文],2002