课程设计任务书
学生姓名: 专业班级:
指导教师: 工作单位:
题目:出版商印刷数据库设计
初始条件:
一个印刷书的印刷公司希望建立数据库来处理用户的印刷需要。一本书的出版发行人员提交了一份描述印刷工作的单据,印刷工作需要的使用材料,由购买清单指定。
要求完成的主要任务:
1. 根据上述的初始条件,进行调查分析并设计适当的属性。设计一个出版商数据库,DBMS可选Ms SQL Server、Access、VFP等。
2. 完成课程设计说明书,其格式遵守学校今年的新规定。主要内容包括:需求分析,概念设计,逻辑设计,物理实现等。
3. 基于该数据库,最好实现一个或多个应用程序(自己确定功能),程序设计语言(工具)任选。这一项是选作,不作硬性要求。
时间安排:
本学期第19周:
1. 消化资料、系统调查 1天
2. 系统分析 1天
3. 总体设计,实施计划 2天
4. 撰写报告 1天
指导教师签名: 年 月 日
系主任(或责任教师)签名: 年 月 日
出版商印刷数据库设计
1. 概述:
1.1设计题目:出版商印刷数据库设计
1.2可行性分析:题目的初始化条件是,出版发行人员的一份描述印刷工作的单据,以及购买清单所指定的印刷所需要的工作使用材料。因此,可以根据这两个条件出发,为印刷公司建立一个比较简洁而又功能完善的数据库系统。
2. 系统目标和建设原则:
2.1 系统目标设计:
2.1.1使得印刷工作更加清晰化,条理化,自动化。
2.1.2 很容易地完成印刷工作单据的输入,购买清单的输入。
2.1.3 能为用户提供一个比较友好的界面,方便用户查询各个印刷工作的前台和后台的具体情况。比如出版的书名,作者,印刷数量,交货时间等。
2.1.4 能够预测计算出出版一本书的大概盈利值。(盈利值=投资人提供资金-印刷工作耗费资金-购买所需材料耗费资金)
2.1.5 设计一个系统权限管理模块,提供各种类别权限的系统用户。
2.2 建设原则:关系苏护具库。
3. 运行环境规划:
开发环境:Windows XP
辅助工具:PowerDesigner Trial 11,Word 2003
数据库管理系统:SQL Server 2005
运行环境:Windows 2000/XP/2003
4. 需求分析说明:
4.1 引言:
进行数据库设计首先必须准确了解也分析用户需求(包括数据和处理)。目的是为学籍管理数据库系统的设计打下牢牢的基础,是数据库开发的重要文件依据,主要为数据库设计人员使用,是用户和系统分析员的项目依据文件。作为“地基”的需求分析是否做得充分与准确,它决定了在其上构建数据库大厦的速度和质量。需求分析做得不好,甚至会导致整个数据库设计返工重做。
本系统的开发是设计一个出版商印刷的数据库管理系统。
4.2用户需求:
本系统的开发是设计一个出版商印刷的数据库管理系统。由于要求实现的功能比较简单。具体包括一下功能:
* 系统管理员负责对出版发行人员提交的印刷数据单据的内容进行插入,删除,修改等操作。
* 系统管理员负责对购买清单的具体内容进行插入删除,修改操作。
* 用户可以查询出版的各本书的具体信息,以及查询预计盈利值。
* 用户可以查询印刷所用材料的购买清单的具体内容。
以上是用户对系统的基本的功能要求,此外用户还要求系统的效率要高,查询速度要快,比较小的冗余,易维护,具有较高的数据安全性。
4.3 划分功能模块:
根据系统功能的需求分析和出版社印刷管理的特点,经过模块化的分析得到如下图1-1所示的系统功能模块结构图。

4.4数据字典:
数据字典是系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果,数据字典是对系统所用到的所有表结构的描述。出版印刷管理的主要数据见下表:
表4.1印刷工作单据信息表:
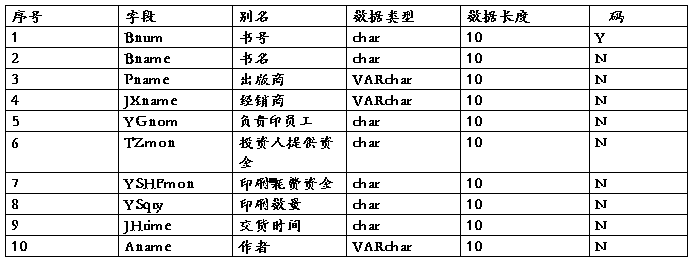
表4.2 购买清单信息表:

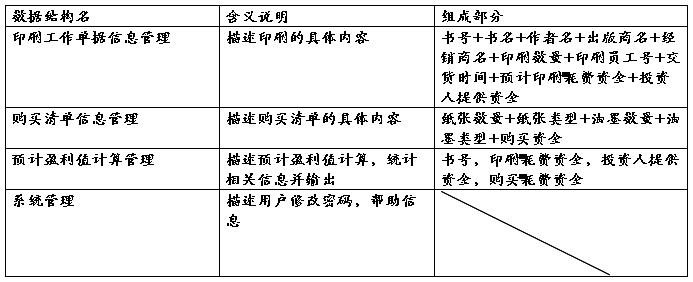
4.5数据结构:
数据结构反映了数据之间的组合关系。一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或若干个数据项和数据结构混合组成。经过数据项和用户需求的分析,我对本系统一共分了4个组,具体如下表所示:
5. 概念结构设计:
概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成独立于具体DBMS的概念模型。
5.1数据流图:由于画数据流图比较繁琐,故而此处略过不画。
5.2 系统E-R图:
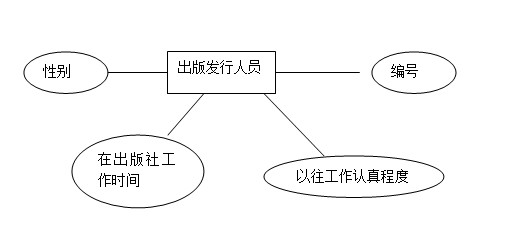
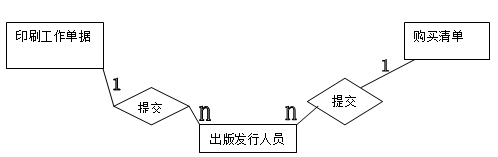
5.2.1.对于本系统,可以把出版发行人员独立出来作为一个实体,由于其具体属性无关紧要,故而E-R图比较简洁,具体E-R图如下:
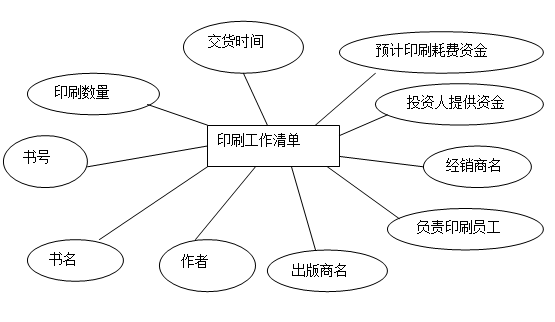
5.2.2.印刷工作单据作为实体的E-R图如下:
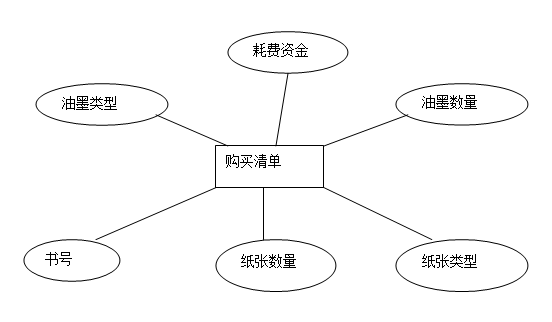
5.2.3.购买清单位实体的E-R图如下:
5.2.4 在这样一个系统中,存在这样一种关系:
提交:(一个出版发行人员只可以提交一份印刷工作单据和一份购买清单,而一份印刷工作单据可以由不同的出版发行人员提交,一份购买清单也可以由不同的出版发行人员提交,故而出版发行人员和印刷工作单据是多对一的关系,出版发行人员和购买清单也是多对一的关系。
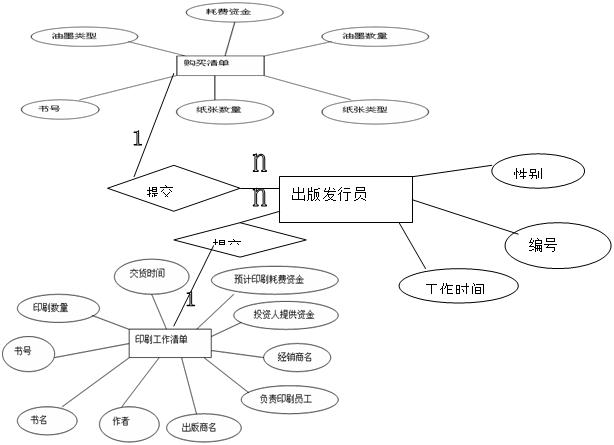
5.2.5系统总的E-R图:
6. 逻辑结构设计:
逻辑结构设计就是把概念结构设计阶段设计好的基本E-R图转换为与选用DBMS产品所支持的数据模型相符合的逻辑结构。
设计逻辑结构一般分为3步进行:
(1)将概念结构转换为一般的关系、网状、层次模型;
(2)将转换来的关系、网状、层次模型向特定DBMS支持下的数据模型转换;
(3)对数据模型进行优化。
6.1 关系模型
将E-R图转换为关系模型实际上就是要奖实体型、实体的属性和实体型之间的联系转换为关系模式,这种转换一般遵循如下原则:一个实体型转换为一个关系模式。实体的属性就是关系的属性,实体的码就是关系的码。对于实体型间的联系则有以下不同的情况:
(1)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的个实体的码以及联系本身的属性均转换为关系的属性,每个实体的码均是该关系的侯选码。如果与某一端实体对应的关系模式合并,则需要在关系模式的属性中加入另一个关系模式的码和联系本身的属性。
(2)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的个各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为n端实体的码。
(3)一个m:n联系转换为一个关系模式。与该联系相连的个实体的码以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分。
(4)3个或3个以上实体间的一个多元联系可以转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分。
(5)具有相同码的关系模式可合并。
将概念结构设计阶段设计好的基本E-R图转换为关系模型,如下所示:
* 印刷工作单据(书号,书名,作者,出版商,经销商,印刷数量,投资者提供资金,交货时间,印刷耗费资金,负责印刷员工编号)此为印刷工作单据实体所对应的关系模式。
*购买清单(书号,纸张数量,纸张类型,油墨数量,油墨类型,耗费资金)此为购买清单实体所对应的关系模式
*出版发行员(编号,性别,工作时间,以往工作认真程度)此为出版发行员实体所对应的关系模式
6.1 物理模型:

7. 数据库的物理设计:
7.1 物理结构设计
数据库的物理设计就是为一个给定的逻辑数据模型选取一个最适合应用要求的物理结构的过程。物理结构设计阶段实现的是数据库系统的内模式,它的质量直接决定了整个系统的性能。因此在确定数据库的存储结构和存取方法之前,对数据库系统所支持的事务要进行仔细分析,获得优化数据库物理设计的参数
数据库的物理设计通常分为两步:
(1)确定数据库的物理结构,在关系数据库中主要指存取方法和存取结构;
(2)对物理结构进行评价,评价的重点是时间和空间效率。
7.1.1 确定数据库的存储结构
由于本系统的数据库建立不是很大,所以数据存储采用的是一个磁盘的一个分区。
7.1.2 存取方法和优化方法
存取方法是快速存取数据库中数据的技术。数据库管理系统一般都是提供多种存取方法。常用的存取方法有三类。第一类是索引方法,目前主要是B+树索引方法;第二类是聚簇方法;第三类是HASH方法。数据库的索引类似书的目录。在书中,目录允许用户不必浏览全书就能迅速地找到所需要的位置。在数据库中,索引也允许应用程序迅速找到表中的数据,而不必扫描整个数据库。在书中,目录就是内容和相应页号的清单。在数据库中,索引就是表中数据和相应存储位置的列表。使用索引可以大大减少数据的查询时间。
但需要注意的是索引虽然能加速查询的速度,但是为数据库中的每张表都设置大量的索引并不是一个明智的做法。这是因为增加索引也有其不利的一面:首先,每个索引都将占用一定的存储空间,如果建立聚簇索引(会改变数据物理存储位置的一种索引),占用需要的空间就会更大;其次,当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的更新速度。
由于本系统不是特别复杂,故而不需要额外建立一个索引。
8. 数据库的实施:
完成数据库的物理设计之后,设计人员就要用RDBMS提供的数据定义语言和其他实用程序将数据库逻辑设计和物理设计结果严格描述出来,成为DBMS可以接受的源代码,再经过调试产生目标模式。然后就可以组织数据入库了,这就是数据库实施阶段。
数据库的实施主要是根据逻辑结构设计和物理结构设计的结果,在计算机系统上建立实际的数据库结构、导入数据并进行程序的调试。它相当于软件工程中的代码编写和程序调试的阶段。
8.1数据库系统的功能设计和说明:
8.1.1完成数据库的物理设计之后,设计人员就要用RDBMS提供的数据定义语言和其他实用程序将数据库逻辑设计和物理设计结果严格描述出来,成为DBMS可以接受的源代码,再经过调试产生目标模式。然后就可以组织数据入库,最后就在此基础上编写各个表相关的触发器和存储过程。
触发器是用户定义在关系表上的一类由事件驱动的特殊过程。一旦定义,任何用户对表的增、删、改操作均由服务器自动激活相应的触发器,在DBMS核心层进行集中的完整性控制。这里只简单举个例子:
数据更新
CREATE TRIGGER scupdate ON dbo.publishwork //建立印刷工作单据信息表更新触发器
FOR UPDATE
AS
UPDATE buylist//更新购买清单信息表buylist
SET Bnum = (SELECT Bnun FROM INSERTED) //将buylist表中的书号改成印刷工作单据表改后的
WHERE Bnum= (SELECT SNO FROM DELETED); //更改对应的书号
8.2数据库的实现:
在SQL SERVER 20## 中生成的表格如下:
印刷工作单据信息表:
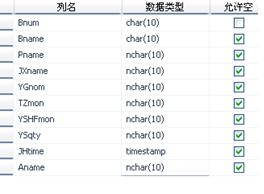
购买清单信息表:
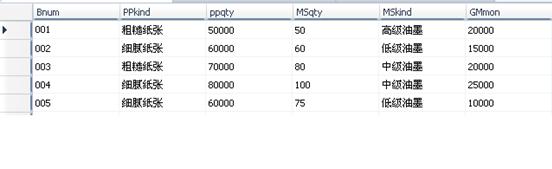
8.3数据的载入:
数据库实施阶段包括两项重要的工作,一项是数据的载入,另一项是应用程序的编码和调试。由于本次课程设计没有进行应用程序的开发,因此对于后一项工作在这里就不做描述了。具体输入的一部分数据如下图所示:
输入印刷工作单据的信息:

输入购买清单的信息:
9. 数据库的运行和维护:
9.1 通过SQL语句进行简单测试
当一小部分数据输入数据库后,就可以开始对数据库系统进行联合调试,这一阶段要实际运行数据库应用程序,执行对数据库的各种操作,由于没有应用程序,所以只有通过SQL语言直接在数据库中执行对数据库的各种操作。
通过在SQL Server 2000的查询分析器中输入相应的SQL语句,就可以得到相应的结果,具体如下所示:
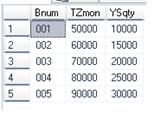
(1) 查询印刷工作单据的部分信息:
select Bnum ,TZmon,YSqty from publishwork
执行结果:
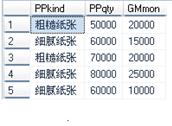
(2) 查询购买清单单据的部分信息:
select PPkind,PPqty,GMmon from buylist
执行结果
(3) 一些修改,删除表项的例子这里不在给出。
10. 设计体会与建议:
为期一周的课程设计终于结束。随着这份任务书的尘埃落定,这次课程设计也算圆满完成。虽然当中存在很多不足,但是感觉自己能够独立认真的完成这次课程设计所给的任务,也算是有点欣慰。
通过这一个星期的课程设计使我对这学期学的知识有了全面的认识。由于以前大部分时间都在学习理论的知识,所以对数据库设计不是很了解。这次课程设计是对自己的理论知识的全面考察,同时也是对自己应用能力的考验。在这次设计的系统中,我主要实现的功能是完成对印刷工作单据表和购买清单表的插入,修改,删除的操作。可以按照特定的信息进行查找,并按照特定的要求进行排序,并打印输出。可是尤为不足的是,自己在系统建设目标和用户需求上所期待的计算预计盈利值并没有实现出来,由于时间的仓促并没有写出对应的应用程序,这是比较遗憾的地方。
另一方面,我感觉这次的课程设计老师所给的题目要求含糊了些,我到现在都还不确定自己这样的想法模型到底是不是老师所要求和所想的模型。只能自己按照自己的理解,凭着自己对那几句简洁的初始条件的理解进行设计。通过跟同学的商议,觉得这样应该是可行的。希望老师能理解。
总的来说,这次课程设计收获良多。感觉理论和实践存在很大的差距。自己在以后的学习过程中应该更加注重实践。
11. 参考文献:
《数据库系统概论》 第三版 萨师煊 王珊 高等教育出版社
《数据仓库技术与联机分析处理.》 王珊等 北京.科学出版社
《数据仓库》 Inmon W H等 电子工业出版社