《资源植物学》
一、实验课名称:《资源植物学》
Resources Botany
二、实验课性质:非独立设课
三、适用专业:生物科学
四、采用教材及参考书
1. 何明勋主编.资源植物学,上海:华东师范大学出版社,1996
2.刘胜祥主编.植物资源学(第二版),武汉:武汉出版社,1994
3.董世林主编.植物资源学,哈尔滨:东北林业大学出版社,1994
4.戴宝合主编.野生植物资源学,北京:农业出版社,1993
五、学时学分:
课程总学时:54;课程总学分: 18;实验课总学时:36;
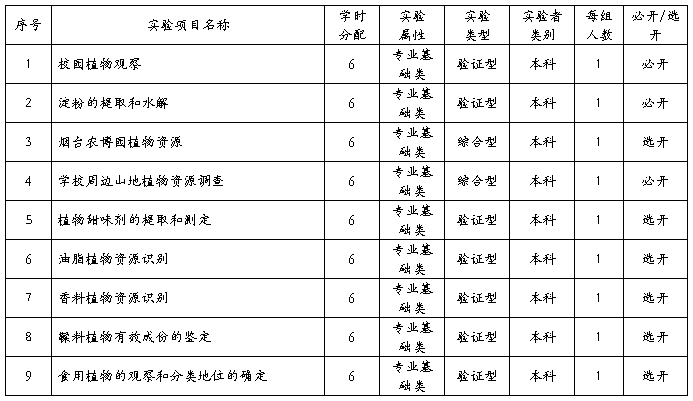
六、实验项目名称和学时分配
七、实验教学的目的和要求
资源植物学实验是资源植物学教学的一个重要组成部分,要求把课堂教学中讲授的理论知识应用到实际材料的观察,做到理论联系实际,加深和巩固所学的理论知识,开发学生的智力,启发学生的学习兴趣。并通过实验,熟练掌握各种植物资源的特点、资源植物学的研究方法、植物化学的基本原理和研究方法、保护更新技术等知识,培养独立思考、独立工作的能力,养成严谨的科学态度与实事求是的工作作风。
八、实验项目的内容和要求
实验一 校园植物观察
实验内容: 观察校园内环境中植物的类群生长情况;观察裸子植物的生长情况和种类;观察被子植物的生长情况和种类。
实验要求:观察校园内种子植物的特点,了解种子植物中裸子植物与被子植物的区别。为校园内生长的种子植物设计挂牌(裸子植物与被子植物各10种,要鉴定到种)。
实验二 淀粉的提取和水解
实验内容: 以马铃薯或甘薯等为原料,利用多糖和水生成胶体溶液的原理,采用过虑和沉降等方法提取淀粉。
实验要求:掌握淀粉提取和水解的原理及操作方法。
应配备的主要设备名称和台件数

实验三 烟台农博园植物资源
实验内容: 参观并调查烟台市农博园花卉育苗室,热带作物温室,苹果、樱桃等水果种质园。
实验要求:调查植物类群,并了解不同环境中植物的生长情况;掌握环境中植物的保护、利用情况。
实验四 学校周边山地植物资源调查
实验内容: 观察环境中植物的类群;不同环境中植物的生长情况;环境中植物的保护、利用情况;环境中的植物与我们文化生活的关系。
实验要求:通过观察生活、工作环境中的植物类群,了解植物资源,学习调查的方法。根据你的观察,写出3000字左右的调查报告。
实验五 植物甜味剂的提取和测定
实验内容: 进行甜味剂提取操作
实验要求:掌握植物甜味剂(糖类)提取的原理和技术
实验六 油脂植物资源识别
实验内容: 油脂植物形态特征观察
实验要求:能够识别主要油脂植物;了解主要植物油脂的特征及利用现状。
实验七 香料植物资源识别
辛香料植物器官形态特征观察
实验要求:能够识别主要辛香料植物;了解主要辛香料的用途及利用现状。
实验八 鞣料植物有效成份的鉴定
实验内容: 鉴别鞣质的成分,测定其含量
实验要求:了解单宁理化性质;掌握单宁的定性和定量
实验九 食用植物的观察和分类地位的确定
实验内容: 观察环境中植物的类群;观察环境中的油料植物(10种),淀粉类植物(10种),蛋白类植物(5种)。
实验要求:观察生活、工作环境中的食用植物,了解食用植物的特点和分类学中的地位。根据你的观察,用表的形式归纳、总结25种植物的特点和分类学中的地位(要求鉴定到科)。
九、实验课考核方式
(1)实验报告:本门课程对实验报告的要求包括以下内容:①实验目的:明确;②方法与步骤:具体操作步骤、注意事项等;③结果:详细记录每一步的结果;④绘图:绘制的形态图或结构图要准确、整洁,线条要清晰,大小比例要适中。
(2)考核方式:实验课考核成绩确定:本课程考核成绩由平时成绩(占30%)、实验报告成绩(占30%)和期终考核成绩(占40%)三部分构成。
①平时成绩确定:由任课教师根据考勤、实验操作、问题回答和出勤情况确定,按A(优)、B(良)、C(及格)、D(不及格)四个等级评分。
②实验报告成绩:由任课教师根据学生实验报告写作是否符合规范要求、内容是否正确及的具体情况给出。每次报告均按A(优)、B(良)、C(及格)、D(不及格)四个等级评分,实验报告成绩为各次报告成绩的平均值。
③终期考核成绩:实验课结束后进行笔试或口试及现场操作考核,按A(优)、B(良)、C(及格)、D(不及格)四个等级评分。
第二篇:课上实验
实验16 主成分分析与聚类分析
一、实验目的
通过本实验学习主成分分析法,学习如何寻找主要因素,如何寻找一个变换,把原来存在相关关系的一组变量或多个样品的多个指标转化为不相关的一组变量或少数指标的方法.学习如何应用聚类分析法对一些因素进行分类的方法.
二、实验使用的软件
Mathematica4.0或以上版本。
三、实验的基本理论与方法
1. 主成分分析
设有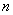 个样品,每个样品测得户个指标,共有
个样品,每个样品测得户个指标,共有 个数据,然而指标之间往往互有影响主成分分析的工作就是从
个数据,然而指标之间往往互有影响主成分分析的工作就是从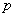 个指标中找出妙的几个综合性指标,利用对少数几个指标的分析来达到目的.当然希望找到的综合指标能尽可能多地反映原来资料的信息,而且彼此之间是相互独立的.
个指标中找出妙的几个综合性指标,利用对少数几个指标的分析来达到目的.当然希望找到的综合指标能尽可能多地反映原来资料的信息,而且彼此之间是相互独立的.
设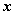 是户维随机向量,它的均值向量为
是户维随机向量,它的均值向量为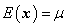 (维实向量),它的协方差矩阵为
(维实向量),它的协方差矩阵为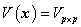 ,现在求的线性函数
,现在求的线性函数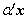 (
(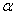 也是维实向量),使得的方差尽可能地大.由于
也是维实向量),使得的方差尽可能地大.由于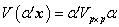 ,对于任给常数
,对于任给常数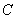 ,
,

因此,对不加限制时,问题没有意义,于是限制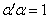 .求
.求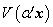 的最大值,实际上就是求
的最大值,实际上就是求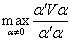 的值.由线性代数理论可知,它就是矩阵
的值.由线性代数理论可知,它就是矩阵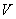 的最大特征根
的最大特征根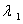 ,且就是)的相应特征向量,不妨记为
,且就是)的相应特征向量,不妨记为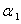 .同样,与正交的单位向量中,使得
.同样,与正交的单位向量中,使得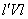 最大的
最大的 (
(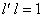 )是
)是 对应的特征向量
对应的特征向量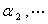 ,与
,与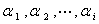 正交的单位向量中,使得最大的向量是
正交的单位向量中,使得最大的向量是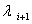 对应的特征向量
对应的特征向量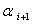 (其中
(其中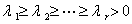 ).因此,把的非零特征根所对应的单位特征向量
).因此,把的非零特征根所对应的单位特征向量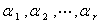 分别作为系数向量,
分别作为系数向量,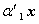 ,
,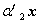 ,
,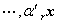 分别称为随机向量的第一主分量,第二主分量,……,第r主分量.中主对角元素
分别称为随机向量的第一主分量,第二主分量,……,第r主分量.中主对角元素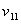 ,
,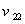 ,…,
,…,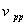 分别是中各个分量
分别是中各个分量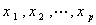 的方差,因而 的“总方差”也就可以认为是 ++…+=
的方差,因而 的“总方差”也就可以认为是 ++…+=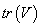 。另一方面,记
。另一方面,记
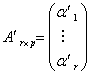 令
令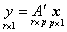 ,
,
则 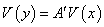 ,
, ,
,
即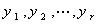 不相关,各自的方差为
不相关,各自的方差为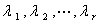 ,总方差为
,总方差为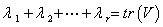 .第一主分量的方差最大为
.第一主分量的方差最大为 ,比值
,比值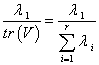 表明了
表明了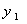 的方差在全部方差中的比值,称为第一主分量的贡献率.这个值越大,表明这个变量的综合能力越强,代表力也越强.主分量分析就是求出方差矩阵的特征值与特征向量,并加以解释.具体做法如下:
的方差在全部方差中的比值,称为第一主分量的贡献率.这个值越大,表明这个变量的综合能力越强,代表力也越强.主分量分析就是求出方差矩阵的特征值与特征向量,并加以解释.具体做法如下:
1)求出有关数据的协方差矩阵
设第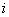 个随机变量的个观察值分别为
个随机变量的个观察值分别为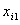 ,
,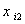 ,…,
,…,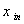 ,个随机变量的观察值可排成一个
,个随机变量的观察值可排成一个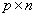 矩阵
矩阵
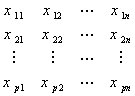
由于协方差矩阵的元素
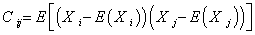
以统计均值代替随机变量的均值,记
则协方差矩阵的通项为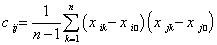
2)求协方差矩阵的特征值与特征向量
利用Mathematica中的求特征值与特征向量语句即可.
3)分析
根据特征值及特征向量分析主成分是什么,主成分所占比例是多少.
2.聚类分析法
对给定的个对象及其某些性质的观测可以根据内在相似性对它们进行分组.聚类分析的工作就是对给定的个观测对象的个观测特征,将它们聚成若干个可定义的类,而对应的备择假设是它们不能分类.聚类分析的方法很多,这里主要介绍散布于某个中心值周围的群的聚类.聚类分析的主要思想是两个组的分离程度依赖于各组均值之间的距离和组内各观测点之间的平均距离之比.具体做法如下:
1)首先求出有关数据的相关矩阵
相关矩阵的通项为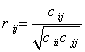 ,其中
,其中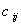 为协方差距阵的元素。
为协方差距阵的元素。
2)分析
根据相关矩阵以及某个标准,将相互之间相关系数较大的一组变量聚成一类,其余类似.
四、实验内容与步骤
1. 表16.1给出20个土壤标本的有关资料,即含沙量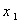 ,淤泥含量
,淤泥含量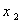 ,粘土含量
,粘土含量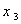 ,有机物
,有机物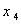 及酸性指标PH值
及酸性指标PH值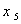 .实际上,这些数据是很大一批资料的一部分,但是为简单说明主分量分析方法,只限于20个样本.试对表中数据作主分量分析.
.实际上,这些数据是很大一批资料的一部分,但是为简单说明主分量分析方法,只限于20个样本.试对表中数据作主分量分析.
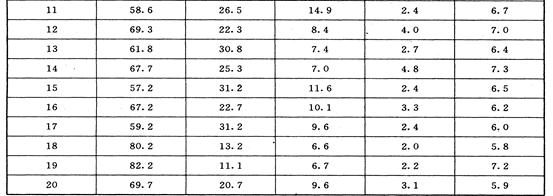
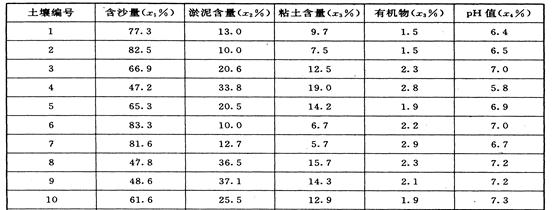 表16.1
表16.1
1) 表中数据的协方差矩阵
Clear[a,b,c]
a={{77.3,82.5,66.9,47.2,65.3,83.3,81.6,47.8,48.6,61.6,58.6,69.3,61.8,
67.7,5.2,67.2,59.2,80.2,82.2,69.7},{13.0,10.0,20.6,33.8,20.5,10.0,12.7,
36.5,37.1,25.5,26.5,22.3,30.8,25.3,31.2,22.7,31.2 ,13.2,11.1,20.7},{9.7,
7.5,12.5,19.0,14.2,6.7,5.7,15.7,14.3,12.9,14.9,8.4,7.4,7.0,11.6,10.1,9.6,
6.6,6.7,9.6},{1.5,1.5,2.3,2.8,1.9,2.2,2.9,2.3,2.1,1.9,2.4,4.0,2.7,4.8,2.4,
3.3 ,2.4,2.0,2.2,3.l},{6.4,6.5,7.0,5.8,6.9,7.0,6.7,7.2,7.2,7.3,6.7,7.0,6.4,
7.3,6.5,6.2,6.0,5.8,7.2,5.9}} (输入数据矩阵)
mean[x_]:=Apply[Plus,x]/Length[x] (定义平均值函数)
b=Table[mean[a [[i]],{i,1,5}] (分另求五个变量的均值)
c=Table[Sum[(a[[i , k]]- b[n])*(a[[j,k]]-b[[j]]),{k,1,2 0}]/19,{i,1,5},
{j,1,5}] (作协方差矩阵)
Out[ ]:={{138.327,- 102.123,-36.204,- 0.942211,- 0.0351579},{-102.123,79.7382 , 22.3846,1.52661,0.021684 2,{- 36.204, 22.3846,13.8194,- 0.584395,0.0134737},{- 0.942211,1.52661,- 0.584395,0.643447,0.0337895},{0.0351579,0.0216842, 0.01 34737,0.0337895,0.267789}}
2)利用Mathematica中的语句Eigenvalues,Eigenvectors,Eigensystem,求c的特征值及特征向量.输入
d=Eigensystem[c]
得到协方差矩阵的特征向量和特征值作成的表{特征值,{特征向量}}
{{223.841,8.21807,0.00000,0.474078,0.2621 6},{{-0.784945,0.587081, 0.197864,0.006811,0.00019333},{0.223099,0.560796,-0.783895,0.145751, - 0.0001 66084},{0.57735,0.57735,0.57735,0.00000,0.00000},{- 0.0270671, -0.0855086,0.112576,0.976094,、0.162859},{0.00465914,0.0140937, -0.0187528,-0.161094,0.986649}}}
3)根据所得结果分析
注意到有一个特征值是0,变量中有线性相关关系.这线性关系是
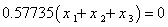
因此,可以去掉一个变量,对到,重复这个分析
Clear[a,b,c,d]
a={{13.0,10.0,20.6,33.8,20.5,10.0,12.7,36.5,37.l,25.5,26.5,22.3,30.8,
25.3,31.2,22.7,31.2,13.2,11.1,20.7},{9.7,7.5,12.5,19.0,14.2,6.7,5.7,15.7,
14.3,12.9,14.9,8.4,7.4,7.0,11.6,10.1,9.6,6.6,6.7,9.6},{1.5,1.5,2.3,2.8,
1.9,2.2,2.9 2.3,2.1,1.9,2.4,4.0,2.7,4.8,2.4,3.3,2.4,2.0,2.2,3.1},{6.4,6.5,
7.0,5.8,6.9,7.0,6.7,7.2,7.2,7.3,6.7,7.0,6.4,7.3,6.3,6.2,6.0,5.8,7.2,5.9}}
b=Table[mean[a[[i]]],{i,l,4}]
c=Table[Sum[(a[[i,k]]-b[[i]])*(a[[j,k]]-b[[j]]),{k,1,20}]/19,{i,1,4},{j,1,4 }]
d=Eigensystem[c]
得到协方差矩阵的特征值与特征向量如下
{{8 6.6401,7.09356,0.473024,0.262143},{{0.955786,0.29682,0.0149714,
0.000291625},{-0.288018,0.945193,-0.153803,0.00018941},{-0.0585583, 0.140727,0.974693,0.16352 3,{0.00947906,-0.0235944,-0.161535, 0.986539}}}
第一主成分为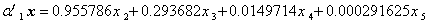
所占比例 =0.917129
=0.917129
说明第一主成分所占比例为91%以上.这个主成分主要是淤泥含量和粘土含量,与有机物和酸性无关.
2.表16.2给出了 48个应征者在 15个方面所得分数,这15个方面包括:
(1)申请书形式(2)外貌(3)学术能力(4)讨人喜欢(5)自信程度(6)精明(7)诚实(8)推销能力(9)经验(10)积极性(11)抱负(12)理解能力(13)潜力(14)交际能力(15)适应性
现在对这15个方面进行聚类,看看哪些方面可能是相关的或混同的.
(1)求相关距阵


mean[x_]:=Apply[Plus,x]/Length[x]
a=Table[mean[a[[i]]],{i,1,15}]
b= Table[Sum[(a[[i,k]]-b[[i]])*{a[[j,k]]-b[[j]]},{k,1,48}]/47,{i,1,15},{j,1,15}] (协方差矩阵)
c=Table[c[[i,j]]/(Sqrt[c[[i,j]]*c[[j,j]]]),{i,1,15},{j,1,15}] (相关矩阵)
N[%,2]
表16.1

得到相关矩阵

(2)作聚类分析
利用这个相关矩阵可以进行聚类分析。如果两个向量的相关系数大于0.7,就认为它们是靠近的,并且如果一组向量的相关系数都大于或等于0.7,他们就构成一个类.注意到(16,12)和(12,13)有最大相关0.88,假定取(12,13)作为一个可能聚类的核心,之后又发现10,11,都与变量12,13高度相关,并且这两个变量相互间也有较大的相关,因此,可以把他们归为一类,得到集合(10,11,12,13),进一步,考虑变量6和8,也可以并入这“类.而且如果将变5和13的相关系数放宽,把0.67作为一个略低的临界值,5也可以加进来,这样7个变量聚成一类(5,6,8,10,11,12,13),如果从相关矩阵中去掉7个变量所对应的行和列,就得 到其余8个变量的相关矩阵,其相关系数都不到0.7.在这个标准下,可以说其他变量不能聚类,或着说各变量自成一类而构成8个类.把0.7作为临界值是有些任意性,如果把靠近的要求放宽,就可以把(1,9,15)组合到一起,同样也可以把(4,7,14)组合在一起,其平均相关系数为0.60,变量3(学术能力)自成一组,变量2(外貌)与变量11,12,13的相关系数都大于0.5,因此,大概可以包含在主要组中.
可以假设这些变量是不独立的,并且用四种组合来判断:第一是外貌、自信程度、精明、积极性、抱负、理解力、和潜力的混合物,第二是申请书、经验和适应性(主要是经验分量);第三包括讨人喜欢、诚实和交际能力;第四是学术能力.
五、练习与思考
某大学一年级15名学生体检按四项指标进行:犯身高Jz体重*。胸围J。坐高,得数
据如下:
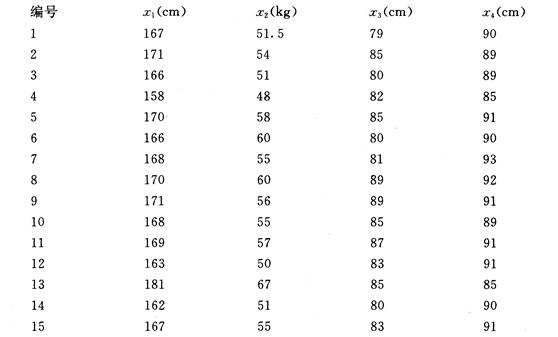
试对体形作聚类分析.